►
Description
Deep Learning for Science School 2019 - Lawrence Berkeley National Lab
Agenda and talk slides are available at: https://dl4sci-school.lbl.gov/agenda
A
Okay,
so
in
a
first
few
lectures
in
this
day
planning
it
was
where
you
were
getting
familiar
with
image
classification.
How
neural
networks
can
help
you
with
yeah
I've,
seen
the
previous
talk,
I've
seen
how
many
cuts
you've
seen
already
so
I
promise
you
there
will
be
a
few
dogs
dog
lovers
so
yeah,
so
we
pretty
much
I
think,
like
all
of
us,
pretty
much
familiar
with
image
classification
for
now,
but
what
if
we
have
much
more
complex
same
with
multiple
objects?
And
what
can
we
do
so?
A
There
are
different
ways
like
there
are
different
recognition.
Problems
can
be
division,
scientists
looking
for
as
of
right
now,
so
one
of
there's
called
semantic
simulation.
I
will
be
covering
it
and
that
just
solve
a
classification
problem
for
each
pixel
on
the
edge
so
for
each
pixel
we
design
what
category
it
belongs
to
then.
The
next
problem
is
bounding
box
object,
detection,
where
we
try
to
find
identify
objects
of
the
certain
classes
and
then
delineate
them
with
next
a
bit
more
involved.
A
Thin
is
instant
segregation
there.
Instead
of
just
bounding
boxes,
we
can
found
objects
and
delineate
them
with
masks.
And
finally,
what
computer
vision
community
is
working
on
as
of
right
now
as
an
optic
simulation
as
well,
where
we
just
try
to
predict
both
instance
and
semantics.
Imitation
together,
we'll
cover
it
a
bit
later
and
there
is
more
to
recognition
problems
in
computer
vision.
So
if
you're
unhappy
with
just
boxes
and
masks,
then
you
can
get
key
points
for
human
post.
A
If
you're
not
happy
with
just
key
points,
you
can
get
poses
and
like
align,
that
each
person
with
a
dance
pose
basically
with
canonical
shape
of
the
human
and
then,
if
you're
not
happy
with
2d,
you
can
go
to
3d
and
then
recognize
not
just
masks
of
no
check
but
they're
meshes
as
well.
There
will
be
a
lecture
on
3d
geometry
that
will
color
or
this
kind
of
words
tomorrow.
A
Okay,
so
now
we
will
go
through
this
through
this
topics.
First
touching
with
semantics
condition:
oh
by
the
way,
if
you
have
any
questions-
and
anything
is
unclear,
please
do
stop
me
and
ask,
and
I
will
be
more
than
happy
to
answer.
Okay,
so
semantic
simulation
again,
while
we're
task
is
label
each
pixel
with
semantic
category.
So
before
we
just
had
a
cat,
we
had
a
category
for
the
whole
image
now,
for
each
pixel
will
have
a
category
like
grass,
cat
sky,
trees,
I
think
it's
pretty
clear.
A
Okay,
now
we
have
like
you
important
properties
of
semantics
imitation.
First
of
all,
it's
a
predefined
set
of
semantic
categories,
so
the
same
thing
as
class
of
date
like
image
classification,
but
also
important
property
that
distinguish
it
from
other
recognition
problems.
I
will
cover
later
is
that
it
does
not
distinguish
different
objects
of
the
same
semantic
class.
So
if
there
are
multiple
people
on
the
image,
they
all
will
have
the
same
semantic
class.
A
So
that's
it
I'm,
not
an
expert
in
any
applications
other
than
common
objects
and
Agra
centric
view,
but
the
right
view
papers,
they're
people
do
segmentation
and
detection
for
brain
tumors,
and
then
there
is
one
papers
from
physicists
there:
they
try
to
analyze
their
scans,
I,
guess
and
Sigmund
iam
particles
and
track
particles.
I
have
no
idea.
They
do
use
semantic
simulation
and
please
check
it
out
how
for
this
thing,
so,
okay,
how
now
we
know
what's
the
problem,
we
know
that
it
used
almost
like
lots
of
different
application
for
it.
A
So
how
will
solve
it
actually?
Well,
as
I
said,
we
just
need
to
classify
each
pixel
in
the
image
so,
as
we
already
have
image
segmentation
image
classification
network,
let's
just
use
it
for
each
patch
of
the
image
now,
for
is
this
pixel.
We
really
care
for
this
pixel
we're
pretty
cow
for
this
pixel
will
predict
rest
nice.
A
So
it's
the
same
exactly
the
same
network
right
the
problem
here
that
first
of
all,
it's
very
slow
so
because
you
need
to
get
all
the
patches
and
three
classes
so
solution
for
that
is
actually,
as
I
will
networks
up
full
of
convolutions
and
convolutions
do
not
care
about
your
input
size.
So
if
you
use
convolution
for
the
bigger
image,
what
you
get
is
a
bigger
out,
so
that's
it
so
in
principle,
most
part
of
our
networks
that
just
convolution,
so
they
can
be
applied
to
any
input
image
and
that's
nice.
A
So
let's
try
to
use
this
property.
So
that's
a
thematic
okay,
any
architecture
of
modern
compassion,
n.
So
you
problems
in
this
him
already
so
their
first
like
a
few
convolutional
blocks
that
operate
on
different
levels
on
different
image
resolution
and
they're
fully
convolutional.
So
you
can
apply
them
to
any
input
size
right.
So
if
you
apply
it
to
the
bigger
image,
then
here
you'll
just
get
bigger
output,
so,
instead
of
seven
by
seven
there
will
be
something
bigger.
So
what
is
not
fully
convolutional
here
is
the
head
of
the
network.
A
So
what
we
do
with
our
7
by
7
by
7
by
7,
is
a
spatial
resolution.
1024
is
our
channels.
We
do
we
first
flatten
them
and
then
use
ab
c--'s
like
a
few,
fully
connected
players
to
process
them
and
finally,
number
of
classes
right
so
and
this
thing
is
clearly
not
fully
composition.
So
if
you
apply
the
same
thing
to
the
bigger
image,
what
will
happen?
A
There
will
be
more
than
seven
by
seven
by
thousand
24
channels
here
and
then
this
fully
controller
connected
layer
will
not
work,
because
it
expect
to
have
exactly
this
number
ditches
by
the
way
multiplication
of
seven
by
seven
by
24,
so
that
will
not
work.
So
what
we'll
do
to
make
it
fully?
Convolutional
is
a
pretty
simple
transformation.
A
So,
instead
of
flattening
flattening
things
out
in
this
layer,
we
will
leave
it
as
it
is
so
seven
by
seven
by
1024
and
now
we'll
present
our
fully
connected
layer
as
simple
one
by
one
convolution,
that
not
one
by
one,
sorry,
seven
by
seven
convolution
that
goes
from
one
height
1,024
channels
to
4096.
So
and
again,
it's
absolutely
the
same
weights.
A
So
we
just
FC
just
has
this
number
of
weights
applied
to
old
features
here
and
the
same
thing
happens
here,
so
it's
the
same
number
of
weights
applied
to
the
same
number
of
features
output
in
the
same
number
of
it,
so
nothing
has
changed,
which
has
changed
the
way
we
represent
our
and
then
we
do
the
same
thing
with
all
fully
connected
layers
later
on.
So
instead
of
just
seeing
it
as
FC,
we
see
it
as
a
one-by-one
convolution
with
the
Save
Changes.
Is
this
transformation
clear
right,
simple,
nice?
A
Okay,
so
now
the
whole
network
is
actually
fully
conventional,
so
we
can
do
stuff
with
it
exactly
the
same
way.
It's
nothing
changed
and
it
can
be
applied
to
any
input
image.
First,
given
an
input
image
of
the
same
size
as
original
as
a
regional
classification
network.
We
got
seven
by
seven
here
and
then
we
got
one
one
by
one
in
there.
So
that's
happening
with
our
padding:0
here,
so
we
just
apply
one
seven
by
seven
conversion.
Here,
that's
right
one!
A
If
we
increase
our
padding,
so
we
don't
want
to
have
like
pixel
segment
class
in
the
very
center,
but
in
all
locations
in
this
seven
by
seven.
We
just
increase
padding
here.
So
we
not
just
use
this
seven
by
seven
thing,
but
we
pad
it
from
all
parts,
and
now
we
can
use
seven
by
seven
convolution
in
all
locations
of
this
by
seven
pitch
map.
So
that
gives
us
instead
of
one
by
one
that
gives
us
zone
by
seven
and
that
seven
by
seven
goes
on
so
now
for
input.
A
Image
would
have
seven
by
seven
semantics,
seven
by
seven
classification,
and
now
you
can
use
it
for
bigger
images.
So
if
you
use
a
bit
bigger
image,
you
got
instead
of
seven
by
seven,
you
get
eight.
If
you
get
two
times
bigger
image,
instead
of
sound
by
sound,
you
get
40
by
40.
So
that's
an
easy
way
to
just
apply
your
classification
Network.
This
same
classification
network
that
was
trained
on
image
net,
whatever
classification
network
right
now,
all
cnn's
we
use,
I
actually
the
same.
They
use
the
same.
A
Like
stages,
they've
staged
aside
your
friend,
but
it's
also
like
for
five
different
stages
with
different
resolutions
go
into
smaller
resolution,
so
you
can
apply
any
of
that
and
then
give
an
image.
It
will
give
you
very
small
prediction,
and
sometimes
it's
enough,
but
for
lots
of
tasks
we
really
want
a
bigger
projection.
So
what
we
do
here
instead
of
this
boolean
operation,
so
why
it's
so
small,
it's
so
small,
because
we
use
boolean
operations
here
so
here
and
here
we
Christelle
resolution-
so
let's
just
remove
it.
A
So
we
use
the
same
weights,
but
instead
of
straight
to
convolution
or
folding
there
we
just
remove
pulling
or
make
straight
equal
one.
Then
it's
all
the
same
resolution.
So
in
the
end,
we'll
get
prediction
just
eight
times
smaller
than
a
recharge.
The
age
for
some
application
is
actually
good
enough.
It's
larger
resolution,
unfortunately,
that
will
give
you
a
bigger
computational
costs,
because
now
here
you
just
have
more
spatial
relations
addition.
Another
way
to
get
bigger
output
is
to
use
unit
type
of
structures
there
you're
first
using
your
pulling
and
strided
convolutions.
A
You
go
to
very
small
resolution
and
then
using
on
pooling
that
just
knows
where
you
pull
and
then
and
pull
in
the
same
location
or
use
the
convolution,
which
is
opposite
operation
of
convolution.
It
returned
their
segments
back
to
their
original
size.
So
the
main
difference
between
these
two
approaches,
so
they
both
used.
Quite
often
they
sometimes
they
combined
in
something
in
the
middle,
but
usually
unite.
Kind
of
approaches
are
used
in
it
places
there.
A
But
if
you
have
a
huge
image
where
the
global
connections
and
then
it's
not
clear
from
a
local
connective
like
from
a
local
context,
it's
really
hard
to
say:
what's
the
right
cost,
then
this
kind
of
approaches
are
working
well,
so
for
classic
computer
vision,
problems
like
common
objects,
a
common
objects
or
eggh
eccentric.
Like
autonomous
ryan's,
when
people
usually
use
this
kind
of
methods
for
tasks
where
we
need
to
signal
cells
for
some
small
objects,
then
people
usually
rely
on
unit
kind
of
architectures.
A
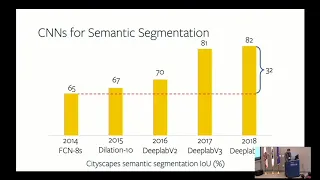
Okay,
now
that's
the
basic
architectures
in
last
four
years,
we
as
computer
vision,
made
a
significant
progress,
so
we
went
from
65
intersection
of
a
union
to
82
they
just
nowadays
the
images
looks
that
result:
semantics
imitation
looks
pretty
good
and
I
will
show
you
a
few
examples.
So
what
did
we
learn
from
this
from
this
improvement?
So,
first
of
all,
we
learnt
that
skip
connection
so
important.
So
if
you
go
with
this
middle
point
here,
the
size
of
your
pictures
is
there.
Spatial
resolution
is
very
small
and
then
you
lose
a
lot
of
information.
A
So
let's
say
the
object
in
the
very
beginning.
Here
was
less
than
32
by
32
pixels.
That
means
that
at
this
point
it
will
be
less
than
one
position
in
the
whole
fish
map,
so
using
skip
connections
so
going
from
here
and
concatenating
or
summing
up
or
doing
something
with
it
to
bring.
This
features
here
helps
recognition
quality
a
lot.
So
now
we
have
a
local
context
about
some
high
resolution,
details
that
we
can
use
and
in
the
end
it
improves
performance
significantly.
A
Another
way
another
improvements
would
have
in
semantics.
Imitation
is
architectures
like
this,
so
instead
of
one
unit
or
like
yeah,
there
are
different
ways
of
calling
this
stuff,
so
some
people
call
it
unit
because
of
the
shape.
Some
call
it
how
a
glass
because
of
the
shape-
and
sometimes
it
works
well,
so
it
allows
you
to
go
because
of
this
keep
connections
here
they
original
information
is
still
preserved.
A
So
we
skip
it
here
now,
it's
here
and
again
and
again,
and
that
allows
you
to
several
times
look
at
the
bigger
pictures
here,
look
at
the
bigger
picture
and
now
upscaling
back
using
some
small
features
and
so
on
so
stack
house
gloss
in
a
task
there.
You
need
some
very
tiny
details
like
key
points,
semantic
finding,
there's
a
key
point
or
something
like
this.
Then
this
super
important.
A
There
is
like
we
know
more
now.
We
know
and
like
hopefully,
I
will
feel,
will
mature
at
some
point
and
we'll
be
able
to
explain
this
kind
of
things
now
most
of
his
papers.
They
don't
even
have
you
know
some
artificial
examples
that
you
show
well
Regas
like
synthetic
data,
you
can
show
that
ok,
I,
have
an
infinite
amount
of
data
and
I
can
see
whether
it's
able
to
learn
something
or
not
able
to
learn
something,
and
then
most
of
this
paper.
A
Don't
even
do
this
thing,
so
they
just
show
best
numbers
on
our
data
sets.
So
it's
really
hard,
but
please
listen,
ok,
so
another
problem
with
what
so
what's
important
in
semantics,
immunization,
beyond
the
skip
connections,
what
is
important
is
context.
Context
is
crucial
so
here
on
this
example.
If
we
look
on
this
part
of
the
play
field
here
and
this
patches
of
grass
here,
they
look
the
same
so
from
their
immediate
neighborhood.
The
visual
appearance
is
exactly
the
same.
Oh
there
are
more
examples
like
this,
but
basically
for
semantics.
A
In
addition
to
segments,
this
part
is
a
play
field
and
this
part
is
Brust.
It
needs
to
know
that
there
is
a
net
here.
There
is
a
player
here
and
so
on.
So
how
we
can
get
this
kind
of
bigger
context
so
see
that
allow
the
network,
as
some
local
patches
in
a
high
resolution
here,
to
see
the
bigger
picture
to
see
the
global
context.
So
one
solution
is
to
just
use
a
bigger
convolution.
A
So
here
is
a
1d
example,
and
we
use
usually
three
by
three
nowadays,
but
we
can
use
seven
by
seven
15
by
15
and
30
by
30
and
unfortunately
that
will
most
likely
first
of
all,
it's
hard
to
train
it
is
slow
and
then
it
also
fits
badly.
So
as
soon
as
you
have
30
by
30
convolution,
it
will
start
learning
exact
patterns
and
you
would
need
a
lot
to
make
an
not
object.
So
instead
there
is
a
solution
of
deleted
or
otros
convolutions
there.
A
We
apply
it
not
to
the
dense
neighborhood,
but
using
this
part
so
I
promise.
That
would
be
the
only
one
formula
in
my
slide,
so
there
will
be
no
other
for
most
I.
Think
you
disappointed
yeah
just
wanted
to
get
me.
Give
you
notice.
Ok,
so
the
latest
convolution
is
we
can
it's
the
same
three
by
three
convolution,
but
instead
of
applying
it
in
a
dance
neighborhood,
we
now
look
further
and
we
can
go
further
and
so
on.
So
in
2d
case
it
would
look
like
this.
A
So
now
we'll
have
a
sparse
connection
and
even
though
it
can't
see
all
the
neighborhood,
it
turns
out
that
this
is
pretty
helpful
and
using
this
kind
of
architectures
now
using
some
global
context.
So
this
like
types
of
things
that
have
usable
and
semantics
in
addition
and
proven
to
be
very
good
and
improving
performance
for
all
unit
kind
of
architectures
and
for
architectures
we
would
just
increase
the
resolution.
So
this
kind
of
layers
where
we
get
a
feature
map,
we
apply
free
by
free
convolution,
with
different
dilation
rate,
and
here
the
relation
rate
is
crazy.
A
So
it's
like
18
pixels.
So
we
have
center
pixel,
then
the
next
pixel
will
be
in
18
pixel
distance
from
it.
But
this
thing
is
really
helpful
for
semantics
notation
because
it
gives
you
it
gives
the
opportunity
for
the
network
to
see
to
see
to
the
to
the
boundaries,
to
like
much
bigger,
to
see
them
much
bigger
context,
and
you
can
do
it
with
this
dilated
or
a
torus
convolutions.
Another
way
is
using
a
pooling.
So
given
a
food
feature
map,
you
do
some
different
callings.
A
Sometimes
you
just
pull
the
whole
feature
map
into
just
one
spatial
location.
So
just
sum
it
up,
and
then
you
unfollowed
back
so
using
that
sample
and
so
on.
So
this
is
proven
to
be
very
useful
for
semantics.
Imitation
now
some
details,
semantics
mutation,
so
training
details
as
with
classification,
we
just
use
multinomial
logistic
regression,
even
though
there
is
a
lot
of
correlation
within
different
pixels.
A
So
it's
they're,
not
independent,
but
during
training
we
just
treat
each
pixel
independently,
and
so
it's
just
multinomial
logistic
regression
in
each
pixel,
absolutely
they're,
just
not
perfect,
but
it
works.
So
few
things
that
is
important
to
make
it
train
properly
is
first
of
all
cause
imbalance,
so
sometimes
like
in
real-world
data
sets
like
it's
really
depends
on
your
data
set
in
our
community.
A
A
So
another
thing
which
is
pretty
important
is
hard
samples
money.
So
if
we
do
autonomous
driving
sin,
but
if
we
do
computer
vision
for
autonomous
driving,
usually
it's
pretty
easy
to
signal
sky
road
buildings
and
because
of
the
how
many
pixels
on
the
road,
even
though
the
loss
there
is
pretty
low
but
summon
them
up,
it's
a
huge
gradient
signal,
and
so
we
want
to
remove
it
in
that
house.
A
So
if
you
have
a
class
imbalance,
if
you
have
some
samples,
some
pixels,
that
are
much
easier
than
another
sample
pixels
and
it's
important
to
think
about,
and
then
with
training
and
testing,
it's
exactly
the
same
picture
as
with
classification,
so
data
augmentation
is
the
most
important
thing
for
you,
so
you
can
do
cropping.
You
can
do
scalene
rotating
colored
mutation
whatever,
and
it
helps
a
lot
so
just
by
doing
it,
you
can
improve
your
performance
by
10,
relative
percent,
20
percent
and
yeah.
That's
important.
A
So
here
a
few
examples
for
semantic
simulation
results
here:
autonomous
driving
sinners,
it's
pretty
dark,
but
yeah
and
common
objects
as
well
and
in
general.
If
you
have
enough
data-
and
here
enough
is
actually
not
a
very
big
number
so
for
this
scenarios
for
this
scenarios
you
need
more
data
because
it's
very
diverse
there
were
different
images,
any
images
actually.
So
there
are
images
like
this,
but
I'ma
just
with
people
for
this
kind
of
images.
If
you
want
as
much
explanation
to
work,
you
need
a
lot
of
like
a
lot
of
images.
A
10K
20k
hundred
K
would
be
a
good
number,
but
for
examples
like
this,
where
it's
all
this
AG
eccentric
straight
view,
so
it's
all
this
you
see
in
the
streets.
There
is
a
lot
of
priors
in
how
streets
look
like
it's
all
this
road
and
the
down
sky
bar
buildings
here.
So
there
are
lots
of
props
and
actually
for
this
kind
of
images
for
this
kind
of
tasks
and
I
assume
more
tasks
outside
of
computer
vision
like
this,
then
the
data
set
might
be
much
smaller.
A
A
A
So
that
means
that
it
goes
beyond
the
image
itself
and
then
it
sees
that
zeros
that
you
pad
your
image
and
now
actually
ResNet
can
figure
out
where,
like
this
excel,
is
position
even
the
devout
position
encoding,
because
it's
knows
how
far
away
it
basically
can
detect
the
corners
because
corners
it's
where
zero
start
outside
the
image,
because
it
knows
where
it
is,
it
can
actually
calculate
the
position
like
its
position
coding.
So
even
devoured,
explicit
position
according
SGD
will
do
everything
for
you.
A
So
that's
a
beauty
so
and
well
beauty
and
at
the
same
time,
it's
very
hard
to
debug
because,
as
really
will
do
whatever,
like
you,
do
mistake
and
thence
the
hosting
ready
and
descend
will
fix
it.
Somehow
so
yeah
position
encoding
is
important.
Yet
it
works
without
it,
and
maybe
you
can
clearly
see
that
it
prefer
even
like
if
you
do
like
complete
gibberish
image.
A
So
with
something
like
strange
and
like
I,
don't
know
you
completely
like
blur
it
with
a
huge
Gaussian
filter,
it
still
will
prefer
to
say
sky
above
a
road
below,
so
it's
able
to
do
some
kind
of
positional
side
position
according
in
self.
It
is
a
problem
like
glass
as
very
hard
problem
than
we're
talking
about
3d
reconstruction
because
then,
like
it's,
not
good
depth.
Estimation
those
glass
messes
up
there
here
we
talk
about
recognition
and
the
worst
thing
that
can
happen
and
usually
happens,
is
if
something
is
reflected
in
the
glass
it
will
segment.
A
What
was
reflect
so
if
I'd
see
there,
if
you
see
reflection
on
a
huge
building
with
a
properly
like
people
there,
it
will
segment
it
as
if
people
there
and
not
as
a
glass.
So
that
can
happen
that
in
general
recognition
like
recognition
problems,
they
don't
care
about
your
bus,
so
they
just
losses.
Okay,
there
you
just
look
in
the
bigger
pictures.
They
know
that
cars
do
have
loss
there.
A
So
that's
a
thing
like
3d
methods
that
try
to
you
know
reason
about
how
our
world
is
freidy,
how
things
should
be
trick,
how
race
should
be
traced
and
so
on
there.
It's
important
because
for
this
kind
of
models
of
our
work,
that's
confusing
here
we
don't
have
model
at
all.
So
here
we
just
it's
a
pure
convolutional
based
recognition
model
that
you
do
not
put
any
prayers
in
it
and
that
it's
knows
that
there
are
windows
in
the
car
and
adjust
segments
and
properly
usually,
but
sometimes
our
glass
as
they
show
like
stacked.
A
Architectures
I've
seen
a
few
that
did
this
context
thing
not
only
on
each
stack
and
each
stack
hourglass,
but
on
each
skip
connection
and
like
basically
putting
more
than
less
and
then
it's
improve
their
performance
there
in
general,
like
you
want
it
in
the
end,
so
basically
you
get
a
good
concepts.
What
is
what
like
some
local
information
and
then
you
want
to
use
it
somehow
later,
so
it
might
be,
doesn't
make
a
lot
of
sense
to
put
it
in
a
very
beginning,
but
then
later
yeah
I
haven't
seen
any
examples
there.
A
A
So,
first
of
all,
it
gives
you
some
invariance
to
some
small
perturbation
right,
because
if
you
use
max
pooling
and
like
two
by
two,
you
can
actually
shift
the
image
a
bit
like
one
pixel
and
it
will
not
change
anything,
but
also
we
do
polling
right
now
to
make
our
resolution
smaller.
To
be
able
to
increase
our
channel
damage,
because
if
we
don't
do
polling,
we
still
have
wait,
increase
channel
dimension
that
will
increase
their.
How
much
memory
do
we
need
and
that's
not
efficient?
A
We
can't
fit
everything
in
GP
right
now,
most
of
the
state
of
your
networks.
They
usually
don't
use
polling
at
all,
but
they
use
strided
convolutions.
So,
instead
of
three
by
three
convolution
applied
on
each
location,
they
apply
free
by
freakin
volition,
then
move
in
not
one
pixel,
but
two
pixels
and
apply
it
again,
so
usually
to
reduce
dimension,
which
is
important.
People
use,
try
the
convolutions
pulling
as
well
where
to
put
pulling
hard
questions
so
that
hand
designed
networks.
A
They
have
like,
usually
five
stages
like
going
from
a
regional
image
to
a
smaller,
smaller,
smaller
up
to
thirty-two,
which
it's
it's
it
does
depended.
Definitely
so
for
classification
networks,
you
don't
need
a
lot
of
you
don't
need
stages
to
be
very
big
in
very
beginning
with
high
resolution.
You
want
to
go
to
smaller
resolution
faster
and
then
do
more
computations
here.
So
you
would
put
pullings
very
short,
like
in
very
beginning
of
the
network,
to
get
to
a
smaller
resolution
and
then
like
get
to
that.
A
If
we're
talking
about
semantic
simulation,
then
actually
it's
pretty
important
to
think
about
like
to
to
work
with
high
resolution
images,
so
it's
actually
the
rough
papers
that
shows
that
it's
better
to
have
bigger
stages
in
the
beginning
of
the
network,
with
bigger
resolution
but
less
number
of
channels
and
then
like
putting
this
following
layers
a
bit
later.
So
it's
toss
dependent.
It's
really
like
whether
all
the
information
is
like
context,
information
that,
like
you
need
to
process
later
with,
like
seen
everything.
A
A
Okay,
so
beyond,
so
that's
a
semantic
simulation
result
as
computer
vision,
scientists,
researchers
see
them
now
we
can
go
further
and
instead
of
2d,
we
can
use
free,
D
data,
so
nothing,
nothing
has
changed
so
instead
of
two,
we
use
this
same
exact,
same
architectures,
but
instead
2d
convolutions.
We
use
free,
D,
convolutions
and
the
rap
papers
that
doing
it
for
usual
objects
and
the
3d
volumes.
There
are
also
physicists
who
trying
to
do
the
same
thing
as
a
3d
space.
A
The
problem
with
3d
is
all
this
memory
efficient.
Like
memory,
you
don't
have
enough
memory
and
computational
efficiency.
So
for
images
like
this
for
3d
balloons
like
this,
there
are
lots
of
void
space
there.
Nothing
actually
happening
there
so
for
that
there
are
special,
sparse,
convolutions
or
manifold
conditions
that
allow
you
to
actually
work
only
in
the
places
where
things
are
and
then
do
not
do
anything
anywhere
else.
So
actually
the
semantics,
in
addition,
can
be
applied
to
all
kind
of
data.
A
Okay,
so
that's
it
whether
it's
a
semantic
simulation
and
we
go
into
bounding
box,
object,
detection
and,
as
I
said,
we're
trying
to
find
all
object
of
certain
classes
and
delineate
them
with
new
boxes.
So,
let's
start
with
a
kitten.
So
it's
an
image
classification,
the
same
cat
in
image
classification.
We
just
answer
the
question:
what
in
bounding
box
detection
object?
Detection?
We
are.
We
answer
questions
what
in
we're,
not
to
the
pixel
extent,
but
to
the
bounding
box?
A
A
Then
we
just
apply
our
classification
Network
and
in
the
end,
instead
of
just
class
prediction,
we
also
add
another
head
that
would
predict
our
box
coordinates
so
that
just
four
numbers-
and
now
we
have
two
losses:
one
is
a
classification
prediction:
they
just
cross
entropy
or
multinomial,
logistic
regression
and
Bonnie
BOTS
loss,
which
is
usually
just
a
regression
loss.
Usually
people
in
bounding
box
detection
people
either
use
smooth
floss
a
smooth,
l1
was
or
just
cuber
was
somehow
sometimes,
but
usually
just
l1
lost
they're.
A
Okay,
with
one
object,
it's
pretty
clear
what
if
we
have
multiple
objects
in
our
image,
so
first
we
can
use
some
heuristic
to
generate
proposals.
There
are
lots
of
pre
deep
learning
ways
to
basically
on
the
image
find
the
blobs
that
looks
like
it
can
be
something
and
then
just
say:
okay,
that's
a
proposal
we'll
be
talking
about
proposals
a
bit
later
so
now,
using
this
representation,
we
take
each
proposal.
A
Now
because
some
proposals
might
be
bad,
so
it's
just
like
nothing
there
and
we
can
predict
for
numbers
here
and
now,
as
we
have,
proposals
is
not
just
for
absolute
numbers,
but
usually
it
just
doubt
us
how
proposal
box
needs
to
be
changed
to
get
there
to
get
there
right
prediction
as
about
okay,
so
with
appearance
of
deep
learning,
this
kind
of
models,
that's
a
general
idea.
How
object
detection
works
like
how
objects
actually
methods
works?
A
We
will
go
in
details
how
some
state
of
method
works,
but
in
general,
with
appearance
of
deep
learning,
for
some
classic
computer
vision,
data
set
without
deep
learning
and
to
the
planning
we
got
3x
improvement,
maybe,
but
that
didn't
stop
there,
and
through
this
four
years
we
get
another
freaks
improvement
as
well.
So
we
making
our
detection
models
much
more
sophisticated
and
it's
performance
increase
hello.
So
here
I
will
not
talk
about
there.
You
know
the
whole
history
of
object,
detection
approaches,
I
will
not
go
like
what
we
used
like
five
years
ago.
A
A
So
ok,
we
have
an
image
and
we
do
some
pre
image,
Kemper
image
computation,
so
it
just
our
apps
here,
the
same
thing
fully
convolutional
part
of
the
network
that
given
an
image,
our
use
of
features
that
somehow
explain
the
image
now
next
step
from
this
features
we
use
rpm,
which
is
region
proposal
network
that,
given
these
features,
predict
possible
locations
for
objects.
How
we
do
it,
given
the
features
I
promised
you
some
non
cuts
here
this
so
given
feature
map.
We
go
through
the
whole
points
in
the
future
map.
A
For
each
point,
we
say
like
how
likely
this
point
is
like
there
is
an
object
in
this
point
and
we
predict
so
we
predict
probability
of
object.
A
new
predict
also
proposal
box,
so
RPN
usually,
is
a
very
lightweight
at
thing.
So
it's
like
one
free
by
free
convolution,
something
like
this.
Based
on
this
features,
we
just
pretty
batch
of
proposals
and
then
like
crop
them
based
on
objects,
cool
now
using
these
proposals
we
need
to
do
the
same
thing.
We
did
with
usual
our
CNN
with
an
image
itself.
A
So,
given
the
proposal
we
went
to
image,
we
cropped
it
and
go
up
here.
We
don't
go
back
to
the
image,
but
using
proposals
we
try
to
crop
feature
map
from
this,
like
we
try
to
crop
from
exact
fishermen,
how
we
do
it,
we
get
our
clausal,
we
get
a
feature
map.
We
know
that
in
the
end,
we
want
all
proposals
in
respect
of
their
size
to
have
the
same
representation
to
then
figure
out
what
class
it
is.
A
So
for
that
we
need
to
have
the
same
spatial
resolution
for
any
object
with
like
boundaries
back
up
their
scale.
So
how
we
do
it,
we
get
a
proposal
we
get.
Oh,
we
get
some
green
there.
We
try
to
get
there
even
grid,
but
because
we
use
average
polling
and
talk.
So
each
cell,
like
this
two
pixels,
will
get
average
pulled
to
this
location
because
we
use
pixels
and
sometimes
disk,
is
a
discretization.
A
Can't
be
made
perfectly
here,
we
have
like
some
errors
here
like
this,
but
we
need
to
have
them
and
we
have
four
by
four:
that's
our
input
idea.
Well,
nowadays,
there
are
better
ways:
our
align
that
actually
recognize
that
there's
discretization
problem
is
indeed
a
problem
that
gives
you
worse
performance
and
they
try
to
pull
not
real
pixels,
but
some
interpolated
values
from
inside
this
box.
So
that's
a
bit
of
a
details,
yeah
so
the
most
important
part.
A
Given
any
proposal,
we
crop
from
the
feature
map
some
some
part
and
then
use
an
average
bully
or
max
pooling.
We
get
any
proposals,
all
proposals
to
the
same
spatial
resolution.
So
after
that
we
can
batch
all
the
region
proposals
back
ROI
all
right
by
our
I,
pull
our
eyes
region
of
interest.
Now
we
can
put
all
our
proposals
to
the
batch
so
now,
instead
of
image
dimension
before
now,
our
batch
of
image,
dimensional
batch
size
was
number
of
images.
A
Now
our
batch
size,
it's
number
of
regions
using
this
Fisher's,
we
just
applying
multi-layer
perceptron
so
for
you
fully
connect
players
to
get
from
there
to
again
softmax
classification,
so
class
prediction
and
box
regatta,
so
we
briefed,
but
that
shifts
from
this
proposal
to
the
best
to
the
predicted
pulse.
So
that's
an
overview
of
the
whole
framework.
That's
how
most
of
the
detection
methods
nowadays
works.
A
That
means
like
both
detections
my
survived
so
usual
output
of
the
network
would
look
like
this,
so
there
is
a
person
in
the
horse
there
and
there
will
be
two
different
detections
for
person,
two
different
or
sometimes
more
sometimes
hungry
predictions
for
the
same
mode.
So,
in
order
to
remove
them,
we
use
some
simple
post-processing
heuristic
based
on
the
class,
a
class
scored.
So
how
sure
our
classification
prediction?
How
sure
it
is?
This-
is
the
right
box
and
using
non
maximal
suppression.
We
suppress
predictions
with
a
lower
score.
A
That's
a
complete
heuristic
and
the
rap
papers
nowadays
that
trying
to
do
it
smarter,
trying
to
utilize
all
the
predictions
to
refine
the
final
prediction
and
so
on.
But
this
is
a
basic
approach
and
it
works
pretty
well
so
getting
smart
here
will
give
you
another
point
or
two,
but
not
much.
Okay.
So
that's
a
whole
framework,
this
thing
and
then
not
much.
Some
suppression
on
top
one
important
part
is
any
like
any
questions.
So
far.
Yes,
oh
yeah,
you
about
yeah,
not
much
so
suppression.
Definitely
s
Curie!
A
Stick
will
ruin
things
for
this
kind
of
cases.
So
if
it's
a
huge
occlusion
and
then
occlusion
the
way
that,
like
you
know,
bonded
works
so,
for
example,
I'm
looking
like
an
ass
and
there
is
a
person
here-
our
bounding
boxes
are
very
simple
and
then
they
will
be
suppressed.
But
if
we
stay
in
close
to
another
person,
then
that
thresholds
are
there
put
so
that
usually
they
will
not
be
suppressed,
but
you're
right.
Sometimes
it
does
happen.
So
it's
a
simple
heuristic,
the
wrong
ways
of
doing
it.
A
A
The
importance
is
the
the
important
thing
called
fbm
feature
permit
network
that
produce
features
with
a
different
scales
so
and
I
will
explain
it
in
a
bit
more
details,
so
in
object,
detection,
as
with
semantics,
imitation
context
matter,
a
lot
for
object,
detection
scale
matter,
so
we
need
to
pre,
there
might
be
person
close
to
to
the
camera
and
then
it
will
be
huge
person.
It
might
be
person
far
far
away
from
a
camera.
A
Then
it's
the
size
bunch,
like
small
handful
of
pixels,
that
you
still
need
to
recognize
as
a
person
so
scale
matter
a
lot
and
we
need
our
detectors
need
to
classify
objects
in
there.
Like
in
the
huge
different
scales-
and
here,
if
we
have
just
one
thing
here,
then
one
proposal
huge
one-
might
get
a
few
like
a
lot
of
features.
Then
the
super
small
object
might
be
super
small
here
and
then
not
much
information
safe
there.
A
So
instead
feature
permit
network
is
a
one
solution,
not
ideal,
but
it's
improves
the
ability
of
the
detection
network
to
yet
scale
right.
So
what
are
options
in
general?
So
we
realize
that
scale
is
a
problem
for
us
what
our
function
so,
first
of
all
the
option
that
was
used
for
ages
in
computer
vision.
A
A
Unfortunately,
for
us
it
would
mean
that
we
need
to
apply
our
convolutional
neural
network
several
times
and
that's
not
efficient
in
our
approach
is
to
leave
it
all
to
the
pictures
so
saying
that
ok
features,
HDD
and
SGD
will
help
us
to
get
that
good
features
in
the
top.
So,
with
a
small
resolution
we
still
will
be
able
to
get
a
like
small
objects
there.
Unfortunately,
well
there
are
lots
of
works
that
I
do
a
net
performance
is
not
so
great
and
you
can
see
that
scaling
is
an
issue
for
this
kind
of
approach.
A
So
SGD
doesn't
help
us
that
much
here
now
the
approach
also
used
very
like
a
lot
recently.
I
would
say
last
two
years,
but
before
people
were
using
pyramid
feature
here.
Ok,
so
they
basically
do
prediction
not
using
the
last
features,
but
they
also
use
features
before
pooling
substrata
collusions.
They
they
had
earlier
in
our
network.
They
not
as
good
in
terms
of
features,
so
they
haven't
seen
much.
There
wasn't
a
lot
of
convolutions
yet
so
they
have
a
very.
They
just
noticed
some
features,
but
there
is
a
higher
resolution
and
people
do
use
it.
A
It's
fast,
unfortunately,
quite
some
optimal
and
small
objects
are
still
get
miss,
so
1/2
PN
is
remedy
feature
pyramid
network
is
a
remedy
for
all
of
it
and
it
looks
a
lot
like
unit
and
the
main
idea
is.
We
have
a
huge
classification
network
here.
Let's
have
in
this
features,
let's
go
back
and
get
feature
Maps
on
difference
by
a
spatial
resolutions,
but
they
all
would
have
a
global
context.
So
for
that
we
go
back
using
skip
connection,
but
here
this
decoder
part
that
goes
from
a
small
resolution
to
bigger
resolution.
A
Unlike
usual
unit
architectures,
that's
also
quite
heavy.
This
thing
is
very
simple,
so
go
in
with
us
from
a
small
resolution
to
bigger
resolution
with
just
absol
Oh
features
and
then
using
white
diamond
commission
from
here.
We
go
here,
so
this
picture
does
not
actually
represent
that
this
part
is
much
heavier.
It's
a
whole
classification
network,
and
here
we
have
just
a
few
conditions.
So
it's
quite
light
weighted
addition,
but
in
the
end,
what
we
have
feature
maps
that
are
on
different
with
spatial
resolution
that
all
have
a
strong
information
from
this
feature.
A
Maps,
that's
in
the
whole
image
and
had
a
bunch
of
conversions
before
them.
So,
okay,
that's
a
fpn,
eight!
It's
suboptimal
still,
because
we
have
this
feature
Mars.
There
are
not
all
possible
future
maps
with
just
a
few
skills,
but
in
the
end,
what
we
do
we
added
here
so
instead
of
just
one
feature
map
which
is
small,
we
get
feature
maps
with
different
resolutions
and
then
based
on
proposal
size.
A
So
if
it's
a
huge
proposal,
then
we
crop
it
from
a
smaller
future
permit
like
from
a
higher
scale
of
the
future
permit,
and
if
it's
a
tiny
miny
object,
then
we'll
drop
it
from
here
and
it
turns
out
that
this
improves
performance
significantly.
So
this
now
is
a
final,
faster
sin,
n
plus
FP
n
pipeline
and
in
the
last
two
or
three
years
FP
and
fosters
n
FP
n
is
a
foundation
for
all
challenging
object,
detection
at
charges.
So
in
computer
vision
we
are
metric
driven.
A
So
there
are
lots
of
challenges
and
then
people
basically
push
away.
So
they
use
a
lot
of
computation
and
they
use
old
data
augmentation.
They
use
everything
and
sampling
and
so
on
and
that
kind
of
competition
there
you
can
see
which
model
can
be
pushed
to
the
like
best
possible
accuracy,
and
this
cannot
be,
and
as
we
see
in
the
last
few
years,
phosphorus
+
FB
n
is
a
part
of
foundation
of
all
approaches.
So
that's
a
good
thing
to
start
out
from
I
haven't
covered
all
you
techniques
on
top
of
clusters
in
Plaza
pian.
A
There
are
plenty
they're
different
they're,
addressing
different
problems
in
object
detection,
but
in
general,
if
you
need
object,
detection
in
your
field,
then
Foster's
an
imposter
peon
is
the
right
thing
to
start
from
now.
Some
people
do
use
it
already.
So
physicist
again,
do
not
ask
me
what
happened
on
these
images,
but
I
definitely
seem
that
they
use
for
surasena
to
produce
these
things.
Okay,
so
slice
will
be
online,
so
you
could
read
it
actually,
okay,
so
that's
it
for
bounding
box
detection.
What
I
didn't
cover
in
this?
A
The
topic
I
didn't
cover
single-stage
detectors,
so
the
detectors
that
remember
we
had
a
proposal
stage
that
gave
us
a
handful
of
proposals
and
then
some
network
on
top
of
its
small
one,
but
still
powerful
network
that
basically
improves
proposals.
So
there
are
single
stage
detectors
that
are
trying
to
do
everything
with
basically
one
proposal
so
proposal,
RPN
proposal
region
proposal
network
would
give
you
the
output
the
final,
so
the
plastic
there
much
faster.
A
The
downside
is
the
not
as
good
in
terms
of
recognition
power
because
they
need
to
predict
the
exact
bounding
box
using
this
features
and
no
specific
object,
computations
or
everything's
conversion,
so
their
worst
performance.
But
if
you're
about
speed-
and
what
is
important
for
you
is-
you
know-
crit
says
data
on
the
fly,
then
this
kind
of
tack.
You
should
look
in
this
kind
of
technique
and
there
are
few
links
there.
Starting
from
there,
you
will
find
a
good
methods
for
your
problem.
Okay,
any
questions.
A
Now,
okay
I'll
go
further,
so
instant
signal,
Asian,
instant
second
ation,
is
a
simple
addition
to
balance
detection.
Instead
of
just
bounding
boxes
will
try
to
delineate
objects
with
their
masks
now
yeah
and
usually
for
each
segment,
not
usually
about
all
these
for
each
segment.
We
just
can
get
it
bounding
box
around
it
right
and
our
mask
is
a
basically
prediction
inside
each
box.
A
That
means
that
we
can
just
add
another
hat
and
faster
center,
because
all
predictions
all
we
need
to
do
here
is
to
get
a
mask
inside
bounding
box
faster
CNN
in
then
do
prediction
per
each
region.
So
that's
ideal
case
for
us
and
that's
what
we
do.
So
that's
a
foster
CNN
pipeline
the
same
thing:
FB
a
FB
n
gives
us
the
pictures
here
then
RP
n
gives
us
proposals.
Then
we
use
our
eye
line,
which
is
a
fancier
version
of
our
rifle
to
get
pictures
mo
P
sub
class
prediction
box
regression.
A
A
Yes,
yeah
yeah.
Definitely
so
it
does
improve
so
multi.
So
here
we
have
a
lots
of
courses.
We
just
sum
them
up.
It
does
work.
So
usually,
why
do
we
need
to
predict
box?
Because
ya
know,
because
the
thing
is
that
Indian,
even
if
you
don't
use
cascaded
cascaded
approach-
and
there
are
cascaded
approaches
that
go
much
more
convoluted-
that
this
doing
like
cascade
several
times
and
so
on,
but
even
devout
it
predicted
masks
based
on
proposal.
A
So
if
you
do
that
differently,
that
might
break
things.
So,
if
you
do
some
back
there
as
Gigi
helped
you
to
remedy
it,
but
if
it's
not
the
same
thing,
you're
in
inference
go
back.
So
even
though
that's
we,
we
we
break
in
this
role
here
and
you're
in
inference.
We
do
something
different,
but
because
this
box
is
much
more
precise
and
proposal
that
helps
us
so
yeah
important
thing
here
as
again
have
all
our
features
have
the
same
resolution,
a
respect
of
size
of
the
proposal.
We
always
have
the
same
masks.
A
28:20,
that's
the
way
like
how
close
again
the
same
thing.
I,
don't
know
whether
you
need
it,
but
features
are
aligned
to
get
this
features.
Few
convolutions
predicted
masks
always
28
by
20.
How
this
masks
look
like.
So
given
an
image
given
a
proposal
box,
it
gives
you
28
by
28,
mask
all
the
time.
It
doesn't
matter
how
big
is
actual
object.
So
if
your
proposal
is
worse,
then
you
must
will
be
shifted
like
this.
So
that's
harder
to
predict
and
then,
like
other
examples,
the
couch
there
with
bad
proposals
early
it.
A
It
missed
lots
of
big
part
of
the
couch,
but
that's
what
we
have
and
yeah
human
okay.
So
that's
the
loss,
how
we
get
our
mask
for
our
loss
and
we
use
usual
semantics
in
nation
to
learn
this
thing
there
now
what
we
do
in
the
inference
part.
So
we
predict
it
our.
So,
given
this
image,
given
a
person
there,
we
got
our
prediction
28
by
28,
then
we
resize
it
back
to
the
size
of
the
bounding
box,
go
ahead
and
trash
called
it,
and
then
we
get
that
output
for
our
person.
A
So
that's
how
Moscow
st.
not
phosphorus
hand,
but
math
Garcia
works
in
jail.
So
here
are
a
few
examples.
You
can
see
that,
even
though
it
works
on
28
by
28
style
and
in
general
should
be
pretty
low
resolution
because
of
this
trick
here,
because
we
upscale
soft
predictions
and
not
like
binary
masks.
Yet
because
that's
a
prediction
like
how
likely
there
is
a
person
there,
we
get
actually
bigger
resolution
and
effectively
bigger
resolution
than
28
by
20.
And
here
you
can
see
examples.
People
are
segmented,
not
perfectly.
A
You
still
can
see
bad
examples
here,
but
pretty
well
and
here's
another
example
with
people
in
the
table
and
segments
okay,
what
wasn't
covered
in
instant
segmentation
part
so
Moscow
sin
again.
If
you
want
to
do
instant
segmentation
in
computation
mas
Carson
is
your
friend
again
to
free
last
year's
all
best
solutions.
All
challenges
do
use
Moscow
see.
So
that
is
the
best
thing.
If
you
wanna
want
to
go
faster
if
pixel
level,
accuracy
is
much
more
important
for
you
for
recognition.
A
So
if
you,
okay,
with
missing
some
small
objects,
but
what
is
important
for
you
to
segment
each
pixel
for
the
object
that
you
do
find,
then
there
are
other
methods
and
be
usually
overall.
They
called
bottom-up
approaches
to
instead
segregation,
unlike
Moscow,
say
no
faster
sin,
which
is
top-down.
We
first
find
proposals
and
then
we
do
something
for
each
proposal.
Independent
bottom-up
approaches
are
doing
it
other
way
around.
A
They
first
do
semantics
imitation
for
the
whole
image,
so
we
do
not
distinguish
different
of
different
objects
of
the
same
class
and
then
we
group
instances
using
some
additional
information
or
we
do
not
learn
semantics
condition
at
first
then
we
just
for
each
pixel
we'll
learn
some
embedding
and
then
use
clustering
to
group
them.
So
there
are
methods
like
this.
They
can
be
faster,
though
not
always,
but
in
general
the
recognition
power
is
a
bit
lower
than
with
mouse
cursor,
but
sometimes
pixel
level.
You
see
it's
bad,
okay,
any
questions
about
installation.
A
Yep
now
I
will
skip
an
optic
simulation
for
a
second
and
I'll
talk
about
more.
What
is
there
more
so
in
general,
the
same
thing
is
with
instance
equation.
If
you
have
some
object
annotation,
so
they
just
inside
bounding
box,
then
you
can
just
add
another
head
to
the
masker
send
pipeline.
So,
for
example,
post
estimation
having
it
have
any
people
there
you
get
this
keep.
We
call
the
key
points
for
joins
of
the
people
and
then
it
just
another
hat.
A
A
A
Manual
annotation,
so
here,
like
I,
haven't
mentioned
it
in
the
very
beginning,
but
the
whole
talk
is
about
supervised
training,
so
we
always
have
data
with
crowns
roof
and
whenever
we
train
some
in
my
talk,
but
now
we
would
train
something.
There
is
a
crown
jewel.
So
here
there
were
trained
mechanical
torques
that
see
seen
like
how
we
put
the
joints
there,
just
a
few
joints
and
there
are
easy
joints
like
ice.
Like
people
do
you
know
where
I
saw,
but.
A
There
are
papers
doing
it,
there
are
papers
now
more
and
more
papers
doing
things
like
this,
but
this
thing
is
of
mineralization
so
but
yeah
you
right
and
there
are-
there-
is
a
lot
of
like
the
trend
in
computer
vision
in
January.
Right
now
is
to
go
away
from
supervised
training.
It
is
not
there
yet.
We
still
use
a
lot
of
supervision,
but
in
general,
lots
of
new
papers
are
trying
to
do
something
but
synthetically
that
kid
actors
not
still
no
synthetic.
We
can
go
more
synthetic
from
there,
but
yeah
people
trying
to
do
stuff.
A
The
question
was:
will
it
fail
if
it's
an
amputee?
There
is
no
limp
it
can,
but
in
general
the
thing
is
that
all
predictions
here's
are
in
the
panel.
So
again
as
we've
gloss,
we
don't
have
priors.
So
it
learns
some
priors,
but
if
there
is
no
no
support
from
a
visual
appearance,
it
will
not
predict
it,
and
you
know:
we've
inputted
I
think
the
thing
is
that
there
are
lots
of
examples
that
people
are
included.
A
So
it's
pretty
natural
and
in
branch
of
lots
of
examples
there,
people
only
half
of
the
key
points,
visible,
so
I
think
it
I,
don't
know.
I
haven't
seen
examples
it
might
fail,
but
in
general
it
like
heavily
rely
on
visual
appearance
and
it
doesn't
have
prayers.
We
do
not
force
it
to
predict
the
whole
person
and
that's
like
for
the
old
days
like
10
years
ago.
People
are
still
interested
in
this
problem
and
then
definitely
you
will
have
this
problem
here.
It's
like
whatever
you
have
in
your
training,
any
other
questions.
A
Okay.
So
if
you
somehow
not
happy
with
key
points,
you
want
something
more.
Then
we
can
go
to
dance
pose.
So
here,
instead
of
predicting
just
key
points
for
each
person
there,
we
predict
correspondence
for
each
point
on
the
person.
We
predict
correspondence
of
this
point
to
some
canonical
shape
of
a
person
and
again
that
just
another
hat
so
for
each
proposal
we
use
convolution
that
predicts.
Uv
coordinates
its
way
to
flatten
out
this
3d
shape
and
yeah
example.
How
it
actually
works.
A
You
can
see
it
works
for
you.
Well,
the
rap.
That's
sure,
like
two
years
ago,
I
think
right
now,
they're
better,
so
how
they
collected
this
annotation.
It
was
basically
you
can't
collect
this
kind
of
annotation,
so
they
collected
much
more
density
than
than
key
points
and
then
interpolated.
So
in
a
sense
it
works
here.
I
don't
have
unfortunate
evideos.
But
what
how
you
can
use
this
thing
you
can
now
having
a
full
human
body.
You
can
now
transfer
their
textures
from
one
person
to
another
person,
so
yeah.
A
A
So
if
you
have
a
stereo
video,
it
could
be
better.
It
definitely
will
be.
Any
additional
information
will
help
us
the
problem
right
now.
There
are
not
many
datasets,
but
there's
kind
of
information
with
this
kind
of
grandeur.
So
there
are
lots
of
stereo
datasets,
but
then
there
is
no
grant
of
like
this,
so
we
we
work
with
whatever
we
have
and
right
now,
it's
images
with
just
like
single
view.
A
A
Yeah,
so
that's
why
I
think
we'll
where
go
in
there.
So
you
know,
for
example,
Daimler
who
are
doing
missus
vehicles.
They
collected
a
huge
data
set
of
autonomous
Raya
and
released
it
to
scientific
community.
So
not
only
BAM
been
like
not
like
from
one
point
for
this
private
company,
why
they
would
release
their
data,
because
then
everyone
can
train
their
Ottomans
writing
scenarios
but
the
same
time
it
boosted
our
research
quite
a
lot,
and
now
there
are
like
many
more
methods
that
wouldn't
appear
without
this
data.
A
So
now,
as
this
cameras
like
multi
camera
setups
appearing
on
the
phones,
there
will
be
more
companies
collecting
this,
because
data
collecting
is
expensive
because
you
need
to
on
a
day
there
and
so
on.
So
more
like
I
think
nowadays
as
you're
right
and
this
cameras
are
more
and
more
common.
This
companies
will
share
more
data
and
will
be
working
on
them
and
there
will
be
cool
methods
that
are
doing
this
in
a
multi-user.
A
Yes,
it
can
so
usually
so
that's
a
pretty
hot
topic
as
of
right
now,
because,
like
there
are
more
and
more
data
sets
that
had
this
kind
of
data
so
right
now
what
people
would
do
there
first
of
all
will
collect
features
from
neighborhood
frames
so
and
we'll
still
do
prediction
per
frame
or
what
they
will
do.
You
already
had
sequential,
like
RNN
lecture
about
sequential
methods
right,
so
they
would
predict
something
in
a
previous
frame
and
then
we'll
use
these
predictions
as
a
priors
for
the
next
frame.
A
So
things
like
that,
so
this
is
a
things
that
I'm
working
right
now
there
are
more
papers
appearing
and
yeah,
but
in
general,
like
majority
of
computer
vision
still
far
has
a
so
on
one
image
and
yeah.
So
there's
all
these
images
without
any
temporal
smoking
and
like
even
without
temporal
moving
it's
like
yeah.
You
see
it's
flickering
with
the
hard
cases.
We
have
a
lot
of
contributions,
but
in
general,
in
this
kind
of
data,
it's
pretty
stable,
even
without
temporal
information,
even
though
we
have
temporal
information
for
the
better
okay.
A
Now,
if
you're
not
happy
with
2d
masks,
we
can
go
further
again
with
into
the
mask
if
we
have
annotation
for
3d
shapes
of
the
objects
instead
of
just
masks,
we
can
predict
work
so
great
and
then
from
box
is
great.
We
can
predict
meshes
how
exactly
we
do
it.
I
will
not
go
into
much
details
here,
but
you
can
do
it
because
it's
just
one
box
like
because
it's
again
pair
box
computation,
so
we
just
add
another
hat.
A
It
can
be
very
complex,
but
still
one
hat,
okay
and
now
I'll
be
talking
about
Tomczyk
segmentation,
which
is
what
computer
vision
field
started
to
work
fairly
recently
again
so
image
segmentation
tasks
in
the
last
two
years
looks
like
this.
So
there
is
an
instant
segmentation
there.
We
try
to
segment
each
thing
and
segment
it
with
a
mask
and
different
people
will
happen,
masks
and
semantics
English,
where
we
try
to
submit
everything.
A
But
then
all
people
here
will
have
the
same
sight
and
for
someone
outside
of
computer
vision,
which
is
actually
quite
surprised
like
why
these
two
tasks
like
why
image
segmentation
is
not
both
of
them.
But
that's
a
lots
of
historical
reasons
and,
first
of
all,
that's
because
it's
easier
to
solve
it.
That
way,
so
there
are
easier-
and
there
are
lots
of
methods
improving
like
on
one
of
this
part,
but
in
general
for
real-world
applications
you
likely
in
computer
vision.
You
will
likely
need
both
of
them.
So
have
a
few
illustrations
here.
A
So
let's
say
you
have
just
instant
segmentation
here
you
have
it's
a
real
prediction:
you
have
a
first
sense
keys
and
like
given
that
information,
you
know,
okay,
I
have
a
skis,
so
it's
either
cross-country
skiing
or
mountain
skiing.
And
this
probably
kid
here,
I,
don't
know
this,
probably
kids,
something
so
you
don't
know,
what's
the
general
scene,
my
outlook,
but
if
we
had
semantic
simulation
at
the
same
time,
it
would
give
us
much
more
information.
A
So
now
we
see
that
that's
not
a
kid,
but
it's
actually
a
person
flying
in
the
middle
of
the
sky,
those
kiss-
and
we
now
have
much
more
information
about
general
geometrical
layout
of
the
same
and
overlaying
it
with
an
actual
image.
We
see
that
going
from
here
to
there
is
not
not
a
big
difference
when
you
about
this
the
same
true
if
we
go
all
the
way
around.
So
if
we
have
just
semantics
innovation,
it's
enough.
If
we
want
to
know
where
we
can
drive,
so
what
is
the
road
and
what
is
the
payment?
A
But
here
we
need
to
reason
about
individual
objects
if
we
want
to
drive
safely
so
here
we
need
to
know
whether,
like
this
blob
of
people,
wants
to
cross
the
road
Oh
No,
and
for
that
you
would
need
instance
imitation
as
well
so
combined.
It
will
give
you
more
information
again
here.
It's
a
real
prediction,
given
this
information,
you
know
much
more
about
this.
Actually,
so
that's
why
I
think
for
practical
approaches
in
computer
vision.
Usually,
you
would
anyway
need
both
semantics
condition
and
instant
segmentation
together.
A
This
is
not
a
new
task
for
computer
vision,
so
we've
been
trying
to
you
address
it,
because
it's
clear
that
it's
useful
for
applications
we've
been
trying
to
address
it
several
times
in
the
past
years,
but
because
there
was
no
enough
data,
there
was
no
data
sets
with
both
semantics
Englishman's
segmentation.
There
was
no
matrix
for
that.
So,
like
every
time
the
new
paper
appear,
progress
stopped
there
so
and
there
we
recently,
we
proposed
a
Panoptix
communication.
There
Panoptix
see
never
finished
once
and
in
this
case
we
now
the
field
is
much
more
mature.
A
We
have
more
data
sets.
We
have
data
sets
with
semantic
simulation,
and
this
is
a
segmentation
we
have.
We
come
up
with
the
new
metrics
that
allow
you,
because
computer
vision
is
metric
treatment,
so
we
need
metrics
there
and
yeah.
Now
field
is
growing
and
people
are
interested
in
this
kind
of
task.
So
how
to
solve
this
kind
of
task,
and
the
first
approach
is
a
very
naive
approach.
We
just
get
an
input
we
use.
A
Whatever
is
your
best
semantics
imitation
network
to
get
semantic
simulation,
the
best
instant
simulation
method
to
get
your
instant
simulation
and
then
using
some
heuristic
combine
them
together
into
Panoptix
in
Dasia.
So
why
do
you
need
heuristic?
Because
maskers
and
for
example,
it
pretty
that
can
overlap
here?
We
actually
cannot
allow
any
overlapping
it's
closer
to
semantics
invitation.
So
we
need
some
theorist
and
recently
so
using
the
two
networks,
it's
possible,
that's
very
inefficient.
You
can
put
it
into
one
GPU,
and
actually
you
can't
improve
this
architecture
much
more.
A
So
that's
why
currently
most
of
the
Panoptix
condition
that
methods
based
on
this
kind
of
approach.
So
we
use
the
same
feature,
premier
network,
that
having
a
classification
backbone
first
and
then
using
some
light
weighted
decoder
to
get
features
on
different
scales.
What
would
you
use
in
these
features?
We
use
masters,
and
that
can
predict,
is
the
segmentation
and
then
using
the
same
features.
We
combined
them
together
and
predicts
the
semantics
imitation
from
the
same
kind
of
features.
Surprisingly,
I
will
not
go
to
the
detail
so
how
this
method
works,
and
so
on.
A
First
of
all,
it's
not
yet
another
arson
and
framework
ad,
so
because
it's
not
per
proposal,
but
here
this
kind
of
pixel
level
recognition
had
ports
with
a
whole
image
there,
and
this
thing
I
will
not
go
to
the
details
of
performance
and
so
on,
but
we
can
see
that
this
kind
of
approach
can
deliver
state-of-the-art
results,
both,
for
instance,
imitation
and
semantic
segmentation.
At
the
same
time,
we
can
see
some
results.
A
People
have
like
the
same
class
will
have
the
same
color,
but
they
will
be
separated
with
with
boundaries.
So
we
can
say
that
combination
works.
Sometimes
it
fails,
but
it
works
reasonable.
There
are
more
examples
and
yeah.
This
kind
of
topic,
I,
don't
know
whether
it's
very
useful
for
research
purposes,
but
Panoptix
emulation
right
now
gets
a
lot
of
traction
and
from
this
baseline
approach,
people
do
you
start
to
innovate
and
come
up
with
a
new
architectures.
A
I
will
not
cover
them
in
too
much
details
yeah
that
people
trying
to
see
how
we
I
can
combine
this
region
based
approach
that
we
see
each
region
independently
and
combine
it
with
a
whole
picture,
approaches
that
are
trying
to
see
the
whole
image
at
once
and
I.
Think
that's
it.
So
if
you
have
any
questions,
so
we
covered
different
recognition
tasks
that
computer
vision,
field
facing
and
yeah.
Thank
you.