►
From YouTube: Intro to GPU: 03 NVidia Software Stack, Part 1
Description
No description was provided for this meeting.
If this is YOUR meeting, an easy way to fix this is to add a description to your video, wherever mtngs.io found it (probably YouTube).
A
A
So
I
will
primarily
be
focusing
on
GPU
computing
in
the
context
of
NVIDIA
GPUs,
but
I
will
try
to
when
I
make
certain
statements
indicate
whether
it's
true
across
vendors
or
not
so
the
general
context
I'm
gonna
be
talking
about
today,
is
how
do
we
use
GPUs
to
accelerate
science
applications?
So,
as
Kelly
said
there,
there
are
cases.
A
So
the
the
contacts
basher,
the
the
context
is
that
we
have
accelerated
nodes
that
are,
we
would
call
heterogeneous
nodes
or
accelerated
nodes
now,
and
so
any
modern
server
node
that
is
GPU
accelerated,
has
both
CPUs
and
GPUs
and
they
solve
different
tasks.
So
Jack
indicated
that
CPUs
are
optimized
for
speed,
whereas
GPUs
are
optimized
for
throughput
and
that's
exactly
the
right
way
to
think
about
it
that
the
CPU
should
be
used
for
the
latency
sensitive
parts
of
your
calculation
and
the
GPU
should
be
used
for
the
parts
of
your
calculation
they're
sensitive
to
throughput.
A
So
on
a
GPU
accelerated
application,
you
don't
take
your
entire
application
and
put
it
on
the
GPU.
Gp
was
not
good
for
every
task,
but
it
is
good
for
latency,
sensitive
tasks,
io
really
two
tasks,
for
example,
if
you're
generating
output
like
a
plat
file
or
some
other
sort
of
data
from
your
simulation
or
reading
it
in
at
the
beginning.
Typically,
you
leave
that
to
the
CPU
and
you
identify
the
part
of
your
code,
and
how
do
I,
oh
you're,
still
I
can
just
do
this
slide.
The
whole
time
right.
So
this
is
the
context.
A
A
Accelerated
computing,
which
is
this
general
concept
of
using
both
CPUs
and
GPUs
again
targeting
each
one
of
the
thing
that
they're
good
at
is
I
would
say
perhaps
the
de-facto
trend
now
in
HPC.
Certainly
there
are
still
plenty
of
HPC
centers
that
are
deploying
standard
like
Intel,
Xeon,
servers
and
I.
Don't
think
those
are
going
anyway,
any
time
soon,
but
certainly
at
the
do-e
and
many
of
the
major
HPC
centers.
A
You
do
see
this
trend
of
using
both
CPUs
and
GPUs
and
an
accelerated
computing
context,
and
you
know,
as
Jack
said
one
one
argument
you
can
make
is
it's
coming,
so
you
have
to
be.
You
have
to
do
it
and
another
way
to
think
about
it.
Is
that
it's
not?
You
know,
this
is
a
trend
that
I
think
is
going
is
extending
over
the
long
term.
So
it's
not
just
Pro
mutter.
It's
not
just
summit
I.
Think
you
see
a
trend
now
we're
further
foreseeable
future.
A
There's
going
to
be
this,
this
heterogeneity
in
in
modern
HPC
servers
and
that
will
then
be
reflected
in
the
in
the
systems
that
large
centers,
like
D.
We
procure
so
CUDA
as
an
example
has
had
quite
a
remarkable
growth
since
it
was
developed
in
the
mid
2000s.
This
gives
you
some
of
the
stats
that
we
have
planned
like
several
hundred
applications
that
have
been
ported
to
NVIDIA
GPUs,
including
essentially,
all
of
the
top
10
or
15
HPC
applications
that
are
used
at
the
major
centers.
A
A
There
are
also
performance,
portable
ways
from
both
the
programming
languages
model
level
and
the
performance,
abstraction
layer
with
examples
like
Raja
and
Coco's
to
help
you
do
that
so
again,
GPU
accelerated
computing
is
everywhere.
Of
course,
I'm
sure
most
of
you
or
all
of
you
know
that
the
world's
number
one
and
number
two
supercomputers
are
GPU
accelerated
using
NVIDIA
GPUs
they're.
These
are
hundred
petaflop
systems
here
at
do
e.
A
Most
of
the
other
major
leading
systems
in
the
world
are
GPU
accelerated
and
you
know
like
a
large
fraction
of
top
500,
has
acceleration
in
some
way.
In
particular,
a
very
large
fraction
of
new
systems
on
top
500
are
GPU
accelerated
in
video,
but
also
the
other
vendors
work
very
closely
to
ensure
that
all
of
the
major
ecosystem
tools
and
libraries
that
are
used
in
data
science
and
high-performance
computing
are
available
on
GPUs.
So
that
includes
things
like
the
deep
learning
frameworks
like
pi
torch
and
tensor
flow
for
NVIDIA
recently
includes
things
like
scikit-learn
tasks.
A
We
things
like
that.
30
use
traditional
machine
learning
in
data
science
applications
and,
of
course,
we
work
closely
with
traditional
scientific
HPC
developers
to
port
their
codes
GPUs
as
well.
So
if
you
are
a
user
of
a
code
more
than
a
developer,
there's
a
very
good
chance
that
your
code
already
runs
on
GPU
as
well
or
is
you
know
somebody
is
looking
at
it?
A
You
know
for
like
autonomous
driving
or
robotics
that
sort
of
thing,
and
so
we
have
one
platform
that
is
available
across
all
of
these
these
platform.
All
of
these
various
devices
and
one
thing
that
we
work
hard
to
ensure
is
that
an
application
that
you
write
that
works,
for
example,
here
at
a
day
you
know
do
HPC
Center
can
also
work
on
one
of
these
devices.
It
may
not
be
the
same
performance,
but
it's
one
architecture
that
underlies
all
of
this.
A
The
I
mentioned
these
two
GPUs,
so
I'll
discuss
very
briefly.
The
two
major
GPUs
server
class
GPUs
that
Nvidia
deploy
is
the
v100.
Is
our
current
top-of-the-line
high-end
data
like
computational
science
and
like
deep
learning,
training
type
GPU.
So
this
is
really
our
biggest
baddest
card.
It's
a
300
watt
chip
has
thousands
of
cores
in
it,
including
tensor
core,
so
I
Jack
might
have
mentioned
this,
but
these
are
specialized
pieces
of
hardware
that
do
essentially
matrix
multiplication,
since
that's
a
very
common
piece
of
math,
in
both
HPC
and
in
and
artificial
intelligence.
A
So
we
specifically
put
that
in
the
chip-
and
this
is
a
trend,
so
Nvidia
really
invented
this
least
in
the
context
of
scientific
HPC.
But
you
also
see
other
vendors
I
think
will
probably
be
going
in
this
direction,
where
the
benefits
from
being
able
to
do
this
particular
instruction
very
well
I
think
are
compelling
enough.
That
you'll
see
a
trend
in
that
direction.
A
To
you,
this
GPU
runs
at
something
like
seven
teraflops
of
double-precision
peak
math
and
then
like
a
2x
that,
if
you're
doing
single
precision
math
and
the
GPU
comes
in
either
16
gig
or
32
gig
variety
in
terms
of
the
end
of
memory
on
the
ship,
the
ones
on
Cori
GPU
nodes
have
16
gigs,
but
there's
also
a
variety,
that's
32
and
it
has
very
high
memory
bandwidth.
That's
almost
a
terabyte,
a
second
on
the
actual
ram
on
the
ship.
A
Conversely,
t4
is
our
lower
power,
more
energy
efficient
GPU.
This
is
typically
used
in
in
the
context
of
artificial
intelligence
for
inference
locations
right,
you've,
trained
your
your
machine
learning
model,
and
now
you
wanted
to
play
it
to
actually
do
do
some
inference
with
your
with
your
train
model.
So
it's
a
lower
power
card
doesn't
have
as
much
compute
power
doesn't
have
any
double
precision:
compute
power,
so
it's
really
targeted
at
those
AI
type
inference.
A
A
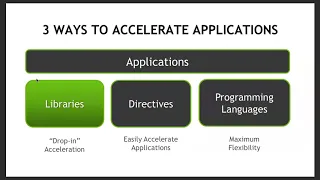
There
are
generally
three
ways
to
that.
We
think
about
accelerating
your
applications.
Take
advantage
of
GPUs
on
accelerated
nodes.
I
would
put
these
into
these
three
buckets
so,
generally
speaking,
there
are
the
use
of
libraries,
the
use
of
directive
based
approaches
and
then
the
use
of
lower
level
of
programming
languages
so
I'll
take
each
of
these.
In
turn,
and
in
this
direction
going
from
left
to
right,
you
have
your
going
from
you
know
in
descending
East
of
use,
so
libraries
are
the
easiest
ones
to
use
and
programming
languages.
A
The
most
most
time
intensive
to
get
involved
with,
but
then
potentially
increasing
flexibility
and
power.
So
you
may
be
giving
up
some
potential
performance
you
can't
top
target.
You
are
workloads,
specifically
the
exact
thing
you're
trying
to
do
injury
using
libraries,
because
there's
typically
a
well-defined
set
of
API
is
you
typically
would
drop
down
to
the
programming
languages.
For
that
with
that
said,
there
are
certain
workloads
where
you
don't
want
to
do
that
right.
So
I
probably
don't
have
to
tell
you
that
you
don't
want
to
write
your
own
FFT.
A
You
don't
want
to
write
your
own
matrix
multiplication
right.
There
are.
There
are
workloads
where
the
library
is
in
fact
the
best
way
to
do
it
and
you
trying
to
write
the
programming
language
version
of
it
is
actually
a
bad
choice
right
or
or
what
takes
so
much
of
your
time
that
it
is
not
a
good
use
of
your
time.
So
the
programming
languages
are
really
there
for
workloads
that
don't
easily
get
exposed
as
a
typical
standard
library
function
like
a
matrix
multiplication
or
an
FFT,
or
that
sort
of
thing,
so
I'll
start
with
libraries.
A
As
I
mentioned,
the
core
selling
point
here
is
both
ease
of
use
and
and
performance
and
quality
right.
So
the
idea
is
that
this
is
a
well-defined
implementation
of
a
particular
reference
application.
And
again
this
is
not
a
Nvidia
specific
statement
right.
Whatever
platform
you're
on
the
vendor
provides
almost
always
and
a
well
optimized
implementation
of
Blas
of
F
of
fftw.
That
sort
of
thing
and
the
same
statement
is
generally
true
on
GPUs,
where
somebody
has
done
that
work
for
you,
because
they
know
the
architecture
better
than
you
do
better
than
I
do.
A
Even
so,
if
you're,
if
you're
familiar
with
a
system
like
Cori,
you
might
be
using,
for
example,
Intel's
math,
kernal
library,
on
NVIDIA
platform,
we
have
a
set
of
libraries
that
do
these,
these
same
sorts
of
things
so,
for
example,
cou
Blas
for
blaster
teens,
who
FFT
is
the
name
of
our
FFT
library
who
ran
for
and
am
number
generation.
So
we
have
all
these
libraries
for
doing
the
standard
sorts
of
operations
that
you
do
and
again
I
would
say
for
the
other
GPU
vendors.
A
This
is
the
same
thing
where
AMD
has
versions
of
this
library
that
they've
announced
for
doing
very
similar
sorts
of
things
and
I'm
sure
that
Intel
will
as
well
for
their
discrete
GPUs
and
again.
The
main
selling
point
here
is
both:
it
doesn't
take
that
much
time
to
do,
but
you
can
still
get
very
good
performance
because
these
are
hand-tuned
for
the
architecture
in
question.
A
These
are
some
examples
and
libraries
some
of
them.
I've
already
mentioned
the
KU
blas
for
dense
linear
algebra,
whose
farce
for
sparse
linear,
algebra,
ku
DN
n
is
our
library
that
we
have
for
the
types
of
calculations
is
very
common
in
deep
learning.
You
often
may
be
you
know
if
you're,
if
you're,
writing
your
own
low-level,
deep
learning
or
AI
application,
you
probably
would
need
to
use
those.
Otherwise,
the
deep
learning
frameworks
implement
them
for
you
and
that's
the
way
you
want
to
take
advantage
of
them.
A
So
as
an
example
of
how
you
would
do
this,
we'll
take
a
sack,
speed
application,
so
X,
plus
y
and
I'll,
come
back
to
this
this
example
later.
But
what
you
have
here
is
the
idea
that
you
can
take
a
function
that
might
have
been
called
Saxby
right,
so
you
write
your
own
C
function.
That
does
it
and
you
convert
that
into
an
API
that
we
provide
Kublai
sexby
in
this
case.
That
does
that
same
thing
for
you.
A
So
the
idea
is
it's
going
to
be
a
standard
API
that
you're
probably
familiar
with
if
you
use
such
a
like
a
level-one
Blas
operation
before
from
another
vendor,
and
the
other
step
that
you
have
to
do
is
just
make
sure
you're
taking
aware
of
memory
management,
so
GPUs
and
CPUs
have
separate
memory
spaces
and
you
get
the
most
performance
when
you
use
the
memory
space
that
is
closest
to
the
device
again,
that
is
not
a
specific
statement.
That
is
not
a
new
statement.
A
Even
if
you
use
the
core
ek
Anil
knows
you're
familiar
with
the
fact
that
there's
a
high
bandwidth
memory
and
then
this
the
standard,
a
large
memory
which
is
slower
right,
and
so
that
is
a
very
common
thing.
That
is
just
by
far
the
trend
for
heterogeneous
computing.
There
are
a
diverse
set
of
memory
spaces,
and
if
you
manage
those
memory
spaces,
you
will
get
the
highest
performance,
so
you
would
typically
allocate
memory
directly
on
the
GPU
and
these
are
the
api's.
You
would
use
to
do
that
and
then
you
can
just
link
your
application.
A
Now
this
is
what
your
CPU
source
code
might
look
like
before
you
did
any
GPU
acceleration
work.
You
might
have
like
a
million
elements
and
you're
performing
a
Saxby
operation
on
those
elements.
So
this
is
your
C
code
and
then
we're
gonna
add
the
bits
that
make
this
GPU
accelerated
code
using
library.
So
the
first
thing
we
do
is
add
the
cout
blast
prefix,
which
basically
says
I
want
the
version
of
this.
That
comes
from
the
Nvidia
library.
A
We
have
to
do
some,
you
know
initialization
and
teardown,
so
that's
boilerplate
code.
We
have
to
actually
allocate
the
memory
again
going
back
to
my
point.
That
is
better
to
allocate
the
memory
on
the
GPU
and
we
we
tell
qu
Blas
about
this
this
this
array.
You
say
we
want
you
to
have
this
to
know
about
this
and
be
able
to
operate
on
it
and
we
call
it
a
sex,
but
then
we
get
it
back
at
the
end.
A
So
we're
transferring
that
we're
allocating
data
on
the
CPU
on
the
GPU,
we're
copying
data
from
the
CPU
to
the
GPU,
doing
some
compute
and
then
copying
you
back,
and
this
is
a
very
common
workflow
and
it's
kind
of
where
everyone
typically
starts
when
they're
doing
GPU
computing.
And
again
you
do
that,
because
if
you
were
to
leave
that,
if
you
were
attempt
to
leave
the
memory
on
the
CPU,
even
if
it
worked,
you
get
very
low
performance,
because
all
of
your
data
would
be
streaming
through
the
interconnect
between
a
CPU
and
the
GPU.
A
A
You
still
have
to
target
the
specific
parts
of
your
application
that
you
want
to
accelerate,
but
you
don't
have
to
write
low
of
a
code
targeting
the
specific
architecture,
so
Helen
will
give
a
much
deeper
description
of
one
example
of
this
approach
for
openmp
I'm,
just
gonna,
you
know
give
you
a
high-level
overview
to
give
you
a
flavor
of
what's
going
on
here,
but
know
that
what
I'm
describing
here
is
not
the
only
the
only
path
to
directed
based
programming.
The
example
that
I
will
use
is
a
parallel
program
framework
called
open
ACC.
A
So
this
is
a
performance
portability
model
for
taking
specific
loops
in
your
application
and
then
accelerating
them
on
GPUs,
and
so
the
idea
is
that
you're
finding
the
parts
of
your
application
we're
expending
the
most
time,
and
these
are
typically
exposed
as
parallel
for
loops
right.
That's
the
most
parallel
do
loops
and
tour
Tran,
that's
the
most
common
use
case
and
then
you're
accelerating
those
on
GPUs.
So
this
is
a
little
bit
different
from
a
library
use
case
because
now
you're
taking
a
specific
workload
in
a
specific
to
your
application.
A
That
cannot
be
expressed
as
a
standard
library
operation
and
then
accelerating
that.
So
this
is
kind
of
the
10,000
foot
view
where
you
take
your.
You
find
you
divided
gratification
into
the
serial
part
of
your
code
and
the
in
the
part
that
can
be
paralyzed.
You
put
a
compiler
directive
there
and
then
it
does
something
to
accelerate
that
on
GPUs
I'll
get
back
to
the
details
in
a
second.
A
This
is
an
example
from
the
clover
leaf
mini
app
from
awwe
in
the
UK,
where
we
demonstrated
performance
for
both
paralyzing
using
open
AC
on
both
CPUs
and
GPUs
and
generally.
What
we
find
is
that
you
can
get
very
nice
speed
ups
in
both
cases,
so
opening
CC
can
be
used
both
to
paralyze
across
threads
on
your
CPU
node,
but
can
also
be
used
to
paralyze
across
threads
on
the
GPU
node
and
for
this
particular
hydrodynamics,
meaning
app.
A
You
can
get
like
10
that
order
10
X
speed
up
on
using
all
the
cores
in
the
node
using
open,
ACC,
and
then
you
see
something
like
order.
250
200
X
speed
up
using
GPUs
for
that,
and
so
you
get
relative
to
a
single
core,
and
so
it's
there's
performance
portability
in
the
sense
that
you
can
take
that
and
then
run
that
across
multiple
architectures
in
principle,
open
ACC,
like
OpenMP,
has
a
kind
of
patchwork
of
support
and
various
places.
A
The
open
EC
is
generally
supported
on
NVIDIA
GPUs
Oakridge,
for
example,
I
believe,
has
expressed
interest
in
having
open
ez2c
available
on
frontier
I.
Don't
know
that
I
can
get
more
detail
than
that.
You
have
to
ask
them,
but
certainly
there's
some
set
of
vendors
and
some
sort
of
architectures
and
which
open
ACC
is
supported.
It's
not
just
in
video
GPU.
So
that's
the
extent
to
which
we
can
say
its
performance
portable.
A
Similarly,
with
an
approach
to
open
MP,
there's
going
to
be
some
set
of
vendors
that
implement
the
target,
offload
implementation
that
will
get
you
later
today
and
then
and
those
those
in
principle
least
that
code
could
be
running
both
CPUs
and
GPUs.
That's
the
promise
of
this
approach
right
that
you
have
one
source
base
that
can
run
in
either
one
and
then
at
compile
time.
The
compiler
generates
the
instructions
that
target
each
architecture
for
efficiency.
A
So
many
of
the
top
HPC
applications
have
either
adopted
or
or
experimented
with
open
ACC,
including
a
few
of
the
top
ten
HPC
applications.
In
terms
of
total
time
you
used
HPC
centers,
and
for
many
of
them
they
get
pretty
significant
speed,
ups
using
open,
C
and
and
particularly
for
a
large
code
bases.
A
This
is
pretty
critical,
because
if
you
have
like
a
million
line
code-
and
you
have
a
net
spread
where
many
loops,
then
the
development
burden
of
maintaining
all
of
those
loops
can
be
challenging
so
having
a
directed
based
approach
where
the
the
directors
are
ignored,
if
the
compiler
doesn't
know
what
to
do
with
them.
For
example,
if
you're
compiling
for
serial
CPU
code
is
very
helpful
from
a
development
perspective,
it
helps
make
the
code
easier
to
maintain.
A
So
this
is
a
high-level
example
of
how
you
would
use
open
ACC
at
compile
time
to
generate
something
like
this,
so
you're
responsible
for
data
management.
As
I
mentioned
generally,
you
you
allocate
some
data
on
the
GPU
or
copy
data
from
a
CPU
to
the
GPU.
Then
you
identify
your
parallel
part
of
the
code.
You
stick
a
directive.
This
is
a
Fortran
example:
bang
dollar
a
CC
pair
of
loop.
A
Basically,
you
put
that
in
front
of
a
do
loop
and
then
that
says
take
this:
do
loop
and
accelerate
it
on
the
GPU,
so
the
compiler
dissolved
the
work
of
figuring
out
how
to
spread
that
work
across
the
GPU
cores
and
make
it
an
efficient
thing.
It
is
not
a
magic
wand.
If
you
try
to
use
this
on
work
that
cannot
be
efficiently
paralyzed.
A
You
will
not
get
a
good
result
right
and
so
that's
either
work
that
has
some
inherent
serialization
in
which
the
case
the
compiler
will
just
refuse
to
paralyze
it
or
ones
where
the
work
is
not
efficient
on
the
GPU.
So
a
very
good
example
of
this
would
be
if
the
loop
is
has
a
very
small
trip
count
right?
A
If,
if
you
have
a
hundred
elements
of
work
to
do
in
this
loop,
that
will
not
saturate
the
GPU
I
mentioned
that
modern
GPUs
have
thousands
of
cores
right,
and
so,
if
you
only
launch
a
hundred
elements
at
work,
you're
only
using
a
small
fraction
of
the
threading
that's
available
on
the
device.
So
you
typically
want
to
make
sure
that
the
amount
of
work
you
have
to
do
exposes
enough
parallel.
A
The
GPU
can
do
it
effectively
because,
like
I
said,
any
one
of
those
cores
is
not
a
very
good
core
right
and
so
the
way
the
GPU
works
effectively
is
by
hiding
latency
from
any
one
core.
By
having
enough
work
to
do
at
any
one
clock
cycle,
we
hopefully
have
some
bit
of
work
to
do
so.
You
really
need
a
lot
of
work
in
your
loop
to
make
that
effective.
A
So
this
is
what
you
look
at
an
example
of
a
worked
out
example,
where
you
first
copy
data
and
at
the
beginning
of
your
loop,
you,
you
can
put
a
directive.
That's
basically
says
paralyze,
this
region
of
the
code.
In
this
case
a
cc
kernels
basically
says
find
the
loops
in
this
structured
block
or
in
the
case
of
Fortran,
between
the
ATTC
kernels
and
the
end
kernels
paralyze
that
work
and
then
end
your
data
region
at
the
end
to
copy
the
data
back
to
CPU.
A
And
if
you
have
questions,
please
feel
free
to
ask
as
you
go
where
they
go
so
open
ACC
is
available
from
PGI
for
free.
So
if
you
download
the
community
ition
of
the
PGI
compiler,
you
can
download
and
experiment
with
this
on
your
laptop
around
your
workstation
and
PGI
is,
of
course,
supported
at
the
major
sites,
so
PGI
compiler
is
available
for
doing
open
ECC
here
at
on
the
Quarian
GPU
nose.
So
again,
I
want
to
emphasize
that
this
was
just
one
story
for
opening
CC.
A
A
It
just
requires
to
identify
parts
of
your
code
that
are
relatively
well
targeted
toward
towards
the
architecture
and
then
tell
the
compiler
how
to
figure
out
how
to
do
something
with
that
and
for
opening
C
in
particular,
we
have
plenty
of
resources
on
the
PGI
website
stack
overflow,
there's
even
a
slack
team
where
you
can
join
and
ask
questions
about
opening
CC.
So
if
that
is
the
thing
that's
appealing
to
you,
you're
certainly
welcome
to
reach
out,
as
I
think
Jack
said.
Certainly
here
at
nerf.
A
There's
a
big
push
to
make
OpenMP
one
of
the,
if
not
the
key,
like
targeted
performance
portability
approaches
for
promoter,
certainly
one
of
the
most
important
ones.
So,
in
addition
to
the
community
support
for
somebody,
hoping
ECC,
there's
also
going
to
be
kind
of
nurse
nurse
expert
and
a
video
expert
support
for
OpenMP
and
so
I
think
you
have
quite
a
few
options
for
doing
performance
portability
on
GPUs.