►
From YouTube: 7. Tech Dive: Jupyter at LSST
Description
June 12, 2019 Jupyter Community Workshop talk by Adam Thornton, Large Synoptic Survey Telescope
A
This
is
a
good
solution
or
please,
if
you
found
a
better
way
to
do
this.
Let
me
know
so:
LSST
is
large,
synoptic
survey
telescope.
It's
a
ten
year
survey
and
Southern's
done.
We
effectively
take
an
image
of
the
entire
Southern
Hemisphere
sky,
every
three
nights
for
ten
years
and
see
what
changes
during
that
time.
This,
as
you
imagine,
generates
a
lot
of
data.
A
There's
also,
this
QR
code
will
take
you
to
this
presentation
if
you
want
to
follow
along
I'm,
not
going
to
dive
into
links
during
the
presentation
but
by
all
means
feel
free
to
follow
them.
There's
a
page
towards
the
end
that
points
to
the
specific
repositories
that
everything
I'm
talking
about
comes
from
and
that
link
is
stuff
about
LSST
and
what
it
what
it'll
be
doing
for
our
purposes.
A
So
15
petabytes
is
not
huge
by
particle
physics
standards,
but
it's
very
by
astronomy
standards,
and
my
piece
in
this
is
that
I
am
designing
the
interactive
notebook
environment
for
the
LSS
to
science
platform
and
it's
point
is,
as
I'm
sure,
you've
gathered
I'm.
It's
running
a
Jupiter
notebook,
in
fact
your
lab,
and
we
will
have
scientists
who
are
working
on
what
are
fairly
small
subsets
of
the
data
trying
to
find
interesting
hypotheses
when
I
say
fairly
small.
A
At
this
point,
that's
probably
a
couple
terabytes
out
of
you
know
15
by
catalog,
but
we
have
no
way
of
predicting
upfront,
and
nor
should
we
try
to
you
know
which
thoughts
out
of
the
day
that
it's
going
to
be
so.
Our
notebook
environment
therefore
needs
not
so
much
raw
computation,
but
it
needs
a
way
to
quickly
access
arbitrary
cuts
through
the
data.
A
So
that's
kind
of
interesting
and
what
what
I'm
really
trying
to
facilitate
is
to
let
the
scientists
have
a
way
to
quickly
shoot
through
their
hypotheses
to
find
the
ones
that
are
actually
interesting
enough
to
just
by
burning
a
humungous
batch
job.
This
is
a
lot
of
what
I
talked
about
last
year,
followed
links.
There's
both
video
and
slides
and
I
thought.
It
was
pretty
good
that
I
am,
of
course
biased.
So
I'm
going
to
talk
very
briefly
about
the
architecture
of
our
notebook
environment.
A
For
starters,
we
are
Cooper,
Nettie's
fixed,
and
your
feet
argue
with
me
that
this
is
not
the
way
you
should
do
it
and
you're
almost
certainly
wrong,
but
by
all
means
try
to
change
my
mind,
so
that
implies
containerization.
We
find
that
this
is
a
great
layer
of
abstraction.
In
that
you
know,
you
don't
have
to
care
about
not
just
as
virtualization,
but
you
not
care
about
the
specifics
of
the
machine.
The
cpu
details,
the
nib
card
right
containerization.
A
A
Don't
know
if
I,
firstly,
do
not
feel
that
singularity
solves
very
many
problems
that
much
better
than
dr.,
although
it
does
solve
the
problem
of
no
way
you're,
letting
the
flaming
dumpster
fire.
The
doctor
secured
near
my
agency
environment,
which,
okay,
that's
that's
what
yes,
but
the
there
are
efforts
underway
to
provide
kubernetes
interfaces
to
singularity
containers
and,
like
from
from
the
LSST
perspective,
our
artificial
positions.
We
don't
care
as
long
as
we
have
acute
control
as
our
control
plane,
like
the
underlying
system,
could
be
whatever
the
thing
that
we
really
love
about.
A
Uber
Nettie's
is
the
way
that
makes
application
composability
very
straight
boards
now,
in
the
worst
part,
at
least
for
me
of
doing
complex
multi
container
applications
in
raw
docker
is
all
of
the
network
coordination
trying
to
expose
the
ports
and
figure
out
how
all
that
works.
Human
at
ease
doesn't
overlay
network,
and
that
just
makes
it
go
away,
which
is
wonderful.
A
You
define
services
and
then
those
services
are
sort
of
virtual
IPS
in
front
of
you
know
a
group
of
well
a
pod,
a
group
of
containers,
and
so
you
can
do
har
load
balancing
very
easily
right.
If
one
of
them
dies,
your
Nettie's
will
start
one
to
replace
it,
and
so
that
that
makes
designing
the
application
a
much
better
experience
and
that
you
can
say:
ok,
you
need
some
of
this
components
some
backbone.
This
one
needs
to
talk
to
that
one,
and
then
the
system
magically
does
all
the
work
humming
it
together.
A
For
you,
there
are
two
pieces
here
for
running
you're,
stuck
on
kubernetes
I'm,
going
to
start
with
one
where
you
are
a
project
rather
than
a
data
center
service
might
suspect.
That's
slightly
the
minority
in
this
room,
and
you
know
from
from
that
perspective,
it's
very
easy
to
say:
hey,
you
know,
whoever
is
hosting
this.
We
need
a
kubernetes
interface
and
to
like
Google
provides
one
guys.
A
It's
it's
pretty
big
stick.
If
you
are
a
data
center
service
provider,
guess
what
the
three
big
public
clouds
already
provide
this
as
a
managed
service
sooner
or
later,
you're
gonna
have
to
the
longer.
You
drag
your
feet.
The
worse!
That's
going
to
hurt!
You
can
argue
with
me
about
this.
People
have
I'm
pretty
convinced
if
you
do
wrong.
A
The
other
nice
thing
is
that
it's
really
easy.
So
kubernetes
has
a
well-defined
interface.
It
has
a
very
completed
API.
The
documentation
is
sometimes
lacking
or
not
particularly
tractable,
but
it
is
quite
plausible
to
orchestrated.
Customize
has
just
been
rolled
into
core
kubernetes.
It's
a
pretty
cool
templating
engine.
A
Terraform
works
well,
but
there's
steep
learning
curve,
I'm,
not
a
fan
of
the
helm,
tiller
model,
but
home
3
is
gets
rid
of
tiller
and
it's
an
alpha
now.
So
that
may
be
useful
or
of
course
you
can
roll
your
own
orchestration
system
based
on
Python
or
shell
scripts
and
guess
which
I
did,
and
that
was
a
terrible
mistake
and
I'm
gonna
be
fixing
that
becoming
months.
A
It's
that
less
than
there
yes.
So
the
second
piece,
of
course,
is
Jupiter
hub
that
that's
what
we
are
using.
The
spawner
containers
I,
have
heard
places
and
I
have
heard
the
reasons
for
using
something
other
than
Jupiter
hub.
I
have
not
heard
any
reasons
that
I
consider
convincing
right.
This
is
what
Jupiter
hub
does
it
does
it?
A
Well,
it's
got
a
nice
pluggable
authentication
model,
whatever
it
is
you're
thinking
of
replacing
it
with
real
hard
about
that
choice,
and
then
Cooper
left
we're
using
that
instead
of
classic
notebooks,
because
we
are
still
several
years
from
science
first
plant,
the
telescope
is
supposed
to
go
online
into
2020
to
early
2023.
You
know
it's
a
big
project.
Is
it
going
to
hit
those
dates?
I
don't
know,
but
it's
pretty
close,
but
by
then
we
expect
that
almost
everyone
will
be
running
Jupiter
lab.
A
We
also
expect
it
since
its
10-year
survey
there's
a
very
good
chance
that
by
the
end
of
it
we'll
be
running
whatever
the
thing
after
Jupiter
lab
or
maybe
the
thing
after
the
thing
after
jeepers
lab
is
and
since
Jupiter
lab
still
gives
you
classic
you
like.
If
you've
got
users
who
rely
on
notebook
extensions
that
are
not
yet
lab
extensions,
ok,
you
can
accommodate.
A
But
if
you
have
those
users
encourage
them
that
they
are
savvy
enough
to
write
their
own
extensions
or
at
least
open
some
issues,
so
that
someone
else
can
bring
their
workflow
into
a
Jupiter
lab
world
alright
and
now
I'm
going
to
do
the
meet
at
the
talk
which
is
and
challenges
and
solutions.
These
fall
into
four
basic
categories:
JA,
Roth
resource
control,
configuration
user
environments.
A
All
of
these
are
things
we
ran
into
while
implementing
our
notebook
system
that
we
have
solutions
of
greater
or
lesser
goodness
to
so,
I
am
very
much
interested
in
hearing
about
whether
you've
run
into
these
and
how
you
solve
them.
So
authentication
the
first.
The
first
thing
to
know
about
it
is
domed
right,
so
somebody
else
has
already
written
it.
It's
better
than
what
you
wrote
because
sure
it's
easy
to
do
the
80%
case,
and
then
there
are
all
these
hideous
little
corners
effectively.
All
you
need
is
you
have
an
identity,
it's
a
user!
A
That
users
attach
the
some
number
of
groups
and,
implicitly
what
a
group
does.
Is
it
says
what
capabilities
you
have
like
if
you
can't
abstract
your
system
at
that
layer,
you
either
have
some
really
weird
challenges
or
you're
thinking
about
it
wrong.
So
a
lot
seems
to
be
a
nice
way
to
do
that.
It's
at
least
work
right,
a
Jupiter
lab
inflation,
where
everybody's
coming
in
through
an
HTTP
endpoint
like
they
have
a
browser
you're
using
to
grow
that
in
a
browser,
so
the
OAuth
flow
makes
a
lot
of
sense.
A
A
How
much
attached
is
a
JSON
web
token
tttt
headers
and
was
that
which
contains
identity
and
basically
scope,
so
what
what
capabilities
here
allowed
to
your
session
and
that
flows
through
the
rest
system?
Oh
this,
we've
got
the
code
to
do
all
this.
It's
really
quite
easy
and
you
parse
the
header.
You
look
for
a
particular
header.
You
look
at
the
values
and
those
header
and
you
make
thumbs-up
thumbs-down
station
on
them.
A
Something
a
bit
us
last
week
that
took
an
embarrassingly
long
time
to
debug
is
that
as
of
December
node,
not
Jas
defaults
to
maximum
HTTP
header
size
of
8k,
which
wasn't
so
much
a
problem
initially
right.
Most
of
the
LSST
users
from
our
identity
providers.
Perspective
have
like
four
groups
right,
so
it's
not
large!
A
Then
the
NCSA
system
administrators
started
trying
to
use
our
system
and
debug
it
and
they're
in
like
50
groups
and
all
of
a
sudden,
their
logins
weren't
working
hours
were
her,
and
that
was
very
strange
and
you
may
want
to
bump
up
your
header
size
as
it
turns
out,
and
you
can
do
that
with
no
adoptions.
So
what
we're
doing
for
SSO
since
NCSA
is
our
long-term
data
storage
facility,
we're
going
through
CI
logon
we're
using
NCSA
as
the
identity
provider.
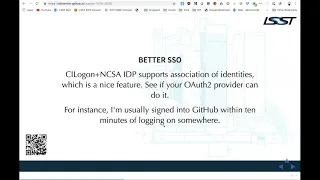
A
So
you
stay
that
way
until
you
shut
the
Machine
off
so
I
very
much
recommend
this
sort
of
model
for
authentication
on
the
resource
control
so
are
basically
fundamental
to
everything
we
do
from
an
auth
and
the
resource
entitlement
perspective.
This
is
what
a
group
really
does
say
a
if
you
are
a
member
of
this
class
of
users.
A
You
are
entitled
to
that
set
of
resources,
and
you
know
if
your
Rd
provider
can't
put
users
in
multiple
groups,
there's
something
really
really
wrong
with
it,
because
we've
had
this
in
UNIX
for
40
years,
and
so
you
know
each
group.
Basically,
you
may
have
a
different
set
of
capabilities
and
what
a
user
is
allowed
to
do
is
the
union
of
all
the
capabilities
of
the
groups,
so
any
interesting
way
to
translate
this
into
kubernetes
this.
A
The
other
cool
thing
about
the
other
cool
thing
about
on
namespaces
is
that
when
you
destroy
a
namespace
all
of
the
namespace
resources
in
it
go
away
now,
as
you
start,
constructing
more
and
more
complex
assemblages
of
stuff
in
namespaces
and
you'll
see
how
pretty
soon
you're
going
to
have
rolls
and
roll
bindings
and
config
maps
and
secrets
in
main
spaces.
It
gets
really
easy
to
leak
it
unless
you're,
just
like
goodbye,
namespace
and
creating
namespaces
real
close
to
free
index,
the
only
the
only
thing
that
isn't
in
space,
it
is
physical
volumes.
A
There
is
a
nasty
corner
case
where
you
have
to
create
shadow
fiscal
volumes
per
which
I'll
get
to
with
better
planning
and
a
less
recalcitrant
persistent
storage
provider
than
we've
got.
You
can
probably
avoid
this,
so
the
other
resource-
that's
easy
to
forget
about
is
time,
and
this
may
be
the
most
important
one
to
a
user,
because
we
have
an
extremely
complex
analysis,
stack
and
because
I'm
doing
kitchen
sink
approach
with
to
your
lab
and
because
I
haven't
paid
much
attention
to
trying
to
optimize
size.
A
We
have
enormous
so
I
mean
we're
really
really
doing
it
wrong,
it's
pretty
huge
and
that
you
know
even
on
a
nice
network,
that's
gonna
take
a
while
to
pull
and
unpack.
So
we
totally
cheap.
We
have
a
people,
er
I've,
written
a
set
of
classes
that
basically
go
to
a
repository,
scan
it
for
particular
tags.
On
a
on
an
image
name.
We
have
tags
on
each
of
our
science
platform,
lab
images
that
are,
you
know
it
is
today.
A
It
is
daily
and
a
day
for
it
is
weekly
number
X
where
it
is
release
number
Y,
and
we
know
that
format.
So
we
can
do
this
and
we
just
continually
pull
those
so
once
you
already
have
it
in
the
image
cache.
That's
basically
instantaneous,
but
the
first
pull
is
typically
10
to
15
minutes
with
images
of
our
size
on
our
network.
That's
fine!
A
We
build
out
of
SIOC,
so
our
images
are
built
sometime
in
the
middle
of
the
night
Illinois
time
and
by
the
time
people
come
in
the
pre
polar
which
runs
once
an
hour
has
already
done
the
work
to
suck
it
down.
So
if
a
user
comes
in
and
picks
today's
daily,
it
starts
in
15
seconds
rather
than
10
minutes,
and
that
is
super
handy,
because
10
minutes
is
way
too
much
time.
The
user
gets
bored
goes
and
gets.
Cup
of
coffee
starts,
looking
at
kitten
pictures
and
then
you've
got.
A
You
know:
summers
of
some
amount
of
reserved,
CPU
and
memory.
That's
sitting
there
browser
tab,
the
users
forgotten
about.
Maybe
they
come
back
after
lunch
and
the
like,
oh
yeah,
I
was
gonna,
get
some
work
done,
so
it
really
helps
to
do
it
quickly
enough
that
they
don't
wander
off
waiting
for
the
spot.
A
Briefly
briefly,
talk
about
intermediate
scale,
parallelism
by
which
I
mean
tasks
basically
they're
things
they're
interesting
problems
that
you
want
to
investigate,
interactively
they're
too
big
to
fit
in
a
single
Python
process
based
right.
A
good
example
is
guide.
Er
2
is
like
1.8
billion
rows,
I
think,
and
you
may
want
to
work
with
a
handful
of
columns.
A
We
the
highlighted
that
the
highlighted
notebook
there
just
uses
latitude
and
longitude
and
basically
does
a
whole
sky
map
of
objects,
and
it's
pretty
cool,
because
you
know,
and
not
that
many
seconds
you
get
a
cross-section
of
all
the
guy
dating
you
can
pan
and
zoom
and
all
sorts
of
stuff
interactively,
which
is
awesome.
But
you
know
you
wouldn't
use
this
for
something.
That's
the
full
catalog
size
for
which
you
probably
are
going
to
one
wheel
badge
system.
A
Now
the
interesting
question
is
by
2033,
which
is
when
the
serve
our
survey
is
projected
to
in
is
15
petabytes,
going
to
be
something
that
you
can
reasonably
use
in
a
desk
like
fully
in
their
active
environment.
I
wouldn't
bet
on
it,
but
I
also,
wouldn't
necessarily
bet
against
it.
So
it's
going
to
be
fun
to
see
where
that
goes.
You
can
certainly
use
different
parallelization
frameworks
than
desk
I
like
desk,
because
it's
very
iconic,
you
don't
have
to
think
very
much
about
how
to
partition
your
data,
though
you
still
do
to
some
degree.
A
One
trick
is
the
keeping
the
Python
libraries
the
notebook
note
that
the
user
is
using
synced
with
the
versions
that
you're
parallel
system
is
using
can
be
tricky.
We
use
the
same
the
same
chief
right.
We
have
the
stack
image
and
we
just
through
the
task
libraries
on
it.
You
pass
an
environmental
flag
in
it
start
up
that
says:
hey
I'm,
a
desk
worker,
not
a
notebook.
The
amount
of
float
we're
adding
to
the
container
is
minimal
compared
to
the
machinery
we
already
have
inside
it.
A
However,
to
do
this
then
you're
going
to
need
to
enable
some
capabilities
such
that
your
user
containers
can
spawn
further
containers.
This
gets
little
tricky.
We
include
a
template
yamo
that
lets
you
spawn
off
a
standard
task
worker
that
is
basically
the
same
size
same
cpu
and
memory
configuration
as
your
primary
container.
A
It
is
modified
by
users.
We
expect
that
very
few
users
will
ever
modify
it,
but
that
is
an
approach.
I'm,
not
sure
it's
the
best.
All
your
desk
workers
in
our
model
go
into
your
own
namespace.
So
the
namespace
is
your
quota
of
total
computer
resources,
which
means
you
still
can't
use
more
than
say
a
hundred
hundred
and
fifty
course
whatever
it
is.
A
We
said
so
the
nice
thing
about
that
is
that
a
the
desk
workers
weep
themselves
after
a
minute
of
not
being
able
to
talk
to
their
controller
node
and
be
like
if
the
user
logs
out
a
namespace,
goes
by
all
their
desk
workers
go
away
too.
You
are
gonna
have
to
learn
how
to
do
role
based
access
control
in
kubernetes,
which
everyone
is
terrified
of
it
is
somewhat
opaque.
A
I
will
grant
the
documentation
is
not
the
best,
but
it
turns
out
to
not
be
that
scary
and
if
you
example
like
it's,
it's
actually
remarkably
straightforward
once
you've
done
it
a
couple
times.
So
it's
not
as
bad
as
it
looks
from
the
outside
some
configuration
stuff.
We
do
a
Jupiter
hub,
minimal
configuration
wrapper
that
just
loads
files
in
a
directory.
A
Those
files
are
exposed
to
schematics
config
maps,
so
you
can
change
them
easily
on
the
fly
bounce
tub
by
the
way,
several
your
hub
and
your
configurable
proxy,
because
that
way
you
can
bounce
the
hub.
All
you
want,
and
it
only
affects
anyone
who
is
actually
trying
to
log
in
at
that
instant
running
users
go
through
the
proxy
which
stays
up.
Something
I
found
that
I
didn't
expect.
I
had
figured
for
each
instance
of
our
notebook
service.
I
would
need
different,
configures
turns
out
you
don't
you
can
make
your
config.
That's
generic
and
anything.
A
That's
instant,
specific,
either
inject
into
the
container
environment
in
your
pod
llamo
or
put
it
in
secrets
if
it
contains
instigator.
The
other
really
really
important
trick
is
that
you
can
create
subclasses
right
in
your
config
notes,
so
we've
subclass,
cube
spawner,
probably
don't
need
to
anymore,
because
it
now
has
namespace
for
f1
dot
o,
but
I
haven't
hadn't
gotten
there.
A
Yet
we
subclass
a
lot
of
the
authentication
providers
miss,
for
instance,
github
and
CI
logon
come
with
a
concept
of
whitelist
that
they
don't
come
with
concept
of
groups
that
if
a
user
is
in,
you
should
deny
access
you
in
CA.
Ncsa
wants
us
to
do
that,
so
you
just
create
sub
class
directly
and
your
config
Mac
and
use
that
as
your
Authenticator
respond.
A
Even
question
period
or
IO
I'm
around
all
day,
so,
yes,
user
environments,
we
use
it's
honor
options
form
to
present
choices
again
because
you've
got
groups
you
could
either
do
you
know
certain
users
only
get
smaller
maximum
container
sizes.
You,
if
you
have
different
disciplines
right,
you
can
show
your
biology
images
to
one
group
of
users
and
responding
interest
another
whatever
right.
You
just
created
an
options,
form
and
display
stuff.
What
what
we
do
with
that
is
display
a
list
of
images
that
are
basically
your
risk
tolerance
rights.
The
latest
three
dailies
latest
two.
A
We
please
last
release
and
then
a
drop-down
that
lets
you
select
anything
we've
ever
built,
which
you
know:
music,
your
own
risk
and
then
so.
The
impersonation
problem.
This
was
something
I
was
asking
about
yesterday
to
find
out
how
other
people
are
doing
it.
We
are
not
scared
of
doing
POSIX
IDs
effectively.
What
we're
doing
right.
You
get
a
list
of
users,
user,
IDs
groups
from
some
authentication
system.
In
our
case,
it's
basically
in
CSA's
LDAP
system.
A
As
long
as
there's
a
32-bit
ID
tied
to
each
user
and
each
group,
you
can
pass
that
down
to
the
container
as
a
singly,
privileged
user
that
can
run
add
user.
You
create
a
local
user
in
group
with
the
right
information
then
used
to
do
to
that
user.
Before
you
start
to
clear
left
from
that
perspective,
then,
once
the
user
starts
at
they
can
open
terminals.
A
It
looks
to
them
almost
exactly
as
if
they
were
the
only
user
on
a
multi-user
system
where
they
did
not
have
we
privilege,
which
is
the
model
we
want
to
encourage,
although
there
is
an
uncanny
valley
effect.
I
probably
don't
have
time
to
talk
about
today
since
I'm
already
writing
at
a
time.
But
ask
me
this
does
require
passing
conflicts-
environmental
variables
down
to
your
spawned,
your
spawned
user.
It's
not
too
hard.
Once
you
start
getting
any
things
with
line
breaks.
A
We
we've
done
this
right
for
30
years.
If
you're,
using
depending
on
your
authentication
provider,
you
may
have
to
do
some
sort
of
shim
layer
to
make
something
that
is
recognizable
as
a
UNIX
ID
from
whatever
unique
identifier
you
get,
but
an
identity
provider
by
definition
has
a
way
to
uniquely
track
each
user
in
each
grid.
So
if
there's
something
that
good
old
file
permissions,
don't
do,
which,
assuming
you
have
a
sign,
it's
not
restrictive
in
the
number
of
groups
which
NFS
p3
in
earlier
is
uh-huh.
A
You
can
also
use
POSIX
ACLs
on
those
file
systems.
To
do
more
sophisticated
stuff,
we
are
currently
still
using
NFS.
As
a
persistent
storage
comes
with
some
drawbacks,
I
mean
the
good
thing.
Is
it
works
and
it
is
ubiquitous
and
everybody
knows
how
to
do
it,
and
it's
been
around
forever,
but
performance
is
not
great.
Locking
has
always
been
and
continues
to
be,
a
nightmare
and
using
non
default
options
in
uber
nedick's,
for
instance,
local
lock
equals
all
which
is
necessary
for
number
the
final
access
stuff
in
our
science.
A
Deck
to
work
requires
Hecky
work
rounds
in
them.
You
can't
just
say,
create
a
container
with
an
NFS,
not
you
have
to
say
you've
created
container
and
build
a
PVC
it
off
of
this
PV,
and
you
put
the
deef
of
the
non
default
options
and
PV.
So
you
end
up
with
Chado
namespaces
and
it's
all
very
fragile,
but
it
does
eventually
work
or
you
can
use
those
paths
now.
This
is
not
documented.
A
It's
working,
but
in
our
experience,
gpfs
mounted
Libre
many
and
just
exposing
the
underlying
host
path
to
the
containers
seems
to
work,
and
the
performance
seems
really
good.
Ncsa
has
some
security
concerns
about
this,
because
GPFS
apparently
requires
more
privileged
and
a
networked
process
and
I
guess
that
makes
sense
it's
worth
investigating
and
then
here
are
some
so
that
that
was
basically
it
here's
this
talk,
but
the
QR
code
also
take
you
there.
The
source
code
of
the
talk
is
just
Emacs
work,
a
lie.
A
You
are
welcome
to
to
all
of
our
work
in
LSST,
with
the
exception
of
some
of
the
actual
hardware,
control
devices
is
open-source
one
kind
or
another.
Most
of
the
infrastructure
stuff
I'm
working
on
is
MIT
license
to
help
yourself
most
of
science,
texts,
gplv3
and
then
useful
repositories
that
have
the
things
I've
talked
about
in
this
table
or
in
here
so
I'm
not
going
to
go
through
those
but
like
feel
free.
So
if
there's
any
time
and
I
don't
really
know
what
time
I
started
like
questions
or
I
will
be
around.
A
No
NCSA
has
to
provide
us
with
Anandi's
clustering.
There's
it's
been
a
learning
curve
for
them
too.
So
you
know
in
a
lot
of
ways:
I
am
a
co
administrator
I,
don't
I
have
kubernetes
powers,
but
I
don't
have
new
powers
on
the
nodes,
and
you
know
I
I
am
that
long
have
basically
been
working
through
the
issues
we
found.
A
This
is
all
specific,
oh
I
probably
should
have
mentioned
earlier
right.
Alice
st
is
mostly
funded
by
the
NSF,
also
the
OEM,
a
host
of
other
private
and
public
donors,
and
because
of
the
funding
model,
it
is
to
share
infrastructure
across
projects.
One
things
I
would
really
like
to
do
is
talk
to
people
about
what
the
architecture
should
look
like
so
gift.
The
political
winds
ever
do
change
such
that
we
get
out
of
that
frankly,
dumb
model.
We
can
do
it
right.