►
Description
August 24, 2023: NUG Monthly Meeting
00:00 - Beginning of Meeting
11:27 - DVS: Best Practices for Reading and Writing Files
33:41 - Question/Answer
A
B
All
right,
great
thanks,
everybody
so
welcome
to
the
August
nug
monthly
meeting
so
today,
because
we
have
a
lot
of
content.
We're
just
gonna.
Do
some
announcements
first
and
a
little
bit
of
trivia
to
get
everybody
warmed
up
for
the
topic
of
the
day,
which
is
about
DBS,
best
practices
for
reading
and
writing
files.
B
B
So
this
is
how
you
would
ask
for
time
at
nurse
that
is
going
to
be
due:
October
2nd,
the
the
requests
will
be
accepted
through
October,
2nd
and
if
you
want
more
information,
we're
going
to
be
hosting
a
like
how
to
prepare
an
ercap
which
I
will
talk
about
in
a
moment
as
well.
So
if
you
want
more
information,
first
I
would
say:
go
to
to
the
weekly
email
look
at
the
links
provided
there,
but
then
you
may
have
another
opportunity
which
I
will
speak
about.
In
a
moment.
B
B
B
B
Okay,
so
this
is
the
first
announcement
for
this
year's
nurse
annual
meeting,
so
this
is
sort
of
like
our
big
user
meeting
for
the
year.
It's
going
to
be
fully
hybrid,
but
in
person
attendance
is
welcome
and
oops.
Sorry,
it's
going
to
be
September
26
to
28th
any
questions
about
the
actual
meeting
feel
free
to
contact
me,
but
here's
some
sort
of
a
like
high
level
information
about.
What's
going
to
be
presented
during
that
meeting.
B
B
Those
presentations
is
a
really
good
idea:
we're
going
to
have
technical
tutorials,
so
these
are
open
to
everybody,
but
they're
kind
of
meant
for
people
who
are
doing
some
more
of
the
Hands-On
work
at
nurse
who
are
interested
in
learning
about
the
API
and
then
also
we're
going
to
have
a
company
called
Xanadu.
They
have
they
have
a
Quantum
Computing,
simulator
software,
I,
think
and
so
they're
going
to
do
a
really
Hands-On
tutorial
with
that.
We're
also
going
to
have
a
ton
of
user
talks.
B
There'll
be
lightning
talks,
they'll
be
contributed,
talks
so
come
find
out
what
all
what
amazing
research
everybody's
doing
and
then
we'll
also
have
sessions
on
how
to
submit
an
ercap.
So
that's
what
I
was
sort
of
alluding
to
if
you
haven't
ever
prepared
one
or
if
you
have,
and
you
just
sort
of
want
some
updated
information.
You
can
come
to
that
session,
that'll
be
by
Richard
Gerber
who's
going
to
talk
about
how
to
prepare
that
we're
going
to
have
a
session
on
how
to
make
the
most
of
promoter.
B
So
this
will
be
kind
of
an
interactive
panel
session
and
then
we're
also
going
to
have
a
session
on
the
integrated
research
infrastructure,
and
so
you
will
get
probably
lots
of
well,
not
lots
of,
but
you
will
get
an
email
that
has
the
link
to
register
and
the
website
where
all
this
information
is
available
so
keep
an
eye
out.
This
is
going
to
be
a
really
great
event.
A
A
B
Be
less
yes,
there
will
be
lunch,
provided
we
have
working
lunches
every
day,
which
is
lightning
talks.
That's
how
the
doe
allows
us
to
provide
meals
is
if
there
is
a
working
lunch.
So
if
you
come
in
person,
if
you
you
have
to
make
sure
to
register
so
we
know
you're
coming
so
that
we
can
order
lunch
appropriately
yeah,
it's
an
important,
important
piece
of
information.
B
There
is
another
sort
of
like
user
annual
Gathering,
the
esnet
Gathering
called
confab.
This
is
happening
in
October,
so
please
see
the
weekly
email
for
the
that
registration
link.
We
are
also
hosting
our
new
user
training.
This
is
so
far.
It's
been
something
that
happens
about
once
a
year,
but
hopefully
start
to
do
that.
More
often,
if
you
have
new
users
joining
your
groups
or
yourself
or
a
new
user,
please
feel
free
to
attend
and
you
can
register
for
that
as
well.
B
There's
an
ideas,
ECP
webinar
on
simplifying
Scientific,
Python
package,
installment
and
usage,
that's
coming
up
on
September
13th
and
there's
an
AI
for
scientific
Computing
boot
camp,
which
is
in
October.
So
here
so
there's
some
other
events.
You
can
go
to
the
events
page
or
in
the
weekly
email
for
all
those
links
and
then,
lastly,
the
applications
are
open
for
the
better
scientific
software
fellowship
program.
B
So
this
is
a
program
that
gives
people
some
incentive
AKA
funding
to
help
them
be
able
to
dedicate
time
towards
some
kind
of
software
engineering
or
software
development
Endeavor,
and
so,
if
you're
interested
in
that,
please
feel
free
to
take
a
look
at
that.
But
that
is
now
open
and
I
guess
I
forgot
to
put
with
the
closing
date
is,
but
again
you
could
probably
Google
this
or
look
in
the
weekly
email
for
the
information
about
that.
B
A
A
B
B
Okay,
all
right,
so
yes,
the
answer
is
B.
It
stands
for
data
virtualization
service.
The
visualization
service
was,
was
meant
to
be
a
little
tricky,
but
it
it's
not
visualizing
data.
It
is
virtualizing
data
which
I
think
we
will
probably
learn
a
little
bit
about
later
today
from
Lisa.
Okay.
The
next
question
is:
what
should
you
avoid
doing?
A
B
B
A
B
C
B
But
that
is
also
right.
It's
just
that
all
of
these
are
good
things
to
avoid,
but
you're
you're
right,
if
you
said
A
or
B
or
C,
those
are
individually
also
correct,
so
great,
okay,
awesome
thanks.
Everybody
for
playing
and
I
will
now
pass
it
on
to
Lisa.
Who
will
tell
us
more
about
all
of
this?
If
you
have
questions
about
any
of
this,
Lisa
is
going
to
be
a
great
person
to
ask
all
right:
Lisa
go
for
it.
Okay,.
D
Good,
okay,
so
hi
everybody,
my
name
is
Lisa
Gerhart
I'm
in
the
data
and
analytics
Division
and
AI
division
of
nurse
I
was
also
I,
led
the
user
integration
effort
during
the
Parliamentary
acceptance
process
and
I'm
the
user
point
of
contact
for
file
system
issues.
So
today,
I'm
here
to
talk
to
you
about
DBS
and
talk
to
you
about
basically
best
practices
for
reading
and
writing
files
around
DBS
and
and
at
nurse
in
general,
so
I'm
sharing
my
whole
screens.
D
D
We
have
a
whole
bunch
in
pearlander
has
a
whole
bunch
of
really
great
stuff,
a
bunch
of
great
GPU
notes
and
CPU
notes,
and
but
for
this
talk,
I
I
prefer
this
view
of
nurse
which
is
sort
of
the
hierarchical
view
of
the
the
file
systems
that
are
mounted
on
parameter,
and
you
know
we.
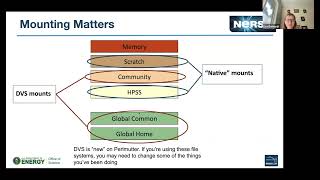
It
is
a
hierarchy
because
you
know
we.
We
have
a
trade-off
between
performance
and
capacity.
As
you
go
down
the
stack
you
know
at
the
top.
We
have
our
super
fast
scratch
system.
D
It's
very
quick
and
we
can
get
here
our
numbers
up
as
high
as
six
terabytes,
a
second
out
of
it,
so
it
it
can
really-
and
it's
got
it's
backed
by
all
flash
behind
it.
So
it's
very
it's
very
responsive,
but
we
it's
pretty
limited
capacity.
We
only
have
35
petabytes,
that's
basically
the
same
size
as
what
we
had
on
Quarry
and
we've
expanded
the
Computing
quite
a
bit
for
Pearl
meter.
D
So
the
ratio
of
available
space
to
Computing
is
going
down
is,
is
pretty
small,
but
it's
great
for
good
I
O
for
fast
I,
O
I
mean
at
the
very
top
is
memory
but
I'm,
assuming
that
if
I
appear
listening
to
this
talk,
you
have
stuff
that
you
want
to
keep
permanently.
So
you
know
you
use
memory
when
you
can,
when
you're
Computing,
when
it
comes
time
to
write
out
you
know
their
Scotch
is
your
first
choice.
Then,
after
that
we
have
our
community
file
system.
D
D
We've
got
300
petabytes
on
there.
We
could
expand
it
out
and
we
have.
We
do
expand
it
out
as
needed.
So
there's
a
huge
amount
of
capacity
there,
but
of
course
it's
very
slow
because
it's
tape
and
then
we
have
sort
of
outlier
they're
more,
like
I
call
them
like
helper
file
systems,
there's
Global
homes
and
Global
Commons
homes
is
the
place
you
end
up
when
you
SSH
into
the
machine.
That's
where
you
start.
D
That's
where
things
like
your
dot
files,
SSH
config
files
live,
maybe
a
few
helper
scripts,
things
like
that
and
then
there's
Global
common,
which
is
a
place
where
it's
it's
all
Flash
ssds,
and
it's
designed
and
deployed
on
our
systems
to
support
software
Stacks.
So
it's
made
to
support
many
small
files.
Lots
of
repeated
reads
those
sorts
of
things.
D
D
So
that
means
that
includes
things
like
input
data,
if
you're,
if
you're
reading
it
a
bunch
of
data
things
like
configuration
files,
output
data
like
if
you're
reading,
a
writing
and
doing
a
lot
of
I
o.
Your
best
bet
is
to
put
this
on
scratch.
If
you
can
and
I
know
that
there
are
some
folks
who
can't
we'll
talk
about
those
a
little
later
and
then
the
software
for
your
batch
jobs
should
ideally
be
in
a
container
at
this
point,
I
think
you'll
get
the
best
results
and
the
most
repeatability.
D
D
We
start
everyone
with
a
small
quota,
but
it's
it's
pretty
easy
to
get
that
expanded.
So
if
you,
if
you
find
that
too
confining
just
open
a
quote,
increase
request
and
we'll
work
with
you,
but
this
is
where
things
like,
if
you're
doing
it,
installing
a
conda
environment
that
should
go
in
Global
Commons.
D
If
you're
planning
to
run
in
the
batch
system
at
scale,
it
should
go
in
global
common,
pretty
much
anything
that
you
install
with
config
makes
cmake
and
you're
not
planning
to
like
SB
cast
to
the
nodes,
or
it
has
a
bunch
of
libraries
in
it
that
should
all
go
in
global
common.
So
if
you're
doing
these
two
things
and
these
two
things
work
for
you
you're
great
good
job,
excellent,
congratulations!
D
So
it
like
I,
said
it
doesn't
matter
how
things
are
mounted.
That's
coming
back
to
this
diagram.
I
just
want
to
point
out
the
the
file
systems
that
are
mounted
on
the
computes
by
DBS,
and
so
our
community
file
system,
the
global
common
and
Global
homes
are
all
mounted
via
DVS
on
our
computes,
and
so
DBS
is
new
on
parameter.
We
were
doing
Native
client
mounts
before
this,
but
we
switched
to
DVS
a
little
while
short
a
couple
months
ago
and
I'll
talk
more
about
that
later.
D
D
So
what
is
DBS?
It's?
Basically
it's
an
I
o
forwarder.
It
was
developed
maybe
20
years
ago,
maybe
30
Now
by
cray.
We
caught
it
on
our
systems
for
a
quite
a
while.
We
had
it
on
Corey
and
Edison
and
Hopper,
and
all
the
systems
for
as
long
as
I've
been
at
nurse
again
I'm
sure
before
that,
but
basically
what
it
is.
D
D
You
know,
because
for
the
login
nodes,
where
there's
only
40
nodes,
those
are
all
mounting
these
file
systems
in
the
in
the
native
way.
With
their
native
clients,
they
don't
use
DBS,
so
logins
don't
use.
Dvs
computes
do
like
I
mentioned
before
the
one.
The
file
systems
that
do
Mount.
This
are
community
Global
common
in
homes.
D
D
It's
it's
a
really
great
file
system.
It's
very,
very
reliable!
It's
great
for
doing
lots
of
I
o
lots
of
reads
and
writes
and
lists,
and
it
can.
It
can
push
bulk
IO.
It
can
do
big
reads
and
big
rights
really
quickly.
It
has
a
lot
of
great
qualities,
but
it's
not
designed
to
run
in
a
situation
where
you
have
many
many
clients
with
potential
Network
bottlenecks
between
them,
and
so
we
were
finding
ourselves
in
a
situation
a
lot
of
times
where
Spectrum
scale
was
the
communication
between
this.
D
The
computer
and
Spectrum
scale
was
having
issues
enough
that
spectrums.
Whenever
that
happens,
Spectrum
sales
says
hold
on.
We
need
to
wait
until
we
get
this
figured
out.
Everybody
stop
until
I
can
figure
out.
What's
going
on,
because
it's
very
important
that
it
not
drop
any
data
right.
We
don't
want
to
lose
any
data,
so
it's
prioritizing
keeping
this
data
and
So
within
anytime.
There
was
a
Slowdown
or
if
a
node
went
into
an
unusual
State
like
a
it,
was
called
like
a
zombie
state
where
it's
not
responding
quite
properly.
D
Spectrum
scale
would
ask
everyone
to
hold,
and
so
what
this
looked
like
on
the
user
side
was,
you
know
a
pause
when
you
go
to
list
a
directory
and
the
login
node.
It
sits
there
for
10
minutes
and
doesn't
do
something.
You
go
to
close
your
editing
with
the
I
o
with
emacs.
You
go
to
close
and
it
just
sits
there
and
doesn't
do
anything
or
when
it
opens,
you
get
a
blank
screen.
It
doesn't
do
anything.
D
So
there
was
a
lot
of
really
frustrating
pauses
on
the
user
side,
while
the
well
things
were
rectified
and
then
on
the
lot
on
the
compute
side
for
batch
jobs.
This
showed
up
as
as
job
failures
or
much
longer
than
expected.
Job
run
times
things
like
that,
so
we
switched
from
running
the
native
Spectrum
scale,
clients
to
to
running
DVS
on
June,
8th
and
the
way
this
is
set
up
at
nurse.
We
have
24
Gateway
servers
that
serve
as
the
DVS
servers.
D
D
So,
if
you're
doing
something
where
you're
reading
like
the
same
LD
Library
path,
every
time,
you're
reading
the
same
config
file
for
this
thing
or
you're
reading
pieces
from
the
same
chunk
of
a
file
over
and
over
again,
that
cache
is
really
going
to
have
a
dramatic
Improvement
in
your
performance,
especially
at
scale,
and
we
actually
have.
We
offer
our
file
systems
over
over
DBS
in
two
different
ways.
We
have
them
in
the
read,
write
mode
which
is
sort
of
the
traditional
mode
you
can
read
from
the
file
system.
You
can
write
to
it.
D
You
cannot
write
to
it
and
the
reason
why
this
matters
is
the
way
that
DVS
handles
this
when
you're
doing
a
write
when
you
allow
rights
just
like
with
deep
with
Spectrum
scale
before
you
have
to
be
really
careful
to
not
lose
any
data,
and
so
the
way
that
DVS
handles
the
way
that
a
server
is
assigned
is
different
for
the
read
write
mode
versus
for
the
read-only
mode.
So
for
read,
write
when
a
file
is
created,
it
gets
its
Gateway
server
and
that's
like
it's
forever
home.
D
If
you
are,
if
you
are
accessing
that
file
via
a
read,
write
now
to
DBS
you're,
always
going
to
go
through,
for
instance,
Gateway
three
every
time,
no
matter
what
compute
node
on
you're
on
no
matter
what
time
of
day,
no
matter
where
it
is,
we
also
keep
the
caching
really
low
so
that
if
you
write
to
that
file
from
somewhere
else,
you're
going
to
pick
it
up
versus
read-only
that
file.
If
you
try
and
access
it
via
the
read-only
point,
you
could
get
any
one
of
those
24
gateways.
D
It's
going
to
give
you,
whichever
one
is
the
least
lightly
loaded
and
then
there's
a
cache
both
on
the
client
side
and
on
the
server
side.
That
will
keep
that
information
right
there
on
the
Node.
So
you
don't
have
to
go
all
the
way
back
to
the
file
system,
which
you
know
is
generally
fast.
But
if
you're
doing
that
64
000
times
those
things
really
add
up
yeah.
D
So
those
two
different
mounts
have
two
different
sets
of
behavior
and
right
now
at
nurse
by
default.
If
you
just
use
the
the
regular
like
slash
global
global
blah
blah
path,
you
will
get
the
read-only
mount
for
Global,
common
and
everything
else.
You
will
get
the
read
write
note,
but
for
these
file
systems
we
also
have
twin
read-only
amounts
that
you
can
use
for
everything
if
you
change
the
path
a
little
bit
and
I'll
talk
more
about
that.
So,
if
you
want
the
read-only
behavior,
you
can
just
use
a
slightly
different
path.
D
D
You
know
they
have
a
petabyte
of
data
that
they're
doing
analysis
on
they
don't
always
know
which
file
they
need
in
there
that's
going
to
be
somewhere
in
there
and
it's
too
costly
to
Stage
that
up
all
up
on
Scratch
and
keep
that
up
to
date.
So
you
know
the
data
comes
in
from
an
external
Source:
it
lands
on
CFS,
they
do
some
analytics
and
then
maybe
it
goes
to
hpss
and
those
things.
So
they
work
with
the
data
on
CFS
because
of
the
size
of
it.
D
So,
for
instance,
if
you
have
a
conda
environment
and
you
install
it
just
without
changing
anything
by
default,
it's
going
to
go
in
your
home
directory
and
then,
for
instance,
if
you
have
something
in
your
dot
file,
like
you
really
like
this
kind
of
environment,
you
want
to
have
it
loaded
whenever
you
log
in
which
is
great,
you
know
it's
there
and
it's
set
up,
but
then
you
go
and
submit
a
batch
job.
That's
maybe
doing
something
else.
D
It's
going
to
grab
that
whole
conda
environment,
lookup
thing
that
happens
in
your
home
whenever
you
start
up
and
drag
it
along
with
your
job
and
do
that
at
scale
when
things
start
up
and
and
for
Sometimes
some
folks,
they
want
that
kind
of
environment.
Some
people,
don't
so
it's
sort
of
an
unintentional
consequence
of
having
this
there
and
set
up
folks
also
tend
to
default
to
doing
a
software
installing
your
home,
you
could
just
try
and
everything
out
you
put
it
in
there.
You
know.
There's
things
like
scripts.
D
Sometimes
you
can
have
hidden
dependencies
in
your
software
that
that
end
up
calling
things
into
your
home
and
they're.
Just
not
it's
just
not
obvious.
The
same
sort
of
thing
happens
with
with
CFS.
You
know,
because
it's
a
shared
space
and
it's
a
little
older
than
Global
common.
Some
groups
tend
to
put
their
software
Stacks
there
and
so
you'll
run
into
a
problem.
When
you
try
to
use
this
at
scale
and
then
there's
also
things
just
hidden
configuration
files
and
dependencies
I
think
that's
true
for
any
file
system.
D
D
So
you'd
want
to
wait
for
that
cash
to
flush
out
which
I
think
is
kind
of,
because
it's
a
little
tough
to
get
the
timing
right.
We
generally
don't
advise
you
using
the
read-only
knot
for
something
that
you're
actively
writing
just
to
be
extra
safe,
but
what
I
think
you
would
end
up
having
you
know
what
you
would
end
up
with
is
there's
a
chance.
You
might
get
the
old
file
right
and
not
get
the
the
new
information
that's
in
there
and
so
I
think.
That's
in
general,
that's
undesirable
for
some
people.
D
E
D
It
depends
so
you
know
if
you
have
like
a
fixed
data
store,
which
is
a
lot
of
the
folks
that
we've
sort
of
seen
run
into
these
problems.
They
have
a
big
set
of
data
and
that
data
is
not
changing.
You
know
if
they're
coming
at
it
to
read,
write
they're
going
to
have
a
they're
not
going
to
have
a
good
time,
so
those
are
the
the.
If
you
have
that
kind
of
thing,
we
definitely
want
to
steer
your
Twitter
everyone
for
sure.
D
D
D
It
was
at
the
point
where
we
would
have
to
reach
out
to
this
user
who's
really
not
doing
anything,
it's
kind
of
natural
to
put
conda
in
your
homes.
It's
not
you,
know,
they're,
not
deliberately
trying
to
cause
this
problem,
but
it
would
cause
basically
what
it
amounted
to
a
center-wide
outage
on
the
computes,
because
this
was
happening.
So
this
is
really
undesirable,
behavior
for
DBS
to
do
this,
so
we
worked
with
our
vendor
to
change
the
scheduling
algorithm
and
as
of
the
16th,
now
there's
something
on
there.
It's
called
the
fairness
algorithm.
D
So
what
it
does
is
when
things
start
to
get
really
high,
instead
of
serving
in
a
first
in
first
out
it'll
cycle
through
all
the
users,
so
maybe
you're
sitting
here
with
your
100
node
condo
thing
pegged
at
a
thousand
just
waiting
and
it's
gonna
say
and
then
someone
else
comes
up
and
says:
I
just
want
a
single
file.
Please
and
they're
like
here's.
Your
file
go
ahead
and
it'll
keep
everybody
else
moving.
Well,
it
slowly
turns
through
this
backlog
from
this
one.
So
it's
it's
an
improvement
in
that
one
uses.
D
D
So,
okay,
so
what
should
you
do
so
I
think
kind
of
kind
of
covered
this
in
Parts,
but
I
wanted
to
put
a
summary
slide
in
here.
If
you
just
want
to
read
from
CFS,
you
have
data
you're,
not
changing
you
just
want
to
read.
You
can
use
the
DVS
Ro
path
instead
of
global.
So
if
you
have
something,
that's
you
know
goes
Global
CFS,
Cedars
your
project,
Mega
important
config.
You
just
change
out
this
first
part
it
becomes
dvsro,
cfse
version
and
then
you're
getting
the
read-only
one.
D
So
if
all
if
you're
running
thoughts
of
no
job-
and
they
all
want
this
config-
it's
going
to
go
super
quick
and
if
you
want
to
run
condo
environments
at
scale,
our
first
recommendation
is
use
a
container.
That's
always
going
to
be
better,
but
if
you
can't
do
that,
use
Global,
common
and
there's
some
instructions
on
our
webpage
about
how
you
would
get
your
conda
installed
to
move
to
the
global
common
path
and
then
there's
a
few
other
things.
D
That
kind
of
like
these
are
more
like
edge
cases
that
you
want
to
avoid
and
one
of
the
things
another
place
where
folks
run
into
trouble.
A
lot
is,
if
you
have
an
ACL
for
DPS
ACLS
live
in
the
extended
attributes,
part
of
the
file
which
unfortunately,
forces
DVS
to
go
back
to
the
file
system,
look
something
up,
and
so
ACLS
tended
to
defeat
any
caching.
That
might
happen
even
on
a
read-only
system.
D
So
I
think
that's
all
I
had
for
today.
I
just
want
to
kind
of
point
out
that
you
know
this
work
is
ongoing.
You
know
we.
We
are
always
trying
to
make
the
I
o
experience
better,
like
I
think
that
DVS
accesses
have
improved
quite
a
bit
over
the
last
week,
and
hopefully
you
guys
feel
the
same,
but
I
know
that
there's
still
some
work
that
we
need
to
do
there
where
we
need
to
investigate
why
sometimes
things
are
a
little
slower
than
we
want
and
we're
actively
working
in
this
area.
D
A
D
Usually,
when
I
see
folks
using
ACLS
for
is
like
they
have
a
group,
but
they
want
to
share
with
like
one
or
two
other
people,
and
so
they'll
add
those
in
as
an
ACL
rather
than
you
know.
Maybe
they
don't
want
those
folks
to
have
access
to
the
whole
directory
or
something
it's
fine.
It
gives
people
fine-grain
control,
directive,
access.
C
This
is
Howard
Richard
from
Llano
I.
Have
a
question?
Can
folks
hear
me
Lisa?
This
is
very
interesting
and
very
timely
for
us
with
our
problems
with
Crossroads.
What
is
the
deviate?
So
you
mentioned
this
baroness
algorithm.
Do
you
know
is
that
a
patch
to
DBS
is,
or
is
that
of
something
that
the
vendor
is
released
with
a
new
DBS
like
RPM,
updates
that
we
should
try
so.
D
A
Lisa
there's
one
more
thing
that
came
up
in
chat.
There's
there's
been
some
discussion
about
already,
but
maybe
you
would
like
to
weigh
in
or
or
not,
but
they
said.
The
question
is:
are
you
supposed
to
use
a
dtn,
a
data
transfer
node
to
transfer
from
scratch
to
CFS
or
as
a
login,
node?
Okay
for
a
few
terabytes.
D
D
You
know
you're
going
to
get
you
likely
might
get
interrupted
and
also
you
just
need
to
be
sharing
the
node
well
with
others.
So
I'd
recommend
Globus
in
general
foreign
I,
see
there's
something
about
the
difference
between
Global,
common
and
home
yeah,
so
homes
is
homes
is
basically
intended
for
just
for,
like
minimal
environment
setup
scripts.
At
this
point,
if
you
have
a
software
stack
and
you
want
to
run
at
any
scale,
I
think
Global.
D
Common
is
the
place
for
you
and
the
difference
right
now,
they're,
both
backed
by
flash,
which
is
much
faster
than
Spinning
Disk,
but
the
the
size
of
the
individual,
the
block
size
on
global
common
is,
is
optimized
for
software
installed.
So
it's
a
much
smaller
block
size
and
it's
got
the
read-only
by
default
mount
on
the
computes.
So
those
are
the
that's
what
the
advantage
common
has
over
homes.
D
And
I
forgot
to
mention
this
in
my
talk,
but
when
we're
talking
about
scale,
it's
not
just
one
job
of
a
thousand
nodes.
If
you
have
a
thousand
one
node
jobs,
it's
going
to
have
the
same
effect.
So
just
think
about
this.
When
you're
submitting
lots
of
jobs,
you
might
get
a
light
queue
day
and
all
your
jobs
will
start
at
once,
and
the
same
thing
will
happen.
B
B
Okay,
well,
thank
you.
Everyone
for
joining
Thank,
you
Lisa
for
your
wonderful
presentation,
I
think.
Hopefully
that
will
be
really
helpful
for
everybody.
We
will
be
posting
the
slides
and
the
recording
of
today's
meeting
on
the
website.
So
if
you
missed
something-
and
you
want
to
hear
it
again-
you
can
always
go
check
it
out
and
feel
free
to
email,
myself
or
Charles
is
usually
here
he's
not
here
today.