►
From YouTube: NUG Monthly Meeting, Jan 2022
Description
Run-time configuration for climate models on Cori —throughput per job or throughput per year? Koichi Sakaguchi from PNNL will talk about experiences running climate models on Cori, including some observations about the impact adjusting sbatch parameters has on workload throughput.
A
So
I
think
most
of
us
are
kind
of
familiar
with
the
the
format
of
this
meeting
now,
but
in
case
you're.
Not
so
it's
intended
to
be
quite
an
interactive
session.
It's
more
meeting
the
webinar,
so
please
participate
yeah.
If
you've
got
an
interesting.
Yeah
got
a
comment
to
make
or
a
question
to
ask
yeah.
I
think
we're
a
a
suitable
size
crowd
that
you
can
probably
just
unmute
and
speak
up
as
it
starts
to
get
very
interactive.
Then
you
know
we'll
move
to
raising
your
hand
yeah.
A
A
Today
I
learned,
which
is
an
opportunity
to
discuss
interesting
things,
you've
done
experienced
or
discovered
or
tripped
up
one
recently
we're
using
nest
systems,
we'll
have
a
few
announcements
and
calls
for
participation,
and
then
we
have
our
topic
of
the
day
and
I
see
yeah
christian
has
been
doing
some
interesting
work
on
how
to
set
up
his
climate
runs
at
nurse
to
get
sort
of
good
throughput,
good
q
time
and
so
on
and
yeah.
So
he's
got
some
interesting,
yeah
news
and
and
discoveries
to
present
there
thanks
squishy.
A
So,
let's
start
out
with
our
whether
the
month
sections
the
opportunity
to
either
show
off
or
shout
out
of
an
achievement
that
you've
heard
of
somebody
else's
head,
it
can
be
big
or
small.
It
can
be.
You
know,
from
getting
a
paper
accepted
solving
a
bug.
That's
been
giving
you
some
group
for
a
little
while
that
took
some
took
some
digging,
maybe
that
maybe
you've
got
a
an
achievement.
That's
good
to
note
as
a
high
impact
scientific
achievement
award
or
an
innovative
use
of
high
computing
award.
A
B
A
C
Thanks,
I
just
want
to
for
me
win
of
the
month,
and
maybe
many
others,
the
two
train
events
this
month,
I
really
enjoy
from
nask
one
is
the
polymer
training
and
then
last
week
we
had
engineering,
hpc,
sv
development,
kita
training.
I
learned
quite
a
lot
from
those
two
training
events
and
just
started
to
trying
offloading
this
existing
fortran
code.
We
use
to
generate
a
computational
mesh
which
takes
a
really
long
time.
C
A
The
I
believe
the
slides
and
recordings
are
up
now
for
those,
so
you
can
find
them
under
the
the
training
section
of
www.nurse.gov
yeah.
For
those
who
didn't
make
it.
We
had
two
sets
of
trainings
one
on
an
introduction
to
pelmeter
generally
a
lot
of
the
the
tools
and
the
other
on
an
introduction
to
the
nvidia
program
and
and
tool
suite.
A
A
So
there's
a
flip
side
of
winner
of
the
month.
There's
today
I
learned,
which
is
a
a
similar
kind
of
format,
but
you
know
it
can
be
something
that
tripped
you
up,
but
you
might
give
the
rest
of
us
a
full
warning
about
or
something
that
might
be
good
to
add
to
nurse
docs
and
I've
seen
in
the
last
week
or
two
actually,
we've
had
a
few
merge
requests,
so
you
can
also
contribute
to
the
docs
by.
A
A
A
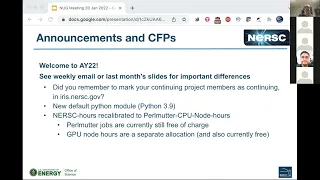
We
definitely
have
a
few
and
the
biggest
one
is
in
case
you
missed.
It
welcome
to
allocation
year
22,
which
began
yesterday
with
maintenance
on
corey,
so
there's
a
a
whole
bunch
of
detail
in
the
nurse
weekly
email,
and
you
know
a
few
other
places
there's
links
from
that
weekly
email.
This
will
be
a
good
place
to
to
begin
a
few
important
differences
that
that
are
worth
watching
out
for
is
for
pis.
A
So
if
you
are
finding
trouble
with
that,
take
a
look
at
iris
and
drop
your
pi
aligned,
that's
sort
of
the
first
thing
to
try
there
another
important
thing.
In
the
new
year
we
have
a
new
default
python
modules.
All
of
last
year
the
default
was
3.8
python.
3.8
this
year,
it's
python,
3.9,
there's
been
a
few
other
upgrades
here,
we're
using,
I
believe
it's
called
member,
which
is
an
improvement
on
conda.
A
A
We've
recalibrated
it
to
what's
expected
to
be
a
pulmonary
cpu
node,
which
is
a
phase
two
node,
so
we
don't
have
those
quite
yet
so
a
permanent
cpu
node
will
have
two
sockets
of
the
amd
epic
processes
that
combat
phase
one
has
felt
motor
phase.
One
has
one
socket
plus
gpus,
so
the
new
hours
have
recalibrated
to
you,
know:
models
sort
of
node
speeds
if
you're
using
palmata
jobs
are
still
currently
free
of
charge
and
will
be
for
a
little
longer.
A
A
A
Okay,
another
important
announcement.
It's
been
a
few
weeks
now,
but
if
you
dig
back
through
your
email,
you
should
have
seen
some
email
invites
to
participate
in
the
nurse
annual
user
survey.
This
is
really
important
for
nursk.
We
use
it
both
to
get
feedback
and
get
a
sense
of
how
our
users
are
experiencing
the
machine
and
the
services
over
the
last
year.
A
A
A
B
A
A
A
Are
there
any
other
announcements
or
cfps?
So
that's
what
I
have
from
nurse
side.
This
is
also
an
opportunity,
for
you
know
people
in
our
music
community
to
tell
us
about
things
as
well.
So
if
you're
involved,
for
instance
in
a
you
know,
a
conference
or
event
that
nurse
users
might
be
interested
in,
this
is
a
good
opportunity
to
spread
the
news
a
bit.
Does
anybody
else?
Have
anything
they'd
like
to
add
on
that
nature?.
B
D
I
will
be
asking
for
this
to
go
out
on
the
weekly,
but
I
thought
I
would
go
ahead
and
say
it
now.
Is
that
lbl,
so
a
couple
of
different
divisions
are
co-organizing,
something
called
the
monterey
data
workshop.
So
in
2019
there
was
the
first
monterey
data
conference
we've
been
trying
to
hold
it
again,
but
with
current
travel
conditions,
it's
been
difficult,
but
we
wanted
to
hold
a
workshop
in
april,
allowing
us
to
share
some.
D
You
know
good
information
on
ai
and
machine
learning,
so
we're
calling
it
the
convergence
of
hpc
and
ai
so
providing
an
opportunity
for
early
career
scientists-
or
you
know
just
just
about
anyone,
but
you
know
I
think
early
career
has
been
hit
pretty
hard
recently
to
get
an
opportunity
to
talk
about
their
work.
It's
very
lightweight.
You
know
not
full
papers,
just
abstracts
on
talks
and
panels,
an
opportunity
to
get
together
and
exchange
good
ideas.
So
please
do
submit
submissions
are
due
by
the
end
of
the
month.
A
D
D
A
So
I
think
we're
slightly
ahead
of
our
usual
timing,
but
that's
that's
all
good
coachee.
Would
you
like
to
start
sharing
a
screen
or
stop
sharing
okay,
yeah,
so
kuchi
sekurichi
is
from
a
pacific
northwest
lab.
He
has
been
a
very
active
nurse
user
and
participant
in
the
nurse
users
group
for
a
while.
Now
and
yeah
we've
been
looking
forward
to
to
seeing
his
findings
on
some
work
he's
been
doing
recently.
C
A
C
Okay,
thank
you
so
much
steve
and
thanks
for
the
all
the
users
and
ask
staff
for
checking
out
my
talk
today.
Some
I
have
a
12
slides
and
the
first
half
is
to
introduce
what
the
climate
models
do
to
give
a
context
for
the
last
half
of
the
presentation
and
really
I'm
talking
about
my
experience
of
optimizing.
My
whole
work
flow
and
the
important
question
for
me
is
model
throughput
or
how
fast
model
simulates
climate
charge
off
or
per
our
annual
or
fiscal
year
is
my
question?
C
Okay.
So
briefly,
so
I'm
a
research
scientist
at
the
channel
now
and
then
doing
studying
mainly
atomic
turbulence
in
the
planetary
boundary
layer
and
related
moist
convictions.
You
know
this
comes
with
clouds
that
you
know
quite
often
formed
as
a
result
of
interactions
between
the
surface
and
atmosphere
and
those
are
also
linked
between
small
scale
and
large-scale
atmospheric
phenomena,
and
that's
also
my
scientific
focus
and
one
model
to
have
the
useful
model
to
study.
This
is
the
one
I'm
showing
here
as
animation.
It's
called
variable
resolution
grid.
C
Many
models
are
having
this
functionality
now.
So
in
this
particular
case,
I
have
verified
4
kilometer
good,
spacing
over
the
us
to
better
resolve
all
those
strong
stones
and
its
global
model.
But
the
rest
of
the
globe
are
using
much
closer
bridge,
spacing
so
to
save
some
computational
cost,
but
still
allowing
two-way
interactions
between
this.
The
focus
of
division
and
outside.
C
And
then
so
we
study
climate,
and
this
is
sort
of
how
we
see
the
us
system,
I
believe,
just
representing
my
own
people.
So
we
have
us-
and
we
want
to
know
about
the
climate
particularly
stimulate
and
verdict
project
the
future,
and
we
divide
our
chronic
component
into
different
components
so
to
facilitate
understanding
in
numerical
modeling,
and
then
this
is
reflected
to
how
to
redesign
the
current
model
for
each
component.
We
have
numerical
models,
for
example,
atmosphere,
land
ocean
sea
ice
and
the
other
components,
and
these
are
couples
so-called
coupler.
C
We
have
this
name
scene,
which
is
used
by
two
kind
of
models,
one
by
doi's
own
model
e3
and
its
system
model
csn,
and,
as
you
can
see,
it's
a
really
huge
chunk
of
mainly
for
current
generation
model.
It's
fortune
code.
I
have
I'm
gonna,
go
into
detail
a
little
bit
later,
but
it's
it's.
A
community
called
and
developed
by
the
community
and
many
users
just
contributed.
So
it's
it's
very
complex.
C
And
if
we
just
focus
on
the
atmosphere,
part
just
quickly
go
through
to
give
you
an
idea
what
we
mean
by
new
major
models.
So
a
large
part
of
the
atmosphere
is
this
dynamics,
crude
dynamics
or
navier-stokes
equation.
So
we
usually
simplify
the
governing
equations.
Given
the
scale
we
can
make
some
approximations.
C
C
That's
that's
a
really
big
research
topic
and
then
so,
if
you
just
to
me
atmosphere
component,
only
this
is
already
very
complex
because
we
have
so.
If
you
go
into
the
directory
of
this
model,
we
have
some
directory
has
scripts
to
build
the
model,
make
file
and
then
source
code
has
different
processes
has
its
own
directory
and
the
one
I
just
talked
about
in
the
previous
slide
is
about
dynamics,
hopefully
dynamics
or
with
identical
core,
and
then
these
models
offer
actually
multiple
choices
for
the
users.
C
For
my
research,
I'm
using
this
experimental
model
impasse
and
in
this
directory
I
have
these
files,
and
this
is
actually
standalone
model
outside
and
imported
to
this
code.
So
we
have
external
directory.
We
have
a
lot
of
another
photon
code,
the
other
physics
where
we
call
has
this
process
I
just
mentioned
and
resolve
dynamics,
radium
transfer,
molecular
skill
processes
in
chemistry
has
its
own
subdirectories
and
in
each
directory
have
so
many
files.
For
this
case,
we
have
122
files
and
different
across
each
file
representing
some
part
of
distinct
hypotheses
and
for
a
given
process.
C
C
C
C
C
C
For
example,
you
know
for
climate.
You
know
we
talking
about
global
warming
from
co2
and
other
greenhouse
gases,
which
is
involved
carbon
cycle
in
co2
in
the
atmosphere
absolutely
in
the
trees
over
the
european
ocean.
Those
are
10
scale
of
uranium,
so
one
application
they
have
to
run
simulations
for
thousands
of
years.
C
For
these
cases,
grid
spacing
tend
to
be
coarse,
but
for
more,
this
societal
impact,
really
studies,
usually
incubate
the
model
for
100
years,
but
then
we
are
trying
to
address
this
chaos
part
by
running
many,
many
simulations
by
certain
changing
initial
conditions
that
goes
to
forgiven
model.
We
repeat
the
same
simulation
100
times,
for
example,
that's
also
very
expensive,
but
those
grid
spacing
are
not
enough
to
realistically
simulate
some
of
the
processes,
particularly
storms.
C
So
then
we
have
to
go
down
higher
resolutions,
but
inevitably
this
shorter
time
period,
but
in
return
we
can
get
those
very
realistic
cloud
fields
from
this
whole
model,
except
for
one.
One
is
observation,
but
all
the
other
is
just
a
modern
global
model
simulation
given
those
so
for
one
of
my
project,
I
was
tasked
to
run
one
of
those
clinic
simulations
using
this
variable
solution
global
model.
This
is
in
terms
of
resolution.
C
This
is
a
moderate
grid
resolution
with
this
many
good
clones
and
this
many
radical
levels
gives
about
4
million
with
boxes.
This
is
experimental
code,
so
we
didn't
have
an
open
mp
support.
We
just
use
mpi
and
then
I
we
for
our
projects
to
be
planned
to
run
this
model
for
about
44
years
for
the
historical
and
future
period.
C
C
Typically,
I
submit
a
job
for
requesting
about
five
three
to
ten
hours.
For
this
simulation
I
usually
eight
hours
to
be
safe
for
some
load
of
area
or
slowing
down
the
sketch
space,
for
example.
So
we
have
enough
time
for
the
two
months
of
simulations
and
at
each
end
of
each
job.
This
kind
of
model
code
writes
what
we
call
we
start
fast.
We
can
continue
in
the
next
job.
C
So,
given
this,
how
many
years
to
run
and
then
the
model
throughput
estimation
is,
we
may
need
about
300
jobs
to
be
submitted
if
there
is
no
queue
waiting.
This
becomes.
If
you
just
run
as
planned
with
six
hours
for
two
months,
then
that
takes
about
66
days.
That's
not
too
bad.
Maybe
we
can
finish
testing
analysis,
and
maybe
we
can
report
the
writer
paper
in
maybe
one
or
two
years.
C
However,
we
need
to
consider
the
two
q
time
because
it's
community
architect
community
hpc
system,
so
that,
as
my
interest
goes
on-
and
I
contacted
steve
to
help
me
to
get
some
information
and
before
showing
some
statistical
cue
wait
time,
I
do
follow
best
practices
in
the
mask
documentation.
This
is
really
our
best
friends.
C
In
particular,
the
visible
huge
impact
was
by
setting
appropriate,
lasting
fire
stripping.
We
got
something
to
documentation
for
some
high
resolution
simulation.
I
showed
a
animation
arc
earlier,
something
like
that
that
setting
this
appropriate
striping
reduced
two
hours
of
writing
single
file
to
just
15
minutes.
This
is
a
restart
file.
I
just
talked
about,
and
other
io
has
also
gets
faster,
so
that
has
huge
impact
on
my
workflow
and
productivity.
C
So
given
these
best
practices,
so
I
did
this
as
much
as
I
can
to
run
simulation
faster
once
I
get
the
key.
But
the
question
is
when
I
get
a
q,
so
what
I'm
showing
is
a
statistics
wire
average
regular
q
wait
time
on
korea,
night,
london
and
it's
shown
to
be
as
a
function
of
requested
hours
and
the
weakest
number
of
nodes,
starting
with
a
single
nose
to
a
huge
number
of
nodes,
and
you
can
see
it
really
really
depends
on
those
two
quantities
changes
a
lot.
C
The
choice
of
my
14
ohms
and
eight
hours,
like
kind
of
empirically,
are
dependent
on
this.
My
q
waiting
time,
but
this
is
really
make
it
more
specific
and
in
the
bottom
I
averaged
some
of
those
groups
into
smaller
number
of
groups
so
that
I
can
see
more
clearly
that's
numerical
values.
So
again,
this
is
requested
hours
in
x-axis.
C
So
if
we
use,
for
example,
one
two
thirty
nodes
with
dark
blue,
that's
starting
from
like
a
few
hours
q
a
time
if
it's
because
I
was
very
short-
but
it
goes
much
larger
more
than
20
hours.
If
you
request
longer-
and
even
if
you
get
30
hours
or
more,
maybe
you
could
end
up
waiting
70
hours
hot
spot
is
this
32
to
63
in
alls
are
very
popular,
particularly
around
10,
to
13
hours.
C
You
might
end
up
with
100
hours
waiting
for
who
you
get
killed
to
get
in
regular
priority
for
my
choice
for
this
particular
resolution.
It's
about
12
hours
average
I
mean
two
times,
then
I
can
add
that
number
to
correct
my
estimate
of
the
real
time
to
get
my
job
done
now.
Instead
of
66
days
it's
about
200
days
and
then,
if
you
just
consider
as
a
manual
work
and
downtime
it's
now,
it
becomes
like
one-year
job
rather
than
three
months
or
quarterly
job.
C
This
really
affects
how
I
even
propose
how
many
things
we
can
get
in
the
you
know,
proposals
when
the
api
asks
me
some
questions
and
then
so
you
cannot
simply,
for
example,
I
know
my
model
code
by
using
more
mp
ranks
or
more
nodes.
We
can
get
faster
solution,
gets
down
faster,
like
two
months,
maybe
one
hour,
but
then
that
some
oftentimes
make
you
average
expected
to
return
longer,
so
it
doesn't
really
always
help
and
then
quickly.
This
is
a
result
for
the
haswell.
That's
even
you
can
see
from
the
color.
C
C
C
Given
the
last
current
charge
policy,
if
the
problem
size
increase,
I
think
the
cost
has
to
increase.
I
think
the
cost
can
stay
constant
for
only
perfectly
strong
scaling
so
that,
if
the
problem
size
bigger,
I
think
it's
been
a
while.
Actually
I
wrote
this
slide,
so
I
have
to
think
but
hold
on
yeah
swim
skating
if
we
increase
for
only
given
problem
size,
if
we
increase
number
of
mp
ranks
but
twice
then
run
time,
it
gets
shorter
in
half.
C
I
kind
of
empirically
change
number
of
mp
ranks
or
how
many
hours
to
request
and
across
different
resolutions
best
fit
line
here
is,
of
course,
as
expected,
worse
than
perfectly
weekly
scaling
efficiency
of
one
and
the
gap
getting
bigger
and
bigger.
So
I'm
sorry.
I
forgot
to
mention
that
the
number
of
mpi
tasks
in
x-axis
is
the
simulation
cost
in
terms
of
mask
our
power
simulation
here.
C
And
then
this
picture
is
the
same
if
I
swap
x
axis
to
the
number
of
degree
columns,
so
it's
getting
higher
and
higher
resolutions
cost
increasing
with
a
steeper
slope
than
the
perfect
weak
scaling
as
expected,
so
meaning
our
current
community
needs
more
and
more
and
ask
others.
You
know
in
our
proposal
as
time
goes,
then,
then
you
know
just
simply
assume
our
model
calls
keeps
the
same
rate
of
increase
as
we
use
mono.
C
And
so
that's
pretty
much.
All
I
have
and
in
the
last
slide
is
some
challenges
I
already
mentioned
in
my
own
thoughts
for
night
learning
and
maybe
different
impulse
see
in
general
queues,
less
than
three
hours
are
much
less
crowded
and
you
can
get
a
queue
like
within
15
minutes
or
so,
and
my
personal
challenge
is
for
our
community
one
month
in
the
modern
time
is
very
convenient
time
scale
because
we
wanted
to
learn
many
different
variables
in
3d
in
space.
But
if
I
output
this
every
time
step
or
one
hour.
C
So,
every
month
we
only
write
certain
statistics
like
mean
or
variance
for
each
month
and
that's
sort
of
our
convention.
So
if
it's
possible,
I
want
to
run
for
one
month
for
one
job,
but
that's
getting
more
and
more
difficult
and
if
it
doesn't
reach
you
a
month
at
the
end
of
each
job,
I
have
to
write
an
additional
file
that
keeps
track
of
those
statistics
for
all
those
expensive
cd
variables
over
hundreds
of
those
variables.
C
Maybe
we
could
do
better
online
calculation
of
statistics
offloading
by
gpu,
but
that's
something
we
as
a
competitor.
We
have
to
think
or
even
dimension
reduction
using
some
sort
of
machine
learning,
and
also
you
know
current
because
of
our
numerical
scheme
is
designed
to
based
on
some
sort
of
you
know,
financial
difference
or
similar.
C
C
However,
as
I
said,
the
studio
flooring
is
not
so
straightforward
for
this
large
community
model,
so
we
might
go
switch
to
a
newer,
imaging
emerging
neural
model
that
does
have
some
already
gpu
of
loading
using
those
directive
based
opacity
for
some
impulse
model
or
screen
voice
kind
of
models.
Newer
version
is
already
written
in
c
transparency
in
fortran
to
use
caucus,
and
yet
many
model
processes
are
memory
bound.
C
So
I
don't
know
how
much
we
can
really
push
those
user
needs
and
then,
in
the
end
my
experience
shows
just
users,
both
developers
and
those
people
running
simulations
required
to
have
more
and
more
in-depth
each
pieces,
knowledge
to
debug
or
when
the
job
fails.
Why
john
failed
to
understand
that
we
need
more
and
more
expertise,
so
I
really
appreciate
and
ask
providing
lots
of
training
events.
A
Actually,
do
you
want
to
keep
on
sharing
for
a
moment
because
yeah
thanks
that
was
that
was
a
whole
lot
of
really
interesting
stuff
and
before
I
asked
questions
I
said,
there's
a
couple
questions
already
in
the
in
the
chat
one
given
us.
Can
we
get
a
copy
of
your
slides?
Can
we
post
a
copy
of
these
slides
with
the
meeting.
C
Yeah,
maybe
after
a
while,
actually
maybe
by
now,
but
I
haven't-
got
permission
to
distribute
a
copy
yet
from
the
lab.
But
it's
already
I
interested
approval.
So
once
I
get
approval,
maybe
I
can
put
a
copy
and
on
my
own
yeah,
maybe
I'll
send
it
to
you,
but
it's
many
of
my
personal
opinions
or
understanding
so
not
guaranteed
community.
A
C
C
C
Specifically,
each
task
was
saving
unnecessarily
a
global
array
and
then
that
it's
not
using
memory
efficiently.
So
once
we
go
higher
resolutions
with
more
and
more
memory
bound
at
the
end
of
the
simulations,
so
they've
forced
me
to
spread
simulations
to
even
larger
number
of
nodes
to
get
enough
memory
for
for
the
particular
one
of
the
tasks
in
charge
of
io
in
each
node.
So
in
the
worst
case,
I
was
only
using
20-ish
cores
on
night
landing
modes.
C
F
C
Io
bounded,
yes,
and
I
found
also
different
subroutines,
write
different
kind
of
output
files,
like
I
said
so,
it's
again
this
challenge
to
go
through
this
huge
model
code,
so
one
by
one
we
found
first
by
using
parallel.
We
do
have
a
really
really
nice,
parallel,
io
library
being
used
and
that's
really
doing
good
job,
but
how
different
some
routines
use
that
library
very
via
line,
so
those
regular
output,
part,
is
really
well
tested
and
then
used
in
library
in
a
good
way.
C
Restart
file
component
was
not
so
good,
but
now
it's
taken
care
of,
and
now
we
align
this
I
just
mentioned.
The
last
slide
is
statistics
when
we
did
not
finish
one
month
using
a
job,
we
have
to
write
statistics
that
part
of
the
table
routine
was
also
not
really
doing
a
good
job
on
how
to
use
or
utilize
those
libraries,
and
that
was
really
taking
a
lot
of
time.
In
my
experience,
and
actually
it
makes
force
me
to
use
a
different
model
for
certain
applications,
yeah.
F
F
C
I
don't
have
the
exact
answer
from
the
papers.
I
learned
the
particular
is
from
io
and
synchronized
or
communication
bounded,
but
that
study
did
not
use
the
full
component
of
the
climate
model
and
my
colleague
profiling
of
the
csm
call
sorry.
I
don't
really
remember
the
exact
answer.
I
have
to
go
back
and
ask
my
colleagues.
F
C
C
F
F
C
A
The
the
model
that
you've
sort
of
assembled
here
for
yeah
for
finding
the
sweet
spot.
You
know
there
are
a
lot
of
variables
in
this
model
because
there's
aspects
of
you
know
what
your
natural
times
that
the
simulation
breaks
down
nicely
into
as
well.
As
you
know,
the
simulation
zone
scaling
and
the
queue
times
for
different
parts
of
the
machine
like
it
looks
like
there's,
probably
enough,
for
you
know
a
very
publishable
paper,
just
just
on
the
the
performance
optimization
or
the
the
throughput
optimization
model
here.
C
F
C
A
Okay,
so
so
I
think
there's
some
some
really
interesting
discussion
going
on
here,
but
I'm
also
aware
that
we're
particularly
at
the
the
official
end
of
the
meeting
time.
So
what
we
might
do
is
flick
very
quickly
through
the
last
sort
of
couple
of
items
and
then
perhaps
people
who
do
have
availability
continue.
Can
we
yeah
we
can
keep
on
chatting
after
this,
but
thank
you
again,
pochi
and
buchmay
and
others
for
really
interesting
presentation
and
discussion.
A
C
A
Last
couple
of
comments
quickly
so
coming
up,
we've
got
a
few
upcoming
topics
looking
at
nurse
docs
and
also
a
preview
of
the
nurse
annual
user
survey,
but
we're
also
very
interested
in
more.
You
know
talks
like
what
pretty
just
gave
you
know
an
overview
of
interesting
work
that
our
users
are
doing
and
yeah.
I
think
we
can
see
that
you
know
there
is
so
much
interesting
stuff
and
interesting
discussions
to
come
out
of
that.
A
This
is
how
oh
availability,
you
look
over
the
last
three
months.
It
really
doesn't
change
very
much
if
you
look
at
that
overall
time.
It's
it's
been
the
scheduled
availability,
which
is
you
know
when
you,
when
you
remove
the
scheduled
downtime
has
been
up
over
99
and
the
overall
availability,
which
does
include
you
know
taking
out
the
downtime
they're
still
up
at
sort
of
97
and
a
half
percent
capability
metric
is
the
fraction
of
the
machine
being
used
for
large
jobs,
which
is
sort
of
a
proxy
metric,
but
yeah
for
work.
A
A
A
A
F
A
A
C
C
Well,
I
don't
remember
actually
yeah
yeah
for
each
io.
I
rank
on
each
node,
so
very
inefficient.
Just
using
the
worst
case,
I
used
only
between
10
to
20
cores
per
mode,
and
then
that
part
is
taken
care
of
in
the
latest
version
of
the
modern
code
by
just
not
saving
global,
when
we
either
calculate
or
cultivate
certain
statistics,
or
something
because
it's
a
global
array
and
three
some
of
the
array
being
saved
like
coordinated
variables
as
3d
and
then
also
not
only
so.
C
We
have
this
grid
structure
of
this
can
be
destruction,
so
it
have
to
be
saving
coordinate
of
the
good
sales
center,
but
also
grid
cell
vertices
and
with
their
lines.
So
there's
so
many
global
coordinate
variables
that
was
saved
efficiently
in
some
part
of
the
modern
course,
and
then
that
is
the
root
cause
of
that
is
because
the
model
developed
10
years
ago
or
20
years
ago,
this
is
has
been
very
generations
ago.
F
F
C
F
C
F
C
A
A
A
A
C
A
Actually,
a
a
huge
amount
of
extra
data
was
being
transferred
to
and
from
the
nodes
during
reading,
and
so
there
was
a
a
lot
of
overhead
that
wasn't
necessarily
in,
and
you
know
so
that
profile
kind
of
helped
us
to
you
know,
find
that
and
and
improve
it.
So
that
might
be
something
that's
interesting
to
look
at
for
further
tweaking
of
the
I
o
aspects.
C
F
F
A
So
so
something
that
that
struck
me,
while
you
were
speaking
english-
is
that
so
there's
there's
so
many
different
variables
going
into
this
model
to
work
out.
What's
the
sweet
spot,
were
there
any
tools
that
you
either
identified
as
being
useful
or
would
be
useful
if
they
existed?
That
would
make
this
easier,
for
you
know,
for
a
different
project
that
was
trying
to
you
know,
get
a
similar
kind
of
information
to
what
you
found.
C
A
In
in
the
sense
of
like
you
were
looking
at
things
like
the
queue
wait
time
based
on
the
number
of
nodes
and
the
and
the
length
of
the
job,
and
then
you
had
an
extra
constraint
of
the
the
job
works.
Well,
when
you
divide
it
into
month-long
chunks,
whereas
you've
got
a
you
know
more,
I
o
and
more
overheads,
if
it's
in
two
two-week
chunks
and
so
that
sort
of
adds
an
extra
constraint,
you
know
the
scaling
of
the
model
itself.
A
You
know
the
that
the
optimal
point
of
there,
like
there's,
there's
sort
of
a
lot
of
factors
that
go
into.
What's
your
ideal,
you
know
throughput
per
year
and
did
you
I
guess
what
I'm?
What
I'm
asking
is.
Do
you
have
any
tips
for
you
know
if
somebody
is
trying
to
do
something
similar,
you
know
with
it
with
a
completely
different
model:
yeah
they
work,
maybe
on
yeah
molecular
dynamics
or
go
a
different
field,
but
but
they
want
to
also
find
a
a
good
optimization.
C
Both
speed
and
then
from
our
discussions,
efficient
ieo,
so
that
we
have
a
freedom
to
choose
ours
and
the
nose
for
you
know,
accepted
throughput
right,
for
my
case,
being
experimental
and
a
big
call
and
lack
of
our
expertise
in
our
project.
Our
project,
members
are
all
scientists.
We
don't
have
any
dedicated
software
engineers
in
our
project,
so
optimizing
the
model
was
a
challenge
and
then
later
we
found
this
memory
scaling
issue,
so
we
only
had
a
freedom
to
change
those
valuables
available
when
we
submit
the
job.
C
C
C
C
C
D
C
C
And
yeah,
so
it's
really
affordable
for
me,
is
that
I
run
simulations
for
maybe
for
eight
hours.
You
know
the
job
I
get,
the
queue
finished,
29
days,
spending,
6
hours,
100
nose
and
then
a
load
of
failure
or
some
model
just
crashed
from.
I
don't
know
floating
point
and
anywhere
anything
instability.
Then
I
have
to
just
go
back
and
yeah
know.
The
failure
is
yeah
time
because
yeah
do
not
visit.
F
B
A
A
To
experiment
with
that,
because
that
allows
you
to
set
kind
of
a
maximum
queue
time-
that's
significantly
higher,
but
a
time
min.
That
then
becomes
what
the
scheduler
uses
to
find
a
slot
and
so
it'll
sort
of
find
the
earliest
slot.
That's
at
least
as
big
as
time
min.
And
if
you
get
a
bigger
slot
than
that.
B
C
A
Can
be
done
in
the
script
you
can
from
from
within
the
script,
you
can
run
the
sleep
command
to
see
how
much
time
is
left.
It
would
take
a
little
bit
of
sort
of
you
know
coding
and
scripting,
but
yeah
in
in
principle,
you
you
could,
at
the
end
of
a
checkpoint,
look
to
see
how
much
time
is
left
and
decide
whether
to
continue
or
to
stop
the
job.
At
that
point,.
C
F
C
C
Yeah,
what
we
can
do
is
maybe
maybe
when
the
job
you
know
when
the
time
left
is
become
like
again
half
an
hour,
maybe
stop
integrating
model
integration
and
then
read
nameless
again
or
get
some
input,
text
file
or
xml
file,
the
past
xml
file
again
and
the
update,
restart
file
setting
and
then,
if
it's
time
to
write
list
and
then
or
or
just
to
make
the
model
right,
listen
for
at
the
time,
but
yeah.
Let
me
think-
and
maybe
I
can
talk
with
some
engineer
as
well.
A
So,
coming
from
the
other
direction,
I
guess,
depending
on
how
well
the
model
responds
to
if
after
you've
written
a
result
file,
then
suddenly
it
hits
timeout
so
that
you
only
lose
a
few
minutes
after
or
or
it
quits
after
that
see,
so
you
could
put
sort
of
a
watcher
in
the
script
to
look
for
a
restart
file
and
when
and
when
a
new
restart
file
appears
check
the
amount
of
time.
If
there's
not
going
to
be
enough
time
to
finish
the
next.
A
So
I
guess
the
other
consideration
that
you
would
need
there
would
be
presumably
the
time
for
a
a
new.
Would
you
yeah
continuing
on
is
not
the
same
as
the
initial
time
like
I
imagine.
The
time
from
the
start
of
the
job
to
the
end
between
the
first
restart
file
is
written
is
probably
a
little
bit
longer
than
from
between
when
the
first
real
style
is,
and
the
second
restart
file.