►
From YouTube: NUG meeting Feb 2021
Description
Video from our monthly NUG meeting on Feb 18, 2021. Topic of the day was "Making the most of Slurm at NERSC" with Shahzeb Siddiqui from NERSC User Engagement Group
A
All
right,
so
people
who
have
been
to
a
few
of
these
now
will
be
familiar
with
this.
Our
plan
is
for
quite
an
interactive
meeting.
We've
got
somewhat
more
than
50
people,
which
potentially
could
get
yeah
a
little
bit
noisy,
but
you
know
that's:
okay,
we'll
we'll
start
off
reasonably
informally
and
if,
if
if
we
need
to
we'll
go
to
a
slightly
more
formal
q,
a
part
but
really
the
key
point
here
is
this
is
not
meant
to
be
just
a
presentation.
This
is
a
interactive
meeting.
A
It's
a
forum,
an
opportunity
to
share
things.
Please
participate
yeah,
unmute
yourself
and
speak
when
you
have
something
to
say
if
it
starts
getting
noisy,
we'll
ask
people
to
raise
their
hand
first
yeah,
but
otherwise,
so
like
that,
if
you
haven't
already
seen,
we
have
a
nurse
user
slack
and
there
is
a
hashtag
webinars
channel
there.
That's
another
good
place
to
ask
questions
and
continue
the
conversation
one
of
the
yeah,
the
nice
things
about.
That
is
that
the
chatter
there
result
is
retained
beyond
the
end
of
the
zoom
meeting.
A
A
A
So,
let's
start
out
with
win
of
the
month,
so
the
purpose
of
this
segment
is
to
show
off
an
achievement
or
shout
out
somebody
else's
achievement,
and
it
doesn't
have
to
be
big.
It
can
be
a
fairly
big
thing
like
having
a
paper
accepted
or
a
relatively
small
thing,
like
solving
a
bug
that
had
you
know,
kept
you
stumped
for
a
few
days.
A
This
is
also
a
good
opportunity
to
tell
about
some
scientific
achievements.
We
know
that
nurse
users
are
doing
some.
You
know
pretty
amazing
things.
We
don't
always
know
the
details
of
what
those
things
are,
but
we
do
really
like
hearing
about
it
and
we
think
it's
inspiring,
for
you
know
us
and
each
other
as
well
in
particular
nurse
hands
out
some
awards
every
year
for
high
impact
scientific
achievement
and
for
innovative
use
of
high
performance
computing,
and
you
know
maybe
you're
doing
some
work.
A
That
is
a
candidate
for
those
awards,
and
you
know
we'd
love
to
hear
about
here.
On
that
note,
actually,
the
early
career
nominations
for
those
awards
are
due
this
week.
We'll
have
an
announcement
about
that
fairly
shortly,
but
just
so
we're
we're
especially
keen
to
hear
about
that.
We've
got
one
more
day
before
the
deadline
for
those
so
yeah
any
high
impact,
scientific
work
or
innovative
uses
of
high
performance
computing
that
you
either
are
doing
or
know
of
you
know
please
nominate
by
the
end
of
this
week.
A
So
maybe
people
are
a
little
shy.
Oh
I'll
kick
one
off.
I
had
something
that
I
I
was
pretty
pleased
with
how
it
came
out
working
with
one
of
our
users,
who
is
who
has
a
high
throughput
computing
type
workflow,
which
and
and
this
particular
workflow
has
an
extra
challenge
in
the
individual
tasks,
mpi
tasks
and
multiple
mpi
tasks
across
you
know,
per
node
mpi
task
across
many.
Many
nodes
are
a
little
bit
tricky
because
most
of
the
workflow
tools
use
the
mpi
infrastructure
to
manage
the
workflow
and
so
running.
A
An
mpi
task
inside
of
an
mpi
job,
essentially
inside
of
a
larger
workflow,
has
a
few
challenges
and
there
is
kind
of
a
known.
You
know,
at
least
in
principle,
solution
which
is
to
use
shifter
containers
so
create
a
docker
container
on
on
the
laptop
and
set
up
a
the
mpi
workflow
to
happen.
Sort
of
you
know
locally
to
a
node
within
that
container
and
then
use
shifter
to
run
that
container
in
parallel
multiple
times
across
many
nodes
of
corey,
and
you
know
it
took
a
it
took
a
few.
A
But
you
know,
after
a
a
a
couple
of
days
of
sort
of
yeah
backwards
and
forwards,
we
yeah
we're
able
to
make
a
a
working
workflow
of
it
and
that
that
will
make
its
way
onto
a
or
a
variation
of
that
will
make
its
way
as
an
example
on
our
documentation
pages
in
the
in
the
not
too
distant
future.
But
you
know
I
was.
I
was
pretty
chuffed
about
that
yeah
anybody
got
any
other
stories
they'd
like
to.
A
C
We
have
one
not
kind
of
wind
of
the
month
but
more
like
ireland
stuff.
That
might
be.
You
know
interesting
to
share,
so
I
was
running
I'll,
try
to
run
globally
high
resolution
simulations
in
the
context
of
climate
simulations,
but
again
io
has
been
taking
quite
a
lot
of
chunks
with
time,
but
I
just
realized
so
again
again
concerning
the
file
size,
ranging
from
the
tens
of
gigabyte
200
gigabyte
as
a
model
output.
C
I
didn't
realize
that
I
have
not
set
properly
the
the
last
file
stripping
striping
before
yeah,
for
example,
in
the
end
of
the
simulations,
the
model
write,
restart
file.
That's
you
know
more
than
100
gigabytes,
but
it
taking
in
the
worst
time
about
two
hours
to
just
write
this
file.
But
then,
after
I
you
know
set
the
five
striping
to
the
the
medium.
I
believe
then.
Actually
it
reduced
like
10
minutes
or
maybe
20
minutes.
C
D
A
C
C
Improvement
exactly
and
then
also
it's
nice
thing
is
once
I
set
this
property
for
the
directory,
then
all
the
files
underneath
you
know
written
after
that.
It's
it's
inherit
that
property.
So
all
the
output
files
is,
it's
naturally
striped
medium
size
by
just
sitting
at
the
top
directory.
So
that's
quite
handy.
Yes,.
C
Yeah,
and
maybe
another
one
that
I
might
want
to
share
is
that
so
this
exercise
was
part
of
my
preparation
for
running
production.
High
resolution
simulation,
so
we
are
testing
different
number
of
nodes
or
different
io
settings
or
compile
optimizations,
and
one
thing
I
so
I
was
in
the
end
of
the
exercise.
I
was
calculating
okay,
so
at
the
end
of
one
year,
our
own
one
year
how
many
simulation
years
can
we
get?
So
that's
the
you
know,
purpose
of
this
exercise,
so
that's
I
just
realized
doing
that.
C
Not
just
increasing
number
of
nodes
to
get
some
improvement
in
the
model.
Throughput
does
not
necessarily
leads
to
much
many
more
simulation
years
to
be
done
in
one
year,
because
let
me
can
I
share
one
like
a
graph
file
on
the
on
the
chat.
I
need
a
google
spreadsheet
to
schedule.
Statistics
for
the
average
q
wait
time
for
corey
knight
landing
on
the
past
one
year
and
were
you.
C
A
A
C
C
C
E
C
C
C
E
A
C
F
C
C
A
Okay,
thank
you.
So
so
that's
some
very
interesting
tips
and
we're
very
much
getting
that.
That's
that's
very
much
in
line
with
our
topic
of
the
day.
So
what
do
I
do?
Is
I
pause
this
conversation
until
we
get
up
to
that
section
and
I
think
we'll
have
an
opportunity
to
to
go
into
some
more
depth
in
detail
and
and
shows
I've
just
got
some
some
background
information
about
why
this
is
the
case
as
well.
A
I
think
we
can
learn
from
not
only
our
own
sort
of
yeah
points
that
we
got
stuck
in
and
tripped
up,
but
the
the
things
that
were
challenging
for
other
people,
but
this
doesn't
have
to
be
things
that
didn't
work.
That's
also
an
opportunity
to
call
out
you
know:
resources
you've
stumbled
across,
for
instance,
or
discovered
recently
that
might
be
valuable
to
other
nurse.
A
A
Well,
we've
had
a
a
few
discussions,
I
think
of
things
that
we
learned,
so
we
can
step
on
to
the
next
item.
So
our
next
segment
is
about
announcements
and
calls
for
participation.
We
have
a
a
couple
of
announcements
from
nurse
side,
but
this
is
also
yeah.
This
is
a
general
user
forum
and
we're
also
keen
to
hear
about
you
know,
conferences,
events
and
so
on
that
you
know
of
or
perhaps
organizing
or
particular
you're
contributing
to
that
would
be
valuable
to
other
nurse
users.
A
A
Yeah
we've
got
a,
I
guess.
Yeah
society
has
a
fairly
big
invisible
target
in
the
pandemic
at
the
moment.
For
that,
the
other
award
is
for
innovative
uses
of
high
performance
computing,
which
recognizes
research,
researchers
who
have
used
nurse
resources
in
innovative
ways
to
solve
a
significant
problem
or
have
come
up
with
a
new
methodology
that
might
have
a
large
scientific
impact.
A
So
this
can
include
things
like
you
know,
using
hpc
in
a
field
where
it
hasn't
previously
been
used
or
used
terribly
much
or
combining
computing
data,
networking
and
edge
services
to
do
something
new.
You
know
you
know
in
a
domain
where
hpc
is
already
in
use,
so
for
the
early
career
eligibility.
This
is
I
take
it
particularly
at
users
using
nurse
resources
who
early
in
their
career,
so
so
postdocs
or
or
nurse
users
who
have
received
their
degree.
A
A
A
A
A
Organization,
so
if
we
don't
have
anything
else
in
the
way
of
announcements,
we
can
go
on
to
our
topic
of
the
day
and
I'd
like
to
introduce
shazam,
siddiqui
who's
part
of
our
user
engagement
group
here
and
has
a
lot
of
experience
with
sloan
and
is
going
to
walk
us
through
some
of
the
details
of.
I
guess
your.
G
Thanks
yeah,
you
can
start
okay,
so
yeah.
This
is
going
to
be
a
quick
recap
on
you
know,
for
you
guys
to
get
up
to
speed
on
slurm
and
get
some
best
practices
using
our
cluster.
So
you
know,
as
you
may
log
you
know,
use
our
cluster.
You
typically
log
in
to
our
nodes.
You
know
please
note
that
these
login
nodes
they're
shared
with
many
users
right,
so
these
are
not
meant
for
computational
resource.
G
What
you
would
typically
do
is,
you
know,
specify
your
s
patch
directives
and
a
and
you
know,
replace
the
number
of
nodes
and
you
know,
run
your
script.
What
what
happens
in
the
back
end
is
your
script.
Actually,
you
know
is
processed
by
this
alarm
server.
It
processes
the
script
and
then
finds
the
allocated
nodes,
and
you
know
fulfills
your
request.
G
So
on
corey
we
have
like
several
login
nodes.
Those
are,
you
know,
those
icons
in
blue
and
sometimes
some
of
our
login
nodes
are
also
used
as
compute
resources
right
when
a
job
gets
allocated,
you
may
you
may
get
allocated
to
one
node,
which
will
be
this
yellow
icon.
If
you
have
multiple
nodes,
then
you
know,
slurm
will
do
that
for
you.
G
That
could
be
those
red
icons
and
you
know,
typically
at
the
end
of
the
job,
you
will
get
an
output
or
error
file
on
the
saved
on
the
disk
right
and
just
one
thing
to
also
notice.
You
know
we
have
cues
that
allow
us
to
submit
exclusive
node.
So
you
can.
You
can
do
that,
but
we
have
like,
for
instance,
a
shared
queue
which
is
shared
with
multiple
users.
G
Okay,
so
when
you
submit
a
job
either
through
s
patch
or
yeah,
basically
what
happens
is
the
job
will
go
through
several
job
states?
The
first
is
the
you
know,
append
and
salaam
will
try
to
figure
out.
You
know
when
it
needs
to
get
the
resources,
so
it
will
be
in
this
state.
It
will
once
it's
done
from
pending.
You
will
configure
the
nodes
that
are
required
to
run
the
job,
and
then
your
job
will
actually
be
in
a
running
state.
G
G
One
thing
to
note:
is
you
use
sq
and
s
control
for
the
lifetime
of
the
job
from
pending
to
completed,
but
you
can
use
sacct
to
query
historical
jobs.
Right,
didn't
know
that
you
know
using
these
commands
frequently
will
ping
our
slurm
server
so
doing
too
much
request.
You
know
on
like
a
loop
can
actually
impact
a
server,
so
it's
it's
generally
prohibited
right.
G
G
G
G
Is
you
know
if
you,
if
you
have
a
job,
you
don't
need
to
guess
the
wall
clock
time
you
can
say
something
like
the
minimum
amount
of
time
that
you
need
like,
for
instance,
if
you
have
a
job
that
runs,
let's
say
six
hours,
but
you
want
to
make
it
this
time
so
that
sloan
will
pick
it
up
more
quickly.
You
can
say,
let's
say
a
time
limit
of
like
let's
say
three
hours
in
this
example.
G
If
you
see
the
whole
box
is
actually
blue,
that's
six
hours,
but
the
dark
blue
could
be
the
the
three
hours
and
then
it
will
just
try
to
fit
it
in
to
the
scheduler.
One
thing
to
note
is
that
some
of
our
q
policies
require
a
min
time.
For
instance,
flex
skew
is
one
of
them,
so
it's
just
one
thing
to
be
noted.
A
A
G
G
It
doesn't
change
the
the
actual
job
time
itself,
so
it
improves
the
back.
The
backfilling
scheduling
algorithm
so
like
allows
scheduler
to
see
that
you
know
this
job,
which
is
supposed
to
be,
let's
say
six
hours.
It
doesn't
need
all
that
time
just
needs.
Let's
say
the
amount
up
to
min
time,
which
may
be
like
two
or
three
hours
and
it
will
schedule
a
job
ahead.
K
A
B
A
G
Next
slide,
okay,
so
in
terms
of
what
we
have
and
the
cues
that
we
have
typically
you
will.
You
will
use
a
regular
clue
for
most
of
your
workload
right
and
you
know
so
in
terms
of
the
the
cost.
You
know
regular,
crucial
piece
of
food
it.
I
think
I
believe
it
has.
I
think
48
hours
is
a
time
limit,
so
it
should
be
sufficient
for
most
of
your
workload.
G
If
you
need,
for
instance,
some
emergency
workload,
premium
queue
is,
is
the
way
to
go,
it
will
submit,
it
will
schedule
the
job
much
faster,
but
you
know
it.
It
is
more
expensive
right.
Premium
queue
is
also
special,
so
yeah
q
in
in
the
sense
that
not
all
user
automatic
access
to
it,
the
your
pi
will
have
to
grant
you
access
to
this,
and
also
the
charge
factor
gets
changed
once
you
reach.
I
believe
two
percent
is
our
is
the
rate
so
just
be
mindful
of
that.
G
G
G
A
log
qos:
this
is
good.
If
you
have
workload,
that
really
is
not
that
important.
You
don't
mind
having
a
long
kind
of
wait
time,
so
you
you
can
use
that
and
it's
also
very
cheap.
The
flex
q
is
is
good.
If
you
support
like
flexible
wall
time,
this
queue
requires
you
to
have
the
min
time
or
time
main
option
set
to
at
least
two
hours.
It
won't
accept
the
job.
If
you
don't
set
this,
so
it
has
to
be
less
than
two
hours
and
it's
only
available
on
k.
G
L-
and
this
is
good
for
if
you
have
your
job
supports
like
restarts
or
if
you
wanted
to
be
able
to
start
if
the
job,
for
instance
gets
killed,
if
you're
going
to
use
a
shared
queue,
this
is
shared
with
other
users.
So
when
you,
when
you
submit
a
job,
you
get
into
a
node,
keep
in
mind
that
you
will
be
sharing
this
note
with
other
users.
G
So
this
is
good
if
you,
if
you
just
want
to
get
your
jobs
done,
but
you
don't
care
about
in
the
case
of
like
performance,
you
don't
need
exclusive
node.
If
you
do
need
an
exclusive
node,
then
you
should
use
something
else
or
just
use
the
exclusive
option:
the
overrun
queue.
This
is.
This
is
good
if
you
have
a
zero
project,
account
balance
and
you
still
need
to
submit
jobs.
G
G
Okay,
so,
as
I
mentioned,
you
know
you
most
of
your
workload
should
be
going
through
the
regular
queue.
You
know.
We
also
have
the
premium
queue.
That's
for
you
know,
like
you,
know,
immediate
kind
of
needs
like
if
you
have
some
kind
of
conference
that
you
need
to
submit
something
and
only
have
like
a
week
or
so
you
know
you
could
use
the
premium
queue
or
so
for
ins.
One
thing
to
note
is
the
flat
skill.
G
G
The
large
kit,
like
if
you're
submitting
like
large
jobs
on
known
nodes,
then
we
also
do
discount
like
up
to
10
20
foods
with
a
50
percent
discount
so
that
it's
good
to
know
if,
if
you,
if
you
want
to
submit
like
a
larger
workload
and
and
this
is
available
on
the
regular
regular
queue,
okay
and
yep
so
just
to
summarize,
you
know,
I
think
one
thing.
One
thing
that
you
may
learn
is
you
know
you
is
the
scheduling
them.
Do
we
use
backfilling?
G
So
if
you
have
short
running
jobs,
you
know
just
try
to
use,
let's
say
mint
or
time
mission
to
get
your
jobs
too
quickly.
You
know
we
support
several
cues.
So
pick
the
right.
Cue
and
that's
you
know,
use
a
flex
queue
when
you
need
it
will
save
you
money
for
sure
users
can
if
you're
gonna
submit
large
number
of
jobs
up
to
1024.
A
Thanks
joseph
so
so
we've
got
about
five
minutes
or
so
for
q
a
and
I
see
actually
canoe
priya,
I'm
not
sure.
If
I'm
pronouncing
it
correctly
has
a
has
asked
a
question
in
the
chat.
If
you
ask
for
four
nodes
using
the
interactive
queue,
can
you
do
this
split
between
two
different
jobs?
I
think
I
want
to
clarify
that
question.
Do
you
mean
running
different
s
runs
together
or
do
you
mean
request
two
jobs
of
two
nodes?
Each.
A
Yes,
you
can
do
that.
We
have
in
the
examples
page
of
our
docs,
which
is,
I
might
put
a
put
a
link
to
it
in
there
in
a
chat
in
a
moment
you
can-
and
you
can
do
this
interactively
as
well
start
an
s
run
in
the
background
where,
for
one
of
the
jobs
and
then
start
the
other
one,
what
you'll
probably
want
to
do
is
actually
I
I
assume
that
you're
looking
at,
for
instance,
comparative
debugging,
that's
correct
yep
as
the
use
case.
A
B
So
this
is
kind
of
related
to
what
the
earlier
speaker
was
talking
about.
You
know
if
you
have
something
that
you
expect,
can
you
backfill
reasonably?
Well,
so
the
you
know,
total
number
of
core
hours
for
your
job
is
is
modest
right,
but
you
know,
essentially
you
know
if
you
can
divide
the
job
up
in
a
way
such
that
you
know,
you
essentially
have
a
rectangle
in
you
know
time
node
space
right.
B
B
A
A
A
B
D
A
So
I'm
just
posting
now
in
the
webinars
channel,
one
of
our
docs
page
is,
is
example
job
scripts,
and
this
is
a
great
resource
actually
well.
We
hope
it's
a
great
resource
for
examples
of
lots
of
different
use.
Cases
which
includes
multiple
simultaneous
jobs
for
I'll
need
to
dig
a
little
further
to
find
the
link
specifically
for
ssh
into
a
node.
A
M
A
The
request
kind
of
acts
as
a
single
job
and
then
basically
the
the
individual
jobs,
get
kind
of
pulled
off
the
request.
So
my
understanding-
and
maybe
shazeed,
has
more
information
about
this.
Is
that
the
request
will
age.
So
so
you
know
the
entire
request
will
reach.
You
know
a
kind
of
you
know
the
same
priority,
and
then
you
know
when
slums
scanning
it
it
will
pull
off.
You
know,
however
many
jobs.
It
can
start
at
the
moment,
or
at
least
the
next
job
that
it
can
start
at
the
moment.
G
Yes,
so
one
thing
that
that
we
didn't
discuss
today
was
the
how
house
learn:
does
job
priority
so
currently
we
we
use
this
learn
feature.
It's
called
multi-factor
priority
when
salary
actually
figures
out
which
job
actually
needs
to
be
scheduled.
It
does
it
based
on
priority
and
there
are
multiple
factors.
G
What
goes
into
job
priority,
and
one
of
the
factor
is
age,
the
the
age
of
the
job
length,
right
as
it
sits
in
the
queue
and
then
also
when
it's
actually
running,
as
you
may
know,
if
it's
a
longer,
if
it's
a
job,
that's
waiting
in
the
cube
for
a
longer
time,
then
the
age
factor
will
grow.
That
means
that
slurm
is
trying
to
figure
out
that
this
job
is
in
the
queue
for
a
long
time.
It
needs
to
get
scheduled
right
same
thing.
G
G
If
you
think
that
would
be
useful,
I
think
we
can.
We
can
try
to
put
some
more
documentation
into
that.
One
thing
to
note
is
that
espio
works
only
for
pending
jobs.
So
if
you
have
a
job
that's
pending
and
you
want
to
know
the
priority
of
pending
jobs,
then
that
could
help
you
can
try
to
see
your
job
and
then
also
sorted
by
the
queues
and
it.
F
G
G
A
A
Yes,
so
we
have
a
couple.
More
questions
have
come
up.
I
might
address
them
in
reverse
order,
because
of
basically
how
how
easy
easily
answered
they
are
so
ronnie
asks.
Do
specific
projects
have
different
priority
and
the
answer
is,
for
the
most
part,
no
different
projects
have
different
allocations,
which
you
know,
I
guess,
influences
how
many
jobs
they
can
run
over
the
entire
year.
A
But
priority
is
all
the
same.
There
is
kind
of
an
exception
in
that
projects
can
request
access
to
the
real
time
queue
and
that's
generally,
for
sort
of
special
cases
such
as
you
know,
needing
needing
to
synchronize
with
time
on
a
on
an
instrument
somewhere.
For
instance,
you
know
super
facility
type
work
and
real-time
queue.
Jobs
have
super
high
priority,
but
that's
kind
of
a
special
case
in
the
in
the
normal
course
of
things.
A
A
A
A
A
A
We're
actually
getting
close
to
the
top
of
the
hour,
and
I
think
we've
covered
the
questions
that
have
come
in
in
the
chat.
We
might
be
able
to
continue
with
a
q
a
session
sort
of
at
the
at
the
end
of
the
meeting.
For
those
who
are
still,
you
know
around
and
available,
but
what
we
might
do
now
is
flip
through
the
last
couple
of
items
in
our
agenda
so
that
we
can
finish
the
sort
of
formal
part
of
the
meeting
before
12
o'clock,
so
the
next
one's
a
fairly
quick
and
easy
one.
A
What's
coming
up
next,
we
are
always
looking
for
topic,
requests,
suggestions
or
better
still
nominations
and
volunteers
to
host
a
topic
of
the
day.
This
is
a
a
great
opportunity
if
you
want
to
do
a
kind
of
a
relatively
short.
You
know,
lightning
talk,
kind
of
level,
overview
of
some
interesting
work
that
you're
doing
using
nurse
resources
and
some
tips
that
you've
learned
that
might
help
other
users.
You
know
we'd
love
to
hear
about
it.
A
A
A
So
that's
that's
great
to
see
we
have
a
target
of
25
percent
of
the
workload
on
corey
being
jobs
that
need
a
system
of
corey
scale,
basically
large
jobs,
things
needing
more
than
more
than
a
thousand
nodes,
and
you
know
it's
good
to
see
that
corey
is
being
well
used
for
this
use
case.
So
we
have
a
25
target
and
over
40
of
our
workload
in
january
was
these
large
jobs.
A
Tickets
are
coming
in
at
a
slightly
faster
rate
last
month
than
than
what
we
closed
them.
So
we
have
a
current
backlog
as
of
a
couple
of
weeks
ago,
of
about
620
tickets,
and
that
is
all
of
the
formal
part
of
the
meeting.
If
people
are
interested
in
sticking
around
a
little
longer
to
chat
about
tips
on
using
slurm,
I
think
I'm
available
for
a
little
longer.
I'm
not
sure
if
I'm
not
sure
what
she's
ed's
calendar
looks
like.
Are
you
available
to
stick
around
for
another
five
or
ten
minutes?
A
Okay,
so
it
might
be
only
only
a
few
minutes
then
and
then
we'll
probably
need
to
drop,
but
I
I
believe
we
have
a
few
other
nurse
people
on
the
line
as
well
so
between
us.
We
can
probably
answer
some
questions
and
I
wouldn't
be
surprised
if
some
of
our
users
online
are
also
quite
experienced
slum
users
and
can
participate
in
that
contribute.
A
E
A
C
C
C
A
C
A
A
A
A
We
have
a
documentation
page
about
variable
time,
jobs
where
we've
got
some
example,
scripts,
pretty
much
for
setting
up
a
long
workload
to
use
the
flex
queue
to
break
it
up
into
chunks
and
then
resubmit
itself
that
you
know
when
it
reaches
the
end
of
one
time
chunk
to
sort
of
automatically
do
long-running
jobs.
But
that
does
require
the
job
to
be
capable
of
checkpointing.
A
A
A
A
A
C
A
C
A
A
A
There
is
a
second
chart
on
that
page
showing
the
number
of
jobs,
and
in
some
cases,
when
you
see
a
you
know
the
the
wait
time
might
be
particularly
high
or
particularly
no
low
for
a
certain
category.
But
then,
when
you
look
it's
because
during
the
period
there
was
only
a
very
small
number
of
jobs,
you
know
five
or
ten
jobs
that
requested
that
sort
of
yeah
that
particular
shape,
and
so
these,
statistically
probably
not
too
significant
jobs,
maybe
kind
of
adding
a
lot
of.
If
you
like
false
variability.
C
A
C
A
A
A
Although
this
is
just
by
nodes
and
not
necessarily
by
time,
weighted
right,
if
I
sorry
wall
time
requested
so
yeah,
you
will
sometimes
find
that
yeah
here.
Some
of
these
you
know
in
this
square
there
was
only
six
jobs,
and
so
that
you
know
is,
is
contributing
to
you
know
one
of
these
boxes
here,
because
it's
not
very
many
jobs,
it's
not
statistically
fantastic.
A
So
it
is
something
to
have
in
mind
when
you're.
Looking
at
this
another
really
useful
one.
I
find
that
in
a
way
zooms
out
a
little
bit
and-
and
I
think
can
be
a
bit
helpful
because
of
that
is
this
backlog,
and
what
this
is
showing
is
the
total
amount
of
queued
work
in
terms
of
you
know
all
of
corey
days.
A
A
Hopefully,
if
it's
a
little
bit
short
it'll,
be
able
to
backfill
and
fill
and
and
start
a
lot
sooner
than
that,
you
will
notice
that
k.
L
jobs
have
a
a
much
lower
backlog,
they're
they're
in
the
kind
of
the
two-day
range
compared
to
10
days
for
haswell,
and
that
is
driven
partly
by
the
fact
that
we
have
five
times
as
many
k,
n
l
nodes
right.
A
C
C
C
D
I
I
E
N
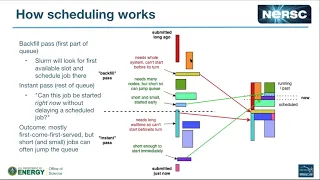
So
sqs,
I
will
remove
that
column
now
before.
What
we
had
is
that
it
tells
you
it's
gonna
be
starting
three
days.
Actually,
it's
not
it's
going
to
start
in
three
days.
It's
it's
about
its
priority
is
going
to
be
reaching
the
threshold
that
scheduler
will
consider
it.
So
this
is
for
the
the
backfield
pass,
but
then
there's
also
when
you
see
it,
it
happens
immediately.
N
It's
because
it's
backfilled,
so
the
column
tells
you
it's
going
to
reach
the
threshold
to
for
the
scheduler
to
consider
its
regular
path
in
how
many
days,
because
we
have
a
threshold
set
there,
but
then
all
the
jobs
in
there.
If
it's
short
enough
small
enough
and
you
can
get
a
opportunity
to
get
back
filled,
it
will
run
quickly.
I
N
Again
that
you're,
this
is
what
this
plot
is
going
to
tell
us.
We
have
in
our
configuration
actual
numbers.
So
if
you
submit
a
job
in
a
regular
queue,
you
come
in
with
a
start
priority,
and
then
we
have
it.
It
takes
you
three
days
to
start
to
be
scheduled,
but
actually
recently
we
removed
that
wait
time.
The
the
original
we
had
this
as
manual
wait
time
for
a
regular
job
to
be
scheduled.
N
Our
a
new
scheme
does
not
need
to
have
this
up
manual
weight
to
originally
we
had
some
some
related
bugs
that
without
this
weight
there
were
issues
related
to
the
system
over
utilization
and
newer
version
does
not
need
this
weight
anymore.
So,
basically,
a
a
job
submit
it
already
reaches
threshold.
So
that's
why
we
remove
that
column,
you're,
not
seeing
it
in
sqs
anymore,
something
like
that.
N
I
A
Jobs
so
expanding
on
that
a
little
bit
so
so
your
job
goes
into
the
queue
at
some
point
with
a
like.
Your
priority
basically
increases
over
time.
The
the
change
that
helen
was
talking
about
where
you
used
to
see
like
a
three-day
wait
was
because
qregular
used
to
start
out
down
here
and
it
would
take.
A
You
know
three
days
to
get
up
to
this
line,
whereas
now
it
starts
right
at
the
top,
but
only
two
jobs
can
increase
past
this
line
at
a
time
per
user
and
above
here
this
is
the
this
is
the
part
of
the
queue
that
slurm
spends
a
lot
of
time,
trying
to
find
a
place
to
schedule
the
job
to
start
and
then
for
everything
below
that
it
does
a
quick
run
through
and
just
ask.
Can
I
start
this
job
right
now.