►
From YouTube: HTM Hackers' Hangout - Apr 7 2020
Description
Details at [https://discourse.numenta.org/t/big-htm-hackers-hangout-april-7-2020/7258](https://discourse.numenta.org/t/big-htm-hackers-hangout-april-7-2020/7258) -- Watch live at https://www.twitch.tv/rhyolight_
A
So
I'm
gonna
go
ahead
and
just
introduce
this
remote
meeting
we're
up
by
the
way
we
are
I'm
streaming.
This
on
to
twitch,
I,
think
there's
six
people
watching
on
twitch
and
I
will
probably
take
a
recording
of
this
and
maybe
put
it
on
YouTube,
because
that's
where
I
have
all
the
other
hackers
hangouts
so
welcome
to
the
hacker
HTM
hackers
hangout.
This
is
probably
like
the
hundredth
one
of
these
that
we
did,
although
we
have
it.
A
I
haven't,
held
one
in
a
while,
mostly
because
I've
been
live
streaming
so
often
that,
like
the
hackers,
hangout
was
sort
of
a
way
for
you
guys
to
see
what
we
were
thinking
about
and
then
give
feedback
from
the
community,
but
I've
gotten
so
much
feedback
from
the
community.
Just
opening
up
live
streams
and
chatting
with
people
in
the
chatroom
that
I
haven't
I
haven't
made
it
a
priority.
A
So
this
is
the
first
HTM
hackers
hangout
that
we've
had
in
quite
a
while
quite
a
few
months,
so
I
just
saw
max
Lee
join
thanks
for
joining
and
for
those
of
you
who
have
something
that
you
want
to
present.
I
know
I
have
on
the
schedule
max
Lee,
Jordan,
Kay
and
Marty
Chang
I,
don't
think
I've
seen
Jordan
yet,
but
you
might
want
to
talk
about
actor
models
and
then
I'll
open
it
up
for
anybody
to
to
have
that
has
a
topic,
but
for
right
now.
A
Let
me
just
say
that
there's
a
lot,
and-
and
at
least
two
of
these
speakers
from
the
community
tonight
are
going
to
be
talking
about
distribution
models
or
ways
of
taking
the
computation
that
we've
talked.
We
talked
about
in
HTM
and
distributing
across
multiple
nodes
and
how
those
will
can
be
cut
up
like
a
what
granularity
we
can
cut
those
up
cut
this
process
by
processing
up
by
region,
cortical
column
or
my
layer.
Perhaps-
and
those
are-
these-
are
all
open
questions
like
the
best
way
to
do.
This
is
unknown.
A
So
one
of
the
biggest
areas
of
to
do
this
in
and
their
platforms
is
a
lick,
sir,
so
I
think
both
max
and
like
there's
another
guy
on
the
forum
delayed
or
Demetri.
He
programs
HTM
s
in
elixir
as
well,
and
those
I
think
you
know
come
with
this
actor
model
and
it's
a
I'll.
Let
the
other
people
talk
about
it,
but
my
questions
or
my
big
questions
are
just
because
no
mint
is
not
working
on
this
at
all.
As
far
as
I
know
we're
not
working
on
doing
distributed,
HTM
processing
in
any
way.
A
So
it's
super
cool
for
me
to
see
the
community
working
on
this,
because
it's
obviously
something
that
everybody
understands
his
valuable
work
to
do
so.
I'm
gonna
just
throw
some
open
questions
out
there
and
it's
mainly
like
what.
Where
do
we
break
it
up
at
in?
In
some
of
in
one
of
my
HTM
school
videos
called
cortical,
circuitry
I
think
I
propose
that
a
layer
would
be
a
good
modular
unit
to
start
out,
because
it's
got
input
and
output.
It
represents
something
and
it
is
a
process,
that's
doing
something.
A
It
could
be
different
from
another
layer.
So
I
I
sort
of
already
threw
that
out
there
I
think
that's
a
that
would
be
a
good
place
for
the
distribution
to
occur.
You
know,
but
but
breaking
up
a
layer.
It
would
be
really
really
hard
in
my
opinion
like,
ideally,
though,
like
if
you
had
all
of
the
proper
the
compute
process
and
parallelism
that
you
could,
you
could
do
it
like.
A
The
brain,
which
is
essentially
like
every
neuron,
is
its
own
node,
but
I
think
we're
pretty
far
cleaved
from
being
able
to
do
that
at
this
point,
so
I
I
think
like
targeting
either
a
cortical
column
or
a
layer
within
a
cortical
column
is
a
good
target
for
anybody
to
shoot.
For
at
this
point,
so
that's
sort
of
what
the
the
community
topic
is.
It
sort
of
it
emerged
and
I'm
gonna.
C
C
Obviously
this
seems
like
something
that
should
be
easy
to
to
implement
and
distribute
and
I'm
strong
yeah
and
two
walls
crashed
and
burned,
and
it
languished
until
a
month
ago
and
in
the
meantime,
I
toe
has
been
working
on
it
chomping
on
back.
You
know
in
the
back
of
my
brain
and
thinking,
okay.
Well,
here's
how
it
would
work
so
I
guess.
C
The
advantage
of
being
is
that
it
was
developed
by
Ericsson
to
run
their
managed
phone
switches
way
way
back,
and
you
know
late
80s,
so
they
designed
it
specifically
so
that
it
was
distributed
so
that
you
could,
you
know,
perform
service
without
taking
out
an
entire
set
of
phone
calls.
It's
now
is
Ericsson
behind
Erlang
and
elixir.
C
They
are
still
behind
early,
but
not
elixir.
Although
I
guess
the
two
communities
have
a
lot
of
bad
and
have
influenced
each
other,
so
yeah
Erickson
is
still
providing
Erlang
and
updating
it
actively
to
kind
of
meet
modern
CPU,
architectures
yeah,
so
I
mean.
But
what
I
really
like
about
beams
it
just
automatically
will
distribute
tasks
across.
However,
many
quarters
you
have
so
no
I
have
a
thread
repair
in
my
system.
At
the
first
generation
thread
drivers,
so
I
can
use
up
to
32
schedulers.
So
you
know,
I
can
spawn
a
hundred
thousand
tasks.
C
Two
hundred
thousand
tasks
and
it'll
just
distribute
the
load
automatically
across
that
and
process
it
and
very
actively
preempt
each
of
those
operations
so
that
everything
gets
done.
In
short
order,
so
I
mean
the
advantage
of
this
and
sort
of
the
emergent
architecture
that
happens
when,
when
you
start
developing
something
and
elixir
is
that
you
start
developing
processes.
So
very
naturally
you
will
have
you
know:
you'll
have
your
server
process
and
then,
when
your
server
receives
a
connection,
you
don't
want
to
have
your
entire
thread
occupied.
C
C
So
this
is
nice.
Okay,
if
any
of
you
have
ever
done,
IT
support.
You
know
with
application
infrastructure
having
to
update
or
or
even
make
change
to
a
live
operating
system
this
this.
This
is
a
good
way
to
do
it.
It
lets
you
buy
a
compile
code
and
then
push
it
so
that
currently
active
sessions
of
running
the
previous
version
of
the
code
whenever
they
finish
they'll
just
automatically
respawn
up
with
the
brand-new
edition
of
code.
So
that's
kind
of
neat
anyway.
So
that's!
That's
all
the
IT
background
behind
it.
C
Now
what
I've
actually
been
thinking
is
how
to
divide
this
up
kind
of
coming
back
half
the
whole
distribution
question
that
Matt's
been
talking
about
that
in
my
mind,
that
the
way
that
I
sit
is
that
you
have
the
pool,
but
really
what
is
the
pool
the
coolest?
It
is
nothing
more
than
sort
of
like
a
container
or
all
of
the
columns
that
happen
to
be
in
your
in
your
system,
whatever,
whatever
encoding
bit
length,
whatever
encoding
you
have
coming
on.
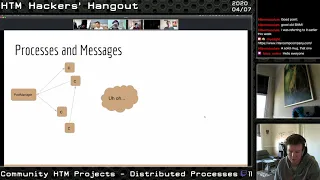
C
Basically,
your
pool
is
managing
that
and
sending
it
off
to
the
columns.
So
that's
the
way
that
I
have
coded
this.
So
when
my
code
starts
up
it,
it
starts
the
pool
the
pool
says:
okay,
I'm
gonna
accept
or
expect
a
certain
encoding
length.
You
know
like
a
hundred
bits
or
a
thousand
bits
whatever
then
on
its
startup,
it
spins
up.
However
many
predetermined
number
of
columns,
then
the
way
that
I've
ever
have
it
written
at
the
moment
is
you
send
in
just
whatever
your
big
encoding
to
it?
C
The
pool
then
distributes
all
of
that
across
all
the
columns
just
broadcast
it
out
wide.
It
says
all
the
columns
here
you
go,
take
it
do
with
it.
What
you
will,
then
each
of
the
columns
will
go
through
they'll
they'll,
do
an
overlap
score
so
based
on
what
they're
distal
connections
are
to
the
input
space
and
what
the
encoded
input
is.
It'll
just
do
a
quick
comparison,
score
saying
how
much
overlap
is
there.
It
will
then
report
that
back
to
the
pool
manager
and
then
the
pool
manager
say
okay.
C
Well,
all
10,000
columns
have
reported
back
in
they
stopped
of
the
average
score
distribution.
I'm
gonna
choose
the
top
60
that
are
above
whatever
threshold.
It
then
keep
in
mind
all
this
is
happening
in
in
parallel.
At
the
same
time,
so
the
column
processes
are
just
chilling
out
there
waiting
for
some
sort
of
message,
so
the
pool
manager
then
sends
a
message
back
out
to
the
winning
columns.
Only
saying
hey,
you've
won,
at
which
point
the
columns
then
look
at
okay.
What
alright?
What
was
then
coding
the
breeder
seeds
based
on
the
overlap?
C
A
D
A
C
So
we're
talking
only
the
spatial
pooling
at
this
moment,
so
I
guess
that
kind
of
brings
us
to.
If
we
go
like
look
at
the
pool
manager
process
that
you
know
that
at
the
moment
we're
talking
about
at
about
step
four
and
then
what
happens
is
that
once
it,
the
pool
manager
said
sends
out
okay
you're
the
winner
message
to
the
columns
it
chooses.
They
then
go
through.
A
C
Essentially,
as
a
key
to
a
map-
and
this
is
just
a
map
of
lists
of
connections-
the
way
that
it
is
keeping
track
of
the
temporal
aspect
of
it-
is
it
when
this
column
winds
so
says:
ok
choose
winning
cell.
At
that
moment,
it
takes
the
previous
time,
steps
winning
winning
column
cell
combinations
and
actually
sends
a
message
to
those
winning
column.
Saying:
hey:
here's
here's
my
column,
ID,
here's,
our
winning
cell
next
time
that
that
your
column
with
this
winning
cell
wins
call
us
yeah.
C
So,
basically,
the
all
of
the
winning
columns
from
time
step.
Minus
one
call
on
the
current
time,
steps
predicted
winning
columns
to
say:
hey
you,
you
might,
you
might
be
firing
right
now,
and
so
basically,
by
by
doing
this,
we
have
you
know
that
you
have
the
pool
and
the
pool
basically
keeps
track
of
who
are
the
winners
at
a
given
time
step
through
the
winners
at
the
previous
time,
step
and
sort
of
coordinating,
choosing
the
winners
and
telling
them
to
strengthen
or
weaken
consequent,
and-
and
it's
works
like
this-
this
works
really
surprisingly.
E
A
C
And
so
it,
and
then
it
was
surprising
so,
okay,
the
setup
that
we
have
here
is
so
ie
X
is
the
sort
of
command-line
interpreter
that
you
pull
up
for
elixir
and
it
really
just
acts
as
a
thin
interface
on
top
of
the
our
lank
interpreter,
and
so
you
call
it
with
IX
dash
X
and
in
a
fast
asked
mix
to
you,
know,
bring
up
your
code
and
you
the
beam
virtual
machine
itself.
Has
this
nice
view
utility
that
you
can
call
using
observer
Dart
that
brings
up
this
nice
QE.
C
C
C
So
you
see
quickly
over
here
that
went
through
it
generated
the
random
initialized
based
on
number
of
parameters
like
connection
space
number
of
connections-
and
you
know
they
created.
You
know
a
basic
list
of
that.
Then
every
column
upon
initialization
will
receive
a
copy
of
this
and
then
randomize
it
for
themselves,
and
so
that's
how
I
deal
with
the
initial
input
encoding
space.
You
know
distribution.
C
So
you
know
that's
neat
so
that
this
means
that
you
know
we
have
our
pool
that
started.
We
have
our
columns
that
aren't
floating
out
there,
and
even
here
we
can
see
our
memory
usage
jumped
up
from
what
had
previously
been
about
50
megabytes
yeah,
that's
a
maybe
400,
gigabytes
total,
and
at
this
point
you
start
seeing
a
little
bit
of
activity
on
the
virtual
machine
across
the
different
schedulers.
C
C
C
This
moment
it
you
just
have
10,000
processes
to
represent
10,000
mini
columns.
Just
chilling
he's
doing
nothing
right
now,
just
waiting
for
some
sort
of
message
so,
for
example
like
if
I
go,
try
to
check
the
state
at
this
moment.
Hey
this
doesn't
crash.
It
should
just
be
a
blank
list
or
it's
you
know
it's
nothing
so
never
mind,
it's
not
updated.
So,
let's
just
send
in
as
a
quick
as
ever.
We
have
the
SD,
our
endpoint,
which
is
sort
of
a
misnomer.
C
It's
just
not
working
doesn't
seem
like
it's:
okay,
okay,
let's
redo
this
AHA
there.
It
is
alright,
so
she
goes
again.
Alright
cool,
so
right
now,
I'm
sitting
in
each
of
these
in
coatings,
and
you
see
sort
of
as
it's
going
through
handling.
You
know
the
server
requests
and
and
parsing
stuff
through,
but
what
I've
been
paying
attention
to
is
the
number
of
seconds
that
it
takes
for
all
of
those
10,000
processes
to
report
back
in.
C
C
It's
pretty
pretty
decent,
and
this
is
just
running
on
a
single
machine.
The
one
thing
I
have
not
tried
yet
is
bringing
up
another
node
on
my
laptop
across
the
room
and
distributing
it
that
way,
but
this
is
this
is
definitely
not
the
most
efficient
way
to
do
it,
for
example,
I'm
using
long
lists,
essentially
tuples
and
basically
I'm
not
doing
it
in
the
most
data
efficient
way.
C
It's
a
pretty
naive
approach
at
the
moment
and
sort
of
yeah
a
lot
of
the
ways
that
I'm
approaching
the
algorithm
were
just
sort
of
quick
and
dirty
shoot-from-the-hip
implementations,
so
there's
definitely
room
to
improve
even
as
well.
Another
thing
that
makes
me
excited
about
it
is
that,
even
though
the
temporal
aspect
of
it
is,
is
it's
nice
it
like
it's
really
nice
if
I
turn
that
off
and
say
I
bump
it
up
to
a
hundred
thousand
or
two
hundred
thousand
mini
columns?
C
Just
so
that
you
know
it
can
learn
the
spatial
aspect
of
it
that
there's
something
it's
taken
about
the
same
amount
of
time
to
do
that,
so
that
that
could
scale
very
easily.
So
what
is
it
we?
That
company
out
there
that's
already
using
SDI
as
as
fingerprints
to
represent
natural
language
processing,
Court
of
Ohio
yeah
court
of
woman
yeah.
C
A
C
A
C
A
C
They're
not
doing
any
temporal
stuff
at
all
as
far
as
I
can
tell.
This
I
feel
like
would
be
a
really
quick
and
dirty
way
if
we
were
to
make
a
homemade
version
of
that,
for
example,
and
then
finally,
it's
kind
of
a
work
in
progress
in
order
to
get
the
pool
state
out
of
it.
It's
just
to
literally
this.
This
sends
back,
but
the
list
of
states
and
serve
concatenating
it
toward
for
the
end
here
all
the
columns,
as
they
report
in
saying,
are
you
active
or
not?
C
C
The
main
thing
I'm
gonna
try
to
put
some
work
into
is
making
it,
making
it
a
little
bit
more
visual
and
perhaps
make
it
so
instead
of
just
doing
raw
URI
parameters,
use
JSON
as
input
and
be
able
to
parse
that
the
other
potential
for
this
by
the
way
is
instead
of
just
having
a
single
pool.
There's
nothing
to
stop
us
from
saying
you
know:
I
I
have
this
one
encoder.
This
type
of
data
so
pool
number
one
is
going
to
be
receiving
FFT
doing
that,
for
example,
pool
number
two
is
going
to
be.
C
You
know
locational
whatever,
whatever
sort
of
concatenated
data
to
you,
you
choose,
so
you
can
start
dividing
up
in
creating
different
pools
to
represent
different
regions
and
again
there
would
be
nothing
actually
stopping
you
from
saying
all
right
across
all
the
pools.
For
this
time
step,
all
the
winners
create
connections
with
each
other.
C
The
other
aspect
of
it
and
serve
what
I'm
intending
it
to
do
is
by
having
a
be
in
sort
of
an
API
format
where
you're
just
making
API
calls
that
you
can
start
getting
more
resource
constrained
devices.
You
know,
like
you
know,
like
ESB
32
or
like
it's
a
simple
little
FPGA
implementation.
You
even
have
all
these.
Instead
of
having
to
do
all
the
processing
on
device,
they
can
just
be
sending
these
API
calls
and
receiving.
You
know
responses
back
to
manage
different
local
state
machines.
So
they're
like
this.
C
This
feels
like
to
me
a
really
decent
way
to
scale
things
but
I'm
more
than
happy
to
be
wrong.
Just
to
make
them
do
better.
You
know,
I
I
was
happy
for
anybody
who
would
want
to
start
tacking
on
this
as
well
and
expanding
it
out,
but
I'm
at
all,
not
married
to
any
particular
aspect
of
other
than
the
fact
that
it
seems
at
least
having
the
pools
and
then
the
columns
and
not
breaking
down
any
further
than
that.
That
seems
to
be
the
most
logical
way
to
go
about
doing
it.
C
The
other
aspect
it
so
the
code
has
changed.
Only
slightly
over
time,
but
on
the
forum
with
this
implementation
of
macro
model,
I
should
probably
created
my
own
separate
thread
to
sort
of
keep
track
of,
like
cerise
gems.
Don't
have
be
spread
about,
but
this
kind
of
is
giving
a
code
view
of
what
is
happening.
What's
calling
what
and
and
how
it's
you
know
lacking
a
little
bit
of
its
detail
and
that
you
know
it's,
it
doesn't
include
any
of
the
temporal
aspect
at
the
moment.
C
For
example,
it's
that's
slightly
out
of
date,
but
I
would
maybe
I'll
just
copy
all
this
and
update
the
readme
in
the
repo
and
then
keep
updated
there.
Yeah
yeah
I
know,
there's
not
a
lot
of
experience.
People
were
using
a
lick,
sir
out
there,
but
I
feel
it's
compelling
enough
that
as
long
as
I
can
make
it
approachable
that
anybody
should
be
getting
to
heck
on
this
if
they
collide
it
so
well,.
A
A
C
A
We're
in
the
engineering
world
here
so
I
think
that
you're
free
to
take
whatever
shortcuts
you
think
work
and
I
think
we're
gonna
find
the
more
we
understand
about
this,
the
more
we
realize
we
can
do
with
it
that
it
wasn't
meant
to
do
just
like
any
new
technology.
You
know
so
yeah
I
would
say,
push
those
boundaries
a
little
bit
and
see
what
happens
when
you
run
into
a
situation
where
wow.
This
is
interesting.
That's
that's
an
indicator
to
move
forward
with
that
thought,
but
I'm.
C
Open
with
this
eye,
I
want
to
potentially
like
it.
If
you
know
once
once
again,
it's
a
little
more
rounded
off
I
do
sort
of
want
to
make
this
into
a
service
just
floating
out
there.
So
you
can
register
your
API
key
start
up
your
pool
and
then
send
stuff
you
know
in
and
out
and
do
with
it
what
you
will
so
if
it
gets
at
that
point,
then
you
know
prevent
to
have
other
conversations.
C
G
C
No,
what
I,
I
gotta
believe
in
this
I
think
this
is
the
way
that
stuff
should
go
as
far
as
scanning
out
I
think
maybe
Martin
might
have
other
ideas
about
the
speed
and
performance
of
it,
but
I'm.
Okay
with
that,
but
the
thing
with
the
lictors
that
it
is
extendable.
You
know
we
can
call
native
code
from
outside.
Of
the
virtual
machine
say
we
have
a
local
implementation,
that's
faster
on
a
specific
hardware,
there's
nothing
to
stop
us
from
using
this
distribution
model
and
calling
that
native
code,
so
cool.
F
F
C
Well,
that's
the
the
beam
virtual
machine.
That's
one
of
the
things
that
I
love
about
is
that
it
kind
of
has
built-in
ideas
for
distribution
already
all
I
need
to
do.
Is
you
know,
open
and
elixir?
You
know
command
line
client
on
my
machine
over
there
make
sure
that
they
had
this
secret
key
and
then
there
they
are.
You
know
they
can
talk
to
each
other
and
distribute
that
way.
H
C
Is
nothing
at
all
the
good
prevent
that
from
happening
with
this,
so
I'd
have
to
make
a
minor
code
modification
with
about
three
lines,
to
be
able
to
generate
multiple
pools,
but
then,
as
far
as
you
know,
the
winning
columns
amongst
those
pools
communicating
with
each
other
and
saying
hey,
set
us
into
a
predictive
state.
There's
nothing
at
all.
Limiting
that
nothing.
A
I
D
J
F
J
Implemented
nah
I
build
for
my
graduation
project.
Now
the
core
design
I
build
that
look.
The
reason
I
build
up
build
Adler
is
because
I
try
to
run
a
reinforcement,
learning
experiment,
experiments
using
HTML
core,
but
it
turns
out
I
have
every
tiny
time
step.
Two
took
me
like
30
seconds
to
simulate,
which
is
a
bit
too
long
for
my
liking,
so
I
rebuilt
the
entire
library
from
sport.
Oh
wait,
I
didn't
show
my
screen
and
what
was.
J
J
D
J
So
that
are
the
reason.
I
feel
that
for
was
because
I
have
to
do.
I
want
to
run
HTM
experiments
for
my
graduation
project,
but
when
I'm
doing
experiments
at
fine
HTML
core
running
way
too
way
too
slow
for
my
liking.
That
I
have
to
every
time
step
took
that
took
about
30
seconds
to
simulate
so
I
rebuild
it.
Our
libraries
on
stage,
which
is
mostly
it,
is
centrally
designed
that
around
that
comes
out
of
10
HTM
Rob
fast
and
as
the
honest.
J
A
J
I
this
deconstruct
me
the
special
Fuller
temporal
memory
operations
into
different
blocks,
so
there's
the
inputs
and
there's
the
cell
activation
and
there's
the
boosting
and
inhibition,
and
also
for
tea
and
foreign
air,
breathers
input
and
other
stuff.
So
these
are
likely
the
tensor
operations
within
the
twisting
formed
frameworks
like
tensor
flow
and
a
torch
so
which
let's
say
you
have
a
it:
an
input,
input,
STR
and
just
and
you
were
on
the
column,
activation
and
inhibition,
or
you
usually
activation
as
a
prediction.
J
This
way
we
can
read
this
way.
We
can.
We
can
write
different
operations,
then
optimize
these
upper
right
upper
upper
operations
individually
to
you
know
just
feel,
stop
faster
and
talking
about
talking
about
hydrogen
tensorflow
sigh
I
just
decided
that
our
problem
probably
deserves
our
good
idea.
So
all
for
my
inputs
are
different,
implemented.
Sensors
there
are
tensor
raise
instead
of
what
we
are
used
to
in
HTM
system
are
sparse,
the
the
early
upside
of
of
a
dense
arrays
Arabic
that
they
are
really
efficient
in
terms
of
CPU
cycles.
J
J
There's
really
not
much
interest
interested
about
brain
work
in
terms
of
the
architecture.
It's
really
just
like
no
hide
fortune
and
serve
well,
but
in
terms
of
distributing
the
different
layers
across
the
different
layers.
Instead
of
what
max
have
done,
and
in
this
data
point
for
next
honest,
you
distribute
every
mini
mini
column
into
different
processes
at
solar.
This
reveals
every
every
layer,
every
special,
polar
or
temporal
memory
into
a
different
different
processor.
So
maybe
my
my
l4
here
runs
on
runs
on
the
CPU.
J
I
can
send
the
out
send
the
output
from
L
alpha
on
the
CPU
tree
l3
on
you
or
FPGA,
or
something
then
every
of
these
blocks
can
be
implemented
a
different
processor.
So,
let's
say
if
we
have
a
eight
GPU
server
or
even
a
server
farm
where
we
can
have
thousands
of
GPUs,
we
could
have
a
layer
run
on
front
of
each
each
GPU
and
just
and
send
all
the
data
across
from
tribute
to
GP
or
server
to
server,
and
the
parallelization
model
is
on
the
other.
Gp
or
CPU
is
really
not
fixed.
J
J
J
J
Encoders
are
scowler
from
our
pure
functions.
They
are
functional,
so
it's
stateless
and
it's
a
lot
more.
Hydrogen
interval
life.
So
we
can
simply
says
the
R
equals
think
folder
with
L
to
B,
and
we
just
give
it
a
random
position
like
1
100
and
it
will
get
Vasa
encode
encoding
of
the
location
and
the
same
for
as
a
spatial
and
temporal
temporal
memory
ended,
simply
say
else:
P
equals.
J
C
I
J
I
J
A
H
J
J
J
Yeah
I
said:
I
want
to
share
start
the
belly
I
see
if
the
IC
development
side
of
stuff,
so
so
one
thing
we
have
been
doing
recently
in
lab
and
research
was
to
try
to
build
a
HTM
paste,
a
celebrate
her
life.
What
people
have
been
doing
for
neural
networks,
which
we
have
been
running
running
to
multiple
problems
and
the
most
important
one
is
there's
this
really?
Is
it
enough
memory
bandwidth
for
running
each
team
on
normal
systems.
J
So
how
do
I
anyway,
one
of
the
most
biggest
bottleneck
we
have
run
into
in
development
at
Fuller?
Was
we
find
that
we
are
running?
We
run
out
of
memory,
bandwidth
really
really
really
fast
and
very
early.
So,
unlike
your
networks,
where
we
have
in
put
image-
and
we
have
output
output
to
something
and
their
ways
are
reducible
in
HT
and
your
synapses
and
permanence
on
are
not
reusable,
so
we
have
to
stream
all
those
data
from
a
memory
constantly
which
uses
up
a
lot
of
memory
bandwidth,
and
so
we
are.
J
J
That's
only
going
to
give
you
a
fraction
of
bandwidth
that
compared
to
what
you
do
mean
so
yeah
we
what
the
biggest
problem
is.
We
don't
have
enough
men
with
any
potential
solutions.
You
just
build
multiple
memory
controllers
onto
your
chip,
but
a
that's
very
expensive,
and
because
memory
controllers
are
expensive
on
their
own,
you
have
to
buy
their
pilot
IP
cores.
You
have
and
they
are
very
large
on
the
chip,
so
the
ships,
but
they
use,
use
up
a
lot
of
your
trip.
Space
and.
J
So
and
because
we
normally
would
prototype
prototype
our
ships
on
FPGAs,
which
you
can
sing
lemma
like
ships
emulators,
where
they
just
they
have
logic
gates
bit
build
on
them,
and
you
can
connect
the
lows.
Those
are
logic
gates
built
whatever
you
want
like
these
stuff,
but
the
problem
with
FEG
is
that
late,
only
normally
only
come
come
with
one
memory
controller
layer.
So
we
can
try
leanette
much
more
memory,
controller
approach.
J
So
without
multiple
memory
controllers
they
will
there
really
isn't
a
good
way
to
accelerate
HTML.
It
took
basically
anything
and-
and
we
have
seen
people
talking
about
early
spike
in
your
network,
accelerators
on
the
forum
somewhere
and
I
need
to
put
out
better,
but
the
the
problem
with
with
building
those
architecture.
Asana
on
the
research
side
is
again,
we
don't
have
enough
memory
bandwidth
so
using
the
the
neuromorphic
architecture.
It
doesn't
help
in
in
this
connect
our
case
out.
Building
HT
and
chips.
J
K
Guess
one
basic
thing
that
may
have
come
up
on
the
forum
before,
because
it's
often
one
of
the
first
things
that
comes
up
when
the
GPU
comes
up
in
the
context
of
HTM
the
you
show
of
a
spatial
cooler
here.
Yes,
that
can
certainly
benefit
from
the
GPU
the
temporal
memory.
Usually
it
has
many
many
cells
like
it
requires
an
enormous
matrix
if
you
have
like,
for
example,
65,000
cells,
mapping
to
65,000
cells,
that
becomes
a
very
big
weight
matrix,
and
so
what's
your
take
on
that?
What's
your
viewpoint
on
that.
J
J
Typically,
you
get
and
at
worst
ten
times
the
year
salary,
less
speed
on
a
GPU
versus
a
CPU,
but
in
the
case
of
HTM
we
only
get
something
around
two
to
three
times,
so
we
have
to
sort
sort
out
like
memory
bandwidth
issue
before
we
can
have
fast
HTN,
but
that
won't.
That
won't
be
the
case
if
we
are
still
using
GPUs
and
CPUs,
but
again
building
custom
chips.
It's
way
way
too
expensive.
You
even
in
academia,.
C
J
J
J
Sorry,
the
very
curious
part
is
a
HTML
core
has
lists
very
weird
performance
trend
where
you
know
it's
floors,
it's
lower
at
about
200
cycle,
2000
bits
and
you
cross
over
some
threshold
and
sudden.
It
goes
faster
and
then
keep
on
going.
Slow,
I,
don't
know
why.
But
this
is
a
very
interesting
observation.
J
J
J
B
K
J
K
J
G
K
J
What
effort
does
when
it
has
a
full
list
of
synapses
it?
You
can
prune
those
synapses
to
periodically,
and
this
is
what
what's
happening.
We
grab
so
I
believe
I
am
Not,
sure
right
now,
I
clean
queenly
synapses
every
something
like
a
hundred
and
fifty
cycles,
I'm,
not
sure
but
yeah
it
clean,
quincy,
synapses
and
you
so
you
and
I
was
usable
space
and
you
can
grow
again.
A
That's
really
impressive,
martin
Congrats
on
on
coming
in
first
with
your
dissertation
and
unless
anyone
else
has
any
comments
or
questions
I,
don't
think
Jordan
K
is
here.
Unless
you
are,
let
me
know
if
you
are
otherwise.
If
anyone
else
has
something
they
would
like
to
present
to
the
community,
please
raise
your
hand
and
twitch.
Sorry,
not
twitch,
zoom
and.
L
L
A
L
J
A
J
L
L
A
A
K
A
K
K
A
L
J
A
A
G
Guys
it's
first
of
all.
Awesome
amazing
work
by
you
guys
so
impressive,
like
really
awesome
to
have
this
meeting
is
a
great
idea.
I
I
didn't
have
a
plan
to
necessarily
share
this,
but
I
was
kind
of
like
all
right.
I've
been
working
on
this
for
like
the
longest
time
and
just
like
super
quick,
so
I
thought,
let's.
G
A
G
G
G
What
I
think
are
hopefully
pretty
good
results
to
show
that
if
you
have
a
bunch
of
basically
that
up
shot
of
it
up
shot
of
it
is,
if
you
have
a
bunch
of
people
play
and
do
like
a
simple
task.
Like
a
generic
task
enough
times,
they
could
start
to
generate,
like
sort
of
like
you
know,
Socratic
patterns
that
you
could
use
too,
especially
if
they're
consistent
to
you
identify
that.
It's
that,
if
you
don't
know
like
who's
playing-
and
you
see
somebody
playing
you
be
like.
G
Oh,
this
looks
like
Matt,
because
Matt
has
a
certain
way
of
generating
sequences
within
the
context
of
this
game.
So
we
could
separate
them
out
from
other
people
that
are
trying
to
do
that
and
there's
certain
people
that
seem
to
it
seems
to
do
a
really
good
job
at
even
with
like
a
really
small
amount
of
data.
G
G
Like
that
yeah
I
think
it
was,
there
was
a
new
mentor
rogue.
There
was
a
project
member
Scott
told
me
about
it
at
one
point
to
like
notice
like
if
somebody
got
up
from
the
computer
and
somebody
else
sat
down,
started
typing
and
you
wouldn't
know
so
so
yeah.
So
it's
it's
a
long,
it's
along
those
lines,
but
yeah.
So
so
anyways
I've
been
like
really
supported
by
Matt
and
a
lot
of
people
for
a
while.
G
Yeah
so
just
wanted
to
say
that,
and
next
we're
gonna
do
workload
assessment
so
like
like
somebody's
doing
a
tasking,
you
want
to
figure
out
in
real
time
like
how
much
effort
are
they
having
to
put
it
and
how
difficult
is
this
for
them?
So
ideas
like
if
they're
being
more
consistent
and
predictable,
then
they're
having
an
easier
time,
if
they're
being
more
chaotic
and
unpredictable
and
having
all
these
high
and
anomoly
scores.
Maybe
they're
like
having
a
harder
time
I'm
so
like
that's
like
the
next
part.
Anyways
thanks.
H
G
Believe
so,
actually,
there's
there's
some
benchmark.
Data
set
that
I
got
I
didn't
actually
haven't,
actually
used
it
yet,
but
there's
benchmarks
for
this
I
actually
had
that
exact
idea
and
I.
Don't
see
why
not
because
you
could
just
encode
it
in
some
kind
of
a
basic
like
XY,
coordinate
space
or
like
two
dimensions,
but
I've
actually
used
that
example
to
describe
this
idea
to
people,
because
I
think
that
would
really
like
show
it
show
it
well
yeah
cuz
like
if
I
were
to
like
for
your
signature.
G
G
Yeah,
so
it
automatically,
because
what
you
do
is
so,
let's
say
you
have
like
40
people
to
play
and
you
have
a
training
set
or
a
learning
set,
basically
for
all
40
of
those
people,
and
then
you
generate
40
different
models,
40
different
new
pick
instances
right,
yeah,
yeah
and
then
and
then
you
have
a
test
set
for
all
those
40
people.
And
then
you
have
a
test
set
like
let's
say
somebody's
playing
you,
it
is
turns
out
to
be
map.
G
You
don't
know
it
could
be
any
of
these
40
people,
you
bounce,
that
test,
set
off
of
all
of
those
40
train
models
and
look
at
the
anomaly
scores
that
come
back
and
if
there's
a
model
that
was
trained
on
mats
up
there
playing,
then
the
idea
is
those
anomalies.
Scores
will
be
lower
from
that
model
because
that
model
is
used
to
seeing
Matt
play
as
opposed
the
model
is
used
as
saying
me
play,
or
you
know,
mark
or
whoever.
G
J
So
this
is
a
bit
of
research
that
I
think
I.
It's
going
nowhere,
so
I
probably
just
share
them
everything.
Hopefully
someone
could
take
it
further
and
you
will
make
it
a
paper.
So
what
what
I've
been
doing
is
I'm
gonna,
Newman,
tirelessly
sparsity
paper
and
sparsity
and
convolution
whenever
paper
I
did
a
bit
of
experimenting
with
sparsity
and
adversarial
attacks.
So
what
I
ended
up
finding
is
well
honest
and
like
a
winner,
algorithm
is
pretty
strong
against
a
quite
a
wide
range
of
attacks
like
ifgf
CF
GSN
with
give
us
thousand
iterations.
J
It
really
can't
break
we
in
our
protected
by
we
can
outwork
them
and
the
other
search
does
just
got
blown
away
and
even
other.
This
even
works
pretty
well
against
other
attacks
like
deep
pool
and
a
single
pixel
attack
and
EAD
attack
on
an
estate
house
ads
using
lean
at
five,
but
not
showing
it
fashion
here,
but
when
they
move
some
to
larger
data
sites
that
they
have
that
like
to
see
partying
or
imagine
yet
and
k
winners
simply
just
doesn't
work
I,
don't
know
why.
J
J
My
gas-
and
this
is
pure
gas,
and
what
I
gather
from
experiments
is
that
what,
when
one
theory
on
how
adversarial
Texas
it
lodges
your
neurons
to
very
high,
very,
very
high
values
or
in
lodges
your
new?
You
write
in
a
weird
pattern
such
that
you're
later
later,
layers
just
doesn't
accurately
predict
stuff.
So
what
K
winner
does
is
it
prevents
Lee
very
button
and
of
the
new
room
from
firing,
so
they
are
not
affected
and
one
thing
you
can
do
to
improve.
J
K
winner
is,
instead
of
just
choosing
top
K,
you
select
the
top
and
to
the
top
plate
top
top
k+
n
in
the
world.
So
you
ignore
the
top
any
rocks.
This
will
slightly
improve
the
protective
performers,
so
it
also
also
preventing
li
new
rounds
was
the
largest
values
to
fire
to
go
on
very
high
values
to
affect
it
exactly
lower
lower
neurons
in
the
lower
layers.
E
M
E
E
J
E
M
M
Here's
the
issue
I
thought
about
for
a
very
long
time
and
I
don't
have
a
solid
solution
for
that
yet
in
mind.
I
want
you
to
quickly
discuss
it.
If
you
use,
if
you
employ
the
standard
approach
classic
approach
and
also
try
to
straightforward
approach,
this
problem
is
not
appearing
because
you
just
wait.
You
just
wait
for
the
results
to
appear
for
every
cycle.
There
is
a
cycle,
but
if
you
distribute
that
workload
there
is
no
cycle
anymore,
there's
just
a
constant
flow
of.
M
Interactions
between
enormous
amount
of
actors
and
they
can
be
on
a
different
nodes
and
here's
the
problem.
If
they
are
on
local
machine,
they
operate
with
one
type
of
latency
local
latency,
an
our
CPU
memory
and
stuff.
If
you
distribute
it
to
the
other
nodes,
there
is
another
type
of
latency,
Network,
latency
and
there's
another
timings
in
different
timings,
and
we
somehow
we
need
to
synchronize
that
said
stuff
to
be
able
to
produce
I,
don't
know
more
or
less
the
reliable
results.
How
will
do
we
fix
it?.
C
C
That
hash
would
ensure
that,
while
the
rest
of
the
pool
has
moved
on
that
incoming
responses
from
perhaps
very
late
in
two
columns
wouldn't
mess
with
anything,
perhaps
even
have
some
sort
of
and
well
okay.
So
in
the
look
and
the
elixir
gen
server
universe,
maybe
have
the
pool
manager
have
a
specific
call,
yeah
specific
call
function
that
says:
here's
here's,
our
current
hash
dipper
on
our
current
timestamp,
the
wrong.
C
So
you
know
at
a
random
interval
and
each
call
and
have
it
check
in
with
the
pool
and
say
hey
where
we
at
and
then
you
know
if
it's
too
far,
behind
it'll
truffle
way,
but
I
tend
to
think
biologically
in
our
brain.
It's
not
like
there's,
no
there's,
no
there's,
no
there's
no
central
operators
like
the
pool
manager.
That's
that's
waiting
patiently
for
everything
to
come
back.
Things
are
just
kind
of
going
when
when
they
go
like
the
neurons
are
firing
when
they,
when
they
reach
their
potential
and
they
they
do
it.
C
So
even
I,
maybe
I'm
mistaken.
But
my
understanding
is
that
even
in
our
brain
there's
a
agency
between
different
parts
and
that
it
doesn't
really
seem
to
matter
other
than
you
know,
those
instances
where
perhaps
we
have
day
job
through
alright
or
so
other
sort
of
other
artifacts
of
even
biological
agency
within
our
brain
as
different
distances
are
firing
within.
H
I,
do
there
is
synchronization
in
the
brain,
the
brain
waves
or
theta
alpha
do
synchronized
entire
areas
and
they
sweep
through
everything
is
based
on
that
as
a
clock.
So
if
you
look
at
some
of
the
data
that
they've
been
gathering
from
imaging
studies,
there's
definitely
synchronization
within
an
area
in
between
areas.
C
H
Where
all
that
that's
the
whole
point
is
it
runs
for
a
tenth
of
a
second
all
right.
You
know
alpha
is
roughly
ten
Hertz,
so
it's
roughly
every
tenth
of
a
second.
Whatever
is
done
is
done
and
that's
this
cycle,
that's
the
current
state
of
the
entire
area
that
can
be
passed
on
to
another
area.
Then
that's
passed
on
with,
depending
on
which
layer
you're
at
to
three
projects
with
long
axons,
five,
six
bounces
through
the
thalamus
and
so
forth,
and
so
on.
But
each
particular
time
step
is
basically
1.
Alpha
cycle.
H
C
F
A
C
H
J
Just
want
to
on
a
subject,
one
thing
that
new
neuromorphic
processors
do
is
that
they
don't
guarantee
that
the
message
will
arrive
and
at
exactly
the
same
same
time
step,
but
they
guarantee
that
the
message
will
arrive
in
a
set
of
nailed
up
time,
let's
say
10
milliseconds
or
10
microseconds,
and
then
they
just
they
simply
say
well.
Each
of
my
turns
them
must
be
larger
than
10
microseconds
and
there
was
it
was
synchronized
automatically
yeah.
This
is
what
chips
and
the
neuromorphic
computers
are
doing.
C
One
is
a
distributor
counter
by
the
way
so
like
right
now,
there's
there's
just
a
single
cool
manager.
That's
receiving
all
the
completion
messages
from
the
columns
essentially,
and
we
could
even
distribute
that
out
so
that
it
isn't
dependent
on
a
single
process
the
tied
up
in
a
single
scheduler
as
well.
So
we
could
reduce
latency
or
this
distributive
lanes.
B
H
Well,
in
your
own
brain,
what
happens
to
is
if
things
happen
within
a
certain
one,
alpha
wave
bucket,
they're,
simultaneous.
There's
an
example
then
that
post
I
have
by
the
link
video
where
they're
talking
about.
If
you're,
watching
somebody
bounce
a
ball
and
they're
walking
away
from
you
and
a
large
arena
at
as
you
watch
them,
you
see
the
ball
synchronized,
it
all
looks
good.
It's
the
same
time
step
because
it
falls
within
the
same
alpha
cycle
when
they
get
a
certain
distance
away.
H
A
A
Yeah
so
market
an
idea.
We
haven't
put
a
lot
of
effort
into
bammy
biological
industry
intelligence
document
for
a
while.
I
haven't
run
this
by
any
of
my
peers
at
the
mint
at
this
point,
but
he
had
an
idea.
Why
don't
we
just
put
it
out
in
the
public
domain
and
wicka
phi
it
and
let
the
community
sort
of
take
over
right.
The
temporal
memory
section,
which
we
haven't
finished
and
I
thought
how
all
of
us
throw
that
ball
and
see
what
happens
so
I
mean
honestly.
Anybody
could
do
that
at
any
time.
A
We
wouldn't
stop
anyone
in
the
community
from
taking
that
content
and
building
it
out
into
a
wiki.
As
far
as
me,
sort
of
getting
that
ball
rolling
on
my
end,
I'm
gonna
I'll
see
what
the
rest
of
the
team
has
to
say
about.
It
I
think
it's
not
a
bad
idea,
because
I
don't
see
us
putting
a
ton
of
energy
into
that
document.
Right
now,.
A
Is
it
anybody
out
I
mean
if
we
did
that?
Would
anyone
be
interested
in
helping
sort
of
bring
take
that
document
to
the
next
level
or
filling
out
the
things
that
are
that
are
not
right?
There's
some
things
are
a
little
bit
wrong.
Bear
I,
don't
know
if
there's
anything
blatantly
wrong,
but
there's
things
that
should
certainly
be
updated
in
it
and
then
there's
complete
chapters
that
are
missing.
I.
H
H
A
A
A
A
That
is
a
it's
a
big
big
problem
that
needs
to
be
worked
out
and
I
think
it
could
lead
to
a
lot
of
advances,
especially
as
Hardware
matures
we'll
be
ready
for
it
when
it
comes
so
appreciate
everybody
and
take
care,
I'm,
gonna,
I'm
gonna
go
ahead
and
end
the
meeting
and
I'll
see
you
guys
on
the
forum.
I,
don't
think
there'll
be
a
research
meeting
tomorrow,
but
next
week
for
sure
alright
take
care
thanks
for
joining
Marcus
and
thanks
everybody
on
twitch
for
joining
and
watching
I
am
I.