►
From YouTube: HTM Forum Q&A - Apr 22, 2019
Description
Broadcasted live on Twitch -- Watch live at https://www.twitch.tv/rhyolight_
A
B
Disillusioned
thanks
for
the
follower
last
week.
Well,
it's
been
two
weeks
now
right,
I'm,
just
catching
up
on
my
forearm
here.
Some
things
I
haven't
read
yet
so
I'll
probably
spend
maybe
an
hour
doing
this,
and
usually
it's
been
a
week.
I
haven't
read
anything
hardly
anything
on
the
forum
for
a
week,
so
I'm
gonna
go
through
and
read
everything
this
person,
Mac
I,
think
has
sort
of
a
newer
user
joined
October.
B
You
can
watch
all
day
in
the
background
I'll
be
on
most
of
the
day.
Honestly.
If
the
research
meeting
doesn't
go
on
very
long,
I
may
just
continue
working
on
some
things.
I
need
to
do
with
with
twitch
I
want
to
work
on
context.
Switching
because
I'm
gonna
have
different
types
of
streams
and
I
want
a
set
of
automation.
B
So
I
can
press
a
button
and
switch
between
like
what
I'm
doing
now
and
a
research
meeting,
because
I'm
just
I
want
to
flow
right
into
it
and
then,
when
research
meeting
ends,
I
may
want
to
switch
to
the
technical
stream
and
I
want
to
have
a
button
to
push
to
just
do
that.
So
I'm
gonna
do
that
so
I,
so
my
streams
will
be
more
fluid,
so
I
might
work
on
that
a
little
bit
today,
okay,
I,
try
to
use
HTM
for
solving.
B
Not
only
detection
system
produces
logs
I
think
it
sounds
familiar
system
work
in
psych
laying
banner
one
process
ends
and
another
same
process
begins:
okay,
okay,
so
he's
got
a
period.
Each
log
contains
a
thousand
samples.
Each
sample
contains
ten
different
features
that
represent
the
current
system.
Mode
categorical
features,
train
the
HTM
on
40,
different
I,
think
he's
I.
Think
I've
talked
to
him
about
this
him/her
I,
don't
know
this
sounds
familiar.
We
I
think
we
had
a
discussion
about
this.
B
A
B
It's
just
no
one's
written
the
code
to
do
it.
I
trying
to
train
an
HTM
model
on
40
different,
valid
logs
first
SP,
then
the
HTM
itself
so
I
understand
that
the
H,
the
SP
is
part
of
the
HTML.
If
you're
training,
it
I,
think
I,
assume
you're,
saying
the
TM,
the
SP
and
then
the
TM,
because
they
really
should
probably
train
together,
but
it
doesn't.
B
B
Try
and
keep
terminology
correct
if
we
can't,
if
everybody
doesn't
agree
on
what
to
call
things,
it
gets
more
complicated.
So,
okay,
the
training
we've
done
after
log
trading,
the
first
one,
then
the
second
epic
and
the
evaluation
phase
I
take
another
hundred
different,
valid
logs
and
apply
on
them.
The
training
HTM
model
an
alton
law
I'm,
not
quite
sure,
so
you
don't
really
have
to
40
different
valid
logs.
B
C
B
Go
down
overall,
as
patterns
are
learned
and
I
agree
with
max
here.
We
definitely
need
me
to
see
data.
Okay,
I'm
gonna,
try!
This
induce
screen
markers
stream,
markers
and
post
snippets
of
this
back
to
the
forum.
I,
don't
know
it
still.
Work
updates
to
neuroscience
audio
I
already
saw
that
Skynet
joke
almost
made
a
Skynet
joke
back
jimmy
traveling
to
the
US
for
conference
first
week
of
June
staying
in
Union,
Square
area
of
San
Francisco.
Oh,
that's,
cool,
okay,
I
need
to
think
I
need
to
hey
Richard
I'm
gonna,
be
in
San
Francisco.
B
C
B
B
B
B
This
one
makes
you
conscious,
but
the
hub
connections
from
temporal
to
prefrontal
lobe.
You
can
see
that
until
Ryan
all
hippocampal
complex,
amygdala,
hypothalamic
clusters,
so
I
mean
I'm
trying
to
learn
the
hypothalamus
stuff.
Now,
in
my
my
brain
coloring
book
I'm
in
the
parts
of
the
the
thalamus
hypothalamic
connections,
area
and.
B
B
C
B
B
Inspect
the
model
instance
and
ensure
it's
an
HTM
finished
model.
So
so
this
is
troubling
me.
So
the
model
is
definitely
an
h2
prediction
model,
but
when
he
runs
when
he
runs
run
the
inference,
the
results
object
that
he's
getting
back.
It
doesn't
have
good
results
in
it:
hello-hello
pi,
2,
3
5.
How
are
you
doing?
I'm,
updating
or
I'm
getting
updated
with
this
forum
that
I
managed
called
HTM
forum
and
people
ask
questions
about
each
team's
there
and
I
answer
them
and
I.
Don't
know
why
this
this
is
so
confusing.
B
B
B
Hello
mark
brown
welcome.
I
was
just
talking
about
you,
I'm,
trying
to
figure
out
why
Freeman
or
Rose
Vaughn
his
this
issue
he's
having
with
model
results.
Why
is
it
even
happening
he's
getting
a
results,
object
back
that
doesn't
have
the
proper
inferences
like
so
I'm,
trying
to
figure
out
why
this
code
looks
familiar
I,
think
I
wrote
it
I
mean
the
for
the
example.
I
know
because
I
hate
this
function,
I
hate
this
function,
it's
okay,
so
the
actual
run
is
in
that
function.
I
believe
right,
yeah.
B
B
B
A
B
B
Question
mark
I,
don't
know
I'm
just
so
confused
there
I'm
gonna
place
this
with
a
red
question.
Fine,
all
right
mark
so
I'm
running
through
of
answering
form,
questions
and
I'm
trying
to
help
people
that
have
questions.
While
I
was
gone,
okay,
good
side
project
from
Derrick
Pinto.
He
used
to
be
a
lot
more.
Oh,
my
god.
This
is
so
cool
I
want.
One
of
these
we've
been
talking
about
making
one
of
these
check
it
out
come
on
play.
It.
C
C
B
You
know
my
HTM
school
video
is
the
temporal
memory,
one
where
I've
got
the
big
block,
you
could
actually
physically
create
that
which
would
be
soon.
We've
talked
about
doing
this
art
installation
in
the
office
with
something
like
this.
They
make
these
cube,
like
things
is
this?
Actually,
you
Derek,
so
this
is
gonna
figure.
This
out
is
that
no.
B
B
B
We,
like
I,
said
we've
talked
about
doing
this
before,
so
there
is
already
a
piece
of
code
that
will
translate
the
state
of
an
HTM.
Basically,
the
SPT
em,
you
know,
SPT
em,
neural
layer
into
3d
coordinates
that
you
could
easily
map
to
something
like
this.
It's
called
high,
brow
and
I
think
it's
even
on
an
HTM
community
project.
B
B
This
isn't
it
agnostic,
so,
like
lewis,
has
implemented
this
in
c-sharp
as
well,
so
that
we
can
do
translations
basically
coordinate
translations
from
an
HTM,
a
structure
representing
an
HTM
layer,
SB
TM
layer,
so
that
it
can
be
based,
basically
exploded
out
into
a
3d
space,
and
you
can
easily
move
it
around
and
stuff,
and
the
state
can
be
reflected
in
that.
So
there's
some
of
the
work.
C
B
B
B
B
B
B
Okay,
eventually
I'd
like
to
form
a
concept
of
operations
for
an
HTM
network
working
on
board,
a
satellite
on
some
telemetry
channels,
which
involves
quantifying
the
memory
requirements
of
high
performing
HTM
networking
a
trade-off
analysis
regarding
performance
and
time
resolution,
number
of
input,
features,
number
of
channels
being
studied,
etc.
It's
complex
appreciate,
advice.
B
Rev,
updated,
I
think
it'd
end
up
being
something
working
along
these
lines.
Oh
okay,
I'm
gonna,
get
to
that
I
think
that's
a
new
topic
and
I'll
get
to
in
a
moment:
Python
3,
pi,
PI
community
fork
namespace.
This
was
in
response
to
a
post
that
I
made
recently
trying
to
figure
out
what
exactly
we're
gonna
call
things,
and
you
know
when
we
pip
install
things
in
Python
3,
so
David.
B
The
main
work
programmers
on
the
nupoc
community
fork
that
may
pick
CPP.
He
says
I'm,
giving
some
thought
to
the
namespace
used
in
the
community
fork
using
HTML
type
I
package
name
is
not
a
problem.
I
was
wondering
if
you
division
this,
to
extend
to
the
directory
names
we
use
in
dot
pi
code
and
C++
code
and
the
names
faces
within
the
code
github
community
rather
than
a
chimp
community.
B
B
Yes,
yes,
yes,
yes,
yes
to
all
these
things
right
in
C++,
using
namespace
HTM,
rather
the
namespace
new
bit.
We
certainly
could
do
that
of
those
what
you
like,
but
it
might
be
quite
confusing
for
people
at
first,
but
in
the
long
run
it
might
be
better
to
use
entirely
separate.
Namespace
is
to
avoid
name
collisions.
What
are
your
thoughts?
B
C
B
B
C
B
Neural
network
rotational
architecture
mirrors
of
many
columns,
I
found
a
paper
on
neural
network
architecture
and
thick
mirrors,
part
of
the
HTM
theory.
If
you
squint,
you
can
see
that
many
columns
grid
cells
work
more
on
rotation
than
adding
or
multiplying,
vector
points
together.
Then
this,
oh
because
this
is
about
rotational
unit
of
memory.
B
Rotational
unit
this
reminds
me
more
of
like
head
head
direction
then,
so,
maybe
you
know
we've
we've
said
you
can
make
the
relationship
right
between
mini
columns
and
grid
cell
modules,
which
then
you
can
make
the
relationship
between
mini
columns
and
orientation
modules,
perhaps
or
head
Direction
modules
or
whatever
so
sure,
I.
Think,
there's,
probably
something
related
here.
I
think
we'll
continued
scrutiny
of
the
experimental
neuroscience
will
help
us
figure
out.
What
exactly
the
relationship
is.
I
think
it's
I
I'm,
not
a
momenta
researcher.
B
I
am
a
community
manager,
but
I
get
to
see
a
lot
of
the
research
and
it
feels
to
me
like
it
would
be
awesome
if
we
could
make
the
whole
mini
column
idea
work
with
the
grid
cell
module
thing.
Oh,
this
has
to
do
with
the
vector
multiplication
in
the
algorithm
space.
Okay.
So
this
is
not
what
I
was
thinking
about.
I
was
just
about
to
read
your
response
mark.
Let
me
try
and
get
read
his
first
I
think
do
I
wonder
if
I
don't
want
to
read
this
paper
right
now.
B
B
B
Okay,
I!
Don't
remember
this!
Oh
yeah
I
do
remember
this.
I
keep
forgetting
to
mark
this,
but
okay,
have
you
tried
to
do
analysis
right
so
I
think
I
was
hoping.
I
could
get
this
person
to
read
about
data
and
coding,
because
I
think
understanding
data
encoding
in
a
temporal
stream
would
kind
of
lead
him
in
the
right
direction.
To
answer
his
other
questions,
Sam
pointed
him
to
some
of
the
papers.
B
B
C
B
B
B
The
way
the
location
vector
is
created
is
not
a
topic
of
the
paper
right.
In
addition,
there's
an
output
layer
that
has
an
arbitrary
representation
for
a
particular
object
which
stays
constant
as
you
explore
the
object
with
your
finger,
but
then
there's
another
paper
type
of
locations
in
the
court.
Neocortex
came
out
later,
which
dispenses
with
dispenses
with
the
output
layer.
B
It
has
a
sensory
layer
and
that
modulates
distal
synapse
on
yes,
yes,
furthermore,
the
location
layer,
this
new
paper
is
made
up
of
several
Bristol
modules,
each
of
which
have
cells
that
connect
to
the
entire
sensory.
Later.
Okay,
yes,
is
my
understanding
correct?
Yes,
it's
good
decent
summary,
I
think
the
second
article
goes
over
the
standard
grid
cell
theory
a
bit
and
says
at
the
very
first
time
that
a
rodent
is
released
into
an
artificial
environment.
Let's
say
a
walled
space
with
various
features
at
different
points,
such
as
a
tree
in
a
stream.
C
B
Don't
know
if
that's
true,
because
it's
I
mean
the
bumps
move,
so
it's
many
bumps
in
specifying
a
location
but
the
but-
and
those
are
random,
looks
like
the
arrangement
of
those
that
grid.
So
the
starting
point,
these
starting
parameters
of
of
that
grid
I
think
is
random.
That's
that's.
What
identifies
a
random
point.
Dammit
I,
keep
forgetting
to
mark
my
stream,
sorry,
so
I
wouldn't
when
I
say
when
you
say
one
bump:
it's
not
like
it's
just
one
bump,
there's
a
it's!
It's
a
bunch
of
bumps
initialized
in
a
random
way.
B
B
B
Anyway,
let
me
try
and
answer
this
question
and
in
the
context
of
the
papers
that
he's
talking
about
each
grid
cell
modules
start
off
with
one
bump
at
around
a
point.
If
that's
true,
then,
if
the
mouse
were
released
for
the
first
time
be
a
different
door
into
the
same
environment
would
start
off
with
the
same
bumps.
If
not,
how
do
you
have
constancy
and
learning
locations
of
features?
So
I
think
that
you
need
to
look
into
place
cells.
B
B
C
B
Enough
suppose,
a
model
based
on
time,
the
old
sequence
model,
where
the
current
vector
makes
predictions
via
modulatory
synapses
on
cells.
Yes,
okay,
the
TM
model,
you
have
learned
a
sequence
of
features:
ABC,
another
sequence
learned
is
EC,
suppose
that
si
is
not
represented
by
a
vector
of
many
many
columns,
but
just
by
one
mini
column.
B
B
So
he's
saying
we
have
a
a
cell
firing
in
a
mini
column
that
represents
E
and
it
might
be
I,
don't
think.
That's
true.
If
there's
a
self,
if
a
Saul
fires
in
that
mini
column,
that
would
be
an
e
another
self
iron
that
min
the
column
would
mean
II
after
a
B
or
C.
Wait,
wait,
wait,
see
sorry
I'm
getting
my
ease
and
C's
and
everything
mixed
up.
So
we
have
a
mini
column,
firing
for
C,
one
of
it
with
this
one
cell.
B
B
B
Mark
says,
submit
column
neurons
map
the
current
access
of
travel
okay,
but
we're
not
talking
about
orientation
here,
I'm
trying
to
answer
this
question
in
context
of
the
papers
that
he's
asking
them
about
why
grid
cells
according
to
the
various
papers,
representations
of
location
are
dimensionless,
but
not
only
that,
but
grid
cells
mean
the
origin
of
the
object.
Being
looked
at
can
be
translated
space,
in
other
words,
recognition
is
very
good
cells,
don't
explain,
orientation,
variance
and
okay
I'm
gonna.
If
the
Y
grid
cells
question
is
because
they
are,
they
are
observed
and
experimental
neuroscience.
B
B
B
B
B
B
Anyway,
I
think
I'm
gonna
leave,
leave
it
at
that
and
I'm
not
gonna
touch
the
other
question
just
because
I
don't
want
to
I
want
to
move
on.
If
you
really
want
to
engage
about
that
specific
question,
let's
start
another
chat
and
the
first
paper
says:
lower
levels
might
not
sense
enough
of
the
environment
to
form
a
model
of
a
big
object,
so
they
learn
parts
of
an
object
like
the
leg
of
an
elephant.
What
happens
at
the
sensory
catch
that
feeds
the
lower-level
strays
to
the
ear
of
an
elephant.
B
Here,
an
elephant
or
in
the
example
of
a
fingertip
I,
don't
know
I'm
gonna,
leave
it
at
that,
and
modeling
should
be
right
with
two
L's
or
one
honestly:
okay,
it'll
it
in
the
latter
model.
Okay,
it's
nine
o'clock
I'm
just
going
to
keep
an
eye
on
my
time
at
ten
o'clock,
I've
got
a
stand-up
meeting,
so
I
need
to
let
you
get
through
this
in
the
later
model
and
if
your
first
encounter
of
an
object,
activates
random
bumps
in
the
grid,
so
modules
in
one
column,
in
your
neocortex.
B
Marcus
commenting
on
this,
the
the
question
is
sort
of
the
wrong
way
to
think
about
this.
We
know
that
the
Isaac
odds
to
different
parts
and
we
build
that
into
an
object.
Yeah,
that's
that's
sort
of
what
I
was
trying
to
think
about.
I
mean
he's
right.
It's
not
like,
like
I,
mean
you're
touching
an
elephant,
your
your
your
fingers
like
skin,
skin
skin
skin.
B
This
feels
like
skin,
but
if
you
move
your
whole
hands
around
it,
it's
you're
getting
a
bigger
picture
of
the
thing
and
and
the
lower
I
think
levels
of
the
sensory
hierarchy
or
continuing
to
model
skin
and
passing
up,
perhaps
a
bunch
of
some
representations
of
a
you're
touching
skin
at
this
orientation
or
something
like
that
to
the
higher
levels
of
the
hierarchy,
which
are
then
saying
seeing
a
bigger
object
based
on
largers.
You
know
in
space
a
sensory
input
in
space.
B
B
And
you
started
off
with
a
random,
random
bumps
and
then
learning
the
object
by
moving
third
space
or
whatever,
five
days
from
now,
when
you
encounter
the
same
object,
you
would
well
okay,
once
you've
learned
an
object,
you
infer
you
you
compare.
Let's
say
this:
you
compare
income
coming
sensory
input
to
it,.
B
You
don't
start
with
the
same
representation,
but
you
end
with
it
by
narrowing
down
STR
unions
through
century
movement
objects
base.
Until
you
are
left
of
the
object,
this
is
sort
of
a
long
question.
You
know
what
I
should
do
is
just
since
I'm
answering
every
one
of
these
and
just
make
this
an
ordered
list.
C
B
B
B
Are
two
layers
interact?
Does
it
interact
they
narrow
down
unions
of
possibilities
with
both
layers?
So
he
sort
of
understands
this.
So
don't
understand
why
you
don't
get
that
question
number
six.
If
you
understand
the
narrowing
down
of
unions,
you
should
understand
that
they
don't
start
off
with
the
same
representation,
but
they
end
up
with
the
same
representation.
B
B
Well,
it's
not
it!
Well.
We
can't
assume
that
the
location
vector
no
so
here's
where
you're
going
on.
We
can't
assume
that
I,
don't
think
so.
I
mean
the
location
vector
does
whatever
the
location
vector
does
and
its
input
to
another
layer
of
cells
in
some
way,
so,
whether
it's
mini
columns
or
not,
or
how
many
many
columns
it
is
or
anything
that
doesn't
matter,
we
should
be
able
to
take
some
portion
of
that
output
and
feed
it
into
a
layer,
not
knowing
anything
about
it,
so
I'm
afraid.
Perhaps
this
is
to
do
this.
C
C
B
B
I,
don't
really
understand
the
question
that
might
it
mean
that
the
first
two
mini
columns
have
narrowed
down,
so
maybe
you're
just
talking
about
what
the
output
represents,
but
but
I
mean
well
I,
I,
don't
necessarily
as
long
as
the
let
me
just
say
this.
As
long
as
the
location
layer
output
is
stable,.
C
B
B
C
C
B
C
B
B
B
C
B
My
inspector
up
and
we'll
see
what
happens:
okay,
okay,
so
now
I
want
to
move
to
this
and
there
it
is
theory
of
how
so
we're
gonna
move
it
there.
And
this
first
question:
everyone
represent
in
hack
a
hierarchical
model,
which
is
at
least
two
sets
of
columns
the
output
of
column
a
in
the
first
okay,
okay.
C
C
B
Because
this
is
all
select
all
and
we're
gonna
move
them
all
to
the
same
place.
Theory
of
that
move.
So
you
guys,
when
you're
posting
a
question
about
a
paper
just
post
it
right
on
the
paper
page.
If
you
can
find
it.
Obviously
this
one
was
hard
because
it
was
named
drunk
so
I.
Don't
blame
you
reading
through
the
paper.
B
It
seems
obvious
to
me
that
the
structure
of
the
input
layer
of
the
column
is
equivalent
to
the
mini
column,
cells
connections,
objects,
undertook
library,
interact
upon
my
standard,
yes
good
and
the
first
set
of
simulations
in
the
input
layer
of
each
column
consists
of
a
hundred
and
fifty
mini
columns
with
16
cells
from
any
column.
A
total
of
2,400
cells.
I
do
not
see,
though,
a
corresponding
data
structure
algorithm
for
the
output
layer
of
the
column,
as
described
in
the
paper
in
the
nupoc
code.
B
B
C
B
After
messing
with
switching
loss,
functions
doesn't
work
well,
oh
yeah.
We
were
just
this
is
from
Sean
they're
talking
about
an
idea
of
running
I,
think
multiple
loss
functions
at
once
and
sort
of
dynamically
switching
between
them,
which
is
an
interesting
idea
and
I
thought.
Somebody
should
have
already
done
that
and
then
Marty
found
out
that
somebody'd
already
done
it.
I
tried
to
put
as
much
as
I
could
about
HTM
into
a
single
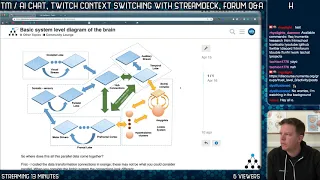
picture.
Let's
look
at
the
picture
by
the
way.
How
do
I
look
at
it?
B
Objects
what
what
what
where
so
I
don't
know
about
this,
so,
okay,
so
the
what
and
the
where
I
would
stay
away
from
that
I.
Don't
there's
not
two
pathways!
So
let
me
just
mention
that
I,
like
the
I
like
the
effort,
but
though
I
don't
think
what
and
where
are
right.
I
would
not
my
first
impression
or
my
first
input
is
that
this
is
all
happening
in
either.
B
What
where
or
both
I
see
you
have
what
and
where
labeled
on
different
layers
and
I,
don't
think
it
works.
That
way.
I
think
that
you're
doing
this,
that
this
process
is
running
in
both
spaces
simultaneously
I
think
that
I
think
this
process
is
running
in
both
spaces
simultaneously
l2
and
3
might
be
yeah
eventually,
they'll
probably
will
have
to
be
split
out,
but
I,
don't
know
enough
to
say
anything
about
it.
Honestly,.
B
Ok
did
I
already:
oh,
hey,
Brad,
hello,
Brad.
First,
oh
hi
I
suddenly
went
down
the
HTM
encoding
with
great
codes,
rabbit
hole
about
a
month
ago
and
ended
up
here.
I
haven't
looked
at
this,
yet
this
sim
I
saw
it,
but
I
haven't
I'm
gonna
come
back
to
that
and
mark
you're
explaining
gray
code
I,
don't
really
know
what
gray
code
is.
What
is
great
good,
reflected
binary
code?
Oh
I,
think
I
know
what
that
is.
B
B
B
Yeah
far,
as
the
Oki
is
concerned
about
the
number
of
columns
required
to
code
for
colors
brain
deals
with
problem
the
code
of
colors
at
a
much
lower
spatial
resolution
than
for
brightness,
yes,
absolutely,
for
example,
in
the
old
NTSC
color
television
standards,
the
color
was
added
as
a
second
lower
resolution
stream.
That
was
face
coded
to
indicate
what
color
tints
should
be
added
to
the
luminance
information.
B
I'm
gonna
I'm
gonna
do
this
a
community
helper,
I
love,
I
love
this
mark
I,
don't
know
where
you
got
this,
but
it's
cool.
It
explains
it
really!
Well,
okay,
let's
go
to
this
some
hash
distributed
scalar
encoder
and
try
and
understand
it.
A
locality-sensitive
hashing
approach
towards
encoding
semantic
data
and
to
STRs
ready
to
be
fed.
Did
you
make?
Did
you
make
this
like
this
looks
very
well-documented,
I'm.
B
B
This
silhouette,
this
reminds
me
of
the
geospatial
or
the
coordinate
encoder.
You
know,
I,
don't
know
these
sim
hash
algorithm
quickly,
estimating
how
similar
two
sets
are
used
by
Google
crawler
to
find
near
duplicate
pages,
okay
and
there's
a
paper
which
I'm
not
going
to
read
right
now.
This
encoder
is
sibling
with
the
original
scalar
encoder
and
the
RDS
see
the
static
bucketing
strategy
here
is
generally
lifted
straight
from
the
RDS
see.
B
B
B
B
This
is
a
custom
random
map
and
this
is
using
sim
has
for
that,
and
this
is
physical
adjacency
a
period
wrapping
yes,
but
not
on
the
RDS
see,
but
you
can
wrap
so
you
could
use
the
sim
hash
encoder
to
create
cyclic,
encoders,
okay
and
we'll
get
to
doing
working
with
cyclic
encoders
on
on
my
building
HTM
system
stream.
If
you
look
at
my
events,
page.
B
So
you
can't
do
a
lookup
table,
but
that
that
would
be
useful
for
would
that
be
useful
for
decoding
topology,
no
required
parameters,
resolution
other
parameters
bucket
radius
of
periodic,
okay
cool,
so
it's
it
can
be
periodic,
which
is
a
bonus.
Scalar,
encoder
performance,
comparison
test
or
run,
and
the
nupoc
docks
algorithm
tutorial.
B
Okay,
so
it
whoops
the
usual
hot
gem.
Data
was
used
for
three
thousand
rows.
Okay,
so
we're
just
doing
coding,
speed,
okay,
so
men
so
0
to
100
or
we're
doing
the
our
DSC
with
a
different
resolution,
maybe
a
rmse.
So
these
are
our
values
and
times.
I
don't
know
these
well
enough
to
know
how
how
comparable
these
are.
But
I'm
assuming
that
brett
has
been
diligent
about
this,
so
it's
a
little
slower.
B
Okay,
how
it
works
step,
one
input,
some
scalar
values,
blah
blah
blah
blah
map;
two
buckets
map,
input,
values,
two
bucket
indices,
using
the
formula
from
our
DSC,
and
this
is
sort
of
our
random
yeah
based
on
resolution
sort
of
starting
point
right.
So
then
we
have
buckets
and
hash
the
bucket
index
hash,
bucket
index
value
of
a
target
bucket
and
neighbors;
okay,
so
you
hash
the
bucket
and
its
neighbors,
so
say
we're
targeting
three,
so
we're
gonna
get
the
hashes
for
it
and
its
neighbors.
B
B
Into
negative
ones,
and
then
the
summed
weighted
binary
columns,
hash
column
summations.
So
this
is
column
1.
This
is
negative
3.
This
is
column.
2
is
1
right.
Is
that
right,
negative
1,
there's
2
negative
1
0
when
I
go
to
1,
0
and
negative
1
0,
and
that's
0,
something
something
I'm
wrong
about
that
so
bucket
3.
So,
oh,
oh
we're
summing
them
like,
like
that
yeah
I,
guess
so
yeah.
B
B
So
then,
we're
going
to
add
up
all
the
columns
collapse.
Integer
sums
back
to
binary
collapse.
The
sums
back
to
binary
for
the
final
step,
hash
value
for
our
target
bucket,
a
regular
sip
hash,
will
change
all
sums
greater
than
0
to
a
binary
1,
while
all
sums
less
than
0
change
to
binary
0.
That's
assumed
hatchway,
usually
results
in
about
50%
sparsity,
interesting.
B
B
B
I'm
gonna
give
an
awesome,
give
an
awesome
for
that
cool.
Well,
it
looks
like
what
you
might
use
this,
for
is,
if
you
want
a
periodic
encoder,
a
scalar
encoder
that
you
don't
have
to
specify
min
and
Max.
So
what
I'm,
seeing
here
my
favorite
thing
at
least
is
this:
it
can.
It
can
be
periodic
and
you
can
give
it
a
resolution
instead
of
a
min
and
Max,
which
is
the
good
thing
about
the
random
distributed
encoder.
Is
you
don't
have
to
worry
about
min
and
Max
as
sort
of
self
expands,
but
you
can't
loop.
C
B
Can
so
that's
cool,
that's
very
cool,
so
it's
a
good
point.
The
Mac
is
and
on
this
coder
is
interesting.
If
I
understand
correctly,
the
goal
is
to
greatly
increase
the
radius
of
the
encoding
so
to
have
a
nonlinear
semantic
similarity.
Oh
I
didn't
even
realize
that
that's
true,
you
could
do
that
so
d-mac
wrote
the
unit
tests
for
the
RDS
see
they
check
for
semantic
similarity
by
running
through
a
range
of
values,
measuring
the
overlap
between
consecutive
output.
Okay,
okay.
B
Don't
bother
yes
good.
The
adaptive
scalar
coder
is
obsoleted
by
the
RDS.
See
yes,
I
would
recommend
against
using
a
cryptographic
hash
function.
It's
not
critical,
but
here
are
some
potential
issues,
time
consuming
to
compute,
typically
seeded
with
random
numbers.
Okay,
very
cool.
Thanks
to
the
reply,
the
goal
is
really
to
exact
same
as
the
RDS.
You
just
accomplished
it
with
a
different
method
by
tuning
some
of
the
parameter
encoder
parameters.
One
could
maybe
accomplish
something
like
you
have
in
your
graphic,
but
it
was
not
a
goal.
C
C
B
C
B
The
catastrophic
forgetting
thing
are
there
any
good
tests
that
I
can
run
in
Python
to
check
if
a
network
has
overcome
catastrophic,
forgetting
lots
of
papers,
but
I
don't
see
a
database
to
check
on
I
might
have
said
something
similar
if
I
trying
to
get
a
spatial
puller
to
learn
all
the
Unicode,
oh
I
set
up
a
regular
PI
torch
autoencoder
with
one
hidden
layer
and
then
added
boosting
and
k
winners
to
the
middle
of
it
to
make
it
sparse.
Yes,
we
talked
about
that.
This
ended
up.
B
Selecting
different
neurons
for
representing
different
inputs,
so
Chinese,
like
inputs,
would
always
select
the
Chaney's
neurons
and
emoji,
like
inputs,
would
always
select
the
emoji
neurons.
There
would
be
some
variations
for
other
neurons
to
cover,
however,
that
doesn't
mean
it
completely
overcome
this
catastrophic,
forgetting
it
could.
Quite,
it
could
never
quite
recognize
all
the
letters
I
can
see
it
retraining,
even
after
hours
and
hours
of
training,
smoothly,
moving
from
one
character
to
the
actual
input,
but
I
could
see
that
I
could
see
many
different
classes
of
characters.
B
B
So
I
think
it
would
be
similarly
more
robust
to
catastrophic
forgetting
Paul,
says
I
know.
The
original
question
was
about
temporal
memory,
but
it's
probably
worth
mentioning
that
there
is
a
difference
between
the
team
algorithm
and
the
SP
algorithm,
which
is
probably
pretty
relevant
here
in
SP,
each
mini
column,
trains,
a
single
segment.
This
increased
increases
the
chances
of
things
being
forgotten
when
the
same
segments
are
retrained
on
some
new
input,
each
mini
column,
trains
on
a
single
segment
right
right
right.
B
B
B
Relative
coordinate,
encoder,
woke
up
thinking
about
the
coordinate
coder
and
what
it
would
mean
if
the
squares
were
relative
to
a
particular
point
rather
than
objectively
laid
out.
As
an
example.
Imagine
an
owner
who
put
a
smart
tag
on
her
pet,
which
could
track
along
Google
Maps.
That's
how
the
current
coordinate
coder
might
work,
but
what?
If
the.
B
But
what,
if
the
tag
sent
its
location
relative
to
the
owners
phone
that
might
still
need
to
be
an
effectively
finite
plane,
but
a
specific
square
in
the
encoder
doesn't
equate
to
a
fixed
Maps
grid.
I
can
imagine
a
lot
of
scenarios.
We're
tracking
an
object
relative
to
a
reference
point
would
be
useful.
I
do
not
think
there's.
There
are
necessarily
practical
implications
of
using
the
existing
chord
encoder
for
this
purpose.
It's
just
using
relative
XY
values
instead
of
absolute
instead
I'm
curious
of
the
community.
B
C
B
B
Almost
almost
misunderstood,
behavior,
okay.
This
was
just
in
response
to
what
I
just
did
I.
Think
you
mean
yes,
he'd
catch
me.
The
anomaly
score
should
go
down.
Overall,
his
patterns
are
like
the
anomaly
scores
received
in
the
validity
phase.
That
means
I
finished
a
train.
The
SP
at
TM
and
I
received
a
high
anomaly
score
in
the
same
position
in
the
validity
after
I
finished
to
training
the
model
on
valid
logs
I.
Don't
underst
so
I,
don't
understand
the
phases
of
your
training.