14 Jan 2022
Matthai Philipose from Microsoft speaks about the work his team did in partnership with OctoML for flexible, bulk video analysis (millions of hours of video and billions of images analyzed per month). At this large scale, inference is a significant portion of the total compute cost and the team is working to make inference super-efficient. Microsoft ran experiments to optimize key ML models with TVM, varying input size, batching and processor targets and compared the inference throughput against the production baseline. The results showed 1.2 - 3x higher throughput typically when optimizing with TVM. Microsoft is now planning on moving TVM optimized models into production.
- - -
Recorded at TVMCon (https://www.tvmcon.org), the Machine Learning Acceleration Conference in Dec 2021.
TVMCon covers the state of the art of deep learning compilation and optimization, with a range of tutorials, research talks, case studies, and industry presentations. We discuss recent advances in ML frameworks, compilers, systems and architecture support, security, training and hardware acceleration.
Connect with us for the latest in ML Acceleration and Deployment:
Website: https://octoml.ai
LinkedIn: https://www.linkedin.com/company/octoml
Twitter: https://twitter.com/OctoML
- - -
Recorded at TVMCon (https://www.tvmcon.org), the Machine Learning Acceleration Conference in Dec 2021.
TVMCon covers the state of the art of deep learning compilation and optimization, with a range of tutorials, research talks, case studies, and industry presentations. We discuss recent advances in ML frameworks, compilers, systems and architecture support, security, training and hardware acceleration.
Connect with us for the latest in ML Acceleration and Deployment:
Website: https://octoml.ai
LinkedIn: https://www.linkedin.com/company/octoml
Twitter: https://twitter.com/OctoML
- 1 participant
- 6 minutes

12 Jan 2022
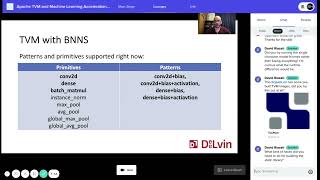
Goal is to demonstrate an importance of BYOS on BNNS example. The main reason of it is private extension called AMX which is not available for public LLVM compiler. This talk will show how BNNS was integrated into TVM and performance result leading from that.
Outline:
- Intro: BYOS overview. Goals and abilities.
- BNNS vs codegen. Why BNNS performance is unreachable through llvm code generation. Apple AMX instruction extension.
- Current state of BNNS support as BYOS integration in TVM. How it can be utilized.
- Performance comparison for some popular topologies (Resnet, Mobilenet and others).
- Why codegen still beats BNNS for some combination of parameters/shapes. Reasons. “Best of both worlds” approach.
- Effect of additional threading. Does it make sense? Performance evaluation of parallel execution of BNNS.
- Conclusions.
This session is split into two parts, a 20 minute talk and a 10 minute community breakout session.
Speaker: Alexander Peskov
- - -
Recorded at TVMCon (https://www.tvmcon.org), the Machine Learning Acceleration Conference in Dec 2021.
TVMCon covers the state of the art of deep learning compilation and optimization, with a range of tutorials, research talks, case studies, and industry presentations. We discuss recent advances in ML frameworks, compilers, systems and architecture support, security, training and hardware acceleration.
Connect with us for the latest in ML Acceleration and Deployment:
Website: https://octoml.ai
LinkedIn: https://www.linkedin.com/company/octoml
Twitter: https://twitter.com/OctoML
Outline:
- Intro: BYOS overview. Goals and abilities.
- BNNS vs codegen. Why BNNS performance is unreachable through llvm code generation. Apple AMX instruction extension.
- Current state of BNNS support as BYOS integration in TVM. How it can be utilized.
- Performance comparison for some popular topologies (Resnet, Mobilenet and others).
- Why codegen still beats BNNS for some combination of parameters/shapes. Reasons. “Best of both worlds” approach.
- Effect of additional threading. Does it make sense? Performance evaluation of parallel execution of BNNS.
- Conclusions.
This session is split into two parts, a 20 minute talk and a 10 minute community breakout session.
Speaker: Alexander Peskov
- - -
Recorded at TVMCon (https://www.tvmcon.org), the Machine Learning Acceleration Conference in Dec 2021.
TVMCon covers the state of the art of deep learning compilation and optimization, with a range of tutorials, research talks, case studies, and industry presentations. We discuss recent advances in ML frameworks, compilers, systems and architecture support, security, training and hardware acceleration.
Connect with us for the latest in ML Acceleration and Deployment:
Website: https://octoml.ai
LinkedIn: https://www.linkedin.com/company/octoml
Twitter: https://twitter.com/OctoML
- 2 participants
- 26 minutes
12 Jan 2022
In recent years, auto tuning has been used to accelerate operators in AI compilers. But there are several limitations in auto tuning methods. For example, the results of auto tuning are usually worse than vendor libraries on real-world industrial online models; Also, the tuning time are super long, it could take hours to days to tune the performance of an end-to-end model inference on the GPU. In this talk we will talk about how we address the limitations brought by auto tuning. By integrating CUTLASS into TVM, we can now generate kernels with performance comparable to state-of-the-art manual written vendor closed-source libraries, (cublas and cudnn) without extensive tuning on Nvidia GPUs. At the same time, it can do more aggressive graph-level optimizations compared with existing AI compiler systems. The first part of the talk will be introducing CUTLASS and the second part of the talk will be illustrating how we integrate it into TVM.
This session is broken into two parts, a 20 minute talk and a 10 minute community breakout session.
Speakers: Leyuan Wang, Andrew Kerr
- - -
Recorded at TVMCon (https://www.tvmcon.org), the Machine Learning Acceleration Conference in Dec 2021.
TVMCon covers the state of the art of deep learning compilation and optimization, with a range of tutorials, research talks, case studies, and industry presentations. We discuss recent advances in ML frameworks, compilers, systems and architecture support, security, training and hardware acceleration.
Connect with us for the latest in ML Acceleration and Deployment:
Website: https://octoml.ai
LinkedIn: https://www.linkedin.com/company/octoml
Twitter: https://twitter.com/OctoML
This session is broken into two parts, a 20 minute talk and a 10 minute community breakout session.
Speakers: Leyuan Wang, Andrew Kerr
- - -
Recorded at TVMCon (https://www.tvmcon.org), the Machine Learning Acceleration Conference in Dec 2021.
TVMCon covers the state of the art of deep learning compilation and optimization, with a range of tutorials, research talks, case studies, and industry presentations. We discuss recent advances in ML frameworks, compilers, systems and architecture support, security, training and hardware acceleration.
Connect with us for the latest in ML Acceleration and Deployment:
Website: https://octoml.ai
LinkedIn: https://www.linkedin.com/company/octoml
Twitter: https://twitter.com/OctoML
- 5 participants
- 29 minutes
12 Jan 2022
We present the goals and the main ideas behind the implementation of a new pass that performs Common Subexpression Elimination (CSE) for TIR. This pass identifies redundant computations (subexpressions) and replaces them by new variables, thus avoiding the overhead of performing the same computation multiple times.
Generated code like TIR often contains some duplicated computations and can benefit well from a CSE pass.
In addition, the implementation is modular in several directions: in particular, it is easy to modify the criteria which selects which computations get introduced into variables. It is also easy to extend the pass for identifying and commoning semantically equivalent computations instead of only syntactically equal ones.
This session is broken into to parts, a 20 minute talk followed by a 5 minute breakout session.
Speaker: Franck Slama
- - -
Recorded at TVMCon (https://www.tvmcon.org), the Machine Learning Acceleration Conference in Dec 2021.
TVMCon covers the state of the art of deep learning compilation and optimization, with a range of tutorials, research talks, case studies, and industry presentations. We discuss recent advances in ML frameworks, compilers, systems and architecture support, security, training and hardware acceleration.
Connect with us for the latest in ML Acceleration and Deployment:
Website: https://octoml.ai
LinkedIn: https://www.linkedin.com/company/octoml
Twitter: https://twitter.com/OctoML
Generated code like TIR often contains some duplicated computations and can benefit well from a CSE pass.
In addition, the implementation is modular in several directions: in particular, it is easy to modify the criteria which selects which computations get introduced into variables. It is also easy to extend the pass for identifying and commoning semantically equivalent computations instead of only syntactically equal ones.
This session is broken into to parts, a 20 minute talk followed by a 5 minute breakout session.
Speaker: Franck Slama
- - -
Recorded at TVMCon (https://www.tvmcon.org), the Machine Learning Acceleration Conference in Dec 2021.
TVMCon covers the state of the art of deep learning compilation and optimization, with a range of tutorials, research talks, case studies, and industry presentations. We discuss recent advances in ML frameworks, compilers, systems and architecture support, security, training and hardware acceleration.
Connect with us for the latest in ML Acceleration and Deployment:
Website: https://octoml.ai
LinkedIn: https://www.linkedin.com/company/octoml
Twitter: https://twitter.com/OctoML
- 1 participant
- 23 minutes

12 Jan 2022
We observe that the key challenge faced by existing auto-schedulers when handling a dynamic-shape workload is that they cannot construct a unified search space for all the possible shapes of the workload, because their search space is shape-dependent. To address this, we propose DietCode, a new auto-scheduler framework that efficiently supports dynamic-shape workloads by constructing a shape-generic search space and cost model. Under this construction, all shapes jointly search within the same space and update the same cost model when auto-scheduling, which is therefore more efficient compared with existing auto-schedulers.
This session is broken into two parts: a 10 minute talk followed by a 5 minute breakout session.
Speakers: Bojian Zheng, Ziheng Jiang
- - -
Recorded at TVMCon (https://www.tvmcon.org), the Machine Learning Acceleration Conference in Dec 2021.
TVMCon covers the state of the art of deep learning compilation and optimization, with a range of tutorials, research talks, case studies, and industry presentations. We discuss recent advances in ML frameworks, compilers, systems and architecture support, security, training and hardware acceleration.
Connect with us for the latest in ML Acceleration and Deployment:
Website: https://octoml.ai
LinkedIn: https://www.linkedin.com/company/octoml
Twitter: https://twitter.com/OctoML
This session is broken into two parts: a 10 minute talk followed by a 5 minute breakout session.
Speakers: Bojian Zheng, Ziheng Jiang
- - -
Recorded at TVMCon (https://www.tvmcon.org), the Machine Learning Acceleration Conference in Dec 2021.
TVMCon covers the state of the art of deep learning compilation and optimization, with a range of tutorials, research talks, case studies, and industry presentations. We discuss recent advances in ML frameworks, compilers, systems and architecture support, security, training and hardware acceleration.
Connect with us for the latest in ML Acceleration and Deployment:
Website: https://octoml.ai
LinkedIn: https://www.linkedin.com/company/octoml
Twitter: https://twitter.com/OctoML
- 1 participant
- 10 minutes
12 Jan 2022
In this session we discuss to use the automatic FP16 quantization in TVM. We talk about some of the benefits from using the features and when and how to use this feature in TVM. At the end we showcase a demo demonstrating model speedup.
This session is split into two parts, a 20 minute talk and a 10 minute community breakout session.
Speaker: Andrew Luo
- - -
Recorded at TVMCon (https://www.tvmcon.org), the Machine Learning Acceleration Conference in Dec 2021.
TVMCon covers the state of the art of deep learning compilation and optimization, with a range of tutorials, research talks, case studies, and industry presentations. We discuss recent advances in ML frameworks, compilers, systems and architecture support, security, training and hardware acceleration.
Connect with us for the latest in ML Acceleration and Deployment:
Website: https://octoml.ai
LinkedIn: https://www.linkedin.com/company/octoml
Twitter: https://twitter.com/OctoML
This session is split into two parts, a 20 minute talk and a 10 minute community breakout session.
Speaker: Andrew Luo
- - -
Recorded at TVMCon (https://www.tvmcon.org), the Machine Learning Acceleration Conference in Dec 2021.
TVMCon covers the state of the art of deep learning compilation and optimization, with a range of tutorials, research talks, case studies, and industry presentations. We discuss recent advances in ML frameworks, compilers, systems and architecture support, security, training and hardware acceleration.
Connect with us for the latest in ML Acceleration and Deployment:
Website: https://octoml.ai
LinkedIn: https://www.linkedin.com/company/octoml
Twitter: https://twitter.com/OctoML
- 2 participants
- 23 minutes
12 Jan 2022
Over the past year I’ve been spending about 20% of my time driving efforts to improve developer-facing parts of TVM, like the Jenkins CI, docker scripts, and pytest infrastructure. In 2022, OctoML plans to invest more heavily to improve the TVM developer experience. In this talk, I’ll discuss the progress made over the past year and some future plans for 2022.
This session is broken into two sections, a 20 minute talk and a 10 minute community breakout session.
Speaker: Andrew Reusch
- - -
Recorded at TVMCon (https://www.tvmcon.org), the Machine Learning Acceleration Conference in Dec 2021.
TVMCon covers the state of the art of deep learning compilation and optimization, with a range of tutorials, research talks, case studies, and industry presentations. We discuss recent advances in ML frameworks, compilers, systems and architecture support, security, training and hardware acceleration.
Connect with us for the latest in ML Acceleration and Deployment:
Website: https://octoml.ai
LinkedIn: https://www.linkedin.com/company/octoml
Twitter: https://twitter.com/OctoML
This session is broken into two sections, a 20 minute talk and a 10 minute community breakout session.
Speaker: Andrew Reusch
- - -
Recorded at TVMCon (https://www.tvmcon.org), the Machine Learning Acceleration Conference in Dec 2021.
TVMCon covers the state of the art of deep learning compilation and optimization, with a range of tutorials, research talks, case studies, and industry presentations. We discuss recent advances in ML frameworks, compilers, systems and architecture support, security, training and hardware acceleration.
Connect with us for the latest in ML Acceleration and Deployment:
Website: https://octoml.ai
LinkedIn: https://www.linkedin.com/company/octoml
Twitter: https://twitter.com/OctoML
- 3 participants
- 30 minutes

12 Jan 2022
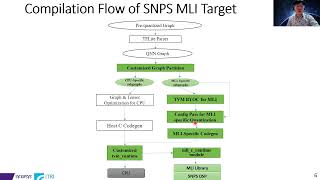
The Synopsys embARC Machine Learning Inference (MLI) library provides software functions optimized for DSP-enhanced ARC EV, ARC EMxD, and ARC HS4xD processors. It enables ARC customers to efficiently develop or port data processing algorithms based on machine learning (ML) principles. Synopsys is collaborating with ITRI to develop a TVM-based NN compiler to translate the neural network model into codes that can be executed on Synopsys ARC processors. In this talk, we discuss how we integrate embARC MLI library and Synopsys DSP into TVM via Bring Your Own Codegen (BYOC) and QNN framework.
This session will be broken into two parts, a 20 minute talk followed by a 10 minute breakout session.
Presenting organizations: Industrial Technology Research Institute, Synopsys
Speakers: Kuen-Wey Lin, David Wang, Chuck Pilkington
- - -
Recorded at TVMCon (https://www.tvmcon.org), the Machine Learning Acceleration Conference in Dec 2021.
TVMCon covers the state of the art of deep learning compilation and optimization, with a range of tutorials, research talks, case studies, and industry presentations. We discuss recent advances in ML frameworks, compilers, systems and architecture support, security, training and hardware acceleration.
Connect with us for the latest in ML Acceleration and Deployment:
Website: https://octoml.ai
LinkedIn: https://www.linkedin.com/company/octoml
Twitter: https://twitter.com/OctoML
This session will be broken into two parts, a 20 minute talk followed by a 10 minute breakout session.
Presenting organizations: Industrial Technology Research Institute, Synopsys
Speakers: Kuen-Wey Lin, David Wang, Chuck Pilkington
- - -
Recorded at TVMCon (https://www.tvmcon.org), the Machine Learning Acceleration Conference in Dec 2021.
TVMCon covers the state of the art of deep learning compilation and optimization, with a range of tutorials, research talks, case studies, and industry presentations. We discuss recent advances in ML frameworks, compilers, systems and architecture support, security, training and hardware acceleration.
Connect with us for the latest in ML Acceleration and Deployment:
Website: https://octoml.ai
LinkedIn: https://www.linkedin.com/company/octoml
Twitter: https://twitter.com/OctoML
- 1 participant
- 22 minutes
12 Jan 2022
TVM has made it a lot easier to port deep learning frameworks for new hardware backends but developers still need to fine tune performance for their specific hardware. This requires the identification of performance bottlenecks which can only be achieved with help from reliable profiling tools. The debug graph executor is very useful for coarse grained function level information. However, in most cases, that’s not sufficient and leaves developers looking for detailed finer-grained loop level information. We are working on a TIR pass that instruments the code with a new builtin which can be used to enable profiling. The profiling mechanism we have developed enables function and loop level profiling and allows hardware targets to collect processor-specific performance metrics. The talk will describe the design and implementation of this generalized profiling mechanism. We will also present the techniques used to reduce profiling overhead on storage-constrained embedded processors.
This session is split into two parts, a 20 minute talk and a 10 minute community discussion.
Speaker: Jyotsna Verma
- - -
Recorded at TVMCon (https://www.tvmcon.org), the Machine Learning Acceleration Conference in Dec 2021.
TVMCon covers the state of the art of deep learning compilation and optimization, with a range of tutorials, research talks, case studies, and industry presentations. We discuss recent advances in ML frameworks, compilers, systems and architecture support, security, training and hardware acceleration.
Connect with us for the latest in ML Acceleration and Deployment:
Website: https://octoml.ai
LinkedIn: https://www.linkedin.com/company/octoml
Twitter: https://twitter.com/OctoML
This session is split into two parts, a 20 minute talk and a 10 minute community discussion.
Speaker: Jyotsna Verma
- - -
Recorded at TVMCon (https://www.tvmcon.org), the Machine Learning Acceleration Conference in Dec 2021.
TVMCon covers the state of the art of deep learning compilation and optimization, with a range of tutorials, research talks, case studies, and industry presentations. We discuss recent advances in ML frameworks, compilers, systems and architecture support, security, training and hardware acceleration.
Connect with us for the latest in ML Acceleration and Deployment:
Website: https://octoml.ai
LinkedIn: https://www.linkedin.com/company/octoml
Twitter: https://twitter.com/OctoML
- 5 participants
- 29 minutes

12 Jan 2022
00:00 - Introduction to Lightning Talks - by Zachary Tatlock
00:41 - Tensorization with MLIR - by Liangfu Chen @amazonwebservices
07:24 - Automatic Tensorized Program Optimization - by Bohan Hou @cmu
14:33 - Tsunami: Training in TVM with Relay - by Altan Haan @Octo-AI
19:33 - R-TVM, a polyhedral mapper for TVM - by Benoit Meister @ Reservoir Labs
25:33 - Fuzing TVM Relay - by Steven Lyubomirsky @universityofwashington
33:16 - RoofTune: Accelerating the Tuning Process Based on Roofline Model - by Hui Zhong @ Beihang University
40:35 - SONAR: Direct architecture and system optimization search - by Elias Jaasaari @cmu
48:04 - Collage: Automated Integration of Deep Learning Backends - by Byungsoo Jeon @cmu
56:11 - The CoRa Tensor Compiler: Compilation for Ragged Tensors with Minimal Padding - by Pratik Fegade @cmu
1:02:47 - Multi-stream Support for Virtual Machine Executor - by Yaoyao Ding @uoft
- - -
Recorded at TVMCon (https://www.tvmcon.org), the Machine Learning Acceleration Conference in Dec 2021.
TVMCon covers the state of the art of deep learning compilation and optimization, with a range of tutorials, research talks, case studies, and industry presentations. We discuss recent advances in ML frameworks, compilers, systems and architecture support, security, training and hardware acceleration.
Connect with us for the latest in ML Acceleration and Deployment:
Website: https://octoml.ai
LinkedIn: https://www.linkedin.com/company/octoml
Twitter: https://twitter.com/OctoML
00:41 - Tensorization with MLIR - by Liangfu Chen @amazonwebservices
07:24 - Automatic Tensorized Program Optimization - by Bohan Hou @cmu
14:33 - Tsunami: Training in TVM with Relay - by Altan Haan @Octo-AI
19:33 - R-TVM, a polyhedral mapper for TVM - by Benoit Meister @ Reservoir Labs
25:33 - Fuzing TVM Relay - by Steven Lyubomirsky @universityofwashington
33:16 - RoofTune: Accelerating the Tuning Process Based on Roofline Model - by Hui Zhong @ Beihang University
40:35 - SONAR: Direct architecture and system optimization search - by Elias Jaasaari @cmu
48:04 - Collage: Automated Integration of Deep Learning Backends - by Byungsoo Jeon @cmu
56:11 - The CoRa Tensor Compiler: Compilation for Ragged Tensors with Minimal Padding - by Pratik Fegade @cmu
1:02:47 - Multi-stream Support for Virtual Machine Executor - by Yaoyao Ding @uoft
- - -
Recorded at TVMCon (https://www.tvmcon.org), the Machine Learning Acceleration Conference in Dec 2021.
TVMCon covers the state of the art of deep learning compilation and optimization, with a range of tutorials, research talks, case studies, and industry presentations. We discuss recent advances in ML frameworks, compilers, systems and architecture support, security, training and hardware acceleration.
Connect with us for the latest in ML Acceleration and Deployment:
Website: https://octoml.ai
LinkedIn: https://www.linkedin.com/company/octoml
Twitter: https://twitter.com/OctoML
- 11 participants
- 1:12 hours

12 Jan 2022
00:00 - Introduction to Lightning Talks - by Zachary Tatlock @universityofwashington
00:32 - Extremely Fast GEMM on AVX512 CPUs Combining TVM and XSMM - by Honglin Zhu @ Tencent AI Lab
06:50 - A Simulation-Based TVM Extension for Auto-Tuning in the Early Design Phases - by Yannick Braatz @boschglobal
14:22 - Leveraging TVM as a front-end compiler for RISC-V based custom tinyML processor - by Vaibhav Verma @universityofvirginia
22:02 - Integrate TVM With MediaTek NeuroPilot for Mobile Devices - by Chun-Ping Chung @mediatek
28:46 - Caffe-SSD Inference on Edge Device Using TVM and Hybrid Script - by Masahiro Hiramori @MitsubishiElectricChannel
35:35 - Support sparse and irregular workloads in TIR - by Zihao Ye @universityofwashington
42:13 - Optimization with TVM Hybrid OP on RISC-V with P Extension - by Jenq-Kuen Lee @ National Tsing Hua University
49:16 - Integer Only Quantization and Pruning of Transformers - by Amir Gholami, Sehoon Kim @UCBerkeley
54:42 - Another Automatic Kernel Generator on Huawei NPU with Polyhedral Compilation - by Shenghu Jiang @ Beihang University
1:01:22 - Extending auto-scheduler to support performance evaluation with timing model - by Minchun Liao @National Tsing Hua University
1:07:56 - TVM at Qualcomm Adreno by Siva Rama Krishna @qualcomm
- - -
Recorded at TVMCon (https://www.tvmcon.org), the Machine Learning Acceleration Conference in Dec 2021.
TVMCon covers the state of the art of deep learning compilation and optimization, with a range of tutorials, research talks, case studies, and industry presentations. We discuss recent advances in ML frameworks, compilers, systems and architecture support, security, training and hardware acceleration.
Connect with us for the latest in ML Acceleration and Deployment:
Website: https://octoml.ai
LinkedIn: https://www.linkedin.com/company/octoml
Twitter: https://twitter.com/OctoML
00:32 - Extremely Fast GEMM on AVX512 CPUs Combining TVM and XSMM - by Honglin Zhu @ Tencent AI Lab
06:50 - A Simulation-Based TVM Extension for Auto-Tuning in the Early Design Phases - by Yannick Braatz @boschglobal
14:22 - Leveraging TVM as a front-end compiler for RISC-V based custom tinyML processor - by Vaibhav Verma @universityofvirginia
22:02 - Integrate TVM With MediaTek NeuroPilot for Mobile Devices - by Chun-Ping Chung @mediatek
28:46 - Caffe-SSD Inference on Edge Device Using TVM and Hybrid Script - by Masahiro Hiramori @MitsubishiElectricChannel
35:35 - Support sparse and irregular workloads in TIR - by Zihao Ye @universityofwashington
42:13 - Optimization with TVM Hybrid OP on RISC-V with P Extension - by Jenq-Kuen Lee @ National Tsing Hua University
49:16 - Integer Only Quantization and Pruning of Transformers - by Amir Gholami, Sehoon Kim @UCBerkeley
54:42 - Another Automatic Kernel Generator on Huawei NPU with Polyhedral Compilation - by Shenghu Jiang @ Beihang University
1:01:22 - Extending auto-scheduler to support performance evaluation with timing model - by Minchun Liao @National Tsing Hua University
1:07:56 - TVM at Qualcomm Adreno by Siva Rama Krishna @qualcomm
- - -
Recorded at TVMCon (https://www.tvmcon.org), the Machine Learning Acceleration Conference in Dec 2021.
TVMCon covers the state of the art of deep learning compilation and optimization, with a range of tutorials, research talks, case studies, and industry presentations. We discuss recent advances in ML frameworks, compilers, systems and architecture support, security, training and hardware acceleration.
Connect with us for the latest in ML Acceleration and Deployment:
Website: https://octoml.ai
LinkedIn: https://www.linkedin.com/company/octoml
Twitter: https://twitter.com/OctoML
- 18 participants
- 1:16 hours

12 Jan 2022
We will present a new approach to scheduling machine learning models called ‘cascading’. Cascading is a form of inter-operator scheduling that can significantly reduce the working memory requirements of a model, allowing big models to run on tiny devices. It can also improve performance for memory-bound processors such as NPUs. In this talk, we’ll cover:
- What cascading is and how it works
- Why TVM is a great compiler framework for exploring cascading
- How we at Arm leveraged this technique when compiling for our Arm® Ethos™-U NPU
This session is broken into two parts, a 20 minute talk followed by a 10 minute community breakout session.
Speaker: Matthew Barrett
- - -
Recorded at TVMCon (https://www.tvmcon.org), the Machine Learning Acceleration Conference in Dec 2021.
TVMCon covers the state of the art of deep learning compilation and optimization, with a range of tutorials, research talks, case studies, and industry presentations. We discuss recent advances in ML frameworks, compilers, systems and architecture support, security, training and hardware acceleration.
Connect with us for the latest in ML Acceleration and Deployment:
Website: https://octoml.ai
LinkedIn: https://www.linkedin.com/company/octoml
Twitter: https://twitter.com/OctoML
- What cascading is and how it works
- Why TVM is a great compiler framework for exploring cascading
- How we at Arm leveraged this technique when compiling for our Arm® Ethos™-U NPU
This session is broken into two parts, a 20 minute talk followed by a 10 minute community breakout session.
Speaker: Matthew Barrett
- - -
Recorded at TVMCon (https://www.tvmcon.org), the Machine Learning Acceleration Conference in Dec 2021.
TVMCon covers the state of the art of deep learning compilation and optimization, with a range of tutorials, research talks, case studies, and industry presentations. We discuss recent advances in ML frameworks, compilers, systems and architecture support, security, training and hardware acceleration.
Connect with us for the latest in ML Acceleration and Deployment:
Website: https://octoml.ai
LinkedIn: https://www.linkedin.com/company/octoml
Twitter: https://twitter.com/OctoML
- 3 participants
- 27 minutes

12 Jan 2022
RAZOR is a library that bridges PyTorch and TVM. Currently users have to make substantial changes to their existing PyTorch training scripts in order to convert it to a TVM model. Built upon PyTorch Lazy Tensor, RAZOR aims to provide smooth user experience by running PyTorch training scripts on TVM with little (2-3 lines) or no code change. It allows users to benefit from the performance boost and heterogeneous backends supported by TVM while retaining the PyTorch imperative programming experience.
This session is broken into two parts, a 10 minute talk followed by a 5 minute breakout session.
Speaker: Haozheng Fan
- - -
Recorded at TVMCon (https://www.tvmcon.org), the Machine Learning Acceleration Conference in Dec 2021.
TVMCon covers the state of the art of deep learning compilation and optimization, with a range of tutorials, research talks, case studies, and industry presentations. We discuss recent advances in ML frameworks, compilers, systems and architecture support, security, training and hardware acceleration.
Connect with us for the latest in ML Acceleration and Deployment:
Website: https://octoml.ai
LinkedIn: https://www.linkedin.com/company/octoml
Twitter: https://twitter.com/OctoML
This session is broken into two parts, a 10 minute talk followed by a 5 minute breakout session.
Speaker: Haozheng Fan
- - -
Recorded at TVMCon (https://www.tvmcon.org), the Machine Learning Acceleration Conference in Dec 2021.
TVMCon covers the state of the art of deep learning compilation and optimization, with a range of tutorials, research talks, case studies, and industry presentations. We discuss recent advances in ML frameworks, compilers, systems and architecture support, security, training and hardware acceleration.
Connect with us for the latest in ML Acceleration and Deployment:
Website: https://octoml.ai
LinkedIn: https://www.linkedin.com/company/octoml
Twitter: https://twitter.com/OctoML
- 1 participant
- 11 minutes

12 Jan 2022
Over the course of 2021, we’ve made some exceptional improvements to the user experience on embedded devices. Let’s look back at the improvements we’ve made and the impact they’ve had: switching to AoT and reducing flash usage, reducing the stack usage of TVM in microcontrollers, improving performance with CMSIS NN and building out a workflow with TVMC to allow integrating your model into an embedded application.
Speaker: Chris Sidebottom
- - -
Recorded at TVMCon (https://www.tvmcon.org), the Machine Learning Acceleration Conference in Dec 2021.
TVMCon covers the state of the art of deep learning compilation and optimization, with a range of tutorials, research talks, case studies, and industry presentations. We discuss recent advances in ML frameworks, compilers, systems and architecture support, security, training and hardware acceleration.
Connect with us for the latest in ML Acceleration and Deployment:
Website: https://octoml.ai
LinkedIn: https://www.linkedin.com/company/octoml
Twitter: https://twitter.com/OctoML
Speaker: Chris Sidebottom
- - -
Recorded at TVMCon (https://www.tvmcon.org), the Machine Learning Acceleration Conference in Dec 2021.
TVMCon covers the state of the art of deep learning compilation and optimization, with a range of tutorials, research talks, case studies, and industry presentations. We discuss recent advances in ML frameworks, compilers, systems and architecture support, security, training and hardware acceleration.
Connect with us for the latest in ML Acceleration and Deployment:
Website: https://octoml.ai
LinkedIn: https://www.linkedin.com/company/octoml
Twitter: https://twitter.com/OctoML
- 4 participants
- 28 minutes

12 Jan 2022
Join the Apache TVM Community for an open discussion on the new TVM Unity initiative.
00:29 - Introduction to discussion
01:06 - TVM Unity Q&A by Tianqi Chen, Jared Roesch and Denise Kutnick @Octo-AI
- - -
Recorded at TVMCon (https://www.tvmcon.org), the Machine Learning Acceleration Conference in Dec 2021.
TVMCon covers the state of the art of deep learning compilation and optimization, with a range of tutorials, research talks, case studies, and industry presentations. We discuss recent advances in ML frameworks, compilers, systems and architecture support, security, training and hardware acceleration.
Connect with us for the latest in ML Acceleration and Deployment:
Website: https://octoml.ai
LinkedIn: https://www.linkedin.com/company/octoml
Twitter: https://twitter.com/OctoML
00:29 - Introduction to discussion
01:06 - TVM Unity Q&A by Tianqi Chen, Jared Roesch and Denise Kutnick @Octo-AI
- - -
Recorded at TVMCon (https://www.tvmcon.org), the Machine Learning Acceleration Conference in Dec 2021.
TVMCon covers the state of the art of deep learning compilation and optimization, with a range of tutorials, research talks, case studies, and industry presentations. We discuss recent advances in ML frameworks, compilers, systems and architecture support, security, training and hardware acceleration.
Connect with us for the latest in ML Acceleration and Deployment:
Website: https://octoml.ai
LinkedIn: https://www.linkedin.com/company/octoml
Twitter: https://twitter.com/OctoML
- 9 participants
- 32 minutes

12 Jan 2022
We accelerate PFNN (Phase-Functioned Neural Network) with TVM. The PFNN algorithm dynamically interpolates weights according to status of the game characters, which is not well supported by most neural network inference libraries. Therefore we reinterpret the compute equations and leverage TVM to implement a fast inference method for PFNN. Our methods show overwhelming performance advantage over traditional BLAS libraries.
This session is split into two parts, a 20 minute talk and a 10 minute community breakout session.
Speaker: Haidong Lan
- - -
Recorded at TVMCon (https://www.tvmcon.org), the Machine Learning Acceleration Conference in Dec 2021.
TVMCon covers the state of the art of deep learning compilation and optimization, with a range of tutorials, research talks, case studies, and industry presentations. We discuss recent advances in ML frameworks, compilers, systems and architecture support, security, training and hardware acceleration.
Connect with us for the latest in ML Acceleration and Deployment:
Website: https://octoml.ai
LinkedIn: https://www.linkedin.com/company/octoml
Twitter: https://twitter.com/OctoML
This session is split into two parts, a 20 minute talk and a 10 minute community breakout session.
Speaker: Haidong Lan
- - -
Recorded at TVMCon (https://www.tvmcon.org), the Machine Learning Acceleration Conference in Dec 2021.
TVMCon covers the state of the art of deep learning compilation and optimization, with a range of tutorials, research talks, case studies, and industry presentations. We discuss recent advances in ML frameworks, compilers, systems and architecture support, security, training and hardware acceleration.
Connect with us for the latest in ML Acceleration and Deployment:
Website: https://octoml.ai
LinkedIn: https://www.linkedin.com/company/octoml
Twitter: https://twitter.com/OctoML
- 3 participants
- 29 minutes
12 Jan 2022
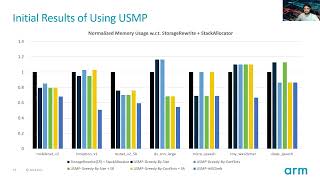
Modern systems that run Machine Learning (ML) workloads have a wide spectrum of devices, from smaller micro-controllers to bigger System-on-Chip (SoCs). The scale of memory present in the devices will determine not only how performant the execution is going to be, but also whether the device could execute the ML workload at all (especially in micro-controllers). We introduce the Unified “Static” Memory Planner (USMP), a comprehensive solution that can ensure memory for tensors that are used within the operators (intra-operator tensors) and between the operators (inter-operator tensors) utilise the least amount of device memory. Additionally, USMP enables the compiler to pool tensors to differently sized memory pools, allowing for intermediary data tensors and constant tensors to be placed on different memory “homes” as specified by the user.
This session is broken into two parts, a 20 minute talk followed by a 10 minute community breakout session.
Speakers: Manupa Karunaratne, Dmitriy Smirnov
- - -
Recorded at TVMCon (https://www.tvmcon.org), the Machine Learning Acceleration Conference in Dec 2021.
TVMCon covers the state of the art of deep learning compilation and optimization, with a range of tutorials, research talks, case studies, and industry presentations. We discuss recent advances in ML frameworks, compilers, systems and architecture support, security, training and hardware acceleration.
Connect with us for the latest in ML Acceleration and Deployment:
Website: https://octoml.ai
LinkedIn: https://www.linkedin.com/company/octoml
Twitter: https://twitter.com/OctoML
This session is broken into two parts, a 20 minute talk followed by a 10 minute community breakout session.
Speakers: Manupa Karunaratne, Dmitriy Smirnov
- - -
Recorded at TVMCon (https://www.tvmcon.org), the Machine Learning Acceleration Conference in Dec 2021.
TVMCon covers the state of the art of deep learning compilation and optimization, with a range of tutorials, research talks, case studies, and industry presentations. We discuss recent advances in ML frameworks, compilers, systems and architecture support, security, training and hardware acceleration.
Connect with us for the latest in ML Acceleration and Deployment:
Website: https://octoml.ai
LinkedIn: https://www.linkedin.com/company/octoml
Twitter: https://twitter.com/OctoML
- 2 participants
- 15 minutes
12 Jan 2022
We have enhanced VTA to enable a larger design space and greater workload support.
Fully pipelined ALU and GEMM units are added to VTA tsim, and memory width can now range between 8-64 bytes. ISA encoding is relaxed to support larger scratchpads. New instructions are added: 8-bit ALU multiplication for depthwise convolution, load with variable pad values for max pooling, and a clip opcode for common ResNet patterns. Additional layer support and better double buffering is also present.
A big performance gain is seen just with fully pipelined ALU/GEMM: ~4.9x fewer cycles with minimal area change to run ResNet-18. Configs featuring a further ~11.5x decrease in cycle count at a cost of ~12x more area are possible. 10s of points on the area-performance pareto curve are shown, balancing execution unit sizing, memory width, and scratchpad size. Finally, VTA is now able to run Mobilenet 1.0 and all ResNet layers.
All features are in open-source forks, some already have been upstreamed.
Presenting Organization: Intel Labs
Speaker: Abhijit Davare
- - -
Recorded at TVMCon (https://www.tvmcon.org), the Machine Learning Acceleration Conference in Dec 2021.
TVMCon covers the state of the art of deep learning compilation and optimization, with a range of tutorials, research talks, case studies, and industry presentations. We discuss recent advances in ML frameworks, compilers, systems and architecture support, security, training and hardware acceleration.
Connect with us for the latest in ML Acceleration and Deployment:
Website: https://octoml.ai
LinkedIn: https://www.linkedin.com/company/octoml
Twitter: https://twitter.com/OctoML
Fully pipelined ALU and GEMM units are added to VTA tsim, and memory width can now range between 8-64 bytes. ISA encoding is relaxed to support larger scratchpads. New instructions are added: 8-bit ALU multiplication for depthwise convolution, load with variable pad values for max pooling, and a clip opcode for common ResNet patterns. Additional layer support and better double buffering is also present.
A big performance gain is seen just with fully pipelined ALU/GEMM: ~4.9x fewer cycles with minimal area change to run ResNet-18. Configs featuring a further ~11.5x decrease in cycle count at a cost of ~12x more area are possible. 10s of points on the area-performance pareto curve are shown, balancing execution unit sizing, memory width, and scratchpad size. Finally, VTA is now able to run Mobilenet 1.0 and all ResNet layers.
All features are in open-source forks, some already have been upstreamed.
Presenting Organization: Intel Labs
Speaker: Abhijit Davare
- - -
Recorded at TVMCon (https://www.tvmcon.org), the Machine Learning Acceleration Conference in Dec 2021.
TVMCon covers the state of the art of deep learning compilation and optimization, with a range of tutorials, research talks, case studies, and industry presentations. We discuss recent advances in ML frameworks, compilers, systems and architecture support, security, training and hardware acceleration.
Connect with us for the latest in ML Acceleration and Deployment:
Website: https://octoml.ai
LinkedIn: https://www.linkedin.com/company/octoml
Twitter: https://twitter.com/OctoML
- 3 participants
- 26 minutes

10 Jan 2022
Recorded at the fourth annual TVMCon, the day one keynote announces TVM Unity, a vision and roadmap for the machine learning hardware and software ecosystem in 2022. New hardware accelerators are emerging with new levels of capability and performance, but harnessing them will require fluid collaboration between data scientists, ML engineers and hardware vendors. TVM will evolve in the coming year to break down the boundaries that constrain the ways current ML systems adapt to rapid changes in ML model architectures and the accelerators that implement them.
Presenters: Tianqi Chen, Jared Roesch, Denise Kutnick
++ Contents ++
00:00 - Apache TVM Community Vision and Update - by Jared Roesch
03:28 - TVM Unity: Technical Vision - by Tianqi Chen
17:24 - Unity Today - by Jared Roesch
29:13 - Unity and the Community - by Denise Kutnick
38:28 - Q&A with the speakers - by Tianqi Chen, Jared Roesch, Denise Kutnick and Matt Welsh
- - -
Recorded at TVMCon (https://www.tvmcon.org), the Machine Learning Acceleration Conference in Dec 2021.
TVMCon covers the state of the art of deep learning compilation and optimization, with a range of tutorials, research talks, case studies, and industry presentations. We discuss recent advances in ML frameworks, compilers, systems and architecture support, security, training and hardware acceleration.
Connect with us for the latest in ML Acceleration and Deployment:
Website: https://octoml.ai
LinkedIn: https://www.linkedin.com/company/octoml
Twitter: https://twitter.com/OctoML
Presenters: Tianqi Chen, Jared Roesch, Denise Kutnick
++ Contents ++
00:00 - Apache TVM Community Vision and Update - by Jared Roesch
03:28 - TVM Unity: Technical Vision - by Tianqi Chen
17:24 - Unity Today - by Jared Roesch
29:13 - Unity and the Community - by Denise Kutnick
38:28 - Q&A with the speakers - by Tianqi Chen, Jared Roesch, Denise Kutnick and Matt Welsh
- - -
Recorded at TVMCon (https://www.tvmcon.org), the Machine Learning Acceleration Conference in Dec 2021.
TVMCon covers the state of the art of deep learning compilation and optimization, with a range of tutorials, research talks, case studies, and industry presentations. We discuss recent advances in ML frameworks, compilers, systems and architecture support, security, training and hardware acceleration.
Connect with us for the latest in ML Acceleration and Deployment:
Website: https://octoml.ai
LinkedIn: https://www.linkedin.com/company/octoml
Twitter: https://twitter.com/OctoML
- 4 participants
- 48 minutes

10 Jan 2022
This tutorial, the first of four in a series introducing new developers to Apache TVM, will walk new developers through the code base and give a general overview of the TVM project.
Speaker: Josh Fromm (OctoML)
- - -
Recorded at TVMCon (https://www.tvmcon.org), the Machine Learning Acceleration Conference in Dec 2021.
TVMCon covers the state of the art of deep learning compilation and optimization, with a range of tutorials, research talks, case studies, and industry presentations. We discuss recent advances in ML frameworks, compilers, systems and architecture support, security, training and hardware acceleration.
Connect with us for the latest in ML Acceleration and Deployment:
Website: https://octoml.ai
LinkedIn: https://www.linkedin.com/company/octoml
Twitter: https://twitter.com/OctoML
Speaker: Josh Fromm (OctoML)
- - -
Recorded at TVMCon (https://www.tvmcon.org), the Machine Learning Acceleration Conference in Dec 2021.
TVMCon covers the state of the art of deep learning compilation and optimization, with a range of tutorials, research talks, case studies, and industry presentations. We discuss recent advances in ML frameworks, compilers, systems and architecture support, security, training and hardware acceleration.
Connect with us for the latest in ML Acceleration and Deployment:
Website: https://octoml.ai
LinkedIn: https://www.linkedin.com/company/octoml
Twitter: https://twitter.com/OctoML
- 2 participants
- 34 minutes
10 Jan 2022
This second tutorial for new developers will show how new coverage support can be added to one of TVMs deep learning language frontends.
Speaker: Josh Fromm (OctoML)
- - -
Recorded at TVMCon (https://www.tvmcon.org), the Machine Learning Acceleration Conference in Dec 2021.
TVMCon covers the state of the art of deep learning compilation and optimization, with a range of tutorials, research talks, case studies, and industry presentations. We discuss recent advances in ML frameworks, compilers, systems and architecture support, security, training and hardware acceleration.
Connect with us for the latest in ML Acceleration and Deployment:
Website: https://octoml.ai
LinkedIn: https://www.linkedin.com/company/octoml
Twitter: https://twitter.com/OctoML
Speaker: Josh Fromm (OctoML)
- - -
Recorded at TVMCon (https://www.tvmcon.org), the Machine Learning Acceleration Conference in Dec 2021.
TVMCon covers the state of the art of deep learning compilation and optimization, with a range of tutorials, research talks, case studies, and industry presentations. We discuss recent advances in ML frameworks, compilers, systems and architecture support, security, training and hardware acceleration.
Connect with us for the latest in ML Acceleration and Deployment:
Website: https://octoml.ai
LinkedIn: https://www.linkedin.com/company/octoml
Twitter: https://twitter.com/OctoML
- 4 participants
- 24 minutes

10 Jan 2022
This third tutorial in the TVM Developer Bootcamp gives quick tutorial showing how to adding a new operator to Relay and TVM.
Speaker: Josh Fromm (OctoML)
- - -
Recorded at TVMCon (https://www.tvmcon.org), the Machine Learning Acceleration Conference in Dec 2021.
TVMCon covers the state of the art of deep learning compilation and optimization, with a range of tutorials, research talks, case studies, and industry presentations. We discuss recent advances in ML frameworks, compilers, systems and architecture support, security, training and hardware acceleration.
Connect with us for the latest in ML Acceleration and Deployment:
Website: https://octoml.ai
LinkedIn: https://www.linkedin.com/company/octoml
Twitter: https://twitter.com/OctoML
Speaker: Josh Fromm (OctoML)
- - -
Recorded at TVMCon (https://www.tvmcon.org), the Machine Learning Acceleration Conference in Dec 2021.
TVMCon covers the state of the art of deep learning compilation and optimization, with a range of tutorials, research talks, case studies, and industry presentations. We discuss recent advances in ML frameworks, compilers, systems and architecture support, security, training and hardware acceleration.
Connect with us for the latest in ML Acceleration and Deployment:
Website: https://octoml.ai
LinkedIn: https://www.linkedin.com/company/octoml
Twitter: https://twitter.com/OctoML
- 3 participants
- 32 minutes

10 Jan 2022
This final TVM Developer Bootcamp session covers how create a new backend for TVM. For each platform that TVM targets, TVM must generate and submit target-specific code for that platform. While large portions of TVM only require general properties of the physical hardware and target platform, these low-level code generators and runtime interfaces must interact directly with the hardware- and platform-specific API. This tutorial will show the interface between target-specific portions of TVM, and is intended for developers who may extend hardware support.
Speaker: Eric Lunderberg (OctoML)
- - -
Recorded at TVMCon (https://www.tvmcon.org), the Machine Learning Acceleration Conference in Dec 2021.
TVMCon covers the state of the art of deep learning compilation and optimization, with a range of tutorials, research talks, case studies, and industry presentations. We discuss recent advances in ML frameworks, compilers, systems and architecture support, security, training and hardware acceleration.
Connect with us for the latest in ML Acceleration and Deployment:
Website: https://octoml.ai
LinkedIn: https://www.linkedin.com/company/octoml
Twitter: https://twitter.com/OctoML
Speaker: Eric Lunderberg (OctoML)
- - -
Recorded at TVMCon (https://www.tvmcon.org), the Machine Learning Acceleration Conference in Dec 2021.
TVMCon covers the state of the art of deep learning compilation and optimization, with a range of tutorials, research talks, case studies, and industry presentations. We discuss recent advances in ML frameworks, compilers, systems and architecture support, security, training and hardware acceleration.
Connect with us for the latest in ML Acceleration and Deployment:
Website: https://octoml.ai
LinkedIn: https://www.linkedin.com/company/octoml
Twitter: https://twitter.com/OctoML
- 2 participants
- 45 minutes

10 Jan 2022
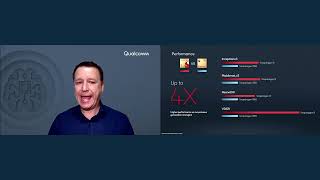
SPEAKERS: Jeff Gehlhaar
--
TVM For Snapdragon Mobile Platform
- - -
Recorded at TVMCon (https://www.tvmcon.org), the Machine Learning Acceleration Conference in Dec 2021.
TVMCon covers the state of the art of deep learning compilation and optimization, with a range of tutorials, research talks, case studies, and industry presentations. We discuss recent advances in ML frameworks, compilers, systems and architecture support, security, training and hardware acceleration.
Connect with us for the latest in ML Acceleration and Deployment:
Website: https://octoml.ai
LinkedIn: https://www.linkedin.com/company/octoml
Twitter: https://twitter.com/OctoML
--
TVM For Snapdragon Mobile Platform
- - -
Recorded at TVMCon (https://www.tvmcon.org), the Machine Learning Acceleration Conference in Dec 2021.
TVMCon covers the state of the art of deep learning compilation and optimization, with a range of tutorials, research talks, case studies, and industry presentations. We discuss recent advances in ML frameworks, compilers, systems and architecture support, security, training and hardware acceleration.
Connect with us for the latest in ML Acceleration and Deployment:
Website: https://octoml.ai
LinkedIn: https://www.linkedin.com/company/octoml
Twitter: https://twitter.com/OctoML
- 2 participants
- 15 minutes
10 Jan 2022
SPEAKER: Steve Roddy
- - -
Recorded at TVMCon (https://www.tvmcon.org), the Machine Learning Acceleration Conference in Dec 2021.
TVMCon covers the state of the art of deep learning compilation and optimization, with a range of tutorials, research talks, case studies, and industry presentations. We discuss recent advances in ML frameworks, compilers, systems and architecture support, security, training and hardware acceleration.
Connect with us for the latest in ML Acceleration and Deployment:
Website: https://octoml.ai
LinkedIn: https://www.linkedin.com/company/octoml
Twitter: https://twitter.com/OctoML
- - -
Recorded at TVMCon (https://www.tvmcon.org), the Machine Learning Acceleration Conference in Dec 2021.
TVMCon covers the state of the art of deep learning compilation and optimization, with a range of tutorials, research talks, case studies, and industry presentations. We discuss recent advances in ML frameworks, compilers, systems and architecture support, security, training and hardware acceleration.
Connect with us for the latest in ML Acceleration and Deployment:
Website: https://octoml.ai
LinkedIn: https://www.linkedin.com/company/octoml
Twitter: https://twitter.com/OctoML
- 3 participants
- 21 minutes
10 Jan 2022
SPEAKERS: Antonio Tomas
--
Designing novel hardware architecture for ML is hard, especially for achieving high energy-efficiency and performance. However, the importance of a robust system software stack is often neglected and poses a bigger challenge. In this talk we will present how at EdgeCortix we have adopted and effectively extended TVM to bring to life the MERA software stack that enables end to end neural network acceleration on our proprietary processor architecture, across ASICs and FPGAs.
- - -
Recorded at TVMCon (https://www.tvmcon.org), the Machine Learning Acceleration Conference in Dec 2021.
TVMCon covers the state of the art of deep learning compilation and optimization, with a range of tutorials, research talks, case studies, and industry presentations. We discuss recent advances in ML frameworks, compilers, systems and architecture support, security, training and hardware acceleration.
Connect with us for the latest in ML Acceleration and Deployment:
Website: https://octoml.ai
LinkedIn: https://www.linkedin.com/company/octoml
Twitter: https://twitter.com/OctoML
--
Designing novel hardware architecture for ML is hard, especially for achieving high energy-efficiency and performance. However, the importance of a robust system software stack is often neglected and poses a bigger challenge. In this talk we will present how at EdgeCortix we have adopted and effectively extended TVM to bring to life the MERA software stack that enables end to end neural network acceleration on our proprietary processor architecture, across ASICs and FPGAs.
- - -
Recorded at TVMCon (https://www.tvmcon.org), the Machine Learning Acceleration Conference in Dec 2021.
TVMCon covers the state of the art of deep learning compilation and optimization, with a range of tutorials, research talks, case studies, and industry presentations. We discuss recent advances in ML frameworks, compilers, systems and architecture support, security, training and hardware acceleration.
Connect with us for the latest in ML Acceleration and Deployment:
Website: https://octoml.ai
LinkedIn: https://www.linkedin.com/company/octoml
Twitter: https://twitter.com/OctoML
- 3 participants
- 16 minutes

10 Jan 2022
SPEAKERS: Derek Chickles, Chien-Chun (Joe) Chou
--
Marvell’s integrated inferencing engine in the OCTEON 10 DPU enables best-in-class inferencing directly in the data pipeline. This talk will highlight the flexibility and performance of the Machine Learning Inference Processor in the OCTEON 10, as well as some of our latest work with the TVM community to enable TVM-based compile flows.
- - -
Recorded at TVMCon (https://www.tvmcon.org), the Machine Learning Acceleration Conference in Dec 2021.
TVMCon covers the state of the art of deep learning compilation and optimization, with a range of tutorials, research talks, case studies, and industry presentations. We discuss recent advances in ML frameworks, compilers, systems and architecture support, security, training and hardware acceleration.
Connect with us for the latest in ML Acceleration and Deployment:
Website: https://octoml.ai
LinkedIn: https://www.linkedin.com/company/octoml
Twitter: https://twitter.com/OctoML
--
Marvell’s integrated inferencing engine in the OCTEON 10 DPU enables best-in-class inferencing directly in the data pipeline. This talk will highlight the flexibility and performance of the Machine Learning Inference Processor in the OCTEON 10, as well as some of our latest work with the TVM community to enable TVM-based compile flows.
- - -
Recorded at TVMCon (https://www.tvmcon.org), the Machine Learning Acceleration Conference in Dec 2021.
TVMCon covers the state of the art of deep learning compilation and optimization, with a range of tutorials, research talks, case studies, and industry presentations. We discuss recent advances in ML frameworks, compilers, systems and architecture support, security, training and hardware acceleration.
Connect with us for the latest in ML Acceleration and Deployment:
Website: https://octoml.ai
LinkedIn: https://www.linkedin.com/company/octoml
Twitter: https://twitter.com/OctoML
- 3 participants
- 15 minutes

10 Jan 2022
SPEAKERS: Jiajun Jiang, Yuguang Deng, Yin Ma
--
How TVM works with PaddlePaddle, Paddle.js and KunlunXin NPU.
- - -
Recorded at TVMCon (https://www.tvmcon.org), the Machine Learning Acceleration Conference in Dec 2021.
TVMCon covers the state of the art of deep learning compilation and optimization, with a range of tutorials, research talks, case studies, and industry presentations. We discuss recent advances in ML frameworks, compilers, systems and architecture support, security, training and hardware acceleration.
Connect with us for the latest in ML Acceleration and Deployment:
Website: https://octoml.ai
LinkedIn: https://www.linkedin.com/company/octoml
Twitter: https://twitter.com/OctoML
--
How TVM works with PaddlePaddle, Paddle.js and KunlunXin NPU.
- - -
Recorded at TVMCon (https://www.tvmcon.org), the Machine Learning Acceleration Conference in Dec 2021.
TVMCon covers the state of the art of deep learning compilation and optimization, with a range of tutorials, research talks, case studies, and industry presentations. We discuss recent advances in ML frameworks, compilers, systems and architecture support, security, training and hardware acceleration.
Connect with us for the latest in ML Acceleration and Deployment:
Website: https://octoml.ai
LinkedIn: https://www.linkedin.com/company/octoml
Twitter: https://twitter.com/OctoML
- 5 participants
- 15 minutes
10 Jan 2022
SPEAKERS: Wenxi Zhu
--
TVM has been widely used in Game-AI/ Map/ Advertisement/ Information-Security in Tencent, and saves us millions of dollars per year. TVM has been integrated into our game AI platform, to boost performance for DL model inference and NPC character control. It turns out that TVM could outperform MKL by 2~3x in our game AI model. Also there is 5x performance improvement and 50% memory footprint reduce in our NPC character control implementation.
- - -
Recorded at TVMCon (https://www.tvmcon.org), the Machine Learning Acceleration Conference in Dec 2021.
TVMCon covers the state of the art of deep learning compilation and optimization, with a range of tutorials, research talks, case studies, and industry presentations. We discuss recent advances in ML frameworks, compilers, systems and architecture support, security, training and hardware acceleration.
Connect with us for the latest in ML Acceleration and Deployment:
Website: https://octoml.ai
LinkedIn: https://www.linkedin.com/company/octoml
Twitter: https://twitter.com/OctoML
--
TVM has been widely used in Game-AI/ Map/ Advertisement/ Information-Security in Tencent, and saves us millions of dollars per year. TVM has been integrated into our game AI platform, to boost performance for DL model inference and NPC character control. It turns out that TVM could outperform MKL by 2~3x in our game AI model. Also there is 5x performance improvement and 50% memory footprint reduce in our NPC character control implementation.
- - -
Recorded at TVMCon (https://www.tvmcon.org), the Machine Learning Acceleration Conference in Dec 2021.
TVMCon covers the state of the art of deep learning compilation and optimization, with a range of tutorials, research talks, case studies, and industry presentations. We discuss recent advances in ML frameworks, compilers, systems and architecture support, security, training and hardware acceleration.
Connect with us for the latest in ML Acceleration and Deployment:
Website: https://octoml.ai
LinkedIn: https://www.linkedin.com/company/octoml
Twitter: https://twitter.com/OctoML
- 2 participants
- 19 minutes

10 Jan 2022
SPEAKER: Jorn Tuyls
--
The integrated AI engines in the Xilinx Versal AI series devices deliver breakthrough AI inference performance through the up to 8X better silicon area compute density when compared with traditional programmable logic DSP and ML implementations. This talk will outline the ongoing TVM based work at Xilinx to build and compile for AI Engine powered ML accelerators. This involves creating a flexible compilation and runtime flow to make effective use of the programmable array of vector processors, shared memory and DMA engines.
- - -
Recorded at TVMCon (https://www.tvmcon.org), the Machine Learning Acceleration Conference in Dec 2021.
TVMCon covers the state of the art of deep learning compilation and optimization, with a range of tutorials, research talks, case studies, and industry presentations. We discuss recent advances in ML frameworks, compilers, systems and architecture support, security, training and hardware acceleration.
Connect with us for the latest in ML Acceleration and Deployment:
Website: https://octoml.ai
LinkedIn: https://www.linkedin.com/company/octoml
Twitter: https://twitter.com/OctoML
--
The integrated AI engines in the Xilinx Versal AI series devices deliver breakthrough AI inference performance through the up to 8X better silicon area compute density when compared with traditional programmable logic DSP and ML implementations. This talk will outline the ongoing TVM based work at Xilinx to build and compile for AI Engine powered ML accelerators. This involves creating a flexible compilation and runtime flow to make effective use of the programmable array of vector processors, shared memory and DMA engines.
- - -
Recorded at TVMCon (https://www.tvmcon.org), the Machine Learning Acceleration Conference in Dec 2021.
TVMCon covers the state of the art of deep learning compilation and optimization, with a range of tutorials, research talks, case studies, and industry presentations. We discuss recent advances in ML frameworks, compilers, systems and architecture support, security, training and hardware acceleration.
Connect with us for the latest in ML Acceleration and Deployment:
Website: https://octoml.ai
LinkedIn: https://www.linkedin.com/company/octoml
Twitter: https://twitter.com/OctoML
- 2 participants
- 20 minutes

10 Jan 2022
SPEAKERS: Ryo Takahashi
--
Woven Planet Holdings believes that we will need to run machine learning (ML) models on top of various processors for the future mobility business. Our ML application domains include not only automated driving but diverse vehicular data driven services (e.g. ride-sharing), high-definition map generation, robotics, and a smart city project. In this business environment with various compile targets, an open-sourced, unified abstraction interface like Apache TVM can contribute to both productivity and safety enhancement. We have embedded TVM into their MLOps Pipeline framework (a key service of the Arene Platform) and are beginning to deploy actual product ML models for multiple targets. In this presentation, a practitioner in Woven Planet will talk about the successes of Apache TVM adoption so far and future roadmap.
- - -
Recorded at TVMCon (https://www.tvmcon.org), the Machine Learning Acceleration Conference in Dec 2021.
TVMCon covers the state of the art of deep learning compilation and optimization, with a range of tutorials, research talks, case studies, and industry presentations. We discuss recent advances in ML frameworks, compilers, systems and architecture support, security, training and hardware acceleration.
Connect with us for the latest in ML Acceleration and Deployment:
Website: https://octoml.ai
LinkedIn: https://www.linkedin.com/company/octoml
Twitter: https://twitter.com/OctoML
--
Woven Planet Holdings believes that we will need to run machine learning (ML) models on top of various processors for the future mobility business. Our ML application domains include not only automated driving but diverse vehicular data driven services (e.g. ride-sharing), high-definition map generation, robotics, and a smart city project. In this business environment with various compile targets, an open-sourced, unified abstraction interface like Apache TVM can contribute to both productivity and safety enhancement. We have embedded TVM into their MLOps Pipeline framework (a key service of the Arene Platform) and are beginning to deploy actual product ML models for multiple targets. In this presentation, a practitioner in Woven Planet will talk about the successes of Apache TVM adoption so far and future roadmap.
- - -
Recorded at TVMCon (https://www.tvmcon.org), the Machine Learning Acceleration Conference in Dec 2021.
TVMCon covers the state of the art of deep learning compilation and optimization, with a range of tutorials, research talks, case studies, and industry presentations. We discuss recent advances in ML frameworks, compilers, systems and architecture support, security, training and hardware acceleration.
Connect with us for the latest in ML Acceleration and Deployment:
Website: https://octoml.ai
LinkedIn: https://www.linkedin.com/company/octoml
Twitter: https://twitter.com/OctoML
- 2 participants
- 17 minutes
10 Jan 2022
SPEAKERS: Grigori Fursin, Thomas Zhu, Alexander Peskov
MLPerf is a community effort to develop a common Machine Learning (ML) benchmark that provides consistent, reproducible, and fair measurements of accuracy, speed, and efficiency across diverse ML models, datasets, hardware, and software: https://mlcommons.org. While MLPerf popularity is steadily growing, the barrier of entry to MLPerf remains high due to a complex benchmarking and submission pipeline and rapidly evolving hardware and software stacks. In this tutorial, we will demonstrate how Apache TVM and the Collective Knowledge (CK) framework can simplify and automate MLPerf inference benchmarking based on our own MLPerf v1.1 submission. Our goal is to explain how our flexible open-source stack can lower the barrier of entry for future hardware participants by providing a powerful framework that is both hardware and ML framework agnostic and can optimize almost any deep learning model on almost any deployment hardware.
- - -
Recorded at TVMCon (https://www.tvmcon.org), the Machine Learning Acceleration Conference in Dec 2021.
TVMCon covers the state of the art of deep learning compilation and optimization, with a range of tutorials, research talks, case studies, and industry presentations. We discuss recent advances in ML frameworks, compilers, systems and architecture support, security, training and hardware acceleration.
Connect with us for the latest in ML Acceleration and Deployment:
Website: https://octoml.ai
LinkedIn: https://www.linkedin.com/company/octoml
Twitter: https://twitter.com/OctoML
MLPerf is a community effort to develop a common Machine Learning (ML) benchmark that provides consistent, reproducible, and fair measurements of accuracy, speed, and efficiency across diverse ML models, datasets, hardware, and software: https://mlcommons.org. While MLPerf popularity is steadily growing, the barrier of entry to MLPerf remains high due to a complex benchmarking and submission pipeline and rapidly evolving hardware and software stacks. In this tutorial, we will demonstrate how Apache TVM and the Collective Knowledge (CK) framework can simplify and automate MLPerf inference benchmarking based on our own MLPerf v1.1 submission. Our goal is to explain how our flexible open-source stack can lower the barrier of entry for future hardware participants by providing a powerful framework that is both hardware and ML framework agnostic and can optimize almost any deep learning model on almost any deployment hardware.
- - -
Recorded at TVMCon (https://www.tvmcon.org), the Machine Learning Acceleration Conference in Dec 2021.
TVMCon covers the state of the art of deep learning compilation and optimization, with a range of tutorials, research talks, case studies, and industry presentations. We discuss recent advances in ML frameworks, compilers, systems and architecture support, security, training and hardware acceleration.
Connect with us for the latest in ML Acceleration and Deployment:
Website: https://octoml.ai
LinkedIn: https://www.linkedin.com/company/octoml
Twitter: https://twitter.com/OctoML
- 4 participants
- 52 minutes

10 Jan 2022
SPEAKER: Yida Wang
In this talk, we’d like to share with the community about the deep learning training projects at AWS, including both the hardware side and software side.
- - -
Recorded at TVMCon (https://www.tvmcon.org), the Machine Learning Acceleration Conference in Dec 2021.
TVMCon covers the state of the art of deep learning compilation and optimization, with a range of tutorials, research talks, case studies, and industry presentations. We discuss recent advances in ML frameworks, compilers, systems and architecture support, security, training and hardware acceleration.
Connect with us for the latest in ML Acceleration and Deployment:
Website: https://octoml.ai
LinkedIn: https://www.linkedin.com/company/octoml
Twitter: https://twitter.com/OctoML
In this talk, we’d like to share with the community about the deep learning training projects at AWS, including both the hardware side and software side.
- - -
Recorded at TVMCon (https://www.tvmcon.org), the Machine Learning Acceleration Conference in Dec 2021.
TVMCon covers the state of the art of deep learning compilation and optimization, with a range of tutorials, research talks, case studies, and industry presentations. We discuss recent advances in ML frameworks, compilers, systems and architecture support, security, training and hardware acceleration.
Connect with us for the latest in ML Acceleration and Deployment:
Website: https://octoml.ai
LinkedIn: https://www.linkedin.com/company/octoml
Twitter: https://twitter.com/OctoML
- 2 participants
- 23 minutes

10 Jan 2022
SPEAKERS: Joey Chou, Alicja Kwasniewska, Sharath Raghava
This case study highlights a multi-object tracking application with reidentification using TVM on the SiMa.ai™ MLSoC accelerator. SiMa.ai will present how to use key TVM functionalities to ensure a smooth execution of a multi-model computer vision pipeline in a heterogeneous environment and efficiently map specific workloads to different computing devices to achieve the highest performance at the lowest power utilization. In addition, the need for analyzing the end-to-end application performance to best fit different markets and applications will be discussed in order to best support customers’ needs.
- - -
Recorded at TVMCon (https://www.tvmcon.org), the Machine Learning Acceleration Conference in Dec 2021.
TVMCon covers the state of the art of deep learning compilation and optimization, with a range of tutorials, research talks, case studies, and industry presentations. We discuss recent advances in ML frameworks, compilers, systems and architecture support, security, training and hardware acceleration.
Connect with us for the latest in ML Acceleration and Deployment:
Website: https://octoml.ai
LinkedIn: https://www.linkedin.com/company/octoml
Twitter: https://twitter.com/OctoML
This case study highlights a multi-object tracking application with reidentification using TVM on the SiMa.ai™ MLSoC accelerator. SiMa.ai will present how to use key TVM functionalities to ensure a smooth execution of a multi-model computer vision pipeline in a heterogeneous environment and efficiently map specific workloads to different computing devices to achieve the highest performance at the lowest power utilization. In addition, the need for analyzing the end-to-end application performance to best fit different markets and applications will be discussed in order to best support customers’ needs.
- - -
Recorded at TVMCon (https://www.tvmcon.org), the Machine Learning Acceleration Conference in Dec 2021.
TVMCon covers the state of the art of deep learning compilation and optimization, with a range of tutorials, research talks, case studies, and industry presentations. We discuss recent advances in ML frameworks, compilers, systems and architecture support, security, training and hardware acceleration.
Connect with us for the latest in ML Acceleration and Deployment:
Website: https://octoml.ai
LinkedIn: https://www.linkedin.com/company/octoml
Twitter: https://twitter.com/OctoML
- 5 participants
- 19 minutes

10 Jan 2022
SPEAKERS: Jesse Dodge, Oren Etzioni
--
The computational budgets used for machine learning research have increased dramatically in recent years. Machine learning systems are also used in production more than ever before, impacting many people around the world. In this interview we will discuss the implications of this increase in computational cost in research and production, touching on the environmental impact of AI and how unequal access to computational resources impacts our communities. The observed trends have shown no sign of slowing down, and thus we will discuss an overarching theme of much work in modern AI: efficiency is more important than ever.
- - -
Recorded at TVMCon (https://www.tvmcon.org), the Machine Learning Acceleration Conference in Dec 2021.
TVMCon covers the state of the art of deep learning compilation and optimization, with a range of tutorials, research talks, case studies, and industry presentations. We discuss recent advances in ML frameworks, compilers, systems and architecture support, security, training and hardware acceleration.
Connect with us for the latest in ML Acceleration and Deployment:
Website: https://octoml.ai
LinkedIn: https://www.linkedin.com/company/octoml
Twitter: https://twitter.com/OctoML
--
The computational budgets used for machine learning research have increased dramatically in recent years. Machine learning systems are also used in production more than ever before, impacting many people around the world. In this interview we will discuss the implications of this increase in computational cost in research and production, touching on the environmental impact of AI and how unequal access to computational resources impacts our communities. The observed trends have shown no sign of slowing down, and thus we will discuss an overarching theme of much work in modern AI: efficiency is more important than ever.
- - -
Recorded at TVMCon (https://www.tvmcon.org), the Machine Learning Acceleration Conference in Dec 2021.
TVMCon covers the state of the art of deep learning compilation and optimization, with a range of tutorials, research talks, case studies, and industry presentations. We discuss recent advances in ML frameworks, compilers, systems and architecture support, security, training and hardware acceleration.
Connect with us for the latest in ML Acceleration and Deployment:
Website: https://octoml.ai
LinkedIn: https://www.linkedin.com/company/octoml
Twitter: https://twitter.com/OctoML
- 3 participants
- 22 minutes

10 Jan 2022
SPEAKER: Sarah Novotny
--
Sarah has long been an Open Source champion in projects such as Kubernetes, NGINX and MySQL. She is part of the Microsoft Azure Office of the CTO, sits on the Linux Foundation Board of Directors, previously led an Open Source Strategy group at Google and ran large scale technology infrastructures before web-scale had a name.
- - -
Recorded at TVMCon (https://www.tvmcon.org), the Machine Learning Acceleration Conference in Dec 2021.
TVMCon covers the state of the art of deep learning compilation and optimization, with a range of tutorials, research talks, case studies, and industry presentations. We discuss recent advances in ML frameworks, compilers, systems and architecture support, security, training and hardware acceleration.
Connect with us for the latest in ML Acceleration and Deployment:
Website: https://octoml.ai
LinkedIn: https://www.linkedin.com/company/octoml
Twitter: https://twitter.com/OctoML
--
Sarah has long been an Open Source champion in projects such as Kubernetes, NGINX and MySQL. She is part of the Microsoft Azure Office of the CTO, sits on the Linux Foundation Board of Directors, previously led an Open Source Strategy group at Google and ran large scale technology infrastructures before web-scale had a name.
- - -
Recorded at TVMCon (https://www.tvmcon.org), the Machine Learning Acceleration Conference in Dec 2021.
TVMCon covers the state of the art of deep learning compilation and optimization, with a range of tutorials, research talks, case studies, and industry presentations. We discuss recent advances in ML frameworks, compilers, systems and architecture support, security, training and hardware acceleration.
Connect with us for the latest in ML Acceleration and Deployment:
Website: https://octoml.ai
LinkedIn: https://www.linkedin.com/company/octoml
Twitter: https://twitter.com/OctoML
- 2 participants
- 24 minutes

10 Jan 2022
SPEAKER: Clement Delangue, CEO Hugging Face
--
Clement describes the evolution of Transformer models, which have generated unprecedented excitement in academia and industry, enabling huge advances in NLP such as next sentence prediction, question answering, and text summarization. He also shares why it’s important to ensure they are used in an ethical and transparent manner, and how we can operationalize ethics within the ML development pipeline to minimize their harms.
- - -
Recorded at TVMCon (https://www.tvmcon.org), the Machine Learning Acceleration Conference in Dec 2021.
TVMCon covers the state of the art of deep learning compilation and optimization, with a range of tutorials, research talks, case studies, and industry presentations. We discuss recent advances in ML frameworks, compilers, systems and architecture support, security, training and hardware acceleration.
Connect with us for the latest in ML Acceleration and Deployment:
Website: https://octoml.ai
LinkedIn: https://www.linkedin.com/company/octoml
Twitter: https://twitter.com/OctoML
--
Clement describes the evolution of Transformer models, which have generated unprecedented excitement in academia and industry, enabling huge advances in NLP such as next sentence prediction, question answering, and text summarization. He also shares why it’s important to ensure they are used in an ethical and transparent manner, and how we can operationalize ethics within the ML development pipeline to minimize their harms.
- - -
Recorded at TVMCon (https://www.tvmcon.org), the Machine Learning Acceleration Conference in Dec 2021.
TVMCon covers the state of the art of deep learning compilation and optimization, with a range of tutorials, research talks, case studies, and industry presentations. We discuss recent advances in ML frameworks, compilers, systems and architecture support, security, training and hardware acceleration.
Connect with us for the latest in ML Acceleration and Deployment:
Website: https://octoml.ai
LinkedIn: https://www.linkedin.com/company/octoml
Twitter: https://twitter.com/OctoML
- 2 participants
- 25 minutes

10 Jan 2022
SPEAKERS: Leandro Nunes, Gustavo Romero
TVMC is a command line driver for TVM. It aims to offer an unified interface for users and run common tasks using TVM infrastructure such as compiling a model, tuning a model, and running a model using the graph runtime. This tutorial presents a detailed walkthrough TVMC from installation to usage, demonstrating its features using a series of small practical projects that can be reproduced by the audience on their own machines.
- - -
Recorded at TVMCon (https://www.tvmcon.org), the Machine Learning Acceleration Conference in Dec 2021.
TVMCon covers the state of the art of deep learning compilation and optimization, with a range of tutorials, research talks, case studies, and industry presentations. We discuss recent advances in ML frameworks, compilers, systems and architecture support, security, training and hardware acceleration.
Connect with us for the latest in ML Acceleration and Deployment:
Website: https://octoml.ai
LinkedIn: https://www.linkedin.com/company/octoml
Twitter: https://twitter.com/OctoML
TVMC is a command line driver for TVM. It aims to offer an unified interface for users and run common tasks using TVM infrastructure such as compiling a model, tuning a model, and running a model using the graph runtime. This tutorial presents a detailed walkthrough TVMC from installation to usage, demonstrating its features using a series of small practical projects that can be reproduced by the audience on their own machines.
- - -
Recorded at TVMCon (https://www.tvmcon.org), the Machine Learning Acceleration Conference in Dec 2021.
TVMCon covers the state of the art of deep learning compilation and optimization, with a range of tutorials, research talks, case studies, and industry presentations. We discuss recent advances in ML frameworks, compilers, systems and architecture support, security, training and hardware acceleration.
Connect with us for the latest in ML Acceleration and Deployment:
Website: https://octoml.ai
LinkedIn: https://www.linkedin.com/company/octoml
Twitter: https://twitter.com/OctoML
- 3 participants
- 1:20 hours

10 Jan 2022
In this tutorial session, a follow up to using TVM with the TVMC command line interface, we will show how to work in Python to get started importing, compiling, and optimizing models with the TVMC Python interface.
- - -
Recorded at TVMCon (https://www.tvmcon.org), the Machine Learning Acceleration Conference in Dec 2021.
TVMCon covers the state of the art of deep learning compilation and optimization, with a range of tutorials, research talks, case studies, and industry presentations. We discuss recent advances in ML frameworks, compilers, systems and architecture support, security, training and hardware acceleration.
Connect with us for the latest in ML Acceleration and Deployment:
Website: https://octoml.ai
LinkedIn: https://www.linkedin.com/company/octoml
Twitter: https://twitter.com/OctoML
- - -
Recorded at TVMCon (https://www.tvmcon.org), the Machine Learning Acceleration Conference in Dec 2021.
TVMCon covers the state of the art of deep learning compilation and optimization, with a range of tutorials, research talks, case studies, and industry presentations. We discuss recent advances in ML frameworks, compilers, systems and architecture support, security, training and hardware acceleration.
Connect with us for the latest in ML Acceleration and Deployment:
Website: https://octoml.ai
LinkedIn: https://www.linkedin.com/company/octoml
Twitter: https://twitter.com/OctoML
- 2 participants
- 21 minutes

10 Jan 2022
SPEAKER: Phil Mazzenet
Lightning Quick Performance on Apple M1 with TVM
OctoML has recently spearheaded ML acceleration work with Hugging Face’s implementation of BERT to automatically optimize its performance for the “most powerful chips Apple has ever built.” OctoML is able to provide an average 3X speedup over Apple’s TensorFlow plugin by leveraging its expertise in Apache TVM, the open source stack for ML performance and portability.
- - -
Recorded at TVMCon (https://www.tvmcon.org), the Machine Learning Acceleration Conference in Dec 2021.
TVMCon covers the state of the art of deep learning compilation and optimization, with a range of tutorials, research talks, case studies, and industry presentations. We discuss recent advances in ML frameworks, compilers, systems and architecture support, security, training and hardware acceleration.
Connect with us for the latest in ML Acceleration and Deployment:
Website: https://octoml.ai
LinkedIn: https://www.linkedin.com/company/octoml
Twitter: https://twitter.com/OctoML
Lightning Quick Performance on Apple M1 with TVM
OctoML has recently spearheaded ML acceleration work with Hugging Face’s implementation of BERT to automatically optimize its performance for the “most powerful chips Apple has ever built.” OctoML is able to provide an average 3X speedup over Apple’s TensorFlow plugin by leveraging its expertise in Apache TVM, the open source stack for ML performance and portability.
- - -
Recorded at TVMCon (https://www.tvmcon.org), the Machine Learning Acceleration Conference in Dec 2021.
TVMCon covers the state of the art of deep learning compilation and optimization, with a range of tutorials, research talks, case studies, and industry presentations. We discuss recent advances in ML frameworks, compilers, systems and architecture support, security, training and hardware acceleration.
Connect with us for the latest in ML Acceleration and Deployment:
Website: https://octoml.ai
LinkedIn: https://www.linkedin.com/company/octoml
Twitter: https://twitter.com/OctoML
- 3 participants
- 12 minutes
10 Jan 2022
SPEAKER: Chip Huyen, Stanford University
--
The success of an ML model today still depends on the hardware it runs on, which makes it important for people working with ML models in production to understand how their models are compiled and optimized to run on different hardware accelerators.
- - -
Recorded at TVMCon (https://www.tvmcon.org), the Machine Learning Acceleration Conference in Dec 2021.
TVMCon covers the state of the art of deep learning compilation and optimization, with a range of tutorials, research talks, case studies, and industry presentations. We discuss recent advances in ML frameworks, compilers, systems and architecture support, security, training and hardware acceleration.
Connect with us for the latest in ML Acceleration and Deployment:
Website: https://octoml.ai
LinkedIn: https://www.linkedin.com/company/octoml
Twitter: https://twitter.com/OctoML
--
The success of an ML model today still depends on the hardware it runs on, which makes it important for people working with ML models in production to understand how their models are compiled and optimized to run on different hardware accelerators.
- - -
Recorded at TVMCon (https://www.tvmcon.org), the Machine Learning Acceleration Conference in Dec 2021.
TVMCon covers the state of the art of deep learning compilation and optimization, with a range of tutorials, research talks, case studies, and industry presentations. We discuss recent advances in ML frameworks, compilers, systems and architecture support, security, training and hardware acceleration.
Connect with us for the latest in ML Acceleration and Deployment:
Website: https://octoml.ai
LinkedIn: https://www.linkedin.com/company/octoml
Twitter: https://twitter.com/OctoML
- 2 participants
- 20 minutes
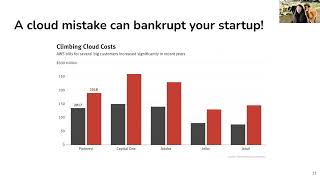
10 Jan 2022
SPEAKER: Alessya Visnjic
--
With TVM, Machine Learning can be run everywhere. For ML Engineers who operate ML models in production this poses an interesting challenge – how do we monitor model, sensor, and data health on the edge? This talk will present an open source library, whylogs, that can be used to instrument ML inference at the edge and discuss how monitoring can be implemented for ML models deployed to a fleet of devices.
- - -
Recorded at TVMCon (https://www.tvmcon.org), the Machine Learning Acceleration Conference in Dec 2021.
TVMCon covers the state of the art of deep learning compilation and optimization, with a range of tutorials, research talks, case studies, and industry presentations. We discuss recent advances in ML frameworks, compilers, systems and architecture support, security, training and hardware acceleration.
Connect with us for the latest in ML Acceleration and Deployment:
Website: https://octoml.ai
LinkedIn: https://www.linkedin.com/company/octoml
Twitter: https://twitter.com/OctoML
--
With TVM, Machine Learning can be run everywhere. For ML Engineers who operate ML models in production this poses an interesting challenge – how do we monitor model, sensor, and data health on the edge? This talk will present an open source library, whylogs, that can be used to instrument ML inference at the edge and discuss how monitoring can be implemented for ML models deployed to a fleet of devices.
- - -
Recorded at TVMCon (https://www.tvmcon.org), the Machine Learning Acceleration Conference in Dec 2021.
TVMCon covers the state of the art of deep learning compilation and optimization, with a range of tutorials, research talks, case studies, and industry presentations. We discuss recent advances in ML frameworks, compilers, systems and architecture support, security, training and hardware acceleration.
Connect with us for the latest in ML Acceleration and Deployment:
Website: https://octoml.ai
LinkedIn: https://www.linkedin.com/company/octoml
Twitter: https://twitter.com/OctoML
- 2 participants
- 21 minutes

10 Jan 2022
SPEAKER: Loc Huynh
--
TVM at Microsoft.
Nexus is a GPU Cluster Engine for Accelerating DNN-Based Video Analysis. We address the problem of serving Deep Neural Networks (DNNs) efficiently from a cluster of GPUs. In order to realize the promise of very low-cost processing made by accelerators such as GPUs, it is essential to run them at sustained high utilization. Doing so requires cluster-scale resource management that performs detailed scheduling of GPUs, reasoning about groups of DNN invocations that need to be coscheduled, and moving from the conventional whole-DNN execution model to executing fragments of DNNs. Nexus is a fully implemented system that includes these innovations.
- - -
Recorded at TVMCon (https://www.tvmcon.org), the Machine Learning Acceleration Conference in Dec 2021.
TVMCon covers the state of the art of deep learning compilation and optimization, with a range of tutorials, research talks, case studies, and industry presentations. We discuss recent advances in ML frameworks, compilers, systems and architecture support, security, training and hardware acceleration.
Connect with us for the latest in ML Acceleration and Deployment:
Website: https://octoml.ai
LinkedIn: https://www.linkedin.com/company/octoml
Twitter: https://twitter.com/OctoML
--
TVM at Microsoft.
Nexus is a GPU Cluster Engine for Accelerating DNN-Based Video Analysis. We address the problem of serving Deep Neural Networks (DNNs) efficiently from a cluster of GPUs. In order to realize the promise of very low-cost processing made by accelerators such as GPUs, it is essential to run them at sustained high utilization. Doing so requires cluster-scale resource management that performs detailed scheduling of GPUs, reasoning about groups of DNN invocations that need to be coscheduled, and moving from the conventional whole-DNN execution model to executing fragments of DNNs. Nexus is a fully implemented system that includes these innovations.
- - -
Recorded at TVMCon (https://www.tvmcon.org), the Machine Learning Acceleration Conference in Dec 2021.
TVMCon covers the state of the art of deep learning compilation and optimization, with a range of tutorials, research talks, case studies, and industry presentations. We discuss recent advances in ML frameworks, compilers, systems and architecture support, security, training and hardware acceleration.
Connect with us for the latest in ML Acceleration and Deployment:
Website: https://octoml.ai
LinkedIn: https://www.linkedin.com/company/octoml
Twitter: https://twitter.com/OctoML
- 3 participants
- 22 minutes

10 Jan 2022
SPEAKERS: Manash Goswami, Ganesan Ramalingam
--
In this talk, I will give an overview of the ONNX (https://onnx.ai) and ONNX Runtime (https://onnxruntime.ai) projects. I will focus on the motivation, the architecture, the adoption, the lessons, and the future roadmap of ONNX and ONNX Runtime. I will discuss the work we are collaborating with OctoML on integrating TVM and ONNX Runtime.
- - -
Recorded at TVMCon (https://www.tvmcon.org), the Machine Learning Acceleration Conference in Dec 2021.
TVMCon covers the state of the art of deep learning compilation and optimization, with a range of tutorials, research talks, case studies, and industry presentations. We discuss recent advances in ML frameworks, compilers, systems and architecture support, security, training and hardware acceleration.
Connect with us for the latest in ML Acceleration and Deployment:
Website: https://octoml.ai
LinkedIn: https://www.linkedin.com/company/octoml
Twitter: https://twitter.com/OctoML
--
In this talk, I will give an overview of the ONNX (https://onnx.ai) and ONNX Runtime (https://onnxruntime.ai) projects. I will focus on the motivation, the architecture, the adoption, the lessons, and the future roadmap of ONNX and ONNX Runtime. I will discuss the work we are collaborating with OctoML on integrating TVM and ONNX Runtime.
- - -
Recorded at TVMCon (https://www.tvmcon.org), the Machine Learning Acceleration Conference in Dec 2021.
TVMCon covers the state of the art of deep learning compilation and optimization, with a range of tutorials, research talks, case studies, and industry presentations. We discuss recent advances in ML frameworks, compilers, systems and architecture support, security, training and hardware acceleration.
Connect with us for the latest in ML Acceleration and Deployment:
Website: https://octoml.ai
LinkedIn: https://www.linkedin.com/company/octoml
Twitter: https://twitter.com/OctoML
- 3 participants
- 17 minutes

10 Jan 2022
Day 2 Keynote from TVMCon (Dec 2021), the Apache TVM and Open Source ML Acceleration Conference.
SPEAKERS: Luis Ceze, Jason Knight, Vanessa Yan, Sameer Farooqui, Matthai Philipose
--
Learn about OctoML, a startup headquartered in Seattle, WA that is focused on making artificial intelligence faster and easier to deploy.
Product Demo features the OctoML Model Zoo with pre-accelerated extremely fast (sub-millisecond) ready-to-download computer vision and language models for both cloud and edge targets.
About OctoML:
OctoML was spun out of the University of Washington Paul G. Allen School of Computer Science & Engineering where a group of computer science experts worked on helping companies deploy machine learning models on varied hardware configurations. It led to the creation of the open-source ML deep learning compiler Apache TVM which has quickly become the defacto deep learning compiler used by companies like Amazon and Facebook.
++ Contents ++
00:00 - OctoML Company and Product Vision - by Luis Ceze
14:55 - OctoML Product Vision Intro - by Jason Knight
16:27 - OctoML Product Demo - by Vanessa Yan, Sameer Farooqui
24:17 - OctoML Product Vision Continued - by Jason Knight
35:17 - TVM-Optimized Video Analysis in Microsoft Watch For - by Matthai Philipose (Microsoft)
41:13 - Future of the OctoML Platform - by Jason Knight
- - -
Recorded at TVMCon (https://www.tvmcon.org), the Machine Learning Acceleration Conference in Dec 2021.
TVMCon covers the state of the art of deep learning compilation and optimization, with a range of tutorials, research talks, case studies, and industry presentations. We discuss recent advances in ML frameworks, compilers, systems and architecture support, security, training and hardware acceleration.
Connect with us for the latest in ML Acceleration and Deployment:
Website: https://octoml.ai
LinkedIn: https://www.linkedin.com/company/octoml
Twitter: https://twitter.com/OctoML
SPEAKERS: Luis Ceze, Jason Knight, Vanessa Yan, Sameer Farooqui, Matthai Philipose
--
Learn about OctoML, a startup headquartered in Seattle, WA that is focused on making artificial intelligence faster and easier to deploy.
Product Demo features the OctoML Model Zoo with pre-accelerated extremely fast (sub-millisecond) ready-to-download computer vision and language models for both cloud and edge targets.
About OctoML:
OctoML was spun out of the University of Washington Paul G. Allen School of Computer Science & Engineering where a group of computer science experts worked on helping companies deploy machine learning models on varied hardware configurations. It led to the creation of the open-source ML deep learning compiler Apache TVM which has quickly become the defacto deep learning compiler used by companies like Amazon and Facebook.
++ Contents ++
00:00 - OctoML Company and Product Vision - by Luis Ceze
14:55 - OctoML Product Vision Intro - by Jason Knight
16:27 - OctoML Product Demo - by Vanessa Yan, Sameer Farooqui
24:17 - OctoML Product Vision Continued - by Jason Knight
35:17 - TVM-Optimized Video Analysis in Microsoft Watch For - by Matthai Philipose (Microsoft)
41:13 - Future of the OctoML Platform - by Jason Knight
- - -
Recorded at TVMCon (https://www.tvmcon.org), the Machine Learning Acceleration Conference in Dec 2021.
TVMCon covers the state of the art of deep learning compilation and optimization, with a range of tutorials, research talks, case studies, and industry presentations. We discuss recent advances in ML frameworks, compilers, systems and architecture support, security, training and hardware acceleration.
Connect with us for the latest in ML Acceleration and Deployment:
Website: https://octoml.ai
LinkedIn: https://www.linkedin.com/company/octoml
Twitter: https://twitter.com/OctoML
- 5 participants
- 45 minutes

10 Jan 2022
Speaker: Gavin Uberti
--
In the summer of 2021, the microTVM community added Arduino bindings the project. These bindings provide a seamless interface for hobbyists to compile, tune, and run AI models on devices like the Arduino Due and Nano 33 BLE without needing to be an expert in the architecture or development platform. This tutorial will demonstrate a walkthrough of a few use cases of microTVM for Arduino. Using commodity and widely-available hobbyist hardware, we will take a common model, optimize it, and compile it to run image and audio processing on-device, using only pip and the Arduino IDE.
- - -
Recorded at TVMCon (https://www.tvmcon.org), the Machine Learning Acceleration Conference in Dec 2021.
TVMCon covers the state of the art of deep learning compilation and optimization, with a range of tutorials, research talks, case studies, and industry presentations. We discuss recent advances in ML frameworks, compilers, systems and architecture support, security, training and hardware acceleration.
Connect with us for the latest in ML Acceleration and Deployment:
Website: https://octoml.ai
LinkedIn: https://www.linkedin.com/company/octoml
Twitter: https://twitter.com/OctoML
--
In the summer of 2021, the microTVM community added Arduino bindings the project. These bindings provide a seamless interface for hobbyists to compile, tune, and run AI models on devices like the Arduino Due and Nano 33 BLE without needing to be an expert in the architecture or development platform. This tutorial will demonstrate a walkthrough of a few use cases of microTVM for Arduino. Using commodity and widely-available hobbyist hardware, we will take a common model, optimize it, and compile it to run image and audio processing on-device, using only pip and the Arduino IDE.
- - -
Recorded at TVMCon (https://www.tvmcon.org), the Machine Learning Acceleration Conference in Dec 2021.
TVMCon covers the state of the art of deep learning compilation and optimization, with a range of tutorials, research talks, case studies, and industry presentations. We discuss recent advances in ML frameworks, compilers, systems and architecture support, security, training and hardware acceleration.
Connect with us for the latest in ML Acceleration and Deployment:
Website: https://octoml.ai
LinkedIn: https://www.linkedin.com/company/octoml
Twitter: https://twitter.com/OctoML
- 2 participants
- 49 minutes

10 Jan 2022
SPEAKER: Horace He, Meta (Facebook) software engineer
People like using PyTorch because of its very flexible eager mode. But, this has often made it difficult to use compilers in PyTorch, particularly for training. We present a new extension point that allows developers to take a compiler that works for inference, and with minimal effort, apply it to PyTorch models in training. For example, we can take the existing Torchscript to TVM integration and re-use it for optimizing subgraphs in training. Our approach also makes many training optimizations from the literature easy to implement, and we’ll provide several examples of how this extension point can be used to easily speed up PyTorch models.
- - -
Recorded at TVMCon (https://www.tvmcon.org), the Machine Learning Acceleration Conference in Dec 2021.
TVMCon covers the state of the art of deep learning compilation and optimization, with a range of tutorials, research talks, case studies, and industry presentations. We discuss recent advances in ML frameworks, compilers, systems and architecture support, security, training and hardware acceleration.
Connect with us for the latest in ML Acceleration and Deployment:
Website: https://octoml.ai
LinkedIn: https://www.linkedin.com/company/octoml
Twitter: https://twitter.com/OctoML
People like using PyTorch because of its very flexible eager mode. But, this has often made it difficult to use compilers in PyTorch, particularly for training. We present a new extension point that allows developers to take a compiler that works for inference, and with minimal effort, apply it to PyTorch models in training. For example, we can take the existing Torchscript to TVM integration and re-use it for optimizing subgraphs in training. Our approach also makes many training optimizations from the literature easy to implement, and we’ll provide several examples of how this extension point can be used to easily speed up PyTorch models.
- - -
Recorded at TVMCon (https://www.tvmcon.org), the Machine Learning Acceleration Conference in Dec 2021.
TVMCon covers the state of the art of deep learning compilation and optimization, with a range of tutorials, research talks, case studies, and industry presentations. We discuss recent advances in ML frameworks, compilers, systems and architecture support, security, training and hardware acceleration.
Connect with us for the latest in ML Acceleration and Deployment:
Website: https://octoml.ai
LinkedIn: https://www.linkedin.com/company/octoml
Twitter: https://twitter.com/OctoML
- 2 participants
- 20 minutes

10 Jan 2022
SPEAKERS: Yuchen Jin, Altan Haan, Ziheng Jiang
--
Today, TVM has a clear boundary between each abstraction layer, for example, Relay to TIR lowering is done in a single shot translation fashion. However, we start to see a strong need of performing optimizations across different layers. In Relax, we want to co-design the high-level abstraction to unify the abstraction across different layers. Relax have three key goals motivated by our past lessons in ML acceleration: support dynamic shape workloads, enable non-compiler experts to write computational graph optimizations conveniently, and unify the abstraction layers for cross-layer optimizations.
- - -
Recorded at TVMCon (https://www.tvmcon.org), the Machine Learning Acceleration Conference in Dec 2021.
TVMCon covers the state of the art of deep learning compilation and optimization, with a range of tutorials, research talks, case studies, and industry presentations. We discuss recent advances in ML frameworks, compilers, systems and architecture support, security, training and hardware acceleration.
Connect with us for the latest in ML Acceleration and Deployment:
Website: https://octoml.ai
LinkedIn: https://www.linkedin.com/company/octoml
Twitter: https://twitter.com/OctoML
--
Today, TVM has a clear boundary between each abstraction layer, for example, Relay to TIR lowering is done in a single shot translation fashion. However, we start to see a strong need of performing optimizations across different layers. In Relax, we want to co-design the high-level abstraction to unify the abstraction across different layers. Relax have three key goals motivated by our past lessons in ML acceleration: support dynamic shape workloads, enable non-compiler experts to write computational graph optimizations conveniently, and unify the abstraction layers for cross-layer optimizations.
- - -
Recorded at TVMCon (https://www.tvmcon.org), the Machine Learning Acceleration Conference in Dec 2021.
TVMCon covers the state of the art of deep learning compilation and optimization, with a range of tutorials, research talks, case studies, and industry presentations. We discuss recent advances in ML frameworks, compilers, systems and architecture support, security, training and hardware acceleration.
Connect with us for the latest in ML Acceleration and Deployment:
Website: https://octoml.ai
LinkedIn: https://www.linkedin.com/company/octoml
Twitter: https://twitter.com/OctoML
- 4 participants
- 22 minutes

10 Jan 2022
SPEAKERS: Wilson Yu, Mei Ye, Amir Khojaste Galeshkhale
--
In this session we will discuss the the importance of “seamless cross platform deployment” and how well AMD and OctoML have been collaborated together. We are exciting to see our collaborations to expand beyond HPC into the Adaptive High Performance Compute Platforms and Markets.
- - -
Recorded at TVMCon (https://www.tvmcon.org), the Machine Learning Acceleration Conference in Dec 2021.
TVMCon covers the state of the art of deep learning compilation and optimization, with a range of tutorials, research talks, case studies, and industry presentations. We discuss recent advances in ML frameworks, compilers, systems and architecture support, security, training and hardware acceleration.
Connect with us for the latest in ML Acceleration and Deployment:
Website: https://octoml.ai
LinkedIn: https://www.linkedin.com/company/octoml
Twitter: https://twitter.com/OctoML
--
In this session we will discuss the the importance of “seamless cross platform deployment” and how well AMD and OctoML have been collaborated together. We are exciting to see our collaborations to expand beyond HPC into the Adaptive High Performance Compute Platforms and Markets.
- - -
Recorded at TVMCon (https://www.tvmcon.org), the Machine Learning Acceleration Conference in Dec 2021.
TVMCon covers the state of the art of deep learning compilation and optimization, with a range of tutorials, research talks, case studies, and industry presentations. We discuss recent advances in ML frameworks, compilers, systems and architecture support, security, training and hardware acceleration.
Connect with us for the latest in ML Acceleration and Deployment:
Website: https://octoml.ai
LinkedIn: https://www.linkedin.com/company/octoml
Twitter: https://twitter.com/OctoML
- 4 participants
- 10 minutes

10 Jan 2022
SPEAKER: Qian Qiu
--
The work of writing a TensorRT plugin requires solid CUDA programming skills and considerable time to make the plugin work properly and optimized. In this section, we will demonstrate an end-to-end tool to generate a user specific op to a TRT plugin, enabled by Relay and AutoScheduler of TVM. This tool can help AI developers to get rid of the tedious hand-written TRT plugin, and convert their models to TRT automatically.
- - -
Recorded at TVMCon (https://www.tvmcon.org), the Machine Learning Acceleration Conference in Dec 2021.
TVMCon covers the state of the art of deep learning compilation and optimization, with a range of tutorials, research talks, case studies, and industry presentations. We discuss recent advances in ML frameworks, compilers, systems and architecture support, security, training and hardware acceleration.
Connect with us for the latest in ML Acceleration and Deployment:
Website: https://octoml.ai
LinkedIn: https://www.linkedin.com/company/octoml
Twitter: https://twitter.com/OctoML
--
The work of writing a TensorRT plugin requires solid CUDA programming skills and considerable time to make the plugin work properly and optimized. In this section, we will demonstrate an end-to-end tool to generate a user specific op to a TRT plugin, enabled by Relay and AutoScheduler of TVM. This tool can help AI developers to get rid of the tedious hand-written TRT plugin, and convert their models to TRT automatically.
- - -
Recorded at TVMCon (https://www.tvmcon.org), the Machine Learning Acceleration Conference in Dec 2021.
TVMCon covers the state of the art of deep learning compilation and optimization, with a range of tutorials, research talks, case studies, and industry presentations. We discuss recent advances in ML frameworks, compilers, systems and architecture support, security, training and hardware acceleration.
Connect with us for the latest in ML Acceleration and Deployment:
Website: https://octoml.ai
LinkedIn: https://www.linkedin.com/company/octoml
Twitter: https://twitter.com/OctoML
- 2 participants
- 14 minutes

10 Jan 2022
SPEAKERS: Cecilia Albertsson, Hiroki Endoh, Shinya Kaji from Fixstars Corporation, NTT TechnoCross Corporation
--
TVM Streamer is our product name for a video processing application called tvminfer implemented in the GStreamer framework using the TVM deep learning compiler stack. In this session, we will present the outline, method of implementation, and performance evaluation results of TVM Streamer, and discuss the versatility of TVM in solving real-world problems.
- - -
Recorded at TVMCon (https://www.tvmcon.org), the Machine Learning Acceleration Conference in Dec 2021.
TVMCon covers the state of the art of deep learning compilation and optimization, with a range of tutorials, research talks, case studies, and industry presentations. We discuss recent advances in ML frameworks, compilers, systems and architecture support, security, training and hardware acceleration.
Connect with us for the latest in ML Acceleration and Deployment:
Website: https://octoml.ai
LinkedIn: https://www.linkedin.com/company/octoml
Twitter: https://twitter.com/OctoML
--
TVM Streamer is our product name for a video processing application called tvminfer implemented in the GStreamer framework using the TVM deep learning compiler stack. In this session, we will present the outline, method of implementation, and performance evaluation results of TVM Streamer, and discuss the versatility of TVM in solving real-world problems.
- - -
Recorded at TVMCon (https://www.tvmcon.org), the Machine Learning Acceleration Conference in Dec 2021.
TVMCon covers the state of the art of deep learning compilation and optimization, with a range of tutorials, research talks, case studies, and industry presentations. We discuss recent advances in ML frameworks, compilers, systems and architecture support, security, training and hardware acceleration.
Connect with us for the latest in ML Acceleration and Deployment:
Website: https://octoml.ai
LinkedIn: https://www.linkedin.com/company/octoml
Twitter: https://twitter.com/OctoML
- 4 participants
- 17 minutes

10 Jan 2022
SPEAKERS: Sean Silva
--
The Torch-MLIR project is a community-driven project under the LLVM umbrella that provides a high-quality PyTorch frontend for the ML compiler community. The PyTorch ecosystem is normalized into a principled IR implemented using the MLIR framework. Torch-MLIR takes care of shape inference, removing mutation/aliasing, and decomposing operators into more primitive operators to simplify backend implementation. In under 2 months since being announced, multiple industry partners have already started collaborating, and we look forward to welcoming you into our community.
- - -
Recorded at TVMCon (https://www.tvmcon.org), the Machine Learning Acceleration Conference in Dec 2021.
TVMCon covers the state of the art of deep learning compilation and optimization, with a range of tutorials, research talks, case studies, and industry presentations. We discuss recent advances in ML frameworks, compilers, systems and architecture support, security, training and hardware acceleration.
Connect with us for the latest in ML Acceleration and Deployment:
Website: https://octoml.ai
LinkedIn: https://www.linkedin.com/company/octoml
Twitter: https://twitter.com/OctoML
--
The Torch-MLIR project is a community-driven project under the LLVM umbrella that provides a high-quality PyTorch frontend for the ML compiler community. The PyTorch ecosystem is normalized into a principled IR implemented using the MLIR framework. Torch-MLIR takes care of shape inference, removing mutation/aliasing, and decomposing operators into more primitive operators to simplify backend implementation. In under 2 months since being announced, multiple industry partners have already started collaborating, and we look forward to welcoming you into our community.
- - -
Recorded at TVMCon (https://www.tvmcon.org), the Machine Learning Acceleration Conference in Dec 2021.
TVMCon covers the state of the art of deep learning compilation and optimization, with a range of tutorials, research talks, case studies, and industry presentations. We discuss recent advances in ML frameworks, compilers, systems and architecture support, security, training and hardware acceleration.
Connect with us for the latest in ML Acceleration and Deployment:
Website: https://octoml.ai
LinkedIn: https://www.linkedin.com/company/octoml
Twitter: https://twitter.com/OctoML
- 2 participants
- 20 minutes

10 Jan 2022
SPEAKER: Tiejun Chen
--
TVM aims to optimize deep models pretrained by any ML upstream frameworks. But as a popular compiler, users have many additional works to make one given model to work over TVM. We are building an automated ML Infer Booster that just tricks the ML framework into thinking it still takes over everything, but essentially, the underlying TVM backend helps boost this ML inference automatically.
- - -
Recorded at TVMCon (https://www.tvmcon.org), the Machine Learning Acceleration Conference in Dec 2021.
TVMCon covers the state of the art of deep learning compilation and optimization, with a range of tutorials, research talks, case studies, and industry presentations. We discuss recent advances in ML frameworks, compilers, systems and architecture support, security, training and hardware acceleration.
Connect with us for the latest in ML Acceleration and Deployment:
Website: https://octoml.ai
LinkedIn: https://www.linkedin.com/company/octoml
Twitter: https://twitter.com/OctoML
--
TVM aims to optimize deep models pretrained by any ML upstream frameworks. But as a popular compiler, users have many additional works to make one given model to work over TVM. We are building an automated ML Infer Booster that just tricks the ML framework into thinking it still takes over everything, but essentially, the underlying TVM backend helps boost this ML inference automatically.
- - -
Recorded at TVMCon (https://www.tvmcon.org), the Machine Learning Acceleration Conference in Dec 2021.
TVMCon covers the state of the art of deep learning compilation and optimization, with a range of tutorials, research talks, case studies, and industry presentations. We discuss recent advances in ML frameworks, compilers, systems and architecture support, security, training and hardware acceleration.
Connect with us for the latest in ML Acceleration and Deployment:
Website: https://octoml.ai
LinkedIn: https://www.linkedin.com/company/octoml
Twitter: https://twitter.com/OctoML
- 2 participants
- 12 minutes

10 Jan 2022
SPEAKER: Siyuan Feng
--
Deploying deep learning models on various devices has become an important topic. The wave of hardware specialization brings a diverse set of acceleration primitives for multi-dimensional tensor computations. These new acceleration primitives, along with the emerging machine learning models, bring tremendous engineering challenges. In this talk, I will introduce TensorIR, a TVM compiler abstraction for optimizing programs with these tensor computation primitives. TensorIR generalizes the loop nest representation used in existing machine learning compilers to bring tensor computation as the first-class citizen.
- - -
Recorded at TVMCon (https://www.tvmcon.org), the Machine Learning Acceleration Conference in Dec 2021.
TVMCon covers the state of the art of deep learning compilation and optimization, with a range of tutorials, research talks, case studies, and industry presentations. We discuss recent advances in ML frameworks, compilers, systems and architecture support, security, training and hardware acceleration.
Connect with us for the latest in ML Acceleration and Deployment:
Website: https://octoml.ai
LinkedIn: https://www.linkedin.com/company/octoml
Twitter: https://twitter.com/OctoML
--
Deploying deep learning models on various devices has become an important topic. The wave of hardware specialization brings a diverse set of acceleration primitives for multi-dimensional tensor computations. These new acceleration primitives, along with the emerging machine learning models, bring tremendous engineering challenges. In this talk, I will introduce TensorIR, a TVM compiler abstraction for optimizing programs with these tensor computation primitives. TensorIR generalizes the loop nest representation used in existing machine learning compilers to bring tensor computation as the first-class citizen.
- - -
Recorded at TVMCon (https://www.tvmcon.org), the Machine Learning Acceleration Conference in Dec 2021.
TVMCon covers the state of the art of deep learning compilation and optimization, with a range of tutorials, research talks, case studies, and industry presentations. We discuss recent advances in ML frameworks, compilers, systems and architecture support, security, training and hardware acceleration.
Connect with us for the latest in ML Acceleration and Deployment:
Website: https://octoml.ai
LinkedIn: https://www.linkedin.com/company/octoml
Twitter: https://twitter.com/OctoML
- 2 participants
- 50 minutes

10 Jan 2022
SPEAKER: Iliya Slavutin
--
In this tutorial, I’ll walk users through creating a simple Swift-based iOS app that uses Apache TVM to run an image classification model.
- - -
Recorded at TVMCon (https://www.tvmcon.org), the Machine Learning Acceleration Conference in Dec 2021.
TVMCon covers the state of the art of deep learning compilation and optimization, with a range of tutorials, research talks, case studies, and industry presentations. We discuss recent advances in ML frameworks, compilers, systems and architecture support, security, training and hardware acceleration.
Connect with us for the latest in ML Acceleration and Deployment:
Website: https://octoml.ai
LinkedIn: https://www.linkedin.com/company/octoml
Twitter: https://twitter.com/OctoML
--
In this tutorial, I’ll walk users through creating a simple Swift-based iOS app that uses Apache TVM to run an image classification model.
- - -
Recorded at TVMCon (https://www.tvmcon.org), the Machine Learning Acceleration Conference in Dec 2021.
TVMCon covers the state of the art of deep learning compilation and optimization, with a range of tutorials, research talks, case studies, and industry presentations. We discuss recent advances in ML frameworks, compilers, systems and architecture support, security, training and hardware acceleration.
Connect with us for the latest in ML Acceleration and Deployment:
Website: https://octoml.ai
LinkedIn: https://www.linkedin.com/company/octoml
Twitter: https://twitter.com/OctoML
- 2 participants
- 14 minutes

10 Jan 2022
SPEAKERS: Andrew Reusch, Mehrdad Hessar
--
Andrew and Mehrdad are two of the core developers of the microTVM project. We’ll give a brief overview of the progress made in 2021 and talk about the bright future ahead for microTVM.
- - -
Recorded at TVMCon (https://www.tvmcon.org), the Machine Learning Acceleration Conference in Dec 2021.
TVMCon covers the state of the art of deep learning compilation and optimization, with a range of tutorials, research talks, case studies, and industry presentations. We discuss recent advances in ML frameworks, compilers, systems and architecture support, security, training and hardware acceleration.
Connect with us for the latest in ML Acceleration and Deployment:
Website: https://octoml.ai
LinkedIn: https://www.linkedin.com/company/octoml
Twitter: https://twitter.com/OctoML
--
Andrew and Mehrdad are two of the core developers of the microTVM project. We’ll give a brief overview of the progress made in 2021 and talk about the bright future ahead for microTVM.
- - -
Recorded at TVMCon (https://www.tvmcon.org), the Machine Learning Acceleration Conference in Dec 2021.
TVMCon covers the state of the art of deep learning compilation and optimization, with a range of tutorials, research talks, case studies, and industry presentations. We discuss recent advances in ML frameworks, compilers, systems and architecture support, security, training and hardware acceleration.
Connect with us for the latest in ML Acceleration and Deployment:
Website: https://octoml.ai
LinkedIn: https://www.linkedin.com/company/octoml
Twitter: https://twitter.com/OctoML
- 2 participants
- 23 minutes