24 Mar 2023
Sarina Sit and Quenton Hall provide an AMD tutorial about Apache TVM and production ML deployments.
- 3 participants
- 22 minutes

24 Mar 2023
Siva Rama Krishna Reddy & Krishna Raju Vegiraju discuss all of the Adreno GPU Performance Enhancements with the use of TVM
- 3 participants
- 5 minutes

24 Mar 2023
Andrey Malyshev and Egor Churaev from Deelvin Solutions speak about the 4x speed-up and upstreaming to TVM mainline on Adreno GPU.
- 2 participants
- 21 minutes

24 Mar 2023
Lianmin Zheng, a PhD student at University of California at Berekley, talks about Alpa - a compiler for distributed deep learning.
- 2 participants
- 25 minutes

24 Mar 2023
Si-Ze Zheng, a PhD candidate at Peking University, talks about analytical tensorization and fusion for compute-intensive operators.
- 2 participants
- 21 minutes
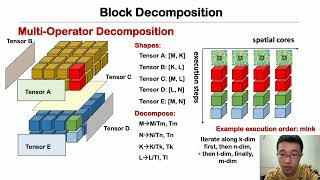
24 Mar 2023
Alexey Voronov from Deelvin Solutions speaks about reducing tuning space by cross axis filtering in AutoTVM.
- 2 participants
- 12 minutes

24 Mar 2023
Jiawei Liu, a PhD student at University of Illinois Urbana-Champaign, speaks about Automating DL compiler bug finding with NNSmith.
- 2 participants
- 13 minutes

24 Mar 2023
Vijay Thakkar from NIVIDA speaks about CUTLASS 3.0 - the next gen of composable and resuable GPU linear algebra library.
- 2 participants
- 19 minutes

24 Mar 2023
Gavin Uberti from OctoML speaks about channel folding and a transform pass for optimizing mobilenets.
- 2 participants
- 20 minutes

24 Mar 2023
Tianqi Chen, Denise Kutnick, Chris Sullivan, and Janet Schneider summarize another year of TVM community growth and TVM Unity.
- 6 participants
- 46 minutes

24 Mar 2023
Vinod Grover from NVIDIA talks about compiling dynamic shapes.
- 2 participants
- 25 minutes
24 Mar 2023
Yixin Dong and Chaofan Lin, PhD students at Shanghai Jiao Tong University, speak about cross-platform training using automatic differentiation on Relax IR.
- 3 participants
- 28 minutes

24 Mar 2023
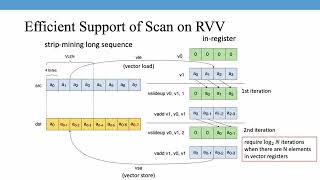
Jenq-Kuen Lee & Hung-Ming Lai from National Tsing Hua University, Taiwan discuss the efficient support of TVM on a RISC V Vector Extension.
- 3 participants
- 10 minutes
24 Mar 2023
Tiejun Chen from VMWare discusses the process of how to empower Tensorflow Serving with backend TVM.
- 2 participants
- 6 minutes

24 Mar 2023
Guyue Huang, a PhD student at University of California Santa Barbara talks about enabling data movement and computation pipelining in deep learning compilers.
- 2 participants
- 21 minutes

24 Mar 2023
Yaoyao Ding, a PhD student at University of Toronto talks in depth about Hidet and task mapping programming paradigms for deep learning tensor programs
- 2 participants
- 22 minutes

24 Mar 2023
Suryanarayana Murthy Durbhakula and Adarsh Golikeri from Qualcomm speak about improvements in the TVM OpenCL codegen for Adreno GPUs.
- 3 participants
- 20 minutes

24 Mar 2023
Ashutosh Parkhi & Grant Watson at ARM collaborate to bring improvements to CMSIS NN integration to life in Apache TVM.
- 4 participants
- 10 minutes

24 Mar 2023
Overview of changes we've made to Ethos-U55 integration in TVM, including new operators, new variants of currently supported operators, and other features. Creating CI to run neural networks on Alif Ensemble boards.
- 3 participants
- 8 minutes

24 Mar 2023
Lifan Lin and Qianshui Jiang from Intel introduce 4th gen Intel Xeon processor and BF16 support with TVM.
- 3 participants
- 26 minutes

24 Mar 2023
Bohan Hou, Ruihang Lai, and Hongyi Jin, PhD Students at Carnegie Mellon University provide a tutorial on Relax and PyTorch.
- 4 participants
- 44 minutes

24 Mar 2023
Peng Wu, Engineering Manager at Meta, brings it all together with an in-depth overview of PyTorch 2.0 and the journey to bringing compiler technologies to the forefront.
- 2 participants
- 37 minutes

24 Mar 2023
Dawn Song at Berkeley discusses what building a responsible data economy looks like.
- 2 participants
- 36 minutes

24 Mar 2023
Tejash Shah of OctoML kicks off Day 3 of TVMCon 2023 - Research & Community Discussions.
- 1 participant
- 6 minutes

24 Mar 2023
Ligeng Zhu & Ji Lin discuss On Device Training under 256KB Memory.
- 3 participants
- 19 minutes

24 Mar 2023
Giancarlo Colmenares & Kai-Ting Amy Wang from Huawei Canada discuss the benefits of optimizing SYCL Device Kernels with AKG.
- 3 participants
- 8 minutes

24 Mar 2023
An Wang from OctoML gives an introduction to The OctoML Profiler detailing the new capabilities of PyTorch Profiling.
- 3 participants
- 16 minutes

24 Mar 2023
Wenqin Xu & Hiromu Yokokura from Renesas Electronics Corporation talk about the integration between Apache TVM and Renesas Hardware accelerators.
- 3 participants
- 19 minutes

24 Mar 2023
Zihao Ye & Ruihang Lai from the University of Washington, details SparseTIR Composable Abstractions in Deep Learning.
- 3 participants
- 19 minutes

24 Mar 2023
Robert Lai & Sheng-Yuan Cheng at MediaTek gives a presentation on how to support QNN Dialect for ApacheTVM with MediaTek Neuron.
- 2 participants
- 14 minutes

24 Mar 2023
Leandro Nunes, Software Engineer at Arm, gives presentation on TVM Packaging in 2023.
- 2 participants
- 24 minutes

24 Mar 2023
Wuwei Lin & Sunhyun Park speak to the ApacheTVM Unity Pass Infrastructure and BYOC.
- 3 participants
- 31 minutes

24 Mar 2023
Wuwei Lin & Sunghyun Park from OctoML discuss the impact of TVM Unity for Dynamic Models.
- 3 participants
- 11 minutes

24 Mar 2023
Zhao Wu gives a great presentation on the intersection between TVM and NIO.
- 2 participants
- 25 minutes
24 Mar 2023
Yuan Zhao & Ajay Jayaraj from Texas Instruments talk about accelerating inferences using C7xMMA through ApacheTVM.
- 3 participants
- 15 minutes

24 Mar 2023
Wenxi Zhu, Honglin Zhu & Shuaining Pan give a great overview of the capabilities of ApacheTVM at Tencent.
- 4 participants
- 19 minutes

24 Mar 2023
Perry Gibson from the University of Glasgow, talks abut transfer tuning reusing auto schedules for efficient tensor program code generation.
- 2 participants
- 16 minutes

24 Mar 2023
Siva Rama Krishna Reddy from Qualcomm provides a tutorial about TVM on Adreno GPUs.
- 3 participants
- 39 minutes

24 Mar 2023
Mohamad Katanbaf of OctoML provides a tutorial on bringing micro TVM to a custom IDE.
- 3 participants
- 35 minutes




24 Mar 2023
Michael J. Klaiber, Paul Palomero Bernardo, Rafael Stahl, Ingo Feldner & Christoph Gerum gives a riveting breakdown of the UMA Universal Modular Accelerator Interface to help you make your hardware accelerator TVM-ready.
- 2 participants
- 9 minutes

24 Mar 2023
Falk Selker from Heidelberg University - Computing Systems Group gives an overview of how to use TVM to bring Bayesian neural networks to embedded hardwares.
- 2 participants
- 8 minutes
