►
From YouTube: Billions of NLP Inferences on the JVM using ONNX and DJL
Description
This session outlines the recently rolled out Hypefactors' MLOps infrastructure designed for billions NLP inferences a day. The workload serves media intelligence and OSINT use cases. The infrastructure is designed with a Java Virtual Machine-first approach that is enabled by ONNX interop and AWS' Deep Java Library. On top of that, we show how quantization drives further performance optimizations.
A
Hello
everyone,
so
my
name
is
viet,
I'm
the
cto
of
hype,
factors
and
hello
from
copenhagen
everyone
we
are
like
a
small
media
intelligence
company
and
with
media
intelligence.
It
means
just
a
moment
where's.
My
slide
here
ever
so
with
media
intelligence
means
that
we
are
mining.
The
media,
landscape,
ongoingly
for
all
various
use
cases
like
product
launch,
tracking
and
such
and
a
long
time
ago,
I
chose
to
base
our
infrastructure
around
the
jvm.
A
For
the
reasons
that
adam
mentioned.
In
his
talk,
also,
we
find
the
developer
experience
very
good.
You
know
this
building.
Profiler
tapping
makes
refactoring
really
nice
at
large
scale,
there's
a
high
there's,
a
big
ecosystem
of
reusable
components,
and
then,
if
you
want
to
make
your
own,
you
can
do
interoperable
to
the
ce
foreign
function.
Interface
and
we've
built
like
a
whole
web
crawler
around
it
across
8
million
sites
and
all
our
data
pipelines
are
the
consequence
built
around
it.
A
So
like
how
that
looks
in
our
infrastructure
today
is
that
we
get
all
these
all
these
different
data
sources.
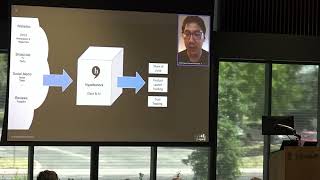
My
websites
printed
newspapers
and
magazines,
television
and
radio
broadcast
and
social
media
posts
into
our
system,
and
we
turn
it
into
business
solutions
like
product
launch
tracking.
We
track
also
trust
and
reputation
or
share
voice,
to
see
how
I,
how
you
are
faring
compared
to
your
competitors
and
there's
much
more,
that
you
can
actually
mine
out
of
the
media
landscape,
because
it's
like
an
ongoing
information
generation
engine
now
under
the
hood.
A
A
We
did
it
with
api
because
it
was
faster
way
to
do
it,
but
then
we
started
to
make
our
own
first.
Our
models
had
to
to
customize
and
to
be
more
spot-on
with
these
enrichments
and
now,
we've
grown
to
such
a
point
that
we're
practically
now
enriching
50
of
our
data
intake.
So
we
are
now
migrating
to
a
system
that
principally
enriches
all
data
that
comes
in,
and
that
leads
us
to
a
new
big
engineering
problem
because
we
calculated
it.
It
goes
into
like
a
few
billion
in
gpu
inferences
per
day.
A
A
A
But
now
we've
reached
a
scale
where
that
didn't
suffice
anymore
and
also
to
horizontal
to
scale
it.
We
looked
at
the
cubenated
system
to
do
that.
The
system
was
launched
last
week,
so
it's
running
it's
humming
right
now.
It's
now
yielding
at
peak
loads
over
nearly
a
billion
inferences
a
day,
and
it
was
quite
a
challenge
along
the
way
to
get
it
running.
A
First
of
all,
we
needed
to
make
it
economical,
so
we
looked
a
lot
of
quantization,
which
is
usually
our
go-to
approach,
initially
to
eight
bits,
but
we
in
this
case
for
this
model,
we
noticed
it
was
we
we
lost
too
much
on
the
effectiveness
of
the
model.
16
bits
seems
to
be
the
switch
spot
where
we
got
like
a
three
percent
gain
three-time
game
over,
not
quantizing
it.
A
We
also
ran
into
conversion
errors
onyx
to
fighters
to
only
conversion
error,
so
suddenly,
like
the
onyx
model,
would
yield
not
a
number
for
the
same
input,
whereas
the
pythos
model
wouldn't,
and
we
saw
that
actually
having
for
specific
queued
drivers
as
well.
So
it
was
a
little
bit
like
figuring
out.
What's
going
on,
we
figured
out.
It
was
in
the
end,
because
one
layer
was
converted
correctly,
so
we
we
decided
not
to
quantize
that
layer
and
that
fixed
it
all
for
us.
A
Another
thing
was
memory
leaks
as
soon
mentioned.
Gtl
is
indeed
I
can
also
speak
from
our
own
experience
very
robust,
and
yet
we
were
unfortunate
enough
to
to
hit
like
a
very
rare
memory
league
in
detail
and
it
took
us
a
while
to
hunt
around
hunted
down.
We
replaced
many
mellow
implementations
to
profile
that,
after
a
while,
we
figured
it
out
and
also
really
happens,
because
we
do
quite
a
lot
of
pre
and
post
processing,
and
so
it
was
tricking
quite
fast
and
basically
was
unstable
in
our
production
environment.
A
To
do
that,
then
we
will
get
alerted
based
on
that.
So
what
we're
looking
next
is
increasing
gpu
efficiency
of
our
system.
Right
now
we
seem
to
be
used
around
10
to
20
of
the
gpu,
not
sure
exactly
how
that
is
measured
that
so
we
need
to
dig
into
that,
but
we
we
have
managed
to
push
it
sometimes
to
50
percent.
So
maybe
it's
a
matter
of
let's
say
using
a
tensor
rt
engine
and
loading
the
onix
models
directly
into
it.
We're
also
looking
to
add
more
models.