►
Description
00:00 Arch & Infra - Liqun Fu, Microsoft
05:17 ONNX Operators - Ganesan “Rama” Ramalingam, Microsoft
14:33 Converters - Kevin Chen, NVIDIA
23:08 Model & Tutorials - Jacky Chen, Microsoft
31:49 Pre-processing - Joaquin Anton, NVIDIA
A
Good
morning,
everyone
thanks
for
coming,
and
there
has
been
two
onyx
releases
since
we
last
made,
and
the
latest
one
was,
is
112
done
by
ibm.
So,
let's
give
it
a
round
of
applause.
Contributors
have
many
had
added
many
new
features
to
onyx
and
the
kpop
making
are
better
cheap
influence
has
removed
at
operator
level.
A
contact
lender
able
to
handle
impact,
not
missing
optional
error.
Checking
for
incorrect
permutation
was
added
for
transpose
chip,
influence
for
consonant
of
shape
is
simplified
and
the
shape
influence
for
expand
was
improved,
such
that
symbolic
shape
is
used.
A
Data
and
the
shape
are
now
utilizing
results
from
data
propagation.
This
last
improvement
was
made
possible
by
extending
chip
info
shift
api
to
expose
results
from
data
propagation.
It
helps
high
touch
exporter
to
utilize,
onyx
chip
influence
functionality
and
chip
influence
for
local
functions
was
added
in
release
111
and
the
further
enhanced
in
the
latest.
One
power
release.
A
A
A
It
is
impossible
in
this
presentation
to
list
all
the
improvements
made
by
contributors.
Here
is
just
a
sheltered
or
only
shortened.
Release
initiators
are
decoupled
with
inputs
such
that
the
virtual
converter
can
reliably
convert
models
across
any
offset
versions
and
with
a
few
additional
bug,
fixed
model
converter
has
become
more
stable.
A
A
In
the
next,
we
plan
to
provide
a
better
support
for
our
mixed
releases.
We
realized
that,
from
our
experience
that
the
major
risk
factor
for
release,
delay
was
due
to
breaking
changes
that
were
detected
by
the
runtime
are
building
really
so
to
eliminate
this.
We
will
plan
to
to
provide
a
ci
pipeline
for
the
runtime
could
be
packed
to
automatically
detect
any
breaks,
changes
while
doing
a
release,
and
so
that
early
action
can
be
taken,
and
we
will
also,
you
know,
continue
with
our
focus
on
shape,
influence,
improvement.
B
B
C
B
The
last
two
releases,
so
in
terms
of
the
new
ops
introduced,
we
have
grid
sample
which
is
used
in
spatial
transformer
networks,
a
layer
normalization
which
is
widely
used,
for
example,
in
language
models,
lectures
but
signal
processing,
ops
where
basically
dftr
fft.
They
have
been
widely
requested
and
they
are
used
in
audio
models
and
sequence
map,
which
was
proposed
by
the
pre-processing
work
group,
which
enables
us,
for
example,
to
handle
batches
of
images,
for
example,
of
varying
sizes.
B
B
So
yeah,
let
me
in
the
remaining
few
minutes.
Let
me
describe
some
of
the
plans
going
forward
and,
as
I
remember,
the
key
goal
for
the
operator's
seg
is
primarily
to
have
a
clear
and
unambiguous
specification
and
there
is
room
for
improvement
here
and
we
do
need
to
improve
their
documentation
for
their
spec
for
various
ops
and
as
to
the
remaining
goals.
B
So
there's
a
tension
here
and
we
basically
need
to
strike
a
balance
between
these
two
and
one
of
the
key
techniques
we
use
to
deal
with
this
challenge
is
the
notion
of
onyx
functions
and
an
onyx
function
is
essentially
an
onyx
op,
whose
semantics
is
specified
by
in
terms
of
other
primitive
ops
so
effectively.
This
function
definition
provides
an
executable
specification
for
the
thereby
improving
the
clarity,
reducing
ambiguity,
but
it
also
provides
a
default
implementation
so
that
it
makes
it
easy
to
build
a
new
backend.
B
B
Proto,
which
is
the
serialized
ir
representation
for
functions
in
onyx,
and
the
plan
is
to
also
allow
use
this
as
a
way
to
debug
using
first
standard
python
debugs,
for
example,
the
definitions
of
functions
and
to
understand
them,
and
so
the
plan
is
to
use
a
subset
of
python.
We
call
ionic
script
to
enable
all
of
this.
B
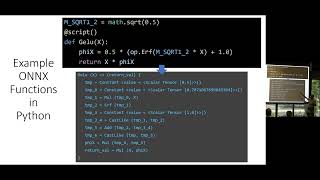
So
let
me
give
some
example
couple
of
a
few
examples.
So
yeah
here
you
see
a
function,
definition
in
python
for
the
well-known
activation
function,
and
so
the
plan
is
so
so
the
we
define
the
function
in
python
this
way
and
the
converter
will
automatically
generate
the
cellular
function.
Definition
and,
as
you
can
see,
in
onyx,
the
real
function
definition
expands
into
a
lot
more
operators
and
is
less
readable.
But
the
compact
specification
is
easier
to
author
and
also
to
read
and
understand
so.
B
And
so
this
is
another
example
that
illustrates
the
use
of
control
flow.
So,
for
example,
a
dropout
which
is
a
standard
up
in
the
python
spec
can
itself
be
specified
as
a
function
on
top
of
a
random
uniform
generation
and
again,
the
use
of
control
flow
makes
it
python.
Control
flow
makes
it
easier
to
naturally
and
compactly
specify
this
semantics
of
these
obs
as
a
function.
B
And
so
this
just
illustrates
the
use
of
standard
debuggers
to
understand
these
function.
Definitions
too.
So,
for
example,
here
you
have
a
tie.
Example:
python
definition
of
an
onyx
function
and
you
executed
just
like
you
would
execute
in
a
standard
python
by
creating
some
inputs
and
invoking
the
function,
and
you
can
use
the
debug
to
look
at
the
values
and
understand
the
specs.
So.
B
So
yeah,
these
are
just
some
more
examples
for
people
interested
just
to
show
how
various
existing
onyx
ops
can
be
compactly
specified
yeah.
I
think
so.
That
brings
me
to
into
the
end
and
thanks
for
coming
and
please
do
get
involved
with
the
operator
sig,
as
shown
here,
there's
a
slack
channel
and
we
have
monthly
sig
meetings
that
you
can
join
and
and
we
welcome
your
contributions.
D
Okay,
great
yeah.
Unfortunately,
I
cannot
make
it
to
the
meeting
in
person,
but
it's
great
to
see
you
know
all
the
participants
here.
So
my
name
is
kevin.
I've
been
involved
in
the
honest
community
for
the
past
couple
of
years
and
today
I'll
be
giving
an
update
for
the
converter,
sig
and
all
the
work
that
we've
done
since
the
last
side.
We've
met
so
for
the
outline
of
this
presentation
I'll
be
going
over.
The
converter
update
so
first
I'll
be
going
over
the
front.
D
End
converter
updates,
which
mainly
deal
with
dll
framework
into
onyx
model
conversion
and
for
these
front
end
converters
I'll
be
going
over
the
pytorch
onyx
tensorflow,
onyx
and
sk
learn
to
onyx
converters
that
we
have
next
I'll
be
going
over
the
back-end
converter
update.
So
these
back-end
converters
mainly
deal
with
onyx
model
format,
translate
them
into
a
back-end
runtime
framework
where
actual
inference
is
run
on
the
onyx
model
and
for
these
backing
converters
I'll
be
going
over
the
onyx
tensor
rt,
as
well
as
the
onyx
tensorflow
converter.
D
Next
up
I'll
be
going
over
the
road
map
for
the
converter,
stick
and
finally,
there'll
be
a
get
involved
slide
for
those
of
you
that
wish
to
participate
in
the
converter.
Stick
anytime
after
this
meeting,
so
the
first
converter
I
would
like
to
go
over
is
the
pi
portion
on
its
converter.
So
the
latest
release
that
will
be
coming
out
very
soon
is
pytorch
version
1.12,
which
supports
onyx
exports
up
to
onyx
offset
16..
D
So
there
has
been
a
bunch
of
new
features
added
in
this
release,
and
some
of
the
highlights
include
the
ability
to
export
neural
network
modules,
specifically
as
onyx
vocal
functions,
and
this
allows
specific
back-ends
to
target
these
functions
specifically
for
accelerated
inference.
There
has
also
been
a
lot
of
new
off
support.
D
You
can
see
the
full
list
listed
there
and
we've
also
added
the
ability
to
export
onyx
before
16
and
optional
data
types,
as
well
as
added
support
for
exporting
quantized
models,
along
with
exporting
model,
train
and
mixed
precision
with
apexel2,
so
for
any
users
that
are
working
with
these
new
data
types
or
working
with
quantized
or
mixed
precision
models.
We
recommend
you
to
try
out
the
new
pytorch
exporter
and
see
the
updated
workflow
into
converting
to
onyx.
D
So
the
highlights
here
is
that
the
default
offset
export
version
has
been
updated
to
13
and
there
are
a
few
new
ops
that
are
now
able
to
be
exported,
including
tfla
batch
map,
moles,
t
of
light
map,
mall
sensor,
scanner
ad
and
random
int.
In
addition,
we've
improved
model
export
for
q2q
model,
as
well
as
general
improvements
for
export
for
models
trained
in
ts
lite.
So
again,
if
you're,
using
qdq
models
or
if
you're
using
cs
lite,
we
recommend
checking
out
the
latest
release
for
the
updated
workflow
into
exporting
to
onyx.
D
Next
up
is
the
sk
learn
to
onyx
converter.
The
latest
release
here
is
sk
learner,
onyx
1.11.2,
which
supports
onyx
export
up
to
offset
15..
The
highlights
here
is
that
we've
added
a
new
up
support
for
sgd
one
class
svm.
We
have
also
a
bunch
of
bug
fixes
for
previously
supported
ops,
as
well
as
improved
library
input
performance
across
the
board.
So
we
recommend
users
to
update
to
the
latest
version
or
improve
user
experience
when
converting
scaler
model
into
on
it.
D
D
Honestly
tensorflow
actually
supports
the
entire
offset
15
offspec
at
least
partially,
as
well
as
supporting
onyx
optional
data
types
so
again
for
any
users
with
models
that
are
using
offset
15
or
lower
and
are
using
optional
onyx
optional
data
types.
We
recommend
using
the
latest
version.
I
wanted
to
tensorflow
to
import
your
model
and
do
any
new
benchmarking
there.
D
As
for
the
roadmap,
the
converter
stick
had
a
few
short
term
and
medium
term
level
goals.
So
for
the
short
term,
we
wanted
to
improve
our
onyx
operator,
documentation,
support
matrix
across
all
of
the
converters,
and
this
has
been
done
over
the
past
year
across
august
converters.
So
this
is
a
very
good
improvement
for
the
medium
term
goals.
There
are
two
main
things
that
we
want
to
focus
on.
D
Finally,
there
is
a
perpetual
goal
across
all
all
converters
to
constantly
improve
both
in
terms
of
buck
fixes
and
improve
operator
and
offset
support
and
for
pythor.
Specifically,
one
big
item
on
the
roadmap
is
that
improved
support
for
pytorch
models
with
lazy,
tensor
and
auto
grad
functions
are
in
the
work,
so
definitely
beyond
the
outlook
for
that
so
finally
feel
free
to
get
involved.
D
So
any
quick
feedback
feel
free
to
join
us
on
slack
in
the
honest
converters,
channel
and
drop
by
a
quick
comment
or
start
a
thread
for
those
that
want
to
get
involved.
A
little
bit
more
in
depth
feel
free
to
subscribe
to
our
honest
converter,
sig
mailing
list
where
we
send
out
invites
for
monthly
meetings.
So
please
subscribe.
If
you
want
to
get
involved
in
that,
and
finally,
we
have
a
very
a
very
amazing
community
across
all
the
converter.
D
Repos,
don't
feel
shy
to
open
up
issues
or
start
discussions
across
github,
because
we
always
welcome
new
contributions
and
new
discussion,
and
we
are
very
welcome
welcoming
to
any
users
that
want
to
get
involved
in
onyx.
So
thank
you.
That
concludes
the
onyx.
Converter
sticks
for
updates
for
today.
Thank
you
all
for
listening.
C
C
C
So
they
don't
have
the
shaping
bands
function.
So
we
cannot
verify
in
onyx.
Otherwise
they
are
all
passed
by.
The
latest
release,
honest
1.2,
and
next.
One
thing
I
would
like
to
highlight
is
that
recently
we
fixed
a
lot
of
broken
test
data
set
in
onyx
monozu.
So
right
now
that
we
have
verified
that
all
the
models
most
of
the
honest
model,
zoom
models
can
pass
on
its
wrong
time
with
cpu
per
rider
and
there's
one.
Only
one
model
failed.
C
C
So
in
meanwhile,
for
honest
model,
zoo
like
we
can
also
like,
have
a
link
to
redirect,
like
certain
rx
module
models
to
hawking
space,
and
you
can
show
some
demo
there
and
in
they
have
a
tutorial
like
how
to
do
it
in
their
gradual
websites
and
in
microsoft.
We
also,
I
have
also
just
published
a
blog
in
our
microsoft,
open
source
cloud.
C
C
Then
I
will
talk
about
honest
tutorials,
so
yeah
for
online
studios.
Mainly
we
like,
we
finally
introduced
the
c
idea,
because
there's
there
are
a
lot
of
dedicated
urls
so
like
right.
Now,
if
you
publish
a
new
notebook
or
document
there,
we
will
in
the
ci
it
will
automatically
to
to
if
it
will
validate
the
urls
for
new
prs
and
also
that
we
are
weekly
to
go
through
the
whole
wrap
pose
to
check
all
urls
there.
C
Just
in
case
that
some
url
is
dedicated,
and
also
we
run
some
python
formatters
to
clean
the
notebook
and
yeah
for
the
roadmap.
I
think
here
is
just
like.
We
want
to
keep
polish,
the
old
tutorials
and
in
the
future
I
I
think
we
will
prefer
like
uil
redirections
to
other
tutorials,
okay
yeah,
so
that
that's
why
I
I
want
to
like
say,
welcome
to
contribute
and
actually
the
contribution
of
the
new
rx
module.
C
Run
by
ort
impress
with
cpu
and
get
the
right
result.
Then
your
pr
is
ready
to
go
so
yeah.
If
you
have
any
topics
you
want
to
bring
up,
feel
free
to
join
us
on
slack,
there's
a
channel
called
like
onyx
monozu
and
please
help
us
to
review
the
prs.
There
are
a
few
openings
and,
most
importantly,
I
I
was
looking
for
more
volunteer
approvers
for
sick
model
tutorials.
C
E
E
E
E
E
E
E
E
E
To
enable
this
pattern,
we
propose
the
sequence
map
operator
sequence.
Map
is
a
generic
sequence
processing
operator
that
can
apply
a
graph
to
each
element
in
an
input
sequence
producing
a
sequence.
As
an
output,
we
can
use
sequence
map
to
apply
our
preprocessing
graph
defined
on
a
one
sample
basis
to
a
batch
of
samples.
E
E
E
The
second
extension
is
a
keep
aspect:
ratio
policy
that
changes
the
interpretation
of
the
target
size.
The
policy
can
be
to
stretch
ignoring
the
original
aspect,
ratio,
which
is
currently
the
default
behavior
or
it
can
be
to
treat
the
target
size
as
either
a
maximum
or
a
minimum
size,
while
keeping
the
original
aspect
ratio.