►
Description
No description was provided for this meeting.
If this is YOUR meeting, an easy way to fix this is to add a description to your video, wherever mtngs.io found it (probably YouTube).
A
A
The
problem
we
are
trying
to
solve
at
fiddler
is
that
ai
and
machine
learning
teams
are
flying
blind
when
it
comes
to
deploying
models
to
production,
they're
suffering
from
more
four
main
problems.
One
is
models
are
a
black
box
and
they
want
to
have
transparency
into
them.
Number
two
model
performance
can
drift
over
time
and
especially
with
corona,
whereas
lots
of
teams
have
experienced
this
model
performance
drift
problem
and
they
want
to
monitor
these
models
continuously
and
then
models
can
carry
bias,
especially
affecting
certain
ethnicities
or
certain
genders.
A
A
Here
the
problem
we
are
trying
to
solve
is
not
just
helping
the
data
science
teams,
but
also
helping
you
know
a
lot
of
other
teams
connected
to
them:
the
business
users,
the
customer
support
teams,
the
it
operations
teams.
They
all
have
questions
about
these
models.
How
do
they
work?
Can
I
trust
them?
You
know
how
do
I
monitor
them,
but
we're
basically
building
a
platform
to
satisfy
these
questions
around
that
are
coming
up
around
these
black
box
models
today,.
A
Here's
our
background.
We
all
come
from
tech
companies
in
the
bay
area.
I
was
an
engineering
lead
at
facebook,
working
on
explainable
ai,
for
news
feed,
where
we
built
a
lot
of
monitoring
and
diagnostics
tools
for
newsfeed
and
that's
how
the
team
got
formed
and
we've
been
working
towards
this
mission
of
building
trust
into
ai,
making
ai
explainable
and
monitor
it
continuously
for
for
a
wide
variety
of
enterprise
companies
out
there.
A
B
B
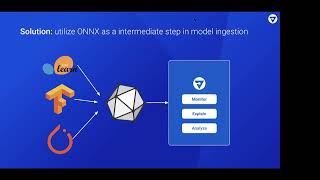
So
we've
we
ran
into
this
example,
specifically
with
scikit-learn,
where
certain
versions
were
working
for
us
and
certain
versions,
weren't
working
for
us
in
our
same
core
platform,
and
so
our
solution
was
to
use
onyx
right.
We
want
to
be
able
to
have
this
nice
middle
ground
where
we
say:
okay,
no
matter
what
kind
of
model
the
customer
comes
with.
We
have
onyx
sitting
there
in
the
middle.
We're
able
to
convert
the
model,
create
a
uniform
model
type
and
then
absorb
it
all
the
same
into
the
platform,
and
it
gives
the
customers
a
sales
experience.
B
They
don't
need
to
be
aware
of
the
inner
inner
workings
of
our
system.
They
just
get
to
put
the
model
into
production
and
have
us
monitor,
explain
and
analyze
it,
and
so
we're
gonna
show
you
a
demo
just
a
bit
of
how
fiddler
has
been
able
to
use
onyx
to
to
boost
its
core
functionality
and
to
create
a
more
seamless
experience.
Some
things
that
we
have
for
the
future
is
we'd
like
to
do
some
more
automated
conversions
right.
B
We
have
this
great
fiddler,
client
library,
that
our
customers
are
using
and
we
like
to
have
onyx
function
now
to
be
more
plugged
into
our
client
library,
so
that
customers
are
able
to
provide
any
type
of
type
of
model,
run
a
quick
few
lines
of
code
and
get
an
onyx
model
that
can
be
used
in
fiddler.
Furthermore,
we'd
like
to
add
more
support
for
more
of
the
converters
that
are
community
driven
surrounding
onyx.
B
So
there's
a
lot
already
out
there
we'd
like
to
support
more
of
them
and
beyond
that
we'd
like
to
also
support
custom
model,
converters,
all
part
of
fiddler,
client,
library
and
so
yeah.
Those
are
the
three
things
we'd
like
to
do,
and
so
now
we'd
like
to
go
ahead
and
show
you
a
quick
demo.
It's
our
quick
start
notebook
for
customers
of
how
fiddler
uses
onyx
to
to
create
more
seamless
experience.
So
we're
gonna
run
just
a
few
of
these
basics.
B
Basic
imports,
we're
going
to
use
psychic,
learn
version,
2,
24.1,
we're
going
to
use
our
fiddler
client
library
we're
going
to
set
up
a
few
base
constants,
so
we're
going
to
use
an
auto
insurance
data
set,
as
in
our
example,
and
we're
going
to
separate
our
data
set
out,
we're
going
to
then
upload
our
data
set
and
we're
going
with
using
the
fiddler
client
library.
Now
we're
going
to
do
is
we're
going
to
set
up
a
model
info.
B
We're
going
to
convert
our
inputs
now
we're
going
to
create
our
actual
model
using
onyx
converting
our
scaler
and
pipeline
from
here.
We're
going
to
now
create
this
model
directory
that
we're
going
to
use
to
upload
all
of
our
assets,
we're
going
to
create
a
model
onyx
file
and
we're
going
to
create
a
model
yaml
file.
B
So
fiddler
uses
this
concept
of
the
package
py
file,
it's
a
way
of
describing.
How
does
our?
How
does
my
model
take
in
data
and
how
does
it
create
a
prediction?
And
so
you
can
do
all
these
great
converters
kind
of
in
this
middle
part
where
our
our
back
end
systems
will
use
this
file
to
create
a
custom
kind
of
prediction
pipeline
for
your
model,
and
so
we're
gonna
use
the
honest
runtime
package
which
we're
gonna
to
take
our
model.
B
Take
the
data
in
all
the
same
and
then
make
a
prediction
with
it.
So
the
customer
doesn't
really
need
to
be
aware
of
exactly
how
the
prediction
is
being
made,
we're
going
to
run
our
custom
package
validator
and
make
sure
everything's
running
seamlessly
before
you
upload
into
the
system.
It
creates
a
more
seamless
and
less
kind
of
trying
experience
for
the
back
end
as
well.
B
Great
predictions
are
triggered
now
we
can
actually
test
that
we
can
take
a
prediction,
a
slice
of
our
inputs
and
we
can
just
make
sure
they're
running
correctly,
and
we
can
see
that.
Yes,
we
have
a
correct
set
of
predictions
now,
let's
head
over
to
the
fiddler
ui
and
let's
take
a
look
really
quick
at
our
actual
model
in
our
system.
So
if
we
refresh
our
page,
we
can
see
that
we
now
have
a
quick
start.
B
Onyx
gradient,
boosting
project
with
a
single
model
in
there
we
can
head
in
here-
and
we
can
see
all
of
our
information
is
all
the
same.
Despite
being
an
sklearn
model,
we
are
able
to
track
it
all
the
same.
We
can
head
over
to
our
analyze
tab
and
we
can
run
a
slice
query
and
we
can
see
all
of
our
predictions
here
and
what
fiddler
is
able
to
do
now
is
we
can
take
any
of
these
predictions
and
we
can
explain
it
so.
A
Can
you
explain
it
here?
What
fiddler
is
showing?
You
is
a
shapley
value
explanations
for
that
prediction.
It
provides
this
human
risk
human
readable
explanations
of
what
make
what's
making
this
customer
lifetime
value
higher
number
of
policies,
employment
status,
vehicle
size.
You
can
also
look
at
the
attribution
view
where
you
can
present
this
information
in
a
tabular
format,
which
features
are
actually
negatively
hurting
the
you
know,
customers,
lifetime
value
and
their
predicted
customer
for
item
value
and
which
features
are
actually
you
know
positively
increasing
them.
A
So
that's
how
you
can
use
the
explainability
to
you
know,
reason
about
the
predictions
and
be
able
to
understand.
You
can
also
do
what,
if
analysis
and
whatnot
so
that,
basically,
you
know,
completes
our
demo
in
terms
of
how
we
use
onyx,
to
you,
know,
import
the
models
into
fiddler
import,
a
variety
of
models
and
help
them
to
be.
You
know,
make
them
available
for
explainability
and
monitoring
and
hope
you
enjoyed
this
demo.
Thank
you
so
much.