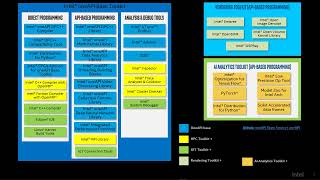
►
From YouTube: 006 ONNX 20211021 Kuah ONNX and OneAPI for xPU
Description
Event: LF AI & Data Day - ONNX Community Meeting, October 21, 2021
Talk Title: Intel® OneAPI software stack: ONNX Support for xPU hardware
Speaker: Kiefer Kuah (Intel)
A
A
The
different
architectures
of
these
xpus
present
a
challenge
to
developers.
I
mean
it's
great
to
have
all
these
different
devices
and
you
know
their
strengths
for
different
apps,
but
with
these
many
heterogeneous
devices
developing
for
them
is
challenging
and
and
to
develop
them
your
code,
the
apps
optimally,
it's
it's
even
more
challenging,
right
and
and
also
the
other
thing
is
not
just
xps,
but
with
every
new
generation
of
these
xpu's
there'll
be
new
instructions
and
new
technology.
A
You
have
to
constantly
be
updating
your
code,
so
development
cost
time
and
effort
will
will
grow
very
quickly.
So
one
api
was
conceived
to
alleviate
some
of
this
cost
and
effort.
It
won't
completely
remove
you
know
100,
all
of
that,
but
it
will.
It
will
lower
that
cost
and
the
effort
and
time
needed
to
develop
code
for
each
of
this
xpu.
A
A
These
are
highly
optimized
for
kernels
and
another
one.
I
guess
the
last
one
I'll
highlight
is
the
one
ccl
it
provides.
Primitives
for
communication
patterns
that
occur
in
deep
learning
applications
so
that
this
can
be
used
to
support
scale
up
for
platforms
with
multiple
one
api
devices
or
scale
up
for
clusters
with
multiple
computer
nodes.
A
This
library
supports
key
data
type
formats
that
are
used
in
deep
learning,
such
as
fp16
fp32,
vfloat16
and
int8,
and
it
implements
a
variety
of
operations.
Computationally,
computationally,
intensive
and
prevalent
in
dl
graphs
and
such
as
convolution
and
matrix
multiplication
intel
has
added
deep
learning
instructions
such
as
dl
boost
in
the
cascade
cpus.
A
A
A
So
we
have
done
sorry,
so
this
is
sort
of
an
ongoing
work
and
we
have
done
some
of
that.
Some
of
the
features
have
been
added.
Some
more
features
we
added
into
the
one
dnn
runtime
execution
provider,
if
onyx,
rent
in
onyx
runtime
so
last
year,
that
was
support
for
32-bit
fp323
floating-point
data
type.
It
was
supporting
inference.
It
was
supporting
a
convolutional
network
as
well
as
cpu.
It
did
not
have
gpu
support
at
that
time.
A
We
added
the
gpu
support
and
currently
we're
also
adding
support
for
nlp,
basically
ops
in
the
execution
provider
for
nlp
transformer
models
and
we're
also
getting
support
for
training.
Since
onyx
is
beginning
to
support
some
training
ops
as
well,
and
we're
also
beginning
to
support
integrate
data
types
and
potentially
other
data
types
as
well
in
the
future.