►
From YouTube: 2023-01-12 meeting
Description
cncf-opentelemetry meeting-2's Personal Meeting Room
A
A
B
A
A
A
A
The
context
here
is:
they
gave
us
the
end
of
the
year
like
last
week
to
kind
of
like
fiddle
around
and
do
anything
they
wanted
for
a
hacky
kind
of
whatever
and
I
I
had.
In
my
mind,
the
open
discussion
about
we've
called
it
t
value
or
some
some
way
of
encoding,
a
non-power
of
two
or
threshold
for
sampling,
span
IDs
and
choice
ideas.
A
A
Hopefully
we
wrote
up
the
spec
a
year
and
a
half
ago-ish
about
p-value
and
R
value
and
speculated
that
if
there
were
a
random
bit
in
the
state
the
the
trace
context,
we
could
use
it.
So
we've
discussed
a
few
ideas,
but
I
wanted
to
flush
it
out
a
little
bit
in
a
way
that
made
it
more
concrete
for
me.
So
this
is
it
one
of
the
I
wrote,
wrote
These
requirements,
I
kind
of
made
this
up,
but
I
think
this
is
a
good
starting
point
for
us.
A
The
exact
representation
part
here
means
I,
don't
want
to
make
any
confusion
over
converting
to
and
from
floating
points
and
decimal
representations
being
non-exact,
for
example,
and
this
part
about
encoding
easily
is,
is
essentially
try
and
keep
what
we
have
with
p-value.
When
I
see
P2
I
know
it
means
25,
because
I
can
do
base
2,
math
really
fast.
A
It's
not
a
common
representation
that
most
people
read,
but
after
you've
worked
in
floating
point
for
a
bit.
This
looks
normal.
So
this
is
my
52-bit
significant.
This
is
my
binary
exponent
and
so
on-
and
this
is
this
is
useful
to
me
and
and
I
I
kind
of
arrived
at
this
working
through
it
in
a
far
more
tortured
manner.
A
We
have
52
bits
of
significant
in
our
probability
score
and
we
can
just
compute
a
filter
really
easily
I
worked
this
out
twice
once
I
did
it
with
like
bit
shifting
and
all
the
tricks
that
one
is
familiar
with
if
they're
written
in
C
or,
like
you
know
your
your
floating
Point
standard
and
the
other
one
I
did.
If
you
just
wanted
to
use
the
printf
library,
you
can
almost
just
get
away
with
that
and
I
wanted
to
show
you
both
of
that
those
approaches.
A
A
And
now
I
compute
a
threshold
by
taking
the
next
value
down,
which
is
to
subtract
1
in
the
50
from
the
57
bit
number.
So
that's
a
56-bit
number
and
now
I,
just
truncate
and
the
way
I
encoded
this.
This
is
a
discussion
point
or
an
option,
but
I
I
count.
The
number
of
leading
zeros
and
I
put
that
at
the
end.
So
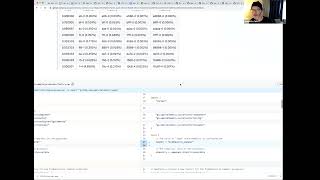
this
is
a
one
hex
digit
Precision
sampling
threshold
with
zero
trailing
with
zero
leading
zeros
and
I.
A
Have
two
I
can
bracket
my
exact
number
0.9
by
either
e
or
F,
it's
somewhere
in
the
middle
and
I
so
to
a
first
for
to
a
first
approximation,
which
is
four
bits
of
information.
I
can
use
either
e0
e-0
or
f-0
to
approximate
sampling.
Point
nine,
but
either
way
that's
an
exact
number,
so
I
can
get.
The
point
is
I
can
get
exactly
87.5
percent
if
I
want
a
single
digit
of
precision
or
I
can
get
93.75.
A
A
A
A
I'm
looking
for
my
processor,
here's,
the
traces
processor,
so
I
I
modified
the
probabilistic
sample
processor
I,
didn't
I,
didn't
write
anything
from
scratch
here,
I
just
modified
it.
Currently,
it's
using
a
like
a
coin
flip
of
its
own,
but
if
you
assume
that
the
seven
bytes
of
right,
most
bytes
or
the
least
significant
bytes
of
the
trace
ID
are
random,
then,
where
is
it?
I
need
to
not
I
need
a
compare
function
here.
A
It
is
so
the
body
of
the
the
main
body
of
this
sampling
filter
in
the
in
the
collector
does
used
to
look.
It
used
to
look
like
this
we're
throwing
that
away
and
I'm
doing
a
simple
thing.
Literally.
All
I'm
doing
is
calling
bytes
compare
with
my
seven
bytes
of
Trace
ID
and
the
low
threshold,
so
I
chose
the
smaller
probability
and
I
have
a
function
that
can
print
it,
which
is
what
I
use
to
demon
to
build
the
table,
but
I
also
I,
think
I
wrote
a
test.
A
No
I
didn't
write,
I
wrote
so
I
wrote
some
code
to
compute
it.
That's
what
I
want
to
find
for
y'all.
Oh
here
it
is
so
calculate
from
a
string.
It
parses
it
as
a
I
actually
tried.
This
was
me
experimenting
for
hackathon,
so
I,
either
partially
as
a
rational
number
or
as
a
floating
Point
number
using
the
big
number
Library,
so
that
I
can
get
exactly
50
56
bits
to
Precision.
A
For
my
little
table
there
I
subtract
one
just
as
I
described
by
doing
I
hate
using
big
numbers,
but
they
work.
They
work
so
just
get
so
anyway.
I've
subtracted
one
from
the
number
as
a
two
as
a
57
bit
number
a
test
for
zero,
so
I
didn't
cover
the
boundary
condition
of
like
the
number-
that's
just
a
boundary
of
56
bits
of
sampling,
so
this
number
is
smaller
than
one
to
the
50s
negative
52.
A
The
negative
56
can't
be
sampled
here
and
we
should
recognize
that
and
then
I
count
the
number
of
leading
zeros
and
misspelling.
Apparently
thank
you
and
then
I
shift
by
the
number
I
shift
away.
Those
zeros
I'm
doing
this.
All
in
as
I
said
bit
shifting
techniques
and
then
I,
you
know
I
did
some
stuff.
This
is
like
this
needs
a
test
or
two
but
any
case.
I.
A
The
very
final
part
of
my
presentation
here
is
that
I
put
in
another
link
here
showing
how
you
can
do
this
calculation
just
using
the
printf
library,
because
the
printf
library
can
compute
that
57
56
bit
or
52-bit
threshold
for
us.
If
we
Pat
it
correctly,
you
can
use
the
math
next
after
function
to
do
that
subtraction
step.
C
Using
52
bits
out
of
the
56
random
bits,
so
actually
we
do
not
use
four
bits
right
for
this
approach
right,
which
is
completely
fine,
yeah,
so
I'm
just
wondering
what
you
would
propose,
or
how
would
you
define
the
T
value
then?
Would
the
T
value
be
the
the
filter,
which
is
actually
an
integer
number
right?
So
basically
it
everything
translates
to
an
integer
comparison
at
the
end
that
you're
just
comparing
the
the
seven
bytes
part
of
the
tree
city
with
the
filter
right
so
and.
A
C
A
Kind
of
the
question
I
so
first
of
all,
I
I
was
thinking.
We'd
stick
with
the
Trace
State
approach.
Although
I
I
know
there
are
some
vendors
who
think
it's
a
little
bit
overwrought
and
that
we
should
just
put
an
attribute
on
a
span
of
the
sampling
or
just
account.
That's
an
independent
question
to
me.
What
I?
A
Sorry
there's
if
you
start
with
a
probability
number
as
a
string,
you
get
and
it's
not
exact.
You've
got
two
options
and
I've
always
chosen
the
lower
for
for
just
to
make
an
arbitrary,
but
you
can
choose
the
upper
make
it
work
as
well,
and
that
gives
me
this
and
then
I
and
I
choose
Precision,
which
is
an
independent
question
which
is
like
and
then
I
encode.
This
string.
A
This
string
exactly
equates
with
what
you
described
the
integer
equation
or
the
integer
formulation,
but
it's
just
slightly
compressed
and
the
other
way
you
could
represent
this
easier.
E-0
is
simply
just
e
because
it's
got
no
no
leading
zeros,
but
if
you
get
down
to
like
numbers
here
where
I
said
15-2,
that's
an
encoded
form
of
zero
zero
one
five
and
we
could
just
have
zero
zero
one.
Five
Beyond
The
Wire,
in
fact,
after
the
hackathon
I
kind
of
question,
whether
putting
the
number
of
leading
zeros
at
the
end
makes
sense
at
all.
C
C
C
C
If
you
stick
to
a
width
of
two
you're,
probably
Limited
where
you
you
cannot
represent
really
small
probabilities
accurately,
for
that,
would
you
would
need
to
Define
some
floating
Point
representation
right,
and
this
is
some
fixed,
comma
representation
ahead
of
the
sampling
probability
of
the
filter.
Actually.
D
C
A
Information,
14
hex,
bytes,
Dash,
zero,
because
you're
zero
leading
bits
and
that's
why
I'm
starting
to
question
this
dash
dash
leading
zeros
formulation
at
all
entirely,
so
you
get
up
to
14
hex
digits.
Some
of
them
will
be
leading
zeros.
You
can
drop
trailing
zeros
because
we
can
infer
them
exactly
and
that's
basically,
all
this
is
I
had
fun
doing
this
I
I,
like
the
idea
that
somebody
who
doesn't
get
floating
Point
really
well
can.
C
It's
basically,
what
you
can
say
is
if
you
just
use
a
certain
amount
of
bits
for
representing
the
T
value,
and
the
number
of
bits
basically
represents
the
number
of
sampling
probability,
the
amount
of
sampling
probabilities,
which
you
can
realize
right.
So
if
you
just
have
two
bytes
for
the
T
value,
then
at
the
end
you
can
only
realize
2
to
the
power
of
16
different
sampling
probabilities
so
that
that's
it
I
mean,
and
then
you
are
already
somehow
discretizing
the
same
probabilities
as
we
did
actually
for
the
P
value
for
the
p-value.
C
We
have
six
bits
or
yeah,
and
for
that
reason
we
can
represent
two
to
the
paths.
Sorry,
we
can
represent
64
different
sampling,
probabilities
roughly
so,
and
if
you
want
to
have
a
final
discretization,
you
need
of
course,
more
bits
to
represent
the
the
p-value
or
in
this
case
the
T
value.
So
this
is
what
you
have
to
decide
on
yeah.
How
many
bits
do
you
want
to
invest
for
storing
the
T
value,
and
this
gives
you
the
possibilities?
How
many
different
sampling
probabilities
you
can
realize?
Then
you
can
still.
C
A
D
D
A
No
I.
Well,
let's
see
the
I
think,
because
Trace
state
has
been
formulated
as
a
human
readable
string
in
the
specs
that
we're
using
I
prefer
to
use
hex
hex
decimal,
so
you're
right.
Some
of
the
challenge
in
that
code
that
I
try
to
not
talk
through,
as
we
were
as
we're
racing
through
it.
Just
now
has
to
do
with
converting
X
to
Binary,
because
in
the
in
the
collector
processor,
that
I
showed
the
the
call
was
byte
stock.
A
Compare
I
had
converted
the
hex
into
bytes
because
the
trace
comes
through
it
bytes
or
at
least
the
collector
converts
it
into
to
a
bytes
representation.
So
there's
some
there's
some
use
of
hex
just
because
it's
human
readable
and
that's
what
I
expect
users
to
read,
but
I'm
not
doing
this
because
to
perform
there's
no
performance
motivation
for
using
X,
it's
just
about
the
specs
being
strings
and
for
me
I
guess,
hex
to
bits
is
fairly
straightforward.
Right
I
mean
I!
A
A
A
You
know
sampling
probabilities
in
a
discrete
sense
that
Omer
says,
but
I
don't
care
about.
So
many
of
them
I
only
care
about,
as
in
scientific
notation,
I
want
some
number
of
significant
figures
in
my
Precision
of
my
sampling
and
and
I.
Don't
need
14
bytes
of
precision,
except,
as
you
know,
are
near
the
very
extremely
small
numbers
where
relatively
speaking-
and
this
is
where
I'm
kind
of
hand
waving.
A
D
Yeah
so
yeah,
so
this
well
in
this
area.
Obviously
the
the
previous
approach
with
the
r
values
with
square
powers
of
two
they
handled
these
lower
probabilities
very
well
because
of
their
exponential
nature,
and
this
approach
is
more
linear
right.
So
we
have
the
linear
space
of
these
values
and
that's
why
we
struggle
with
lower
probabilities
and
one
of
the
motivations
for
what
you've
indicated
at
the
very
beginning.
D
There
were
three
points
there,
and
one
of
those
was
was
that
we
want
to
sample
tail,
do
tail
sampling
with
probabilities
other
than
power
of
two
in
in
the
tail
sampler,
so
I
I
think
we
discussed
this
several
meetings
ago.
Well,
with
with
this
random
bits
in
Trace
ID,
we
have
a
workaround
for
that,
because
we
now
can
choose
between
to
powers
of
two
of
sampler,
of
something
probability
with
well-defined
probability,
which
would
be
based
on
this
random
bits
from
Trace
ID.
So
why?
Why
not
following
this?
D
A
I'd
like
to
make
sure
that
we
are
that
that
I
fully
understand
and
because
you
you
I'm
reminded
of
the
histogram
work
which
partner
and
I
are
a
little
closer
to.
But
you
may
you
I,
think
you've
seen
Peter,
and
we
talked
about
log,
linear
and
linear
and
exponential
histograms
right
you're,
saying
to
me
that
the
p-value
representation
is
an
exponential
with
effectively
zero
bits
of
significant.
A
C
C
C
A
I
think
we're
both
responding
to
Peter's
query,
so
I
want
to
say
another
way
of
putting
that
and
I
I'm
still
trying
to
find
a
manner
that
the
user
can
sort
of
read
and
interpret.
So,
let's
suppose
that
right
now
we're
talking
to
the
current
p-value
is
precision
zero,
so
Precision
one
might
be
hex
one
hex
digit
in
my
formulation.
Right
so
then
I'm
going
to
say
p
values
are
a
fraction.
A
fractional
expresses
a
floating
point.
A
A
With
a
single
hex
digit
of
additional
Precision,
now,
where
it
gets
hard,
is
that
I
had
in
my
formulation
in
the
in
the
example
that
I
pitched
earlier
used
a
log
linear
encoding
because
it
works
out
that
way
in
the
IEEE
spec.
For
me,
I
just
take
the
linear
portion
and
truncate
it
somewhere
and
I
slap
it
into
my
exponential
representation,
whereas
what
you
described
is
conceptually
I
think
better,
but
it
there's
a
harder
step
which
might
I
guess
maybe
doesn't
quite
meet
the
same.
A
The
third
part
of
my
requirements
in
the
same
way,
which
is
that
I,
have
to
look
at
that
1.8
and
say
I,
know:
1.8
is
halfway
as
as
exponent
1,
so
we're
talking
somewhere
between
0.5
and
1
and
then
point
eight
means
I'm
halfway
in
a
logarithmic
space
between
0.5
and
1,
which
means
I'm
at
square
root
of
1
over
square
root
of
two
so
that
1.8
equals
1
over
square
root
of
2
sampling.
I.
A
Think
I've
done
math
in
my
head,
which
is
probably
wrong,
but
roughly
speaking,
something
like
that
right,
so
that
p-value
1.8
means
1
over
square
root
of
two.
That
makes
sense
to
me
as
well
on
the
histogram
work.
I
think
I
think
it's
a
little
harder
to
convert
between
the
that
encoded
string,
1.8
turning
that
into
one
over
square
root,
two
means
doing
some
math
and
now
I'm
using
my
the
question
of
using
table
lookup
versus
he
was
calling
the
math
Library
anyway.
C
We're
discussing
is
a
new
discretization
of
the
same
Pro
probabilities.
We
proposed.
You
know
to
use
just
pause
of
two,
which
is
a
fine
for
Marvel
Indra,
but
it
seems
that
the
windows
would
like
to
have
the
average
sampling
rate.
So
and
if
this
is
the
case,
then
I
think
we
shouldn't
come
up
with
another
kind
of
discretization.
A
C
Now,
what
I'm
saying
is
that
who
is
the
with
the
with
the
seven
part
of
Randomness?
We
can
realize
actually
every
sampling
rate,
which
is
representable
by
double
Precision
value,
except
for
the
very
small
ones
yeah
which
are
not
important
in
practice
yeah.
But
we
when
it's
really
slow
small,
then
yeah.
C
If
it
goes
yeah
to
to
the
what
is
called
the
subnormal
range,
for
example,
then
and
I
think
we
would
have
to
problem,
and
we
would
have
problems
to
realize
that,
but
actually
I
think
we
can
represent
any
same.
We
can
realize
any
sampling
rate
which
is
Meaningful
and
can
be
represented
as
a
double
Precision,
folding,
Point,
number
and
yeah.
So
if
if
people
want
to
have
average
sampling
rates,
then
we
should
allow
that
without
information
loss
yeah.
A
Right
I
think
just
just
make
sure
I'm
clear,
though
the
The
Proposal
that
I
pitched
just
now
does
give
you
the
option
to
choose
as
many
as
14
bytes
of
threshold,
which
gives
you
the
ability
to
have
no
loss.
If
you
choose
that
would
balance
that
with
like
the
idea
that
you
know,
common
common
ratios
and
things
are
often
can
be
expressed,
with
less
with
less
loss
and
and
with
more
compression
I
guess.
So,
if
I,
if
I
was
trying
to
do
a.
C
A
C
A
The
idea
of
a
14
by
Trace
State,
to
express
any
arbitrary
probabilities
is,
is
okay,
yeah,
I
I.
It
feels
like
a
simple
benefit
to
say
something
like
you
can
truncate
as
many
of
those
bites
away
as
you
want
for
a
loss
of
precision,
but
but,
but
still
in
doing
so,
you
you
get
exactly
what
you
ask
for
we
just
had
with
zeros
or
something
like
that.
You
can
also
pad
with
the
same
at
the
last
digit,
which
would
let
you
do
repeating
fractions
more,
exactly
I,
don't
know.
A
C
A
But
it
has
this
property
that
I
we
would
call
perfect
subsetting
in
the
in
the
hip
effects,
but
histogram
work
so
whether
I
choose
e0
or
E,
zero,
zero,
zero
or
E
zero.
Zero,
zero,
zero,
zero,
zero
they're,
all
exactly
the
same
so
that
I
can
I
can
widen
Precision
without
exactly
in
every
case,
which
makes
it.
A
A
I
mean
I
went
back
to
like
thinking
of
elementary
school
math
like
you
write
down
the
fraction
one
over
three
and
and
you
know
how
to
write
that
in
decimal
is
1.333
and
then
like
after
some
point,
you're
not
going
to
write
more
threes,
because
it's
not
helping
you
in
any
way
to
write
more
threes.
So
that's
kind
of
why
I
I
came
to
this
idea
of
yeah.
C
A
But
the
feature
I'm
trying
to
replace
in
our
customers
world
is
that
we
have
a
one
and
end
setting
on
our
collectors
today
that
says
you
can
have
one
in
N
sampling,
it's
an
integer
right,
so
I
I
have
a
customer
with
with
one
in
three
or
one
in
four
or
one
in
five
or
one
and
six
or
one
seven
or
one
like
those
are
the
actual
numbers
they're
using
as
they
experience
overload.
They
ratchet
that
up,
so
one
in
ten
becomes
point
one
and
that
that
is
I
can
I
can
represent.
A
That
and
I
have
the
example
of
course
here.
So
oh
no
I
didn't,
but
one
in
a
million
is
the
same
shifted
over
a
bit.
Well,
it's
not,
but
let's
just
pretend
so
I'm
doing
one
in
a
million
and
I
can
choose
to
represent
that
as
four
zeros
and
then
five
bits
of
information,
which
means
I'm,
throwing
away
so
I.
Have
nine
X
digits
specified
so
I'm
throwing
away
five
digits
of
precision
to
get
one
in
a
million
with
one
thousand
error.
A
But
what
really
matters
is
I'm
trying
to
count
integer
things
at
the
end
of
the
day
and
what
matters
is
not
the
is
that
I'm
going
to
count
one
over
that
number?
So
we
we
actually
want
to
look
at
the
error
in
the
inverse
or
find
values
that
are
very
close
to
integers
and
which
might
change
the
requirements
a
little
bit
and
I
thought
through
this
a
sec
and
I
thought.
If
you.
C
B
A
C
C
A
Guess
the
reason
and
the
thing
that
left
me
feeling
good
at
the
end
of
the
week
was
this.
This
example
really
because,
like
most
people,
don't
understand
floating
Point
numbers,
and
so,
if
you
can
say
almost
certainly
you're,
you
have
a
library
function
called
next.
After
and
your
F,
your
printf
library
knows
how
to
do
this
0.14x
and
then
you
just
slice
that
string
and
you've
got
your
threshold,
and
then
you
know
the
the
processor
can
just
do.
A
bytes
can
error
on
the
seven
bytes
after
converting
hex
to
bytes,
and
it's
like
super
simple.
A
C
Simplicity,
sorry,
regarding
Simplicity
or
I,
think
the
simplest
way
is
just
to
put
the
707
bytes
hex
encoded,
and
then
you
can
see
the
everyone
yeah.
This
is
just
a
filter.
It
filters
out
all
all
tracities
which
are
smaller
than
this
value,
which
is
super
simple
and
everyone
understands
and
of
course
you
have
to
compute,
then
the
the
multiplicity
somehow
or
that
not
the
model
or
the
the
adjusted
count
right
and
by
taking
some
formula.
But
actually
what
happens?
A
I
would
probably
still
propose
that
the
story
you
just
said
is
super
easy
to
parse.
This
is
the
threshold
you
convert
it
into
bytes
and
then
there's
some
formulas
to
compute
probabilities
from
that
that
we
know,
and
that
involves
adding
one
and
then
right
as
because
of
the
property
here,
zero.
The
value
zero
is
exactly
one
out
of
two
to
the
56..
We
start
from
there
and
then
you
and
then
so.
A
That's
why,
plus
one
I
just
I
just
want
to
throw
in
this
like
you,
can
you
can
erase
as
many
as
a
bit
as
you
want
and
they'll,
be
padded
with
zeros
to
produce
14
bytes
for
this
approach
and
then
and
then
you're
you're,
given
the
freedom
to
use
three
bytes,
if
you
want
or
five
bites,
if
you
want
or
seven
bites
or
nine
bites,
it's
all
the
same,
but
that
could
be
an
extra
paragraph
and
maybe
that's
version.
Two.
A
A
Okay,
my
colleague
Carlos,
who
sometimes
attends
this
meeting
just
to
keep
track,
is
tracking
this,
and
somebody
at
lifestep
is
going
to
keep
pushing
on
this.
It
might
be
me
so
I'm
glad
we
talked
about
it.
It
sounds
like
the
more
palatable
approach
just
says:
put
14
x,
bytes
and
simple
I'll
I'll.
Remember
that.