►
Description
From the 2017 OpenZFS Developer Summit:
http://www.open-zfs.org/wiki/OpenZFS_Developer_Summit_2017
A
B
Am
selling
to
party
I
lead
the
filesystem
team
in
agile
just
to
give
a
context
roughly
round
number
2013.
It
took
the
GFS
from
the
illness
and
since
then,
we
have
been
developing
the
chiefest
features
independently
for
various
season,
I'm
going
to
talk
about
them.
While
we
had
to
do
our
own
development,
mainly
because
of
the
things
we
were
doing,
they
were
mainly
on
AI,
ops
or
latency
side.
They
were
mainly
on
the
IAP
soliton
seaside
and
some
of
the
problems
which
we
were
facing.
B
I'm
just
going
to
talk
about
briefly
current
model
before
we
did
this
project.
What
was
the
problem?
What
are
the
challenges
in
that?
And
how
did
we
even
her
and
improved
I,
ops
and
bandwidth,
which
we
saw
that
so
just
giving
a
beef?
How
does
storage
pool
allocated
is
bundled
in
current
GFS?
You
can
plug
in
any
device
under
several
Metis
lab
classes,
la
classe,
el
tovar
class
or
data
class
when
we
started
desire
added
another
class
for
metaclass,
especially
putting
all
the
data.
B
Sorry
metadata
on
the
fast
media
says
DS
so
that
we
can
put
things
like
holiday,
indirect
blocks
did
of
indexing
tables
and
all
that
animate
a
class,
so
it
it
has
been
appeared
to
the
I'll,
say
la
class
and
data
class.
In
that
sense,
it
gave
good
improvements
in
some
of
the
cases,
but
it
still
I'll
talk
about
the
problems
which
it
has.
The
problem
was
the
usual
source
utilization.
You
have
few
number
of
drives.
B
How
do
you
utilize
the
tribes
in
such
a
that
it's
very
efficient,
so
the
model
is
that
you
put
some
devices
to
the
log
devices
or
some
some
to
the
casts
or
some
some
to
the
metadata
devices,
so
they
are
idle
either
statically,
partisan
or
you
create
regular
partitions
and
put
them
inside
that.
So
two
approaches
dedicated
devices
realized
very
quickly.
It's
not
going
to
work
because
we
want
to
share
that
SSD
devices
which
are
more
performant
latency
boils
and
all
that
among
several
data
classes,
not
only
in
few
and
definitely
not
in
dedicated
manner.
B
So
why
not
to
do
partitions?
The
problem
with
partition
is
very
inflexible.
Once
you
have
created
the
sizes
you
cannot
do.
You
cannot
change
the
sizes
before
doing
something
bigger
to
the
pool
and
all
that
and
even
bigger
problem.
What
do
you
do
on
the
party
since
when
to
class
of
data
or
writing
or
pounding
at
same
time
on
the
same
device
and
there's
no
mechanisms
to
throttle,
say
Laplace
it
pumping?
B
How
do
I
ensure
the
middle
class
or
caste
class
is
not
completely
starved
because
underlying
they're
talking
to
same
device
and
there's
no
mechanism
to
make
them
pipeline
in
in
a
nice
fashion?
So
what
can
we
do?
So,
let's
we
came
up
with
an
idea:
why
not
share
all
the
devices
and
make
it
completely
virtualized
and
implement
all
the
services,
all
the
classes
on
top
of
it?
What
it
provides
is
it
gives
you
said
capacity
you
get
tires
and
bandwidth
completely
shared,
and
also
because
we
are
talking
about
low
caste
meta.
B
All
of
them
have
different
data
protection
requirement.
For
example,
caste
I,
don't
need
to
worry
about
drive
failure
and
all
that
I
can
just
probably
discard
it
to
whenever
there's
a
problem,
but
I
must
provide
a
very
good
data
protection
for
meta
or
log
when
I
am
doing
that.
Secondly,
there
is
a
very,
very
different
characteristic
in
the
applications,
for
example,
lies
completely
sequential
you're.
Just
writing
big
big
logs
and
everything
but
method
it
is
completely
random.
I
have
spawned
so
essentially
in
any
file
system
uses
you
illallah
see.
B
There
is
a
bimodal
pattern
of
the
user,
either
in
throughput
or
in
the
eye
ops,
and
by
sharing
these
devices
we
can
utilize.
The
both
parts,
throughput
and
I,
have
seen
very,
very
efficient
model.
How
are
you
we
also
need
to
provide
some
of
the
quality
of
service,
because
the
moment
you
start
sharing,
you
need
to
also
make
sure
some
of
the
services
don't
get
a
star,
or
at
least
you
have
some
methods
by
which
you
can
provide
services
getting
something
from
each
class
of
service
on
top
of
it.
B
Just
whatever
I
talked
about
this
service
of
comparing
with
those
slices
are
partitioned.
When
you
have
everything
in
partition,
your
just
bombarding
the
iOS
to
the
device
directly.
There's
no
mechanism
can
control,
but
when
we
have
shared
all
these
classes
on
top,
we
can
funnel
through
separate
priority
queue,
and
you
can
put
dynamic
or
adaptive
Waits
and
process
them
as
per
your
need.
B
B
The
storage
is
still
divided
in
Metis
lab
classes.
We
have
different
sizes
like
fix,
for
get
sizes
of
slab
instead
of
having
200
fixed
but
drive,
but
pretty
much
similar
concept
and
then
pull
it
all
these
classes,
on
top
of
it,
so
you'll
notice,
lock,
clasp
and
metaclass.
They
appear
exactly
same,
but
l
to
our
caste
doesn't
appear
which
is
maintaining
whatever
is
the
current
GFS
model
where
L
torque
is
not
necessarily
accepted,
metaclass
in
true
allocation
sense,
we
maintained
it
exactly
same
for
two
reasons:
we
wanted
to
have
extremely
fast
allocation
performance.
B
If
we
go
to
any
other
location
structure
model,
it
basically
means
you
have
to
pay
some
price
for
allocating
in
the
l2
cache,
and
we
wanted
extremely
fast.
It's
just
a
rolling
case
model.
Your
rolling
log
model
II
keep
writing
sequentially.
So
allocation
is
almost
always
some
atomic
instruction.
You
don't
need
to
worry
about
all
that
cost
of
the
other
case
and
no
space
map
involved
and
all
that,
so
it
provides
a
pretty
flexible
model
to
allocate
and
the
way
L
to
Ark
is
designed.
It
I
will
talk
about
little
more
in
detail.
B
In
terms
of
implementation,
we
had
to
come
up
with
separate
items
because
we
wanted
to
have
different
allocator.
For
example,
we
didn't
want
to
have
a
same
alligator
for
each
class
of
service,
so
we
made
the
changes
so
that
alligator
is
per
class,
so
every
meta
swap
class
will
have
its
own
alligator.
It
will
have
its
own
priority
queues
and
also
load
of
space
map
load
and
all
they
also
have
a
very
different
policy,
for
example,
lock
class
we
don't
unload
at
all.
We
keep
it
all
the
time
loaded
it
raw.
B
It's
very
efficient
mechanisms
to
condense,
coalesced,
smaller
blocks,
and
you
get
the
contiguous
of
space
by
that
way,
and
also
every
class
has
its
own
data
protection
type.
So
you
can
chew,
you
can
configure.
All
of
these
are
configurable
some
default,
so
meta
data
you
can
choose,
mirror
to
parameter
or
whatever
gasps,
no
redundancy
law
mirror
or
triple
murder,
whatever
you
type.
So
how
did
we
end
up?
Providing
all
this
black
pointer?
A
light
supports
three
pointers.
We
don't
we
didn't
need
to
do
anything.
B
Only
thing
which
you
needed
was
that
in
the
allocator
we
strictly
enforce
the
drive
that
every
allocation
is
aware
of
which
types
coming
from
and
every
block
pointer
every
allocation
goes
to
different
drive
and
that's
how
we
implemented
the
mirror
or
triple
mirror
on
top
of
it,
coming
back
to
dynamic
resource
sharing,
once
we
pull
it,
so
we
became
more
greedy.
How
do
we
efficiently
utilize?
The
capacity
for
example,
give
an
example:
let's
say:
I
dedicated
I
dedicate
some
capacity
to
metadata
when
I
create
a
pool.
B
Definitely,
nobody
is
using
that
much
metadata,
so
taking
examples
out
of
hundred
gigabyte
of
SSD,
maybe
one
megabyte
is
using
ously.
So
why
do
I
give
everything
to
metadata?
Maybe
I
can
just
give
one
gigabyte
and
use
remaining
to
the
to
Ark
or
anybody
else
who
is
always
going
to
utilize
it
and
when
there
is
a
need
that
metadata
grows,
I
can
dynamically
pull
the
or
take
away
the
data
from
the
cache
and
put
it
in
the
meta.
B
So
this
is
the
this
is
the
crux
of
the
USB
here
move
the
data
from
different
classes
to
other
class.
In
our
practical
use
case,
we
happens
there
only
cache,
but
there's
nothing
which
it
sticks
doing
for
others.
Although
mechanism
will
be
slightly
different,
so
just
given
hint
we
have,
as
I
said,
we
need
to
give
some
some
slabs
to
log
and
some
slabs
to
meta
and
Cass
almost
takes
everything
when
there
is
a
pressure
on
anything
log
and
meta
have
given
example.
B
Here
in
the
meta,
we
can
say:
ok
I'm,
going
to
take
away
some
space
away
from
the
cache
and
give
it
to
meta.
So
this
is
single
dynamic,
stonker
algorithm,
basically,
which
will
figure
it
out
for
gigabyte
worth
or
ad
about
whatever
is
a
slab
size,
and
it
will
shrink
the
gas
in
that
much
and
dynamically
attach
it
to
the
metal.
Now
meta
grows
from
one
slab
to
two
slabs
and
it
can
use
all
you
can
put
it
to
the
log.
B
However,
this
required
several
enabler
changes
because
state
forward,
we
couldn't
have
done
it
and
there
were
other
reasons
why
we
had
to
do
that.
First
change
we
had
to
do
was
that
we
had
to
make
our
canal
to
work
independent
right
now,
at
least
when
we
took
the
GFS,
they
were
completely
intertwined.
Basically
at
work
was
visible
in
our
indexing
was
in
art.
There
was
no
separate
index
infrared
to
our
that
created
a
problem
for
right
bandwidth,
so
we
separated
it
out
our
canal
to
work.
We
had
to
pay
as
little
price
of
separate
indexing.
B
Father
l2r,
but
at
least
at
least
is
allows
us
to
scale
the
bandwidth
to
the
number
of
devices
underneath
second
change.
We
had
to
do
because
we
wanted
to
make.
We
want
to
take
the
whole
SSD
space
as
a
gas,
so
we
need
more
indexing
memory
and
in
the
model
which
you
had
it's
roughly
used
like
160
to
170
bytes
for
one
structures,
it
seemed
pretty
much
very
high,
so
we
separated
out
l2
are
made
a
very
compact
64
64
byte
in
Co
structured
allowed
to
go
more,
of
course,
indexing.
B
If
you
have
many
more
SSD
devices,
it
requires
some
other
persistence
model,
not
only
memory
indexing.
We
can
talk
separately
so
now.
Also,
we
had
to
change
on
the
way
we
stored
l2
art,
it's
completely
persistent
at
work
and
stored
as
a
linked
list
of
one
one
megabyte
pages
and
that
one
megabyte
phase
linkless
chaining
allows
us
to
quickly
scan
from
a
given
point
to
a
given
point
and
take
away
the
space.
B
That
was
that
give
us
a
very
nice
model
that
we
can
figure
it
out
given
offset
and
given
a
size
where
is
that
chain
and
that
chain
I
can
plug
it
him
back
to
either
log
or
meta,
as
required
and
I
mean
just
brief
idea.
How
link
basically
chung
has
its
own
Lieber
class.
Basically
chunk
is
the
one
megabyte
page
which
I
has
talked
about,
and
all
these
one
mega
PI
by
pages
they
have
head
and
tail
as
I
said.
B
If
any
of
the
hell
to
our
blocks
are
hot,
we
have
separate
McCallum's
to
track
them
and
we
refeed
them
in
the
head
so
that
they
remain
into
l2
Arkansas,
getting
thrown
away,
it's
kind
of
a
runtime,
the
compaction
of
the
space,
but
it
also
eliminates
the
need
for
maintaining
any
elaborate
ill
allocation
structures
and
the
l2
our
hash
table
is
very
similar
to
buffers
indexing
table.
Whatever
is
in
for
our
almost
similar.
It's
just
that
it
works
on
the
l2.
Our
devices
and
l2
are
one
megabyte
buff
page.
Basically,
it
has
all
the
headers.
B
B
The
way
you
have
parties
is
basically
a
partition
front
part
to
log
and
remaining
tomato,
and
some
part
to
cast
like
that
and
compared
to
I
flash,
so
orange
bar
is
the
one
which
is
without
flash,
because
it
it
is
sharing
I'm
sowing
three
sample
diameter
performance
trends
because
they
are
kind
of
the
worst
cases
for
random.
Our
performance,
mixed
load
of
50%,
random,
right,
50%,
random,
read
and
our
0p
is
basically
absolutely
hundred
percent
random
light.
B
So,
as
you
can
see
the
same
set
of
device,
there's
no
change
for
SSDs
used
in
different
model
provide
almost
twice
performance
and
if
you
see
it
in
see
also
significantly
reduce
because
we
have
more
bandwidth
or
I
observe
level
during
the
service.
So
we
did
another
test
with
the
bigger
block
size.
Let's
say
how
much
it
improves
if
it
is
pencil
kind
of
workload
are
slightly
bigger
block
size.
B
B
So
once
we've
had
this
idea
of
I
flash
say
shading
on
only
under
says
d
devices,
if
you
think
about
it,
if
I
just
say
la
classe
is
nothing
but
a
streaming
class
sequentially
streaming
and
metaclass
is
nothing
but
a
random
miops
performance
class.
Why
can't
I
make
the
similar
model
for
my
all
flash
pool.
A
B
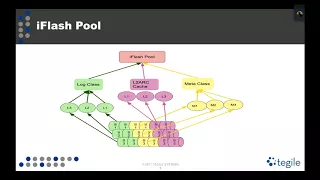
So
you
can
just
assume
this
lock
class
is
nothing
but
a
streaming
class.
What
it
gives
me
two
things,
one:
the
allocations
never
spread
across
the
disk,
because,
if
your,
how
you
have
anything
which
is
you're,
writing
temporarily
and
you're
going
to
describe
very
soon,
if
there's
no
point
writing
in
the
whole
whole
Drive-
and
we
just
contain
this
very
small
part.
Another
thing
which
you
do
is
that
we
keep
this
log
or
streaming
classes
loaded
all
the
time.
That
provides
me
two
benefits
as
it
is
freed.
B
If
you
have
unloaded
space
maps
you
do
it
never
have
an
idea.
Where
is
the
biggest
contiguous
chunks?
But
when
you
have
a
loaded,
you
can
always
find
the
biggest
contributor,
because
the
tree
is
already
coalescing
it
in
the
runtime
metaclass
same
thing,
as
I
said,
you
can
have
separate
allocation
mechanism
and
I
didn't
talk
about
the
allocator.
Also
in
the
lock
class
you
can
a
completely
separate
allocated
from
the
metaclass,
because
la
class,
you
know
that
you're
going
to
allocation
cache
is
the
most
critical
factor.
B
Everything
else
is
secondary,
so
why
not
optimize
it
in
such
a
way
that
you
completely
writing.
Add
that
acts
some
sort
of
a
head
and
just
keep
moving,
and
then
you
roll
back.
So
it
still
follows
the
metal
slab
class
model,
but
it
starts
from
say,
metal,
slab,
0,
1,
2,
3,
4,
5
till
then,
and
then
comes
back
to
metal,
slab
0
and
if
it
is
temporal
class,
most
of
this,
too,
most
of
the
used
structures
are
freed,
so
it
certainly
remains
steady
for
metaclass.
B
We
have
completely
different
policy
because
we
want
to
optimize
space
efficiency
and
all
that,
so
we
have
we
try
to
pack
as
much
as
possible
in
a
given
metal
slab
class
before
we
move
to
different
class
so
same
idea,
whatever
we
had
on
the
high
philosophy
in
carpet,
indent
or
alpha
has
to
provide
different
kind
of
quality
of
service
performance
for
esteeming
and
run
of
my
applications.
Now
you
can
think
that
you
can
put
like
lagdi,
VLANs
and
lock
glass
and
some
other
things
on
metaclass.
B
On
top
of
it,
you
need
some
other
administered
intervention
to
be
able
to
do
that,
at
least.
For
now,
but
it
provides
a
platform
that
we
can
provide
that
also
at
top
level.
In
a
sense,
it
provides
very
efficient
resource
sharing,
creates
multiple
streams.
It
also
provides
a
good
advantage
because
it
gives
more
parallelism
at
the
city
drives,
which
are
very
good.
The
more
queue
depth
you
have
at
the
DRI
level
they
perform
even
more
I,
have
sorry
even
better
adapt
dynamically.
This
resource
setting
is
done
with
based
upon
size
or
threshold
of
safe
fragmentation.
B
We
can
change
and
it
explores
the
Bywater
patterns
found
in
almost
every
file
system
at
various
times
and
GFS
is
pretty
pretty
neatly:
bimodal,
there's
a
data
phase,
and
then
you
have
metadata
phase.
So
there's
completely
nicely
aligned
my
model
patterns,
so
you
can
exploit
them
and
aggregate,
but
performance
is
much
better
compared
to
dedicated
one.
It's
very
extensible.
You
can
use
it
to
all
flowers
or
anything
else.
If
you
want-
and
you
can
provide
the
extensible
benefits
to
the
application.
B
Right
so
similar
to
our
the
best
thing
about
the
arc
is
that
it
provides
you
the
resistance
to
sequential
lights
and
all
that
kind
of
things.
So
we
wanted
to
have
something
which,
even
though
we
move
to
different
models,
how
do
we
provide
that
kind
of
thing,
even
at
the
l2
arc
level?
So
we
have
basically
something
called
a
heat
index
for
a
block
and
we
maintain
that
heat
index
and
there's
a
pool,
wide
heat
index
maintained,
saying
if
anything
is
above
that
heat
index,
we
are
going
to
retain
them.
B
B
B
So,
as
I
said,
the
biggest
poll
which
we
did
was
in
number
2013
after
that
bug
fixes
which
we
see
generate
bug,
fixes
we
pull
them
in,
but
unfortunately
10
hours,
so
much
that
we
cannot
do
any
pull
at
this
point
of
time.
We
thing
I
mean
a
lot
of
good
useful
features.
We
are
not
able
to
pull
because
there's
a
huge
variance
in
our
code,
but
some
of
the
changes
which
are
good,
for
example,
compressed
dark
and
all
so.
B
B
B
B
So
right
now,
if
it
is
a
hybrid
system,
we
used
to
have
a
model
where,
if
meta-data
class
has
a
problem,
we
can
spill
it
to
data
class.
But
if
it
is
just
drive,
it's
a
pathetic
performance
problem,
so
we
have
stopped
doing
that.
Instead
of
that,
we
have
addressed
the
problem,
which
is
the
metadata
consumption,
so
biggest
consumer
for
metadata
in
our
use
case
is
the
DDT
table
and
we
have
added
a
mechanism
where
you
can.
B
B
B
So
these
three
are
the
complete
representation
of
say,
VM
and
database.
Both
VM
and
database
have
almost
similar
profile,
very,
very
little,
sequential
and
mostly
random.
Just
for
the
comparison
purpose.
What,
if
sequencer?
Let's
say
everybody's
writing
sequencer?
What
happens
I
did
that?
Also
this
basically
means
I'm.
Just
writing.
Sequential
in
small
size,
so
mainly
doesn't
happen
in
small
size
doesn't
happen
many
application,
but
for
32k
at
least
in
database
log
lines
or
backup
workloads
in
some
of
the
use
cases
we
do
see.
So
even
there
we
don't
see
the
impact.
B
So
this
is
I'll
say
it's
VM
and
database
workload
representation
here
this
one
is
32.
K
is
basically
SQL,
Analytics
or
bigger
block
size
databases,
those
kind
of
things
and
in
those
use
cases
also.
This
is
mainly
with
the
very
highly
dependable
workloads.
Basically,
everybody
is
running.
We
did
open
other.