►
From YouTube: Improving ZFS send/recv by Jitendra Patidar
Description
From the 2021 OpenZFS Developer Summit
slides: https://docs.google.com/presentation/d/1DHXaBQcw3MmeZzg-Y5FEgStGEFHi4IfwN5VfgzNLKPA
Details: https://openzfs.org/wiki/OpenZFS_Developer_Summit_2021
A
My
learning
on
zfs
started
around
two
and
a
half
years
back
when
I
joined
nutanix
files.
Team
nutanix
files
is
a
scale-out
file.
Server
solution
built
on
top
of
nutanix
core
sci
platform
on
top
of
nutanix
file
servers,
different
type
of
file
shares
can
be
destroyed,
can
be
deployed
and
for
with
respect
to
different
use
cases
and
workloads.
A
A
Solutions
this
product
has
and
for
that
product,
gfs
and
receive,
is
used.
So
today
I
am
going
to
talk
about
couple
of
two
optimizations.
We
done
for
share
level
replication
solution,
so
one
of
the
optimization
which
we
done
around
zfsn
block
traversal
and
the
second
optimization
is
for
share
level
replications
on
the
zfs
receive
site.
So
I'm
going
to
cover
these
two
optimizations
in
today's
talk.
A
Yeah,
before
jump
over
to
optimization
just
brief
of
cfs
and
receive
so
gfs
send
is
a
replication
tool.
It
traverses
through
the
block
tree
for
even
snapshot.
It
does
searches
for
all
the
blocks
for
full,
send
and
change
lock
for
incremental,
send
and
for
those
blocks.
Then
it
dumps
records
on
a
send
screen
or
the
wire
for
receiver
side
to
process
them
and
replay
on
the
target.
So
zfs
vc
basically
receives
those
records
from
stream
and
processes
them
and
dumps
applies
them
on
the
target.
A
So
that's
a
brief
now
I'll
talk
about
first
optimization,
so
cfs
sand.
Basically,
as
I
said,
traverses
block
tree
from
the
root
of
given
snapshot,
it
traverses
through
corresponding
objects
and
for
each
of
the
objects.
Then
it
traverses
down
to
the
indirect
blocks,
non
m0
prongs
and
then
finally
reaches
to
the
l0
blocks
for
l0
blocks.
Then
it
prepares
corresponding
drr
records
and
dumps
on
the
sand
stream.
Okay,
so
while
traversing
indirect
blocks,
basically
zfs
traversal
does
prefetching
and
it's
it's
basically
to
make
traversal
faster.
A
A
So
that's
a
problem,
because
if
you
are
doing
two
aggressive
replace,
then
it
could
have
basically
performance
impact
on
other
active
workloads
running
on
your
system
and
also
it's
possible
that
if
you
are
doing
very
early
and
aggressive,
replace
the
blocks
which
you
prepared
for
the
benefit
of
saint
reversal,
those
itself
get
evicted
and
so
the
it's
not
much
beneficial
for
traversal
itself.
Also,
so.
A
The
aggressive
prefetch
is
not
really
helpful.
We
so,
though,
now
I
talk
about
the
solution,
so
the
optimization
is,
is
in
align
to
the
controlling,
basically,
the
this
aggressive
refreshing.
We
have
in
the
traversal,
so
while
traversing
indirect-
and
we
know
it
could
have
max
one
zero.
Two
four
blocks
pointed
underneath
so
in
place
of
doing
bulk
prefetch
of
all
those
one.
Zero
two
four
blocks
do
control
prefetch
in
different
slot
so
like
when
you
are
traversing
first
going
to
trevor's.
A
The
other
workloads
which
are
running
parallel
system
has
minimum
impact,
so
so
that
that's
optimization,
I
have
one
to
enable
defined
like
zfs
drivers.
Indirect
refresh
limit
is
by
default
defined
to
32,
and
it
can
be
configured
with
respect
to
any
workloads
have
need
of
changing
it
to
lower
or
higher
value
yeah.
So
I
already
have
this
these
optimizations
post
to
upstream,
so
this.
A
Yeah,
so
that
that
was
the
first
optimization
now
I'm
going
to
cover
the
second
optimization
before
detailing
on
second
optimization,
just
brief
on
the
distributed
share.
So
basically
on
nutanix
file
servers
we
have
we
support
different
type
of
file
share,
so
one
of
the
type
of
files
here
is
distributed.
Share,
so
distributed
share
is
consists,
basically
consists
of
multiple
z,
pools
and
data
sets,
and
these
simple
data
sets
scattered
across
multiple
file
server
vms.
A
So
this
is
primarily
a
build
for
homes,
home
directory
use
case
and
it's
later
expanded
for
other
different
industry
enterprise
workloads.
So,
as
you
can
see
in
the
diagram
the
as
you
can
see
in
the
diagram,
the
different
users
home
directories
are
just
getting
distributed
across
different
file
servers
and
they
are
baked
by.
A
Data
sets,
so
that's
a
brief
on
distributed
share,
so
I
am
going
to
talk
about
second
optimization,
which
is
basically
replicating
these
distributed
shares
from
source
to
target,
so
as
as,
as
I
has
explained,
distributed
share
basically
consists
of.
Multiple
data
sets
simple
data
set
which
are
scattered
across
different
nodes,
so
like
in
this
example,
I
have
distributed
share
with.
A
A
So
like
in
this
example,
you
have
10
mb
for
data
set
1
and
then
100
mb
for
data
set
2
and
then
around
1
gb
for
data
sets
3.
So
now,
based
on
the
replication
throughput,
which
you
get
on
the
wire,
for
example,
in
this.
In
this
example,
it
is
I'm
saying
like
we
have
like
10
mbps
throughput.
So
in
this
case
it
would.
What
would
happen
is
replication
of
this
data
set
would
complete
in
different
timelines
so
like
for
first
data
set,
it
could
complete
around
one.
A
Second,
then,
for
second
data
say
we
could
around
10
complete
on
around
10
seconds
and
then
last
one
would
complete
around
100
seconds.
So
the
point
is
basically,
the
replication
of
this
data
set
would
complete
in
different
timelines
and
if
you
are
talking
about
share
level
consistency,
because
this,
thus
this
distributed
share
on
the
source
side
is
basically
made
out
of
these
three
data
sets
so
on
the
target.
A
If
you
see
the
consist
view
of
this
share
on
the
target
site,
it's
basically
all
the
that
particular
snapshot,
which
you
are
replicating
in
current
timelines.
The
that
point
of
image
on
the
target
side,
so
basically,
if
these
are
completing
in
different
timelines,
though
target
side,
we
see
a
not
a
complete
view
of
that
particular
snapshot.
So
basically
it's
temporarily
inconsistence,
so
com.
This
level
consistency
is
temporarily.
Inconse
is
compromised
basically
for
this
use
case,
so
now
yeah.
So
now
I'm
going
to
talk
about
this
optimization.
A
Before
I
jump
into
details
of
optimization,
I
will
just
cover
a
brief
overview
of
gfs
receive,
which
would
help
us
understanding
the
optimization
so
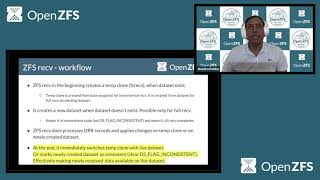
gfs
receive
basically
in
the
beginning
begin
part.
Is
it
creates
a
temporary
clone
from
the
existing
data
set
or
the
best
snapshot
for
incremental
and
from
existing
that
dataset
for
the
full
receive
if
it
could
have
it
creates
new
data
set
as
well.
If,
if.
A
And
then
it
basically
receives
on
the
temp
clone
or
newly
created
data
set.
So
that's
a
the
receiving
part
is
basically
reading
from
the
stream
and
then
processing
those
records
and
applying
on
the
target.
Once
compressive
processing
is
done
where
all
your
changes
change
set
is
available
on
the
target
in
the
temp
clone
or
newly
created
data
set,
then
the
last
part
at
the
end
part
of
receive
it
just
switches
that
temporary
clone.
A
And
makes
that
received
snapshot,
changes
available
on
the
line
or
in
case
of
newly
created
it
marks
that
data
set
consistent
and
make
it
available.
So
the
point
is
as
soon
as
you
receive,
with
respect
to
receiving
and
applying
on
the
live.
So
as
soon
as
you
receive
completes,
your
changes
gets
available
on
the
line
with
a
receiver.
C
A
So
the
primarily
we
wanted
to
have
the
receive
of
these
different
data
sets
corresponding
to
share
complete
in
same
timeline,
and
we
wanted
to
have
a
of
corresponding
content
chain
set
available
on
the
live
in
a
controlled
manner.
So
so
as
a
solution,
what
I
have
done
is,
as
explained
the
receive,
has
three
parts
begin
then
receive
stream
processing
and
then
the
end
part,
so,
basically,
after
stream
receive
completes
and
all
change
set
available
on
the
target.
Just
the
end
part
is
left
to
do
in
that
stage.
A
I
am
basically
the
in
the
solution
I
am
proposing
to
break
the
receive
and
breaking
the
receive
is
built
on
top
of
existing
feature
like
regime
receiverism
token
we
have
so
we
are
using
that
functionality
and
building
on
top
of
that,
so
basically
generate
a
token
from
that
stage,
where
we
are
just
going
to
end
the
receipt.
So
the
token
is
generated
such
that
it
has,
along
with
existing
content.
It
has
additional
fields
to
indicate
that
this
is
a
activate
token.
Basically,
all
the
contents
has
received
on
the
target.
A
Just
the
activation
part
is
left
to
do
so.
You
can
just
whenever
needed,
to
activate
this
snapshot,
which
you
have
received
target.
You
can
do
a
later
point
of
time
so
and
then
few
other
additional
fields
in
the
token,
because
we
are
going
to
activate
this
to
use
this
token
for
activation
directly
on
the
target,
so
you
could
need
certain
information
which
is
coming
from
the
source,
so
we
keep
it
those
flags
and
necessary
info
in
the
token
itself,
to
keep
it
handy.
While
we
are
going
to
activate
this
snapshot
later
point
of
time.
A
A
This
gives
basically
control
control
way
of
activation
yeah.
So,
with
respect
to
implementation,
I
have
two
cli
defined.
One
is
in
align
to
the
breaking
the
receive
at
the
end
part.
So
hyphen
p
is
option
here,
gfs
receive
sign,
it's
it's
used
along
with
hyphen
ace,
which
is
basically
receive
resume
token
functionality.
So
this
optimization
is
built
on
top
of
that.
So
when
you
hyphen
p,
along
with
hyphen
s,
that
is
you
break
at
the
end.
So
workflow
is
like
the
dmv
received
begin
down.
A
Finally,
once
you
have
those
activate
tokens
available,
you
could
use
those
to
not
token,
but
the
target
itself
you
can
give
with
hyphen
a
option
and
internally
zfs
would
do
this.
Optimization
would
internally
face
the
token
from
the
target
and
then
prepares
begin
record
and
goes
through
the
receive
begin
and
just
receive
end
workflow,
which
is
which
was
left
over
to
do
with
when
we
given
hyphen
p
option.
A
So
in
our
use
case,
as
I
said,
we
have
multiple
data
sets
underneath
the
share,
so
those
and
those
are
scattered
across
different
z
pools.
So
we
have
to.
We
can't
do
them
activate
them
within
same
transaction
group
because
they
are
scattered
across
the
sea
pools.
So
we
needed
a
controlled
way
of
activation
on
top
of
this
infrastructure.
So
we
have
infrastructure
layer
which
does
control
activations
and,
if
necessary,
also
doesn't
basically.
A
A
So
this
this
builds
and
functionally
works
as
well,
but
I
still
have
to
clean
up
and
do
more
testing
to
make
it
available.
Master
opencvs
master,
pull,
request,
yeah
and
yeah.
So
this
this
this,
this
is
basically
help
doing
a
controlled
activation
of
further
our
use
case
of
distributed
share.
I
could
be
helpful
in
generic
use
cases
where
the
shares
are
created
with
multiple
set
of
z
tools
and
data
sets.
A
On
temporary
clone
and
once
the
receive
for
all,
corresponding
data
sets
complete
and
then,
if
we
have
control-
and
we
know
that
we-
we
can
activate
this
and
make
it
available
on
the
live.
So
we
have
control
to
activate
this
and
get
it
available
on
the
live.
So
that
gives
a
consistent
view
for
the
share
on
the
target
side
for
the
end,
consumers,
and-
and
this
also
gives
control
to
drop.
A
A
A
C
That's
that
that's
possible,
but
we
had
a
couple
of
other
underpinnings
there.
For
example,
the
fsid
is
something
that
we
construct
internally.
So
there's
there's
a
lot
of
other
things.
For
example,
the
data
set
names
that
we
pick
are
based
on
on
the
on
the
on
the
share,
uuid
and
stuff,
like
that,
so
a
lot
of
other
things
had
to
be
reworked.
B
C
D
Yeah,
I
think
this
file,
it's
an
interesting
idea,
paul.
I
don't
think
that
you
can.
I
don't
think
that
it's
possible
with
the
functionality
in
zfs
today
because,
like
you,
could
do
the
receive
as
clone
like
you
said,
but
then
you
know
if
you
have
an
existing
share
on
on
the
original
one
of
the
original
name,
there
isn't
a
primitive
that
would
let
you
like.
B
D
Yeah
yeah,
but
I
mean
it
might
be
that
that
would
I
mean
maybe
it
would
be
better
to
have
that
be
a
first
class
thing
where
it's
like.
Oh
I
have.
I
have
a
file
system,
it
has
a
clone.
Neither
of
them
have
any
snapshots
just
like
swap
the
contents
of
them,
which
is
exactly
what
happens.
You
know
at
the
when
the
receive
completes.
D
Yeah
and
the
more
the
general
thing
like
it
might
have
so
many
restrictions
that
it
ends
up
feeling
kind
of
forced
and
you
have
all
these
error
modes
right
where
it's
like.
Oh,
like
you
tried
to
do
the
promote
you
tried
to
do
this
swap,
but
there
was
a
snapshot
versus
like
with
the
receive
it's
like.
A
Doing
it
inside,
it
also
gives
control
control
of
not
allowing
snapshots
in
between
the
receives.
So
you
can,
because
if
you
are
one
snapshot
you
are
receiving
and
if
you
are
creating
another
one,
then
you
have
to
decide
on
which
one
to
keep
keep
on
top
of
base.
If
you
are
so
this
doing
internally,
it
also
gives
control
of
like
not
allowing
new
snapshots
on
target.
While
you
are
receiving.