►
From YouTube: ZVOL Performance by Tony Hutter
Description
From the 2022 OpenZFS Developer Summit: https://openzfs.org/wiki/OpenZFS_Developer_Summit_2022
Slides: https://drive.google.com/file/d/1smEcZULZ6ni6XHkbubmeuI1vZj37naED/view?usp=sharing
A
A
So
back
in
August
of
2021,
our
archive
team
at
Lawrence,
Livermore
National
Laboratory
was
testing
out
some
new
hardware
and
they
were
benchmarking
xevolves
on
ZFS
and
what
they
were
seeing
was
when
they
would
do
parallel.
Dd
rights,
just
normal
DD
rights.
They
would
get
about
1.7
gigs
a
second
and
then,
when
they
re-ran
the
same
test
with
o
direct,
they
would
get
2.9
gigabytes
a
second,
so
basically
line
rate,
and
they
were
saying
well.
Why
is
that?
A
A
So
I
started
down
the
rabbit
hole,
so
this
is
a
non-odirect
right.
This
is
just
a
normal
right
and
flame
graph.
That
I
learned
about
at
a
past
opencfs
conference,
I
think
from
one
of
your
presentations
Matt.
So
here
with
the
non-odirect
right,
you
can
see.
Xeval
Wright
is
like
60
percent
of
the
total
time
and
if
you
look
at
the
O
Direct,
it's
maybe
20
percent.
A
A
The
Z
Vol
driver
is
a
block
device
driver
for
the
Linux
kernel
and
the
API
it
historically
used
was
through.
Submit
bio,
submit
bio
is
a
function
that
you'd
pass
in,
and
you
say
whenever
you
have
an,
I
o
that
you
want
to
write
to
my
block
device
pass
this
struct
bio
and
what
I
was
seeing
was
when
you
would
do
o
direct
you'd.
A
Get
these
nice
big,
like
half
megabyte
or
megabyte
block
iOS,
but
if
you
did
Regular
rights
so
non-odirect
you
get
these
tiny
little
4K
pios
coming
in
there's
tons
of
them,
and
that
makes
sense
because,
when
you're
doing
a
regular
write,
the
kernel
is
going
to
block
or
Cache
everything
in
the
page
cache.
That's
why
you're
getting
all
these
little
4K
block
iOS.
A
So
how
does
that
relate
to
debuff,
fine,
so
debuff
find
is
a
function
that
looks
up
the
debuff
for
the
block
that
you're
writing.
The
debuff
is
like
the
internal
representation
of
the
Block
in
Cache,
and
so
you
have
to
lock
the
block
before
you
write
it,
and
so,
as
you
can
imagine,
there
are
tons
and
tons
of
blocks
in
Cache.
A
Okay,
this
is
a
simplified
view
of.
What's
going
on
so,
let's
say:
I
want
to
write
block
zero
I
first
need
to
Hash
the
bucket
this
case
bucket
three
and
lock
it
so
that
nobody
changes
out
the
the
list
from
under
me
and
then
I
iterate
through
all
the
blocks
in
the
bucket
until
I
find
zero
I,
lock
it
okay!
A
If
you
do
a
one
megabyte
write
and
it's
broken
up
into
little
4K
block
iOS,
then
you're
going
to
have
256
little
block
iOS
all
trying
to
lock
the
same
block
and
the
way
it
works
in
the
zval
driver
is
that
when
a
block
I
o
comes
in
it'll
hand
it
off
to
a
thread.
So,
let's
just
say
you
have
16
processor
or
16
CPUs
16
threads,
so
it
hands
off
all
these
little
block
iOS
to
all
these
threads
and
they're
all
trying
to
get
the
same
lock.
A
A
So
when
you
load
up
the
ZFS
module
it'll
create
the
number
of
buckets
based
upon
how
much
available
memory
you
have.
So
it
could
be.
You
know
thousands,
but
historically
we
always
hard-coded
8000
locks,
so
one
lock
would
handle
multiple,
multiple
buckets.
So
when
you
had
all
this
lock
contention
going
on,
you
were,
you
could
be
holding
a
lock
that
other
parts
of
the
block
device
you
wouldn't
be
able
to
access
it
there
either.
A
A
So
anyway,
it's
a
new
API
for
talking
to
your
block
driver
and
the
difference
is
instead
of
getting
tiny,
little
block
iOS
from
the
page
cache
you
get
one
big
struct
request
that
points
to
multiple
block
iOS.
So
that
way
you
can
lock
the
block
per
big
request
rather
than
per
little
block.
I
o
so
that's
the
main
benefit
to
ZFS,
but
there
are
other
benefits
too.
So
the
reason
it's
called
block
multi-q
is
that
it's
a
queued
interface.
A
So,
instead
of
with
submit
bio,
where
you
submit,
and
then
you
wait-
okay
next
one
submit,
it
just
puts
it
into
a
queue
with
block
multi-q,
so
the
kernel
can
rearrange
or
merge
iOS
if
it
wants
within
the
queue
and
then
when
it's
ready
to
kick
it
out
of
the
queue,
then
it
wakes
up
your
driver
and
it's
called
multi-q,
because
there's
not
just
one
big
queue.
There's
multiple
cues
that
you
can
spread
across
multiple
CPUs,
so
you
get
better
parallelism.
A
All
right
so
on
to
the
benchmarks,
so
here
I
took
eight
nvme
drives,
made
them
into
a
raid,
zero
pool
and
then
just
ran
DD,
and
this
is
one
DD
to
one's
Evol,
running
regular
non-odirect,
and
so
you
can
see
with
the
old
submit
bio
interface.
I
got
between
400
and
600
megabytes,
a
second
at
different
block
sizes
and
then
with
block
multi-q
I
got
around
750
to
900
ish,
so
pretty
good
speed
up
there.
A
This
is
the
same
Benchmark
1dd
to
one
Z
Vol,
but
with
o
direct,
and
you
could
see
it's
close
to
the
same,
but
block
multi-q
is
actually
a
little
bit
worse
in
all
the
cases
and
I'll
go
over
later.
Why
I
think
that
is
okay?
This
is
a
parallel
write
Benchmark.
This
is
spawning
off
16
DDS
in
parallel
writing
to
16
Z
Vols,
and
this
is
kind
of
the
best
case
scenario
for
Block
multi-q.
A
Okay,
now,
let's
look
at
reads
so
this
is
a
single
read:
single
DD
read
from
a
single
Z,
vol
non-odirect
and
the
performance
is
close
to
the
same,
but
block
multi-q
is
a
little
bit
better
at
8K,
Vault
block
sizes
and
one
Mega,
Ball
block
sizes
and
then
parallel
read.
They
basically
perform
the
same
again.
Parallel
reads:
16
DD
reads:
non-odirect.
A
A
Okay,
so
now
I
want
to
look
at
all
those
same
benchmarks,
but
look
at
the
CPU
usage,
and
here
I
was
just
running
the
time
command.
So
I
was
looking
at
wall
clock
real
time
and
system
time,
so
CPU
time
and
wall
clock
time.
So
real
is
the
wall
clock
times.
This
is
the
CPU
time
and
like
before
you
can
see.
A
The
yellow
line
is
the
ultimate
bi
interface
with
this
is
a
single
right,
so
it
takes
a
lot
longer
to
complete
and
block
multi-use
a
lot
quicker,
but
you
can
also
see
the
red
line.
Is
the
block
multi-q
system
time?
And
you
can
see
that
the
block
system
block
multi-q
system
time
is
higher
than
the
submit
bio
system
time.
So
it's
using
your
coars
morph
is
using
Warrior
cores
more
efficiently.
A
And
then
this
gets
even
more
pronounced
in
the
parallel
right
case.
Again
we
know
block
multi-q
is
a
lot
faster
here,
but
if
you
look
at
the
red
line,
which
is
the
block
multi-q
CPU
timer
system
time,
and
then
you
compare
that
to
the
submit
bio
system
time,
the
green
line,
you
can
see
that
block
multiq
is
really
using
Warrior
cores,
which
is
good.
I
mean
you
pay
for
those
cores.
You
want
to
use
them
to
get
faster
rights.
A
A
Looking
at
single
reads:
non-odirect
block
multi-q
was
a
little
bit
faster
at
8K,
which
we
knew
and
about
the
same
amount
of
system.
Time
and
rounding
it
out.
Parallel
reads:
Nano
direct,
basically,
the
same
single
reads
with
odirect.
Basically,
the
same
parallel
reads
with
odirect
block:
multi-q
is
a
little
bit
slower
for
the
AK
block
size.
A
Okay,
so
those
were
all
sequential.
This
is
some
numbers
that
Tony
Nguyen
ran
my
point.
These
are
a
bunch
of
different
tests
that
he
ran.
I
don't
want
to
get
into
the
actual
numbers,
because
it's
all
over
the
board
and
that's
kind
of
the
point.
The
point
I
want
you
to
take
away
from
this-
is
that
lock
multi-q
is
not
an
instant
win.
You
really
have
to
try
it
with
your
workload.
It
may
be
a
lot
worse
for
random,
reads
and
writes
if
you're
running
odirect,
you
probably
don't
even
want
to
use
it.
A
Now
I
mentioned
that
block
multi-q
was
a
little
bit
slower
in
some
of
the
cases
and
I
said
I
want
to
touch
on
it
later
and
I.
This
is
the
reason
why
I
think
it's
a
little
bit
slower
check
my
time
here
when
you
do
a
write
with
block
multi-q,
it
gets
put
into
a
queue
into
the
kernel
and
then
at
a
certain
time
the
kernel
is
going
to
kick
it
out
of
the
queue
to
your
block
drivers,
the
Z
of
all
driver
to
say
processes.
It
process
it.
A
So
that
takes
time
once
it
goes
into
the
zval
driver.
Then
we
spawn
off
a
thread
to
deal
with
it.
That
takes
time
so
it
kind
of
gets
double
queued,
two
wake-ups
and
it
doesn't
necessarily
have
to
be
that
way.
You
could
do
a
right.
It
goes
into
one
of
the
block
multi-qs
and
then,
when
the
kernel
wakes
up
your
block
driver,
we
could
just
synchronously
do
a
right.
We
could
just
Synchro
synchronously
call
zeev
all
right
and
when
I
tried
that
it
worked
for,
like
the
first
four-ish
writes,
and
then
it
would
kernel
panic.
A
A
A
So,
for
example,
if
you
want
to
use
block
multi-key,
if
you
want
to
test
it
out,
you
would
set
this
to
one
and
then
import
your
pool,
because
that
would
load
your
Z
Vols
or
you
could
create
a
z
Vol
after
it
or
you
could
even
have
cases
where
you
create
a
z.
Vol
set
this
value
to
1,
create
another
Z
Vol
and
those
two
z-volves
use
the
two
different
code
paths.
One
uses
submit
bio
one
uses
block
multi-q,
xivo
threads.
This
is
actually
an
existing
pre-block
multi-q
parameter.
A
This
is
just
the
number
of
z-val
processing
threads
in
the
zval
driver.
I.
Think
it's
default
set
to
one
which
says
use
the
number
of
CPUs
as
evolve
block
multi-q
threads.
You
can
think
of
this
as
the
number
of
cues
to
tell
the
kernel
to
create
I
think
this
is
also
set
to
zero.
To
say:
okay
default
to
the
number
of
CPUs
evolve
block
multi-q
depth.
A
You
can
tell
the
kernel
how
big
you
want
your
cues
to
be,
but
in
all
my
testing
it
didn't
really
affect
the
performance
at
all
and
then
finally,
zevolve
block
multi-q
blocks
per
thread.
This
is
kind
of
a
way
of
telling
the
kernel
how
big
you
want
your
iOS
to
be,
or
what
is
the
optimal
size.
I
would
like
my
iOS
to
be,
and
this
is
an
interesting
value
which
I'll
get
into
a
little
bit
so
I
mentioned
because
of
the
Locking.
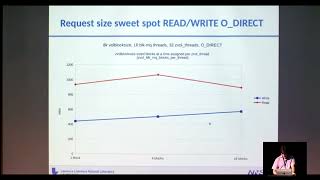
A
You
want
to
process
big
block
iOS
or
more
specifically,
you
want
to
process
block
iOS
that
are
the
same.
I
o
size
as
your
Vault
block
size,
so
you'd
say:
okay.
Well,
if
my
Vault
block
size
is
one
megabyte,
then
I
want
to
tell
the
kernel.
I
want
one
megabyte
block
iOS,
and
you
can
do
that.
That's
fine,
but
then
remember
that
it's
doing
all
this
overhead
with
this
double
queuing.
A
And
this
is
where
I
kind
of
went
down
the
rabbit
hole.
So
the
kernel
provides
this
function
called
block
q.
I
o
opt
which
is
documented
as
set
optimal
request
size
for
the
cube,
but
if
you
set
it
to
one
megabyte
or
whatever
you
want
to
set
it
to,
it
doesn't
seem
to
give
you
those
iOS.
So
I
didn't
have
any
luck
with
this,
but
there's
kind
of
a
roundabout
way
to
do
it.
With
these
two
other
functions.
A
A
A
Just
a
few
other
interesting
commits
I
want
to
talk
about
reduce
debug
fi
debuff
find
Lock
contention.
This
was
something
that
Brian
merged
and
this
basically
converts
all
those
debuff
locks
from
a
mutex
to
a
rewrite
semaphore,
and
this
could
potentially
help
if
you
have
like
mixed
reads
and
writes.
Although
we
did
get
a
report
from
one
of
our
vendors
saying,
we
didn't
get
as
good
of
performance
with
this
and
then
the
other
commit
I
want
to
mention.
Is
this
dynamically
sized
debuff
hashmutex
array?
I
did
talk
about
this
earlier?
A
A
Okay,
so
what
else
can
we
do
Beyond
block
multi-q?
What
are
some
future
things
we
could
do
to
improve?
I've
already
talked
about
the
double
queuing.
I
think
that's
probably
the
biggest
win
with
the
least
amount
of
effort.
If
we
can
just
Synchro
synchronously
call
zval
Wright
from
whenever
we
get
a
block,
I
o
I
think
that's
going
to
be
a
lot
better.
A
A
A
A
You
have
to
recompile
all
your
applications
to
pass
in
the
O
direct
flag
at
open
which
no
one's
going
to
do,
or
you
could
do
this
thing
called
Library
call
interception
where
you
can
hijack
calls
to
say
open
or
open
ad,
redirect
them
to
your
library
and
then
in
your
library.
You
add
in
the
O
direct
flag
and
then
just
call
the
normal
o
Direct.
A
So
this
is
what
I
want
to
do
for
the
hackathon
tomorrow
and
we'll
see
if
this
helps.
So
this
would
only
help
if
you're,
if
you're,
using
it
with
an
application,
that's
using
Z
Vols,
but
it
could
also
help.
If
you
have
a
file
system
on
top
of
a
zval
you
could.
You
could
use
this
hack
too.
So
this
could
speed
up
like
copy
or
sync
tar
things
like
that.
A
A
A
A
A
Yeah,
the
question
was:
did
I,
try
did
I
try,
setting
Z
vol
request;
sync
guys
try
setting
that
to
one
to
get
around
the
double
queuing:
I,
yes,
and
no
that
code
path.
That
you're
talking
about
is
what
I
used
for
the
synchronous
right,
I
didn't
set
that
value
I,
just
hard-coded
it
and
tried
it
and
that's
what
was
giving
me
the
problem.