►
From YouTube: Second March 2022 OpenZFS Leadership Meeting
Description
Agenda: test framework; compression
https://docs.google.com/document/d/1w2jv2XVYFmBVvG1EGf-9A5HBVsjAYoLIFZAnWHhV-BM/edit#
A
Welcome
to
the
second
march,
2022
open,
zfs
leadership
meeting
thanks
for
joining
us
again
this
month,
four
weeks
after
the
last
meeting,
we
occasionally
do
have
these
meetings
fall
twice
in
the
same
month,
I
see
only
one
agenda
item
on
the
in
the
dock
update
on
compression
from
rich.
I
love
to
hear
about
that
and
then
we'll
have
time
for
other
q
a
show
and
tell
please
review
my
code,
etc.
A
B
It
helps
when
I
unmute,
doesn't
it
yeah
yeah,
conveniently
the
first
entry
on
the
meeting
list
is
a
request
for
people
to
review
it.
So
it
combines
two
things
in
one,
but
no
it's
a
pretty
simple
thing.
I
was
tinkering
around
with
updating
the
compressors
and
I
noticed
exactly
how
poor
the
performance
was
with
the
standard
and
trying
to
use
it
at
any
non-trivial
compression
level.
Even
on
systems
where
you
have
quite
a
lot
of
computational
power
available.
B
B
B
B
B
Currently,
the
pr
that
I
opened
only
tries
this
if
you're,
using
a
z,
standard
level
over
three
and
if
you're,
using
a
block,
if
you're
handing
it
a
source
block,
that
is
at
least
128k,
because
the
standard
three
seemed
to
be
about
the
cutoff,
where
it
stopped
being
a
performance
win
as
reliably
even
with
just
lc4,
or
rather
it
was
still
a
performance
one
with
just
lz4
but
z
standard.
One
plus
lz4
was
not
necessarily
a
win
and
just
using
lz4
had
the
previous
described
significant
storage
efficiency
loss.
B
So
you
know
that's
where
that
heuristic
is
right
now,
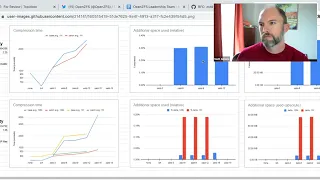
but
the
graph
you
have
on
screen
is
possibly
my
favorite
of
them,
showing
going
from
two
hours
to
about
15
minutes
for
compressing
a
z
standard
15
on
a
raspberry
pi
for
a
40,
odd
gig
data
set.
That's
mostly
incompressible,
so
you
know
that
that's
nice.
B
The
high
compressibility
result,
above
that
also
on
the
pi,
doesn't
go
that
high,
because
it
would
have
taken
most
of
a
day
to
run
the
benchmark,
because
this
is
the
average
of
multiple
results
and
if
it
takes
several
hours
yeah.
But
the
shape
of
the
graph
is
pretty
clear:
it's
a
logarithm
because
otherwise
the
if
you
do
it
linearly
it
just
drastically
dominates
with
the
results
on
the
end,
and
you
can't
tell
that
there's
a
difference
for
the
earlier
results,
but.
A
B
A
E
A
A
B
Well,
the
worst
case
would
be
lt4
z,
standard
one
then
z,
standard
four,
but
the
top
left.
The
top
set
of
results
is,
or
rather
the
top
left
results
are
on
the
highly
compressible
data
set.
That
gets
a
ratio
of
like
2.25
to
1
on
z,
standard
3.,
so
you
can
see
that
it's
actually
still
slightly
faster.
There,
too.
C
B
A
A
B
C
B
B
That,
actually,
I
don't
have
graphs
ready
for
it,
but
I
do
have
some
experiments
with
that
and
a
companion
pr
that
lets
you
tune
how
where
it
draws
that
threshold
in
general,
because,
as
somebody
pointed
out,
you
know
on
a
four
meg
block,
12.5
percent
is
quite
a
lot
to
require
of
it
when
you
want
all
the
savings,
but
it's
not
it's
not
significantly
different.
If
I.
C
B
Yeah,
so
I
the
reason
I
made
the
pr
or
I
made
the
branch
that
I
haven't
opened
up
here
for
yet
to
let
you
tune
the
threshold
for
12.5
percent
was
because
I
found
and
actually
that's
what
started
me
on
making.
This
was
because
I
found
that
on
highly
incompressible
data
sets.
If
you
turn
up
that
threshold,
then
you
know,
as
I
wrote
up
in
the
pr
my
understanding
of
how
lg4
does
its
early
abort
is
not
quite
what
I'm
doing
here
so
much
as
like.
B
B
So
there's
a
number
of
places
that
this
could
be
tuned
further,
like
I
jumped
from
finding
64k
that
as
a
bad
heuristic
to
start
compressing
to
128k
and
that
works
pretty
well,
there's,
probably
a
sweet
spot
in
between
there,
depending
on
your
data
set,
of
course
and
yeah.
There's
the
comment
that
I
put
in
it's
just
a
summary
of
this,
but
you
know
I'd
like
it.
B
If
anyone
had
any
review
comments
feedback,
I
just
pushed
a
less
invasive
version
of
it,
because
the
initial
proof
was
just
copying
and
pasting
the
z
standard
compression
step
again.
But
you
know
this
just
wraps
the
function
and
calls
but
yeah
there's
a
number
of
dimensions
to
be
tuned
to
find
something
optimal
and.
B
B
B
A
C
B
A
D
B
A
A
Yeah,
yes,
presumably
because
it's
you
know,
it's
there's
60
megabytes
or
you
know
a
third
of
a
third
of
a
percent
of
the
stuff.
It
just
decided.
Oh
well,
we're
not
going
to
do
the
z
standard
six
on
it.
The
other
thing
I
would
do
is
you
know
to
show
that
the
worst
case
of
what
you're
paying
would
be
with
z,
standard
four
right,
because
that's
the
first
level
that
you
start
this
behavior
right.
That's.
B
A
A
Is
probably
is
presumably
like
cheaper
than
z
standard
six,
so
I
would
just
do
it
on
z,
standard
four
to
show
like
this
is
the
worst
case
and
then,
hopefully,
that's
like
yeah.
In
the
worst
case,
we're
gonna
add
like
one
percent
of
the
cpu
time
or
whatever,
and
then
and
then
we
say
great,
like
that's
fine
go
ahead.
B
C
G
C
Quite
a
bit
faster,
but
there
is
going
to
be
in
the
pathological
case.
You
are
spending
a
bunch
more
time
and
yeah
if,
if
we
can
make
it
work
with
just
lz4
as
the
heuristic
instead
of
having
to
do
as
a
four
and
then
centered
one.
I
think
that
would
be
better.
But
I
agree
that
you
don't
want
to
opt
out
of
compression
on
blocks
that
would
have
compressed.
So
we
have
to
make
sure
we're
not
doing
the
false.
C
C
G
B
Yeah
the
5900x
was
done
with
nvme
drives.
The
pi
4
was
done
with
a
usb
attached
ssd
because
it's
the
fastest
interface
on
it,
though
it
bottomed
next
on
the
usb
chip
anyway,
but
that
also
slightly
dovetails
into
the
other
three
bullet
points
I
threw
on,
which
are
that,
surprisingly,
to
me,
I
didn't
find
that
much
of
a
win
updating,
lz4
c
standard
or
z
lib
for
that
matter.
B
Which
is
sad
because
I
spent
some
time
making
sure
that
it
worked
pretty
robustly
but
I'll,
at
least
with
the
z
standard
stuff.
I'm
going
to
continue
experimenting
with
it
because
I
feel
like
I
must
be
doing
something
wrong,
but
with
some
of
the
graphs
I
got
but
lz4
the
decompressor
I
mean
I
pitched
in
the
pr
is
a
significant
win
to
use.
B
B
B
When
using
the
versions
that
had
up
before
they
had
the
versions
before
they
tinkered
with
the
compression
constants
to
make
it
more
expensive,
but
after
they
added
a
bunch
more
optimizations
which
surprised
me-
and
I
need
to
make
sure
that
I'm
not
compiling
it
without
the
go
fast
flag
somewhere,
but
there
are
charts
there.
But
basically
it's
not
that
consistently
a
win,
and
once
you
get
past
one
five,
oh,
they
upped
the
difficulty
on
the
compression.
So
there's
a
marked
jump
on
anything.
That's
not
the
5900x
or
on
incompressible
data.
B
C
B
B
Yeah,
unfortunately,
the
far
look
ahead
stuff
is
like
128
plus
megabytes.
I
did
look
at
wiring
up
the
dictionary
stuff,
but
that's
a
very
complicated
proposition
and
makes
everything
really
complicated,
especially
with
wanting
immutable
results
or
reproducible
results
rather
and
zlib.
I
looked
at
just
out
of
morbid
curiosity
and
didn't
find
significant
wins
from
any
of
the
the
lib
forks
that
I
tried.
B
A
So
we
we
probably
will
have
to
rely
on
some
argument
about
like
well
the
number
of
blocks
that
fall
into
this
range,
where
they
can't
be
compressed
by
lz4,
but
they
can
be
compressed
by
z,
standard
one.
Those
are
the
only
ones
that
we're
really
paying
this
extra.
This
significant
penalty
for
and
those
are
going
to
be
such
a
tiny
fraction
of
the
blocks
that
it's
okay,
but.
A
Yeah,
so
really
you're
going
to
have
to
be
kind
of
going
based
on
some
argument
about,
like
what
percent
of
the
blocks
are
like
this
versus
the
percent
of
the
blocks
that
are
like,
like
you're
you're,
saying,
like
there's,
there's
whatever,
like
three
percent
of
the
blocks,
we're
going
to
pay
this
extra
25
of
cpu
time.
But
then
there's
you're
going
to
win
some
cpu
time
on
the
blocks
that
turned
out
to
be
not
compressible
at
all,
and
we
detect.
We
detected
that
which
seems
like
it's.
B
A
C
A
C
C
A
A
A
B
The
way
I
would
probably
do
it
would
probably
be
to
compile
a
second
version
of
the
compressor,
because
it
does
it
as
a
define
for
how
frequently
it
skips
forward
yeah.
So
if
you
define
that
to
never
do
it,
the
reason
I
wouldn't
just
substitute
a
variable
is
that
I'd
be
worried
about
it
being
able
to
inline
things
yeah,
but.
A
In
any
case,
I
think
this
is
very
promising.
I
think
you
know
folks
have
talked
been
talking
about
this
for
this
kind
of
approach
for
years
and
years.
I
think,
since
even
you
know,
in
the
gzip
days
of
saying,
like
hey
like,
can
we
make
something
or
just
we'll
just
like
give
up
more
quickly,
and
so
seeing
this
actually
land
would
be,
would
be
really
great.
C
B
C
B
Much
more
complicated,
the
other
other
thing.
I'd
remark
is
that
currently
I
just
have
a
module
tunable
to
turn
off
the
behavior,
so
you
know
it's
very
easy
to
test,
but
also
it
would
be
easy
to
convert
that
into
a
parameter
so
that
if
people
found
that
their
performance
was
markedly
worse
with
this
configuration
or
they
really
wanted
all
the
savings.
A
Some
like
middle
ground,
that
is
nearly
as
good
like,
where
there's
really
no
significant
downsides
for
any
workloads.
I
feel
like
we're
really
close
to
that,
so
I
think
I
think
we
should
try
to
keep
on
your
current
approach
of
just
having
it
be
a
mod
module
parameter
rather
than
elevating
it
to
another
property.
B
A
A
C
B
B
A
B
C
C
Mostly,
I
imagine
people
use
like
the
default
three
or
they're
going
like
very
high
because
they
wanna
all
the
trade
off.
I
think
you
know
I
recommend
people
probably
don't
go
over
10
because
the
it
just
the
speed
drops
down
to
like
single
digits
megabytes
per
second
per
core
after
that,
when
you
get
right
up
to
like
19
and
the
memory
usage
also
goes
a
lot
higher
for
not
much
game,
but
you
know
for
ike
level
stuff
where
they
know
I'm
going
to
write
this
once
and
keep
it
a
long
time.
H
B
B
One
of
them
I'd
be
mostly
fine
with
distributing.
I
actually
gave
someone
a
copy
for
another
reason
for
one
of
them
it's
just
though
I
think
I
can't
publicly
distribute
it
because
the
license
doesn't
agree.
One
of
them
is
my
directory
of
lsi
firmware,
zip
files.
That's
the
incompressible
one,
the
highly
compressible
one
is
the
snapshot
of
my
mailer.
B
H
C
B
Yeah
I
have
copies
of
those.
The
problem
I
found
was
mostly
that
they're,
all
pretty
small
so
like
you,
can
make
a
million
copies
of
them,
but
the
only
one-
and
I
think,
the
one
that
got
used
for
a
lot
of
disease
standard
benchmarking
in
the
initial
pr
which
I
actually
should
run
on
this.
I
didn't
think
to
put
those
together.
I
was
using
it
for
other
things
is
a
don't
book
wikipedia.
A
H
Yeah,
so
if
you
want
to
go
through
the
trouble
and
automate
the
generation
of
these
test,
data
sets
because
they
think
we
cannot
commit
the
test
data
sets
anywhere.
But
if
you
can
commit
the
script
that
generates
the
test
data
sets.
That
would
be
a
pretty
good
win
methodology.
If
it's
not
too
much
work
for
you.
B
G
B
A
B
B
E
C
A
C
Send
it
tried
to
do
would
hit
the
the
dirty
data
cap
because
200
times
24
is
over
four
gigs
and
it
would
cause
a
delay
flush
out
and
be
like
okay,
you're
over
you're
quoted
now
and
wouldn't
let
you
finish
the
receive
and
would
fail,
but
now
that,
because
it's
a
single
v,
dev
pool
the
inflation
factor
is
one
the
test
doesn't
fail
and
it's
a
negative
test.
So
it's
supposed
to
fail,
and
so
I
don't
know
what
to
do
to
make
the
test
actually
test
what
it's
trying
to
test.
A
Yeah
I
mean
there's
a,
I
can
imagine
a
bunch
of
different
approaches
it.
It
might
be
reasonable
to
like,
since,
as
you
were,
describing
the
problem,
you're
saying
you
know,
you're
supposed
to
be
able
to
go
over
your
quota
by
one
txg
right
and
the
txg
is
four
gigs
and
but
but
we
aren't
writing
four
gigs
of
data
right.
So
the
test
was
relying
on
this
other
behavior
that
it
wasn't
trying
to
test,
and
you
know
now,
we've
changed
that,
and
so
it
fails.
A
A
F
C
Think
the
the
virtual
pool
recruiting
might
not
actually
be
four
gigs
right,
all
right,
so
yeah
I'll
make
that
change
and
add
that
to
the
pr
and
that
should
solve
that
failing
test
a
bunch
of
the
other
ones.
I
just
had
to
add
explicit
z-pool
sinks
in
between
steps
so
that
you
know
before
they
were
flushing
because
they
had
written
at
least
a
couple
hundred
megabytes
of
data,
but
they
were,
it
turns
out.
H
So
there
there's
a
bunch
of
crafty
code
in
the
testrunner.pi
that
I
don't
really
know
whether
anybody
is
using
specifically.
The
zfstest.sh
script
only
uses
the
testoner.pi
in
a
certain
way,
which
is
using
run
files
every
time,
even
if
you're
on
the
single
test
with
dash
lower
lowercase
t,
and
it
still
generates
a
run
file
that
just
contains
that
one
test
and
runs
that
at
least
I
think
that
is
the
case.
H
G
H
So
the
feature
that
checks
the
checks
for
inadvertent
tunable
modifications-
I
implemented
it
inside
testrunner.pi
as
a
python
function.
Decorator
that
runs
like
in
the
test
or
test
groups
run
function,
basically
snapshots
module
parameters
before
running
the
test
and
then
after
compares
and
panics,
if,
if
the
module
parameters
don't
match,
so
it's
a
pretty
intrusive
approach
and
I
don't
really
have
the
cycles
to
to
make
it
as
pretty
as
I
think
john
kennedy
asked
me
to
do.
It.
C
H
H
Yeah,
I
don't
it
would
probably
work
because
most
of
our
tunables
are
really
you
write
something
in
and
you
get
that
value
out.
So
in
theory
that
might
work
but
yeah.
I
would
personally,
I
think,
if
a
test
group
or
an
individual
test
doesn't
reset
the
tuner
bits
to
whatever
they
were
in
the
beginning,
then
that
is
a
faulty
test
and
we
should
fail
immediately.
H
A
E
G
C
Yeah
so
like
right
now,
when
you
write
individual
blocks,
get
they
happen
in
a
task
queue.
That
is
a
thread
and
we
limit
it
so
we're
only
using
75
percent
of
the
available
task
queues
or
whatever
for
compression,
but
I
think
that
yeah,
you
would
be
able
to
spin
off
extra
threads
and
and
possibly
do
that.
Concurrently,
I
don't
know
what
that
looks
like
as
far
as
cancelling
the
says,
standard,
four
or
better
based
on
the
result
of
the
other
one,
but
I
think.