►
From YouTube: Automated + secure CI/CD with Red Hat OpenShift on AWS (ROSA) and Advanced Cluster Security(ACS)
Description
CI/CD pipelines automate the testing of your updates and apply security practices to the change. Security concerns are flagged and addressed with Advanced Cluster Security for Kubernetes. Try ACS in your environment: https://www.redhat.com/en/technologies/cloud-computing/openshift/advanced-cluster-security-kubernetes/trial
A
A
In
order
to
do
we're
going
to
use
two
openshift
capabilities,
openshift
pipelines
based
on
tepton
and
openshift
git
Ops,
based
on
Argo
CD
tecton,
is
a
fantastic
new
technology
that
actually
puts
native
kubernetes
objects
into
the
kubernetes
engine,
allowing
for
the
control
of
pipelines,
whereas
Argo
CD
is
a
compliance
operator
that
controls
the
state
of
objects
on
the
system
itself.
What
you're
going
to
see
in
the
demo
now
is
a
combination
of
these
two
in
an
automated
fashion,
to
show
the
absolute
in
action
so
now
I'll
pass
over
to
Gerald.
B
B
Openshift
pipelines,
as
shown
here,
is
a
cloud
native,
continuous
integration,
continuous
deployment
solution.
It
uses
tecton
building
blocks
to
automate
deployments
across
multiple
platforms
by
abstracting
the
wide
underlying
implementation
details.
It
leverages
kubernetes
resources
for
these
building
blocks,
enabling
users
to
compose
tasks
into
a
pipeline
which
defines
the
overall
orchestration
open
share
pipeline
ships
to
the
number
of
tasks
out
of
the
box.
However,
users
can
use
additional
Community
tasks
provided
from
tecton,
Hub
or
Define
their
own
as
needed
to
support
their
workflows.
B
You
see
an
example
of
tecton
up
here
with
all
the
different
tasks
that
are
available
and,
in
this
particular
demo,
we're
actually
going
to
use
one
of
these
tasks
in
the
messaging
section
we'll
be
using
this
task
here
to
send
a
message
to
a
slack
Channel,
while
openshift
pipelines
will
be
handling
the
CI
portions
of
this
demonstration.
Openshift
git
Ops
will
be
handling
the
continuous
deployment
or
the
deployment
aspects
of
this
demonstration.
B
Openshift
get
Ops,
provides
the
capability
to
deploy
and
manage
configuration
and
applications
using
the
git
Ops
methodology.
Openshift
itself
uses
the
declarative
model
for
deployments
and
configuration,
which
is
a
very
natural
fit
with
a
git
Ops
approach.
This
entire
demo
in
fact
was
provisioned
with
openshift
get
Ops,
and
if
we
switch
over
to
the
openshift
git
Ops
View,
we
can
see
all
the
different
components
that
have
been
deployed
to
support
this
demonstration.
This
includes
infrastructure
components
like
openshift
security,
development
tools
like
Nexus,
and
sonar
Cube,
open
shift
pipelines.
B
B
So
an
openshift
pipelines,
as
mentioned
earlier.
It
is
really
composed
of
a
set
of
tasks,
and
these
tasks
are
represented
in
these
bubbles
that
you
see
here.
So
we
have
variables
tasks,
get
column,
tasks
Etc
with
each
task.
You
can
have
one
or
more
steps,
so
the
variable
task
only
has
one
step,
whereas
the
maven
task
has
two
steps.
B
If
I
go
to
the
tasks
runs,
so
a
task
run
is
a
equivalent.
Is
the
running
instance
of
that
task?
Every
task
when
you
run
it
becomes
a
task
run
and
if
I
look
at
an
individual
task
screen
here
and
I
look
at
its
yaml,
you
can
see
that
each
of
these
task
runs
as
being
signed
by
tecton
chains.
Tecton
change
is
an
add-on
for
openshift
pipelines.
B
It
is
currently
in
Tech
preview,
but
will
GA
quite
shortly,
and
tecton
changes
are
responsible
for
signing
all
of
the
task
runs
as
well
as
the
artifacts
that
are
generated
by
the
pipeline,
and
this
is
really
ensuring
that
organizations
can
ensure
Province
Providence
for
their
particular
application
that
they're
building
and
ensure
a
secure
supply
chain
as
they're
building
that
application.
So
here
I
can
see
that
it's
signed
if
I
scroll
down
a
bit
here.
B
I've
got
the
actual
signature
that
has
been
attached
to
this
particular
task
run
and
you
can
also
go
and
look
in
recore
for
the
metadata,
for
this
particular
test
run.
That's
associated
with
the
signing,
so
tecton
change
is
really
providing
all
of
that
provenance
information
and
ensuring
that
we
have
that
secure
supply
chain
as
we
go
through
things
going
back
to
the
details,
if
I
go
back
to
my
Pipelines
pipeline
runs
back
to
that
pipeline.
B
Well,
actually,
we
can
see
the
and
then,
as
we
continue
on
so
that's
a
brief
overview
of
the
the
tasks
and
how
they
work.
They're
really
set
up
in
a
directed
graph
one
after
the
other
and
executed
in
sequence.
From
left
to
right,
we
can
now
dig
in
and
actually
look
at
how
the
application
itself
is
being
built
so
for
the
first
step
of
the
the
pipeline.
B
What
we're
doing
is
we're
using
this
variables
task
to
aggregate
a
variety
of
information
about
the
environment,
that
the
downstream
tasks
will
then
use
to
interoperate
with
a
variety
of
different
Technologies,
so,
for
example,
for
openshift
security,
we
need
to
know
where
it's
been
deployed
to
and
the
token
that
we
need
in
order
to
authenticate
the
pipeline
to
interact
with
openshift
security.
Similarly,
we'll
do
things
with
sonar,
Cube
and
Nexus
to
allow
that
interaction
as
well.
B
Once
we
have
that
information
collected,
we
can
then
proceed
with
building
the
actual
application,
so
the
first
step
is
to
clone
that
Repository
and
for
the
source
code
for
that
application
and
then
we'll
move
on
to
actually
doing
a
build
using
Maven.
Now
this
is
a
Java
application,
so
we're
using
Maven
to
do
that
build.
But
if
this
was
a
different
language
or
framework,
we'd
use
a
completely
different,
build
tool
to
do
that,
build
as
well
within
the
maven
environment.
We're
executing
two
goals
within
that
Maven
environment.
B
The
first
goal
is
the
package
goal
which
will
actually
build
the
Java
artifact
the
jar
file
that
will
eventually
be
deployed
to
very
different
environments,
and
the
second
goal
is
to
take
that
Java
artifact.jar
file
and
publish
it
into
our
Nexus
artifact
repository,
which
is
a
third-party
repository
that
we're
using
and
make
that
available
to
developers
via
that
mechanism.
Once
we've
got
that
artifact
built
we're
going
to
move
on
to
the
static
code
analysis.
B
Here
we
integrate
with
sonar
Cube,
one
of
our
partners
and
performance,
static
code
analysis
that
can
be
used
as
part
of
our
Downstream
gating
checks.
When
we
move
to
production
and
we'll
see
that
a
little
later
on,
once
we
have
our
artifact
and
we've
done
the
code
code
analysis,
we
can
actually
build
the
container
image
at
this
point
in
time.
So
we
will
build
that
container
image
and
then
we
will
publish
that
container
image
in
an
open
shift
container
registry.
B
What
we
can
do
is
we
can
actually
run
that
scan
that
image
through
a
policy
check
in
openshift
security,
and
that
policy
check
will
then
use
policies
that
the
organization
has
created
and
curated
for
the
needs
of
their
particular
organization
in
order
to
validate
and
verify
that
that
image
is
in
compliance
with
their
requirements
for
our
particular
demonstration
here.
What
we've
said
is
that
we
need
to
have
at
least
a
critical
vulnerability
before
we
will
fail
this
particular
scan.
We
only
have
one
policy
violation
in
play.
B
Right
now,
which
is
at
the
red
hat
package
manager
is
in
the
image.
However,
that's
a
low
severity,
and,
as
a
result
of
that,
we're
only
getting
a
warning
out
of
the
policy
check
instead
of
a
failure
that
will
allow
to
proceed
on
and
go
to
the
next
step
in
the
the
pipeline.
Now,
if
we
did
have
a
failure,
we
can
then
send
a
notification
through
slack
to
let
the
developers
and
the
security
team
know
that
there
is
a
problem
that
they
need
to
identify
and
rectify
as
they
go
through
the
process.
B
So
that
is
the
upper
parallel
Branch
we're
running
our
security
scan
and
validating
compliance.
The
second
part
of
the
branch
here,
the
lower
part,
is
where
we're
actually
going
to
deploy
the
application
into
our
environments.
So
we
have
two
environments
that
we're
going
to
be
deploying
into
one
is
the
development
environment
and
the
other
is
the
stage
environment.
The
third
environment
production
is
going
to
be
done
separately
and
it
is
going
to
be
done
through
a
manual
approval
process
for
these
lower
environments.
We're
actually
going
to
do
continuous
deployment,
I.E,
no
gating,
no
approval
required.
B
The
next
step
is
a
very
simple
step.
It
is
really
just
coordinating
the
deployment
of
that
image
in
a
synchronous
fashion
with
openshift
get
Ops
and
ensuring
that
that
image
that
gets
deployed
successfully
in
the
development
environment
once
it's
deployed
successfully
in
the
development
environment,
we
are
then
going
to
do
an
integration
test
on
that
application.
Now
the
application
that
we've
deployed
is
an
API
based
application,
so
we're
going
to
do
an
API
test
on
that
application.
B
In
order
to
do
that,
we're
going
to
use
a
tool
called
Newman,
a
third-party
tool,
called
Newman
to
execute
those
API
tests
and
ensure
that
that
application
is
functioning
to
specifications
before
we
move
on
to
the
The
Next
Step.
So
once
we've
done
that,
we
can
then
continue
on
with
deploying
in
the
stage
environment
and
we're
going
to
follow
the
same
three
steps
that
we
did
previously.
I
won't
go
into
them
in
detail
again
and
deploy
into
that
stage
environment
with
a
git
update,
a
sync
and
an
integration
test.
B
Now,
once
both
of
these
branches
have
completed
this,
this
task
will
then
execute
next.
What
this
task
does
is
it
notifies
the
developers
that
the
build
has
been
completed
and
gives
them
information
about
the
output
of
that
build
and
the
way
that
we're
doing
that
to
allude
to
what
I
mentioned
earlier
about
techton
Hub?
That
is
done
through
a
slack
message,
so
we
look
at
our
slack
messages
here.
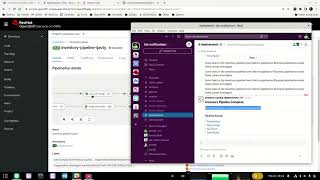
B
You
can
see
this
pipeline
I
believe
this
is
actually
the
notification
from
the
pipeline
that
we're
running
where
we
see
that
the
pipeline
executed
successfully
and
that
we
are
giving
the
developers
a
variety
of
information
here
about
that
pipeline
execution
that
they
can
go
and
look
into
for
additional
information
about
the
execution
of
the
pipeline.
So
there's
a
link
here
back
to
the
pipeline,
run
that
we're
showing
here
there
is
a
link
to
the
openshift
containers
registry,
where
the
image
is
being
stored.
B
There
is
a
link
here
to
openshift
security,
so
the
developers,
if
they
want
to
review
that
scan
in
more
detail
along
with
the
policies
they
can
go
and
view
that
here
and
then.
Finally,
we
have
a
link
to
our
sonar
Cube
code
analysis,
where
the
developer
can
review
that
as
well.
So
these
three
things
here,
these
three
items
we're
going
to
review
in
more
detail
when
we
review
the
next
step
in
the
process,
which
is
deploying
the
application
to
prod
through
a
gating
check.
B
However,
in
most
Enterprises
it
is
common
to
have
getting
requirements
in
higher
environments.
In
this
part
of
the
demo,
we
will
see
how
we
accomplish
this
using
git
workflows,
specifically
we're
going
to
use
a
pipeline
to
automate
the
creation
of
a
pull
request,
which
must
be
manually,
reviewed
and
accepted
before
the
change
can
be
deployed
to
a
production
environment.
B
The
first
step
is
identifying
a
specific
release
that
needs
to
be
deployed
to
production.
Many
organizations
have
an
existing
change
management
process
solution
and
these
can
be
integrated
with
openshift
pipelines
in
a
variety
of
ways,
with
web
hooks
being
the
one
of
the
more
common
mechanisms
for
doing
so
now
in
this
particular
demo
that
we're
doing
here,
the
pipeline
is
still
executing
in
our
cluster,
that
has
the
dev
stage
and
CI
CD
environments,
but
we
have
a
separate
cluster,
we're
actually
deploying
the
production
environment.
B
So
what
this
pipeline
is
going
to
do
is
going
to
execute
a
variables
task,
first,
similar
to
what
we
saw
in
the
previous
pipelines,
which
will
aggregate
some
information
that
the
other
tasks
are
needing
and
then
the
next
step
that
it's
going
to
do
is
to
get
the
image
digest
in
order
to
update
the
production
environment.
The
reason
why
we
need
to
execute
this
task
is
the
notification
that
we're
getting
from
the
container
registry
only
contains
a
reference
to
the
tag
I.E
the
prod
tag.
B
So
we
need
to
go
back
to
the
container
registry
and
translate
that
prod
tag
back
into
an
image
digest.
Once
we
have
that
image
digest.
We
can
then
update
the
reference
in
git
for
the
production
environment,
and
we
saw
this
task
in
our
previous
examples
for
the
development
and
staging
environments.
However,
there
is
one
key
difference
that
we're
doing
here
in
this
particular
execution
of
the
task,
in
this
case
we're
telling
the
task
to
create
a
new
branch
which
we
did
not
do
before.
B
So
we
will
clone
that
repository,
but
we
will
then
create
a
new
Branch.
We
will
update
that
digest
in
that
new
branch
and
we
will
commit
that
new
Branch
back
to
our
repository
once
that
is
completed.
We
will
then
create
a
pull
request
in
a
repository
that
a
human
will
then
be
able
to
review
and
approve.
If
we
go
and
look
at
our
pull
requests
here,
we
can
see
we
have
that
pull
request
ready
to
go,
and
if
we
look
at
our
code,
you
can
see
that
I've
got
a
couple
of
branches.
B
B
B
We
can
look
at
the
vulnerabilities,
get
more
information
about
what
this
is
about
and
decide
whether
or
not
this
is
something
that
we're
okay
with
proceeding.
In
this
case,
let's
say:
yes,
we're
fine,
with
proceeding
with
those
vulnerabilities,
so
they're
identified
and
we'll
click
that
box.
The
next
step
is
to
look
at
the
scan
and
policies
in
openshift
security.
So
let
me
go
ahead
and
click
that
one
this
will
take
us
to
the
openshift
security
portion
where
we
can
review
the
image.
So
we
can
see
that
this
has
a
risk
priority
of
20..
B
It
has
a
top
CVSs
score
of
7.5,
it's
used
in
two
deployments,
namely
the
development
and
staging
deployments,
and
we
can
see
a
list
of
all
of
the
cves,
the
vulnerabilities
that
openshift
security
is
identified
for
this
particular
image.
Now,
in
this
particular
case,
we
don't
have
any
vulnerabilities
that
are
failing
policy,
but
if,
for
example,
with
this
moderate
one
was
a
critical
vulnerability.
However,
we
investigated
it
and
we
know
that
it's
not
going
to
be
addressed
by
the
vendor
in
a
timely
fashion,
and
it
also
does
not
impact
our
particular
application.
B
We
can
request
that
this
CDE
be
deferred
and
the
security
team
can
then
review
that
request
for
a
deferral,
deferral
and
approve
it,
and
at
which
point
we
will
start
passing
our
policy
checks,
and
we
can
continue
on
with
deploying
to
production,
to
review
the
policies.
We
can
go
to
the
deployments
that
we've
done
already
and
we
can
see
the
two
policy
statuses
here
that
we've
passed
all
of
our
policies,
so
we're
good
to
go
in
terms
of
deploying
this
particular
image
into
our
production
environment
from
an
openshift
security
perspective.
B
So
I'm
going
to
go
ahead
and
I'm
going
to
check
that
box
off
and
then
the
last
step
is
I
mentioned
in
my
previous
flow
is
that
we
integrated
with
sonar
Cube.
We
can
go,
look
at
our
static
code
analysis
and
get
an
understanding
of
the
overall
state
of
our
application
in
terms
of
its
code.
We
can
see
there
are
no
outstanding
bugs
or
vulnerabilities
that
have
been
done,
Fire
by
sonar
q,
but
we
do
have
six
code
smells.
We
can
drill
into
those
and
have
a
look
and
see
if
there's
anything
here.
B
That's
of
a
particular
concern
to
us
in
our
case,
there's
nothing
here
that
we're
really
too
concerned
about
we're
willing
to
accept
this
so
again,
we'll
go
ahead
and
we'll
check
that
off
now
at
this
point
in
time,
we're
actually
ready
to
merge
this
pull
request,
but
before
I
do
that
what
I'm
going
to
do
is
I'm
going
to
break
this
off
into
a
split
screen.
So
we'll
take
this
tab
here
and
split
into
one
half
and
we'll
take
this
tab
and
split
it
off
into
another
half
and
go
back
here.
B
Let's
go
ahead
and
merge!
This
confirm
the
merge
so
once
this
gets
merged
at
this
point
in
time,
openshift
GitHub,
so
you
can
see
that's
happening
here,
we'll
go
ahead
and
actually
deploy
this
application.
So
you
can
see
the
old
pod
is
there.
The
new
pod
is
now
being
stood
up
with
the
new
image
and
then
the
old
pod
goes
away
and
we've
actually
deployed
this
change
now
automatically
through
openshift
get
Ops
once
we've
merged
that
change
into
git
Ops.
You
can
also
see
there's
something
else.
That's
running
here.
B
This
is
a
post
sync
Hook
from
openshift
get
Ops
that
is
triggering
a
testing
pipeline
so
that
we
can
test
our
new
deployment
in
production.
Just
to
validate
that
there's
nothing
wrong.
We
can
run
some
automated
tests
against
it
and
you
know
get
that
warm
fuzzy
feeling
that
our
deployment
was
successful.
So
if
we
look
at
that
in
more
detail,
we
go
back
to
pipelines.
Let
me
change
back
to
cicd,
oops,
sorry,
wrong,
cluster.
B
Suppose
I!
Don't
do
that
anymore!
Go
back
to
this
cluster
Pipelines
and
we
can
see
our
production
test
pipeline
is
run.
We
can
go
ahead
and
have
a
look
at
that
when
you
see
there's
really
only
two
steps
here,
we
run
an
integration
test
similar
to
what
we
did
before
using
Newman
to
test
the
apis
and
make
sure
that
nothing
is
broken
in
production,
and
then
we
send
a
notification
to
slack
to
ensure
that
to
let
the
developers
and
the
team
know
that
we've
deployed
this
to
production.
So
we
just
go
down
here.
B
We
can
see
now
that
we've
gotten
a
message
saying
that
production
has
been
synchronized
by
openshift
get
Ops
and
that
we've
succeeded
at
that
and
we're
good
to
go
with
our
production
deployment.
Now
that
we've
run
our
pipeline
a
few
times,
we
can
go
in
and
see
detailed
information
about
the
metrics
of
the
pipelines
in
terms
of
How
It's
performing
so
we're
going
to
look
at
the
metrics
tab
of
the
pipeline.
We
can
see
the
success
ratio
for
the
pipelines.
The
number
of
pipeline
runs
that
have
happened.