►
From YouTube: CNCF Harbor's Community 19 May, 2021
Description
CNCF Harbor's Community Zoom Meeting
A
A
B
B
B
So
in
the
future
it
is,
we
want
to
add
a
new
feature
that
helped
to
limit
to
the
the
replication
bandwidth
here.
I
I
submit
a
simple
purpose.
First,
in
this
proposal,
I
I
want
to,
I
want,
to
add
a
add,
a
speed
limit
when
user
added
the
replication
rule
here,
he
has
that
he
can
set
a
speed
for
one
replication
of
for
the
replication
job
and
the
under
this
will
limited
the
the
limited
replication
drop
to
the
speed.
B
B
Sorry,
I
mean
main
user,
create
a
pool
library
job
with
500
speed
and
it
will
download
each
each
ripple
with
this
speed-
and
here,
for
example,
he
has
two
rebels
radius
and
the
postgres.
So
totally
it
will
use
one
one
million
bags
per
second
and
he
can
also
create
another
replication
job
with
this
one
per
second,
and
if
there
are
three
levels
it
will
use
up
to
three.
B
B
B
B
A
A
C
C
Okay,
can
you
guys
see
my
screen
yep,
okay,
cool,
so
yeah
alex
mentioned
the
hub
operator.
You
know,
1.0.0
has
been
ga
in
at
the
early
over
may
in
early
may,
and
here
I
want
to
you
know
you
know,
recognize
some.
You
know
signature
significant
contributors
who
had
these
very
important
contributions
in
the
1.000
list.
C
They
are
from
you
know,
pierre
siemen
and
jimmy
max
hudson
from
oh
team
and
and
jamin
jung
from
vmware
team
and
the
tai
phong
wong
from
netease
and
goes
the
baby.
That's
a
a
hui
from
mama
and
xiao
xiao
yang
drew
from
qing
cloud
and
chiang
changing
from
a
loader
cloud
and
exever
it's
a
free
contributor,
so
a
great
thanks
to
those
contributors
who
did
a
very
significant
contribution
to
this
release.
C
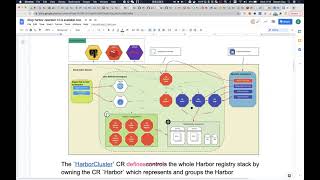
Okay,
here
I
want
to
quickly,
you
know,
share
some
overview
of
the
hub
operator.
Actually,
the
hardware
reader,
you
know,
provides
a
high
cut,
customization
ability
for
you
to
defend,
configure
your
you
know.
Own
hardware
stack
based
on
your
own
needs.
I
think
this
diagram
can,
you
know,
describe
the
overall.
You
know
design
of
the
hub
operator,
so
there
is
a
top
level
on
customer
resource
named
hardware.
Cluster
user
can
use
this
cr
to
defend
their.
You
know
deploying
on
harbor
cluster
stack.
C
That
means
the
why
we
use
the
harper
cluster
as
the
the
say,
because
you
know
harbor
is,
is
composed
of
multiple.
You
know
service
components
besides
harbor
its
own
component.
Our
need
depends
on
some.
You
know
a
service
like
process
seeker
as
database
and
already
said
cache,
and
you
know,
storage,
as
you
know,
something
like
a
first
scene
of
some
ss3
as
its
backhand
storage
service.
C
So
the
cloud
means
the
whole
stack
will.
You
know
include
the
hardware
components
as
well
as
its
dependent
service,
okay
here,
because
he,
the
cluster,
has
a
very
flexibility
for
you
to
define
your
scale.
For
example,
besides
it
deploying
the
harbor
components
like
hyper
core
hybrid
hydroxides,
the
you
have
very
very
you
know
a
strong
flexibility
to
configure
the
dependent
service.
C
C
Of
course,
if
you
have
some,
you
know
cloud
service
like
rds
or
someone
already
said
service,
then
you
can
also
create
some
endpoint
and
directly
configure
it
into
the
hardware
class.
That
means
from
this.
You
can
also
configure
some
external
or
pre-installed
service
as
the
dependent
service
of
the
harbor.
Okay.
C
C
You
know
you
other
section
for
you
to
to
defense,
such
in
cluster
service
for
the
in
cluster
for
post
seeker.
We
leverage
the
third
party.
You
know
zelado
pcker,
as
our
you
know,
a
p
secret
service
vendor.
We
use
already
ready
surfing
over
operator
as
the
radius
vendor
and
we
use
the
meo,
as
you
know,
as
a
compass
s3
compatible
back-end
storage
service.
So,
for,
though,
for
using
those
third
party,
you
just
need
to
define
your
requirements
in
the
hyper
class
part.
C
You
know
it's
a
little
different
with
the
configuration,
but
you
can
define
some
requirements
for
the
service.
Then
you
know
a
hardware
operator
will
help
you
to
connect
it
to
the
underlying
operator
to
create
some.
You
know,
service
shares
and
configure
these
services
here
into
harbor.
As
you
know,
corresponding
back-end
configuration,
let's
make
the
harbor.
You
know
work
aware.
So
that's
that
means
you
have
very
flexible
flexibility
to
configure
your
harbor.
For
example.
Maybe
you
use
rds.
C
That
means
the
aws
pcq
service
as
your
back-end
database,
but
you
can
also
use
a
miao
operator
to
create
a
ls3
back-end
service
in
the
class.
So
they
can.
You
know
mixed,
not
you
know
all
external
or
all
in
class
right,
because
you
you
can
configure
the
hardware
stack
based
on
your
real
needs
or
based
on
your
element.
C
So
in
a
short
words,
you
can
configure
external
service.
You
can
also
deploying
you
know
the
service,
together
with
the
hardware
components
into
the
cost.
Okay,
of
course,
here
I
want
to
mention
in
the
1.0.
The
service
is
it's
posed
where
the
ingress,
so
you
need
to
you,
know,
install
some
ingress
control
like
a
default
ngx
or
gce
or
ncp.
C
C
C
We
support
s3
and
s3
compatible
stuff
like
ews,
s3
and
miao,
and
we
also
support
swift
as
a
back-end
storage
and
besides
creating
the
hardware
class.
That
means
deploying
a
hybrid
cluster.
You
can
also
you
know,
update
your
cluster
by
changing
some.
You
know,
property
of
the
spec.
We
also
you
know,
supports
you
to
configure
different
replicas
of
different
components.
C
Okay,
and
besides
this,
we
also
support.
You
know
in
place
upgrades
that
means
you
can
upgrade
the
hardware
deployed
by
this
operator.
So
if,
of
course,
this
is
the
first
version,
so
there
is
no
upgrading
case,
but
in
future,
if
there
is
some
new
hyperversion,
you
know.
Currently
you
can
do
the
in-place
upgrades
process.
C
Of
course
we
support
cascade
deletion.
That
means,
after
you,
you
know,
create
delay
to
the
hardware
cluster.
All
the
link
in
the
resource
will
be
deleted
and
it
says
the
deployment
we
also
under
the
lifecycle
management.
We
also
support.
You
know
a
d2
operation.
That
means
you
can
configure
the
hardware
system
settings
with
the
config
map
in
a
declarat
declarative
way.
That
means
you
can
create
a
configure
map
to
specify
some
system
settings.
This
system
system
setting
can
be
applied
to
the
deployed
harbor.
C
Okay.
That
means
it's
a
very
easy
way
and
simple
way
for
you
to
update
your
updated
system
settings
where
you're
deploying
a
hardware
stack
okay-
and
I
just
mentioned
before
this
time-
we
expose
the
related
service
with
the
ingress.
So
far,
we
support
a
different
ingress
controller
like
ngx
as
a
default
one,
and
we
also
support
the
gce
from
google
and
the
nzx
ncp
from
the
vmware
sx.
C
C
You
know
we
also
want
to
make
sure
the
hub
operator
can
work
well
with
the
counter
ingress
controller
counter
is
also
a
a
kubernetes
ingress
controller
and
a
by
responsible,
you
know
already
needed
from
the
member
okay
for
the
long
term.
You
know
for
the
long
term
plan
here
at
least
some
key
features
we
may
introduce
in
the
long
term
release
the
first
one
is
support
more
back-end
storage.
C
Besides
the
current
reverse
system
s3
and
the
swift,
maybe
we
later
will
support
more
like
aero,
you
know
global
storage
and
adding
the
oss
and
gcs
the
google
cloud
storage
bike
and
also
will
support,
remove
the
optional
hardware
components
by
directly
updating
the
spec
of
the
deployment
hardware
class,
as,
as
you
know,
harbor
has
some.
You
know
mandatory
components
that
the
wheel
must
be
deploying
the
when
deployed
harbor
and
has
some
option
of
or
components
like
chatter,
museum,
notary
and
that's
you
know-
should
be
selected
by
your
by
yourself.
C
So
when
you
want
to
downgrade
your
full
stack
from
by
removing
some
hardware
components,
you
can
just
update
the
spike
so
far
it
does
not
support
okay,
and
we
also,
you
know,
introduce
the
new.
You
know
service
exposing
way
you
know.
Besides
the
ingress,
we
will
support
the
load
balancers
a
new
way
to
expose
the
related
accessing
service
and
maybe
in
future
we
support,
backup
and
restore
the
data
we
defend
some.
You
know
on
ucr
to
to
to
configure
this
process
and
maybe
auto
scanning
for
the
components.
C
C
You
know
choose
deploy
the
harbor
to
make
you
you
know,
use
the
harbor
in
a
very
you
know
easy
way.
You
know
very
simple
way.
Okay,
I
think
the
detail
operation
might
contain
some.
The
following
item.
Like
first
we'll,
you
know
a
refractor
the
configure
map
based,
you
know,
system,
setting
system,
setting
configurations.
C
We
all
you
know,
provide
a
crd
based
that
we
do
with
with
the
crd.
We
can
defend
some
system
settings
with
strong.
You
know
tabs
that
mean
it's
very
easy
for
addition
at
presenter,
I
mentioned
the
configure
map.
This
is
the
project
we'll
replace
the
config
map
with
pistol
with
a
new
crt,
basically
for
you
to
apply
system
settings
to
the
developer,
harbor,
okay,
and
we
also
support
auto
mapping.
You
know
approach
for
between
the
coordinating
name,
space
and
the
hardware
projects.
C
That
means,
if
you
you
know,
set
some
splash
special
settings.
When
you
create
a
company
name
space,
there
will
be
a
corresponding
hardware
project.
You
know
created
in
your
target
hover,
and
we
also
you
know,
support
you
know,
like
pull
secrets,
auto
injects.
That
means,
after
you
created
your
companies,
there
will
be
a
hardware
project
include,
and
we
also
create
some
robot
account
in
the
target
hub
project
and
the
mandate
to
the
service
account
for
you
to
so
you.
You
do
not
need
to
take
care
of
such
configuration
and
directly
start.
C
C
You
know
we
based
on
the
container
image,
rewriting
we
support
the
transparent
per
cache
setting.
That
means
we
can
provide
a
way
for
you
to
set
a
global
product
cache.
That
means
for
all
the
related
name
space
in
all
the
related
kubernetes
coordinating
names
with
their
image
paths.
You
know,
for
the
workload
deployed
to
that
means
to
those
limb
space.
The
emitter
part
can
be,
you
know
automatically
overwrite
to
the
specified
cache
per
cache
product,
so
that
for
you
to
you
know,
you
do
not
need
to
configure
it.
C
You
know,
with
a
very
you
know,
complicated.
We
will
provide
some.
You
know
simple
way
for
you
to
enable
the
perk
proxy
cache
of
hardware
in
your
coordinated
name
space.
So
all
the
details
will
help
you
to
will.
You
know
improve
the
user
experience
you
know
of
using
hardware
in
the
kubernetes
we
will
make.
We
will
let
it
use.
You
know,
use
a
hardware
with
the
small
and
the
simple
way.
So
this
is
a
lego
of
the
decor
operation
and
actually
for
the
d2l
operation.
Fundamentally,
we
have
the
we
have
done
some
prototype.
C
You
know
poc
project.
So
if
you
have
you
know
interest,
you
can
navigate
to
that
project,
to
learn
more
okay,
so
and
for
the
long
term
planning
we
have
created
the
1.1
and
the
window
to
read
the
plan.
If
you
want
to
learn
more
what
will
be
introduced
in
the
next
releases,
you
can
check
those
two.
Those
are
two
different.
You
know
plan
items,
okay,
so
that's
something
about
the
new
hub
operator,
so
we
will
continue
to
improve
the
hyper
reader
to
make
sure
it
has.
You
know
reasonable.
C
A
Thanks
thanks
steven
yeah,
you
know
this
is
this:
is
incredible?
We've
been
working
on
this,
for
what's
it
been
like
eight
months
at
least
you
know,
I
think,
a
huge
thanks
to
two
of
each
cloud
ray
of
each
cloud
put
in
a
lot
of
work
here
and
I
think
they're
they're
gonna
be
they're
gonna,
be
using
the
operator
very
soon
right.
A
A
I
would
just
mention
that
we
would
basically
have
the
harper
helm
deployment
as
well
as
the
harbor
operator,
and
you
can
use
helm
if
you're
targeting
a
smaller
single
cluster
deployment,
and
you
review
the
operator,
for
you
know
more
as
a
service,
but
it
doesn't
mean
that
we're
stopping
development
or
deprecating
the
helm
chart
in
any
way
we're
going
to
keep
both
helm
is
still
incredibly
popular.
It's
incredibly
easy
to
you
know
just
edit
a
bunch
of
a
bunch
of
values
in
the
helm
chart
you
can
see.
A
The
operator
is
much
more
complicated
right
and
there's
different
ways
to
deploy
it
with
these
components.
Without
you
know,
as
a
full,
stack
or
or
you
know,
a
thin
stack,
so
both
our
options
both
are
two
ways
to
deploy
those
kubernetes
clusters
that
we're
going
to
keep
investing
in.
So
any
other
questions
for
steven
for
the
operator
in
general,.
D
A
A
A
D
Yeah,
so
we
had
a
ton
of
attendees
for
both
the
session
that
we
had
in
the
office
hours.
So
I
want
to
thank
all
the
maintainers
and
everyone
that
showed
up
to
the
both
the
session
and
answering
a
ton
of
questions
during
the
office
hours.
There's
a
a
lot
of
questions.
We
captured
a
lot
of
them
in
a
hackmd,
that's
been
shared
out
to
the
community
and
to
all
maintainers
as
well.
So
hopefully
we
can
follow
up
on.
On
a
few
of
those,
there
were
some
feature
requests.
D
It
was
just
a
fantastic
showing
to
both
both
the
session
and
the
office
hours
and
is
great
to
see
one
more
thing
and
we'll
we'll
talk
more
about
this
in
june,
but
orlan
who
is
going
to
be
or
who
is
the
new
community
manager
for
harbor
and
me
we're
working
on
a
plan
for
a
setting
up
a
working
group
for
technical
documentation
for
harbor
to
kind
of
make
sure
that
the
technical
documentation
becomes
a
little
more
autonomous
within
the
project.
And
we
have
a
few
already
interested
contributors.
D
Who
wants
to
be
a
part
of
this.
So
I'm
going
to
ramp
things
up
in
june,
we'll
launch
it
in
june.
We'll
will
kind
of
revamp
the
office
hours
that
we
that
we
used
to
have
and
make
them
into
office
hours
for
technical
documentation,
first
and
foremost,
to
kind
of
get
that
working
group
up
and
up
and
running,
we'll
reuse.
The
harbor
dev
mailing
list
to
make
sure
that
everyone's
aware
of
the
conversations.
D
No
yeah
so
we're
going
to
switch
that
out.
So
we
have
the
community
meetings
at
this
time
and
it
makes
sense
to
have
the
office
hours
at
the
same
time,
so
we'll
schedule
the
office
hours
on
the
on
the
reverse
weeks,
not
the
reverse,
the
opposite
weeks.
So
today
we
have
a
community
meeting,
so
in
june,
we'll
have
office
hours
the
week
after
the
commitment.
A
Yeah,
I
mean
we're
only
really
speaking
to
tnn
here.
Everyone
else
is
a
harvard
maintainer
or
a
harvard
team
member,
but
the
2.4
is
yeah.
The
2.4
is
being
planned
right
now,
so
the
2.3
fc
is
this
week
and
then
ga
is
going
to
be
two
weeks
from
now,
two
or
three
weeks,
three
weeks
from
now,
so
we're
trying
to
collect
requirements
for
2.4.
A
A
A
We
only
had
two
last
year
so,
but
I
think
for
2.4
I
you
know
I
have
a
bunch
of
issues
if
I'm
from
github
smaller
issues
but
a
whole
series
of
them
and
then
you
know,
I
think
we're
making
improvements
to
replication,
just
a
lot
of
work
to
be
done
in
the
operator.
Still,
as
you
can
see
and
yeah
day,
two
management
is
a
big
theme.