►
Description
No description was provided for this meeting.
If this is YOUR meeting, an easy way to fix this is to add a description to your video, wherever mtngs.io found it (probably YouTube).
A
A
A
A
They
contribute
to
tensorflow,
could
flow
upstream
other
projects,
and
essentially
these
workloads
or
these
models
generate
their
own
data
types
artifacts
that
need
to
be
stored,
curated
and
shared
right,
so
some
type
of
a
content
management
system
and
being
that
there
is
no
dedicated
registry
for
these
machine
learning
artifacts
on
the
market
right
now,
the
latest
version
of
harbor
being
that
I
can
host
any
ocean
artifacts.
So
we
had
some,
you
know,
exchanged
some
ideas
and
thought
about.
A
You
know
why
not
distribute
these
as
oci
artifacts
and
start
using
harvard,
because
we
have
the
rule-based
access
control.
We
have
the
policies
around
lifecycle,
management
policies
for
deploying
replicating
right,
and
the
heart
is
already
running
on
the
on
the
kubernetes
cluster.
We
want
to
make
the
best
registry
for
kubernetes
workloads.
A
So
I
think,
regardless
of
whether
harvard
is
the
right
solution
for
this
type
of
workload,
it'll
be
interesting.
It'll
be
illuminating
to
see
what
that
process
looks
like
the
process
of
you
know,
looking
at
what
the
registry
vendor
has
to
do,
and
then
what
the
artifact
vendor
has
to
do
and
see.
If
you
know
we
can
potentially
turn
these
data
types
into
something
that
can
be
hosted
and
managed
on
hardware.
So
with
that
I'll
hand
it
off
to
the
henry.
B
Nothing
hi
thanks
alex,
I
actually.
I
would
like
to
have
the
the
person
counselor
from
the
psycho
to
share
his
his
powerpoint
and
also
discuss
his
the
the
pro
so
that
he
has
written
so
basically
check
out,
as
alex
said,
he's
a
long
time
partner
in
the
harvard
community
for
the
since
the
very
beginning
of
the
project.
B
C
C
D
B
C
C
C
D
C
Is
our
our
technique
lead
in
in
thai
cloud
who
is
working
on
our
internal
docker
registry,
but
he's
not
online
today
in
this
meeting
and
my
name
is
gautu
and
I
am
working
on
running
machine
learning,
workloads
on
kubernetes
and
I
I'm
maintaining
some
products
in
kubeflow
community
if
you
are
familiar
with
qfloor
the
pf
operator
and
petrol
jupiter
and
something
else
are
maintained
by
me.
So
let's
begin
this,
this
is
today's
agenda.
C
First
of
all,
we
will
introduce
the
background
of
this
of
our
proposal
and
after
that
we
will
illustrate
the
motivation
of
this
proposal
and
up
then
we
will
illustrate
our
design.
We
have
two
design
for
the
feature.
The
one
is
entry,
implementation
and
the
other
one
is
out
of
three
and
we
will.
We
will
show
the
communicators
2
approaches
and
we
can
discuss
it
after
this
illustration
and
ok.
So,
let's
begin
first,
we
need
to
introduce
some
basic
knowledges
about
deep
learning,
because
our
motivation
is
related
to
deep
learning.
C
So
sorry,
first
of
all,
let's
have
a
look
at
our
company.
Sitecloud
is:
is
a
company
focusing
on
communities
and
deep
learning
to
build
personalized
cloud
services,
and
here
is
our
github
organization.
You
can
check
out
here
and
we
are
one
of
the
top
contributors
in
harvard
community
and
many
other
con
projects,
for
example
the
cube
law
as
something
else
and
okay,
it's
it's
about
the
company
I'm
working
at
and
after
that
we
will
introduce
machine
learning
physics
for
a
basic
machine
learning
workflow.
We
have
three
processes
here.
C
First,
we
need
to
change
the
model.
If
you
want,
if
you,
if
you
know
about
deep
learning,
you
must
heard
about
model
training
or
something
else.
So,
first,
we
need
to
train
the
model
locally
and
after
that
we
need
to
distribute
the
model
and
after
that,
finally,
we
will
serve
the
model
in
production.
C
C
So
we
think
that
sap
is
not
extensible.
We
want
to
distribute
the
model
with
oci
based
registry,
for
example,
hubble.
So
we
have
such
a
client.
We
call
it
ormb
and
we
can
use
this
client
this
binary
to
save
the
model
and
push
the
model
to
the
hardware
registry.
After
that
we
can
just
pour
it
in
production
server
and
export
it.
C
After
that,
we
can
just
use
it
to
serve
it
to
serve
it
online,
and
here
is
our
design
of
this
binary
or
we
can
call
it
a
client
we
have
define,
we
define
our
own
model,
config,
similar
to
the
oci
image
conflict.
Here
we
need
to
define
it,
and
here
is
it's
here-
is
the
model
specification
you
can
see
that
it
is
similar
to
the
model.
Config,
sorry
similar
to
the
image
config
in
oci
specification.
C
B
C
So
this
is
our
our
own
open
source
product
and
we
will
we
are
using
it
to
push
and
promote
from
or
to
harbor
registry,
and
we
found
something
not
easy
to
implement
in
harbor,
for
example,
when,
when
users
call
this
api,
this
hardware
api
to
guides
to
get
the
model
artifact
details
we
can
find.
We
can
get
this
response
and
you
can
see
we
we
can.
C
The
media
type
is
our
own
defined
media
type,
vmd,
dot,
tekla,
dot,
model,
dot,
config,
and
it
is
the
media
type
of
the
config
layer
and
we
can
get
the
type
model
and
this
type
is
defined.
It's
possessed
by
harvard
default
processor
and
when
users
get
him
charged
instead,
he
can.
He
can
get
more
information
here,
for
example,
besides
the
media
type
and
the
text
and
something
else
he
can
also
get
the
extra
attributes
and
it
is
possessed
by
helm,
chart
processor
in
hardware
core
and
the
information
here
is
stored
in
this
config
layer.
C
So
we
just
copy
the
config
layer
to
the
extra
attributes
and
we
add
this
extra
attributes
in
this
api
response
and
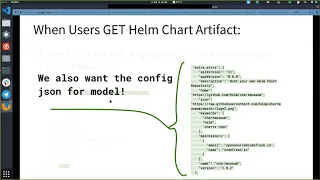
we
also
want
the
config
json
for
model.
So
we
want
to
save
the
save
the
model
config
in
the
api
response
too,
not
just
for
help
chart
or
cab
or
some
standard
artifact
types,
but
we
do
not
want
to
keep
the
artifact
specific
logic
in
hardcore,
since
it
is
not
necessary
because,
as
you
know,
our
own
model
specification
is
not
mature
and
we
are
still
isolated.
C
C
Now,
however,
using
the
processor
interface
to
process
the
artifact
types,
we
now
have
four
processors.
Here
we
have
a
helm,
charge,
processor
and
the
oci
image
processor
and
the
c8b
processor,
and
we
have
one
default
processor
for
any
other
artifact
types
and
we
have
two
base
processors
which
will
be
embedded
into
this
implementations.
C
C
Besides
this,
we
also
have
some
artifact
types,
which
is
private
and
we
do
not.
We
will
not
open
source
it
in
the
future.
So
if
we
keep
the
current
design,
we
may
have
several
folks
in
the
community.
For
example,
if
we
have
some
internal
actually
artifact
types
inside
out,
we
will
have
to
fork
a
harbor
and
use
that
fork
to
serve
our
internal
artifacts
and
it's
similar
to
tencent
or
it
netted
or
some
other
companies.
C
So
as
we
will,
we
will
have
more
and
more
artifact
types
in
the
future
and
we
do
not
to
make
have
a
a
fragmented
platform.
So
we
do
not
like
this
approach,
and
this
is
the
motivation
of
our
proposal
and
after
that
we
will
discuss
about
our
design
for
this.
For
for
the
problems
to
address
to
address
these
problems,
we
have
two
design
choices.
The
first
one
is
in.
We
call
it
entry
implementation.
C
So
in
this
approach
we
will
just
implement
a
new
processor.
We
call
it
common
processor.
So
you
can.
This
is
the
workflow
to
upload
a
new
upload,
a
new
user-defined
artifact
to
hover
core?
First,
we
will
we
will
post
the
blobs
to
the
oci
based
registry.
After
that
we
will
ensure
that
registry
exists,
and
after
that
we
will
put
the
manifest
to
the
reddit
to
the
registry,
and
you
can
see
we
will.
C
C
C
We
have
another
object,
we
call
it
user
defined
artifact
or
we
can
have
a
similar
name,
but
we
just
store
some
the
artifact
details
here
and
in
this
field
we
just
store
the
icon
of
our
own
type
and
we
also
store
the
kind
of
the
artifact
and
we
will
store
the
artifact
hype
and
additions
here.
The
most
important
section
is
additions
in
this
field.
C
In
addition,
we
will
store.
We
will
store
how
many
additions
should
be
used
in
the
in
our
customized
artifacts
type,
and
you
can
in
this
example.
We
have
three
additions
here,
the
first
one
is
readme
and
it
will
be
stored
in
a
separate
content
layer
and
we
will
store
the
blog
reference
in
the
addition,
slides-
and
you
can
see-
is
here
and
the
blob
points
to
the
content
layer
and
its
digest
is
record
here
and
after
that
we
have
a
table
content
layer
here
and
you
can
get
the
content.
C
You
can
get
the
table
content
there
from
this
blog
there
and
finally,
we
will
have
a
general
layer
here.
General
layer
means
that
we
do
not
know
the
format
or
the
or
the
context
in
the
in
the
layer,
but
it
is
not
the
real
content
there.
It
is.
It
is,
I
addition.
So
it
is.
We
call
it
general
edition
for
readme.
C
So
so,
when
we
have
such
a
schema,
we
can
implement
the
processor
like
this.
We
call
it
common
processor
or
general
processor
in
in
the
get
artifact
type
function.
We
will
first
pour
the
config
from
the
artifact
and
it
is
the
config
layer
and
we
can
get
the
artifact
type
from
the
config
layer.
We
can
get
the
conclair.harvard.userdefinedartifact.
artifact
type,
then
we
can
get
the
get
this
this
value
or
mb,
or
we
can
modify
it
to
model
or
something
else.
C
C
We
can
use
it,
we
can
iterate
the
additions
to
get
the
names
for
every
edition
and
we
can
use
the
name
slices
as
the
return
values
of
this
function
core
and
in
abstract
metadata
we
can
use.
We
also
use
similar
logic.
We
pour
the
config
layer
and
we
set
the
metadata
to
the
config
layer,
json
object,
and
after
that
we
can
get
the
config
layer
in
the
hover
api
core.
So
it
is
our
motivation,
in
illustrated
in
the
previous
section.
B
C
And
the
the
last
one
is
abstract
addition,
so
we
will
pull
the
config
layer
first
and
we
will
get
the
addition
digest
from
the
config
layer.
And
after
that
we
will
pour
the
con
addition
blob
from
using
the
addition
digest
and
after
that
we
will
use
the
addition
layer
as
content
and
we
will
parse
the
type
from
the
condition
layer,
config
layer,
dot,
hover
dot
user,
defined,
artifact,
dot
additions
and
additions
to
get
the
type
from
the
config.
C
We
call
it
entry
approach
in
inquiry,
implementation
and
besides
this,
we
have
another
implementation
here
and
we
call
it
autophagy
implementation.
And
in
this
approach
we
propose
a
new
processor,
we
call
it
http,
processor
and
the
http
processor
will
communicate
with
the
processor
extender
via
rest
for
api,
and
it
is
similar
to
the
kubernetes
scheduler
extender.
If
you
know
it,
and
the
the
logic
is
a
little
different
from
the
previous
way.
C
We
will
use
the
http
processor
to
abstract
metadata
and
the
http
processor
will
post
some
restful
apis
to
the
processor
extender
to
get
the
metadata,
and
it
is
the
main
difference
between
these
two
approaches,
and
so
in
this
way
we
will
have
some
changes
to
harvard.
We
need
a,
we
need,
a
new
implementation,
http
processor
and
we
need
a
configuration
yaml
file,
processor.yaml
and
in
http
processor.
C
So
you
can.
We
can
have
a
look
at
the
example
how
to
implement
abstract
metadata.
So
when,
when
the
user
calls
http
processor
dot
abstract
metadata,
we
actually
send
a
restful
api
to
the
processor
extender.
We
will.
We
will
have
manifests
in
the
request
body
and
we
will
have
the
artifact
in
the
request
body.
Besides
this,
we
also
need
some
information
about
the
registry
to
allow
the
processor
extender
to
pour
the
manifest
from
the
docker
register.
C
The
first
one
is
to
implement
the
http
processor
and
the
second
one
is
to
implement
alls
in
atps
in
http
processor,
because
we
need
to
let
atp
processor
extender
to
poor,
manifest
from
hardware
registry
directly
and
the
last
one
is
to
write
a
tree.
It's
regis,
it's
about
registration
using
processors.yaml
and
the
development
process
is
like
this.
C
We
first
need
to
implement
the
http
processor
and
the
extender
without
us
and
after
that
we
need
to
implement
the
registration
and
the
last
one
is
to
or
is
about
us,
and
this
approach
is
about
the
out
of
three
approach
and
you
can
get
the
details
in
our
proposal
and
that's
all.
We
already
illustrated
our
motivation
for
this
feature
and
our
two
design
choices
here
and
we
are
open
to
the
community
and
welcome
any
suggestions
here
and
we
can
discuss
about
it.
D
The
next
yeah
this
one
yeah,
so
I
think
it
you
know
the
the
way
I
envisioned
this
is
that
when
we
look
at
this
from
a
plug-in
architecture,
is
that
someone
submits
the
schema
for
this
user
defined
artifacts
that
contains
all
these
data
would
assume
the
icon
will
be
part
of
the
schema.
Think
of
this,
as
almost
like
a
zip
file
that
contains
an
icon
and
and
this
file
that
contains
the
schema
so
that
hardware
doesn't
have
to
go
pull
the
icon
from
a
url.
C
D
You
know:
harbor
has
a
lot
of
set
of
capabilities
around
policy
like,
for
example,
codas
retention
policies.
All
of
those
obviously
work
for
pretty
much
any
oci
compliant
artifact,
but
not
everything,
for
example,
scanning
doesn't
work
for
just
about
any
artifact,
so
it'd
be
great
to
know
in
this
schema.
If
scanning
can
be
enabled
on
this
set
of
artifacts,
because
you
know
we
need
to
know
you
know
how
do
we
enable
you
know
static
analysis,
whether
that's
by
trivia,
clear
or
something
else
on
the
back
engine.
C
Okay,
for
your
first
question
for
your
first
selection,
I
will
have
a
detailed
review
with
our
colleagues
to
give
you
a
reply
and,
as
far
as
I
know,
the
icon
url
here
is
not
will
not
be
used
directly
by
harper
core
services.
It
will
be
used
by
harvard
ui
to
pour
the
icon
directly
from
from
the
browser.
So
I
think
we
do
not
need
to
embed
it
into
the
into
the
artifact.
As
you
know,
the
some
other
standard
artifact
types
like
crab
or
helm
charts.
C
D
E
D
So
essential
will
allow
basically
any
artifact
to
wrap
anything
into
an
oci
list,
and
this
config
schema
will
include
details.
You
know
I
want
you
to
think
about
what
it
would
mean
like
to.
Basically,
if
you
have
lots
of
these
artifacts,
what
do
you
mean
for
our
ui
to
go
load
that
icon
from
a
uri
right,
whether
it's
local
or
otherwise,
yeah.
E
As
for
the
icon,
I
think
we
can
have
a
lot
of
time
to
discuss.
I
think
that
we
have
to
make
decisions,
or
the
main
main
decision
we
need
to
make
in
today's
discussion
is
which
approach
we
should
choose,
whether
if
the
entry
us
configure
json
based
processor
or
out
of
three
processors
yeah
and
that's
the
decision,
we
need
to
discuss.
D
E
C
Yeah,
so
I
think
we
do
not
need
to
dive
into
the
details
of
the
schema
here,
because
it
is
just
a
draft
and
we
do
not
make
a
final
decision,
so
we
can
just.
We
want
the
community
to
give
us
some
input
to
choose
one
design
choices.
For
example,
we
want
to
use
entry,
implementation
or
auto
tree
implementation,
but
as
for
the
details
of
the
schema,
I
think
we
can
have
a
another
meeting
or
something
else
to
decide
it
yeah.
F
Yeah,
actually
one
one
question
I
I
want
to
ask
actually,
in
your
background
you
mentioned
there
is
some
user
different
artifact
tabs
that
you
don't
want
to
open
to
be
open
source,
yeah,
yeah
right
sure,
but
that's
if
yeah,
if
it
is,
you
know,
if
for
the
entry
you
need
to,
you
know,
expose
your
information
metadata
information
right,
expose
the
information
in
the
computer
configure
gsm
file.
That
means
your.
E
C
F
I
think
the
two
main
differences,
maybe
is
why
I
need
to
you
know:
we
need
to
defend
a
spike
right
every
one
if
they
want
to
harbor
support
to
in
a
process
their
data
they
need.
They
need
to
follow
that
spec,
but
for
the
out
of
the
trade
we
don't
have
a.
We
don't
need
to
develop
spike
right,
yeah
and
follow
this,
but
follow
the
api
to
introduce
the
capability
into
harbor.
C
Yeah
yeah,
you
can,
can
you
see
my
screen?
Actually,
we
have
some
pros
and
cons
for
these
two
design
choices
here
and
as
for
entry
implementation,
it
is
easy
to
mention
and
no
extra
effort
to
support
new
types,
because
we
just
mentioned
one
common
processor
here,
and
it
is
also
more
secure
than
the
other
approach,
because
we
do
not
need
to
let
the
extender
to
pour
the
port
manifest
from
the
hyper
core.
C
E
Valid
here,
because
if
they
want
to
show
something
on
hardware,
either
way,
they
need
to
do
some
work.
If
they
choose
intro,
they
need
to,
you
know,
write
their
config.json
following
the
schema.
If
they
choose
other
trees,
they
will
write
a
processor.
They
will
write
a
service
to
support
that
so
either
way.
There's
some
work.
F
C
F
E
It
appeared
to
be
more
extensible,
but
not
exactly.
I,
I
didn't
follow
the
whole
sequence
of
flow
for
the
olive
tree,
but
essentially
hubble
still
need
to
get
some
blob
and
let
the
api
to
pull
some
blob.
So
how
does
the
http
processor
know
the
digest
of
this
blob?
There
is
still
still
some
contract
here
right.
D
C
A
And
I
think
the
entry
also
can
be
reviewed
by
other
artifact
authors
right.
So
if
we,
if
we
set
the
standard
for
what
the
config
should
look
like,
then
we
can
push
this
out
to
every
vendor
that
wants
to
be
imposed
on
hardware.
It
seems
like
df
is
lower
right.
It's
less
friction
to
get
something
to
to
be
able
to
push
to
harvard,
because
just
writing
something
in
accordance
to
a
config
spec
is
is
much
easier
than
writing
the
actual
http
processor
and
whatnot
yeah
yeah.
I
didn't
really
understand
it.
F
F
C
G
A
E
F
E
F
F
Another
response,
a
data
structure:
there
is
another
disadvantage
there.
If
some,
you
know,
user
defense,
artifact
has
been
defended
before
our
specification
is
published.
They
can
also
click
cannot
just
you
know,
still
be
rendered,
because
if
they
want
to
you
know
they
need
to
change
their
structure
to
follow
this
new
spec.
That's
true.
E
F
E
E
F
E
F
E
F
D
E
C
D
B
F
We
need
to
treat
this
diploma
as
a
whole
deployment,
not
as
a
separator
right,
because
for
the
user
keys
they
provide
the
http
pro
process
as
the
new
you
know,
as
a
new
component
service
to
their
platform.
However,
harbor,
together
with
this
new
processor
as
a
whole,
you
know
artifact
platform
not
to
harbor
itself,
so
this
should
protect
that.
G
F
F
D
E
F
C
A
F
F
E
E
A
E
D
C
E
E
But
if
you
put
out
of
tree
inside
harbor
that's
more
problematic
because
we
need
to
handle
it
in
installation.
So
so
again
I
prefer
entry,
at
least
for
this
case
or
for
now
yeah.
I
understand
the
other.
Three
is
more
expense
has
better
extensibility,
but
you
don't
have
a
lot
of
artifacts.
We
need
to
support
now.
Maybe.
F
A
G
A
You
know
this
is
the
first
step
before
we
look
at
details
around
what
the
theatrical
skills
look
like
the
newspaper
scout
tree.
I
think
so.
I
will
share
this
on
the
community
meeting
notes
as
well
as
the
community
pr
everyone
can
head
over
there
and
ask
some
comments.
Ask
questions
we'll
probably
have
another
meeting
you
know
outside
of
this
community
meeting
to
discuss
this
and
if
anyone's
interested,
please
please
ping
me.