►
Description
RustConf 2016 - A Modern Editor Built in Rust by Raph Levien
This talk will present XIeditor, a new project to build a high-performance text editor primarily in Rust. In addition to a deep dive into technical details, the talk will touch on aspects of building polished GUI apps and running a community-focused open source project.
A
Actually,
the
the
first
thing
is:
how
do
you
pronounce
sigh,
that's
kind
of
what
I've
settled
on
everybody
has
a
different
idea,
but
that's
that's
excellent.
So,
yes,
I'm
real
Avena
I'm
at
Google.
This
is
actually
my
20%
project.
This
is
not
an
official
Google
product
and
to
the
extent
that
I
express
opinions
it.
Those
are
my
own
and
not
of
Google.
A
So
so
let
me
show
you
a
little
bit
like
you
know,
just
jump
in
and
do
a
little
bit
of
a
demonstration.
So
one
of
the
things
that
I
do
a
lot
is
that
I
open
a
lot
of
extremely
large
files,
so
this
file
is
380
megabytes
and
it
loaded
pretty
fast.
I
actually
want
to
get
that
even
faster
by
loading
asynchronously.
But
that's
that's
not
the
way
it
works
right
now.
A
It's
a
synchronous
load
so
to
talk
about,
maybe
a
second,
maybe
a
little
bit
more
and
then
as
I
scroll
through
that
you
know,
I'm
getting
like
complete
60
frames,
a
second
just
butter,
smooth
scrolling.
That's
the
goal
of
this
editor
is
extreme
performance.
So,
let's
talk
a
little
bit
about.
You
know
what
it.
What
is
the
shape
of
this
project
overall,
its
its
host
on
github?
It's
under
an
Apache
2
license.
It's
completely.
A
You
know
it's
not
just
open-source,
but
like
really
kind
of
community
based
open-source
project,
I
started
it
a
little
bit
more
than
six
months
ago
and
took
it
public.
You
know
it's
kind
of
doing
it.
Just
on
my
own,
for
a
couple
months
took
it
public
in
late
April,
the
code
base
is
in
a
couple
of
different
pieces,
there's
almost
10,000
lines
of
rust
code,
which
is
the
core
and
then
a
bunch
of
libraries
and
the
libraries
potentially
have
interest.
A
You
know
outside
this
project
and
especially
there's
this
rope
library,
which
is
the
string
representation,
I'll
talk
about
a
lot
more
detail
later
and
that's
almost
half
of
the
it's
all
in
stable,
rust,
completely
safe,
zero
uses
of
and
safe
in
the
code
and
I
thought.
The
earlier
talk
was
really
interesting
about
the
use
of
traits.
A
The
ratio
traits
is
actually
pretty
high
compared
with
some
of
the
other
I
do
use
traits
extensively
and
I'll
talk
about
that
in
a
little
bit
more
detail,
there's
also
twelve
hundred
lines
of
Swift
code
in
this
project,
which
is
the
cocoa
front
end.
It's
a
Mac,
it's
a
mac
app,
although
the
intent
is
I,
want
to
see
more
front
ends.
I
want
to
see
lots
of
different
platforms
that
this
runs
on.
So
it's
my
20%
project
open
to
the
community.
A
So
the
goal
of
this
editor
is
I
kind
of
open
up
this
performance,
and
how
am
I
achieving
performance?
There's
a
bunch
of
different
ways.
You
do
that
so
that
the
most
obvious
is
use
a
fast
language,
rust
and
then
you
know
I
wanted
to
do
it
in
a
more
modern.
You
know
I
really
want
to
use
kind
of
the
best
known
techniques
of
doing
all
of
these
text.
Editing
primitives-
and
you
know
if
you
look
back
20
30
years
ago,
when
people
were
kind
of
building
these
tools.
A
Multi-Core
parallelism
doesn't
really
exist.
You
don't
really
try
and
use
that
to
solve
problems.
So
I
haven't
done
a
lot
yet,
but
I
want
the
architecture
to
support,
do
as
much
work
in
parallel
as
possible,
where,
where
I
think
things
get
even
more
interesting,
is
to
use
the
most
advanced
data
structures
and
the
most
advanced
algorithms
for
manipulating
text.
So
they
the
data
structure,
is
ropes
and
as
far
as
algorithms,
the
most
important
thing
to
do
is
do
as
little
work
as
possible.
A
So
when
you
do
an
edit,
you
do
an
incremental
computation
of
only
updating,
just
a
few
tiny
things
around
that
it
get
that
on
the
screen
and
don't
like
recompute
things,
but
I
think
one
of
the
things
that
makes
AI
most
unlike
previous
editor
projects
is
using
asynchrony
as
a
core
defining
principle.
There
are
projects,
certainly
it's
inspired
by
any
ovum
which
which
tries
to
do
that,
but
I
think
I've
taken
it
a
little
bit
farther.
So
the
goal
is
to
never
block
Onslow
operations.
A
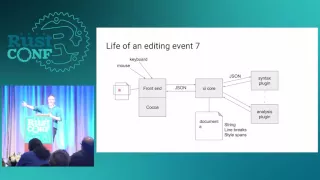
So
this
is
a
little
bit
of
a
picture
of
the
way
that
the
editor
is
designed.
It's
in
separate
it's
in
lots
of
different
modules.
So
it's
really
like
a
micro-services
architecture,
and
so
this
core
at
the
center
of
it,
is
a
small
server
and
then
there's
a
front
end,
which
is
bound
to
your
GUI
platform
but
the
core.
It
doesn't
it's
just
sitting
there
you
know
responding
to
requests
and
then
the
core
owns
the
state
of
truth
of
the
document.
A
So
if
you
open
a
very
large
file,
that's
in
memory
in
the
core
and
the
front-end
is
only
looking
at
a
tiny
window
only
what's
on
the
screen,
so
the
core
does.
The
front-end
doesn't
have
to
deal
with
like
scaling
to
very
large
documents
and
then
another
part
of
this
architecture
is
that
a
lot
of
the
things
that
that
you
want
to
do
the
plugins?
Those
are
in
separate
processes
and
again
kind
of
wired,
together
with
this
micro-services
tile
style
architecture.
So
I'm
going
to
walk
through
what
happens
when
you
press
a
what?
A
How
does
that
actually
end
up
in
a
in
an
edit
on
the
screen
and
kind
of?
How
does
this
flow
through
this
architecture?
So
you
start
with
a
cocoa
event,
insert
text
a,
and
that
happens
obviously
on
the
front
end
and
that
turns
into
a
JSON.
So
these
this
is
just
pipes.
This
is
just
the
the
core
is
just
listening
on
standard
in,
and
you
see
this
JSON
RPC
message:
I'm
showing
kind
of
a
simplified
version
of
the
JSON
RPC,
but
it's
it's
still
pretty
simple.
A
So
it's
an
edit
request
and
insert
and
the
string
that
you
want
to
insert
is
a
so
that
immediately
is
reflected
in
the
document
as
a
change
to
the
document,
which
is
a
change
in
this
case.
Just
to
the
string
of
the
document,
and
the
next
thing
that
happens
is
that
the
core
now
dispatches-
and
this
happens
kind
of
this
part
in
parallel-
it's
sending
out
a
of
different
messages
to
different
other
things
that
are
subscribing
to
those
changes
to
that
document.
A
So
it
sends
first
of
all,
an
update
to
the
view
and
said
display
sends
to
the
front
end
display
these
lines,
which
are
representing
the
view
of
what's
on
the
screen.
It's
also
sending
to
the
plugin
the
syntax
plug-in
very
fine-grained
information.
It
says
this
this
edit
change.
This
edit
happened
to
the
document
and
you
know
where
and
what
changed
and
why?
Because
sometimes
the
plug-in
will
care
about
that.
A
So
the
view
is
now
updated
and
then
the
syntax
plug-in
is
a
little
bit
more
time
to
think
about
what
color
should
that
really
be,
and
it
sends
a
JSON
message
back
to
the
core
that
has
these
syntax
highlighting
expands.
So
the
core
then
basically
updates
its
state,
which
contains
both
the
string
and
these
style
spans
and
also
dispatches
to
the
front
end
another
JSON
RPC
that
says:
okay,
the
screen.
What's
the
view
that's
on
the
screen
has
changed
a
little
bit
and
then
the
front
end
displays
that
so
that's
kind
of
step
by
step.
A
What
happens
in
this
in
this
architecture?
So,
a
little
bit
a
little
bit
about
the
front
end
I
wanted
to
kind
of
explore
the
most
modern
ways
of
writing.
You
know
all
these
kind
of
apps,
and
so
the
friend
end
is
written
in
Swift
I
wanted.
Even
though
a
goal
is
for
this
to
work
on
lots
of
different
platforms,
I
did
not
want
to
use
a
cross-platform,
GUI
library,
because
I
feel
there's
always
some
way
in
which
it
does
not
really
look
like
a
modern
app.
A
You
know
like
a
native
app
and
it
doesn't
really
feel
like
a
native
app.
So
it's
like
for
each
of
these
platforms.
I'm
writing
a
fully
native
front
end
and
the
the
front
end
contains
all
of
the
logic
that
is
specific
to
that
particular
platform.
To
that
particular
GUI
and
another
you
know
way
that
I'm
achieving
performance
is
that
it's
really
only
holding
a
tiny
amount
of
state.
A
A
So
when
you
do
this
asynchronous
stuff,
you
know
just
saying
Oh
things
can
be
happening
here
and
they
can
be
happening
there
at
the
same
time
causes
problems
that
if
you
have,
you
know
an
edit
that
is
being
proposed
by
your
plugin,
either
to
do
syntax,
coloring
or
things
like
inserting
indentation
if
you're
typing.
At
the
same
time,
you
get
two
edits
that
really
conflict
with
each
other
or
potentially
conflict
with
each
other
and
there's
a
lot
of
literature
on.
How
do
you
resolve
that?
A
How
do
you
resolve
really
concurrent
edits
that
are
happening
from
different
sources
and
usually
people
think
of
operational
transformation
in
the
context
of
a
networked
collaborative
editor?
And
you
know:
that's
that's
a
direction
this
could
go
because
the
engine
for
computing,
the
operational
transformation,
is
pretty
powerful.
It's
pretty
general,
but
I'm,
really
focusing
on
just
solve
the
problems
of
concurrent
edits
that
are
happening
because
of
a
keyboard,
a
plug-in.
You
know
all
on
the
same
machine.
So
so
you
definitely
you
can
get
these.
You
can
get
these
cases
where
things
are
happening.
Concurrently.
A
What
you
do
you
take
that
edit
and
you
transform
it?
You
say
in
order
for
that
edit
to
make
sense
in
the
new
state
of
the
document.
I
have
to
transform
it
slightly.
You
know
they
inserted
a
character
here,
so
I'm
just
going
to
take
this
and
adjust
it
so
that
it
now
fits
in
the
new
state
of
the
document.
So
I'm
going
to
write
more
about
this
you'll
hear
more
about
it.
A
A
A
rope
is
basically
a
balanced
tree
where
each
of
the
leaves
is
holding
some
piece
of
the
string,
so
the
size
of
the
leaves
is
bounded
and
the
branching
is
bounded,
which
means
that
pretty
much
any
editing
operation
that
you
want
to
do
is
going
to
be
log
in
in
the
worst
case,
in
the
size
of
the
buffer.
If
you
look
at
something
like
a
gapped
buffer,
if
you're
editing
with
a
lot
of
locality,
you'll
have
you
know
a
1,
but
if
you
do
something
that
kind
of
you
know
has
to
move
that
gap.
A
That
can
be
a
n.
So
you
have
a
thing
where
your
average
case
is
maybe
pretty
good,
but
your
worst
case
can
get
really
bad.
One
of
the
advantages
of
rope
is
your
worst
case
is
always
is
always
log
n.
So
in
this
case,
you
can
see
the
you
know
like
in
the
nodes,
I'm
storing
the
size,
I'm
storing
the
number
of
bytes
of
string
of
the
children.
A
So
the
implementation
of
this
in
rest
I
think
here's
an
area
where
the
goals
of
Zhai
and
the
capabilities
of
rest
as
a
language
really
mesh
beautifully
that
the
tree
there's
a
generic
tree
implementation
and
that's
parameterised
through
trait.
So
there's
a
leaf
trait
and
a
node
info
trait
and
you
can
plug
those
in
in
right
now.
I
have
three
completely
different:
specializations
for
different
ways
in
which
I'm
representing
sequences
and
I'm,
representing
computations
that
I
want
to
do
on
sequences
and
I.
Think
this
is
going
to
expand.
A
I,
think
I'm,
going
to
use
it
to
store,
like
incremental
syntax,
highlighting
state
so
I'm,
storing
the
stray
I'm,
storing
the
line,
breaks
and
I'm
storing
the
rich
text
annotations
in
three
different
specializations
of
this
tree.
So
the
theory
behind
it
is
you
know
it.
You
really
can
represent
any
mono.
Humble
morphism
I'll
talk
about
that
a
little
bit
more.
In
case
people
don't
know
what
that
is
another
way
in
which,
like
the
capabilities
of
rust,
fit
the
needs
really
closely.
Is
that
the
the
API
gives
you
this
immutable
data
structure?
A
So
you
have
this
tree
and,
yes,
you
have
to
build
up
a
new
tree,
but
you
only
have
to
allocate
a
log
n
nodes
and
that's
good,
but
in
rust
you
can
do
even
better
if
you
just
want
to
mutate
one
of
these
ropes-
and
you
happen
to
be
the
only
one
holding
a
reference
to
that.
Then
you
can
there's
this
get
mute
method
of
this
arc.
Reference
counted
container
that
lets
you
just
get
that
reference
and
do
that
mutation
and
the
type
system
guarantees
that
everybody
else
is
going
to
see
an
immutable
copy.
A
So
if,
if
somebody
else
was
holding
a
reference
to
that
rope,
it
would
make
the
copy-
and
you
would
not
be
changing
the
state
out
from
somebody.
So
if
you
were
to
implement
this
in
a
language
like
C++
you'd
get
the
performance,
but
we're
doing
a
lot
of
kind
of
aggressive
things
here,
we're
doing
a
lot
of
things
that,
in
you
know,
if
I
were
reviewing
C++
code
I'd
see
this
is
too
dangerous.
A
A
So
what
is
a
mono?
A
homomorphism,
a
mono?
Eight
is
a
binary
operator,
really
that
has
the
Associated
property
and
the
identity
problem,
that's
pretty
abstract.
So
so
what
are
some
good
examples
of
monoids?
A
string
is
a
classic
monoid,
and
so
the
binary
operation
is
just
string.
Concatenation
and
your
identity
is
the
empty
string.
Another
example
is
integers
and
then
your
your
binary
operation
is
addition
and
your
identity
operator.
Your
identity
element
is
0,
so
it's
pretty
obvious
that
these
things,
you
know
both
hold
the
both
respect,
the
mono
add
properties.
A
So
then,
what
is
the
homomorphism?
Well,
a
homomorphism
is
a
function
from
one
monoid
to
another.
So
a
really
good
example
is:
let's
go
from
strings
to
integers,
where
that
function
is
the
length
of
the
string
so
they're,
both
glenoid
and
the
this
function.
This
string
length
function
is
preserving
the
the
the
binary
operator
in
a
way
that,
like,
if
you,
if
you
do
a
computation
on
one
side,
that's
accurately
reflected
on
the
other
side.
A
So
when
you
go
back
to
the
to
this
picture
of
this
tree,
then
the
leaves
are
storing
the
m
monoid
and
the
nodes
are
storing
the
end.
So
you
know
you're
not
replicating
those
leaves,
but
at
every
point
in
the
tree,
you
know
what
that
length
is-
and
this
is
generalized
to
you
know
anything
that
you
want
to
compute.
That
fits
within
the
monoid
homomorphism
framework
and
there's
a
few
things
like
right
now.
The
main
focus
is
on
counting
new
lines,
and
so
that
gives
you
you
know.
A
If
you're
storing
both
the
string
length
and
the
new
line
count,
then
you
can
do
a
traversal
of
that
tree.
That's
still,
you
know
log
n.
That
will
give
you
a
correspondents
like.
Where
am
I?
What
is
the
offset
within
this
file
for
a
given
line
and
vice
versa
and
there's
there's
actually
a
lot
of
other
interesting
things
you
can
do
in
this
framework
and
won't
go
into
lots
of
detail
now,
but
I
think
this
is
going
to
power.
A
Another
algorithm
that
is
really
important
to
get
right,
really
important
to
get
fast
in
an
editor
is
a
word
wrap
and
one
of
the
things
that
I
have
done
in
Zhai
is
very
aggressive.
Making
this
incremental
so
we'll
go
back
to
the
we'll
go
back
to
the
to
the
file
here
and
I'll.
Do
word
wrap
first
of
all,
as
a
bulk
operation
and
that'll
take
a
little
bit
of
time,
but
not
too
bad,
and
now
that
I'm
here
you
know
as
I
type.
A
A
It
says
that
I've
touched
140
bytes
when
I
did
that
and
it
took
0.01
milliseconds,
which
is
pretty
fast.
So
how
do
I
do
that?
I
I
start
the
incremental
word
wrap
process
at
the
line
before
the
given
edit,
because
you
know
you
can
like
you
it's
possible
for
it
to
affect
the
line
before
the
one
where
the
cursor,
but
it
can't
affect
anything
earlier
than
that
and
it
keeps
going
until
you're
able
to
sort
of
resynchronize
with
the
previous
state
that
you
had
so
it
actually.
A
You
know
a
lot
of
times
it
converges
pretty
quickly.
So
the
result
of
line
of
wrapping
word
wrapping
is
stored
in
a
line
break
data
structure,
which
is
just
another
specialization
of
the
rope
of
the
underlying
rope.
So
this
is
just
storing
line
breaks
and
the
as
I
said
that
initial
word
wrap.
It's
currently
synchronous.
You
have
to
do
it
on
the
hole
buffer
before
it
responds
again,
but
I'm.
You
know,
I
want
to
make
that
asynchronous
about
really
soon
in
the
design.
A
I
think
supports
that
it's
just
a
little
bit
more
tricky
coding,
so
many
editors
do
plugins
by
kind
of
exposing
bindings
to
a
scripting
language
in
the
same
process
as
the
editor.
So
you
basically
get
these
data
structures
that
get
exposed
of
buffer
and
selection
and
cursor
and
so
and
so
forth
and
ins
I
I've
decided
to
do
it
in
a
pretty
radically
different
way,
and
so
this
is
really
microservices
and
it's
really
the
UNIX
philosophy.
It's
real.
A
You
know
taking
modules
and
wiring
them
together,
so
that
each
module
gets
to
focus
on
doing
one
thing:
for
example,
syntax
highlighting
so
these
these
plugins
communicate
over
a
pipe
with
JSON,
RPC
and
there's
a
buffer
protocol.
Where
you
know
the
the
plug-in
is
maintaining
a
window
into
the
into
the
file.
A
So
if
the
file
is
really
small,
it's
just
storing
a
copy,
but
if
the
file
is
really
big
in
my
store
like
a
one
megabyte
window
and
then
if
you
have
to
do
a
lot
of
processing
on
that,
then
you'll
do
our
pcs
back
and
forth
to
get
access
to
that.
So
this
is
working
today.
I
can
actually
demo
this
again
I'll
open
it
open
one
of
the
files.
Oops
didn't
mean
to
do
that
this
one
and
then
again
all
I'll
make
that
a
little
bit
bigger.
A
Why
is
this
not
oh
there?
It
is
make
it
a
little
bit
bigger,
so
you
can
see
it
and
then
I'll
do
the
syntax
highlighting
and
then
you
know,
as
I
type,
you
don't
see,
see
hi
said
I
wouldn't
do
live
coding,
and
here
we
go.
I
should
probably
give
that
a
name
with
it.
If
we
had
a
syntax
analysis,
plug-in
and
I
would
have
given
me
an
error
message,
therapist
not
yet
so
this
is
working
and
you
know
it's
it's
incremental
and
you
know
it's
it's
using
this
operational
transformation.
A
So
if
the
syntax
highlighting
we're
really
slow
and
I
continue
typing,
then
it
would
all
be
valid
and
then
it
would
eventually
catch
up
like
the
the
model
of
CR.
Dt
is
really
eventual
consistency.
So
the
idea
is,
you
know
when
you
stop
typing.
Eventually
the
thing
will
converge
to
the
to
the
true
answer.
So
this
is
inspired.
This
idea
that
you
can
have
things
talking
to
each
other
is
inspired.
A
There's
a
few
efforts
out
there,
including
the
Microsoft
language
server,
the
one
that's
used
in
typescript
and
I'm
I'm,
actually
hoping
to
support
that
protocol
directly,
as
well
as
the
you
know,
kind
of
more
specialized
protocol
that
I've
built
just
for
communication
with
things
like
syntax,
highlighting
and
indentation,
and
so
on.
So
the
syntax,
highlighting
module
that
you
just
saw
there.
This
is
based
on
Tristan,
Humes,
syntax
library.
A
A
The
way
it's
implemented
internally
is
its
using
the
onik
bindings
to
the
owner,
guruma
library,
which
is
the
reg
X
library
from
Ruby
I,
have
implemented
a
rust
based
wrapper
around
the
burnt
sushi
reg
X
crate,
because
you
do
need
to
support
things
like
back
references
and
contacts
and
stuff
like
that.
It's
not
quite
ready
yet,
but
it's
an
interesting
possibility
to
take
this
whole
thing
to
rust.
A
Only
so
there's
no
C
bindings
in
there
at
all,
and
hopefully
like
better
performance,
because
the
burnt
sushi
rig
acts,
great
uses,
really
kind
of
intelligent
finite
state
machine
techniques
to
get
even
faster
records
handling.
So
it's
pretty
fast.
It's
not
the
fastest
syntax
highlighting
in
the
world,
but
it
is
a
lot
faster
than
the
ones
that
are
just
written
in
JavaScript
that
you
see
people
use.
A
So
one
of
the
motivations
for
making
plugins
is
you
know:
I
was
looking
at
this
is
like
should
plug
it
should
syntax
highlighting
work
is
just
be
something
that's
in
the
core
natively
supported,
or
should
it
be
out
there
in
these
plugins
and
one
reason
I
wanted
in
plugins
is
I.
Don't
think
that's
that
reg
X
based
highlighting
is
the
is
the
future
I.
A
Is
this
a
bracket
or
is
this
a
comparison
operation
and
so
I
think
that
has
a
potential
to
be
both
faster
and
more
accurate,
just
strictly
better
across
the
board
and
I'm
kind
of
excited
about
the
potential
of
having
a
syntax
highlighting
module
being
used
in
context
other
than
just
driving
syntax
highlighting
of
zayed
etre?
So
let
me
show
you
kind
of
you
know:
how
would
that
work
like?
A
So
if
that
was
a
huge
file,
it
would
be
saying
you
know
give
me
the
first
megabyte
of
that
file,
so
okay,
fine
sure
pump
in
the
main
good,
and
it
says
here
your
color
spans,
and
so
then
you
know
if
I
want
to
say
Oh
edit,
that
you
know
make
that
you
know
hat
is
starting
to
comment.
You
know,
after
that
then
I
just
send
another
RPC.
That
says
edit
insert
here's
where
you're
editing,
here's
the
text
that
you're,
adding
and
so
sure
here's
your
new
color
spans.
A
You
heard
your
first
and
you
know
given
like
we're
rust
is
going
like
you
could
even
imagine
compiling
this
to
as
I'm,
using
in
script
and
running
the
whole
thing
in
a
deploying
the
whole
thing
to
the
web,
so
the
RPC.
How
does
this
work
so
it's
based
on
JSON
RPC-
and
this
is
one
of
the
most
conscientious
on
people
say
why
JSON
that's
so
inefficient,
so
slow,
it's
actually
not
inefficient.
A
Json
implementations
tend
to
get
optimized
like
crazy.
So
if
you
were
just
defining
a
binary
protocol-
and
you
just
started
writing
code,
that
would
probably
be
slower
than
the
actual
cert,
a
JSON
which
has
been
through
a
tremendous
amount
of
evolution
and
optimization
and
anytime
you're
writing
a
plugin
and
you're,
like
oh
I,
have
to
do
this
RPC
layer
well
doing
it
in
JSON.
That's
very
easy.
I
mean
you
talk
about
batteries
included.
A
This
is
a
double-a
battery,
not
a
cr123a
right,
so
the
the
current
code
is
is
using
threads
and
like
so
there's
this
thing
where
you're
blocking
on
input-
and
you
actually
want
to
be
a
little
bit
more
sophisticated,
especially
in
the
syntax,
highlighting
plug-in
that
you
know
you're
thinking
and
if
somebody
presses
a
key
you
get
in
an
edit
event
that
comes
in.
You
actually
want
to
interrupt
you're
doing
this
in
chunks.
A
You
don't
want
to
do
it
a
line
at
a
time,
but
if
you
see
an
event
coming
in,
you
want
to
be
sensitive
to
that,
and
so
there's
like
a
method
that
says
you
know,
is
there
request
pending,
and
then
you
pull
that,
like
really,
you
know
every
time
you
actually
do
a
line
and
the
way
that's
implemented.
Is
that
there's
a
separate
thread,
that's
blocking
on
input,
and
it
sends
a
message
over
a
channel
to
the
thread:
that's
actually
computing,
your
syntax,
highlighting
and
then
it's
using
arc
mutex
all
over
the
state.
A
Every
you
know
that
anytime,
you
need
access
to
some
piece
of
data.
Then
you
you
do
you
go
through
an
arc
mutex
to
get
that
and
that's
not
the
future.
This
is
the
future
that
I
really
would
love
to
replace
this
with
using
the
futures
library
which
we
just
saw,
and
that
would
have
some
pretty
significant
advantages
that
this
that
moving
just
moving
an
object
from
one
thread
to
another
thread
and
crossing
the
Linux
Cisco's
just
call
barrier
to
do
that
is
between
five
and
ten
microseconds,
and
so
by
doing
it
with
futures.
A
You
actually
are
going
to
save
that
overhead
altogether
and
another
thing
I'd
like
to
do
is
you
know
this
idea
of
the
future?
This
idea
of
saying:
okay,
here's!
You
know
a
request
to
do
something
and
I'm
not
ready
with
the
answer
yet,
because
maybe
it's
an
RPC
over
here
or
maybe
it's
a
slow
computation,
the
right
model
is
here's
a
request.
The
result
is
a
future
with
the
result
and
that
that
I'm
I
think
can
be
kind
of
a
metaphor
right
now.
A
This
is
kind
of
coded
by
hand,
but
I
think
that
can
be
an
organizing
metaphor
for
this
and
I
think
I
want
to
refactor
it
in
such
a
way
that
the
psycorps
can
be
more
embeddable
in
other
apps
and
not
necessarily
even
dependent
on
json-rpc.
That
just
becomes
a
detail,
so
switching
gears
a
little
bit.
Another
component
of
Zhai
is
that
Unicode
library
right
now,
the
main
thing
that's
in
there
is
this
line
breaking
algorithm,
so
uax
14
has
all
the
rules
about
like.
A
If
you
have
a
combining
character,
then
that's
not
a
line
break,
but
if
you
have
a
space
it
is,
and
you
know
it's
actually.
Emoji
has
a
whole
set
of
rules.
It's
very
complicated
and
you
know
the
industry
standard.
Implementation
of
this
thing
is
ICU.
You
see
that
almost
everywhere
and
of
course,
I
wanted
to
do
it
my
own
way,
and
so
I
built
a
kind
of
it's
at
the
heart
of
it.
It's
a
state
machine
that
it.
You
know
you
character.
A
It
just
runs
through
the
string
character
comes
in
what
Unicode
class
is
it
advanced
the
state
machine
by
one
state,
and
then
it
says
either
this
is
or
is
not
a
line
break
opportunity
and
though
the
implementation
turns
out
to
be
three
times
faster
than
ICU,
because
I've,
just
you
know,
focus
relentlessly
on
the
core.
What
is
this
thing
really
need
to
do
and
the
API
is
designed
to
support
that
incremental.
So
it's
the
incremental
breaking.
A
So
you
know,
obviously
you
get
an
iterator,
it's
very
natural,
very
clean
interface,
so
you
only
run
it
as
far
as
you
need
to,
and
then
you
initialize
it
with
some
state
which
might
be
in
the
middle
of
a
line
and
just
run
it
only
as
much
as
you
need
and
so
I'm
hoping
to
do
more
with
Unicode
there's
a
bunch
of
interesting
problems
that
need
to
get
solved.
I
think
the
most
interesting
of
these
is
the
case.
A
You
know,
because
there's
these
case
transforms
and
there's
you
know
different
normalization
forms
90%
of
the
time,
especially
when
you're
dealing
with
a
really
big
like
dump
of
something
like
you
know
that
ninja
file
that
I
opened
before
it's
asking
so
I'm,
hoping
to
use
a
homomorphism
to
say,
like
a
sort
of
a
difficulty
level
and
say
ASCII
is
the
simplest
difficulty
level
and
then
there's
more.
That
might
tell
you,
oh
you
have
to
use
these
more
complex,
more
expensive
algorithms
to
do
case
transformation.
A
So
when
you're
doing
search,
you
know
you're
going
over
the
trees
say
for
this
whole
subtree
I
can
just
use
this
really
really
fast.
You
know
just
run
over
bytes
and
you
know,
and
with
20
with
not
20
I
guess
to
do
the
case
transformation.
And
then,
if,
if
it's
you
know,
if
it's
a
complex
language,
that
needs
more
complicated
case,
transform
rules-
and
you
say,
okay-
go
go
the
slow
path
and
I
want
to
make
sure
all
this
stuff.
A
You
know
with
lots
of
different
features
and
fixes
and
improvements
and
lots
of
really
great
discussions
that
go
on
on
the
github
issue
tracker
as
well,
and
the
process
of
doing
this
you
know,
like
certain
JSON,
didn't
escape
control
codes
correctly,
so
that
was
really
cool
interaction.
You
know,
like
here's,
a
fix
and
a
little
discussion
is
this:
the
best
way
is
just
going
to
regress
performance
and
then
that
got
merged.
A
You
know
some
of
the
like
Unicode
property
lookup,
you
know,
I
use,
tries
that's
faster
than
binary
search,
so
pull
request
to
rustling
to
get
the
Unicode
property
lookup
faster
and
then
the
line
breaker
like
it
was
really
good
timing,
because
you
know
servo
had
this
thing
that
was
just
get
spaces,
it
didn't
really
use.
Do
the
Unicode
rules
right
and
I
was
like
hey.
Do
you
need
this
and
they're
like
yeah?
This
would
be
great
and
so
again
getting
that
integrated
into
servo
happen
within
I.
A
A
C
All
right
now
I'm
nervous
cuz.
They
might
have
better
questions
I'm,
actually
really
curious
about
the
you're
scrolling
of
the
300
Meg
file.
What
it
would
it
you
just
just
described
the
protocol
to
actually
like
yeah,
scroll
and
refresh
is
that
it
like
a
deltas
or
your
shipping
Delta's
back
and
forth,
or
what.
A
A
So
it's
at
most
one
screen
full
of
information
as
you
scroll,
obviously,
you've
got
state
that
lives
in
the
core
that
doesn't
live
in
the
front
end.
So
it's
ends
at
that
point.
That's
like
one
of
the
few
synchronous
are
pcs
in
the
system
and
it
says
you
know
give
me
the
give
me
the
view
the
rendered
view.
A
So
it's
got
all
the
line,
breaks
and
syntax
and
the
style
spans
in
there
give
me
the
rendered
view
for
this
region
and
then
that's
an
RPC
that
come
goes
out
and
it
comes
back
as
JSON
lines
with
spans
and
gets
displayed
and
then
I've
I
won't
show
it.
There's
like
debug
information,
that's
almost
always
less
than
one
millisecond
round-trip
to
make
that
RPC
happen.
So,
even
though
it
is
synchronous,
you
know
it's
not
slowing
down
the
the
scrolling
process.