►
From YouTube: Clojure visual-tools meeting 10: Oz
Description
In this monthly meeting of the Clojure visual-tools group (Aug 5th, 2022), Christopher Small gave a presentation about the internals of Oz and some features under development. Then, we discussed possible ways to extend it.
Repo: https://github.com/metasoarous/oz
Summary: https://clojureverse.org/t/visual-tools-meeting-10-summary-video-oz/
A
Hello,
everybody:
this
is
another
session
of
the
visual
tools
group
and
today,
we'll
have
a
session
about
oz
and
this
tool
by
christopher
small
who
will
present
it
in
a
moment,
and
this
group
is
a
group
that
meets
about
once
a
month
to
discuss
collaborations
and
updates
about
tooling
enclosure,
and
maybe
we
will
begin
by
introducing
ourselves
briefly
and
then
we'll
go
about
the
main
part
and
then
we'll
at
the
end.
We'll
have
some
discussion
and
richie
is
it
okay?
Would
you
tell
a
little
bit
about
yourself.
B
Yeah
hi,
I'm
richie,
which
is
I
I
just
recently
graduated
got
my
phd
and
I
use
a
lot
of
clojures
for
my
work
and
I
actually
use
oz
as
well
for
visualization
appreciate
the
work
by
the
way
before
that
I
was
looking
for.
I
think
I
was
using
encantor
very
long
time
ago
and
then
that
thing
just
kind
of
become
dead,
and
then
I
was
just
searching
for
a
long
time
for
for
actually
a
useful
one
from
us.
B
Thank
you
very
much
yeah.
So
I
think
closure.
At
least
I
mean
I'm,
I'm
I'm
not
just
into
closure,
I'm
into
list
in
general,
and
I
think
at
this
point
the
closure
is
probably
the
the
most
viable,
the
most
practical
one.
Just
because
it's
connected
to
the
jvm
has
access
to
so
many
tools,
libraries
and,
and
also
it
also.
B
I
would
say
it's
a
little
bit
more
updated
version
of
a
lisp
that
has,
you
know,
use
all
all
three
kind
of
different
versions
of
parentheses,
right,
curly,
brace
bracket
and
and
the
regular
parenthesis,
which
is
very
useful,
very
useful,
very
much
easier
to
read
than
the
the
commonly,
but
so
I
enjoy
using
clojure
a
lot
and
I
think
the
the
the
process
you
know
the
the
ripple
development
process
is
extremely
extremely
powerful,
underrated
and
those
are
closure.
The
the
concurrency
aspect
of
it.
B
That's
what
I
also
the
other
reason.
I
I
like
the
most
a
lot
of
my
my
previous
phd
research,
workout
evolving,
like
developing
this
concurrent
algorithm,
so
so
that
everything
add
together.
So
I
do
have
I
I
think,
for
past
eight
nine
years
they
just.
I
just
learned
everything
on
myself
and
I
don't
know
anybody
in
person
that
do
closure.
I
try
to
kind
of
get
a
few
people
around
me.
B
B
You
know
very
various
topics,
I'm
just
very
interested
in
and
also
I
recently
started
working
at
the
you
know,
my
my
new
job,
actually
as
a
clojure
developer
and
and
I'm
the
only
one
in
the
company
doing
a
small,
a
kind
of
a
core
project
of
that
is
a
written
enclosure
and
I'm
looking
to
probably
get
some
of
my
team
member
educated.
So
I
mean
some
of
the.
B
A
Beautiful,
thank
you
so
much
and
by
the
way,
richie
is
also
involved
in
a
new
group
where
we
will
be
discussing
tensorflow
and
using
tensorflow
tensorflow
from
closure,
and
maybe
it
is
something
we'll
discuss
in
the
near
future.
I
hope
and
yeah
thanks
and
maybe
I'll
tell
about
myself,
I'm
danielle
I
do
which
group
is
that
it
doesn't
have
a
name.
Yet
it
has
a
stream.
A
B
Yeah
I
got
into
closure
because
I
was
interested
in
language
development.
I
mostly
do
web
dev,
but
I've
done
some
other
interesting
things.
I've
done
some
stuff
with
constraint,
solving
floating
point
base,
constraint,
solving
and
integer
base,
which
is
like
what
most
constraint
solving
is
I've
used
instant
parse
to
help
write
a
language
enclosure
and
other
other
than
that.
I
mainly
just
do
web
dev
stuff.
B
B
So
mostly
I
build
like
data
publishing
tools
for
various
uk
government
agencies,
although
I'm
in
canada
and
yeah,
I
guess
yeah.
I'm
currently,
like
I
mentioned,
looking
to
find
some
sort
of
like
container
or
notebook
tool
to
publish
this
like
closure,
data
content,
examples
and
tutorials
and
stuff
like
that,
and
so
I'm
really
curious
about
yeah
oz
and
clerk
and
all
the
other,
viable
ones
and
curious,
like
like.
I
said
to
find
something:
that's
going
to
be
like
it's
it's
hard
to
find
something.
B
That's
good
for,
for
both
like
purposes
like
easy
to
publish
and
easy
to
navigate
and
use
and
like
read
as
a
book,
but
then
also
like
a
useful
like
software
environment,
so
like
something
that
you
can
copy
paste
examples
from
and
actually
run
them
and
something
that
you
can
somehow
test
the
examples
that
are
in
it
and
stuff
like
that.
So
there
are
like,
obviously,
a
million
solutions
out
there
for
publishing
like
a
static
website
like
publishing
a
bunch
of
content
as
a
book
on
the
internet,
I'm
hoping
to
find
something.
B
But
not
like
so
far
that
it
looks
terrible
anyway,
yeah,
so
super
curious
with
this.
I'm
excited
for
this
this
next
hour
and
anyway
it's
it's
a
very
slow,
ongoing
project.
I
guess
I'm
trying
to
find
my
way
towards
some
way
to
like
maybe
take
a
day
or
two
off
a
week
from
work
and
do
this
instead,
but
for
now
it's
just
like
a
little
part-time
hobby
pace,
type
of
thing,
but
yeah
anyway.
That's
me.
A
Fantastic,
thank
you
so
much
then
christopher.
Maybe
you
would
like
to
present
yourself
in
a
moment
and
then
we'll
just
go
about
diving
into
pose
and
probably
we
could
make
it
a
little
less
than
an
hour
and
then
we
leave
some
time
at
the
end
to
kind
of
broaden
the
picture
and
talk
about
the
big
picture
and
yeah.
So
what
do
you
feel
about
herself.
C
In
a
nutshell,
it's
it's
data-driven
philosophy.
I
think
that
sort
of
obviously
data-driven
programming
methodology
and
and
and
data
science
kind
of
feel,
like
they
go
hand-in-hand,
just
a
lot
of
the
ways
that
closure's
been
so
brilliantly
designed
to
think
of.
Well,
let
me
let
me
stop
from
waxing
poetic
here.
C
I
think
we
all
know
we
don't
know
why
we
like
closure,
but
yeah,
so
it
you
know,
as
part
of
that
you
know
living
in
an
ecosystem
that
is
still
kind
of
young
like
to
be
able
to
kind
of
contribute
back
to
that.
So
I
built
a
few
different
tools
in
in
my
time
that
kind
of
touched
on
the
space.
One
was
semantic
csv,
which
is
like
a
csv
processing
library.
Back
in
the
day.
I
think
now
that's
somewhat
been
a
lot
of
that.
C
It
was
really
interesting
and
kind
of
you
know
visualization
as
a
value
and
kind
of
felt
like
he
was
very
in
line
with
the
the
closure
philosophy,
but
it
was
just
kind
of
too
verbose
for
like
day-to-day
data
visualization,
and
I
had
seen
that
the
the
folks
who
are
working
on
it,
who
are
actually
here
in
seattle
at
the
the
interactive
data
lab.
I
saw
that
they,
this
other
project
vega
lite,
which
was
supposed
to
be
more
for
like
day
to
day
data
science
work.
C
There
was
a
little
library
that
that
kind
of
you
know
had
had
see
what
was
it
called
wizard,
which
was
just
very
simple:
it's
just
a
rebel
tool
for
visualizing,
you
know
for
for
displaying
visualizations
in
a
web
browser,
so
I
had
a
websocket
and
you
know
it
would
send
these
visualizations
and
and
visualize
them,
and
and
and
this
would
be
possible
by
the
fact
that
the
the
vega
and
vaguely
data
visualizations
are
just
data
specs
right.
So
it
was
really
easy
to
just
take
a
specification.
C
C
So
I
started
working
with
that
and
realized
that
there
are
some
things
I
wanted
to
do
that
you
couldn't
do
in
vega
light
she
actually
needed
the
full
vega
to
do
the
original
author
wasn't
interested
in
in
adding
vegas
support,
considered
it
wasn't,
wasn't
his
bag,
and
so
I've
worked
the
project
and
started
working
on
it
and
realizing.
Oh,
you
know
we
could
add
hiccup
in
here
as
well.
C
It's
kind
of
an
additional
layer
for
composing,
visualizations
and
other
potentially
other
user
interface
or
reporting
kind
of
stuff,
and
before
you
know
it,
this
whole
project
is
snowballed,
and
now
I
don't
even
know
what
the
thing
is
we'll
talk
about
that
a
little
bit
more
later,
but
but
that's
that's
kind
of
where
we're
at
now.
The
project
is
evolved
considerably
over
the
years
as
you
kind
of
get
to
now.
Okay,
now
you've
got
hiccup
right,
so
you're,
pretty
close
to
like
sort
of
a
static
content
generator.
C
Now
I
was
like,
let's,
let's
actually
build
that
into
something
that
watches
files
and
and
and
could
be
used
to
like
do
live
coding
of
of
a
website
like
a
static
website,
a
blog
or
something
or
or
even
kind
of
a
notebook
kind
of
workflow.
And
what
I'm
talking
about
today
is
kind
of
a
little
bit
of
where
that
evolution
has
led
to,
but
also
as
as
daniel
pointed
out,
how
how
how
I
see
it
being
used
in
sort
of
a
more
flexible
capacity.
C
As
you
know,
from
from
a
developer
perspective
from
the
perspective
of
someone
who's
wanting
to
take
the
tool
and
kind
of
do
something.
That's
maybe
a
little
outside
of
its
wheelhouse,
but
actually
they
use
it
almost
as
a
library
or
as
a
component
in
some
bigger
system
and
so
those
two
things
kind
of
feed
off
of
each
other.
C
So
so
again,
I'm
going
to
kind
of
start
off
in
talking
about
oz
as
a
data,
sync
processing
framework
and
then
get
into
extending
it
and
and
and
how
you
do
that
and
then
hopefully
get
feedback
from
folks
about
what
they,
what
what
they
think
about
this
direction,
whether
they
have
ideas
is
this
bad.
Is
this
good
what
you
know
what
other
things
are?
Are
we
not
thinking
about
here
and
so
yeah?
C
If
there's
no
questions
right
now,
I'll
go
ahead
and
go
ahead
and
dig
in
so
the
first
thing
to
really
point
out
is
that
I,
like
every
time
I
talk
about
odds,
I'm
like
never
quite
sure
how
to
describe
it.
I
kind
of
started
describing
this
like
a
swiss
army
knife,
which
is
kind
of
true,
because
it
is
this
tool
where
again,
you
could
really
do
a
lot
with
it.
C
I
mean
right,
there's
all
this
sort
of
stuff
that
you
can
do,
and
so
it's
it's
really
hard
for
me
to
like
capture
like
a
nice
package
like
what
actually
is
oz
right,
and
I
think
that
really
what
it's
turning
into
is
async
data
processing
toolkit,
and
that
means
a
lot
of
these
other
things
right.
But
but
you
know
the
pithiest
way,
I
think
it
could
put
it
isn't
it's
an
engine
for
processing
and
visualizing
code
documents,
data,
etc
right
with
it
with
hopefully
at
least
an
extensionable
extensible
execution
model.
C
Whatever
the
sort
of
processing
flow
that
we're
working
on
is
so
some
of
the.
What
this
kind
of
means
is
that
some
of
the
things
that
this
potentially
encapsulates
or
covers
are
kind
of
the
the
tasks
of
what
you
might
traditionally
call
like
a
workflow
manager
or
workflow
tool
in
kind
of
a
bioinformatics
or
you
know
in
some
kind
of
parts
of
the
data
science
space.
So
I
remember
some
of
the
names
of
these
things.
C
It
also
kind
of
exists
as
a
build
tool,
which
I
mean,
there's
overlap
between
those
things
too
right
right
back
and
I
was
at
fred,
hutch
cancer
reaches
center
was
kind
of
how
I
got
into
data
science
doing
bioinformatics
stuff.
It
was
we
didn't.
We
were
actually
using
s
cons,
which
is
this
make
replacement
written
in
python,
usually
used
for
building
software,
but
we
had
sort
of
repurposed
it
for
building
bioinformatics
analyses
because
actually
has
a
lot
of
things
that
are
really
nice.
You
can
track.
C
You
know,
hash's
input
files
and
keeps
track
of
the
commands
that
you're,
whether
they've
changed,
whether
the
files
have
changed
and
sort
of
does
a
pretty
good
job
of
only
running
what
needs
to
get
rerun.
It
had
a
lot
of
constraints
that
sort
of
borne
out
of
the
fact
that
it
was
really
focused
on
building
software
and
that's
why
it
had
built,
but
we
were
really
able
to
do
a
lot
with
another
advantages
of
using
this
kind
of
tool
for
for
orchestrating
analyses.
C
C
C
C
C
So
if
you
have
watching
code
and
evaluating
as
you
save
changes,
there's
a
lot
that
you
get
that's
that's
kind
of
similar
to
what
you'd
have
from
an
ide
right
where,
as
as
you
run
or
as
you
update
things,
you're
able
to
see
which
chunks
of
code
are
failing,
what
what's
stream
of
that?
That
might
also
be
failing
or
up
from
running
it.
C
C
As
a
doing
the
initial
work
on
making
things
we're
running
here
and
everything
was
that
we
actually
want
right,
we
don't
want
to
have
to
wait
until
a
file
has
fully
fully
finished
running
to
start
displaying
anything
right.
It
was.
It
was
really
annoying
to
me
with
it
with
the
earlier
sort
of.
You
know
one
point,
whatever
iterations
of
oz,
that
if
you
had
a
file
that
had
a
lot
of
analysis
going
on,
you
literally
had
to
wait
until
the
entire
thing
was
complete
to
get
any
kind
of
feedback
to
see.
C
And
and
a
notebook
file,
but
the
the
way
that
I
had
set
things
up
in
oz.
1.0
is
a
very
simple
assumption
about
code
changes
only
things
after
your
first
code
change,
get
re-run
right,
and
so,
if
you're
going
in
and
changing
a
body
of
text
in
the
middle
of
a
code
file
you're
having
to
re-evaluate
the
entire
file
right
and
any
you
know,
computational
steps
that
could
come
after
that.
C
C
Next
iteration
is,
for
obviously
like
I
should
be
getting
results
and
feedback
as
thing,
and
a
kind
of
key
consequence
of
that
is
that
you
need
to
have
something
to
render
right
off
the
bat
and
so
the
process.
The
pre-processing
step
in
in
the
oz
process
model
is
really
about
building
up
your
initial
view
of
the
data.
C
Sorry
you're
right,
you're,
taking
in
some
kind
of
data,
whether
it's
markdown
or
closure,
or
you
know,
or
whatever
kind
of
assets
and
you're
going
to
be
coming
up
with
some
hiccup
representation
of
them
right.
So
so,
in
the
case
of
code,
say
or
even
markdown,
that
has
code
sort
of
embedded
within
it,
you're
going
to
need
some
initial
view
of
that
code,
and
so
where
things
are
still
getting
processed
a
sequence,
their
code
is
still
being
evaluated.
C
We're
going
to
use
these
well,
and
we
do
now
use
these
oz,
async
block
hiccup
elements
which
represent
something
that
hasn't
completed
yet
right.
So
now
these
async
blocks
they
can
actually
have
content
associated
with
them
right
so
that
you
can
start
displaying
something
so,
for
instance,
for
for
a
code
block
from
from
a
closure
file.
You're
gonna
want
to
display
that
code,
and
you
know
on
the
on
the
live
view.
C
We
actually
display
something
that
tells
you
how
long
that
code
is
taking
to
evaluate,
has
a
little
ticker
when
it's
done.
You
know
that
that
checks
off,
but
in
addition
to
well
yeah
so
so
the
first
goal
is
really
to
generate
this
sort
of
initial
view,
with
these
async
blocks
for
places
where
there's
something
that
we
still
have
work
to
do
on
right.
C
C
The
languages
that
are
sort
of
thing,
but
but
I
you
know,
I
think,
there's
still
potential
in
that
space
so
anyway
kind
of
take
again
we're
supposed
to
be
focusing
on
execution
model
here.
So
the
pre-processing
step
again,
it's
the
static
phase
right
we're
coming
up
with
some
static
representation
of
whatever
it
is
that
we
want
to
visualize
whatever
kind
of
document
we're
working
with.
C
C
We
update
a
live
view,
synchronous
results,
so
once
that's
happened,
we
go
into
the
execution
mode
and
in
the
execution
mode,
these
asynchronous
blocks
are
processed
in
parallel.
I
should
have
put
that
there
and,
as
updates
complete
they're,
sent
to
the
live
view,
so
once
all
of
those
asynchronous
blocks.
C
And
completed
now
we
fall
back
up
in
a
case,
for
example,
where
you
don't
really
have
right
where
the
live
view
isn't
quite
good
enough,
because
you're
say
updating
your
writing
to
a
pdf.
That's
something
that
or
even
actually,
if
you
are
just
writing
to
html,
but
for
your
your
final
static,
html
document.
You
want
that
to
be.
You
know
you,
you
need
all
the
actual
content
before
you
write
that
you
can't
just
have
these
asynchronous
blocks
in
there,
and
so
so.
C
A
A
C
C
C
Yeah
great
so
so
yeah
I
actually
do.
I
was
thinking
the
same
thing
daniel
that
this
is
actually
a
pretty
good
time
to
stop
for
questions.
But
let
me
let
me
just
say
a
couple
more
things:
real,
quick
that
kind
of
fully
fleshed
things
out
a
little
bit
more,
so
the
dependencies
are
mediated
by
this
oz
block
id,
which
is
a
hash
based
on
the
source
of
whatever
block
your
you
are
currently
on
and
all
of
its
dependencies.
C
And
so
again
the
analysis
step
is
something
that's
kind
of
abstracted
and
which,
among
other
things,
returns
a
set
of
dependencies
as
other
block
ids.
And
then,
when
we're
computing,
this
quote-unquote
current
block
id
that
that
ends
up
being
a
you
know,
derived
based
on
its
dependency
block
ids,
as
well
as
whatever
source
and
stuff.
C
Yeah
yeah,
let's
see
where
has
most
of
my
work
on
so
for
the
initial
kind
of
pass
that
I
mean
right
now.
This
is
actually
maybe
a
good
time
to
step
back
and
say
where
the
project
as
a
whole
is
right.
Now,
right
now
I've.
Unfortunately,
oz
has
been
in
sort
of
a
weird
state
for
a
while.
I
had
I
had
very
high
aspirations.
C
Last
time
I
talked
about
oz
that
within
a
few
months
or
so
I'd
be
releasing
a
non-alpha,
2.0
release
and
and
that
you
know,
we'd
see
oz
2.0
coming
into
the
world.
You
know
more
sort
of
fully
within
you
know,
within
a
few
months
of
course,
fast
forward
and
we
had
a
war
in
ukraine.
Sadly,
my
my
parents,
my
family,
was
involved
in
the
the
wildfires
in
new
mexico
largest
in
history
this
year,
and
so
I
went
down
there
to
help
them.
C
You
know,
keep
working
on
that
alpha
branch
and
and
getting
things
pumped
out,
but
again
this
year
has
just
been
a
little
more
challenging
than
anticipated.
So
I
kind
of
left
a
note
in
and
here
I'll
actually
so
right
now,
if
you
go
to
metasaurus
oz,
there
should
be.
Oh,
did
I
not
oh,
I
guess
I
didn't
push
it
okay!
Well,
I
I
was
supposed
to
have
pushed
here.
Let
me
see,
can
I
push
that
now?
Oh,
I
thought
I
thought
I
did
it
in
browser.
C
But
basically,
if
you
want
to
use
something,
that's
stable
use,
the
1.6
point
something
version
and
I'll
have
that
hard-coded
in
here,
and
if
you
want
to
test
out
some
of
the
new
asynchronous
slash
parallel
processing
functionality,
then
then
go
ahead
and
check
out
the
the
2.0
build,
but
just
know
that
it
is
more
alpha
than
the
than
the
1.6
version.
Currently
is
so,
let's
see
where
are
we
back
here?
C
C
C
This
is
a
little
hard
to
maybe
I
could
type
some
out
later
if
you're
interested,
but
if
you
do
the
tick,
tick,
tick
style
of
code
embedding
in
a
markdown
file.
If
you
know
what
I
mean,
you
can
stop
me.
If
you
don't
you'll,
you
may
be
familiar
with
the
model
of
on
the
first
tick,
tick
tick
you
could
put
clj
or
js,
or
you
know
some
some
extension
to
notate
what
language
you're
working
with
what
language
the
code
is
in.
Well,
there's
a
there's
a
an
additional.
C
If
you
put
space,
I
think
it's
eval
that
might
be
changed
to
execute
here
to
kind
of
match
execute
here,
then
that
will
actually
execute
the
code
as
say
a
vega
light
spec
or
in
the
future.
That'll
execute
potentially
closure
or
closure
script,
maybe
a
skittle
or
or
whatever,
and
potentially
other
languages
right.
So
if
you'd
like
to
embed
some
r
in
your
in
your
data,
science,
notebook
or
some
python,
you
should
be
able
to
do
that
as
well.
B
C
C
B
There'll
be
one
code
snippet
in
the
file
that
doesn't
require
for
the
namespace
and
then
none
of
the
other
code
snippets
will
use
it.
So
do
you
have
like
is
this
that
style
that
you're,
that
you're
aiming
for
or
you
want
it
to
be
like
actual
copy
and
paste
in
whatever
code
block
the
code
is
expected
to
be
copy
and
paste
did
and
there's
no
like
references
to
other
previous
code
blocks,
or
is
it
going
to
be
more
like
literate
programming,
where
the
whole
markdown
file
is
considered
like
a
single
namespace.
C
There
should
actually
be
nothing
wrong
with
that,
but
yes,
it
would
be
implicit
that,
if
at
the
very
top
of
your,
if
the
first
code
block
in
your
in
your
markdown
file,
say
again
like
a
readme,
as
you
mentioned,
it
has
a
namespace
declaration
in
it.
Then
everything
after
that
would
fall
within
that
namespace.
C
B
C
Yeah
yeah
there
are.
There
is
some
stuff
like
that.
That
hadn't
occurred
to
me
that
there
was
some
similar
work
going
on
there,
but
but
yeah
that's
actually
one
of
the
things
that
again
like
I
want
to
do
more
in
oz
to
actually
make
testing
of
kind
of
first
class
consideration,
because
I
think
that'll
make
it
insanely
more
useful
as
a
as
a
general
purpose
programming
tool
but
yeah.
So
there's
probably
some
similar
stuff
going
on
there.
I
don't
know
I
I
think
I
know
the
project
you're
talking
about
there.
C
May
there
may
even
be
a
couple
of
them
now
I
don't
know
what
they're
using
to
do
it
but
yeah.
My
guess
is
it's
pretty
similar?
What
I'm
doing
right
now
is
literally
just
using
the
I
think
it's
jagthos's
markdown
processor.
I
think
that's
right
and
what
happens
is
when
those
code
blocks
come
out.
All
those
little
annotations
come
out
as
classes
on
that
code
block.
C
You
know
represented
as
hiccup,
and
so
we
look
for
those
class
annotations
that
it
parses
out
in
order
to
figure
out
how
we're
going
to
interpret
those
blocks
of
code.
So
then,
once
we've
taken
those
blocks
of
code,
you
know
we
can
pass
them
through
the
oz
reader
and
it
can
do
all
of
its
work.
You
know
well
again
going
it
goes
to
the
pre-processing
step,
to
figure
out
what
namespaces
are
required,
what
the
dependencies
are
blah
blah
blah
blah
right.
B
B
What
do
you
call
it?
It's
like
the
lines
don't
execute
in
order.
It's
not
an
out
of
border
execution
model,
so
I
have
to
figure
out
the
order
to
actually
keep
things
in
so
I'm
sort
of
like
this
is
a
that's
an
easy
thing
to
do
compared
to.
I
think
what
you're
doing
so,
I'm
interested
in
the
the
issues
you've
run
into
with
like
cutting
up
these
files
and
figuring
out
how
to
deal
with
the
dependencies,
especially
with
async
stuff.
C
C
Now
I
don't
want
to
scare
you
too
badly,
because
I
think
that
one
of
our
real
advantages
here-
and
I
think
this
goes
very
strongly
in
in
the
corner
of
support
for
closures,
approach
to
paradigming,
sorry,
closure's
approach
to
to
programming,
and
in
particular
it's
it's.
You
know.
It's
emphasis
on
pure
functional
programming
is
that
we
don't
have
a
lot
of
mutations.
There's
some
kind
of
key
language
constructs
that
do
require
mutation
in
particular.
Every
time
we
use
a
multi-method
right,
we
are
mutating
some
state
somewhere.
C
It's
just
not
possible,
I
mean
you
can
even
kind
of
I
mean
I
think
you
should
be
able
to
prove
at
some
level
that
you
know
without
running
unless
you're
in
some
kind
of
really
strictly
typed
language
that
you
know
is
doing
like
has
provers
and
solvers
and
stuff
built
into
it.
There's
only
so
much
you
can
do
to
say
with
absolute
confidence
that
that
some
code
is
not
going
to
mutate.
Anything.
A
C
C
This
block
depends
on
this
because
of
the
way
that
things
are
mutating
here.
But
if
you're
trying
to
write
you're,
probably
going
to
come,
come
up
with
problems
if
you're
trying
to
write
code,
that
is,
you
know
like
what
you
might
write
and
say
python,
or
or
javascript
or
wherever,
where
you're,
creating
an
array
and
then
mutating
it
in
place.
We
don't
write
that
kind
of
code
very
often
so
like.
B
C
C
Let's
you
know,
let's
take
it
to
the
next
step
or
whatever,
but
there
are
some
problems
with
that,
so
in
particular,
and
I'm
trying
to
remember
all
the
details
of
this
is
a
little
fuzzy
now,
but
it's
not
always
the
case,
for
example,
that
when
you
re-evaluate
say
a
function,
definition
like
define
blah
blah
blah
some
function,
yada
yada
right,
you
might
be
able
to
add
a
listener.
To
that
var,
I
know
you
can
add
listeners
to.
C
I
think
you
know
listeners
of
ours
is
that
right,
but
certainly
you
can
add
listeners
to
to
atoms,
say
right,
but
there's
a
lot
of
cases
where
you
know,
especially
if
you
have
like
a
function
involved.
The
function
definition
might
be
exactly
the
same,
but
you're
going
to
get
a
new
function,
object
and
there's
no
way
to
test
it
for
equality
with
another
function
and
sadly,
not
everything,
not
every
value,
enclosure,
sort
of
knows
what
its
quote-unquote
source
was
right.
C
C
C
We
can
discuss
that
more
in
a
little
bit
here
if
folks
are
interested,
but
where
you'd
specify
all
of
these
pieces
that
I'm
kind
of
abstracting
away
right
now,
so
these
are
some
of
the
key
ones
that
that
may
that
may
pop
up-
and
you
know
these
are
all
going
to
be
kind
of
more
fully
specced
out
soon.
Here,
oh
right,
I'm
kind
of
mixing
things
up
here.
C
I
think
this
was
initially
written
assuming
this
was
going
to
be
not
block
type
but
actually
doctype,
so
I
think
parse
func
function
and
analyze
function
and
yeah.
At
least
these
two
would
be
for
the
doctype,
and
these
three
would
be
for
the
block
type.
So,
to
clarify
what
I
mean
there,
a
document
is
some
like
say:
a
closure
file
or
a
markdown
file
or
an
html
file.
C
C
C
C
Well,
I
guess
we
could
talk
about
that
later,
but
here,
let's
just
do
a
little
example
here,
because
this
is
this
is
just
so
cool
to
me.
So
here
we've
got
kind
of
a
gratuitous
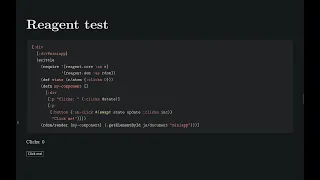
reagent
test
right,
so
we're
requiring
reagent
core
reagent,
dom
defining
our
atom
our
state
atom.
Here
here
we
have
a
component,
displays
the
current
number
of
clicks
and
it
has
a
button
which,
which
updates
the
the
click
count
using
swap
so
indeed,
this
this
does
the
thing.
C
Now
again,
one
of
the
things
that's
broken
in
os
2.0.
Is
that?
Actually,
I
think
daniel
pointed
this
out
to
me
is
that
the
the
template
function
and
some
of
the
other
things
are
only
working
in
the
static
compile
mode.
So
that's
one
of
the
things
that
I'm
working
on
fixing
right
now,
so
this
is
actually
the
static
compilation
that
I'm
playing
with
here,
but
but
yeah
you
can
see
it
does
the
thing-
and
this
is
this-
is
really
cool.
I
think
this
opens
up
a
lot
of
really
really
awesome
possibilities.
C
C
What
this
is
doing
is
it's
using
the
template
function,
feature
of
oz,
oz,
build,
isn't
the
only
one
that
takes
it,
but
that's
how
I'm
using
it
right
now
is
using
this
template
function.
So
what
this
does
is
this
this
slideshow
that
I'm
using
right
now
was
generated
from
a
closure
source
file,
and
we
can
look
at
that
if
folks
are
interested
and
what
we
did
was
created.
A
custom
template
that
styles,
these
things
and
gives
the
functionality
of
slides-
and
I
can
try
to
go
over
the
code
here-
just
really
quickly.
C
First,
there's
a
slide
view.
This,
just
you
know,
puts
things
in
a
div
and
you
put
your
yeah
basic,
simple
div,
and
then
we
have
a
function
which
groups
the
slides
together,
and
this
is
basically
just
the
the
the
processing
model
here
is
that
every
time
you
see
an
h1
block,
that
is
to
say,
you
know
a
header,
a
large
header,
you
start
a
new
slide
and
so
in
my
source
code
for
these
slides,
then
every
time
I
want
to
start
a
new
slide.
C
I
just
include
a
head,
an
h1
tag
and
everything
after
that
will
be
included
in
that
slide
and
yeah.
The
rest
of
this
code
doesn't
matter
too
much,
but
it's
just
recurring
through
and
adding
things
to
the
last
slide.
If
that's,
what
the
right
thing
to
do
is
and
then
starting
a
new
slide
if
it
needs
to
do
that.
C
The
next
thing
is,
we
add
ids
to
the
slides
and
you'll,
see
why
that's
important
in
a
minute,
but
that's
basically
just
so
that
you
can
navigate
between
slides
more
easily
and
then
there's
our
actual
slides
template
here,
where
we're
kind
of
putting
all
that
stuff
together.
Calling
out
slide,
ids
and
group
slides
and
then
in
build
all
that.
C
If
we
go
back
up
here
and
look
at
the
execution
model,
it's
this
initial
payload
that
it's
going
to
be
generating
right,
like
this
view
that
it's
generating
here
is
going
to
be
what
it
spits
out
from
that
template
function
that
we
just
defined
right.
So
that's
that's!
What's
going
to
get
sent
to
both
to
the
browser
and
to
the
static
compilation,
let's
see
so
what?
C
This
is
probably
like
not
the
best
code,
I've
ever
written,
there's
a
lot
of
repetition
here,
but
sometimes
that's
fine,
but
this
is
just
a
very
basic
routine,
which
lets
me
use
page
down
and
page
up
to
key
in
on
those
on
those
slide,
ids
that
we
were
generating
up
in
the
step
above
here.
You
remember
right
here,
we're
adding
slide
ids
we're
just
going
through
the
slide
blocks
and
range.
Oh,
this
is
sloppy.
A
C
Yeah
exactly
yeah
yeah
yeah,
so
technically
this
all
this
code
is
yeah.
I
mean
yeah
right.
I
love
macros,
so
yeah.
So
all
of
this
code
is
being
evaluated
in
closure
in
the
jvm,
but
all
this
macro,
skittle
is
doing
is
taking
all
the
code
that
you
give
it
and
it's
basically
just
quoting
it
and
sticking
it
in
a
script
tag
and
returning
that
as
data
and
so
again
we
can
look
at
that
up
up
here.
C
C
C
A
B
A
C
Yeah,
and-
and
this
is
this-
is
wrapping
up
here
so
so
coming
soon.
Next
steps
for
me
are
to
add
back
in
markdown
and
other
support
and
again
kind
of
finish,
abstracting
and
generalizing
this
this
system
that
I've
been
describing
better
tracking
and
hassling
of
input
data
files.
So
I
want
to
create
a
some
kind
of
demarcation
in
basically
just
a
code.
You
know
a
function
in
the
api
that
that
tracks
things
as
sort
of
like
data
file.
C
Finally,
this
is
kind
of
a
somewhat
wild
idea,
but
I'm
really
interested
in
figuring
out
how
to
sort
of
mesh
this
with
like
a
knowledge
base
integration.
So
that
you
could
actually
have
oz
notebooks
that
get
spit
out
into
rome,
research,
notebooks
or
or
athens,
or
logseek,
or
obsidian
or
or
notion
any
of
these
kind
of
knowledge.
C
You
know
notebooking,
and
you
know,
data
workflow
kind
of
tools
fit
within
that
paradigm
is
kind
of
an
exciting
intersection
to
explore
so
yeah.
That
kind
of
leads
us
to
some
questions
which,
which
I
have
and
which
I'm
interested
in
feedback
on
we
can.
We
can
take
the
discussion
in
whatever
way
folks
want,
but
these
are
some
of
the
things
that
I'm
kind
of
thinking
about
right
now,
I'm
interested
in
hearing
from
folks
on
so
the
first
is:
how
do
we
register
global
live
view?
C
Requirements
for
the
live
view
docs?
So
this
is,
this
is
kind
of
a
key
to
making
oz
really
truly
extensible
oz.
Has
this
challenge
where
again
it's
it's
able
to
view
things
both
in
a
live
view
mode,
but
also
in
sort
of
a
static
compilation
mode
and
that's
just
very
fundamental
to
like
what
oz
is
and
really
the
kind
of
a
key
to
this
whole.
C
C
Getting
back
to
this
question,
how
do
we
register
things
for
the
live
view
side?
How
do
we?
How
do
we
extend
that?
One
option
is
just
to
use
this
something
like
this
skittle
macro,
but
is
there
jason?
Yes
somehow,
but
is
there
also
a
way
somehow
to
do
a
more
traditional
closure
script
compilation
in
order
to
get
some
functionality
into
the
live
view,
so
that
it
knows
how
to
render
your
custom,
your
custom
data
type
or
whatever,
right
now
to
be
fair,
there's
a
lot
that
can
be
done
just
by
using.
C
Yeah
right
so
there's
a
lot
that
can
be
done
just
by
how
shall
I
say
this
a
lot
of
the
times.
You
don't
actually
need
something
different
for
live
view
than
you
do
in
just
a
static,
html
document
right
now.
What
what
gets
spit
into
a
static
html
document
for
for
for,
say
a
vega
light
visualization
is,
would
probably
actually
work
decently
enough
for
for
for
the
live.
Sorry,
I
think
I
said
that
wrong
yeah.
What
gets
spit
out
for
a
static
document
would
actually
work
decently.
C
Well
enough
for,
for
the
live
view,
sort
of
mode,
there's
some
nice
things
that
you
can
do.
If
you
have
some
closure
script
running
where
you
can
look
and
see
what
is
you
know
what
what
has
actually
changed
here?
Can
we
be
a
little
bit
more
efficient
about
what
we're
recomputing
with
the
vega
vega
light?
Visualization,
I'm
also
really
interested
in
figuring
out.
C
Are
there
ways
that
the
front
end
can
and
the
live
view
I
mean,
can
interact
with
the
back
end
and
say
be
used
as
a
toggle
or
control
for
for
for
things
that
you're
doing
on
the
computational
side?
So
like
could
you
drag
a
selection
of
data
points
in
in
a
data
visualization
and
then
have
it
spit
out
those
ids
in
the
in
in
some
atom
or
something
on
the
the
the
java,
the
job,
the
jvm
side?
C
So
for
things
like
that,
having
this
ability
to
register
live
views
that
are
different
from
what's
getting
compiled,
statically,
I
think,
is,
I
think,
is
valuable.
The
question
is
just
how
do
you
do?
That
is
skill
enough.
Do
we
want
to
plug
in
some
other
kind
of
closure?
Script
compilation
maybe
include
shadow
cljs
as
part
of
the
project.
C
So
I'm
interested
in
hearing
from
folks
on
that
the
next
is
how
to
optimize
the
ecosystem
compatibility
so
that
folks,
who
are
using,
say
clerk
or
clay
or
notespace,
or
I
mean
any
one
of
these
other
things
out
there
all
be
able
to
kind
of
share
their
work
right.
So
clerk
in
particular,
has
kind
of
a
very
different
assumption
about
like
what's
going
to
get
displayed
on
a
page,
and
I
think
for
good
and
for
bad
oz
has
been
kind
of
conservative.
C
In
that
you
know,
we
decided
early
on
that
there's
lots
of
things
that
you
might
be
playing
around
with
as
a
programmer
like.
If
you
just
type,
you
know,
range
you're,
gonna
get
an
infinite
sequence,
and
if
you
try
to
display
that
on
the
browser,
it's
gonna,
you
know
you're
gonna
get
a
crash
right,
and
so
our
approach
has
been
just
to
say:
okay.
C
Well,
we
don't
display
anything
unless
you
explicitly
ask
for
it
right,
whereas
the
approach
that
clerk
has
taken
is
we're
gonna
go
through
a
bunch
of
work
to
to
kind
of
paginate
through
a
data
structure
and
show
you
kind
of
the
head
of
it
and
if
you
wanna
see
more
we'll
kind
of
click
through
which
is
really
cool.
I
mean,
I
think
it's
really.
C
One
of
the
innovations
of
of
the
clerk
model
is
that
that
gets
you
this
system,
where
everything
you
type
in
your
code,
notebook
is
going
to
be
displayed,
which
is
one
less
step
work
for
someone
who's.
You
know
doing
data
science
and
kind
of
going
through
the
the
the
notebook
workflow
in
oz,
it's
kind
of
required
that
you
actually
say
like.
C
What's
going
to
get
displayed
in
your
output
documents,
I
think
has
has
some
value
for
creating
compatibility
between
tools
and
daniel,
and
I
have
chatted
a
little
bit
now
about
using
something
like
kindly
to
describe
what
kinds
of
documents
or
you
know,
input
or
output
types
you
might
be
working
with.
So
we
can
chat
about
that
a
little
bit
and
then
finally,
how
to
negotiate
dependencies
between
code
and
different
languages.
And
obviously
this
is
like
not
really
solvable.
C
But
if
we're
going
to
have
say
a
markdown
file
that
has
chunks
of
closure
code,
we
can
do
the
same
work.
We're
doing
right
now
to
analyze
that
closure
code
and
say:
okay,
well,
we're
defining
a
var
here,
and
this
next
block
of
code
uses
that
var.
So
clearly
it
depends
on
it
and
so
on,
but
it
if
you
sort
of
imagine
yourself
in
a
polyglot
scenario
where
you're
writing
some
closure
code
to
do
some
data
analysis.
C
You
actually
just
want
to
write
some
python
code
and
get
your
job
done
right
because
that's
what's
that's,
what's
easiest
for
you
to
do
or
you're
maybe
you're
working
with
people
who
are
more
comfortable
in
python
and
they
actually
just
want
to
plop
in
a
python
block
and
read
some
data
that
you
wrote
out
to
a
file
and
do
some
work
in
python.
That
way,
the
question
is:
how
do
we
decide
what
needs
to
get
run
before?
What,
when
you're
working
with
multiple
languages?
C
C
This
dependency
model
that
comes
out
of
the
analysis,
step
of
the
pre-processing
phase,
again
kind
of
going
back
to
to
this
to
this
slide
here
right,
if
we're
able
to
abstract
sufficiently
this
analysis,
you
know
requirement
and
dependency
now
phase
of
the
pre-processing
side
of
things.
Then
perhaps
we
can
come
up
with.
C
C
C
It's
definitely
my
goal,
that
oz
be
something
that's
extensible
and
that
you
can
really
use
in
a
lot
of
different
contexts
and
that
we
can
have
a
suite
of
tools
that
all
kind
of
interoperate
well
with
each
other,
not
just
in
the
oz
sphere,
but
that
you
know
oz
playing
nicely
with
projects
outside
of
that
space
or
that
is
to
say
in
in
kind
of
the
greater
closure
data,
science,
ecosystem
and
yeah.
So
I'm
excited
to
chat
with
folks
about
about
how
we
can
make
that
vision.
A
reality.