►
Description
00:00 Intro
00:35 Project updates
03:07 Conventions service intro and demo
29:48 Review outstanding RFCs
A
All
right
welcome
everyone
to
the
cartographer
community
meeting
slash
office
hours
today.
We
will
have
a
planned
session
covering
content
from
both
kind
of
sessions.
So
I'm
glad
that
you're
here
and
then
we'll
get
started
all
right
for
the
agenda.
I
will
be
the
note
taker
unless
you
have
an
objection
just
to
go
straight
to
the
content.
A
A
This
one
could
look
symbolic,
I
mean
which
is
a
new
project,
another
project
in
a
not
so
crowded
landscape
already,
but
but
the
reality
is
that
it
opens
some
doors.
I
mean
the
most
concrete
outcome
of
cartoon.
The
landscape
is
that
it
falls
into
the
scope
of
the
global
cncf
meetup
communities,
hundreds
of
meetups
around
the
world.
Their
scope
is
to
cover
the
projects
in
the
landscape,
so
that
opens
some
doors
and
one
of
those
doors.
We
we
have
our
first
talk
as
a
project
under
the
synthetic
landscape.
A
A
Yeah.
Thank
you
emily
and
thank
you
to
all
the
team.
I
mean
this
is
the
first
milestone
on
several
steps
that
we
need
to
take
towards
working
with
that
foundation.
This
is
great
all
right
and
next
up,
you
know,
as
you
probably
remember,
last
office
hours.
Scott,
you
know
share
briefly
about
how
the
conventions
controller
famous
convention
service
repo,
is
now
public.
It's
basically
a
new
open
source
project
that
now
lives
under
the
cryptographer
umbrella
and
scott
was
kind
enough
to
prepare
the
brief
intro,
especially
for
the
community.
B
B
I
share
yeah
thanks
so
just
to
set
context.
Everything
we're
talking
about
here
is
in
the
context
of
rfc.
I
guess
17.
This
was
numbered
before
the
rfc
process
changed,
so
I'm
not
sure
if
it
would
keep
that
number
what
going
forward,
but
this
is
what
the
pr
was
originally
opened
with
we're
basically
just
proposing
the
idea
of
hey
cartographer
is
great.
B
B
So
streep
is
available,
vmware
tanzu
cartographer
conventions.
If
you
want
to
go,
take
a
look
in
the
readme
there's
instructions
of
how
to
get
the
source
and
compile
it.
There
is
also
a
I
guess:
it's
not
actually
a
release,
but
there
is
a
a
build
that's
available
if
people
want
to
take
a
pre-compiled
binary
and
use
that
instead
might
not
be
the
easiest.
I
don't
know
if
we
have
instructions
about
to
actually
consume
this
yet,
but
we
can
sort
of
work
on
that
up
all
again.
This
isn't
a
real
release.
B
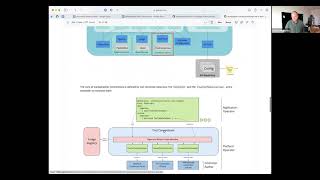
So
we
have
a
design
dock
that
describes
a
lot
more
of
the
details,
so
people
can
go
through
and
read
this
at
their
leisure,
fair
amount
of
overview,
but
the
things
I
really
want
to
call
out
are
just
sort
of
like
where
this
fits
in
in
the
grand
scheme
of
cartographer
and
don't.
I
need
to
recreate
this
diagram.
This
is
quite
old
at
this
point
and
not
what
actually
exists
within
cartographer
today.
B
But
the
general
notion
is
that
you
have
a
supply
chain
that
defines
a
bunch
of
resources
that
get
templated
out
and
then
one
of
them
is
this
pod
intent
resource
and
then
the
output
of
this
resource
gets
picked
up
and
put
into
the
final
resources
that
get
delivered.
So
everything
we're
talking
about
is
this
sort
of
within
this
red
box
and,
more
specifically,
what
we're
doing
is
we're
introducing
two
new
crds,
a
pod
intent
and
a
cluster
pod
convention.
B
So
basically,
the
focus
here
is
just
on
applying
conventions
to
essentially
pod
template
specs.
We
couldn't
spend
the
conventions
in
the
future
to
support
other
types
of
resources,
but
it
would
basically
be
a
new
effort
for
each
of
those.
But
basically
what
happens
is
that
the
pod
intent
resource
gets
defined.
Oops.
B
Inside
it
defines
a
pod
template
spec
and
then
the
status
of
it
gets
enriched
by
the
controller
and
emits
back
out
an
enriched
version
of
that
same
pod,
template
spec,
and
we
can
look
at
what
that
looks
like
a
little
bit
later
internally.
The
convention
server
is
basically
taking
this
pod
sample
spec
for
each
image
defined
within
it.
B
There's
ideas
about
sort
of
extending
that
to
have
sort
of
other
styles
of
defining
conventions
in
the
future,
so
you
don't
necessarily
have
to
have
an
http
server
running
in
your
cluster,
but
right
now
what
we
support
is
webhooks,
so
basically
calls
out
to
each
of
these
convention
servers.
Lets
them
enrich
the
pod
templates
back,
collects
that
aggregate
result
and
then
updates
the
status
so
that
cartographer
can
then
read
that
status
and
then
propagate
it
further
along
the
supply
chain.
B
B
And
then
similar
to
ydt
we're
also
kind
of
thinking
about
like
what
would
it
look
like
if
we
used
wasm
or
webassembly
to
do
that
same
logic?
Basically,
ydt
and
wasm
both
have
the
ability
to
run
arbitrary
code
safely
within
the
sandbox
like,
so
we
could
take
a
user's
business
logic
and
apply
it
inside
of
the
controller
safely,
as
opposed
to
right
now
we
have
to
do
a
web
hook
to
sort
of
maintain
isolation.
B
B
Basically
just
applies
well-known,
idioms
to
spring
boot
applications
when
it
comes
to
when
it
can
detect
and
discover
that
it
is
a
spring
boot
workload.
So,
basically,
I
have
an
image
here.
It's
in
my
own
docker
registry.
It's
basically
just
the
spring
pet
clinic
app
compiled
using
vacated,
build
packs.
So
nothing
too
fancy
about
it
other
than
just
the
version
of
the
kind
of
build
packs
that
built
it
support
s-bombs.
B
B
We
can
see
we
have
sort
of
our
same
spec
that
we
sent
into
the
server.
In
this
case
the
the
status
has
been
enriched
from
the
controller,
and
we
have
our
output
pod
template
spec.
That
has
a
whole
bunch
of
extra
information
encoded
into
it.
One
of
the
common
things
you'll
see
is
this
applied
conventions
annotation.
So
this
is
sort
of
a
list
of
all
the
annotations.
Sorry
of
all
the
conventions
that
were
applied
to
the
specific
pod
intent.
B
So
you
can
kind
of
see
what
the
system
is
doing
on
your
behalf.
So
in
this
case
have
a
dumper
convention
which
is
basically
just
logging,
the
the
raw
context
of
the
request
to
standard
out.
We
can
look
at
a
little
bit
later,
but
we
also
see
that
the
spring
sample
convention
was
doing
a
lot
of
things
so
like
it
detected
it
with
spring
boot
detected.
It
was
a
web
app
that
detected
that
it
had
the
spring
boot
actuator
installed.
B
It
detected
that
there
was
a
mysql
driver
and
it
detected
that
it
was
a
postcast
driver
and
what
this
actually
does
and
what
it
looks
like
and
what
it
can
start
to
do
for
you
is
start
to
apply
common
behavior
that
a
well-behaved
workload
on
kubernetes
like
should
define,
but
developers,
don't
always
remember
to
do
so
like
in
this
case,
a
couple
of
things.
It's
doing
is
it's
defining
liveness
and
writing
this
probes,
and
not
only
is
it
defining
these
probes,
but
it's
defining
a
probe,
that's
appropriate
for
the
workload.
B
So
in
this
case
it
knows
that
because
the
spring
grid
actuator
is
available
that
this
path,
actuator
health
liveness,
is
where
spring
mood
is
exposing
and
expecting
to
be
invoked
for
lightness,
cribs
and
then.
Similarly,
with
readiness,
the
path
is
a
little
bit
different
and
this
is
a
place
where,
because
the
convention
technologists
bring
boot
and
kubernetes,
it
can
sort
of
glue
these
two
things
together
and
apply
this
behavior.
B
B
B
So
in
this
case
we
see
like
the
actual,
build
pack
that
produced
this
s
bomb,
the
the
format
of
the
s
bomb
and
the
encoding.
So
this
is
a
sift
spawn
and
json
format.
There
are
others
that
will
probably
be
more
interesting
for
those
who
are
familiar
with
spring
boot
applications
I'll
just
copy.
This.
B
B
So
we
can
see
things
like.
Oh
there's
a
mysql
driver.
You
can
see
the
version
of
that
mysql
driver.
If
I
keep
looking,
we
should
see
spring
boot
and
spring
dependencies.
It's
basically
just
whatever
data
is
available.
Just
we
basically
collect
it,
pass
it
through
and
let
conventions
decide
what
to
do
with
that.
B
A
B
So
it
depends
on
what
perspective
you're
looking
at
at
what
time
so
effectively
the
pod
intent
defines
on
its
spec
a
template,
which
is
a
pod
sample
spec.
So
the
idea
is
that
would
be
created
by
cartographer
when
it's
stamping
out
the
pod
intent
resource,
then
the
controller
basically
applies.
All
the
conventions
takes
the
resulting
pod,
template
spec
and
updates
the
pod
intense
status
with
that
enriched
pod
template
spec.
B
B
B
So
these
things
are
applied
sequentially
so
that
the
the
sort
of
the
behavior
aggregates
and
then
that
resource
faux
resource
also
has
a
upon
temple
spec
on
its
status.
That
is
basically
the
enriched
version
of
the
pod
template
spec
coming
from
a
specific
convention
that,
then,
the
controller
sees
and
passes
off
to
the
next
convention
or
returns
on
the
status
of
the
platform.
All
right,
sorry
on
the
pod,
intent.
A
D
D
B
So
like,
if
so
in
addition
to
the
s-bombs,
just
there's
also
just
oci
metadata,
that's
available
so
or
you
can
also
just
base
conventions
off
of
the
pod
template
that
gets
injected.
So,
in
the
case
when,
like
there's,
really
like
nothing
interesting
in
the
ocean
metadata
and
there's
no
s
available,
so
it
depends
on
what
your
convention
is
doing
so,
like
we
have
another
sample
that
just
injects
an
environment
variable
it
doesn't
care
what
the
image
is,
doesn't
care
what
what's
going
on
it
just
blindly
injects
an
environment
variable.
B
B
It's
kind
of
a
very
dumb
approach,
in
terms
of,
like
it's
just
bluntly,
applying
to
everything
but
being
able
to
introspect
the
oci
metadata
being
able
to
introspect
the
responses
that
are
available.
Allow
you
to
have
greater
confidence
about
what
the
content
of
the
image
there.
So
it
allows
you
to
kind
of
create
more
precise
and
focused
conventions,
but
you're,
absolutely
right
that,
like
if
you're
using
different,
build
packs
within
the
cloud
native
bill
pack,
ecosystem
you'll
get
different
s-bombs
that
are
produced.
B
B
B
B
So
in
this
case,
what
it's
getting
is
both
the
the
pod
template
spec,
as
well
as
all
of
that
image
metadata,
so
it
can
sort
of
go
through
and
find
the
images
that
it
cares
about
and
then
sort
of
add
some
some
dependency
bomb
helpers.
That
sort
of
allow
us
to
sort
of
ask
questions
of
the
metadata
and
then
what
this
ends
up
actually
looking
like
in
practice
and
sorry
ignore
all
of
the
the
compiler
warnings.
B
This
is
a
nested
go
module
which
their
ide
doesn't
really
support
very
well,
but
we
basically
just
have
a
bunch
of
these
conventions
where
we
have
like
one
function
to
detect
whether
or
not
this
particular
convention
is
applicable
and
then
a
second
to
actually
apply
the
behavior
of
that
convention
so
like
in
this
case.
We're
basically
just
saying:
does
our
dependency
metadata
have
the
spring
boot
dependency?
Yes
or
no,
then,
if
it
does,
it
basically
just
sets
a
label,
an
annotation
saying
like
yep.
B
This
is
spring
boot,
and
this
is
the
versions
from
good
so
like
not
very
interesting
in
terms
of
what
it
does,
but
just
sort
of
sets
up
the
context
of
like
yes,
this
is
a
spring
boot
workload
like
we
know
it's
a
spring
boot
workload,
then
sort
of
getting
more
advanced
sort
of
just
like
there's
a
graceful
shutdown
so
like
the
kubernetes
graceful
shutdown
can
now
interact
with
the
spring
boot
graceful
shutdown.
Those
two
can
cooperate
and
have
an
understanding
of
each
other
when
the
spring
web
app.
B
B
We
can
do
things
like
knowing
that
actuator
is
installed
and
making
sure
that
the
management
endpoints
and
the
measurement
ports
are
set
up
appropriately.
Then
we
can
actually
define
probes
based
off
of
the
actuator
endpoints.
So
basically,
you
just
start
to
like
apply
all
these
logic,
and
I
don't
want
to
go
too
deep
into
what
this
is,
but
you
can
kind
of
just.
B
B
C
B
E
C
D
B
B
There
are
also
end-to-end
tests
using
github
actions,
so
we
basically
deploy
conventions
under
controller.
We
deploy
a
couple
of
the
actual
conventions
of
this
a
couple
sample
conventions.
We
create
a
pod
intent
and
then
we
basically
do
assertions
on
the
potential
just
to
make
sure
it
produced
the
expected
output.
B
B
A
Yeah
and
no
I
scored
I
I
this
confirms
my
suspicion
that
we
need
to
incorporate
the
conventional
controller
into
a
content
generation
plan
for
the
project
I
mean
talks,
blog
posts,
etc.
I
mean
I
feel
we
need
to
to
share
the
story
on
all
the
features
that
it
brings
to
the
project.
Thank
you.
Thank
you.
Scott
all
right
back
here
next
up
will
be
to
review
outstanding
rfcs,
so
I
will
start
from
left
to
right,
starting
from
introduction
for
new
rfcs
yeah.
We
should
oh
actually
yeah.
That's
exactly
what
yeah
I
know.
A
So
I
I
will
encourage
you
an
old
team.
Whenever
you
you
file
an
rfc,
please
add
it
to
the
rfc
project,
so
we
can
see
it
here
the
cards,
so
I
will
move
this
for
pending
introduction.
I
mean
then
the
introduction,
but
there
there's
already
a
long
discussion
and
the
thread
for
this
one.
So
I
don't
know
if
you
wish
you
might
want
to
provide
a
brief,
intro
update
on
this
specific
privacy
or
you
want
to
share
your
screen.
D
Yeah
we've
got
runables
and
I
have
twice
now
written
about
runnables
and
how
to
use
them
and
it's
complicated
in
part
because
first
you've
got
to
like
teach
people
like
here's
tecton
and
here's
how
takton
works
and
deckdown's
not
trivial.
And
then
it's
like
okay,
now
wrap
that
tech
down
thing
and
run
a
ball
and
then
wrap
that
roundabout
thing
in
a
class
in
a
carto
template.
D
And
so
this
proposal
is
to
leave.
All
of
that.
It
is
meant
to
be
additive
to
to
leave
all
of
that
behavior
in
place,
but
to
enable
users
to
cut
out
one
of
those
steps
that
being
that
users
as
they
when
they
get
started.
They
don't
need
to
define
their
own
runnable
that
you
could
just
put
a
flag
on
your
cluster
source,
template
and
say
this
is
meant
to
be
an
immutable
resource
and
cartographer
would
say.
D
And
then
yeah,
that's,
that
would
be
the
responsibility
of
the
workload
supply
chain.
You
know
technically
the
workload
controller
and
then
the
runnable
controller
would
do
its
job.
The
the
once
that
resource
is
created
cartographer
doesn't
need
to
care
much
about
it.
Although
there's
yeah,
you
would
need
to
know
how
to
how
to
read
the
outputs
off
of
that
runnable.
D
The
workload
controller
would
need
to
know
that
the
runnable
crd
exists
and
it
would
it
would
be.
We
would
be
encoding
logic
to
write
runnables
into
the
workload
crd.
So
that's
I'll
say
for
my
part,
because
testing,
because
I
see
testing
as
a
core
responsibility
of
a
supply
chain.
I
am
unconcerned
about
adding
that
knowledge
to
the
workload
controller,
but
I
think
it's
it
is
worth
pointing
out.
D
Yeah
there's
there's
some
details
in
here
about
how
exactly
there's
there's
an
example
here,
and
there
are
details
about
how
things
would
have
to
technically
work.
I
don't
know
if
we
necessarily
need
to
take
the
time
to
discuss
that,
so
I
will
pause
here
and,
if
folks
want
me
to
go
into
that
detail,
I'm
happy
to
do
so.
E
I
was
like
well,
I
don't
want
to
use
pipelines
I'll
just
run
I'll,
just
go
from
runnable
to
task
run
like
skip
the
whole
tekton
pipeline
concept
and
just
go
straight
to
task,
and
I
found
that
I
was
and
then
I
had
certain
situations
where,
like
like
the
default,
git
cli
task
from
the
text
on
catalog
didn't
have
all
the
inputs.
I
think
that
I
needed
so
I
had
to
modify
the
task
or
something
like
that.
E
E
I
went
through
the
process,
but
they're
done
at
a
higher
level,
and
so
I
was
trying
to
you
know
condense
things,
and
so
I
kind
of
went
a
different
way
and
found
that,
like
I
got
stuck
so
I
don't
remember
the
details
enough
to
ask
the
question
in
a
better
way,
but
if
you
know
there's
still
the
question
of
like
somebody
having
to
if
you're
writing
your
own
text
on
task,
maybe
it's
easier.
But
I
guess,
if
you're
trying
to
work,
I
don't
know
like
work
with
a
task.
E
D
D
E
It
was
complicated
because
then
I
yeah,
like
you
know
sometimes
the
answer
is
like
well
take
a
totally
different
approach
about
where
you're,
injecting
the
variables
like,
instead
of
putting
the
parameters
at
this
level,
actually
put
them
up
in
the
cluster
template
right.
So
you
have
to
really
just
say
this
is
the
right
place
to
do
it,
but
yeah.
D
I
I've
used
tekton
a
handful
of
times,
so
my
instinct
is
that
every
pipeline
and
every
task
should
list
out
here
the
prams
that
I
require,
and
so
once
once
you
get
familiar
with
that
with
that
specification,
you'll
be
like
oh
okay.
This
pipeline
says
perhaps
here
so
I
need
to
like
create
some
params
here
on
my
pipeline
run
and
then
the
thing
that
we're
trying
to
simplify
is
that
right
now
cartographer
asks
you
to
define.
D
D
You
have
to
like
say:
oh
I'm
going
to
have
this
cluster
run
template
that's
going
to
create
these
params,
and
then
I'm
going
to
have
this
or
sorry
I'm
going
to
have
this
runnable
that's
going
to
define
some
params
and
it's
going
to
pass
it
to
a
cluster
on
template,
and
then
the
cluster
on
template
is
going
to
pass
it
to
a
pipeline
run.
Another
fight
and
then
it
it
just
gets
into
just
the
tecton
stuff.
D
Where
techton
then
says
oh
I've
got
this
pipeline
run,
that's
passing
these
variables
into
the
pipeline,
and
so
we
can't
like
I
said
I
don't
have
a
hypothesis
of
how
to
protect
users
from
that
tecton
specific
level.
But
I,
but
knowing
that
that's
there,
I
want
to
simplify
the
number
of
levels
that
you
have
to
pass
it
through
on
the
cartography.
D
D
But
what
we'll
do
is
just
allow
we'll
just
let
you
hide
all
that
complexity
by
saying
like
hey.
This
is
an
immutable
thing
and
behind
the
scenes,
cartographer
will
be
programmatically,
stamping
this
out
in
part
because,
like
there's,
nothing,
there's
nothing
creative
about
going
from
this
to
this,
like
you
just
need
to
know
how
to
do
it,
and
so
it's
like
well,
we
know
how
to
do
that.
We
could
just
put
that
in
code
and
do
it
for
people.
B
B
D
D
Just
to
be
additive,
and
so
the
or
not
just
the
additive,
but
also
not
to
touch
like
there
are
no
implications
for
how
the
runnable
controller
does
its
work
here,
and
the
change
that
you
propose
is
a
change
to
the
runnable
controller.
So
I'm
not
yeah,
I'm
not
opposed
to
allowing
inline
template
templates
in
the
runnable
crd,
but
I
also
want
to
separate
out
that
proposal
from
this
one.
D
D
If,
if
we,
if
we
didn't,
think
that
that
was
an
advantage,
then
I
would
say
like
oh,
if
we're
talking
about
just
embedding
templates
directly
into
the
objects
like,
let's
just
allow
the
like
one
thing
that
we
could
do
is
say
you
know
you
put
this
flag
on
here,
that
it's
an
immutable
thing
and
and
then
you
just
don't
like
there's
no
runnable
right,
we're
just
like
we.
We
understand
that
we
are
going
to
stamp
out
some
object.
D
We
understand
that
it's
going
to
have
a
generate
name
instead
of
a
name
and
when
there's
a
change,
we're
just
going
to
create
a
new
one,
and
we
take
that
logic
that
right
now,
the
the
runnable,
the
runnable
controller,
is
doing,
and
we
just
embed
it
completely
into
cart.
The
the
workload
controller.
D
C
Yeah
I
like,
I
do
think
that
object
hierarchy
is
important
right
and
like
having
that
summary
object.
That
can
kind
of
you
know
aggregate
all
your
collection
of
immutable
objects
under
the
hood.
It's
really
nice
to
have
that
there,
because
you
know
it
gives
information
about
that
set
of
immutable
objects.
C
D
D
Those
would
probably
be
very
different
from
the
concerns
of
what
the
workload
would
want
to
report,
but
the
current
concern
that
is
reported,
which
is
just
what's
the
latest
good.
What's
what's
the
one
that's
going
to
pass
on
information,
that
seems
like
something
that
could
possibly
be
handled
by
the
workload.
E
E
D
I'm
curious
to
hear
what
other
people
have
to
say:
I'm
kind
of
indifferent
to
it.
I'm
like
yeah,
you
know,
write
your
supply
chain
as
you
as
you
want,
and
the
tutorials
are
there
to
kind
of
scale
you
up
in
terms
of
the
implications
of
some
of
those
choices.
But
there's
been
no
point
when
I've
felt
the
need
to
point
out
like
oh
here's
why
you
might
want
to
avoid
using
pipelines-
and
I
think
you
you
know
that
idea
like
cartographers-
should
know
everything.
That's
going
on
in
pipelines
are
going
to
hide
information.
E
D
Yeah,
I
would
say
I
have
a
couple
of
examples
that
do
first,
a
git
clone
and
then
do
some
sort
of
test
like
I
think
all
of
them
are
linting
tests
at
the
moment,
but
yeah
like
because
I'm
trying
to
write
like
the
simplest,
the
simplest
thing
from
the
cartographer's
standpoint,
which
is
just
like
hey
you've,
got
you
define
a
workload
and
then
you're
going
to
lint
it
and
then
you're
going
to
like
build
it
and
deploy
it.
So
it's
not
it's
not
leveraging
flex
cd.
E
D
D
D
D
Anyways.
I
bring
that.
I
bring
all
that
up
to
say
this
is
this.
Is
the
one
specific
thing
that
I
know
that,
like
oh
yeah,
we've
got
some
some
use
cases
of
runnables
that
are
defining
the
selector,
and
this
simplification
is
just
like?
No,
we
don't
right
now.
This
rfc
says
we're
not
going
to
do
that.
So
somebody
wants
to
step
up
and
say
like
we
should
absolutely
do
that.
Then
there's
more
work
to
be
done
on
this
rfc.
A
A
This
goes
the
two
blocks
with
the
technical
oversight
committee
so
again
try
to
well
the
conventions
rfc
it's
in
review,
so
maybe
I
was
to
move
it
under
the
regular
receipt
process,
looks
like
it
requires
a
couple
of
approvals,
additional
approvals
for
this
to
be
moved
and
yeah,
we'll
try
to
keep
the
discussion
going
on
the
thread
for
the
remaining
origins.
Please
any
question
comment.