►
From YouTube: Carvel Community Meeting - April 5, 2021
Description
Carvel Community Meeting - April 5, 2021
We meet every Monday at 11:30am PT / 2:30pm ET. This week's topics include project roadmap items for April, Issue #208 - Add per wait timeout, and backlog items to work on for the week. Full details here: https://hackmd.io/F7g3RT2hR3OcIh-Iznk2hw
A
A
If
you
have
anything
that
you
wish
to
discuss
while
attending
these
meetings,
please
add
that
to
the
agenda
down
here
at
the
discussion
topics
for
anything
that
we
don't
get
to
today,
we
will
move
those
to
our
carnival
office
hours,
which
are
held
every
second
and
fourth
thursday
of
the
month
at
11
30
a.m,
pacific
time,
2,
30,
p.m.
Eastern
time.
A
For
anything
that
you
know,
you
wish
to
also
bring
to
the
to
the
group
that
you
need
help
with
regarding
carvel,
we
invite
you
to
attend
those
office
hours
as
well,
and
the
maintainers
are
there
to
help
you
out
with
anything
that
you
need.
You
may
need
the
carpal
office
hours
will
be
held
next
time
for
this
week.
It'll
be
what
is
that
april
april
8th,
so
we
invite
you
to
join
us,
then,
as
well
as
well
as
every
monday.
A
B
B
C
B
B
So
maybe
we
can
move
through
the
updates,
then
helen's
planning
to
go
over
the
the
road
map,
so
maybe
we'll
skip
over
that
right
now
and
wait
till
helen's
able
to
join,
but
then
touching
on
the
other
things
that
we
have
going
on.
So,
as
mentioned,
the
recursive
bundles,
also
known
as
nested
bundles,
has
been
completed.
D
E
F
So,
every
month
we'll
try
to
kind
of
review
where
we
are
what
our
priorities
are
as
a
team.
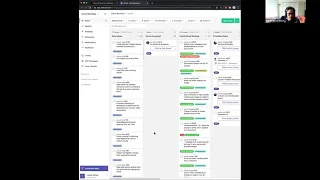
So,
if
you've
attended
a
community
meeting
last
week,
you
might
have
seen
this
diagram.
So
a
few
things
to
note.
We
have
different
tracks
of
items
here
and
whatever
that
is
like
filled
boxes.
Those
are
active
development
that
we're
coding
and
developing
the
things
that
are
outlined
are
things
that
we
are
either
identifying
the
problem
space
or
coming
up
with
a
solution.
F
It's
something
that
we
call
discovery
and
framing
space.
So
you
know
we
have
kind
of
pretty
much
two
tracks
of
work
going
on.
There
are
people
developing
they're
people
and
constantly
you
know,
discovering
and
exploring
so
that's
kind
of
like
the
two
things
to
highlight.
If
you
haven't
seen
this
last
month
and
each
of
the
boxes
have
relative
sizing,
you
know,
as
we
go
we'll
definitely
unearth
more
of
the
scoping
and
what
the
size
is,
but
these
are
kind
of
like
the
relative
sizing
of
different
boxes
and
the
priority
order
of
different
things.
F
F
We
are
going
to
prioritize
them
based
on
needs.
So
if
there
are
any
specific
cap
k
build
or
any
other
tools
that
are
not
these
three
at
the
top.
Please
utilize
the
feature
voting
capability
in
each
of
the
github
issues,
so
you
can
throw
a
thumbs
up
or
heart
or
smiley
emoji
in
each
of
the
issue
that
you
would
like
us
to.
You
know,
focus
on
and
prioritize
it
that's
one
way.
We
would
like
to
hear
your
feedback
and
your
opinions.
F
F
What
we're
currently
working
on
is
the
type
checking
piece
for
schema
and
we
think
it's
still
it's
a
quite
a
big
of
a
chunk
of
work,
so
we're
still
working
through
that
and
afterwards.
What
comes?
Is
this
notion
of
supporting
unannotated
yaml
as
data
values,
and
this
will
come
really
powerful
when
used
with
the
new
packaging
api
from
cap
controller,
so
that
as
you're
using
the
packaging
api
from
cad
controller?
F
You
know
you're
not
just
bound
to
using
ytt's
data
values,
but
you
can
bring
any
other
data
values
so
again
kind
of
following
our
unix
philosophy.
You
know
we
want
to
be
the
composable
tool.
We
also
want
to
be
able
to
allow
that
mix
and
match
of
different
tools.
So
that's
what
we're
focusing
on
and
afterwards
we're
going
to
work
on
supporting
open
api
schema.
What
we
mean
by
that
is
that
you
know
you
can
now
export
ytt
schema
into
open
api
schema
again
related
to
packaging
api.
F
This
gives
you
that
flexibility,
when
you're
leveraging
cap
controller's
packaging
api
you're
not
just
bound
to
using
ytt
schema,
but
you
can
bring
any
open
api
schema
and
you
can
do
validations
and
type
checking
and
all
that
we'll
be
continuing
on
the
schema
track.
Where
now
we're
gonna
do
validations,
so
it's
not
just
structural
type
checking
but
we'll
you
should
be
able
to
check,
validate
like
ranges
and
like
values
or
required
fields,
and
all
that
so
that's
what's
coming
cool.
I
won't
go
further,
there's
a
bit
more,
but
we'll
come
back
next
month.
F
Who
knows
things
shift
so
in
order
to
work
through
these?
You
know
development
track.
We
are
prioritizing
those
discovery
tracks
accordingly
and
yeah
for
image
package
track.
We
just
wrapped
up
recursive
bundles.
So
now
you
have
the
ability
to
create
a
bundle
in
a
bundle
in
a
bundle
in
a
bundle
for
eternity,
and
it
has
different
names.
I
think
in
their
tweet
we
said
nesset
bundles.
Basically,
it's
the
same.
That's
the
bundles,
recursive
bundles.
F
F
In
addition
to
that,
regarding
to
image
package,
we've
been
working
on
two
different
initiatives:
more
or
less
kind
of
lightweight
involvement,
but
we
wanted
to
involve
in
different
open
source
community
as
well
how
they're
doing
image
signing
so.
Some
of
our
members
have
been
going
to
notary,
v2
or
cosign
and
different
initiatives
to
kind
of
talk
about
what
is
the
future
of
image
signing,
so
we've
been
taking
spending
some
time
there
and
there
are
other
other
open
source
that
we
are
chiming
into
their
sigs
and
working
groups.
F
With
cap
controller,
the
teams
continue
to
building
on
the
expand
on
the
current
alpha
release
of
packaging
api,
so
hopefully,
sometime
in
the
summer
time,
the
team
is
hoping
to
release
a
ga
version
of
it.
So
the
team
is
constantly
working
through
it.
Feedback
is
much
appreciated
as
well.
The
alpha
release
is
out
there.
So
if
you
have
questions
about
it
or
concerns-
or
you
know,
need
improvements,
please
you
can
reach
out
to
us
either
through
community
meeting
open
office
hours
or
slack,
so
we're
all
ears
for
your
feedback.
F
G
Just
a
reminder:
this
is
the
last
week
for
comments
on
the
proposal
open
for
image
package,
the
renaming
proposal,
so,
if
you
haven't
had
time
just
go
through
it
I'll
add
I'll
edit
that
discussion
the
link
there.
I
forgot
to
do
that.
Just
look
at
it
see
if
it's
something
that
interests
you
just
go
through
it
see
if
there's
anything
that
is
strange
or
if
it
looks
good
for
your
use
case
and
if
not
just
comment
and
we'll
have
a
chat.
B
B
H
H
That's
the
idea
and
the
point
here
being
that,
at
the
very
least,
if
there's
some
kind
of
situation
where
you
want
to
use
schema
but
there's
a
greater
constraint
than
what
is
available
currently
in
the
set
of
types
that
we
support
to
be
able
to
to
somehow
maybe
turn
that
off
into
and
check
that
in
some
other
way
until
we
get
to
being
able
to
support
that
very
specific
type.
An
example
here.
E
H
So
this
way
that
you're
not
stuck
so
you
can
begin
using
the
feature
and
if,
for
some
reason
you
need
a
value
like
that,
you
can
tell
it
to
back
off
or
if
you
genuinely,
as
the
author,
don't
want
to
put
a
constraint
on
what
value
would
show
up
there.
Maybe
you
actually
don't
care
what
a
particular
value
is
under
a
key.
So
that's
the
spirit.
H
H
H
Okay
and
then
this
one
is
well.
What
do
we
mean
by
any
false
then
implied
in
this?
Is
that?
Well,
it
just
means
what
whatever
is
inferred,
so
one
reason
why
you
might
want
to
do
this
is
if,
for
some
reason
that
that
any
that
value
over
here,
the
boolean
for
that
value,
you
want
to
be
calculated.
So
maybe
you
want
to
turn
it
on
or
off
whether
or
not
you
want
that
to
be
dynamic.
H
H
H
H
E
I
think
this
is
great
that
last
note
at
the
bottom.
There
is
perhaps
interesting
just
that
arrays
must
continue
or
permeate.
The
schemas
must
continue
to
be
well-formed.
So
arrays
need
exactly
one
item.
You
can't
have
a
null,
so
we
don't
relax
any
constraints
on
that
we're
just
now,
once
your
schema
is
used
to
template
data
values,
then
the
data
values
will
not
complain
if
the
or
the
schema
will
not
complain.
If
the
any
keyword
is.
E
C
I
have
a
question
which
is
right
now:
the
types
of
these
data
values
are
inferred
through
the
value.
Is
there
anything
in
the
spec
or
future
roadmap
about
making
the
type
of
a
data
value
explicit,
like
data
values,
type
equals
string?
Is
that
something
we're
thinking
of
doing
in
the
future?
Yes,
okay,
then
how
it
like.
C
I
was
just
thinking
like
how
that
would
work
with
any
equals.
True
and
or
maybe
what
the
thoughts
were
around.
Maybe
using
a
super
class
like
you
know
the
any
type
like
type
equals
string
or
type
equals
any
instead
of
having
a
special
attribute,
n
equals
true
or
false
might
be
useful
for
other
people
watching
as
well.
I
don't
know.
H
That's
a
good
question
one
one
thing
to
note:
it
was
that
case
of
of
like
making
any
toggleable.
So
that
was
one
thing.
The
other
is
that
kind
of
philosophically
any
any
itself
is
in
some
conceptually
is
not
really
a
type,
it's
a
collection
of
types.
It
means
sort
of
everything,
so
that
sort
of
has
driven
that
this
is
as
opposed
to
a
special
keyword.
H
C
H
G
Because,
in
the
end,
oh,
my
god,
my
letters
are
awesome
now
that
I'm
noticing
it.
So
what
I
was
saying
is
that
currently
we
have
an
array
that
has
a
zero
on
it.
What
if,
inside
that
array,
we
had
this,
and
I
cannot
move
this
so
in
the
end,
where
you're
saying
that
foo
that
inside
of
this
any
you
need
to
have
a
food
that
is
an
int.
Is
this
like
what
what
should
happen
in
a
case
like
this.
E
G
G
H
G
G
G
E
H
Yep
to
put
a
finer
point
on
it,
that's
perfect,
stephen
and
to
put
a
finer
point
on
it.
If
you
attempt
to
try
and
put
an
annotation
on
a
collection,
let's
say
you
use
like
the
brackets
to
name
an
array
and
you
think
you're
you're
putting
an
annotation
on
top
of
that.
The
annotation
applies
to
the
first
element
in
that
array:
same
same
story
with
the
map.
If
you
try
and
use
the
flow
notation
for
yaml
and
you
try
and
annotate,
it
will
apply
to
the
first
item.
I
G
H
H
Else:
okay,
yeah.
I
guess
I
would
consider
stuff
like
that
to
be
something
that,
like
as
a
pair,
should-
let's
not
let's,
not
take
anybody
who's,
writing
a
story
as
the
authoritative
source
on
what
is
good
ux,
but
that
we're
all
responsible
for
that.
And
if
you
do
see
something
you're
like
this
is
not
feeling
great
like.
We
should
absolutely
like
we're
we're
all
shaping
this
together.
H
I
H
D
H
I
think
when
we
wrote
this,
the
documentation
story
was
ahead
of
this
one.
I
can't
remember
good
question:
if,
if
the
documentation
story
had
been
played
before
this,
then
this
is
additive.
Otherwise
we
could.
We
could
shift
that
to
the
to
the
one
story.
The
whole
point
was
to
sort
of
get
the
whole
feature
set
complete
because
we
knew
we
were
shifting
things
here
and
there,
okay,
cool.
H
H
H
My
schema
in
some
other
tool:
that's
using
open
api,
so
one
of
our
one
of
the
concrete
drivers
we
have
is
in
the
packaging
api
from
cap
controller
and
so
you're
able
to
actually
specify
the
schema
for
inputs
into
the
package
and
that's
in
this
open
api
format.
So
what
would
what
should
that
look
like?
What's
the
what's
the
command
line
feature?
Where
should
this
go
under
template?
H
Should
this
be
another
command,
or
something
like
that
so
taking
some
time
to
like
explore
different
options
and
come
up
with
a
proposal
around
that
and
then
the
other
thing
is
a
bit
of
a
gut
check
like
let's
go.
Take
a
look
at
the
open
api.
Spec
we've
done
this
in
the
past,
but
just
this
is
this:
is
a
kind
of
final
flight
check,
preflight
check
as
we're
writing
stories,
for
this
particular
feature
story
or
stories,
and
so
that's
it.
H
H
And
by
proposal
with
lowercase
p
like
really
this
is
this
is
not
about
like
go,
create
a
pr
per
se.
Whatever
is
appropriate
there
like
if
those
those
tend
to
be
when
there's
some
controversy
that
needs
to
get
worked
out
or
it's
large
enough
scope,
that's
a
big
impact.
This
could
be
something
you
capture
in
a
just.
Google
doc
or
in
an
issue
would
be
great
something
that
describes.
The
overall
feature
is
fine.
It
doesn't
have
to
be
heavyweight.
H
B
And
then
so
between
you
know,
ytt
schemas
that
explore
story.
The
next
things
in
the
backlog
would
start
being
some
of
these
kind
of
loose
items,
the
loose
github
issues
that
are
prioritized
already,
which
we
have
talked
about
in
the
past.
But
it's
been
a
little
bit
so
maybe
looking
at
a
couple
of
these,
does
anyone
have
any
questions
or
things
that
they
want
to
dive
into
right?.
B
D
C
C
Yeah
I'm
wondering
how
granular
so
when
we
say
change
it's,
we
create
a
resource
that
changes,
the
entire
creation
of
updating
a
resource
that
changes
just
the
updating
of
that
resource,
wondering
if
we
should,
if
we
want
to
continue
down
this
approach
like
whether
there's
value
in
I
expect
this
pod
to
not
take
any
longer
than
10
seconds
during
the
pod
initialization
phase
or
during
the
pod,
create
the
container
creation
phase.
I
wonder
if
we
should
be
that
granular,
not
just
30
seconds,
to
create
or
update
any
resource.
D
D
H
I
Yeah,
okay,
I
think
my
initial
thought
was
just
like
cap
already
creates
this
change
graph,
that,
like
sort
of
encapsulates,
encapsulates
everything
that
the
change
entails
and
just
defining
like
an
upper
bound
on
the
time
that
those
would
take
to
apply.
I
think
increasing
the
granularity
could
become
a
lot
of
configuration,
potentially
an
unwieldy
amount.
So
I
thought
this
was
like
a
nice
medium
of
like
okay.
I
H
Yeah,
I
don't-
I
don't
know
enough
about
it
to
to
pick
out
whether
or
not
you've
already
are
baking
into
this
request,
like
the
generalized
approach,
but
that's
kind
of
like
the
next
step
in
my
head
is
okay,
so
there's
this
feels
like
it's
describing
kind
of
a
specific
semi-specific
somewhere
in
between
situation
and
thinking
about
well.
What
mechanism
generally
would
solve
that
problem?
That
would
include
this
particular
scenario,
and
maybe
this
is
it.
Maybe
this
is
like
that
level
of
of
granularity.
G
G
It
is
deterministic
cool
okay,
so
that
that
would
not
be
a
problem
because
it
might
group
things
differently
in
some
sense
or
if
there's
already,
if
there's
already
things
installed
in
the
cluster,
it
might
not
need
to
install
anything.
So
the
dag
will
just
bypass
those
changes
without
doing
them.
So
in
the
end,
I'm
not
sure
like
if
the
granularity
should
be
at
the
node
of
the
dag
or,
if
or
on
the
group
of
changes
that
cap's
going
to
do
at
every
at
a
particular
point.
But
if
it
should
be
at
per
operation.
I
D
E
D
I
think
it
makes
sense
to
keep
them
both
since
someone
using
cap
may
not
know
how
many
changes
will
happen
when
they
deploy.
So
it
might
be
hard
to
calculate
like
perch
change,
timeout
times
the
number
of
changes
you
have
and
that
would
be
like
the
total
timeout
might
still
be
helpful.
To
then,
have
you
know
a
total
timeout
where
you
know
if
my
deployment
takes
longer
than
this
amount
of
time
definitely
should
fail.
H
Both
yeah
I'm
hearing
the
spirit
of
this
idea
is
to
to
fail
as
fast
as
possible
without
any
false
negatives,
so
that
would
that
would
make
sense
you're
like
look
regardless
of
what
happens
if
30
minutes
later
this
thing's
not
up,
I
don't
want
to
yeah
and
then
in
the
meantime,
there's
certain
things
that
I'd.
Rather,
if
this
thing
that
I
know
should
come
up
in
less
than
a
minute,
if
it's
been
more
than
a
minute.
C
Yeah,
like
just
variables,
like
you,
know,
you're
pulling
from
a
registry,
maybe
pulling
from
that
registry
just
takes
slower
and
in
a
certain
environment
versus
others.
That's
something
that
the
package
author
won't
have
any
visibility
in,
but
the
person
installing
has
a
better
sense
of
how
fast
things
are
on
their
data
center.
C
D
H
H
G
C
Well,
I
just
wanted
to
back
up
on
the
previous
point,
which
is
so
the
package
author,
like
communicating
that
a
module
that
the
package
author
is
distributing
like
how
currently,
how
can
they
broadcast
that
something's
going
wrong
during
installation?
Is
there
any
other
mechanism
or
tool
they
can
use
like?
I
want
to
create
a
deployment,
and
I
want
to
fail
fast.
It's
the
only.
Is
there
no
other
knob
option
they
can
pull
on
to
to
broadcast
that
you
know
this
deployment
is
just
not
deploying
correctly
because
of
xyz
other
you
know.
C
Are
there
any
probes
or
anything
else
that
could
potentially
use
to
fail
earlier
and
not
have
to
rely
on
time,
which
is,
I
think,
really
dependent
on
the
data
center
and
the
place
where
it's
really
running
like?
If
it's
missing
a
configuration
option,
do
we
have
to
just
wait
on
a
time
unit,
or
is
there
some
other
way
they
can
determine
whether
it
should
fail
early
or
not.
H
H
So
is
it
stuff
that,
if
you're,
if
you're,
actually
writing
the
controller,
that's
doing
the
reconciliation,
then
you
do
have
the
ability
to
catch
these
things
and
report
them
as
status
conditions.
But
if
you
don't,
then
you
don't
you
don't
have
that
ability,
if
you
don't
can't
affect
that,
so
it
it's
complicated.
I
think.
D
I
I
G
H
It
might
be
nice,
we
want
that.
Would
we
want
the
tool
to
quit
prematurely
prematurely?
I
mean
there's,
there's
some
some
broad
time
I
just
like.
Okay,
it's
just
like
I'm,
not
not
going
to
literally
wait
days,
but
I'd
be
a
sad
panda
if
things
were
just
taking
a
while
and
then
the
tool
quit
out
on
me.
H
B
G
G
A
Got
it
okay,
I
missed
that.
Thank
you,
okay.
Well,
then,
we
didn't
get.
We
didn't.
We
were
able
to
cover
everything
in
this
meeting.
So
there's
there's
nothing
from
this
particular
meeting.
That'll
be
moved
to
office
hours,
but
there
are
usually
discussion
items
that
come
from
the
next
few
days
and
we'll
add
them
to
the
office
hours,
but
we
highly
encourage
you
to
bring
anything
that
you
wish
to
discuss
or
if
there's
anything
that
you
need
help
with
from
the
maintainers
of
cargill.