7 Jul 2020
Purpose
Deep dive discussion on Velero restore hooks product requirements and design approach.
Documents
Product Requirements: https://github.com/vmware-tanzu/velero/pull/2679
Design: https://github.com/vmware-tanzu/velero/issues/2609
Deep dive discussion on Velero restore hooks product requirements and design approach.
Documents
Product Requirements: https://github.com/vmware-tanzu/velero/pull/2679
Design: https://github.com/vmware-tanzu/velero/issues/2609
- 6 participants
- 50 minutes

23 Apr 2020
In this new "Learn from our maintainer" series, Carlisia shows how quick the developer build/run/test workflow can be when you run the Velero server locally. She does a detailed (read long!) show and tell of how to setup this workflow. She starts from the beginning, from installing the Velero CLI and installing Velero in a local (Kind) cluster, and explains all the commands and flags as she goes along. She also explains and shows (almost) everything that happens in a Kubernetes cluster as the result of changes to code and to configurations as she switches to bundling code changes in an image and pushing it to a cluster. Octant 0.12.0 is highly featured in this demo!
- 1 participant
- 45 minutes
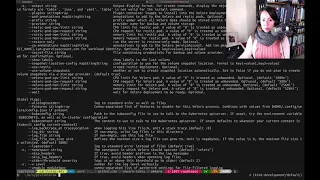
16 Jan 2020
In this session we discussed the upcoming removal of the current `velero install`, and what could substitute it. A more intuitive CLI UX is in the works. PR: https://github.com/vmware-tanzu/velero/pull/2202
- 3 participants
- 1:05 hours
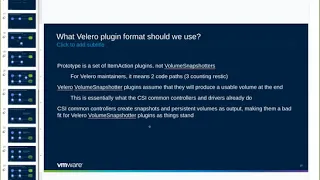
9 Dec 2019
Here is the recording of the meeting for our discussion of the Velero/CSI integration. Thanks to everyone who could attend.
The written proposal is at:
https://github.com/vmware-tanzu/velero/pull/1661
The summary slides are at:
https://docs.google.com/presentation/d/1QG0gu5Y9xiF6rjkqFgsOMOWMjSkj6Il18dNWKWRjipo/edit?usp=sharing.
The plan currently is to get the proof of concept plugins up to date with the v1beta types, get the design document merged, then ensure that the Velero core code base is updated to reflect necessary changes behind the `EnableCSI` feature flag - these changes will be communicated in release notes and blog posts when it's released. We'll also be giving regular updates during our community meetings.
The written proposal is at:
https://github.com/vmware-tanzu/velero/pull/1661
The summary slides are at:
https://docs.google.com/presentation/d/1QG0gu5Y9xiF6rjkqFgsOMOWMjSkj6Il18dNWKWRjipo/edit?usp=sharing.
The plan currently is to get the proof of concept plugins up to date with the v1beta types, get the design document merged, then ensure that the Velero core code base is updated to reflect necessary changes behind the `EnableCSI` feature flag - these changes will be communicated in release notes and blog posts when it's released. We'll also be giving regular updates during our community meetings.
- 3 participants
- 57 minutes
24 Jun 2019
In this demo we will show how to backup an application in one cluster and and restore it in another cluster.
Interested in the open source project Velero?
Check out https://velero.io!
Interested in the open source project Velero?
Check out https://velero.io!
- 1 participant
- 8 minutes

24 Jun 2019
How do you migrate an application running on Kubernetes between providers?
In this demo, we'll show how to move an application from AWS to GKE.
Want more info about the open source project Velero?
Head over to https://velero.io.
In this demo, we'll show how to move an application from AWS to GKE.
Want more info about the open source project Velero?
Head over to https://velero.io.
- 1 participant
- 6 minutes
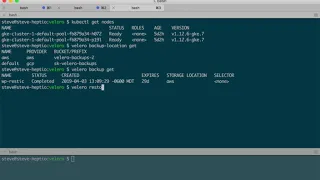
21 Jun 2019
Show notes: https://github.com/heptio/tgik/tree/master/episodes/080
00:00:00 - Welcome to TGIK!
00:04:00 - Week in Review
00:19:00 - Velero and why it was renamed from Ark
00:21:00 - Let's get started, starting with the docs
00:25:00 - Creating an S3 bucket & IAM Account
00:34:00 - Run velero install
00:38:00 - Install nginx example workload
00:48:00 - Take a backup using velero backup create
00:52:00 - Look at contents of backup
01:03:00 - Create scheduled backup
01:07:00 - Install velero into cluster 2
01:09:00 - Migrate nginx app from cluster 1 into cluster 2
01:13:00 - Roadmap
Come hang out with Joe Beda as he does a bit of hands on hacking of Kubernetes and related topics. Some of this will be Joe talking about the things he knows. Some of this will be Joe exploring something new with the audience. Come join the fun, ask questions, comment, and participate in the live chat!
This week we will look at Velero (https://velero.io). Velero (formally called Heptio Ark) is a backup and disaster recovery tool for Kubernetes. We've been working on this for quite a while and it recently hit 1.0.
00:00:00 - Welcome to TGIK!
00:04:00 - Week in Review
00:19:00 - Velero and why it was renamed from Ark
00:21:00 - Let's get started, starting with the docs
00:25:00 - Creating an S3 bucket & IAM Account
00:34:00 - Run velero install
00:38:00 - Install nginx example workload
00:48:00 - Take a backup using velero backup create
00:52:00 - Look at contents of backup
01:03:00 - Create scheduled backup
01:07:00 - Install velero into cluster 2
01:09:00 - Migrate nginx app from cluster 1 into cluster 2
01:13:00 - Roadmap
Come hang out with Joe Beda as he does a bit of hands on hacking of Kubernetes and related topics. Some of this will be Joe talking about the things he knows. Some of this will be Joe exploring something new with the audience. Come join the fun, ask questions, comment, and participate in the live chat!
This week we will look at Velero (https://velero.io). Velero (formally called Heptio Ark) is a backup and disaster recovery tool for Kubernetes. We've been working on this for quite a while and it recently hit 1.0.
- 1 participant
- 1:17 hours

4 Apr 2019
This is a recorded public webinar from April 4, 2019, where Steve Kriss and Tom Spoonemore presents Velero, shows how it's being used for Kubernetes backup and migration tasks, and includes live demos.
Check out Velero here:
https://github.com/heptio/velero
Join the Velero Community Meetings every 1st and 3rd Tuesday, details here:
https://github.com/heptio/velero-community
Check out Velero here:
https://github.com/heptio/velero
Join the Velero Community Meetings every 1st and 3rd Tuesday, details here:
https://github.com/heptio/velero-community
- 2 participants
- 43 minutes
15 Dec 2017
Disaster Recovery for your Kubernetes Clusters [I] - Andy Goldstein & Steve Kriss, Heptio
It’s 3am. Your pager is beeping. Your Kubernetes cluster is down. Don’t panic - we’ve got you covered. In this talk, we’ll describe a variety of disaster scenarios you may encounter. We’ll arm you with the knowledge you need to overcome them. Whether you’re a systems administrator, application developer, or end user, after this talk you’ll walk away with a thorough understanding of Kubernetes disaster recovery, including:
A disaster recovery overview
- Strategies for Kubernetes
- Comparisons to federation and high availability
- Which components to back up vs recreating from scratch
How to minimize your time to recovery
- Automate cluster creation and infrastructure configuration
- Back up and quickly restore your cluster applications, workloads, and persistent volumes using tools such as Heptio Ark
How to handle specific disaster scenarios
- Losing nodes
- Recovering from bad configuration updates
- Cloud provider outages
About Andy Goldstein
Andy Goldstein is an engineer at Heptio where he works on tooling to make operating Kubernetes clusters easier, and he also contributes to Kubernetes. Prior to his current role, Andy worked on Kubernetes and OpenShift at Red Hat. Andy lives in Rockville, MD, with his wife, two children, and two noisy cats.
About Steve Kriss
Steve Kriss is a systems engineer at Heptio working on building tools and products to help Kubernetes users be successful, and has been a contributor to upstream Kubernetes as well as a member of the Kubernetes release team in the past. Steve recently relocated to Seattle from New York and is still trying to find a good bagel.
Join us for KubeCon + CloudNativeCon in Barcelona May 20 - 23, Shanghai June 24 - 26, and San Diego November 18 - 21! Learn more at https://kubecon.io. The conference features presentations from developers and end users of Kubernetes, Prometheus, Envoy and all of the other CNCF-hosted projects.
It’s 3am. Your pager is beeping. Your Kubernetes cluster is down. Don’t panic - we’ve got you covered. In this talk, we’ll describe a variety of disaster scenarios you may encounter. We’ll arm you with the knowledge you need to overcome them. Whether you’re a systems administrator, application developer, or end user, after this talk you’ll walk away with a thorough understanding of Kubernetes disaster recovery, including:
A disaster recovery overview
- Strategies for Kubernetes
- Comparisons to federation and high availability
- Which components to back up vs recreating from scratch
How to minimize your time to recovery
- Automate cluster creation and infrastructure configuration
- Back up and quickly restore your cluster applications, workloads, and persistent volumes using tools such as Heptio Ark
How to handle specific disaster scenarios
- Losing nodes
- Recovering from bad configuration updates
- Cloud provider outages
About Andy Goldstein
Andy Goldstein is an engineer at Heptio where he works on tooling to make operating Kubernetes clusters easier, and he also contributes to Kubernetes. Prior to his current role, Andy worked on Kubernetes and OpenShift at Red Hat. Andy lives in Rockville, MD, with his wife, two children, and two noisy cats.
About Steve Kriss
Steve Kriss is a systems engineer at Heptio working on building tools and products to help Kubernetes users be successful, and has been a contributor to upstream Kubernetes as well as a member of the Kubernetes release team in the past. Steve recently relocated to Seattle from New York and is still trying to find a good bagel.
Join us for KubeCon + CloudNativeCon in Barcelona May 20 - 23, Shanghai June 24 - 26, and San Diego November 18 - 21! Learn more at https://kubecon.io. The conference features presentations from developers and end users of Kubernetes, Prometheus, Envoy and all of the other CNCF-hosted projects.
- 6 participants
- 35 minutes

14 Nov 2015
Want to view more sessions and keep the conversations going? Join us for KubeCon + CloudNativeCon North America in Seattle, December 11 - 13, 2018 (http://bit.ly/KCCNCNA18) or in Shanghai, November 14-15 (http://bit.ly/kccncchina18).
Clusters as Cattle: How to Seamlessly Migrate Apps across Kubernetes Clusters - Andy Goldstein, Heptio (Intermediate Skill Level)
Before the arrival of Cloud Native, IT departments frequently treated each component--a service/application, a virtual machine, or a bare metal server--as a special, fragile entity that required the utmost of care. Kubernetes, and more broadly Cloud Native, presents us with better ways to handle our infrastructure. For example, when we need to upgrade to a newer Kubernetes version, we can use automation and tooling to create a new cluster and migrate existing workloads over to it. In this talk, Andy will describe different strategies for moving workloads between clusters. He'll show you how to use tools such as Ansible and Kubeadm to quickly install a new cluster, along with Heptio Ark to back up one cluster and restore into a new one. Andy will also demonstrate how you can perform zero-downtime migrations using Envoy for cluster ingress, traffic shifting, and some DNS “magic.”
About Andy
Andy Goldstein is an engineer at Heptio where he works on tooling to make operating Kubernetes clusters easier, such as Ark, a disaster recovery tool for backing up and restoring Kubernetes workloads and persistent data. He is also a contributor to Kubernetes. Prior to his current role, Andy worked on Kubernetes and OpenShift at Red Hat. Andy lives in Rockville, MD, with his wife, two children, and two noisy cats.
Join us for KubeCon + CloudNativeCon in Barcelona May 20 - 23, Shanghai June 24 - 26, and San Diego November 18 - 21! Learn more at https://kubecon.io. The conference features presentations from developers and end users of Kubernetes, Prometheus, Envoy and all of the other CNCF-hosted projects.
Clusters as Cattle: How to Seamlessly Migrate Apps across Kubernetes Clusters - Andy Goldstein, Heptio (Intermediate Skill Level)
Before the arrival of Cloud Native, IT departments frequently treated each component--a service/application, a virtual machine, or a bare metal server--as a special, fragile entity that required the utmost of care. Kubernetes, and more broadly Cloud Native, presents us with better ways to handle our infrastructure. For example, when we need to upgrade to a newer Kubernetes version, we can use automation and tooling to create a new cluster and migrate existing workloads over to it. In this talk, Andy will describe different strategies for moving workloads between clusters. He'll show you how to use tools such as Ansible and Kubeadm to quickly install a new cluster, along with Heptio Ark to back up one cluster and restore into a new one. Andy will also demonstrate how you can perform zero-downtime migrations using Envoy for cluster ingress, traffic shifting, and some DNS “magic.”
About Andy
Andy Goldstein is an engineer at Heptio where he works on tooling to make operating Kubernetes clusters easier, such as Ark, a disaster recovery tool for backing up and restoring Kubernetes workloads and persistent data. He is also a contributor to Kubernetes. Prior to his current role, Andy worked on Kubernetes and OpenShift at Red Hat. Andy lives in Rockville, MD, with his wife, two children, and two noisy cats.
Join us for KubeCon + CloudNativeCon in Barcelona May 20 - 23, Shanghai June 24 - 26, and San Diego November 18 - 21! Learn more at https://kubecon.io. The conference features presentations from developers and end users of Kubernetes, Prometheus, Envoy and all of the other CNCF-hosted projects.
- 1 participant
- 35 minutes
