►
From YouTube: WebPerfWG call - September 24 2020
Description
No description was provided for this meeting.
If this is YOUR meeting, an easy way to fix this is to add a description to your video, wherever mtngs.io found it (probably YouTube).
A
A
A
They
should
let
you
know,
or
yes,
yeah
I'll,
basically
we'll
have
some
skeleton
agenda
and
then
we'll
send
it
to
the
list
and
folks
could
comment
and
pylon
ideas
on
that,
okay,
cool
and
with
that
we
can
probably
get
started.
We
don't
have
a
ton
of
open
issues
discussed
today,
but
at
least
one
of
them
seems
to
be
a
hefty
one.
So
we
can,
we
can
take
our
time
and
discuss
it
in
depth.
Nick,
do
you
want
to
take
on
yeah.
C
And
honestly,
so,
just
before
we
dive
into
that
too,
I
did
want
to
mention
that
we've
had
two
weeks
worth
of
hackathons
now
over
the
last
two
tuesdays.
Thanks
to
everybody,
that's
helped
participate
in
those.
I
think
we've
done
a
lot
of
good
stuff.
I
know
you
had
shared
a
list
of
all
the
things
we
accomplished
on
the
first
one
and
we
all
made
a
lot
of
good
progress
last
tuesday
as
well.
So
I
think
for
anybody
else,
that's
interested
at
all.
C
We
love
the
help,
but
you
know
I
think,
as
a
group
we're
doing
a
good
job
kind
of
pushing
a
lot
of
things
forward,
so
yep,
okay,
so
the
thing
that
I
wanted
to
bring
up
actually
came
from
some
of
the
from
the
first
hackathon
turned
out
to
be
a
little
bit
bigger
than
even
I
expected.
So
this
is
navigation
timing
issue
128.
C
C
C
C
C
C
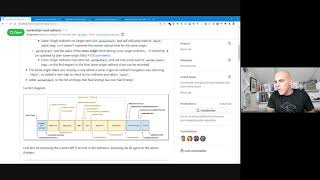
Some
code
review
feedback
suggests
we
may
want
to
make
it
a
little
more
obvious
that
the
worker
start
time
should
happen
before
fetch
start
definitively
within
the
diagram.
So
we
could
either
kind
of
move
worker
start
up,
and
this
little
arrow
could
be
before
fetch
start
or
we
could
have
a
whole
phase
right
here,
like
a
new
phase
which
is
called
worker
or
something
just
to
make
it
more
obvious
that
there's
a
period
of
time
between
service
worker
startup
and
when
the
fetch
happens,
and
that's
your
kind
of
service
worker
startup
time
any.
D
C
C
The
worker
phase,
that
was
worker
startup
period,
completes
yep
and
that's
what
we
do
have
locked
into
our
processing
model
right
now,
like
that's
how
we
describe
it,
but
obviously
it'd
be
helpful
to
have
a
visual
representation
of
that
okay,
so
that
one's
relatively
low
controversy.
I
think
one
thing
that
we
do
today
or
that
we
were
talking
about
is
the
workers
start
itself
is
actually
well
there's.
There's
a
bug
in
the
processing
model
that
I've
attempted
to
fix,
where
we
were
in
the
case
of
redirects.
C
So
let's
say
your
navigation
redirects
to
a
crossover
cross-origin
domain
and
it
comes
to
a
final
resting
place.
The
worker
start
time
was
actually
reflecting
the
cross-origin
origins
service
worker
if
it
had
any
and
not
the
final
origin,
and
if
you
had
to
redirect
the
final
origin
was
always
zeroed
out
or
sorry.
If
you
had
same
origin
redirects,
it
was
always
zeroed
out.
So
there's
just
a
bug
in
the
processing
model
that
this
pull
request,
attempts
to
fix-
and
you
can
kind
of
take
a
look
at
that
if
you'd
like.
D
A
C
Potentially
well
so
so
that
steps
into
the
other
potential
change.
That
was
that
we
were
going
to
propose,
which
is
that,
in
the
case
of
multiple
redirects,
the
service
worker
startup
time
would
always
be
the
first
request
of
the
last
same
origin
redirect
chain
right.
So
if
there's
multiple
same
origin
redirects
at
the
end,
it's
the
first
request
of
that,
because
that's
when
the
service
worker
should
be
starting
up.
C
If
there's
only
one
thing
at
the
end,
it's
just
the
last
resource.
I
think
you're
you're
explaining
an
even
more
edge
case,
which
is
where
we
hop
over
to
the
last
origin,
but
then
half
away
then
hop
back,
and
in
that
case,
does
the
service
worker
get
die
down?
Does
it
start
back
up,
it
would
seem
to
me
like,
according
to
the
proposal
we
would,
it
would
probably
be
a
zero
millisecond
service
worker
startup
time,
because
that's
the
startup
time
of
the
last,
the
first
request
in
the
last
same
origin
redirect
chain.
C
A
E
C
Well,
the
the
redirects
are
currently
protected
by
the
same
origin
check
and
the
same
origin
check
says
if
the
previous
origin
and
the
current
origin
are
different,
they
must
be
zero
and
if
there
are
any
redirects
to
another
origin,
they
must
be
zero.
So
it's
even
more
aggressive
than
worker
start
like
it
says.
If
there's
any
redirects
that
happen
anywhere
off
origin,
those
must
be
zero.
No
matter
what.
E
E
C
We
yeah
potentially,
that
I
guess
that's
the
proposal
here
is
that
at
the
end
there
you're
staying
all
you're
staying
on
the
same
origin,
no
matter
what
the
the
problem.
I
I
think
the
problem-
I
don't
know
if
it's
problem,
but
maybe
if
you
if
we
set
redirect
start,
for
example,
to
be
the
first
redirect
of
the
last
name
origin.
C
C
So
I
think
I
think,
if
we
were
to
like
try
to
set
redirect
start
to
be,
you
know
my
same
origins,
timings
it.
It
potentially
gets
us
into
territory.
Well
then,
what
do
you
have?
The
redirect
count
be?
Is
that
zero,
or
is
that
just
reflective
of
the
final
origins,
and
is
that
confusing
to
people
that
know
that
there's
other
redirects
off
origin
redirects
on
that
chain,
yeah.
A
E
G
Yeah,
I
have
a
question
here
regarding
the
this
box
in
between
redirection,
app
cache.
So
workers
start,
if
understood
correctly,
can
mean
two
things
either.
If
the
search
work
is
up
and
running,
it
will
be
the
the
time
before
the
fetch
or,
if
it
not,
it
will
be
the
time
that
the
thread
actually
started
right
right.
G
G
E
C
G
C
So
let's
say,
let's
actually
just
use,
let's,
let's
get
rid
of
cross
origins
here,
let's
just
say
you
navigate
onto
the
same
domain
and
then
you
end
on
the
same
domain.
So
there's
just
one
or
I
guess.
Let's
say
you
navigate,
you
start
off
domain.
You
start
on
the
search
result.
Page
you
hit
the
first
page
on
the
domain,
then
that
redirects
to
the
second
page,
they
both
have
a
service
worker.
The
in
that
case
the
worker
start
would
be
the
beginning
of
the
first
same
origin.
C
A
C
E
A
downside
of
the
proposal
where,
if
we
preserve
redirects
in
the
sort
of
more
aggressive
way
that
it
is
today
but
have
workers
not
be
that
way,
then
there's
a
confusing
overlap.
I
mean,
on
the
one
hand,
I
guess
we
I
don't
know
if
we're
saying
that
we
regret
the
way
we
did
redirects,
I
don't
know
but
like
if
we
want
to
start
exposing
things
on
the
same
origin,
but
do
it
on
one,
but
not
the
other.
That
is
confusing.
C
Both
for
consistency,
you're
saying
it
should
just
be
the
worker
startup
time
of
the
final
document,
not
the
beginning
of
the
requests
in
the
last
chain
yeah.
So
in
that,
in
that
case,
you
would
never
be
able
to
if
you,
if
you
have
a
document
series
that
has
a
service
worker,
you
would
never
be
able
to
measure
the
service
worker
startup
time,
but
in
the
other
way
we
wouldn't
really
be
able
to
either
because
the
redirect
would
be
included
in
that
service
worker
startup
time.
A
Yeah,
but
I
mean
in
that
scenario
service
worker
will
delay
like
you
still
need
to
take
that
service
worker
startup
time
into
account,
because
it
will
potentially
delay
like
unless
we're
talking
about
navigation
preloads,
which
are
a
bit
unique
in
that
sense.
But
otherwise
the
service
worker
is
in
the
critical
path
and
will
delay
you.
So
you
probably.
C
Even
if
it's
all
same
origin
redirects
because
worker
start
would
actually
be
at
the
beginning
of
this
redirect
phase
in
that
case,
and
then
you
would
have
all
your
redirects
and
you
don't
have
a
worker
end.
So
you
don't
know
the
actual
startup
time
of
the
worker.
You
know
the
startup
time,
plus
the
redirect
phase
together
and
you
can't
separate
the
two
out.
B
C
A
So
at
some
point
I
think
during
the
hackathon
we
talked
about
maybe
splitting
the
redirect
phase
into
cross-origin,
redirects,
right
or
potentially
cross-origin
redirects
and
the
full
chain
of
same-origin
redirects
that
led
to
the
for
service
workers.
If
we
had
a
service
worker
before
then
like
during
the
cross-origin
phase,
like
you
know,
cross-origin
same
origin,
cross-origin
kind
of
hop,
it
would
still
be
in
the
critical
path,
but
we
won't
be
able
to
measure
it
yeah.
A
C
Yeah
I
mean
like
a
search
result,
page
that,
like
pings
itself
back
to
the
search
engine
and
then
redirects
to
the
final
page
once
or
twice
it
could
be.
You
know
I
don't
know
yeah
anyway.
I
guess
now
that
we've
talked
about
it.
I'm
not
like
I'm
kind
of
sad
that
worker
start
would
not
be
useful.
In
any
case,
if
there
are
any
redirects
makes
me
sad.
E
E
C
We
deal
with
this
as
well
with
the
akamai
impulse
data,
where
we
have
a
couple
names
for
these
phases,
like
that,
we
commonly
think
that
they
are.
You
know
like,
even
though
here
it's
called
app
cache
builders
like
that,
there's
also
like
a
head
of
line
blocking
kind
of
phase.
Sometimes
that
can
happen
based
on
the
timestamps
that
you
got
and
stuff
like
that.
C
A
A
G
B
F
No,
I
mean
I,
I
think
that
thanks
timo
for
answering
the
question
about
the
gaps
and
nick
kind
of
for
adding
in
a
little
bit
there,
I
thought
that
was
productive.
I
mean
I
feel
like
we
still
maybe
are
kind
of
inching
towards
the
metric
being
worker
start
time
instead
of
workers
or
like
we
want,
like
a
workers
startup
time
instead
of
work
or
start,
so
I'm
just
gonna,
I'm
just
gonna,
throw
that
out
there.
I
don't
really
have
ideas,
but
it
feels
like
that's,
maybe
a
little
bit
more.
C
B
C
Yeah
yeah,
thanks
for
bringing
that
up
honestly,
like
I
haven't
squared
away
all
these
changes
with
how
it
would
affect
the
actual
resource,
timing,
spec
and
stuff
there,
so
I
can
make
sure
to
keep
them
in
sync.
Obviously,
okay
work
to
be
done.
I
will
summarize
everything
that
we've
discussed
here
tag
the
people
that
have
been
talking
and
we
can
continue
talking
in
the
issue
or
elsewhere.
Thank
you.
B
B
B
You
won't
get
the
buffers
anyway,
so
just
spin
it
up
with
entry
types
and
pass
on
the
entry
that
you're
interested
in,
but
it's
basically
kind
of
unergonomic
and
also
requires
exception
handling
which,
from
what
I've
heard,
some
developers
are
not
entirely
comfortable
doing
that
in
a
production
code,
which
is
a
little
surprising.
But
then
we
basically
don't
have
a
solution
for
this.
B
I'm
also
not
sure
how
how
how
much
we're
expected
to
provide
all
this
support
for
exposing
how
how
supported
the
parameters
within
that
single
method
are
right
because
there's
also
like
we
could
just
go
all
the
way
like.
Oh,
this
is
important.
This
is
important,
but
then
it
becomes
really
spammy,
maybe
as
well
the
api
anyway.
So
I
was
curious.
What
other
people
here
think?
Basically,
if
there
are
people
that
have
experience
trying
to
use
the
buffered
flag,
whether
it
has
been
a
painful
experience
or
whether
they
think
the
status
is
okay
or.
C
B
Yeah
so
because
the
the
parameters
are
inside
a
dictionary,
I
believe
a
user
agent
that
does
not
support
type
will
zero
if
it
does
not
find
entry
types
which
will
be
the
case
if
you
just
pass
type
and
buffered.
So
it
will
just
say:
oh,
you
didn't
pass
entry
types
and
I
expect
it
will
throw.
Although
I
didn't
verify
this
probably
should
like
say
in
firefox
or
safari,
I
think
currently
it
will
throw
if
you
try
to
observe
with
type
and
buffered.
A
H
Yeah,
well
something
for
for
the
rest
of
the
group.
I've
touched
on
that
briefly
during
the
hackathon,
basically
for
kind
of
a
reference,
something
that
can
show
us
the
tricast
way
that
probably
nicola,
which
mentioned,
is
also
one
of
the
proposed
ways
to
do
feature.
Detection
for
the
passive
event
listener
attribute,
like
it's
kind
of
pretty
old,
and
also
there
you.
H
Repository
which
is
basically
the
feature,
detection
pattern,
so
there's
already
discussion
there.
It's
pretty
long.
I
haven't
done
my
research
on
that
discussion,
but
there
have
been
like
some
some
arguments
going
on
for
a
couple
of
years:
oh
okay,
to
be
honest,
yeah
and
four
years
that
seems
super
relevant
yeah
yeah.
It's
exactly
what
we
have
been
discussing.
H
E
I
suppose
I
can
share
anecdotally
in
in
using
I've
only
used
this
api
once
so
far,
but
I
did
make
the
mistake
that
I
did
have
a
track.
Try
catch
on
the
buffered
version
and
then
didn't
have
another
try
catch
for
the
regular
version,
because
that
would
also
need
a
try
catch
for
different
browser
support
and
for
how
the
types
go
back
as
well.
So
I
definitely
plus
one
on
the
ergonomics.
E
D
A
Cool
so
who's,
who
wants
to
take
an
ai
to
dig
into
the
like,
whereby
yale,
107
and
see
where
that
landed.
The
issue
is
still
open,
so
it's
likely
that
the
answer
is
nowhere,
but
still
it
would
be
interesting
to
not
rehash
that
discussion
because
it's
been
going
on
for
the
last
four
years.
Apparently.
B
A
A
Measure
svas
other
than
user
timing,
so
they
basically
want
us
to
reset
all
the
start
of
navigation
observers.
At
least
that's
my
reading,
but
maybe
nicholas
and
michael,
do
you
have
like?
Do
you
think
we
should
just
fold
this
into
the
broader?
We
need
to
measure
sbas
or
is
there
something
more
than
that
here.
I
I
I
do
think
it
it's
just
deserving
to
be
folded
into
the
broader
definition,
so
it's
more
than
just
resetting
of
observers
and
re-reporting,
because
it's
not
apples
to
apples
what
gets
reported
during
page
load.
So
I
think
nicholas
commented
that
for
at
least
layout
instability
you
can
you
have
full
control
over
doing
something
like
that,
like
you
can
reset
your
counters
and
accumulate
per
route
and
stuff
like
that,
so
the
existing
api
already
works.
I
I
I
I
Hopefully,
network's
all
right,
my
last
sentence
was
just
on
input,
delay
and
event.
Timing.
One
difference
is
that
there's
a
a
minimum
threshold
for
event:
timing
for
subsequent
events
after
the
first,
whereas
if
you
really
wanted
to
reset
after
a
spot
transition,
you'd
want
to
have
a
like
zero
minimum
threshold.
So
that's
the
one
thing
for
at
least
input
delay
that
you'd
want
to
be
able
to
reset.
A
C
A
A
B
So
I
was
doing
a
tag
review
for
has
dropped
entry,
which
is
in
case
people,
don't
remember.
It
is
basically
a
parameter
for
the
callback
of
the
performance
observer
where
it
tells
you
whether
the
observer
is
observing
an
entry
type
for
which
the
buffer
has
become
full
and
one
entry
has
been
basically
dropped
from
the
buffer,
which
means
basically
you've
lost
some
data
on
that
observer.
B
F
B
B
I'm
being
petty
or
has
a
buffer
overflow
right
to
make
it
grammatically
correct
yeah,
but
I
mean
that
that
was
the
feedback.
We
got.
Oh
and
I
guess
one
question
that
just
came
up.
If
you
have
the
callback
and
let's
say,
there's
a
user
agent
that
supports
only
the
previous
callback
and
then
you
pass
the
callback
that
has
that
additional
parameter.
Will
that
cause
issues
or
is
the
parameter
just
ignored?
I
don't
know
enough
javascript
to
know
the
answer.
A
It's
ignored
unless
they,
so
typically,
you
can
look
at
the
args
and
I
think,
like
at
some
point
they
will
be
undefined.
So
unless
someone
explicitly
checks
like
the
case
where
it
will
break,
is
if
someone
explicitly
checks
that
arguments
that
didn't
exist
are
undefined
and
do
something
in
that
case.
B
B
C
C
A
F
B
Comment
that
in
the
tag
review
and
basically
their
their
complaint,
was
that
it's
not
as
accurate,
because
it
implies
that
it
has
only
dropped
a
single
entry
which
I
don't
really
agree
with,
because
it's
just
does
there
exist
an
entry
that
has
been
dropped.
Not
has
it
dropped
exactly
one
entry
but
anyway
that's
what
they
said
so.
A
Yeah,
maybe
we
could
we'll
add
the
issue
like
yeah.
We
we
can
have
that
discussion
in
the
like,
with
the
tag
reviewers
themselves
and
yeah,
but
I'm
yeah.
The
association
with
buffer
overflow
is
not
not
great
and
it
will
cause
confusion
so
yeah
we
we
can
continue
to
negotiate
something
but
yeah.
If,
like
do
you
have
a
link
like
a
handy
link
to
the
tag
review
that
you
can?
I
I
just
posted
it.
Yeah.