►
From YouTube: App Runtime Deployments Working Group [May 12, 2022]
Description
No description was provided for this meeting.
If this is YOUR meeting, an easy way to fix this is to add a description to your video, wherever mtngs.io found it (probably YouTube).
A
A
A
So
here
in
the
chat,
this
is
the
storyboard
chris
has
provided
us
a
gcp
account
thanks
for
that
that
yeah
worked
like
a
charm,
and
now
we
yeah
have
a
new
account
or
project
where
we
can
set
up
everything.
So
far,
things
run
quite
smoothly,
but
well
we
may
we
are
already
hitting
you
know,
hitting
the
first
problems,
and
maybe
we
have
to
ask
reuben
for
assistance,
but
nevertheless
it's
also
a
good
practice
for
refreshing
kubernetes
know-how.
B
A
B
A
B
A
B
D
C
C
C
A
B
B
I
think
on
the
last
one,
the
challenge
is
going
to
be
the
time
zone,
overlap,
figuring
out
how
we
we
can
coordinate
that
we
may
have
to
to
say:
okay,
we
will
actually
schedule
the
timers
okay,
we're
going
to
kind
of
release
here
and-
and
maybe
you
know,
we
have
to
figure
out
okay.
What
features
need
to
be
there
which
c,
which
component
bumps?
B
Are
we
waiting
for
if
anything
or
we're
just
going
to
take
whatever's
on
release,
candidates
and
say:
okay,
we're
cutting
all
these
from
that
make
sure
that's
ready
to
release,
but
I
think
that
would
be
better
to
actually
shed
you
all
the
time
and
say:
okay,
yep,
say
friday
morning
or
well,
that's
hard,
because
that's
the
end
of
week
for
you,
so
I'm
not
sure
friday
evening
is
great.
We
may
have
to
circle
around
and
say
like
tuesday
mornings
or
something,
but
it
all
depends
on
on
your
availability.
A
B
D
B
B
I'm
not
sure
yet
that's
one
of
the
questions.
I
need
to
ask
them
because
with
bionic
I
had
a
pipeline
here,
but
I
could
apply
it
to
all
the
instance
groups
and
it
was
just
a
case
of
validating
that
everything
worked
which
by
and
large
it
did
so
I
I
don't
know
whether
they
in
the
short
term
but
planning
on
having
a
pipeline
here
to
test
it,
while
it's
it's
fairly
unstable
or
what
they're
thinking
there
I'll
I'll
start
up
her
because
they
they
reached
out
to
me
through
vmware
channels.
B
Generally
speaking,
we've
never
done
maintenance
branches,
yeah,
we've
just
rolled
forward
to
whatever
the
the
new
versions
are,
and
if
someone
needed
to
to
revert
back
to
something
older,
they
can
craft
their
own
ops
files.
For
that,
that's
the
beauty
of
of
cf
deployment.
Anyone
could
craft
an
ops
file
to
to
make
any
change.
They
need
to.
A
B
B
B
A
B
A
A
B
B
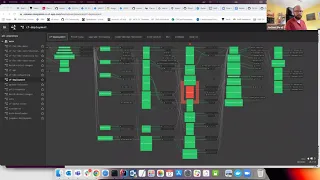
So
the
way
this
works,
if
you
go
back
to
the
the
main
pipeline
view.
Yes,
every
time
a
new
cf
deployment
is
released,
it
triggers
all
the
way
on
the
left
there
and
it
will
actually
redeploy
a
long-lived
environment
with
the
new
version
and
then
every
time
cats
runs,
on
the
right
hand,
side
that
the
two
boxes
in
in
parallel
there
and
it
then
triggers
bless
cats.
B
One
of
the
things
that
that
does
is
it
creates
a
branch
on
cf
deployment,
with
the
version
that
that
environment
is
deployed
with
okay,
the
last
successful
deployment,
the
last
successful
run
of
cats
was
against
cf
deployment
19..
And
so,
if
you
look
in
here,
you
should
see
that
the
branch
that
it
created
well,
this
one
this
one
doesn't
get
to
run
the
the
van
cats.
So
we
need
to
there's
a
problem
with
what
looks
like
an
internal
certificate.
B
Getting
an
error
about
the
certificate
that
cloud
control
the
internal
cloud
control
is
set
that
is
being
specified,
so
I'm
not
sure
whether
that
just
means
that
the
app
needs
to
be
updated
to
ignore
the
validity
of
the
search
or
whether
there's
something
we
can
do.
It
seems
hard
to
provide
the
ca
used
to
create
cloud
controllers,
internal
search
to
the
application,
because
that
would
mean
I
would
have
to
go
into
the
diego
trust
store.
B
A
B
B
B
Yes,
the
test
in
the
test
they
chose
to
try
and
make
a
request
to
a
10
dot
ip
address
which
was
denied.
Then
they
added
the
dynamic
asg
that
it
worked.
Then
they
removed
it
again
and
confirmed
that
it
didn't
work,
and
I
think
it
was
just
the
fact
that
they
chose
to
use
the
internal
address.
They're
like
okay,
well,
try
and
talk
to
power
control,
whether
there's
a
better
alternative.
I'm
not
sure.
C
B
B
So
I
know
we
have
like:
we
have
the
cf
deployment
project,
but
then
we
also
have
the
working
group
project
and
there's
also
I
I
would
imagine
I
think
I
created
a
cats
project
when
I
was
before
the
working
group
was
was
formed.
I
think
there's
a
a
repo
specific
project
for
cats
as
well.
If
you
go
over
to
the
projects
tab,
I
think
yes.
A
A
D
C
D
Have
an
automation
where
all
the
issues
and
prs
of
all
the
different
projects
gets
an
aggregated,
because
that
that
makes
it
easier
to
get
an
overview,
and
otherwise
you
would
need
to
look
through
20.
Okay.
Our
working
group
here
is
pretty
small,
but
the
infrastructure
working
group
or
the
interfaces
working
group.
They
have
50
plus
projects
and
then
it
doesn't.
D
B
D
A
Yeah,
I
think
using
issues
to
to
track
tasks
and
stories
is
a
good
idea.
I
already
tried
this
automation
from
ruben
with
the
better
projects
and
I
think
I
did
not
manage
to
aggregate
all
the
single
projects
we
have
into
one
I
can
try
again
and-
and
we,
as
many
already
mentioned,
the
disadvantage
is
that
you
cannot
create
notes
here.
So
you
have
to
use
then
issues
and
requests
to
track
every
piece
of
work.
Yeah.
A
A
A
A
A
A
A
B
So
if
you
open
up
the
task
for
bosch
deploy,
if
you
scroll
down
it's
all
near
the
bottom
boss
deploy
cf
develop,
then,
if
you
scroll
past
all
of
the
upload
releases
output,
you'll
see,
we
have
a
tool
here,
this
yeah
it's
called
up
timer
and
this
basically
tests
app
availability.
So
we
have
a.
We
push
an
app
before
the
upgrade
starts
and
it
gets
polled
consistently
during
the
upgrade
to
make
sure
that
the
app
is
available.
B
B
Oops
then,
interspersed
in
here
you
will
start
to
see
failures
so
like
this
is
recent
log
failures
and
then,
if
you
go
all
the
way
to
the
bottom,
you'll
see
a
summary
of
how
many
failures
there
were
so
up
a
little
bit.
This
is
like
the
cleanup
output,
so
there
should
be
a
table
right
here
here
that
green
section.
It
will
tell
you
how
many
requests
it
made
during
the
upgrade
and
how
many
failed.
A
A
D
B
B
So
if
we
look
at
that
same
section
here,
this
was
pretty
much
the
entirety
of
so
that
that
went
from
17.1,
which
means
that
it
was
upgrading
to
what
became
18..
So
if
we
go
down
and
look
at
bosch,
deploy
cf
develop
again,
which
is
near
the
bottom
and
just
scroll
all
the
way
to
the
bottom.
So
we
saw
zero
app
availability
failures.
We
saw
one
push:
failure.
B
B
C
A
C
B
B
B
D
We
ran,
we
ran
into
the
same
trap
with
our
standard
tests
and
yeah.
So,
but
that's
maybe
something
we
could
at
least
put
on
on
the
task
list
to
to
think
about
whether
we
want
to
have
one
test
that
runs
on
a
let's
say:
landscapes
that
is
scaled
out.
Don't
know
what
that
means
for
the
costs,
so
we
should
have
here
then
a
temporary
landscape.
That
is
not
a
long
living.
One.
B
Yeah,
I
mean
all
of
these
environments
other
than
cats
are
temporary.
That's
why
it
does
the
deploy
the
latest
release
and
then
deploy,
develop
and
then
tear
everything
down
again
so
yeah.
We
could
definitely
do
something
as
long
as
we
have
a
gcp
project
or
aws
or
whatever
we
choose
to
run
it.
That
has
the
capacity
to
to
spin
up
more
vms.
You
know
I,
I
don't
think
it
would
be
hard
to
set
up.
C
A
B
A
A
B
A
A
C
D
B
B
D
D
B
D
D
Or
something
like
that?
Okay-
maybe
that's
another,
just
yeah
it
has
to
plan-
I
mean
it's,
it's
not
really
urgent.
We
can
do
it
also.
You
know
manually
if
we
get
the
s3
key
somewhere
and
then,
but
that
would
be
something
that
comes
up
basically
after
every
security
scan
and
you
can
do
whatever
you
want.