►
Description
Setting up networking for one Kubernetes cluster can be a challenge but it becomes even more fun once you add multiple clusters into the mix.
In this talk we’ll go over the solutions that RVU (Uswitch) came up with to allow their applications to talk between clusters and the rationale behind them, from building their own tools like Yggdrasil for multi-cluster ingress to implementing other tools such as Cilium for multi-cluster services.
We’ll see what benefits and drawbacks the different approaches can have and also explore why we opted to avoid using a traditional service mesh to achieve our multi-cluster networking goals.
A
B
B
Necessarily
so
far,
I
at
least
share
with
you
what
we've
done
and
what's
worked
for
us.
So
what
hasn't
worked
for
us
in
some
cases,
yep
so
leave
a
bit
of
context.
I
work
in
a
team
known
as
airship.
We
provide
a
platform
for
the
developers
that
work
at
rvu.
We
build
that
common
infrastructure
common
tooling.
That
kind
of
thing
to
take
away.
The
management
from
from
teams,
so
they
can
focus
on.
Actually
you
know
developing
websites
and
stuff,
not
worrying
about
machines
or
patching
or
how?
B
How
am
I
going
to
get
metrics,
how
many
logs
etc?
That's
kind
of
our
job?
To
do
that,
however,
things
weren't,
always
this
way
back
in
the
older
days
of
rvu,
all
the
teams
used
to
run
their
own
infrastructure
themselves,
which
was
a
mix
of
all
sorts
primarily
running
in
aws,
but
you
know
some
would
just
be
standard.
Ecd
machines
might
be
like
ecs
clusters,
some
people
were
using
puppy,
ansible
to
provision
machines,
etc.
It
was
up
to
the
individual
teams
and
we
decided
as
an
organization.
B
It
would
be
more
valuable
if
we
consolidated
on
one
platform
instead
of
having
all
these
teams
managing
themselves,
which
is
where
my
team
was
formed
so
slowly
over
time
we
moved
everyone
over
to
a
set
of
kubernetes
clusters
as
kind
of
base
infrastructure,
but
when
this
happened,
this
created
a
slightly
new
dynamic
that
was
new
to
the
company
of
we're
now
all
running
on
the
shared
infrastructure,
and
we
don't
necessarily
have
control
over
it
and
what
happens
when?
Inevitably,
you
know
that
infrastructure
breaks
right.
B
C
B
So
we
needed
something
to
sit
in
front
of
kubernetes.
To
do
this.
For
us
and
one
of
the
first
things
we
found
while
looking
around,
was
a
project
called
envoy.
This
is
a
project
by
lyft,
it's
a
cncf
graduated
project
and
it
does
all
the
kind
of
things
you'd
expect
from
a
modern
proxy.
It's
lightweight
it
can
do
health
checks,
retries,
load,
balancing,
etc.
B
One
of
the
things
we
were
particularly
interested
in
was
its
ability
to
do
dynamic
configuration,
so
it
has
a
api
which
you
typically
communicate
with
by
grpc,
and
you
can
use
this
to
like
load
the
config
into
it
in
a
very
dynamic
fashion.
So
so
these
all
seem
like
good,
good,
good
attributes
for
a
proxy
to
solve
this
problem
for
us,
so
our
first
pass
and
what
this
looked
like
looks
roughly
like
this,
so
we
had
a
envoy
cluster.
It's
like
a
cluster.
B
We
had
a
envoy
sat
in
front
of
our
kubernetes
clusters
and
it
had
some
configuration
in
it
which
told
it
which
service
was
running
in
which
cluster
effectively,
so
it
knew
that
our
main
energy
comparison
service
was
running
in
one
cluster,
maybe
two
clusters,
whereas
our
credit
card
service
was
running
in
in
the
other
two
clusters,
and
it
would
have
this
configuration,
and
so
it
knew
where
to
read
the
traffic
when
it
came
in.
It
would
also,
you
know,
handle
health
failure.
B
B
Static,
it
was
a
giant
yaml
file
that
we
had
full
of
envoy
configuration,
which
I
don't
know
if
you've
looked
at,
is
not
the
the
most
attractive
to
write
yourself.
But
you
know
if
a
developer
wanted
to
add
a
new
service
or
if
they
wanted
to
change
what
cluster
their
service
was
running
in
or
say
it's
now
running
in
free
clusters
or
whatever
they
had
to
you
know,
raise
the
pr
we
had
to
redeploy
the
infrastructure
and
whatnot,
so
it
wasn't
the
most
easy
thing
to
do
so.
B
We
thought
there
must
be
a
better
solution
to
this.
We
alluded
to
earlier,
there's
a
dynamic
configuration,
but
how?
How
do
we
get
this
configuration
and
we
we
looked
at
the
ingress
object
that
already
exists
in
the
cluster
as
a
source
of
inspiration.
So
on
the
left
we
have
ingress
resource,
it's
a
kind
of
standard
generic
one,
it's
an
ingress.
B
It
has
a
host
and
a
port
and
the
status
which
is
normally
added
by
your
cloud
provider
or
whatever
is
doing
lingerie
behind
the
scenes,
which
includes
the
kind
of
address
of
what
what
things
should
hit
the
english
on.
And
if
you
look
on
the
right,
we
have
a
small
snippet
of
a
much
larger
envoy
configuration
and
you'll
find
there's
a
lot
of
there's
a
crossover
right.
B
So
how
do
we
give
it
to
it
and
that's
where
we
built
our
own
thing
as
it
didn't
seem
to
be
anything
that
did
this
for
us,
so
we
built
a
tool.
It's
called
aggressive
after
the
north
tree
of
life
that
connects
the
many
rounds.
We
have
a
norse
naming
convention.
Please
look
up
north
mythology
if
you
want
to
work
here,
but
we
we
built
this,
it's
open
source
on
github.
B
If
you
want
to
peruse
it
your
own
ledger,
it's
just
built-in
go
and
it
acts
as
a
kind
of
mix
of
a
controller
and
it's
a
mix
of
like
a
kubernetes
controller
and
an
envoy
control
plane.
So
what
it
does
is
it
goes
and
watches
various
kubernetes
clusters
for
ingress
resources
and
based
off
these
ingress
resources.
It
translates
that
into
envoy
configuration
and
sends
over
to
our
envoy
cluster.
So,
for
example,
if
you
have
an
ingress
in
one
cluster,
you
also
will
pick
that
up
and
configure
one
for
it
to
be
there.
B
So
this
was
a
nice
and
easy
way
to
allow
people
to
come,
get
the
benefits
of
envoy
without
really
needing
to
even
know
about
it,
because
from
all
a
developer's
perspective,
is
they
just
create
an
ingress
object
in
one
cluster?
They
create
another
cluster
envoy.
Does
the
raspberry
or
gets
configured
for
them?
They
don't
need
to
worry
about
that
detail.
They
just
use
ingress,
which
is
a
fairly
common
standard,
object
that
everyone's
familiar.
A
B
And
yeah,
and
it
gave
us
the
advantage
of
yeah
if
the
cluster
goes
down,
for
example,
it
will,
as
alluded
to
it,
will
move
the
traffic
to
the
ones
that
are
working
based
off
health
checks
and
whatnot.
This
was
a
good,
a
good
like
first
start
some
reliability.
I
guess
for
our
clusters,
especially
in
the
early
days
of
using
kubernetes.
This
was
more
more
frequent
than
I
wanted,
but
what
we
realized
we
had
done
here
was
we
had
accidentally
created
some
kind
of
service
mesh,
see
it.
B
It
soon
became
apparent
to
our
developers
that,
instead
of
going
between
clusters
going
through
envoy,
was
a
very
efficient
or
easy
way
to
connect
to
our
internal
services.
So
they
could
talk
to
each
other,
and
this
started
to
become
a
de
facto
way
of
kind
of
cross-cluster.
Communication
was
to
go
through
envoy,
because
you
know
it
always.
It
always
knows
where
the
service
is,
and
it
will
always
root
you
to
where
it's
healthy.
B
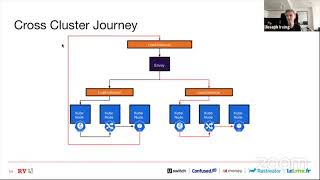
So
this
is
a
kind
of
like
slightly
zoomed
out
detailed
look
of
what
this
might
look
like
if
we
view
a
request.
So
if
you
first
look
at
the
black
line
here,
this
is
like
a
standard,
let's
say
user
request
from
a
website.
It
goes
through
to
envoy.
It
hits
some
load
balancers,
it's
a
node,
it's
like
proxy
to
an
ingress,
pod
or
something
and
then
finally
ends
up
in
an
actual.
You
know
application
pod,
that's
serving
the
website
or
something.
C
B
The
biggest
legacy
in
the
world,
but
once
you
add
up
quite
a
lot
of
these
hops,
they
can
become
significant
enough
to
be
a
problem,
and
it's
also
one
of
the
other
key
things.
That's
losing
something
you're
losing
identity.
By
doing
this,
by
going
out
of
a
cluster,
then
back
into
a
cluster,
it's
hard
to
distinguish
whether
this
is
kind
of
like
service
to
service
traffic,
whether
it's.
B
That's
this
load
of
network
traffic.
So
if
you
want
to
use
things
like
kubernetes
network
policies,
things
like
that,
it
all
becomes
a
lot
more
difficult,
so
yeah,
so
with
the
advantage
of
it
being
easy
to
use
and
envoy
was
also
doing
a
lot
of
the
hard
work
for
you,
but
the
disadvantage
of
we
were
getting
this
extra
latency
and
this
lack
of
identity,
which
we
could
be,
could
make
life
very
difficult
for.
So
we
thought
we
probably
need
a
better
solution
for
this.
B
This
wasn't
the
original
intent
of
our
thing
and
the
the
obvious
place
we
looked
to
was
some
kind
of
service
mesh
right
that
service
mesh
can
do
this
kind
of
stuff.
So
we
started
a
journey
of
exploring
a
variety
of
the
service
meshes
that
were
out
and
about
at
the
time,
with
a
few
key
features
that
we
were
interested
in
the
primary
one.
As
is
the
topic
of
this
talk
was
multi-cluster
services.
You
know
it
had
to
be
able
to
do
across
cluster.
B
That's
so
pretty
important,
the
second
one
which
might
be
nice
to
have
of
something
we
were
quite
kind
of
the
idea
around
real
real
inverted
commas.
Pod
eyepiece-
and
when
I
mean
real,
I
mean
the
pod
ip
of
your
pods
is
the
same.
It
comes
from
the
same
cider
that
your
your
vpc
is,
for
example,
so
you're
not
using
like
a
virtualized
network
you're
using
real
little
polyps,
and
this
allows
you
to
you
can
do
stuff
like
it
can
simplify
networking.
You
can
do
something
like
you
know.
B
We
actually
do
like
bbc
flow
logs
on
your
pods
or
things
like
this.
It's
that
it
can
make
life
easier
and
third
and
father
and
in
some
ways
the
most
important
was
it
had
to
be
easy
to
add
to
our
existing
stack.
We
didn't
want
to
have
to
rethink
how
we
did
everything
to
be
able
to
use
this.
This
was
a
fairly
small
feature
we
wanted.
We
didn't
want
that,
to
you
know,
change.
B
Code,
for
example,
to
take
advantage
of
this
feature,
especially
as
the
current
way
was
so
easy.
How
would
we
convince
people
to
use
it
if
the
new
way
was
much
more
difficult?
So
we
went
out.
We
we
reviewed
a
load
of
service,
meshes,
I'm
not
gonna
like
pick
on
all
of
them
by
names
or
anything.
So,
but
we,
we
reviewed
a
load
of
them
and
we
found
some
common
problems
across
across
the
ones
we
did.
Look
at
a
big
one
was
didn't
support.
Multicluster,
especially
when
we
looked
at
this.
B
There
were
a
number
they
just
didn't
support
it,
so
that
was
that
that
was
a
non-starter
second
was
a
few
of
them
were
quite
quite
complicated
and
had
quite
a
lot
of
additional
features
we
weren't
interested
in.
They
were
doing
a
lot,
whereas
we
needed
only
a
fairly
specific
thing
and
the
added
overhead
of
operating
these
services
didn't
seem
worth
it
compared
to
what
we
were
actually.
A
B
A
B
Which
is
you
have
your
standard
pod?
You
have
your
application
containers
into
the
zed
pod
and
you
that's
what
we
have
a
sidecar
container
that
runs
alongside
this,
that
does
all
the
networking
stuff,
so
it
often
might
terminate
tls
it.
Does
the
service
discovery
et
cetera,
but
there
were
a
few
key
problems
with
this
that
that
stopped
us
from
progressing
much
further,
one
of
which
is
they
didn't
work
in
the
in
it
phase.
B
If
you
have
any
containers,
they
wouldn't
be
able
to
use
a
sidecar
container
and
there's
often
complications
around
the
startup
shutdown
of
your
body.
Let's
say
you
know
your
application
containers
start
before
your
sidecar
containers
you,
you
might
have
some
strange
network
shenanigans
going
on.
We
lose
quality,
fun
jobs,
cluster
in
our
clusters,
and
we
we
found
that
they
would
forever
forever
hang
because
the
side
cars
wouldn't
know
to
terminate
when
the
job
was
finished.
Now
these
are
all
generic
problems
to
side
cars.
B
A
lot
of
service
measures
that
use
this
kind
of
approach
have-
and
I
know
over
the
years
there
have
been
more
and
more
workarounds
to
to
fix
some
of
these
problems,
but
they
do
cause
complications
and
don't
work
in
every
scenario.
So
we
found
this
to
be
slightly
undesirable
at
the
time.
So
after
looking
for
all
of
these,
we
found
a
new
project
that
we
were
familiar
with.
B
That
seemed
to
fix
a
lot
of
our
things,
and
that
was
psyllium,
so
cilium,
developed
primarily
by
a
temporary
surveillance,
currently
is
in
the
process
of
becoming
a
cncf
project.
I'm
still
in
voting,
I
believe
so.
I
won't
preempt
the
result,
but
yeah
it
should
be
a
scentsy.
Thank
you
very
project
soon,
hopefully,
and
that's
some
key
things
we
liked
a
lot
one
was
it
ran
as
a
demon
set?
It's
not
it's,
not
a
traditional
service
mesh,
it's
more
of
a
cni.
A
B
Pods
of
your
applications,
it's
just
running
on
each
node.
It
supported
real
eyepiece.
It
does
that
using
aws
elastic
network
interfaces
in
adress,
specifically,
that
does
also
support
them
in
other
clouds.
I'll
talk
about
that
has
a
feature
called
cluster
mesh,
which
was
the
you
know,
the
main
thing
we
wanted
it's
the
custom
s
is
a
way
of
networking
between
kubernetes
clusters
using
celium
and
some
well,
maybe
just
a
cool
thing,
but
it
also
does
everything
using
a
technology
called
ebpf.
B
C
A
C
B
B
A
B
B
Application
but
yeah
this
is
how
psyllium
does
it
specifically,
but
more
interesting,
perhaps
was
how
it
handles
services.
So
on
the
left
here,
we've
got
a
kubernetes,
node
and
and
cilium's
running
on
it
and
on
the
right
here.
We've
got
just
a
standard
kind
of
generic
service
in
kubernetes,
where
you
have
a
name
and
you
have
like
a
cluster
ips,
a
pretty
standard
way
of
doing
a
service
in
queue,
and
you
have
two
parts.
C
B
Are
associated
with
that
service
they
match
your
selectors
etc,
and
then
what
psyllium
does
behind
the
scenes
slightly
simplified?
But
what
it's
doing
is
it's
writing
some
bpf
rules
which
associate
that
cluster
ip,
which
is
just
a
virtual,
fake
ip
with
those
pod
ips,
and
it's
writing
them
into
the
kernel,
in
which
case
the
two
pods
shown
here
similar.
B
Does
with
ip
tables
and
that's
how
it
just
works
for
standard
service?
Simple,
not
not
much,
nothing
too
crazy
here,
but
what
you
can
then
do
with
cilium
is
you
can
expand
this
to
cover
multiple
clusters?
So
if
I
have
the
same
service
in
cluster,
a
let's
say,
and
then
the
service
again
in
cluster
b
and
cilium
will
realize
it's
the
same
service
in
both
clusters
and
we'll
just
compile
the
rules
to
forward
to
any
of
the
ips,
regardless
of
what
cluster
they're
in.
So
you
just
get
this
list
of
rules.
B
C
A
B
Know
if
the
pods
aren't
ready
or
not,
they
won't
come
up
as
ready,
endpoints
and
wouldn't
be
added
to
this
list.
So
that's
a
nice
bonus
for
that
yeah,
and
this
is
very
simple
because
it
means
you're,
not
there's.
No
there's
no
complicated
shenanigans
going
on
from
the
app's
perspective.
It
just
hits
the
service
as
it
would
normally,
and
it
now
has
just
more
options
of
where
to
go.
I
can
now
go
to
a
different
cluster
as
long
as
that
ip
address,
you
know
it
is
rootable
and
well
not
to
that
part.
B
And
this
is
what's
the
best
part
about
psyllium
is
this
is
a
normal
service
definition
kubernetes
and
the
only
thing
that's
different
about
this
service,
which
is
the
psyllium
service
that
can
go
across
cluster?
Is
this
annotation
here?
It's
added
an
annotation
of
global
service
truth,
and
this
was
enabled
for
your
service.
You
do
that
and
you
need
to
ensure
that
the
service
is
deployed
in
any
cluster
which
you
want
to
access
the
service
from
as
well.
You
need
the
kind
of
address
for
your
your
pods
to
hit.
C
B
There's
no
there's
no
going
around
in
and
out
et
cetera,
is
actually
talking
from
one
ip
address
to
what
I
another
ip
address,
and
it
does
it
all
kind
of
without
even
needing
to
know,
what's
going
on
so
that
that
was.
That
was
how
we
solved
that
problem
and
as
well.
Not
only
are
we
avoiding
this,
you
know
latency
ad,
for
example,
we're.
B
We're
now
doing
it
from
pod
to
pod
and
psyllium
is
aware
of
what
pods
are
talking
to
what
pots
yeah.
We
are
still
maintaining
all
the
pod
identity
in
this
scenario.
So
if
we
want
to
apply
security,
security
rules
find
like
network
policy
and
stuff
it
all
works,
we
can
use
our
pods
labels,
services
etc.
For
this
to
work,
which
is
which
is
nice
if
you're,
if
you
need
to
do
that
kind
of
thing
now,
we
found
once
we'd
done
this.
It
was.
B
It
started,
become
very
easy
to
like
link
an
arbitrary
number
of
kubernetes
clusters
together
as
well,
we're
primarily
in
aws,
so
something
we
took
advantage
of
which
we
hadn't
used
before
was
aws,
is
a
transit
gateway
feature
for
those
not
familiar.
Transit
gateway
effectively
allows
you
to
simplify
peering
connections
between
between
vpcs
and
significantly,
whereas
in
a
traditional
aws
setup
you
might
have
had
to
peer
all
your
clusters
together
in
this
kind
of
complicated
web
of
peering
connections
with
transit
gateway.
B
You
just
add
that
to
each
vpc
and
then
the
you
know
it
works
like
a
hub
and
spoke
in
the
network.
Traffic
can
just
flow
from
one
cluster
to
another
cluster
and
vice
versa,
as
long
as
the
route
tables,
security
rules
etc,
correct.
This
should
just
work.
So
if
we
wanted
to
create
a
new
cluster
and
add
it
to
the
mesh,
we
just
you
know
spin
it
up,
attach
it
to
the
translate
gateway
and
tell
him
about
it,
and
then
the
networking
just
just
works.
B
So
this
was
this
was
nice
and
then
easy
much
much
preferable
to
connections.
If
you
have
done
a
lot
of
those
in
the
past
and
we
found
this
works
quite
easily
as
well
between
different
clouds.
So
we
also
have
some
stuff
running
in
google
cloud,
primarily
some
of
our
data
stuff,
everyone's
in
gcp
and
gt.
B
We
do
a
lot
of
stuff
with
bigquery
and
whatnot,
so
we
do
have
some
clusters
over
there
and
just
by
connecting
the
two
clouds
together,
which
in
our
case
we
just
connected
them
via
a
vpn
to
our
transit
gateway
and
using
a
trendy
vp
on
the
gcp
side,
we
could
easily
share
network
connectivity
between
them
in
a
secure
fashion
and
psyllium
again,
just
just
works.
You
know
we
have
celium
deployed
on
our
gk
clusters.
B
Difference
what
cloud
you're
in
as
far
as
this
is
concerned,
so
yeah,
so
you
can
do
this
target,
it's
an
arbitrary
number
of
clouds,
so
it
works
very
nicely
and
easily
so
yeah.
That
was
that
was
kind
of
our
general
networking
step
that
we
we've
done
with
psyllium.
Only
downsides
to
this
approach
is
one
question,
though,
and
the
first
one
we
hear
quite
quickly.
B
I
guess
was
that
it
does
use
ebpf
as
it's
primary
way
of
doing
stuff
and
when
things
go
wrong
with
vpf,
it
can
be
tough,
especially
for
someone
like
me
to
debug.
What's
going
on
compared
to
the
more
like
vanilla
ways
that
traditional
service
meshes
do
it,
you
might
need
to
learn
some
new
skills
to
debug
some
of
these
issues.
I
will
well,
I
must
say
it
was
more
when
we
were
starting
than
we
did
here.
We
don't
really
have
issues
with.
C
B
Anymore
and
there's
also
at
the
psyllium
community
are
like
amazing,
like
if
you
go
on
the
psyllium
slack
and
say
to
them
my
thing
doesn't
work.
They
will
spend
way
more
time
than
I
I
would
afford,
trying
to
help
you
debug
it.
I've
spent
many
hours
literally
hours
with
them,
sending
them
diva
blogs
and.
B
One
was
more
about
like
the
kind
of
missing
link,
I
guess
is
still
around
like
with
our
old
setup.
We
went
through
envoy
and
we
got
all
the
benefits
of
like
health
checks
and
wheat
fries,
and
you
know
it's
doing
its
load,
balancing
and
whatnot,
and
by
going
pod
to
pod,
you
do
lose
a
bit
of
that
right,
you're,
just
doing
simple
basic
kind
of
like
round
robin
style
load
balancing,
but
there's
no
there's
no
redries
or
anything
built
into
psyllium.
B
B
Support
police
out
of
the
box
yeah
some
like
future
of
this
is
a
is
a
well
we've.
We
have
basically
only
just
scratched
the
surface
of
what
psyllium
can
do.
It's
it
does
a
lot
of
stuff
they're
always
going
to
be
adding
new
features
to
it,
and
it
can
completely
replace
wherever
please
replace
q
proxy.
These
days,
which
we
go.
It
can
has
this
amazing
graphical,
ui
called
hubble,
which
can
show
you
all
sorts
of
nice
networking
data
visualizations.
B
What's
going
on
in
your
clusters,
there's
stuff
like
ipsec
using
psyllium,
now
exists
so
yeah.
We,
we
really
even
started
to
take
full
advantage
of
all
the
stuff.
It's
it's
delivering,
which
is
I'm
pretty
pretty
exciting
and,
just
as
I
know,
it
can
be
ran
with
other
service
measures
as
well.
For
example,
if
you
want
to
use
a
like
kind
of
like
sidecar
approach,
service
mesh
syllium
works
just
fine
with
that.
There's
no
problem
working
in
tandem
with
these
things.
In
fact,
it.
A
B
B
C
B
A
C
B
A
B
I've,
you
might
say,
yeah.
Originally
we
used
it
with
the
usb
pc
cni,
as
that
was
the
only
way
of
doing
it.
So
we
chain
it,
but
it
used
to
be
chain
so
yeah
the
vpcc,
and
I
would
do
the
you
know,
allocation
and
then
psyllium
would
do
the
rest.
But
these
days
it
can
be
used
as
a
complete
replacement,
which
is
where
we're
using
it
in
our
newer
clusters,
brilliant.