►
From YouTube: Production Grade Kafka on K8s by Anand Iyer
Description
Stateful workloads have always been a challenge in the Kubernetes ecosystem. Kafka one of the most used event-driven systems is becoming the backbone system and with most of the infrastructure workloads now on Kubernetes, we need a robust and native way to communicate with Kafka inside Kubernetes. In this talk, I would like to introduce a Kafka Operator for Kubernetes which allows ease of deployment and management of the Kafka workloads.
A
So
we
look
at
the
agenda
first,
so
we're
going
to
cover
introduction
to
kafka.
We
are
going
to
look
at
kafka
capabilities
or
typical
traditional
deployment
and
how
the
stream
c
project
is
going
to
help
us
in
this
overall
design
will
look
at
the
overall
deployment
architecture,
kubernetes,
operated
design
for
kafka
and
we'll
look
at
a
demo
as
well,
so
apache
kafka.
So
basically
for
folks
who
are
new
to
kafka
I'll,
just
take
another
five
minutes
to
quickly
brush
you
through
the
concepts
like
kafka's
and
even
streaming.
A
A
Brokers
are
actually
a
cluster
of
kafka
brokers,
handles
the
delivery
of
messages
and
a
broker
uses
these
apache
zookeeper
for
storing
the
configuration
and
for
the
cluster
coordination.
Typical
leader
election
mechanism
is
also
taken
care
by
the
zookeeper
capabilities
are
microservices
actually
uses
for
sharing
the
data
highly
useful.
A
If
a
data
requires
a
high
throughput
low
latency
guarantees
messaging
ordering,
it
provides
a
rewind
replay
kind
of
a
mechanism
so
that
you
can
reconstruct
your
complete,
complete
application.
State
message.
Compaction
is
provided
you
can
horizontally
scale
your
cluster
configurations,
replication
of
data
to
control
your
ft
modes
retention
of
high
volumes
data
for
immediate
access.
All
of
these
you
kind
of
get
with
kafka,
so
some
of
the
use
cases
is,
of
course,
it's
very
popular
in
event.
A
Driven
architectures
also
used
in
even
sourcing
to
capture
changes,
message,
brokering
activity,
tracking
operational
monitoring
through
metrics
log
collection
and
aggregation
of
course
commit
logs,
and
this
for
the
distribute
systems,
but
also
stream
processing,
so
that
applications
can
respond
in
the
data
real
time.
So
majority
of
pipelines,
if
you
are
building
pipelines,
so
kafka
would
be
the
central
nervous
system
in
that
pipeline.
A
Cluster
is
a
group
of
broker
instances
partitions,
basically
partitioning
takes
a
single
topic
log
and
then
breaks
it
into
multiple
logs,
each
of
which
can
have
a
separate
node
in
the
kafka
cluster.
This
way,
the
work
of
storing
messages,
writing
new
messages
and
processing.
Existing
message
can
be
split
among
many
nodes
in
the
cluster,
so
partition
is
a
key
concept
and
achieving
your
high
availability
concept
in
in
kafka.
A
Then
you
have
a
partition
leader
which
handles
all
the
producer
request.
Then
you
have
a
follower
which
can
replicate
as
well
as
consume
the
request,
so
in
total
kafka,
cluster
comprises
of
multiple
brokers.
Brokers
contains
topics
that
can
retrieve
and
store.
Data
topics
are
then
split
by
partitions,
where
the
data
is
written
and
then
partitions
replicate
across
the
topics
for
fault,
tolerant.
A
These
internal
communications
are
managed
with
tls
and
then,
if
you
want
to
build
on
top
of
it
some
metrics,
so
you
will
have
a
kafka
exporter.
If
you
want
your
clients
to
be
talking
through
http,
you
can
have
a
kafka
bridge
if
you
have
use
cases
where
you
want
to
integrate
an
external
system
directly
to
the
kafka
or
your
kafka
needs
to
directly
send
the
data
to
an
external
system.
A
So
that's
where
the
kafka
connect
comes
into
the
picture,
we
can
use
the
source,
connector
and
sense
connector
to
do
this
integration
and
then
kafka
mirror
basically
allows
you
to
kind
of
replicate
mostly
used
for
the
data
replication
scenarios,
and
then
yes,
that's,
that's
pretty
much
a
typical
kapha
component.
You
would
see
let's
look
at
a
traditional
deployment,
so
we
create
we
will.
If,
if
just
imagine
if
there
is,
there
is
no
stringy
project,
how
would
you
look
like?
How
would
you
look
at
a
kafka
deployment
or
a
community's
environment?
A
So
basically
we
will
create
stateful
sets
because
you
need
persistent
volumes.
You
need
a
stateful
set
in
the
end
to
make
sure
your
logs
your
commit
logs.
What
you
are
actually
storing
are
quickly
accessible,
so
you
are
going
to
create
stateful
sites
for
zookeeper
and
broker
you
are
going
to
deploy.
These
replica
sets
manage
these
endpoints
for
external
access.
You
have
to
manage
the
versions
of
all
the
resources.
A
Remember
that
for
a
given
broker
version,
you
need
to
have
the
right
zookeeper
version
as
well.
Then
you
have
to
build
your
own
observability
stack.
You
have
to
perform
upgrades
roll
backs,
manage
the
scalability
challenges,
and
then
you
also
will
have
to
build
a
lot
of
tools
to
just
maintain
this
complete
stack.
So
it's
complex
and
just
imagine
if
you
look
at
a
production
gate
scenario
where
you
have
more
than
100
brokers,
more
than
20
000
partitions.
A
A
It
provides
lots
of
deployment
configurations
so
for
development,
it's
as
easy
as
just
running
it
on
a
kind
and
on
for
production.
It
gives
many
capabilities,
such
as
rack
awareness,
deploying
on
different
availability
zones,
applying
teens,
tolerations,
making
sure
kafka
runs
on
dedicated
nodes.
All
of
those
is
possible,
and
then
it
also
allows
us
to
expose
kafka
to
end
clients
in
a
more
secure
way.
It
pro
it
provides
access
like
an
output,
load,
balancer,
ingress
and
openshift
routes.
A
Also
in
security,
it
provides
mtls,
cramshaw
and
a
layer
of
authentication,
plus
authorization
use
cases
as
well.
The
cube
native
management
of
kaffir
is
just
not
limited
broker,
so
basically,
swimsuit
allows
you
to
manage
even
the
topics
users
mirror
maker
connect.
Everything
is
using
the
custom
resources.
A
A
Now
it
gives
the
benefit
to
all
of
our
sre,
because
for
them
they
are
looking
at
kubernetes
resources
and
now
even
our
one
of
our
critical
application
is
behaving
like
a
community
resources.
Only
so
that's
where
the
the
swimsuit
project
comes
handy.
Let's
look
at
some
of
the
features
it
allows
you
to
deploy
and
run
kafka
clusters,
seamless
installation,
seamless
deployment,
upgrade
process.
You
can
manage
all
the
kafka
components.
You
can
manage
the
different
dependencies
as
well.
A
A
A
A
So
here,
if
you
see
the
cluster
operator,
is
responsible
to
manage
and
deploy
your
complete
kafka
cluster,
so
that
will
be
responsible
to
upgrade
your
brokers,
upgrade
your
zookeepers
making
sure
you
are
having
the
right
deployments
right,
set
off
replicas
running.
All
of
that
will
be
kind
of
governed
by
by
the
cluster
operator.
A
The
topic
operator
is
pretty
much
managing
anything
related
to
kafka
topics,
so
you
can
actually
create
kafka
topics
on
the
communities
using
the
cooperative
crs
and
similar
goes
for
the
user
operator.
So
general.
Now
you
are,
you
are
actually
giving
the
the
operators
more
power
to
actually
manage
your
kafka
clusters.
On
the
same
hand,
you
also
have
the
isolation
of
the
rules
what
it
offers.
A
A
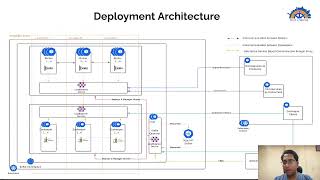
Cluster
so
left
hand,
side
section,
actually
talks
about
your
kubernetes
cluster,
where
all
of
your
client
applications
are
running
and
sorry
the
right
hand
side
is
actually
all
your
or
all
your
services,
where
your
clients
are
actually
connecting
to
the
front
side,
which
is
your
actually
your
kafka
deployments.
So
here
is
where
you
will
be
deploying
your
kafka,
and
these
will
be
running
on
dedicated
nodes.
So
here
you
can
see
it's
running
on
a
dedicated
kubernetes
cluster.
It
has.
It
is
under
a
kubernetes
kafka,
namespace,
and
then
you
can
see.
A
A
A
Similarly,
you
also
have
a
scenario
where
your
sres
can
actually
communicate
more
efficiently.
So
here
you
can
see
they
will
be
actually
directly
talking
to
the
operator.
So,
let's
look
a
look
at
the
use
cases.
How
your
kafka
would
would
work
right.
So
here
you
can
see
an
operator
which
actually
goes
and
deploys
and
manages
your
complete
deployment.
A
Your
operator
actually
talks
to
aps
server
and
constantly
reconciles
make
sure
you
have
the
right
number
of
replicas
of
your
brokers
and
your
zookeepers
running
and
also
sres
can
actually
run
these
crs
and
make
sure
that
they
can
build
more
tools
on
top
of
it
kind
of
create
a
kafka
connect,
model
or
or
a
kafka
mirror
maker.
All
of
these
are
kind
of
then
honored
based
accordingly,
after
your
kafka
is
deployed.
A
A
So
what
what
it
is
holistically
when
you
say
there
is
a
complete
kafka
system
or
an
ecosystem
which
is
needed,
so
what
shimsu
offers
is
a
complete
set
of
ecosystem
which
is
needed
on
a
production
grade
systems
right,
so
you
can.
We
just
discussed
about
the
kafka
components
like
broker
and
zookeepers.
We
also
talked
about
a
kafka
cluster
operator,
which
kind
of
allows
you
to
upgrade
and
manage
maintain
your
operators.
A
On
the
other
hand,
you
also
have
these
kafka
resources
operator,
which
is
for
for
mostly
creating
these
topics
and
users.
You
have
an
observability
stack
which
allows
you
to
generate
metrics
out
of
your
resources
and
track
those
resources
and
also
create
alerts
on
top
of
it.
It
has
a
very
nice
set
of
configurations.
A
lot
of
open
source
configurations
are
available,
which
you
can
actually
tune
with
it.
Shrimsi
comes
up
with
lot
of
sample
grafana
dashboards,
which
we
can
use
to
actually
export.
A
A
It
identifies
anomaly
detection
to
make
sure
that
none
of
the
brokers
are
put
into
some
thresholds.
It
also
makes
sure
that
you
can.
You
can
actually
avoid
throttling
based
on
cpu,
based
on
requests
based
on
memory
based
on
the
events
coming
in
you.
You
have
many
options
based
on
the
number
of
topics
based
on
number
of
resources
being
used,
so
you
can
also
make
sure
that
any
given
broker
is
not
overloaded.
A
All
of
these
capabilities
can
be
taken
care
with
the
cruise
control.
Cruise
control
is
another
interesting
project
from
the
linkedin
and
it
kind
of
makes
sure
that
your
cluster
is
evenly
balanced
on
a
on
a
scale
system.
Then
you
have
a
connectors
ecosystem.
It's
it's
it's
one
of
one
of
the
ways
where
you
can
optimize
how
you
communicate
with
external
systems
very
classic
use
cases
if
you,
if
you
are
actually
generating
events
onto
the
kafka,
and
you
want
to
actually
send
this
data
back
to
some
external
system.
A
You
don't
need
any
microservice.
You
can
directly
have
a
connector
or
kafka
connector,
for
example.
Here
in
this
case,
we
have
done
for
snowflake.
We
have
done
for
neo4j,
where
you
can
interconnect
the
data
right
from
kafka
events
to
snowflake
tables,
all
of
them
happening
directly
with
the
help
of
the
connector
on,
and
on
the
other
hand,
you
can
also
mention
how
many
number
of
tasks
can
be
running
running
on
that
particular
kafka
connect
model.
A
All
of
those
are
also
configurable,
and
then
kafka
bridge
comes
where
you
want
to
have
an
http
connection
model
rather
than
having
a
general
tcp
connection
that
is
also
supported.
Kafka
mirror
maker
gives
you
the
disaster
recovery
solution
for
your
complete
kafka
system.
Currently,
the
more
prevalent
and
used
is
kafka,
mirror
maker
2,
which
actually
uses
kafka,
connect
a
design
pattern
to
to
do
this
complete
disaster
recovery.
It
also
supports
active
active.
It
also
supports
active
passive,
both
both
the
ways
and
then
plus.
A
You
can
actually
build
more
and
more
tools.
On
top
of
it
like
something
like
a
kafka
ui,
a
simple
kafka,
cowl
based
ui,
you
can
actually
just
embed
into
it
now.
The
great
thing
about
this
is
your
complete
project
is
very
much
extensible.
Shrimzi
allows
you
to
plug
and
play
all
of
these
components
very
easily
and
kind
of
again
on
the
same
side
have
a
way
to
kind
of
manage
all
of
these
resources
on
a
central
plane.
A
A
So
currently
my
cluster
looks
like
this.
I
only
have
an
operator
running
and
you
can
see
the
operator
logs
running
here.
So
let's
go
ahead
and
do
a
deployment.
So
I'm
going
to
deploy
crd
we'll
talk
about
the
crd
in
a
minute
and
let's
look
at
the
operator.
Okay,
it's
some
action
has
happened
and
you
can
see
here.
A
It
has
created
this.
Let's
go
and
look
at
the
activities
which
are
happening
here,
so
it
has
started
to
create
a
zookeeper
first,
and
you
will
see
that,
with
with
the
crd,
we
are
making
sure
your
deployments
are
streamlined.
It
is
sequentialized,
you
will
first
deploy
the
zookeeper
and
then
only
you
will
deploy
the
brokers,
and
all
of
this
is
taken
care
by
the
by
the
shrimp
itself.
You
can
see
now
the
zookeeper
is
running
and
it
will
schedule
the
broker
immediately
and
we
can
actually
also
look
at
yeah.
A
You
can
see
the
broker
has
also
started
another
way
to
look
at.
This
is
just
by
doing
cube
cattle
get
kafka
and
basically
you
are
now
able
to
track
kafka
resources
using
a
kafka
cr.
Now
this
is
a
one-stop
shop
for
me
to
look
at
everything
related
to
kafka.
This
says
that
I
have,
I
need
one
desired:
kafka
broker
and
one
desired
replica
for
my
zookeeper
and
that's
it.
It
gives
me
something
called
as
ready
and
warnings
unless
until
it's
not
ready,
I
will
not
allow
the
connections
to
be
open.
A
To
my
end,
clients.
If
there
are
warnings,
I
can
make
sure
that
unless
until
I
fix
those
warnings
I
will
not
allow,
I
will
not
make
sure
my
connections
are
open,
so
here
it
will.
We
will
make
sure
that
the
zookeeper
kafka
is
running
and
then
we
are
also
running
an
entity
operator.
Entity
operator
is
nothing
but
basically
it's.
A
A
A
It
has
created
certain
load,
balancers
and
one
load.
Balancer
is
for
an
external
bootstrap
and
the
other
one
is
for
the
kafka
broker,
and
then
you
can
see
an
entity
operator
which
is
a
deployment.
That's
the
part
for
which
you
can
see,
and
these
are
the
two
stateful
sets.
Actually
the
kafka
and
zookeeper
both
are
straightforward.
So,
basically,
just
with
the
crd,
we
have
actually
deployed
a
complete
kafka
cluster
and
you
can
actually
see
all
of
this
resources
available.
A
A
A
A
We
have
a
support
for
nlp.
We
have
support
for
making
internally
exposed,
rather
than
making
it
outside.
Similarly,
we
have
affinity
strategies,
we
have
like
part
affinity
and
definite,
and
just
remember
this
is
a
kind
of
kafka.
This
is
the
cr
which
we're
using
coming
from
the
api
version,
kafka
from
cio
v1
beta2,
and
then
we
assign
some
replicas.
A
You
can
just
update
these
replicas
and
redeploy
and
there
will
be
a
new
number.
There
will
be
new
brokers
coming
up.
You
have
different
options
of
exposing
the
end
points.
We
never.
We
never
recommend
something
like
a
tls
falls
kind
of
a
unsecured
load
balancer
for
for
external
usage.
We
we
always
recommend
something
like
an
mtls
base.
It's
just
as
simple
as
making
this
as
true
all
the
certificate
management
will
be
managed
by
shrimpsee.
A
Similarly,
you
can
have
a
scram
shaft
haven
to
base
mechanism
as
well
or
a
combination
of
tls
with
authorization
as
well.
You.
The
interesting
thing
is
you
can
use
storage
as
jbodz
and
make
sure
you
can
have
multiple
volumes
available
with
it
so
as
and
when
you
have
more
and
more
load
coming
in,
you
can
just
add
number
of
volumes
and
these
volumes
will
get
attached
to
your
existing
brokers
and
all
of
the
configuration
whatever
is
possible,
which
is
supported
by
kafka.
You
can
actually
mention
all
of
these
here
and
shims.
A
They
will
inject
this
as
part
of
your
broker
and
your
zookeeper
deployments.
So
any
time
or
you
make
any
changes
here,
the
rolling
update
happens
for
all
of
these
parts.
It
also
supports
making
sure
that
you
can
have
deployment
on
a
dedicated
node
groups
as
well.
You
can
have
teams,
you
can
have
tolerations.
All
of
that
is
also
supported.
A
Similarly
for
zookeeper
as
well.
We
we
saw
all
of
these,
and
these
are
the
entity
operator
which
contains
our
user
topic
operator
and
a
user
operator,
and
then
we
have
also
used
a
cruise
control
to
make
sure
that
we
can
provide
some
capacities
and
make
sure
that
your
ports
never
go
beyond
these
capacities
and
if
it
goes,
it
kind
of
then
gives
you
some
hard
goals
and
give
you
some
suggestions
and
optimization
goals
based
on
which
you
can
actually
trigger
those
optimization
plans.
A
So
this
is
a
single
single
blueprint
for
me
to
deploy
a
complete
kafka
rather
than
looking
at
different
resources.
I
play
around
with
these
values,
and
I
can
have
my
my
kafka
deployment
kind
of
triggering
based
on
the
change
happening
on
this,
because
for
any
change
event
there
is
a
reconciliation
happening
by
the
cluster
operator.
A
So
that's
what
I
wanted
to
present
in
the
demo.
These
are
the
references
we
have.
You
can
look
at
the
website,
the
github
project.
You
can
look
at
the
the
the
slack
channel
streamsy
on
the
cncf
project.
We
will
will
help
you,
if
you
have
any
interesting
use
case,
will
help
you
to
get
you
guys
on
boarded
with
kafka.