►
Description
The best way to support and accelerate operational practice around Kubernetes and OpenStack is to make it easy to share and reuse deployment automation. This presentation will review leading deployment community methodologies with a focus on Kubernetes Community Ansible Kargo and OpenStack Community Helm with a Digital Rebar underlay.
A
Hello,
everybody
and
welcome
to
the
joint
OpenStack,
kubernetes
environment
I.
Think
I
gave
it
a
more
hybrid
II
cool
sounding
title.
My
name
is
Rob
Hirschfeld
and
we're
going
to
spend
about
40
minutes
talking
about
OpenStack
Saver
topic,
which
is
kubernetes
and
we're
going
to
go
through.
This
is
supposed
to
be
an
operational,
very
pragmatic
assessment
of
this
joint
OpenStack
kubernetes
environment.
This
is
something
that,
six
months
ago,
a
year
ago,
I
was
I
was
very
skeptical
of,
and
so
I've
been
giving
this
presentation
in
a
series
of
progressive
updates.
A
A
My
name
is
Rob
Hirschfeld
I've
been
in
the
OpenStack
community
for
quite
some
time.
I
was
a
board
member
for
four
years
I'm,
currently
the
co-chair
of
the
kubernetes
cluster
ops
sig.
So
if
you're,
a
OpenStack
veteran-
and
you
remember
the
days
before
we
organized
operators,
we're
trying
to
avoid
that
mistake
in
kubernetes
and
I'm-
also
the
founder
of
some
open
source
projects,
one
is
called
digital
rebar.
If
you're
an
openstack
veteran
you'll,
remember
a
project
called
crowbar,
which
is
still
Seuss's
installer
might
as
a
founder
of
that
project.
A
A
So
the
framework
for
this
talk
and
we
will
get
to
some
very
detailed
components
of
how
this
works
and
how
it
goes,
but
it's
important
to
me
to
frame
it
so
that
you
understand
that
we're
talking
about
operational
needs
right.
This
is
not
a
kubernetes
dev
talk,
it's
really
about.
How
do
we
help
opera
raishin,
succeed,
running
OpenStack
and
operators
are
not
developers,
they
have
different
needs.
They
want
things
to
be
very
simple:
they
want
them
to
be
transparent.
They
don't
want
to
be
hacking,
the
codebase
of
the
platform
they
are
trying
to
get
running.
A
They
want
it
to
run,
and
one
of
the
things
that's
important
with
this
is
that
we
don't
want
people
to
our
operators
to
be
asked
to
become
super
users
of
the
platforms
that
they're
trying
to
deploy
while
they're
learning
how
to
deploy
them.
So
that
means
you
don't
try
to
make
kubernetes
operator
learn
kubernetes
right,
not
initially
OpenStack
users
shouldn't
have
to
operator
shouldn't
have
to
learn
OpenStack,
initially
to
run
it
right.
A
My
experience
is
that
running
the
platform
is
very
different
than
using
the
platform
they
have
different
they're,
actually
designed
to
have
different
abstractions
between
what
you
use,
which
you're
trying
to
hide
and
what
you
actually
have
to
deal
with
to
make
that
platform
run
right.
So,
when
you're
dealing
with
a
infrastructure
platform
like
OpenStack
or
kubernetes
on
metal,
you
have
to
deal
with
raid
and
bios
and
drives
and
networks
and
a
whole
bunch
of
messy
stuff
once
that
stuff
that
that
platform
is
installed.
A
Your
users
should
never
see
that
the
whole
purpose
of
those
platforms
is
to
off.
You
skate
the
mess
of
infrastructure,
and
then
the
number
one
thing
that
we
learned
early
in
the
OpenStack
days
and
I
think
is
important
in
any
platform
is
upgrade.
Ability
is
a
number-one
operational
concern
right.
Operators,
unlike
developers,
don't
keep
installing
the
platform
on
a
daily
or
hourly
basis
as
they
test
it
and
change
it
right.
A
We
want
to
explore
to
be
upgradeable
so
that,
as
we
find
bugs
or
patches
or
something
comes
out,
we
can
fix
it,
saying
oh
just
tear
down
your
kubernetes
control
plan
or
your
OpenStack
control
plane.
So
I
can
put
in
a
patch
is
not
an
acceptable
answer,
so
in
general,
kubernetes
has
very
good
semantics
and
operational
foundations
for
this
type
of
infrastructure
pattern.
It's
actually
very
well
designed
to
be
upgradeable
to
be
replaceable
to
be
easier
to
understand,
and
it's
actually
bust
infrastructure
designed
for
people
to
do
a
che.
A
Upgradeable
deploy
instead
have
a
degree
of
self
maintaining,
and
so
that's
one
important
thing
about
this
and
then
there's
a
second
piece
that
to
me
is
evolving
out
of
the
kubernetes
under
OpenStack
story,
which
is
shared
operational
best
practice.
So
one
of
the
things
that's
been
missing
in
the
OpenStack
community,
somewhat
on
purpose
and
somewhat
by
accident,
is
shared
operational
vision.
A
If
you
go
to
the
up,
the
ops,
meetups
you'll
find
that
every
scale
operator
has
their
own
puppet
chef,
ansible
deployment,
scripts
right,
the
vendors
have
their
own
operational
deployment
scripts,
and
so
typically,
when
somebody
finds
an
issue
with
operating
OpenStack,
nobody
else
benefits
and
that
to
me
is
a
serious
problem
in
an
open
community.
We
want
our
operational
improvements
to
flow
throughout
the
community,
so
if
Red
Hat
learns
how
to
up
run
OpenStack
or
kubernetes
better,
we
want
everybody
to
benefit
right.
If
a
scale
operator
like
Google
makes
operations
better.
A
A
Okay,
and
just
to
make
sure
you
understand
the
roadmap
with
this,
because
the
Eric
right
was
giving
a
talk
earlier
today
or
yesterday
talking
about
the
kubernetes
sandwich
in
this
case.
We're
talking
about
the
bottom
right,
I'm,
not
worried
about
running
kubernetes
on
OpenStack
we're
really
talking
about
how
do
we
make
ku
OpenStack
run
on
kubernetes?
A
How
many
of
you
think
that
that's
even
a
good
idea,
people
good
about
5050
excellent,
so
I
was
very
skeptical
about
this
and
will
explain
it
why
I'll
decomposed
that
a
bit,
but
this
is
about
the
underlay
and
then
one
of
the
things.
That's
really
important
to
me
in
this
discussion
in
the
whole
consideration
is
that
it
must
work
with
kubernetes
primitives.
So
this
is
not
right.
My
ground
rules
for
this
whole
talk
is
that
we're
not
talking
about
using
coburn
and
then
hardwiring
it.
A
So
you
need
an
external
scheduler
to
place
containers
or
right
in
place
services
we're
talking
about
using
kubernetes
primitives,
so
that
you
actually
have
an
operable
cluster
that
you
can
use
for
other
things
and
so
that
the
work
that
we're
doing
to
run
OpenStack
on
topic,
kubernetes
leverages
all
of
the
operational
constructs
for
kubernetes,
okay
and
we'll
explain
how
that
works
and
why
that
works,
but
if
you're
installing
kubernetes
and
then
massaging
a
whole
bunch
of
stuff
in
it.
That
to
me
is
a
fail.
A
It's
not
really
using
kubernetes,
so
I'm
going
to
take
a
second
and
describe
kubernetes
I'm,
not
assuming
you
know,
kubernetes
that
well,
it
is
a
container
scheduler.
We
can.
We
can
have
a
cage
match
later
about
whether
it's
an
Orchestrator
or
a
scheduler.
It's
easier
in
my
mind
to
think
of
it
as
a
scheduler.
That
means
it
positions.
Containers
does
some
things
to
keep
them
up,
but
for
the
most
part,
it's
not
making
a
lot
of
decisions.
That
would
be
a
platform
as
a
service
type
thing,
and
it
provides
some
really
robust.
A
Api
is
to
restart
place,
deal
with
networking
and
life
cycle
of
containers,
so
you
can
say,
take
this
container
and
replace
it
right.
Keep
take
this
container
and
keep
it
running
and
things
that
are
working
with
kubernetes
are
designed
for
kubernetes.
It
is
not
magic,
pixie
dust
to
take
your
legacy,
monolithic,
app
and
turn
it
into
this
wonderful,
auto
regenerative
thing
is
designed
to
work
something
called
12
factor
applications
which
have
a
different
configuration
pattern
than
say
OpenStack.
A
It's
designed
for
a
mutable
infrastructure,
meaning
that
you
don't
patch
things
in
place.
You
swap
them
out
very
simple
definition
of
immutable
and
it's
meant
for
things
that
are
service.
Oriented
OpenStack
is
a
good
example
of
a
service-oriented
application
where
we
have
a
lot
of
different
services
that
have
to
interact
together,
probably
could
be
smaller
from
a
kubernetes
perspective,
but
it
is
a
good,
service-oriented
app.
If
you
want
to
see
this
is
a
map
we
built
in
cluster
ops
that
describes
kubernetes
if
you're
used
to
OpenStack
topologies.
A
This
is
probably
just
as
scary,
because
there's
a
lot
of
services
just
like
kubernetes,
is
a
cloud
native
app.
So
it's
designed
with
services,
but
you
don't
have
to
worry
about
a
lot
of
these
services.
Really,
the
heart
of
Nettie's
is
very,
very,
very
simple:
it
has
a
container
runner
called
couplet.
It
has
a
centralized
coordination
point
called
the
API
and
then
it's
back
ended
with
sed
as
a
database.
There's
a
lot
of
other
little
pieces
that
plug
into
that
and
monitor
it
and
there's
adjacencies
that
we
can
worry
about.
A
But
fundamentally
it's
a
it's
a
service
that
runs
on
a
node
to
schedule,
containers
and
a
centralized
database
that
you
it
tells
that
scheduler
what
to
do
so.
The
first
thing
is
kubernetes.
So
if
you've
been
listening
to
things
going
on,
kubernetes
is
rainbows
right.
We
are,
we
are
now
we've
we've
decided.
Openstack
is
old
hat
we've
switched
to
kubernetes
because
it's
going
to
we're
going
to
find
this
pot
of
gold
at
the
end
of
that
rainbow.
A
For
people
who
don't
know
kubernetes
is
named
after
steersman
or
helmsman
for
ship,
so
you'll
see
a
lot
of
ship
analogies
and
the
logo
is
actually
a
steering
wheel
for
people.
It's
not
going
to
generate
rainbows.
It
is
pretty
cool
stuff,
I'm,
very
excited
about
what
I
see
in
community
and
ice
and
the
types
of
abstractions
that
we
get.
It
does
not
solve
all
problems
and
some
of
the
problems
this
chart
I've
been
updating
as
I
go
and
changing
these
arrows.
A
Some
of
them
started
as
red
we've
been
moving
through
the
OpenStack
problem
operations
problem
is
not
solved
right.
That's
the
first
starting
point:
you
got
to
realize
if
we
thought
we
already
had
the
the
perfect
way
to
install
and
operate
OpenStack.
We
wouldn't
need
this
conversation
right,
so
it's
not
solved.
What
I
have
seen
is
that
the
new
deployments,
not
all
of
them,
not
all
the
historic
ones,
but
basically
every
new
deployment
I
see,
is
using
containers
as
the
packaging
mechanism.
A
It's
a
lot
of
good
reasons
for
that
containers
is
really
valuable,
so
we're
seeing
containers
all
over
the
place
in
OpenStack
deployments.
Kubernetes
is
awesome
at
containers.
Anybody
who's
using
more
than
three
containers
likely
needs
a
scheduler.
There
are
a
couple
of
them
on
the
market.
Docker
rancher,
kubernetes,
maysa,
there's
actually
like
four
or
five
other
ones,
kubernetes
is,
is
gaining
a
lot
of
mindshare.
It's
a
good
community.
A
Kubernetes
is,
and
this
is
not
entirely
true,
stable,
simple
and
secure.
We
are
still
working
on
deployment
operations,
capabilities
right,
moving
OpenStack
to
run
on
kubernetes,
if
kubernetes
isn't
actually
Enterprise
ready
is
not
gaining
us
anything.
The
velocity
of
that
transition
is
pretty
good.
We've
been
doing
a
lot
of
work.
A
My
company
does
a
lot
of
work,
helping
run
a
ansible
playbook
set
called
cargo
that
we
think
is
really
exciting,
and
that
shows
a
che
Enterprise
readiness
secure
deployment
capability,
so
we
feel
like
kubernetes,
is
good
enough
to
be
a
base
for
this
type
of
platform,
and
then
the
last
point
here
is
that
if
you
have
kubernetes,
you
get
upgrades
in
h.a
for
free.
It's
not
true.
A
If
your
application
is
designed
to
work
with
the
kubernetes
patterns,
then
you
will
see
upgrades
Nha
fall
out
of
that
pretty
easily
because
of
the
semantics
that
kubernetes
gives
you,
but
your
application
has
to
be
ready
to
take
advantage
of
that
that
type
of
infrastructure-
and
that
is
where
we'll
probably
spend
a
lot
of
time
in
this
deck.
So
before
I
talk
about
challenges
and
problems,
I
want
to
talk
about
some
of
the
benefits.
A
The
patterns
that
you
get
for
upgrading
and
kubernetes
are
real
the
challenges
you
have
to
conform
to
them.
So
if
we
conform
to
what
kubernetes
expects
from
an
upgrade
pattern,
we
do
get
that
type
of
benefit
and
we
as
a
community,
need
it
there's
a
really
good
job,
scheduler
for
maintenance.
So
when
you
want
to
do
routine
tasks
that
do
housekeeping,
you
can
throw
them
in
as
background
tasks
and
it's
taken
care
of
for
you.
A
A
There's
a
big
one!
If
you
assume
that
kubernetes
is
going
to
become
a
dominant
platform,
then
somebody
who
wants
to
run
OpenStack
could
show
up
and
just
install
OpenStack
on
top
of
that
kubernetes
deployment.
That's
my
next
slide
and
then
the
other
thing
that's
a
benefit
to
a
lot
of
a
lot
of
people,
and
thinking
about
this
is
it's
very
constrained.
A
So
if
and
when
I
would
say,
when
the
OpenStack
community
embraces
kubernetes
is
a
deployment
as
the
deployment
dominant
deployment
choice,
it's
going
to
drive
a
lot
of
decisions
because
it's
a
more
constrained
environment,
so
you're
not
going
to
have
all
the
options
that
we
have
enjoyed
as
a
community.
That's
good!
This
present
cons
for
that,
but
fundamentally
what
we
want.
What
the
community
in,
in
my
opinion,
needs
very
desperately
is
reduced.
Friction
for
these
deployments
and
that's
really
one
of
the
things
that
we
want
to
look
at.
A
We
want
to
make
it
much
easier
to
deploy
and
maintain
an
openstack
infrastructure,
and
we
want
to
be
able
to
do
it
inside
of
a
growing
community.
One
of
the
benefits
of
kubernetes
it's
important
to
understand
is
that
kubernetes
is
a
cloud
infrastructure,
so
it
has
very
low
friction
to
deploy
and
install.
If
you
want
to
run
kubernetes,
you
need
an
Amazon
account
and
you
can
have
it
running
in
about
five
minutes.
That
is
not
true.
With
OpenStack
OpenStack
I
mean
we
have
devstack,
but
that's
not
a
running
infrastructure.
That's
that's
development!
Tooling!
A
So
this
is
coming.
I
have
I.
Have
you
know?
I
was
on
the
skeptic
side.
You
can
go
back
and
watch
my
earlier
talks.
I
was
I
really
thought
that
this
was
a
bad
idea
initially,
but
it's
coming
and
I
think
that
it's
very
important
for
us
to
be
pragmatic,
there's
been
some
great
talks.
At&Amp;T
did
a
talk
earlier
today,
I've
seen
a
whole
bunch
of
other
things
going
on
about
this
helmet
art
approach
that
we're
going
to
outline
about
how
to
actually
get
this
to
happen.
A
So
I
see
a
lot
happening
in
the
community
since,
even
since
these
slides
I've
been
watching
people
do
this
very
similar
work
as
I'm
going
to
describe
in
multiple
projects,
so
we're
actually
seeing
some
some
forking
and
competition
in
that
approach.
Not
my
favorite
thing
to
see
that
that's
what
happens
in
open
communities
all
right
so
before
I
talk
tech.
A
This
marketing
message
is
confusing
right,
it
is,
it
is,
would
be
irresponsible
to
not
say,
hey,
wait,
a
second
OpenStack
on
kubernetes
what
I
the
thing
that
the
market
hears
from
that
is
kubernetes
and
that's
true.
One
of
the
challenges
with
this
is
that,
as
we
describe
this
type
of
positioning,
the
clear
message
that
people
get
is
that
OpenStack
is
not
as
big
kubernetes
is
much
bigger
and
that's
the
reality
I
think
of
the
message.
A
It
also
hurts
and
I
think
the
the
foundation
has
really
moved
changed
away
from
this
I
missed
the
keynotes
this
morning,
so
maybe
they're
going
to
they
prove
me
wrong
this
morning,
but
they've
been
moving
away
from
this
OpenStack
one
platform:
message,
if
you
think
back
to
Barcelona
or
Austin,
the
message
for
OpenStack
was
one
platform:
containers,
metal
and
VMs.
If
you're
putting
kubernetes
under
its
it's,
not
as
clear
that
that's
the
message
so
OpenStack
has
to
evolve
and
has
to
respond
to
these
challenges.
A
That's
the
way
the
technology
goes
and
I
think
there's
also
some
confusion
between
container
operations
and
what
this
is.
So
this
is
very
much
about
kubernetes
deployment
container
izing,
your
OpenStack
deployment.
It's
a
great
idea.
A
lot
of
people
are
doing
it,
but
it
is
not
the
same
as
what
we're
talking
about.
The
purpose
of
this
talk
is
to
layout
kubernetes
as
a
management
plane
management
manager
to
control
those
containers.
A
You
there's
a
lot
of
ways:
I've
seen
tons
of
them
very
creative
to
use
ansible
and
chef
and
juju,
and
things
like
that
to
place
containers
on
servers
and
then
manage
the
containers
different.
That's
a
different
strategy
right
because
you
still
have
to
manage
those
containers
using
something
in
this
model.
You
don't
you
use
kubernetes
to
manage
it.
I've
been
beating
on
that
point,
but
I
think
it's
really
important
one.
A
This
slide
just
repeats
that
so
I'm
not
really
going
to
go
over
that,
except
to
point
out
that
the
idea
here
is
that
we
need
to
be
thinking
of
ways
that
OpenStack
adopts
kubernetes
principles
right,
so
twelve
factor
application.
You
need
to
be
able
to
handle
containers
being
added
and
removed.
There's
there
are
operational
requirements
for
kubernetes
that
OpenStack
is
going
to
have
to
respond
to
as
this
process
gains
momentum
and
those
are
things
like
containers,
changing
IP
addresses
and
going
away
off
the
infrastructure.
A
It's
the
idea
that
you're
they're
immutable
and
you
can't
configure
them
so
you
have
to
have
ways
to
get
configuration
into
containers.
That's
important!
So
there's
a
lot
of
aspects
of
creating
a
kubernetes
microservices
application
that
were
not
factored
into
the
OpenStack
designs.
Openstack
designs,
assumed,
service,
persistence
and
kubernetes
applications
do
not
assume
service
persistence.
That
makes
sense.
Okay,
I'm
not
seeing
tons
of
people
nodding,
but
I'm
not
going
to
spend
more
time.
You
will
get
into
Q&A
and
that's
confusing
I
will
explain
it.
A
So
I
have
a
much
bigger
picture
picture,
but
I
want
to
have
a
little
bit
of
text
to
prep
this.
So
kubernetes
is
now
at
version
1.6.
What
the
1.5
release
brought
in
some
critical
primitives
that
we
needed
to
make
this
work
go
so
before
the
last
two
releases.
We
really
couldn't
have
done
OpenStack
on
kubernetes
and
the
one
key
elements
for
this.
This
whole
process
is
something
called
helm.
Helm
is
heat.
This
is,
this
is
a
horrible
analogy,
but
it's
workable
helm
is
heat
for
kubernetes,
so
you
can
create
a
helm
chart.
A
It's
it's
a
yamo
file
that
describes
how
an
application
is
positioned
and
how
it
interacts
with
other
applications.
So
it's
sort
of
a
you
know
via
it's
like
you
would
take
heat
and
spin
up
multiple
VMs.
You
can
take
a
helmet
art
and
spin
up
multiple
containers
and
wire
them
together
and
describe
requirements.
If
you
used
to
docker
doc,
wrestling
called
compose,
helm
and
compose
are
very
similar.
Things.
Helm
is
not
kubernetes,
helm
is
a
add-on
into
kubernetes.
A
Kubernetes
has
worked
really
hard
to
keep
a
very
small
core,
and
so
the
community
resists
adding
a
project
like
helm
into
the
core.
They
keep
things
like
that
in
ecosystem,
so
you
will
probably
see
alternatives
to
helm
surface
and
that's
normal,
but
the
efforts
that
we're
seeing
do
use
helmets.
The
dominant
container,
scheduling
infrastructure
right.
A
Okay,
so
that's
important,
there's
something
called
tagging.
So
what
what
you
can
do
with
with
kubernetes
is,
you
can
say
this
node
has
these
attributes
and
then,
when
you
go
spin
up
a
helm
chart
you
can
say,
put
the
helm
chart
on
nodes
to
have
these
capabilities,
so
you
could
make
them
compute
nodes
or
control
nodes
or
SEF
nodes,
or
things
like
that,
so
you
can
actually
have
an
affinity
with
in
the
infrastructure
based
on
tagging.
A
A
A
So
if
you,
without
that
capability,
you
couldn't
run
Neutron
and
allow
to
have
access
to
the
network
right
or
Swift
and
have
allowed
to
have
access
to
the
drives
you're
going
to
the
containers
operating
in
a
more
isolated
mode
and
that's
important,
because
it's
part
of
the
the
protocols
that
allow
kubernetes
to
do
OpenStack
deployment,
which
doesn't
act
like
a
normal,
doesn't
act
like
a
normal
kubernetes
app
because
you're
going
to
have
long
running
processes,
long
running
containers,
databases
require
you
to
have
stateful
sets.
So
a
stateful
set
is
a
1.5.
A
It
used
to
be
called
pet
sets.
Some
people
are
happy
about
that
change,
and
some
people
aren't
stateful
sets
mean
that
there
is
a
shared
storage
or
persistent
storage
for
a
container.
So
if
you
have
a
container
that
must
maintain
state
or
in
the
pets
vs.
cattle
analogy
must
be
a
pet,
you
can
have
that
container.
A
Just
keep
its
state
so
database
is
a
really
good
example
of
a
stateful
set
application
and
for
us
to
do
databases
in
this
model
which
we're
doing
you
need
to
have
stateful
sets,
and
then
those
have
to
be
backed
by
a
persistent
storage.
So
what
we
actually
end
up
with
is
Seth
for
that.
I'll
show
that
in
the
next
slide
and
then
one
of
the
things
that
was
really
important
for
the
AT&T
crew
and
I
think
this
is
very
useful,
is
there's
multiple
sources
for
the
containers
that
include
OpenStack.
A
So
in
everything
we're
describing
we're
talking
about
container
scheduling
the
containers
have
to
come
from
somewhere
so
somewhere.
Somebody
is
building
OpenStack
containers
that
have
the
OpenStack
Python
code
in
it
and
are
packaged
according
to
the
semantics
of
the
helm,
charts
and
so
that
somewhere.
That
has
to
be
done.
And
if
you
want
to
run
this
on
arm,
somebody
has
to
build
them
for
arm
and
somebody
right.
A
So
we
have
an
interesting
place
where,
if
you
want
containers
from
a
trusted
source,
then
you're
going
to
need
to
be
able
to
have
a
source
for
the
container,
so
containers
don't
magically.
Show
up
like
mushrooms,
they
actually
have
to
be
built
and
maintained
right.
So
if
somebody
patches
OpenStack,
then
somebody
has
to
create
a
new
container
before
you
can
then
roll
that
container
out
into
your
infrastructure.
A
So
that's
the
primitives,
hopefully
that
helps
translate
some
of
what
we're
talking
about
into
kubernetes
speak.
If
you
need
more
kubernetes
lexicon,
we
can
about
that
I'm
happy
to
happy
to
help
with
that
and
there's
a
lot
of
things
that
we
really
have
to
do.
That
aren't
solve
problems
yet
I'm
going
to
flip
to
the
next
slide
and
we'll
talk
about
this.
So
this
is
an
exploded
version
of
that
architecture,
and
it's
designed
to
show
you
a
lot
more
details
about
how
these
things
work
together.
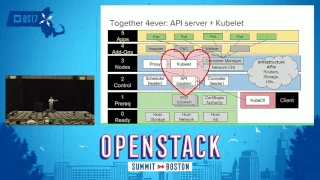
So
kubernetes
is
a
platform.
A
It
has
its
own
control
infrastructure.
So
there's
a
control
set
of
control
nodes.
If
you're
running
in
production,
you're
going
to
have
three
of
them
at
least
you
might
separate
out
Etsy,
D
and
all
sorts
of
things
helm
is
an
application.
That's
going
to
run
on
those
controllers,
it's
not
extra
nodes.
This
is
not
meant
to
be
a
node
mapping.
Otherwise,
it's
a
logical
mapping.
You
have
set
a
kubernetes
workers,
the
kubernetes
workers
are
going
to
be
what
we're
open
stack
actually
runs.
A
So
the
idea
here
is
that
I
could
have
a
OpenStack,
kubernetes
cluster
and
run
the
OpenStack
control
plane
in
that
cluster,
as
a
general
capability
in
kubernetes
would
schedule
it
and
keep
the
database
up.
Keep
the
message.
Bus
up
all
of
the
OpenStack
management
components
would
be
running
because
I
need
stateful
sets.
I
need
SEF
installed
first
and
wired
into
the
stateful
set,
so
I
can
then
use
SEF
as
that
stateful
set
back-end.
That
was
something
I
thought
would
be
a
lot
harder.
This
came
in
actually
pretty
quickly.
A
I,
don't
think
it's
a
production-grade
SEF
cluster.
Yet
to
do
that,
you
actually
need
physical.
It's
a
longer
story.
I
will
take
that
as
a
question
after
afterwards
if
people
are
interested,
but
there
are,
there
are
challenges
like
how
do
I
create
a
production
grade,
scaled
SEF
in
a
kubernetes
cluster,
it's
a
great
application
for
kubernetes
and
there's
a
lot
of
people
who
are
interested
in
running
kubernetes
to
maintain
the
Ceph
infrastructure.
A
Also,
that's
a
not
an
openstack
problem,
it's
a
Seth
problem,
but
it's
really
interesting
and
the
same
thing
is
true
with
software-defined
networking
layers,
so
we
need
to
be
able
to
run
software-defined
networking
in
a
way
that
attaches
into
the
infrastructure
correctly.
Kubernetes
has
its
own
software-defined.
Networking
stack
and
by
default
containers
are
going
to
go
through
that
stack.
So
if
you're
running
Neutron
with
kubernetes,
we
now
have
a
a
conflict
between
how
Neutron
wants
to
interact
with
an
SDN
layer
and
kubernetes
wants
to
interact
with
nest
and
layer,
and
that
will
be
a
challenge.
A
In
some
cases
you
could
use
something
like
Romana,
which
is
a
flat
networking
technology
in
kubernetes,
and
then
just
let
Neutron
do
its
thing.
It
could
be
that
we
actually
want
to
bind
to
another
NIC
a
lot
of
ways
to
solve
this
problem.
Some
of
them
are
going
to
be
more
elegant
than
others,
but
definitely
workable
problems,
but
they're
not
solved
yet.
So.
When
you
look
at
this
chart
right
I'll
go
back
one
right.
We
have
to
be
able
to
handle
networking.
We
have
to
be
able
to
Hale
storage.
A
We
have
to
be
able
to
deal
with
the
fact
that
OpenStack
expects
to
have
configuration
in
a
way
that
is
different
than
what
kubernetes
expects
to
have
configuration
come
from.
Kubernetes
really
doesn't
do
that.
Well,
if
you
drop
a
lot
of
files,
because
files
are
persistent
objects
files
into
your
configuration
space
right,
we
don't
want
to
be
mapping
a
file
on
a
hard
disk
into
a
container
to
make
it
run
for
kubernetes.
We
can,
but
that
then
drives
a
whole
bunch
of
bad
behaviors
in
kubernetes.
A
So
there's
challenges
that
we
have
to
resolve
in
doing
this.
Now.
If
somebody
came
up
my
company's
been
playing
with
this,
we
have
some
demos.
I
have
a
video
that
I
can't
do
a
live
demo
for
this,
but
I
have
a
video
that
shows
doing
a
one-click,
laydown,
kubernetes
laydown
OpenStack,
on
top
of
it.
This
is
achievable.
A
I
think
that
within
it
with
a
couple
months
of
work,
especially
with
the
progress
and
interest
that
will
actually
see
this
being
a
very
practical
deployment,
but
you
you're
not
kubernetes-
doesn't
have
any
knowledge
of
the
infrastructure
so
to
make
this
work,
we're
going
to
have
to
poke
infrastructure
information
into
this
kubernetes
deployment
and
then
have
that
drive
the
helm
charts,
which
then
drives
the
deployments.
So
there's
there's
work
that
we
need
to
do
to
make
all
this
stuff
go.
A
You
know,
do
the
gratuitous
plug
for
what
rack
and
does
we
do
an
open
source
project
called
digital
rebar
that
collects
a
whole
bunch
of
infrastructure
information
and
then
can
inject
it
into
installs.
So
right,
it's
possible
to
do
that
if
without
something
like
what
we
do,
you're
going
to
be
making
ansible
flexible
rolls
or
hand
crafting
helm
charts
to
have
that
infrastructure
information
in
it
right
and
this.
This
is
one
of
the
places
where
kubernetes
is
a
stretch
for
OpenStack
right.
Kubernetes
job
is
to
make
you
not
care
about
infrastructure.
A
It
really
hides
a
lot
of
the
infrastructure
information
that
you
would
want
to
do.
A
good
OpenStack
deployment.
If
you're,
if
you're
building
a
SEF,
you
want
to
know
where
the
SSDs
are,
because
you're
going
to
need
to
put
your
your
caches
on
SSD
you're,
going
to
want
a
jaybird
array
and
you're
going
to
want
the
drives
enumerated
to
build
that
SEF
cluster
right
makes
perfect
sense.
None
of
those
things
are
going
to
show
up
in
kubernetes.
A
It
doesn't
have
any
infrastructure
information,
so
you're
going
to
have
to
add
it
into
the
helm,
charts
or
add
it
into
the
configuration
when
you
bring
up
that
stuff
cluster
and
then
you're
going
to
have
to
know
which
nodes
that
SEF
cluster
is
coming
up
on.
So
it
has
the
correct,
drive
information
and
then
that's
why
I
told
you
there's
work
to
do
and
then
we
want
to
do
this
in
a
way.
A
That's
generic
because
it's
not
helpful
for
the
community
if
you
can
spin
this
up
in
your
lab
or
in
your
facility
and
you've
handcrafted,
helm,
charts
and
somebody
turns
around
and
makes
an
improvement
and
your
forked
so
part
of
the
goal.
For
this,
a
huge
part
of
the
motivation
for
doing
it
is
that,
if
you're
using
this
approach,
we
want
to
be
able
to
have
everybody
benefit
from
improvements
within
the
community
right
we're
actually
moving
into
a
place
where
the
kubernetes
platform
allows
us
to
start
sharing
operational
lessons
and
improving
together
as
a
community.
A
If
we
start
forking
it
to
make
this
stuff
happen,
we've
reduced
the
benefit
for
that
right.
I,
don't
want
to
see
us
have
you
know
operational
chaos
version
two
where
everybody's
doing
kubernetes
on
OpenStack,
but
we're
all
doing
it
differently
right.
We
really
want
to
be
able
to
find
ways
to
bring
that
that
work
back
in
as
a
parenthetical
aside,
if
even
in
the
kubernetes
community
we're
struggling
with
this.
Just
like
OpenStack
struggled
with
it,
there
were
there's
a
list
of
over
60
different
ways
to
install
kubernetes.
A
It's
not
really
quite
that,
but
there's
a
significant
number
of
people
who
have
picked
up
different
ways
to
do
it.
My
company
is
working
very
hard
to
not
follow
that
pattern
and
that's
why
we
use
the
cargo
ansible
playbooks
straight
out
of
community
right.
We
do
not
want
to
have
any
custom
kubernetes
deployments
at
all.
We
don't
have
any
custom
OpenStack
deployments
right
design
from
our
perspective.
A
Distro
is
an
anti-pattern
for
the
core
core
aspects
of
this
technology
right
everybody
we
talked
to
wants
to
stay
in
upstream
for
something
like
a
deployment
or
the
core
bits,
and
so
we're
working
very
hard
to
do
that
and
I
think
it's
important
here,
I
have
one
more
point,
yeah,
so
configuration.
So.
The
idea
here
is
immutable
infrastructure.
How
many
people
are
familiar
with
the
term
immutable
infrastructure,
awesome
wow
this?
This
is
on
a
great
curve.
A
So
the
idea
here
is
that
part
of
part
of
the
challenge
with
this
part
of
Sonya
I-
think
it's
going
to
have
to
come
back
upstream
for
OpenStack
is
dealing
with
immutable
infrastructure
from
a
configuration
point,
so
we
need
to
make
OpenStack
configuration
not
rely
on
configuration
files
that
have
to
be
injected
into
the
infrastructure
it
needs
to.
We
need
to
be
able
to
spin
up
a
service.
Have
it
pull
in
its
configuration
to
I?
Believe
Keystone
v3
has
some
of
those
capabilities
and
we
could
leverage
that.
A
And
I
just
spent
a
whole
bunch
of
time
talking
about
this,
so
I'm
not
going
to
try
and
reread
the
slide
right.
What
I
do
want
to
emphasize
is
the
point
with
this
is
to
try
and
get
OpenStack
into
a
more
operational
point
right.
I
we
have
to
look
at
look
at
what's
been
going
on.
We
have
not
been
converging
operational
practices
into
a
single
set
of
playbooks
or
roles
or
technologies
right.
We
continue
to
have
different
camps
of
deployers.
A
This
is
potentially
an
n
plus
one
problem,
but
what
I've
been
seeing
in
the
field,
in
my
conversations
and
in
the
hallways
here,
is
that
there's
a
significant
number
of
people
who
are
moving
their
deployment
patterns
and
plans
into
a
kubernetes
helm,
chart
approach,
which
means
I'm
very
optimistic-
that
we're
going
to
see
a
convergence
in
the
community
where
people
are
actually
working
on
this
approach
and
making
this
go.
Okay.
A
The
other
thing
that
makes
me
excited
is
seeing
kubernetes
on
metal,
which
I
think
is,
is
a
logical
conclusion
of
where
people
are
going
to
go.
This
approach
does
not
work.
If
you
don't,
if
you
think
kubernetes
will
not
run
on
metal
right,
kubernetes
is
the
base.
It's
going
to
be
the
thing
running
on
metal.
A
A
So
operability
is
not
solved
by
this
aspect
alone
right.
We
can't
just
rub
kubernetes
all
over
OpenStack
as
much
as
we're
trying
to
right
now
and
have
it
solve
our
operability
problems.
Operability
is
not
just
deployment,
it
is
logging
and
monitoring
and
all
these
other
important
pieces
we
have
to
provide
leadership.
Technical
leadership
has
to
be
motivated
to
solve
these
problems.
A
I
think
we're
already
in
a
position
where
OpenStack
isn't
isn't
the
data
center
operating
system.
At
this
point
right,
we
are
part
of
an
infrastructure
in
the
data
center.
I.
Don't
think
anybody
gets
to
claim
the
data
center
operating
system,
meso,
speed
and,
and
so
I
think,
there's
collaboration,
I
think
kubernetes,
ultimately
will
have
a
larger
footprint.
A
This
was
really
controversial
when
I
said
it
six
months
ago
and
I
want
to
support
it
now.
Even
so,
kubernetes
runs
in
Amazon
Google
on
OpenStack
and
azure
on
metal
on
raspberry
PI's.
It
is
showing
up
everywhere
with
very
little
friction,
which
means
that
developers
are
going
to
target
this
platform
and
use
this
platform,
and
it's
going
to
actually
have
a
bigger
footprint
than
people
who
are
going
to
run
and
deploy
OpenStack.
You
already
can
see
that,
and
so
it
is
very
important
if
you
take
nothing
else
away
from
this.
A
It
should
be
the
oh
I,
better,
be
figuring
out
kubernetes
or
some
other
container
scheduling
system,
because
that
is
going
to
be
the
first
thing
that
I
use
as
an
abstraction
layer
and
then
OpenStack
is
going
to
have
other
benefits
around
that
for
helping
me
with
VMs
and
things
like
that.
But
this
is
this
is
a
it's.
A
bigger
kubernetes
is
going
to
be
a
bigger
thing
and.
A
My
prediction
that
I'll
leave
you
with
is
in
2018
so
next
year,
next
time
where
we're
talking
about
OpenStack
installs
in
the
North
American
continent,
I
predict
that
kubernetes
will
be
the
install
method
that
people
are
using
and
I
have
I.
Have
data
I
can't
share
all
my
data,
but
I
have
good
reason
to
believe.
That's
true
cool.
Thank
you
appreciate
it.
A
A
A
So,
if
you
expect
to
configure
that
container,
you
were
making
a
decision
that
you
know
what
that
container
is
going
to
do
and
it
you
don't,
and
so
you
really
have
to
give
up
the
idea
that
you
know
ahead
of
time.
What's
going
to
happen
with
that
container
now,
OpenStack
requires
us
to
do
that.
So
we
pin
containers
to
machines
and
we
can
fudge
it,
but
it's
fudging
it.
It's.
It's
really
hurting
it's
actually
hurting
the
long-term
capabilities
of
how
this
stuff
would
work.
So
I
hope
that
that
helps
it's
a
great
question.
B
There
is
a
very
elegant
solution
for
that
problem
with
the
kubernetes
environment,
using
a
neat
container.
So
before
your
main
process
starts,
init
container
runs
it
before.
Then.
You
can
grab
from
the
config
map,
which
is
mount
to
your
port.
Whatever
configuration
information,
you
need
and
just
apply
to
the
process,
because
when
the
init
container
starts,
you
can
get
your
name
host
where
you
run
IP
address
pretty
much
anything.
It's
available.
You
push
down
to
your
main
process.
Your
main
process
comes
up
with
the
configuration
it
needs.
So
the
issue
is
not
the
issue.
A
Good,
so
this
isn't,
you
know
one
of
the
things
I
love
about
giving
this
talk
is
we're
consistently
finding
places
where
you
know
either
I
didn't
know
something
that
we
could
do
or
we're
finding
people
or
solving
these
problems
much
faster.
So
this
has
been
a
really
exciting,
fast-moving
project
and
we're
going
to
continue
to
see
progress
and
evolution,
which
reinforces
my
point.
Thank
you
appreciate
the
time.