►
From YouTube: An Introduction to Feature Flagging & OpenFeature
Description
No description was provided for this meeting.
If this is YOUR meeting, an easy way to fix this is to add a description to your video, wherever mtngs.io found it (probably YouTube).
A
Hi
everyone
and
welcome
to
the
cncf
on-demand
webinar,
an
introduction
to
feature
flagging
and
open
feature.
So
in
this
call
I'm
going
to
explain
why
a
software
developers
and
sres
are
software
needs
to
be
delivered
safely.
I'll
talk
about
some
ways
to
do
this,
that
the
industry
is
already
doing
and
how
those
techniques
relate
to
Progressive
delivery.
A
The
first
demo
will
be
in
a
non-kubernetes
setup
and
the
second
will
be
on
a
kubernetes
cluster,
so
who
am
I
I'm
Adam,
Gardner
I'm,
a
cncf
and
continuous
delivery,
Foundation
Ambassador
I
work
for
dynatrace
and
I
contribute
to
and
maintain
a
number
of
Open
Source
projects,
as
you
can
hear,
from
the
accent
I'm
originally
from
the
UK,
but
now
live
in
Brisbane
Australia
and
outside
work.
You'll
probably
find
me
in
on
or
under
the
sea,
because
my
favorite
hobby
is
scuba
diving.
So
enough
about
me,
what
is
open
feature
well.
A
I'll
get
into
the
details
later,
but
for
now
understand
that
openfeature
exists
to
bring
standardization
across
the
open
source
feature
flagging
tools
in
the
commercial
vendors
that
are
out
there
feature
flagging
is
useful
for
both
day
one
activities,
that
is
the
actual
deployment
of
the
software
and
day
two
activities
or
the
day-to-day
running
of
the
application
and
I'll
I'll
talk
about
both.
But
let's
start
on
day
one,
let's
start
with
the
basics,
getting
software
to
the
end
user.
So
you
know
you
want
to
get
that
software
to
users
as
quickly
as
possible.
A
So
let's
talk
about
some
of
the
existing
techniques
that
are
currently
used
to
deliver
software
to
end
users
on
day
one
and
the
most
basic
way,
of
course,
is
just
to
set
up
a
time
of
day
that
your
website
or
service
will
be
down.
You
tell
your
end
users
about
this
in
advance
and
then,
when
the
time
comes,
you
just
send
them
all
to
a
holding
page.
You
turn
off
version
one,
and
then
you
turn
on
version
two
when
you're
nice
and
ready
send
everyone
back
to
the
website,
and
now
everyone
gets
version.
A
Two
all
done
this
technique
is
simple
and
it's
cost
effective.
It
requires
no
or
little
additional
staff,
training
or
tooling,
but
it's
not
so
good
for
Mission
critical
applications.
You
know
the
really
important
ones
that
actually
make
you
the
money.
Imagine
Google
going
down
every
time
they
wanted
to
do
an
upgrade.
A
Potentially
it
can
also
cause
you
headaches.
Imagine
that
this
is
for
an
internal
system.
Okay
and
you
update
that
internal
system
or
at
4am
on
a
Sunday.
That's
fine
and
no
one
is
using
the
system.
So
there
are
no
complaints,
but
when
will
you
know
about
that?
First?
Well,
the
first
time
you're
going
to
know
about
that
is
Monday
morning
when
everyone
tries
to
log
in
and
now
guess
how
many
tickets
you're
going
to
have
come
Monday
lunchtime
sitting
in
your
queue.
A
The
second
technique
is
called
a
blue
green
deployment.
With
this
technique,
you
spin
up
a
complete
replica
of
the
environment
so
of
production
for
the
new
version
for
the
Green
version
and
when
you're
ready,
you
switch
everyone
from
old
to
new
from
blue
to
green.
This
has
the
benefit
of
being.
You
know,
on
paper
at
least
a
fairly
easy
deployment
method.
The
the
big
downside
here
are
cost
and
complexity.
A
You've
at
least
double
your
Cloud
Bill
and
then
add
on
staff
costs
and
time
to
build
the
new
environment
and
figure
out
how
to
actually
do
this
and
then
build
in
any
sub
security
or
observability
that
you
need,
etc,
etc.
The
other
thing
you
might
have
noticed
about
these
deployment
strategies
is
they're
blunt
instruments
either
everyone's
on
version,
one
or
everyone's
on
version.
Two.
A
Wouldn't
it
be
nice
to
be
a
little
bit
more
granular
about
who
is
is
on
which
version-
and
this
is
where
Canary
deployments
can
come
in
so
coal
miners
used
to
take
canaries,
the
birds
down
the
mines
with
them,
the
idea
being
that
the
birds
were
the
safety
net.
Coal
mining,
of
course,
can
release
deadly
gases
and
the
birds
were
more
sensitive
to
this
gas
than
the
miners.
A
A
On
the
other
hand,
if
nothing
goes
wrong,
you
know
that
you
can
roll
out
to
a
slightly
higher
percentage
of
users,
for
example
five
percent-
you
repeat
the
process
until
of
course,
hopefully
everyone
is
on
version.
Two,
so
Canary
releases
can
limit
the
blast
radius
of
changes
and
and
with
that
you're
starting
to
progressively
deliver
your
software.
That
is
delivering
software
in
small,
controlled
increments.
The
advantages
to
Canary
releases
are
that
you're
testing
in
production,
you're
testing,
with
real
users
and
real
traffic
and
real
infrastructure.
A
You,
the
the
users,
are
using
the
system,
the
real
the
way
real
users
do.
You
can
do
true,
side-by-side
comparisons
of
version,
1
and
version.
Two
Canary
deployments
can
be
lower
cost
than
blue
or
green,
because
at
the
end
of
the
day,
you've
only
got
one
production
environment
about
having
said
that,
costs
can
easily
spiral
with
Canary
deployments.
You
need
extremely
thorough
observability
to
make
sure
that
you
can
catch
anything
with
those
you
know
with
that
subset
of
canary
users
and
that
that
observability
is
not
an
easy
thing
to
get
right.
A
You'll
probably
also
need
to
buy
build
additional
tooling
to
actually
do
the
canary
deployment
releases
and
then
you'll
have
all
of
the
Hidden
costs,
like
staff,
training
and
enablement
on
all
of
this
new
technology
to
enhance
Canary
releases.
To
take
it
one
step
further:
wouldn't
it
be
nice
to
have
a
way
to
be
even
more
granular
about
who
is
targeted?
What
about
only
the
testers,
getting
the
new
version,
or
only
the
customers
who
want
the
latest
and
greatest
and
maybe
have
have
signed
a
disclaimer,
accepting
that
potential
risk?
A
What
about
people
in
a
certain
country,
I?
Think
I
heard
a
story
that
Facebook
roll
out
their
new
features
to
New
Zealand
first,
because
obviously
they're
first
in
the
world,
it's
a
small
country,
so
it's
a
natural
canary
so
with
traditional
canaries.
To
do
that,
you
need
extra
infrastructure,
maybe
a
service
mesh
or
a
load
balancer,
that's
kind
of
able
to
inspect
that
layer,
7
traffic
and
make
those
Intelligent
Decisions
based
on
the
you
know
some
value
in
the
traffic.
Again,
though,
that
increases
cost
and
complexity.
A
So
if
standard
deployments
in
blue
green
are
the
hammer
and
canaries
are
the
knife,
then
what
are
feature
flux
well
feature
flux
can
be
your
scalpel
feature.
Flags,
give
you
the
ability
to
do
that:
cool,
Advanced,
Canary
layer,
7
traffic,
routing
stuff,
without
requiring
new
infrastructure
or
redeployments.
But
there
is
a
mindset
shift
because,
unlike
the
other
deployment
methods,
you
don't
deploy
and
run
two
copies.
Two
tube
versions
of
the
of
the
code.
You
run
one
copy
and
you
you
deploy
the
features
and
all
new
features
are
hidden
behind
feature
Flags.
A
So
unless
you
explicitly
enable
the
feature
flag
or
enable
the
users
to
to
access
the
feature
Flags,
then
the
feature
itself
is
hidden
now
feature
Flags
also
live
outside
of
your
application,
and
so
the
changes
to
those
can
take
effect
immediately
without
a
redeployment
or
a
restart,
and
if
you
think
about
it
using
feature
Flags,
you
you've
gained
the
ability
to
do
Canary
deployments
almost
automatically
feature.
Flags
can
also
help
on
the
day
two
operations.
A
You
know
that
kind
of
day-to-day
BAU
running
of
the
application
once
it's
actually
in
production,
because
if
the
sres
find
an
issue
in
the
application,
they
can
reconfigure
the
feature
Flags
again
from
outside
to
change
the
behavior
of
the
application
at
runtime
and
you'll
actually
see
this
later
in
the
in
the
demos.
Now,
if
there
is
a
downside
to
feature
flags
as
that,
they
do
need
to
be
put
into
the
application
by
the
developers
feature
flags
are
not
something
that
can
be
bolted
on
after
the
fact
feature.
A
Flags
are,
then,
a
software
development
concept
that
allows
you
to
enable
disable
or
change
the
behavior
of
a
feature
in
the
application
without
modifying
the
source
code
or
requiring
a
redeployment.
So
what
does
the
architecture
of
a
feature
flag?
Enabled
application
actually
look
like?
First,
of
course
you
need
a
feature
flag
provider.
This
is
the
source
of
your
feature
Flags.
It
could
be
something
you
developed
in-house,
an
existing
open
source
project
or
it
could
be
a
paid
for
vendor.
A
A
It
is
that
that
you
need
your
application,
could
also
send
contextual
information
such
as
the
user's
location,
their
email
address,
their
loyalty
tier
or
you
know,
whatever
is
important
to
to
maybe
change
the
decision
of
the
flag,
because
the
feature
the
flag
provider
can
then
use
that
information
to
change
the
value.
That's
sent
back
to
your
application.
A
So,
for
example,
imagine
a
new
feature:
that's
disabled
for
Everyone
by
default,
it
is
released
safely
because
it
is
disabled
by
default,
though
your
flag
definition
contains
a
rule
that
says
well,
if
I
get
contextual
information
that
the
user
is
in
the
testing
group
instead
of
sending
back
disabled,
enable
it
for
them
send
back
enabled
and
that
way
the
testers
can
access
the
feature
in
production,
but
only
they
can,
and
that
sounds
perfect
right,
but
I
mean
we
again.
We
live
in
the
real
world,
so
let's
scale
that
up
to
a
realistic
size.
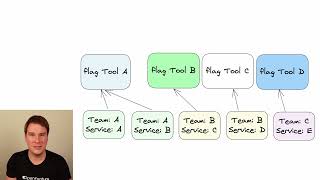
A
So
now
you
have
multiple
Services,
multiple
teams
in
your
organization.
So
imagine
the
best
case
scenario
here.
The
business
has
mandated
that
all
of
the
teams
in
this
organization
use
a
particular
feature
flag
provider
and
that
would
seem
to
be
problem
solved
right.
Well,
what
happens
if
the
business
decide
to
change
the
feature
flag
provider?
Now
every
team
has
a
huge
job
to
recode,
all
of
that
plumbing
in
their
application
and
redo
it
for
whatever
new
provider
the
business
decides
they're
going
to
use.
A
That's,
of
course,
a
lot
of
time
and
money
spent
just
to
move
providers
now
imagine
a
more
realistic
scenario
in
which
each
team
has
kind
of
organically
adopted
the
feature
flags
that
they
use
and
they've
all
decided
to
use
whatever
provider
they
like
you
know
at
the
time
when
they
they
adopted
it
developers
from
one
team,
can't
easily
transfer
to
another
team.
They
need
to
learn
that
new
feature
flag
provider
and
the
ways
to
interact
with
it.
More
importantly,
nothing's
the
same.
A
The
teams
can
experiment
with
different
providers
until
they
find
one
that
really
fits
their
their
requirements.
How
could
you
write
such
a
layer,
yeah
yeah?
Of
course
you
could.
But
again
it's
time
and
effort
to
write
and
maintain
it,
and
also
what
I've
just
described
is
the
open
feature
specification.
So
at
this
point,
you're
probably
also
thinking
yeah.
Well,
that's
nice,
but
I've
got
environment
variables,
I'm,
absolutely
fine.
Things
are
working
perfectly
and
environment
variables
are
primitive
feature.
A
Flags
configuration
can't
be
changed
without
a
redeployment
or
a
restart,
or
at
least
a
recompilation
environment
variables
also
have
no
no
contextual
awareness,
so
they
have
little
to
no
meaningful
Telemetry
data.
So
you
know
if
you
change
an
environment
variable.
Judging
the
impact
of
that
is
is
hard,
if
not
impossible,
so
how
I
mean
you
could
and
and
probably
will
decide
to
extract
the
environment
variables
to
somewhere
outside
of
your
application,
for
example,
you
you
might
start
by
storing
them
in
a
database.
A
This
is
a
step
in
the
right
direction,
as
it
can
also
add,
contextual
support,
but
your
application
code,
as
you
can
see,
still
contains
that
hard-coded
knowledge
of
those
conditions
so
in
this
example,
you're
stuck
with
checking
users
locations
and
without
a
recode
and
a
redeployment,
nothing
else
so
moving
all
of
that
logic
out
into
a
feature
flag
provider
like
this,
gives
you
really
Advanced
capabilities.
Now,
experiments
can,
you
know,
be
be
run
and
deployed
and
updated
independently
of
the
application
code,
and
it's
also
fully
observable
so
obviously
open
feature
is
compatible
with
open
Telemetry.
A
You
can
see
Tracer,
spans
and
metrics
for
which
flag
variants
were
used,
why
they
were
used
when
they
were
used
and
more
crucially,
what
impact
they
had
on
the
end
user.
So
here
are
some
other
scenarios
that
feature
Flags
can
Target
what
if
the
code
is
ready,
but
the
business
is
not.
How
do
you
ship
the
code
and
move
on
without
holding
up
your
other
teams?
A
What,
if
the
feature
is
implemented
across
multiple
Services?
How
do
you
coordinate
the
deployments
of
those
Services?
What,
if
you
want
to
enable
the
feature
sudo
randomly
to
see
how
it
impacts?
You
know
real
world
usage
or
performance?
So
now
that
we
have
a
background
of
the,
why
feature
Flags,
you
know
why
feature
flags
are
so
necessary.
What
exactly
is
open
feature
well
open
feature
is
a
cncf
Sandbox
project
and
it's
an
open
standard
that
provides
a
vendor
a
tool.
Agnostic
API
for
feature
flagging.
That
works
with
your
favorite
feature.
A
Flag
Management,
System,
open
feature
is
not
a
feature
flag
provider;
it
is
the
standard
to
which
feature
flag
providers
conform.
So
here's
an
example
of
an
open
feature
code
snippet
to
retrieve
a
Boolean
value
notice,
the
first
line.
We
we
tell
open
feature
about
our
provider
and
then
we
request
that
open
feature
retrieves
a
Boolean
value
from
our
provider.
The
provider
is
the
translation
code
which
transforms
that
standard
get
Boolean
value
which,
by
the
way,
never
changes,
regardless
of
which
provider
you
decide
to
use
in
the
future
into
the
tool.
Specific
API
calls.
A
So
don't
worry
the
the
tool
maintainers
and
the
vent
does
write
the
provider
code,
so
that
part
is
actually
already
done
for
you.
You
don't
even
need
to
know
their
apis.
So
what
does
all
of
this
mean
well?
Trying
out
a
new
provider
is
as
simple
as
changing
that
first
line
of
code.
Second,
you
write
your
flag,
retrieval
code
once
the
get
Boolean
value
and
you
never
have
to
touch
it
again.
A
It
doesn't
change
based
on
which
provider
you
use,
and
third,
every
team
now
has
a
single
common,
well
understood
and
well-specified
way
to
use
feature
Flags.
So
talking
of
the
tools
and
the
vendors
open
feature
is
being
developed
with
the
industry.
It's
not
like
open
feature
is
coming
along
and
saying.
This
is
how
you
do
it.
What
that
means
is
it
almost
certainly
already
works
with
your
favorite
tool
or
vendor,
and
even
if
you
have
a
homegrown
flag
provider
like
a
database,
it's
easy
to
add
support
for
your
homegrown
solution
as
well.
A
So
it's
time
to
see
open
feature
in
action
and
for
the
first
demo,
I'm
going
to
be
using
an
open
source
open
feature,
compliant
flag
provider
called
flag,
D,
so
flag.
D
is
a
tool
that
implements
open
feature
flag.
D
is
not
open
feature
flag,
D
comes
as
a
binary
and
a
Docker
container,
so
it
can
run
as
a
service
as
I'll
show
you
in
the
first
section
or
as
you'll,
see
in
the
second
demo
that
I
do.
A
You
can
run
it
as
a
sidecar
in
kubernetes,
so
flag,
D
reads
one
or
more
flag
sources
that
are
that
is
Json
files
or
yaml
files
and
makes
those
flags
available
via
an
API.
So
in
this
demo,
I'll
show
you
how
feature
flags
are
read
at
runtime,
without
a
redeployment
of
the
the
application
being
necessary.
I'll
then
show
flagity
reading
from
multiple
flag
sources,
in
my
case,
Json
files
and
then
I'll
extend
that
basic
flag
to
include
contextual
information.
A
The
the
flag
is
reconfigured
to
return,
one
of
three
values:
Triple
A
by
default
for
all
users,
Triple
B,
for
any
users
where
we
pass
an
email
ending
in
at
openfeature.dev
and
Triple
C
for
any
users
using
the
Chrome
browser
for
finally
I'll
show
fractional
evaluation,
and
this
is
useful.
If
you
want
to
pseudo
randomly
assign
requests
or
users
to
different
buckets
in
the
demo,
any
users
with
email
addresses
ending
in
at
faas.com
or
fictional
company.
A
So
the
second
demo
will
be
kubernetes
native
deployment
of
flag
D,
we'll
use
the
open
feature
operator
and
its
job
is
to
watch
for
custom
resources
and
ensure
that
the
right
pods
have
the
right
values
dynamically
and
at
runtime.
The
open
feature
operator
makes
these
values
available
without
a
restart
of
the
Pod
and
thus
without
any
downtime.
A
This
demo
scenario
this
UI,
this
web
page,
will
be
available
for
you
to
experiment
with
it
uses
killer
coder.
So
thank
you
to
killakota
for
providing
the
infrastructure
for
this.
So
as
you
load,
this
everything
starts
everything
kind
of
installs
in
the
background
and
you
get
gitty,
which
is
a
git,
a
git
repository,
so
we've
pre-loaded
a
repo
in
here
with
some
flag
values.
So
this
Json
file
is
the
format
in
which
flag
D
expects
Flags.
A
So
you
can
see
here
we
have
a
number
of
flags,
one
called
my
bull
flag,
one
called
my
string
flag
and
they
just
return
different
types
of
variants.
So
variants
are
the
possible
results
and
if
we
look
at
my
bull
flag,
you'll
notice
that,
by
you
know,
the
default
variant
is
on
meaning
everyone
right
now
gets
on.
So,
however,
you
request
my
bull
flag,
you're,
always
going
to
get
on
returned
these
names,
my
bull
flag,
my
string
flag,
that's
up
to
you!
That's
your
flag!
Key!
A
If
we
scroll
down
and
look
at
something
a
little
bit
more
complicated,
we've
got
a
flag
called
FIB
algo.
It
has
possible
variants
of
recursive
memo,
Loop
and
BNA
and
of
course
the
default
variant
is
recursive.
So
you
can
read
that,
as
there
are
a
number
of
possible
results
when
we
evaluate
this
flag,
but
right
now
by
default,
everyone
is
just
going
to
get
the
recursive
string.
Now
our
application
will
use
that
to
use
the
recursive
algorithm
for
Fibonacci
calculation,
but
there
is
a
targeting
rule
here
that
references
a
rule
set.
A
A
So
if
we
scroll
all
the
way
to
the
bottom,
we've
got
this
email
with
fast
and
it
basically
says:
well
if
the
VAR
is
email
and
if
the
value
that
we
pass,
if
at
fas.com
is
in
that
string
that
we
pass,
then
it's
true,
then
the
rule
is
true,
so
you
can
read
that,
as
our
application
is
going
to
take
the
user's
email
address
pass.
It
back
through
open
feature
to
the
to
flag,
D
flag.
A
A
So
let's
see
that
in
action,
let's
start
flag
D
in
tab,
one
and
I'll
open
a
new
tab.
I'll
leave
that
running
and
I'm
just
going
to
test
that
flag.
D
actually
works,
so
I've
just
done
a
post
to
the
flag,
the
endpoint
notice
it
is
on
Port
8013
I've
asked
it
to
resolve
a
string
and
I've
passed
it.
The
header,
color
flag,
key
and
I
haven't,
given
it
any
context,
and
so
the
value
has
come
back
as
red
and
the
reason
is
default
and
the
variant
is
red.
A
A
A
I'll
commit
the
changes
and
then
I
will
re-request
the
feature
flag
and
now,
of
course,
we
get
yellow
as
expected.
So
in
a
real
system,
you
could
have
multiple
sources
of
the
flags.
You
might
have
multiple
teams
or
multiple
developers
working
on
different
bits
of
their
code
and
they
have
their
flags
and
you
have
yours,
how
do
you
have
flag
D?
A
You
read
both
of
those
sources
of
flux.
Well,
that's
that's
possible.
So
what
I'm
now
going
to
do
is
create
a
new
file
with
a
new
flag
called
brand
new
flag
and
write
it
to
disk
now
I'm
going
to
attempt
to
retrieve
that
new
flag
value
from
flag
D
and
of
course
this
should
fail
because
we
haven't
told
flag
D
about
the
new
file
yet
and
of
course
there
we
are,
it
does
not
found
flaggedy
error
flag,
not
found
as
as
expected.
A
Now,
what
I'm
going
to
do
is
restart
flag
D,
so
I'll
flip
back
to
tab,
one
and
I'll
restart
it
pointing
at
both
files,
so
I've
just
repeated
the
URI
command
one
pointing
to
our
existing
Flags
stored
in
on
a
web
server
in
in
git
and
the
other
on
a
local
file
in
templocalfi
flags.json.
So
now
I'll
go
back
to
Tab,
2
and
retrieve
that
new
flag.
Again
and
this
time
we
do
get
a
value
we
get
a
the
value.
A
Is
this
and
the
reason
is
static,
so
that
proves
that
flag,
D
is
actually
reading
both
of
those
flag
sources
and
making
them
both
available
via
the
API
to
me
and
as
a
developer.
I
then
don't
have
to
care
where
my
flags
are
stored.
Okay,
so
that
was
a
very
basic
set
of
flags.
They
were
pretty
much
almost
environment
variables.
They
were
on
or
off
apart
from
the
targeting
groups.
Let's
look
at
something
a
little
bit
more
complicated.
Now
in
the
flag
Json
file
in
gitty,
you
have
a
flag
called
targeted
flag.
A
Again,
we've
got
a
number
of
variants
first,
second
and
third,
and
the
default
variant
is
first,
but
now
we've
got
a
couple
of
different
rules.
We've
got
a
rule
that
says
if
the
email,
if
the
variable
email
is
passed
and
at
openfeature.dev,
is
in
that
string,
then
those
users
get
the
second
variant
so
BBB
in
this
case
or
if
the
email
Isn't
passed,
but
user
agent
is,
and
it's
cro
and
chrome
is
in
there.
Then
those
users
get
third
and
everybody
else
just
gets
the
default
variant.
A
A
Now,
let's
try
it
passing
the
context
with
email
as
the
key
and
me
at
openfeature.dev
as
the
email
address,
and
you
can
see
it's
a
targeting
match
because
we
get
BBB
and
we
get
second
and
now.
Finally,
let's
do
Chrome
again.
User
agent
is
chrome123
and
we
get
CCC.
So
now,
let's
look
at
the
thing.
I
talked
about
earlier,
the
pseudo-random
evaluation.
If
you
look
at
the
header
color
flag
again,
we've
got
some
variants.
We've
got
a
default
variant
that
previously
we
set
to
Yellow.
A
Now
we've
got
some
targeting
rules
that
you
have
already
seen
the
email
with
fas.com,
but
this
time
we've
got
a
a
fractional
evaluation
and
what
it
does
is
it
takes
the
value
of
the
email
address
that
is
coming
through
and
then
25
of
those
matching
email
addresses,
get
the
red
variant
on
line
90.
25
of
them
get
blue
25
get
green,
a
25
get
yellow.
If
you
keep
sending
the
same
email
address
I.E
the
same,
you
know,
string
they'll,
always
get
the
same:
color
they'll
always
get
red
or
they'll
always
get
blue.
A
So
let's
see
that
now
so
I'm
going
to
pass
user1
at
fas.com
now,
I,
don't
know
which
variant
this
is
gonna
get,
but
it
will
always
now
that
it's
got
red.
It
will
always
get
red,
no
matter
how
many
times
I
run
this
command.
I'm,
always
going
to
get
red
if
I
pass
user
2
at
fas.com,
I
randomly
get
green
and
I'm
always
going
to
get
green
and
so
on,
and
so
forth
now,
just
to
prove
that
the
default
variant
I.E,
if
I,
don't
pass
a
context.
A
We're
back
to
Yellow,
remember
that
was
the
default
variant,
so
there
you
are
by
by
mixing
and
matching
those
rules.
You
can
create
very
complicated
logic
and
that
logic
actually
lives
outside
of
your
application
at
runtime.
So
you
don't
need
any
restarts
or
redeployments
as
you
change
this
stuff
and
and
most
feature
flag
systems.
Allow
things
like
targeting
rules.
Most
vendors
allow
targeting
rules
and
and
contextual
evaluations
like
this
so
yeah.
That
is
the
first
demo
and
now,
let's
jump
into
the
second
demo,
which
again
uses
flag
D,
but
in
a
kubernetes
environment.
A
So
here
we
are
looking
at
the
online
demo.
The
links
will
be
in
the
video
description,
so
you
can
play
around
with
this.
So
we
have
a
kubernetes
cluster
with
the
open
feature
operator
installed.
So
what
does
the
operator
do?
Well,
here
is
our
demo
application
and
you
can
see
Fibonacci
as
a
service
is
pretty
slow.
It
takes
about
four
or
five
seconds
to
do
our
business
logic,
to
generate
the
number
that
the
customers
need.
A
So,
let's
see
how
we
can
use
feature
Flags
to
test
out
our
new
algorithm
for
the
open
feature
operator
will
wait
for
and
read
any
custom
resource
definitions
that
are
defined
as
feature
Flags.
So
let's
have
a
look
at
our
feature
flag
as
it
stands
at
the
moment.
So
we
have
a
custom
resource
called
feature
flag
configuration,
and
this
one
is
called
end
to
end
now.
Within
there
we
have
a
number
of
feature
Flags.
The
first
one
is
called
New
welcome
message.
The
second
one
is
called
hex,
color
and
so
on
and
so
forth.
A
So,
looking
at
the
feature
flag
that
controls
the
Fibonacci
algorithm,
that
is
in
use,
the
demo
scenario
talks
about
a
slightly
different
use
case
and
you
can
see
that
it's
actually
targeting
users
with
any
app
fas.com
email.
So
we're
going
to
change
that
now,
just
to
Target
Sue.
Remember
in
our
scenario:
Sue
is
the
only
user
that
should
be
able
to
use
the
new
algorithm
initially.
A
Okay,
so
the
way
to
read
this
FIB
algo
feature
flag
is
that
it
is
enabled
and
it
has
a
couple
of
different
variants.
These
are
the
possible
values
that
could
be
returned
to
our
application
that
our
application
can
then
use
to
perform
its
logic.
So
we
have
the
recursive
algorithm.
We
have
a
memo,
a
loop
and
a
BNA
algorithm
Now
by
default,
everyone
gets
the
recursive
algorithm.
A
However,
we've
added
an
optional
targeting
rule
to
say:
if
the
email
address
that
we
pass
from
the
front
end
is
Sue
at
fais.com,
then
sue
and
only
Sue
gets
the
BNA
algorithm
by
default.
Otherwise,
if
it
doesn't
match,
we
are
back
to
the
recursive
algorithm.
What
this
means
is
all
users
will
get
the
recursive
algorithm
except
Sue.
So
let's
apply
our
updated
feature
flag
now,
as
a
logged
out
user
I
should
still
get
the
slow
version.
That's
safe!
That's
the
safe
default!
A
A
A
A
Shows
that
Bob
gets
the
new
quick
algorithm,
but
if
we
log
out
of
Bob
and
log
in
as
Ian
Ian
should
still
get
the
slow
version,
and
indeed
he
does
so
we're
starting
to
progressively
roll
out
our
software
in
a
safe
way
over
time.
More
and
more
users
will
be
able
to
use
the
software
that
without
impacting
other
users,
that
we
don't
want
to
so
now.
Imagine
that
we've
finished
rolling
out
to
individual
users
or
teams,
and
we
want
to
just
roll
out
to
anyone
with
an
at
fais.com
email
address.
A
A
And
because
of
the
catch-all
rule,
Sarah
should
get
the
new
version,
fantastic
we're
in
complete
control
at
runtime
of
who
is
able
to
use
this
new
feature
and
who
can't
eventually
we're
going
to
be
in
a
position
that
we
want
to
roll
out
this
to
all
users,
not
just
selected
or
internal
users,
and
that's
great
that's
easy
to
do
to
do
so.
Just
remove
the
targeting
Rule
and
change
the
default
variant
from
recursive
to
binay.
A
Save
the
flag
reapply
the
changes,
and
now
even
the
unauthenticated
users
will
get
the
fast
algorithm
doing.
Progressive
delivery
in
This
Way
shows
that
we
can
roll
out
and
roll
back
in
case
there
is
an
issue
safely
and
at
any
time.
One
other
thing
to
point
out
is
that
at
no
time
did
the
Pod
actually
need
a
restart.
You
can
see.
Our
pod
has
is
still
running
and
has
been
for
16
minutes,
so
there
was
absolutely
no
downtime
while
we
made
all
of
these
changes.
A
So
just
to
summarize,
you
install
the
open
feature
operator
that
installs
flag
D.
You
create
your
feature
Flags,
according
to
the
custom
resource
definition
specification,
and
then
you
annotate
your
application
with
two
new
annotations,
openfeature.dev
enabled
and
openfeature.dev
forward,
slash,
feature
flag,
configuration
and
then
the
feature
flag
or
feature
flags
that
you
need
to
use
in
your
application.
A
So
there
we
are
an
introduction
to
feature
flagging
and
open
feature.
If
you
want
to
get
involved,
the
project
would
love
to
have
you
flagde
the
tool
you've
seen
demoed
today
and
open
feature
both
live
on
GitHub
and
at
openfeature.dev.
The
project
is
also
on
the
socials.
On
Twitter
and
Linkedin
and
the
open
feature
channel
of
the
cncf
slack
openfeature
is
a
cncf
Sandbox
project
and
believe
me,
there's
still
plenty
of
work
to
be
done
and
plenty
of
voices
that
we
are
yet
to
hear
from
and
want
to
hear
from
so
do.