►
Description
No description was provided for this meeting.
If this is YOUR meeting, an easy way to fix this is to add a description to your video, wherever mtngs.io found it (probably YouTube).
A
And
we
will
get
things
going
thanks.
Everyone
for
joining
us
today
welcome
to
cncf's
live
webinar
kubernetes
data
protection
requires
orchestration,
canister,
dot,
IO
delivers
I'm,
Libby,
Schultz
and
I'll,
be
moderating.
Today's
webinar
I'm
going
to
read
our
code
of
conduct
and
then
hand
over
to
Michael
Coursey
solution,
architect,
principal
Cloud
native
project
manager,
both
with
castan
by
veeam
a
few
housekeeping
items.
Before
we
get
started
during
the
webinar.
You
are
not
able
to
speak
as
an
attendee,
but
there
is
a
chat
box
down
the
right
hand.
A
Sidebar,
where
you
can
leave
any
of
your
questions,
feel
free
to
drop
them
in
there
we'll
get
to
as
many
as
we
can.
At
the
end.
This
is
an
official
webinar
of
the
cncf
and,
as
such
is
subject
to
the
cncf
code
of
conduct.
Please
do
not
add
anything
to
the
chat
or
questions
that
would
be
in
violation
of
that
code
of
conduct
and
please
be
respectful
of
all
of
your
fellow
participants
and
presenters.
A
Please
also
note
that
the
recording
slides
will
be
posted
later
today
to
the
cncf
online
programs,
page
at
community.cncf.io,
under
online
programs
they're
also
available
via
your
registration
link
and
the
recording
will
be
available
on
our
online
programs.
Youtube
playlist
with
that
I
will
hand
things
over
to
Michael
and
Mark.
C
B
C
B
B
Sure
so
I've
been
G
j-e-e
architect
for
a
few
years,
so
I
was
really
on
the
development
side.
Then
I
start
to
help
different
teams
with
devops
process
and
one
day
kubernetes
under
the
scene,
and
we
had
to
deal
with
that
and
we
we
had
to
deal
the
the
protection
of
the
workloads
on
kubernetes.
That
was
one
of
my
tasks
and
we
were
looking
for
Solutions
like
kubernetes
cast
iron
and
other
kind
of
solutions
for
protecting
workload
on
kubernetes
and
then
I
naturally
moved
to
custom,
which
is
a
tool
really.
B
We
really
focus
on
that.
So
mainly
now,
I
can
describe
myself
like
a
solution
architect
at
Gaston
I
help
our
customer
to
deploy
casting
on
the
on
their
infrastructure
and
to
integrate
with
the
different
kind
of
database
that
they
have
to
manage,
and
this
different
kind
of
process
yeah
not
speaking
too
much
about
me.
But
that's
that
that's
yes,
a
good
scenario
of
what
I'm
doing
now.
A
C
C
We'll
wind
up
with
some
conclusions,
give
you
all
the
resources
that
we've
cited
in
this
presentation,
including
a
GitHub
repository
with
the
demonstration
code
and
then
we'll
get
to
your
q,
a
all
right.
Let's
get
started
so
when
we
start
talking
to
people
about
how
do
they
solve
their
organization's
ability
to
continue
running
no
matter
what
we
get
into
all
of
the
the
challenges
of
data
protection
and
the
the
time-honored
rule
is
the
three
two
one
backup
strategy.
C
You
need
three
kind
of
online
backups
of
of
your
data
in
two
different
locations
and
one
of
those
has
to
be
at
least
off-site
or
offline.
In
fact,
so,
bringing
that
forward
into
the
cloud
native
world
with
kubernetes
really
shows
a
whole
new
set
of
challenges
for
these
old
problems,
which
is
that
we
see
our
customers
and
our
our
prospects,
all
at
different
stages
of
adopting
kubernetes
and
their
maturity
with
Cloud
operations.
So
we're
going
to
get
into
all
of
that
staple
versus
stateless
workloads.
C
Why
a
lot
of
people
think
Etsy
backup
is
the
way
to
protect
kubernetes.
But
it's
not.
What
is
an
actual
application
consistent
backup,
and
why
would
you
need
to
do
that
instead
of
backing
up
a
kubernetes
cluster
and
ultimately
how
we're
going
to
get
to
exactly
to
how
canister
solves
this
problem
in
an
open
source
manner
to
give
you
application
consistent
data
protection
so,
first
and
foremost,
I'll
actually
show
you.
C
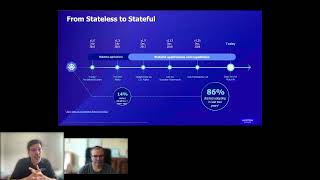
This
is
the
data
on
kubernetes
community
report
we'll
link
to
this
at
the
very
end,
we
see,
basically,
everybody
growing
for
the
last
couple
years
to
get
past
stateless
applications
and
finally
add
stateful
applications,
which
means
that
they
have
storage.
It
means
that
their
state
is
important
and
we'll
talk
about
exactly
those
workloads,
but
as
soon
as
you're
successful
with
kubernetes,
more
and
more
workloads,
more
and
more
complex
workloads
and
more
and
more
traditional
workloads
follow
there
on.
C
So
we
see
that
growth
exploding,
so
the
the
first
myth
and
question
a
lot
of
people
come
up
when
they
meet
us
is
isn't
everything
stateless
on
kubernetes?
Why
do
I
need
backup,
recovery,
disaster,
recovery
and
so
on?
And
the
answer
is
the
cluster
itself
has
a
lot
of
State,
not
just
NCD,
which
we'll
get
to
in
just
a
moment,
but
actually
all
of
the
secrets
all
of
the
configuration
and
when
we
go
even
back
to
2020.
This
cncf
found
that
55
of
their
respondents
were
already
running
safer
workloads.
C
C
So
getting
back
to
this
another
workload
that
we
see
more
recently
growing.
A
lot
is
even
traditional
virtual
machines
running
on
top
of
kubernetes
with
the
cube
vert
project.
Another
cncf
project
is
also
another
growing
workload
that
is
incredibly
stateful
and
the
reasons
for
that
are
as
many
But.
Ultimately,
our
customers
workloads
grow
and
they
grow
in
their
complexity
and
they
bring
more
traditional
workloads
on.
But
the
next
step
is
that,
well,
it's
not
just
enough
to
have.
C
If
you
don't
even
have
staple
workloads,
it's
not
enough
to
present
everything
as
being
stateless,
because
you
in
many
organizations
and
in
many
Industries
you
must
regulate,
you
must
be
able
to
audit.
You
must
be
able
to
be
prove
what
the
cluster
configuration
was
and
get
or
or
doing
it
by
hand
or
just
a
Wiki
document
is
not
enough.
Actually
backing
up
and
restoring
having
the
ability
to
restore
your
workloads
and
the
configuration
is
required
for
audit
purposes.
C
B
Yes,
what
about
you
said
that
everything
is
in
githubs
does
not
mean
that
everything
is
actually
in
the
in
in
the
kubernetes
cluster.
So
so
what
you
said
about
the
intent,
everything
should
be
like
GitHub
said,
and
what
you
really
have
is.
There
is
a
real
distance
from
a
legal
point
of
view.
You
can't
say:
I
have
to
prove
that
my
state
was
this
one
because
look
my
githubs,
my
github's
things
is
like
this.
You
need
to
prove
that
on
kubernetes
it
was
like
that,
and
only
on
kubernetes,
so.
B
Basically
is
the
source
of
Truth
and
from
my
experience,
what
I
can
say
is
even
if
the
good
organization
have
very
good
githubs
process
when
you
are
facing
urgency
when
you
are
facing
obsolescence
of
an
applications
when
you
are
facing
some
time,
ignorance,
many
people,
many,
we
see
many
cases
where
people
are
changing
things
manually.
So
the
deploy
is
a
github's
process.
Then
they
do
some
manual
change
and
it's
very
important
to
be
able
to
track
that
as
well.
C
So
yes,
this
is
the
reality
and
the
final
myth
that
we
also
have
to
explain
to
customers
is
that
just
because
they're
in
public
Cloud,
which
has
great
uptime,
don't
get
me
wrong.
They're
not
fully
protected
right,
they
have
outages,
they
still
need
to
satisfy
audit
requirements
and
ultimately,
every
public
cloud
provider
wants
you
to
do.
C
Disaster
Recovery
can
be
to
another
area
inside
that
public
cloud,
of
course,
but
we
have
many
of
our
customers
trying
to
figure
out
how
to
do
multi-cloud
using
kubernetes
to
be
able
to
do
hybrid
and
multi-cloud
workloads,
and
so
ultimately,
disaster
recovery
and
auditability
and
staple
workloads
is
the
maturity
Journey
that
everybody
takes
and
we
hope
you're
along
those
lines
too,
because
you
will
need
canister
later
on.
So
we've
covered
this
very
briefly.
We'll
have
links
for
these
at
the
very
end.
C
So,
let's
get
to
the
next
major
concern
that
most
people
have.
You
know
when
they
learn
about
kubernetes
one
of
the
first
things
they
they
learn
is
how
to
get
onto
the
cluster
and
then
how
to
insert
you
know,
custom
resources,
and
then
they
hear
that
you
know
backing
up
at
CD
is
the
way
to
preserve
the
state
of
everything.
And
while
this
is
true,
however,
in
reality
we
have
never
seen
anybody
successfully
do
at
CD
backup
and
restore
all
back
to
that
cluster.
C
C
Well,
so,
in
practice
also,
the
kubernetes
project
is
trying
to
lock
down
the
control
plane
as
much
as
possible
such
that
you
don't
have
access
to
even
do
SCD
backups
so
and
and
all
the
other
kubernetes
vendors
are
doing
this
as
well.
So
we
only
would
Advocate
if
you
are
are
beholden
to
this
strategy.
You
need
to
test
whether
or
not
it
actually
works.
Your
only
good
is
your
last
restoral,
but
the
truth
is
that
this
is
not
the
right
way
to
actually
do
backup,
recovery
and
Disaster,
Recovery
or
auditability.
B
I
would
say
that
if
you
are
in
the
situation
where
you
think
oh
I
should
restore
etcd
it's
most
of
the
time,
it's
too
late,
you
are
already
in
a
very,
very
bad
situation.
It's
it's
really
too
late.
The
best
is
to
rebuild
another
cluster
somewhere
and
to
restart
your
application
and
from
your
backup
that
that's
a
better
merger,
better
strategy,
if
you
have
a
backup
system,
recreate
your
application,
your
your
communities,
clusters
somewhere
else
and
restore
your
application,
but
don't
try
to
install
the
etcd
backup.
B
C
Yeah
and
it's
not
to
say,
you
can't
use
gitups
to
populate
things
on
that
new
cluster,
of
course,
but
you'll
need
to
ultimately
restore
the
state
as
well
and
not
org.
So
this
is
where
we
get
to
the
final
contention
and
the
takeaway
that
we'd,
like
you
to
have.
Is
that
really
the
applications
on
a
kubernetes
clusters
what's
important,
the
Clusters
should
become
cattle
should
become
ephemeral,
should
not
be
The
Logical
concern
of
how
you
do
backup,
recovery
and
auditing.
C
It
is
one
of
the
logical
concerns,
of
course,
but
the
applications
themselves,
their
state
and
their
configuration.
That
is
what
everybody
is
after,
so
when
you
approach
this
from
an
operation
standpoint
or
a
traditional
backup
standpoint
or
an
infrastructure
standpoint,
kubernetes
allows
us
to
finally
deal
with
the
entire
vertical
stack
top
to
bottom
application
infrastructure
and
all
the
operations
together.
C
C
Well,
most
people
think
that
once
they
have
persistent
workloads
and
persistent
volume
and
their
persistent
volume
claims
that
all
they
need
to
do
with
CSI
snapshots
volume.
Snapshots
is
that's
good
enough,
but
the
truth
is
while
that
may
be
a
crash,
consistent
snapshot
of
the
storage
on
disk.
At
that
point
in
time
it
is
often
and
I
would
argue,
almost
always
never
good
enough
right.
C
Potentially,
we
see
generic
backup
being
the
next
solution
that
most
people
do
where
they
mount
a
file
system
and
just
basically
take
copy
every
file.
But
this
and
the
next
step,
which
is
this
traditional
CSI
volume
snapshot.
All
of
these
have
failures
for
crash
consistency.
In
the
sense
that
until
the
application
and
all
the
data
is
at
rest
on
that
storage
medium,
you
do
not
have
a
proper
backup.
You
certainly
will
restore
it
and
not
get
what
you
thought.
C
So
we
see
backups
and
restorals
fail,
because
the
backups
weren't
crash
consistent
and
application
consistent.
So
the
next
level
up
from
that
is
logical
backups,
where
you
use
the
applications
backup
facility
if
it
exists
or
even
the
backup
operator
if
it
exists
as
a
way
to
do
an
application.
Consistent
backup-
and
this
is.
C
Better
state,
but
we'll
show
you
that
it's
not
the
final
state
of
of
how
to
achieve
this
properly.
So
what
we
see
you
know,
let's
say
you
mount
a
MySQL
container
in
a
pod
and
you
do
MySQL
dump
on
it
and
you
need
to
get
that
artifact
off.
What
happens
is
those
databases,
those
those
logical
backups,
those
files
grow
and
grow
and
grow
and
grow
and
they
don't
become
incremental.
C
You
have
to
figure
out
a
whole
new
way
to
manage
everything
in
order
to
even
get
to
incremental,
and
why
would
we
need
incremental
backups,
because
now
we
need
to
bring
down
the
database,
get
everything
logically
fleshed
on
disk
and
and
get
going
well
actually
I'm
getting
ahead
of
us.
That's
the
system.
C
Backup
long
story
short,
is
that
this
is
a
good
first
step,
but
actually
not
good
enough
and
not
state
of
the
art
of
what
we
have
in
the
more
traditional
area
of
bare
metal
and
VMS
for
backup
so
system
backups
are
really
where
we
are
in
that
world
more
traditional
world,
and
we
don't
have
that
exactly
on
kubernetes.
This
is
where
canister
comes
in.
We
need
to
actually
stop
the
application,
lock
the
application
or.
C
Invert,
all
those
operations
to
orchestrate
everything,
to
unlock
everything
and
get
the
application
back
to
a
fully
running
state.
This
is
where
we
go,
but
once
we
have
this
orchestrated
set
of
operations
for
system
backups,
we
need
to
then
orchestrate
all
those
Notions
and
then
figure
out
how
to
do
Deltas
or
incremental
backups,
because
that's
how
we
get
to
shortest
backup
windows
and
the
least
amount
of
storage
required
for
all
that
backup
and
Recovery.
C
So
this
is
where
that
complexity
of
orchestration
comes
in,
for
an
application
can
consistent
backup
and
that's
how
you
finally
win
to
get
to
what
everybody
expects
to
happen
on
kubernetes,
but
is
not
currently
the
state
of
the
art,
four
performance,
storage,
efficiency
and
so
on.
Yeah.
Any
any
other
comments
you
might
have
there
I
apologize.
A
B
Is
not
working
anymore
because
it
happens
sometimes
that
you
lose
the
storage
for
many
reasons.
Most
of
the
time,
the
snapshot
is
not
working
anymore
as
well.
You
are
not
able
to
restore
from
the
snapshot
and
you
absolutely
need
an
offside
copy
of
your
backup,
so
just
leaving
you
already
said
that,
but
I'm
I'm
just
saying
that
yeah,
it's
it's
a
common
pattern
to
see
that
when
you
have
a
disaster,
it's
often
a
storage
disaster,
and
you
can't
you
just
can't
use
your
your
snapshot
anymore.
C
So
great
we've
now
shown
you
everything
that
you
need
to
achieve
on
your
journey
to
get
to
mature
data
protection
on
kubernetes
all
the
characteristics
of
that
solution.
But
let's
describe
exactly
how
we
can
start
to
address
this
right
as
Michael
you
were.
You
were
going
to
tell
me
a
little
bit
about
how
how
you
used
to
solve
things
in
in
a
quick
and
dirty
way.
Could
you
could
you
do
that
or.
B
B
It
was
a
Lambda
function
on
the
Ws
and
we
were
taking
a
snapshot
of
every
EBS
volume,
and
that
was
our
solution
and
one
day
we
had
a
disaster
and
we
had
to
recover
and
I
remember
that
it
was
a
nightmare
because
it
was
very
difficult
to
make
the
relationship
between
the
EBS
volume
snapshot
and
the
actual
PVC
that
is
running
on
the
applications.
So
we
had
to
recreate
this
remapping.
Indeed,
this
mapping,
it
was
very
difficult.
B
Also.
We
were
dealing
with
a
lot
of
solution
for
storing
the
for
storing
the
backup.
So
on
the
first
place
we
were
storing
things
on
AWS
S3,
but
then
for
legal
reason.
We
were
told
that
we
should
send
the
backup
on
on
Prime
S3
storage,
so
we
had
to
change
all
the
code
to
make
that
possible
and
we
even
have
to
to
rewrite
the
library.
So
that
was
a
real
pen
and
also
how
can
we?
B
How
could
we,
under
the
logical
backup,
for
example,
when
you
try
to
to
backup
a
MySQL
data,
does
with
mySQL?
You
need
to
establish
a
connection
between
your
client
and
your
database.
So
how
do
you
do
that?
Do
you
create
a
path
forward?
Do
you
open
a
route
and
do
you
do
you
try
to
do
that
on
the
kubernetes
cluster?
C
Right
and
so
we
we've
enumerated
some
of
the
problems
that
our
customers
typically
have
when
they
do
a
quick
and
dirty
backup
script
right,
it
may
actually
work,
that's
not
the
issue.
The
issue
is,
does
it
work
for
everybody
else?
Is
it
available?
Does?
Is
it
flexible?
Are
you
are
you
going
to
maintain
it?
Who
else
has
the
skill
sets
to
run
it?
Is
it
delegated
to
everybody
else
in
this
world
of
devops
and
platform
Ops?
Can
a
developer
run
it?
C
C
So
let's
go
on
to
the
next
slide
and
we'll
show
you
canister
now
so,
as
as
alluded
to
you
want
to
be
able
to
work
with
any
sort
of
application
right,
you
can't
hard
code,
everything
for
one
application
in
one
cluster
in
one
provider
just
won't
scale.
So
canister
is
a
cloud
native
solution.
It's
an
open
source
project.
It's
apache2
license
it's
available
on
GitHub.
It
is.
It
follows
the
kubernetes
operator
pattern
in
the
sense
that
you
can
use
a
Helm
chart
to
install
the
canister
controller
onto
your
kubernetes
cluster.
C
B
B
So
when
we
do
a
backup,
we
give
a
profile
information
so
that
the
backup
system
know
where
to
put
the
backup,
then
come
the
blueprint.
So
the
blueprint
is
really
the
you
can
see
that
blueprint
and
action
sets.
They
always
come
together.
The
blueprint
you
can
see
that
as
a
library
of
functions
like
functions,
that
Define
a
backup,
restor
or
the
direction
of
an
artifact
and
an
action
set,
is
the
actual
invocation
of
a
blueprint
action.
So.
B
Blueprint
like
a
function
or
library
of
a
function,
an
action
set
like
an
invocation
of
this
function,
so
you
always
create
an
action
set
saying
on
which
workload
I'm
working
on
with
which
blueprint
which
action
on
the
blueprint
and
which
profile
these
three
things
create
the
backup
orchestraction
activity.
So
that's
that's
how
we
that's
how
I
would
I
would
Define
this
three
big
custom
resource
yeah.
C
Awesome
and
remember
the
whole
goal
of
this
for
Disaster
Recovery
is
to
get
those
backup.
Artifacts
off
of
the
cluster
wants
to
be
disaster,
recovered
any
place
else
right.
So
most
customers
bring
down.
Example:
blueprints
they
customize
them
for
their
need.
They
upload
it
after
putting
canister
installing
canister
on
their
cluster,
they
upload
some
blueprints.
C
They
set
their
profile
configurations
and
then
the
action
sets
are
the
actual
invocations
that
we
trace
for
the
life
cycle
of
executing
a
blueprint
with
it's
runtime
arguments
and
its
profiles
to
do
a
backup,
delete
or
other
crud
like
create,
read,
update,
delete
type
operation
for
your
artifacts
application
by
application
all
right.
So
that's
a
quick
overview
of
what
it
does.
Let's
get
a
little
bit
more
detailed.
So
how
do
you
interact
once
you've
installed
canister
on
onto
a
kubernetes
cluster?
Usually
you
can
use
a
cube,
cuddle
or
cube
CTL.
C
Okay,
so
we
created
an
action
set
that
invokes
all
of
these
things
buys
all
these
things
together,
the
Caster
controller,
retrieves,
all
those
objects,
the
blueprint,
the
profile
Etc,
creates
an
action
plan
and
then
starts
executing
it.
Those
individual
actions
are
are
examples
of
of
anything
like
a
cube,
executive
or
exec
execu
tiv
type
thing,
so
that
can
be
a
shell
command.
That
could
be
everything
we
could
do
through.
C
C
Do
all
those
operations,
ultimately,
typically
with
our
our
mySQL
database
instance
in
its
pod
and
gets
the
bicycle
instance
appropriately
stopped
flush
to
disk
volume,
backup
or
logical
backup,
in
this
case
a
MySQL
dump,
and
we
get
it
off
of
the
cluster
to
the
backup,
location
and
S3
canister
traxel,
while
executing
all
this
tracks.
Everything
updates
the
action
set
with
its
status.
B
No,
this
is
perfect.
The
only
thing
we
I
could
add
is
the
action
set
is
how
you're
going
to
track
your
operations
is
the
every
time
you
create
a
backup.
You
create
a
new
action
set
every
time
you
create
a
Resto,
you
create
a
new
action
set
and
so
on.
So
if
you
want
to
get
the
history
of
all
your
backup
and
restore
activities,
you
just
follow
the
the
list
of
action
set
and
you
know
what
happened
and
what
failed
and
what
succeed
and
so
on.
C
B
B
Let
me
know
if
you
can
see
my
screen.
Can
you
see
my
screen?
Yes,
okay,
cool,
so
this
is
going
to
be
a
really
common
line
demo,
but
yeah.
That's
how
we
use
canister,
so
I
am
deploying
the
solution
on
an
open
shift.
Cluster
to
be
accurate
is
going
to
be
on
Arrow,
which
means
openshift
on
azure
and
I
am
on
the
namespace
minus
ql
test.
A
B
Disney
space
called
MySQL
test,
I
have
a
m
chart
which
is
deployed,
and
we
see
the
mysqlm
charts.
So
I
got
a
bud
which
is
a
stateful
set.
Actually
it's
a
it's.
A
part
of
a
stateful
set
I
I
do
have
a
stateful
set.
Of
course,
I
also
have
the
PVC,
because
it's
a
State
football
and
I
also
have
secrets,
which
is
the
credential
to
the
databats,
which
is
this
one.
B
B
Yes,
select
Style
from
bits.
I
can
see
one
one
line
of
of
them
still
so
all
that
to
say
that
I
have
data
in
my
database
and
I
want
to
do
the
backup
of
my
address.
So
what
I'm
going
to
do
is
I'm
going
to
use
canister
for
that,
so
first
I
need
to
create
a
profile.
I
already
created
a
profile,
so
I
can
show
you
the
profile
that
I
created.
B
Oh
five
yeah
this
one,
so
this
one
is
a
S3
profile
which
she,
which
means
that
it's
it's
SV
compatible,
but
actually
the
it's
provide
that
point
to
awss,
replicate
and
also
adding
a
blueprint.
So
the
blueprint
is
how
you
define
your
operations
when
you
do
the
backup
and
the
blueprints
has
been
created
by
just
creating
a
blueprint
object.
So
I
can
find
my
blueprint
its
ear.
B
So
a
blueprint
is
made
of
different
actions,
backup
actions,
a
delay,
action
when
I
delete
my
backup
and
a
restoration.
So
if
I
go
to
the
backup
action,
let's
see
the
important
thing.
Actually,
it's
amazing
so
I'm
doing
a
minus
q
and
dump
on
my
database
and
I
zip.
This
dump
and
I
push
this
down
to
the
profile.
That's
what
I'm
doing
exactly
and
once
I'm
good
I'm
saving
the
path
to
this
verb
so
that
I
can
reuse
that
later
now,
I
can
just
do
a
demo
of
a
backup.
C
B
Okay,
so
yeah,
the
perfect
is
there
and
I'm
going
to
create
an
action
set.
The
famous
action
set
that
we've
been
speaking,
so
what
I'm
going
to
do
is
I'm.
Invoking
the
backup
action
on
the
MySQL
blueprint,
which
is
leaving
namespace,
but
it's
to
save
the
stateful
set,
which
is
leading
in
MySQL
test
name
space
and
having
from
them
MySQL
release.
B
B
B
C
B
So
you're
absolutely
right.
This
is
this
is
an
object
and
we
can
see
the
content
of
these
objects.
This
is
really
a
kubernetes
object,
so
it's
an
action
set
with
a
name
with
the
namespace
and
so
on,
and
you
can
see
the
free
component,
the
blueprint
the
profile
and
and
no
that's
all
the
yes,
the
blueprint
and
the
profile
and
yes,
and
on
which
thing
we
are
acting
the
object,
so
the
free
element
duper
print,
the
object
on
which
we
are
acting
and
the
profile
and
in
the
status.
B
You
can
see
that
we
created
The
Dump
here
on
this
S3
packet
and
we
we've
got
a
state,
a
status
of
the
the
good
completion
of
the
of
the
backup.
So
the
state
is
complete
here.
So
now.
Let's
imagine
that
I
lose
my
data
because
I
don't
know
I
made
a
human
evil.
It
can
happen.
So
let's
imagine
that
I'm
removing
my
SQL
database.
B
B
B
B
Yes,
we
could
restore
that
in
another
location.
That
would
be
perfectly
possible
okay,
so
my
body
is
now
running
and
I
could
go
inside
the
database
and
show
you
that
the
test
database
does
not
exist,
that
the
pets
table
does
not
exist,
but
I'm
I'm,
pretty
sure
that
you,
you
trust
me
so
now
I'm
going
to
create
a
restoration.
C
B
Yeah,
the
true
something
that
I
did
not
show,
but
I
could
have
we'll
see,
get
fiction,
set,
maintenance
and
because
IO
it's
where
I
put
all
my
actions
at
you
see
many
action
sets
some
of
them
failed
because
I
was
just
doing
some
fine
tuning,
so
you
can
always
list
the
different
action
in
the
backup
and
my
restore
attempt
and
so
on.
So
you
can
follow
up
your
options.
So
let's
do
that
now:
let's
create
a
resurrection.
B
A
B
B
A
B
So,
to
summarize
the
once
you
have
the
framework
is
installed
and
the
blueprint
is
okay.
The
only
thing
you
need
to
do
to
backup
is
this:
cricketer
create
an
action
set
and
when
you
need
to
restore
the
only
thing
you
have
to
do
is
this:
the
rest
are
consume.
The
the
preview
section
set
the
backup
actions
so
yeah,
that's
that's
my
demo
for
the
moment.
C
All
right,
so,
let's,
let's,
let's
conclude
and
wrap
up
with
what
we
had.
So
what
we've
shown
is
that
canister
is
a
cloud
native,
open
source,
extensible
framework
for
kubernetes
data
protection.
Please
adopt
it!
Please
join
us,
please
improve
it
by
joining
us
at
candister.io,
so
we
have
Community
bi-weekly
meetings
on
Zoom.
C
We
have
a
slack
channel
that
you
can
join
and
ask
questions
our
our
engineering
team
and
many
other
customers
and
adopters
are
there,
and
so
that's
how
the
community
interacts
and
we
figure
out
what
we
need
to
do
next
on
the
roadmap,
for
instance,
I
think
I
saw
the
complete
percentage
doesn't
really
seem
to
make
sense.
There
might
be
some
bugs
there.
C
We
have
a
partner
in
Cube
campus
that
does
a
lot
of
kubernetes
training
and
they
have
a
tutorial
for
using
canister.
Please
come
to
canister
dot,
IO
and
you'll
be
able
to
get
to
all
of
these
references.
The
mySQL
database
blueprint
is
available
on
our
GitHub
in
the
project
and
today's
webinar
materials
themselves.
The
code
that
was
executed
was
is
also
available.
There
I've
also
linked
over
to
the
references
that
we
cited
earlier.
C
The
cncf's
survey
about
going
from
stateless
to
stateful
the
doc,
the
data
on
kubernetes
community
2021
report
for
again
increasing
stateful
workloads
and
which
databases
the
datadog,
HQ
HQ
container
report,
also
for
more
data
in
database
Insight.
We
are
actively
involved
with
the
kubernetes
community
and
kubernetes
Engineering
in
the
data
protection
working
group
that
has
a
charter
and
a
white
paper
on
all
of
the
data
protection
concerns
that
are
needed
between
the
storage
provider,
Community,
the
application
provider
community
and
so
on.
So
please
come
and
join
us
there.
C
C
We
are
in
Prototype
phase
right
now,
so
that
gives
you
I
think
a
great
overview
of
what
canister
does
where
it
does
it
and
how
it
does
it,
which
is
most
important,
because
we're
helping
all
of
our
customers
and
all
of
our
all
the
entire
cncf
and
kubernetes
Community
grow
in
their
data
protection.
Maturity
such
that
they
have
Disaster
Recovery
in
an
application
consistent
way,
and
it's
not
easy,
but
with
a
community
like
this,
we're
solving
it
and
we're
solving
it
at
scale.
B
The
last
thing,
I
would
say,
for
my
experience:
don't
try
to
implement
the
backup
solution
yourself,
don't
try
to
implement
the
backup
framework
or
a
very
small
teeny
backer
from
work
of
your
own,
because
it's
an
incredibly
difficult
problem
to
solve
it's
better,
to
rely
on
framework
that
have
experience
on
this
on
this
model,
and
we
we
do
have
a
lot
of
experience
on
that
and
believe
me
has
been
built
right,
really
big
right.
But
you
need
some
experience
and
too
much
to
exercise
to.
C
A
C
Either
we
did
an
excellent
job
or
people
are
still
trying
to
figure
out.
What's
the
right
next
question
to
ask
well
long
story
short:
as
we
said,
we've
got
lots
of
resources
come
to
canister,
dot,
IO
and
and
learn
about
it,
and
not
only
that
you'll
be
able
to
get
this
entire
presentation
and
our
our
video
recording
Libby.
Hopefully
a
little
later
today,
I'll
send
you
some
final
version
of
these
slides
right
after
we
finish
it.
A
B
This
is
a
very
good
question.
Yes,
thank
you
for
asking
that.
Actually,
I
show
you
that
I
use
the
action
set
to
recover,
but
this
is
not
mandatory
to
create
another
action
set.
You
can
just
create
an
action
set
out
of
the
blue
out
of
the
blue
I'm.
Sorry,
not
out
of
the
blues
if
I
share
my
screen
again,
if
you
are
limitations,
go
ahead,
go
ahead
and
show
this
Windows
as
well.
Okay,
if
I
just
execute
the
OC,
get
the
action
set.
B
The
actions
set
up
minus
n
because
I
you
this
last
one.
It
was
the
restaurant
one,
yes,
okay
and
now,
if
I,
if
I
just
pick
the
content
section
set,
you
see
the
you
can
perfectly
provide
the
information
yourself.
You
don't
have
to
get
back
to
to.
Yes,
you
don't
have
to
rebuild
from
the
preview
section
set.
You
can
just
create
this
restoration
set
directly
by
providing
your
information
and
that
will
work
as
well.
So
it's
just
these
things.
B
C
I
I'll
add
a
tiny
bit
more
there.
So
yeah.
If
you
have
a
brand
new
cluster,
you
would
need
to
get
some
basic
things
installed,
such
as
canister
get
those
profiles
and
blueprints
loaded
and
then
yeah.
You
can
start
with
your
action
set,
but
that's
a
get
Ops
operation,
in
my
opinion,
not
hard
to
do
and
we
have
the
home
chart
so
like.
C
A
Well,
thank
you
both
Mark
and
Michael.
Thank
you.
Everyone
for
attending,
and
those
of
you
who
view
this
later,
thanks
for
watching
we'll
get
this
up
as
soon
as
possible
and
join
us
again
for
another
live
webinar
with
cncf
or
all
of
our
online
programs
that
we
post
weekly
and
thank
you
both
so
much
again
and
we'll
see
you
next
time.
Everyone.