►
Description
No description was provided for this meeting.
If this is YOUR meeting, an easy way to fix this is to add a description to your video, wherever mtngs.io found it (probably YouTube).
A
All
right,
thank
you
for
joining
us.
Everyone
welcome
to
today's
cncf
live
webinar
from
pipelines
to
supply
chains
level
up
with
supply
chain,
choreography,
I'm
libby,
schultz
and
I'll
be
moderating.
Today's
webinar
I'm
going
to
read
our
code
of
conduct
and
then
I'll
hand
over
to
david
espejo,
cartographer
community
manager
at
vmware
and
cora
iberclyde
developer
advocate
at
vmware
a
few
housekeeping
items
before
we
get
started
during
the
webinar.
You
are
not
able
to
talk
as
an
attendee,
but
there
is
a
q.
A
box
on
the
left
hand
right
hand
side
of
your
screen.
A
Please
feel
free
to
put
your
questions
there
and
we
will
get
to
as
many
as
we
can.
At
the
end.
This
is
an
official
webinar
of
the
cncf
and,
as
such
is
subject
to
the
cncf
code
of
conduct.
Please
do
not
add
anything
to
the
chat
or
questions
that
would
be
in
violation
of
that
code
of
conduct
and
please
be
respectful
of
all
of
your
fellow
participants
and
presenters.
A
Please
also
note
that
the
recording
and
slides
will
be
posted
later
today
to
the
cncf
online
programs
page
at
community.cncf.io
under
online
programs.
They
will
also
be
available
via
your
registration
link
and
the
recording
will
be
available
on
our
online
programs.
Youtube
playlist.
With
that
I'll
hand
it
over
to
david
and
cora
to
kick
off
today's
presentation.
B
All
right,
thank
you,
libby
and
thanks
to
the
cncf
for
giving
us
the
chance
of
being
here
all
right.
Welcome
everyone.
In
this
session,
alongside
with
core
iver
clyde
developer,
advocate
at
vmware,
we
will
discuss
or
describe
some
of
the
current
challenges
we
see
in
the
the
whole
problem
of
delivering
software,
and
also
we
will
introduce
a
different
way
to
do
it
using
the
choreography
pattern.
B
Finally,
the
cartographer
open
source
project,
which
is
basically
an
implementation
of
this
pattern,
cora,
will
give
us
a
fantastic
demo
as
usual,
and
we
will
have
a
wrap-up
and
a
section
for
questions
and
answers
all
right.
So,
let's
start
with,
why
so
motivation
for
all
these
comes
from
from
different
places.
B
B
B
B
In
this
pattern,
we
define
a
set
of
steps
that
code
need
to
complete
before
going
into
production,
and
we
have
several
features
here.
First,
each
one
of
these
steps
most
likely
is
executed
by
a
different
tool
right
and
if
you
consider
the
abundant
number
of
tools
present
in
the
in
the
cloud
native
space
for
each
one
of
these
steps,
we
have
a
lot
of
options.
B
So
these
individual
tools
need
to
be
somehow
connected
between
them
or
wire
between
them,
using
this
sequential
pattern
where,
where
each
step
is
completed,
sequentially
in
a
linear
manner
and
also
in
order
to
manage
the
flow
of
information
between
the
steps
we
rely
on
entity,
that
is
that
follows
an
orchestrator
pattern.
Is
it's
a
something
like
the
server
client
pattern,
and
this
orchestrator
not
only
deals
with
what
should
be
done
to
take
code
to
production?
B
I
mean
the
steps
in
the
supply
chain,
but
also
how
it
should
be
done
in
terms
of
all
the
tooling
integration,
the
external
integrations
that
are
necessary
for
this
to
happen.
So,
for
example,
the
tool
that
you
use
to
watch
a
github
repo
is
different
to
the
tool
that
you
use
to
scan
source
code
against
a
set
of
security
baselines
right.
B
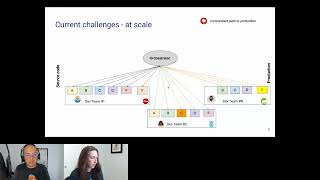
So
we
end
up
with
this
high
level
of
interdependencies
between
different
tools
and
a
very
rigid
logic
that
is
right
there
codified
in
the
orchestrator
that,
in
summary,
this
is
tight
coupling
right
and
if
this
is
an
enemy
for
change
in
distributed
systems
and
thai
coupling
is
also
the
cause
of
some
other
problems
here,
because
it
makes
it
difficult
to
swap
or
add
tools.
So,
for
example,
let's
say
that
for
a
different
workload,
you
you
want
to
have
a
different
tool
that
actually
builds
your
image.
B
If
you
want
to
change
a
tool
for
one
of
the
steps,
you
will
need
to
change
the
logic
that
you
already
created
or
there
in
the
orchestrator.
So
it's
not
easy.
It's
very
fragile
and
hard
to
maintain,
and
in
general,
this
rigid
workflow
also
means
that,
for
example,
what?
If
not
all
the
changes
to
your
app
come
from
a
comment
in
a
github
repo?
In
this
example,
we
are.
The
first
step
is
watch
a
repo
for
a
new
comment.
But
what?
B
If,
for
example,
in
this
scan
source
code,
there's
a
new
vulnerability
discovered
in
order
to
update
or
trigger
the
pipeline?
You
will
have
to
submit
an
artificial
commit
for
it
to
run.
So
it's
a
very
rigid,
workflow,
very
linear,
and
if
some
step
fails,
the
remaining
steps
won't
be
invoked
at
all
and
also
any
delay
in
the
execution
of
one
step
or
any
delay
in
the
response.
Time
from
the
orchestration
will
delay
the
whole
process,
so
the
challenge
becomes
even
harder
when
you
start
scaling.
B
So
when
you,
this
is
the
supply
chain
or
the
pipeline
definition
for
a
specific
app
that
runs,
for
example,
in
a
rails
framework
and
it's
maintained
by
developer
team
number
one.
But
what
if
you
have
another
team
with
a
completely
different
workload
and,
for
example,
they
plan
to
use
a
different
tool
to
build
the
image
you
will
have
to
codify
that
different
logic
in
the
orchestrator
and
so
on.
So
for
you
have
different
teams,
for
example,
this
team
they
have
a
completely
different
pipeline
design
that
doesn't
start
by
watching
a
repo.
B
B
If
we
see
here
each
one
of
these
pipelines
with
different
tools,
these
tools
have
different
inputs,
different
outputs
and
once
you
finally
have
pipeline
number
one
working,
it
doesn't
necessarily
is
useful
for
depth
in
number
two
of
the
team
number
three
for
different
workouts,
so
you
will
end
up
having
a
cicd
pipeline
sprawl
for
as
many
teams
and
as
many
warlocks
that
you
may
have.
You
will
have
completely
different
paths
to
production.
That's
first
thing.
B
B
Well,
most
likely
developers
will
end
up
doing
devops
stuff
instead
of
actually
writing
code,
and
it
creates
a
high
operational
burden
in
general
because
it's
hard
to
maintain
what
happens,
for
example,
again.
If
the
organization
now
wants
to
standardize
in
a
different
tool
for
the
security
scan,
you
will
need
to
change
the
logic
for
all
the
pipelines
in
the
environment
with
it
becomes
a
nightmare
right.
So
these
are
the
challenges
so
far,
and
what
we
are
proposing
here
is
the
adoption
of
a
pattern
that
is
natural
to
event-driven.
B
Imagine
an
orchestra
with
where
each
musician
they
know
how
to
play
the
actual
musical
piece,
but
they
still
rely
on
a
central
conductor
that
manage
the
flow
of
information
for
the
the
whole
musical
world
to
happen
in
choreography
is
different
because
once
they
are
in
the
scenario
and
the
music
starts
to
play,
each
dancer
knows
what
to
do.
Even
if
someone
else
in
the
dance
team
fails
the
remaining
members
of
the
team,
they
know
what
to
do
so.
We
consider
here
the
term
resource
as
a
step
as
a
component
in
your
supply
chain.
B
We
call
it
resource
because
it
could
be
several
things.
It
could
be
a
heat
ups
aging
watching
repo.
It
could
be
a
service
building
your
image.
It
could
be
a
conflict
map
in
your
kubernetes
cluster.
Whatever
you
need
to
take
code
to
production,
we
call
it
a
resource
and
we
know
two
things
about
this
resource.
First,
it
has
a
single
input,
input,
type,
yellow
and
it
will
produce
a
single
output
output,
type,
yellow
output,
value
x.
That's
it
it's
a
black
box.
We
don't
know
how
it
works
and
we
don't
care
at
this
point.
B
We
don't
care.
So
if
we
use
a
different
input
value
well,
it
will
produce
a
different
output.
Pretty
simple,
so
we
can
use
the
choreography
pattern
for
two
things
here
in
the
context
of
supply
chains.
First,
we
can
use
it
for
self
mutating
resources.
So
imagine
this
resource
is
a
githubs
agent
watching
a
repo,
so
the
input
will
be
the
url
for
the
repo
and
the
branch,
and
that's
it
so
imagine
that
the
url
has
not
changed.
The
branch
has
not
changed,
but
there
is
a
new
comment.
B
That
will
eliminate
the
need
for
developers
to
codify
that
kind
of
logic
or
submit
an
artificial
comments
to
trigger
a
pipeline.
It
will
happen
automatically
here
so
now
that
we
are
using
the
image
build
example.
What
happens
if
for
a
different
workload?
You
want
to
use
a
different
tool.
I
mean
instead
of
kpak,
for
example,
volcanic
well
as
long
as
these
need
to
produce
the
same
type
of
output,
which
is
very
likely
it
will
produce
a
path
to
your
image,
using
k,
park
or
mechanical.
B
Well,
you
can
swap
out
or
change
the
tools
without
changing
anything
else
without
affecting
the
logic
of
the
whole
supply
chain,
without
changing
anything
else
very
different
compared
to
the
pipeline
orchestration
pattern
right,
so
that's
resource
a
what
happens
with
the
next
step
in
the
supply
chain.
Well,
the
only
thing
this
next
step
will
do
is
to
subscribe
to
a
specific
type
of
output
or
to
watch
for
a
type
of
up.
B
B
It's
declared
because
we
will
define
these
are
the
components
of
my
software
supply
chain.
These
are
the
inputs,
the
outputs
and
that's
it,
but
there
we
need
a
layer
that
translate
or
reconcile
desired
state
into
actual
state
in
the
underlying
platform.
Who
could
be
that
layer?
Who
could
be
that
choreographer?
B
That
is
common
to
all
the
components
here?
Well
introducing
cartographer
the
supply
chain
choreographer
for
kubernetes?
We
are
in
a
project
that
recently
joined
this
cncf
landscape
like
a
week
ago.
We
are
failing
you
here,
it's
an
open
source
project
initiated
by
vmware,
and
it
has
several
difference
here.
So
the
first
thing
is
that
it
removes
completely
the
dependency
on
a
central
entity
right
and
we
have
the
same
step,
the
same
resources
for
your
supply
chain,
but
the
first
thing
that
it
does
is
to
wrap
them
around
a
common
abstraction.
B
This
abstraction
is
called
template
in
the
cartographer
jargon,
but
conceptually
it
means
that
now
we
remove
all
these
inputs
at
and
outputs
of
each
one
of
the
elements
in
the
supply
chain
that
produces
this
complexity.
That
is
hard
to
maintain.
We
now
have
a
common
abstraction.
Pretty
simple
to
deal
with,
science
has
already
demonstrated
that
the
only
thing
you
can
do
with
complexity
is
to
hide
it
to
put
an
abstraction
layer
on
top
of
it.
You
cannot
remove
it
right.
B
So
the
you
know,
what
we
are
doing
here
in
the
project
is
to
use
that
you
know
to
put
an
obstruction
layer,
a
common
obstruction
layer
for
all
these
steps
in
the
supply
chain.
Then
we
glue
them
together
or
wire
them
together,
using
the
choreography
pattern
that
we
just
saw,
and
then
we
wrap
the
whole
thing
in
a
bigger
abstraction
or
higher
abstraction
called
blueprint.
In
this
case,
a
cluster
supply
chain
blueprint.
B
B
We
have
the
underlying
platform
the
and
we
have
the
photographer
controller
or
choreographer
in
the
middle,
so
devops
and
sec
ops
in
general
operations
team.
They
will
own
and
apply
the
cluster
supply
chain
definition.
They
they
control
two
things.
First,
they
define
the
steps
for
the
supply
chains,
this
the
supply,
the
the
steps
that
quote
need
to
complete
before
going
to
production,
and
then
they
also
define
the
level
of
flexibility
they
will
enable
for
developers.
So,
for
example,
operations
teams
can
say
developers
team,
you
can
choose
whatever
tool
you
want
for
building
your
image.
B
B
The
controller
will
find
a
supply
chain
definition
that
matches
the
workload
definition
and
it
will
translate
that
into
resources
that
needs
to
be
created
or
updated
in
the
underlying
platform.
That's
it
that's
the
whole
idea
so
benefits
here.
I
hope
they're
clear.
First
there's
a
clear
separation
of
concerns.
I
mean
team
members.
They
will
spend
their
time
and
efforts
in
their
respective
areas
of
expertise.
B
They
know
what
to
do
with
their
respective
field
and
also
implies
a
lot
of
flexibility
because
remember
we
have
here
and
a
system
that
that
reacts
to
even
to
low
level
changes.
So,
for
example,
there's
no
new
comet
right,
but
there's
a
new
vulnerability
discovered
by
the
scan
source
code
process.
Remember
it
will
produce
a
new
output
and
it
will
update
the
downstream
resources
accordingly.
B
Also,
you
have
it's
it's
much
more
modular
because,
as
we
saw,
we
have
these
very
granular
controls
and
you
can
also
with
a
as
long
as
the
output
type
is
the
same.
You
can
interchange,
you
can
swap
out
tools
and
add
tools
for
different
warlocks,
very
simple
without
affecting
the
consistency
of
the
whole
supply
chain
definition,
so
that
helps
with
scaling
up
scaling
out
the
the
problem
of
delivering
software.
B
It's
also
consistent
in
terms
that
not
only
the
consistent
interfaces
between
step,
but
in
general,
what
the
operations
teams
define
and
apply
the
cluster
supply
chain
definition
will
it
can
be
reused
for
different
workloads
for
different
environments,
and
it
will
produce
the
same
type
of
outputs
it
will
it
will
give
them
peace
of
mind
that
source
code
is
completing
the
necessary
step
before
going
to
production
right
so
now
for
the
specifics,
how
it
works.
So
we
have
here
the
steps
again,
the
the
steps
or
the
resources
watching
themselves
for
a
specific
output.
B
As
we
mentioned,
the
first
abstraction
is
called
the
template
and
we
have
five
kinds
of
templates
here
and
projects
for
different
components
or
steps
in
the
supply
chain
and
with
different
combinations
of
the
templates
we
produce
what
is
called
a
blueprint.
This
is
the
higher
abstraction
in
cartographer
with
cluster
supply
chain
blueprint
or
being
clustered
delivery.
This
blueprint
constantly
deploys
and
validate
the
configuration
to
the
kubernetes
environment.
B
What,
if
you
already
have
an
investment
on
ci
cd
tooling?
What
can
we
do
here?
Well,
cartographers
ships
with
a
runnable
call
with
a
crd
called
wannable
that
is
used
as
a
gateway,
let's
say
to
integrate
with
existing
task
runners
like
tekton,
jenkins,
circle,
ci,
etc.
You
can
still
use
them
for
the
specific
steps
that
you
require
right
all
right,
so
in
yeah
yeah.
The
theory
of
operation
in
summary,
will
be
that
once
a
developer
submits
a
workload
that
match
specific
blueprint,
cartographer
will
reconcile
that
into
the
actual
resources
in
the
underlying
platform.
B
C
Okay,
I'm
gonna
move
this
screen
over
here,
so
my
demo
was
working
perfectly
and
then
I
started
to
detect
some
problems.
So
if
the
demo
does
not
work,
then
I
will
switch
I
have
I
do
have
like.
I
recorded
it
at
some
point,
so
I
have
a
little
bit
of
a
backup
plan
so
bear
with
me.
Hopefully
everybody
cross
your
fingers
we'll
get
through
it
somehow.
C
So
I'm
gonna
try
to
show
you
one
from
code
to
publishing
your
image
into
a
registry
and
publishing
your
configuration
yaml
into
a
gear
repository
and
then
taking
that
and
having
a
second
blueprint
or
workflow
that
will
deploy
that
to
a
cluster.
So,
let's
get
started,
let's
see
how
far
we
get
with
a
live
demo.
C
So
one
one
thing
to
gather
from
here
is
that
cartographer
is
not
trying
to
do
all
of
the
things
right.
It's
not
trying
to
replace
these
tools
from
the
ecosystem
that
do
their
job
very
well.
Rather,
it's
just
trying
to
help
us
use
all
of
these
tools
together,
integrate
them
in
a
way
that
that
makes
sense
and
that's
easy
to
work
with.
So,
first
of
all,
just
to
reinforce
the
the
concepts
I
wanted
to
talk
about,
what
would
it
mean
for
you
if
you
were
doing
this
manually?
C
Let
me
make
this
just
a
little
bit
smaller
on
the
screen.
If
you
were
doing
this
manually,
so
you'd
have
to
write,
you
know
at
least
one
yama
for
each
of
these
things
right.
One
flexi
ammo
one
k
back
down
with
one
k
needed
a
service
animal,
so
that
would
look
like,
could
look
like
something
like
this
right,
so
this
could
be
so
there's
no
cartographer
here
right.
This
is
just
a
flux.
C
C
So
whenever
kpac
is
done
with
that,
then
we
would
like
to
know
that
there
is
a
new
image
available
and
we
would
like
to
know
what
the
full
tag
of
it
is
with
the
precise
sha
so
that
we
can
inject
that
value
into
our
k
native
definition.
So
here's
just
plain
k
native
so
that
then
we
can
apply
this
to
our
cluster
and
effectively
have
our
application
running
in
our
cluster.
So
all
of
those
things
that
I've
called
out
that
have
to
be
done
manually
are
opportunities
for
automation.
Of
course,
right.
C
C
So
let's
talk
about
okay,
so
let's
go
ahead
and
apply
that
get
that's
the
get
repository.
So
we
have
flux
doing
this
thing
right
so
now,
so
that's
one
thing
right:
applying
that
gamble
in
and
of
itself
that
submission
of
that
configuration
to
the
cluster.
That's
one
thing
to
automate.
The
second
one
is
to
just
monitor
the
status.
So
we
can
see
here
that
the
status
of
this
git
repository
object
has
a
couple
of
things.
C
It
has
some
conditions,
so
we
know
programmatically
we
could
tell
because
the
type
is
ready
and
the
status
is
true.
We
could
tell
that
this
one
is
ready
and
then,
if
we
look
at
here,
this
url
field
has
actually
the
tar,
gz
flux
has
actually
gone
and
downloaded
this
and
storing
it
in
the
cluster
of
that
last
commit
of
code.
So
we
could
just
pull
out
this
value.
We
could
give
it
to
kpac
right
and
the
way
we
pull
it
out
is
dot
status,
dot,
artifact,
dot
url.
C
C
And
then
we
would
want
to
apply
this
yaml
to
the
cluster
and
have
kpak
build
an
image
for
us.
So
at
this
point
this
is
where
I'm
not
sure
that
my
cluster
is
actually
working
out.
For
me,
the
build
does
take
a
couple
of
minutes,
so
I
my
expectation,
is
that
immediately
it's
not
it's
not
ready
yet.
So
this
is
okay.
C
C
We
just
gotta,
give
it
a
little
bit
of
a
minute,
so
so
the
way.
So
just
if
you're
curious,
the
way
kpac
works
is
that
it
uses
a
combination
of
build
packs
to
build
an
image.
So
it's
it's
kind
of
analyzed
our
code.
It's
decided
that
it
has
to
use
four
different,
build
packs
to
build
an
image
for
us.
It's
going
to
execute
each
one
of
those
build
packs
in
order
and
we'll
just
give
it
a
second
to
finish
by
the
time
it's
done.
C
C
C
So
if
you
wanted
to
optimize
this
build
time,
there
are
definitely
things
you
can
do
for
kpac
to
make
the
build
go
faster
that
I
obviously
have
not
done,
but
so
cartographer
doesn't
know
anything
about
kpac,
that's
part
of
the
beauty
of
choreography
and
one
of
the
differences
between
orchestration
and
choreography
that,
as
a
choreographer
cartographer,
is
really
just
a
layer,
above
all
of
these
things.
So
so
you
can
optimize
the
build
for
sure,
but
you
would
be
doing
it
with
kpac.
C
C
We
would
want
cartographer
to
have
been
monitoring
that
and
to
realize
again
that
the
status
type
is
ready
and-
and
it's
true
and
so
now
the
piece
of
information
we
want
to
pull
out
of
here
is
this
latest
image
field
right.
It's
here's
the
tag,
and
this
is
what
we
want
to
give,
so
it
would
be
dot
status,
dot
latest
image
in
the
case
of
k-pac
right.
If
you
were
using
another
build
tool,
then
maybe
it
would
be
a
different.
C
It
would
be
probably
a
different
field
right,
so
so
specifically
so
I've
just
gotten
that
same
value
and
I'm
just
storing
it
in
an
environment
variable.
So
I
can
just
inline.
Do
the
environment,
substitution
and
I'm
going
to
take
that
same
k
native
yaml
that
we
were
looking
at
before,
and
here
it
is
so
now
I
have
this
yaml,
so
my
I
have
choices
now.
C
I
could
either
just
do
sort
of
the
equivalent
of
a
cue
cuddle
apply,
have
cartographer
just
submit
this
yaml
to
the
api
server,
and
then
I
would
have
my
application
running
in
the
same
cluster
where
I've
just
done
this
build,
or
I
could
do
a
git
push
of
this
to
some
ops
repo
so
that
I
could
then
deliver
this
application
to
maybe
multiple
clusters
in
multiple
regions
etc.
So,.
C
Use
cases
are
valid
and
hopefully,
as
long
as
my
demo
keeps
working,
and
we
have
enough
time,
I'm
going
to
show
you
cartographer,
doing
the
get
push
and
then
the
delivery,
but
just
to
continue
on
these
core
concepts.
The
next
thing
is
so:
we've
seen
the
manual
approach
and
we've
observed
the
opportunities
for
automation.
So
how
does
cartographer
actually
do
this?
So
when
you
install
cartographer
it
installs
a
few
additional
resources,
so
I'm
to
grabbing
specifically
for
those
for
the
ones
called
templates.
That
david
was
mentioning
earlier.
C
Our
our
resources,
those
three
that
we
created
into
three
of
these-
we
have
to
choose
the
right
ones
and
basically
you
choose
them
based
on
the
kind
of
output
that
the
templates
provide.
So
you
can
imagine
that
a
cluster
source
template
is
probably
good
for
our
flex.
Cd
get
repository
source,
a
cluster
image
template
is
probably
a
good
choice
for
the
k-pac
one
and
then
k-native
we're
just
deploying
it.
We
don't
need
any
output
from
it,
so
cluster
template
makes
sense.
C
So,
let's
look
at
what
that
looks
like
I'm
just
going
to
focus
on
just
the
get
repository
and
the
k-pac,
because
they
have
more
fields
in
them.
So
the
way
that
you
embed
it
is,
I
see
literally
this
stuff.
Everything
underneath
template
here
is
just
copy
paste.
The
exact
same
thing
that
we
just
submitted
to
that
we
were
just
using
and
that
we
just
looked
at
this
template.
A
C
Kind
of
like
a
freeform
field,
you
could
put
anything
so
cartographer
itself
doesn't
know
how
to
work
with
flux.
It's
just
like
you
give
me
some
yaml
and
I'll
apply
it
to
the
cluster,
so
after
so
so
by
that
we're
giving
cartographer
control
to
create
the
resource
and
then
because
cartographer
has
created
the
resource.
Of
course,
it
has
now
knowledge
about
it.
So
it
can
continue
to
check
the
status
to
see
when
the
when
it's
ready,
when
the
conditions
show
that
it
has
done
something.
C
And
then
at
that
point,
because
this
is
a
cluster
source
template.
The
cluster
source.
Template
has
two
fields
of
output:
one
is
url
and
the
other
one
is
a
revision,
and
so
what
we
have
to
do
is
explain
to
cartographer
how
to
pull
the
information
that
we
need
outside
of
from
the
flux
resource,
and
so
we've
just
seen
that
flux
puts
the
url
that
we
want
in
this
field
called
status,
artifact
url.
C
So
this
is
how
we
bridge
that
gap
and
teach
cartographer
how
to
read
the
desired
information
from
whatever
resources,
underneath
the
template
same
for
kpac
image,
because
this
is
an
image
type
of
template.
The
output
is
going
to
be
an
image
and
we're
telling
it
where
to
get
the
value
is
going
to
be.
The
image
path
is
status
latest
image,
but
other
than
that.
Underneath
this
template
field
we
basically
just
copied
and
pasted
the
very
same
thing
we
just
looked
at
the
only
thing.
C
C
C
To
do
things
in
and
also
we
could
have
maybe
several
git
repositories
that
we
are
monitoring,
so
we
have
to
tell
cartographer
exactly
which
of
those
gate
repositories.
It
should
use
to
inject
the
value
into
kpac.
So
we
do
that
using
a
supply
chain,
so
supply
chain
is
I'm
just
going
to
get
tiny
bit
smaller?
C
I
hope
you
can
still
read
this
okay,
so
here's
our
supply
chain,
so
it's
another
cartographer
resource
and
you
can
see
that
it
has
a
list
of
resources
right.
David
was
talking
about
resources,
so
we
have
three
resources:
our
git
repository,
our
kpac
image
and
our
k
native
application,
and
so
the
way
that
these
work
is
every
resource
is
a
name
and
a
reference
to
a
template,
and
so
these
references
are
exactly
the
templates.
C
We
were
just
looking
at
that's
cluster
source,
cluster
image
and
cluster
template,
and
this
is
just
the
name
of
the
of
the
actual
resource
that
we're
pointing
to
the
metadata.name
inside
of
our
cluster
source
template.
So
so
now
there's
an
order
now.
Cartographer
knows
it
is
first
cape
is
second
and
when
it
does
capec
we're
also
creating
a
dependency.
Now
for
injection,
where
we're
saying
we
need
this
template
that
needs
input
and
that
input
is
going
to
come
from
a
cluster
source
template.
C
So
it's
a
list
of
sources
and
which
one
is
it
it's
the
one
called
source
provider.
So
this
is
matches
this
and
same
here
you're
saying
we're
saying
here
that
we
have
an
image
type
input
coming
from
a
resource
called
image.
Builder.
Here
is
image
builder
and
in
effect
it
is
an
image
type
template,
and
so
that's
basically
it
you
can
have
many
many
inputs.
So
that's
why
they
have
names
here
so
that
you
can
refer
to
them
separately.
C
C
C
Do
is
parameterize
that
information
and
we
do
that
through
something
called
a
workload,
and
so
you
can
also
imagine
that
so
far,
everything
that
we've
seen
the
templates
in
the
supply
chain
is
something
that
an
applications
operator
would
do.
They
could
build
out
multiple
supply
chains
with
multiple
paths
to
production
and.
C
C
If
the
application
operator
exposed
more
fields
for
the
developer
to
use,
then
you
know
it's
possible
that
a
developer
could
fill
in
more
fields,
but
the
sort
of
the
basics
are
these
and
then
because
you
could
have
multiple
supply
chains
running
in
the
cluster.
We
put
a
label
on
the
workload
here
and
this
one
is
called
uptown's
vmware.com
workload
type
web
and
that
label
is
needs
to
match
the
selector.
So
if
I
scroll
back
up
to
the
cluster
supply
chain,
this
has
a
selector
with
the
same
value.
C
So
as
soon
as
that
workload
is
deployed,
this
supply
chain
will
respond.
It'll
say:
oh,
I
have
I
see
that
workload.
I
have
to
act
on
it,
and
so
it
will
take
those
values
and
and
inject
them.
So
the
last
very
last
thing
we
need
to
do
is
go
review
all
of
our
templates
and
parameterize
all
those
values
that
were
hard
coded.
C
So
the
way
that
would
look
would
be,
if
I
scroll
up
here
so
for
our
for
our
cluster
source
template
instead
of
hard
coding,
the
name
when
it's
when,
when
it's
going
to
stamp
out
that
git
repository
resource
for
our
particular
application.
Instead
of
hard
coding,
hello
world.
Now
we're
going
to
take
that
value
from
the
workload
and
instead.
B
A
C
The
url
and
the
branch
again
we're
taking
those
values
from
the
workload.
So
now
this
can
be
used
for
many
applications,
and
you
can
see
here
on
the
image.
One
same
thing:
the
work
the
name
will
match
we're:
gonna
use
the
same
name,
to
name
the
image,
but
we
also
have
other
sources.
We
can
define
more
global
parameters
that
are
shared
across
workloads
so,
for
example,
the
name
of
the
registry.
That
might
be
something
we
want
to
make
more
general,
and
then
you
can
better
understand.
Also
here.
C
C
So
I'm
gonna,
I'm
gonna,
keep
going
with
this
example,
so
I'm
gonna
move
to
to
the
get
ops
example
and
I'll
just
I
guess,
keep
going
until
for
as
long
as
I
have
time
so,
hopefully
I
can
get
through
the
whole
thing,
but
I
do
want
to
show
you
that
these
examples
are
coming
from
here.
I'm
going
to
run
actually
this
there's
a
set
of
examples
in
the
cartographer
repo
which
are
really
great,
and
what
I'm
going
to
try
to
get
through
is
these
last
two.
C
This
is
sort
of
the
get
ops
using
the
supply
chain
to
go
from
code
to
git
repo
and
then
the
delivery
to
go
from
git
repo,
the
ops
repo
to
the
deployment.
But
I
would
encourage
you
if
you're,
if
you're
you
want
to
try
it
on
your
own,
you
can
get
it
from
here
or
you
can
try
the
other
examples
here
as
well,
they're,
all
great.
C
So,
okay!
So
let's
try
the
get
writer
example.
So
we're
going
to
do
a
little
bit
of
a
different
flow,
we're
going
to
go
still
source
using
flux
and
to
build
the
image
using
kpac.
We
might
have
a
time
for
a
little
more
chat
while
cape
is
doing
its
work
and
then
we're
going
to
actually
use
a
cluster
config
template
to
write
the
configuration
to
a
config
map
and
then
use
techton
to
do
a
git
push.
C
I
just
deployed
everything
at
once:
the
the
supply
chain,
as
well
as
the
workload
so
while
that's
running
in
the
background,
so
hopefully
kpac
will
we'll
finish
before
we're
done
talking
about
this.
So
this
this
supply
chain
is
a
little
bit
different
from
the
first
one.
We
looked
at
right.
This
is
the
same.
I
left
the
the
selector
the
same
instead
of
having
two
supply
chains,
we're
just
overwriting
the
last
one
which
is
okay,
and
so
we
don't
have
to
change
the
workload.
C
So
we're
reusing
our
first
two,
the
cluster
source
template
and
the
cluster
image
template
that
we
had
before
and
and
at
the
end,
instead
of
just
deploying
it
we're
going
to
use
a
cluster
config
template
to
write
the
value,
write,
the
k
native
definition
to
a
map
to
a
config
map
and
then
we're
going
to
use
a
cluster
template
that
is
going
to
call
tecton
it's
going
to
utilize
tecton.
To
do
the
gate
push
so
I'm
going
to
show
you
the
cluster
config
template
the
one
that
the
third
new
resource
here.
C
Okay,
so
this
basically,
let's
scroll
to
the
top
okay,
so
here
it
is,
and
so
it's
another
one
of
our
cartographer
templates
cluster
config
template-
and
in
this
case
the
output
of
this
is
going
to
be
some
config
information.
So
we
have
to
tell
it
where
to
find
this
config
information
and
we're
saying
this
one's
not
in
the
status.
C
C
It's
a
bunch
of
ammo,
but
it
includes
it,
includes
that
same
candidate.
This
is
a
little
bit
differently
coded,
I
guess
here,
but
it
is
ultimately
that
same
k,
native
service
definition
and-
and
we
also
want
to
be
able
to
interpolate
values
dynamically,
so
we're
just
using
rather
than
the
dollar
sign
syntax
it
uses
a
syntax.
Ytt
is
a
tool
from
carvel,
very
powerful
for
templating
and
overlaying
yaml,
but
at
the
end
of
the
day,
this
is
going
to
generate
that
same
yaml.
C
So
I'm
not
actually
going
to
show
you
I'm
just
going
to
show
you
that
there's
three
files
here
and
I
think
I
think
soon
with
cartographer
you
might-
we
might
be
able
to
like
consolidate
this
a
little
bit
but
we're
basically
using
a
task-
that's
available
on
the
tecton
catalog
for
git,
cli
and
and
hooking
that
into
cartographer,
but
same
thing,
concepts
that
you've
seen
so
far
more
or
less
to
do
that.
So
from
a
developer
perspective,
since
we
didn't
change
the
selector
on
the
supply
chain,
nothing
really
changes
for
the
developer.
C
So
so
remember
when
I
switch
directories,
I
already
applied
this.
So
let's
see
if
it's
done,
hopefully
it
will
have
finished
already:
okay,
good
okay.
So
in
the
meantime
our
our
workload
finished
running.
So,
let's
see
we
can
use
there's
a
handy,
plugin
called
tree,
let's
to
see
like
what
what
our
resource
kind
of
like
spawned.
What
are
what's
the
tree
of
things
that
that
got
generated
so
sorry?
This
is.
B
C
There
we
go
so
we
as
developers
apply
to
workload
right
and
that
generated
first
a
get
repository
resource
when
that
was
done
created
an
image.
The
image
did
its
thing
and
built
built
an
image,
and
then,
after
that
was
ready.
It
generated
the
supply
chain,
created
the
config
map
with
our
values
and
then
and
then
it
and
then
after
the
configmac
was
ready.
It
called
tekton.
So
what
we
should
have-
and
these
are
red
but
they're-
just
because
they're
jobs-
they
don't
fail.
C
What
we
expect
to
have
right
now
is
that
in
our
git
repository
we
should
have
the
yaml
that
we
would
want
to
deploy
to
any
cluster.
So
I'm
just
going
to
do
here,
a
git
clone.
I
have
a
git
repo
running
on
the
cluster,
but
it's
just
I'm
just
doing
a
git
clone
and
let's
look
at
what
we
got
in
that
git
clone
and
we
said
we
do
have
config
manifest.yaml.
So
that's
good!
That's
what
we
expect
and
if
we
look
inside
the
file
there
we
go.
C
There's
yaml,
here's
the
k
native
portion,
so
it's
done
ytt
without
all
that
ygt
kind
of
like
eye
stuff.
It's
interpolated
all
the
right
values,
so
our
application
name
and
the
image,
and
so
now
this
is
ready
to
be
deployed
to
any
cluster.
You
want
right
so
that
part
of
our
demo
that
part
of
the
demo
finished
right.
The
we've
we've
done
our
job
for
the
left
side
of
githubs.
C
So
now,
if
we
move
over
to
the
right
hand
side,
we
have
something
called
a
delivery.
So
just
as
we've
been
looking
at
supply
chains,
there's
a
counterpart,
we
call
these
blueprints
that
does
the
delivery
of
that
yellow
to
whatever
cluster
you
want,
and
so
it's
going
to
be
responding.
We're
going
to
use
again
very
similar,
we're
going
to
use
flux
to
detect
new
commits
on
that
boss,
repo
and
then
deploy
it
to
kubernetes.
C
So
if
we
look
at
the
delivery
very
similar
structure
to
the
supply
chain,
cluster
delivery
instead
of
cluster
supply
chain,
we
still
have
the
selector
so
that
it
can
detect
when
there
will
be
deliverables
instead
of
workloads,
they're
deliverables
and
again
similar
structure
to
resources.
The
first
one
is
very
similar:
it
still.
It
uses
a
git
git
repository
from
flux
again
because
all
we're
doing
is
pulling
a
get
re
repo,
but
then
for
the
deploy.
We
use.
Another
kind
of
template
called
a
cluster
deployment
template
where
we're
gonna
take.
C
You
know
the
output
from
that
this
one
finds
in
git
and
deploy
that
so
I
think
yeah
we
can
take
okay.
Let's
take
a
look
at
that
yaml
quickly,
but
it's
it's
sort
of
the
same
idea
right.
Cluster
deployment
template.
There's
no
output
here
either.
So
we
just
have
this.
This
template
to
to
grab
whatever
url.
Was
there
extract
that
and
and
we're
just
telling
it?
How?
How
do
you
know?
C
C
Can
teach
photographer
to
work
with
the
resources
that
you're
asking
it
to
deploy
so
the
deliverable
again
the
counterpart
to
the
workload.
So
this
would
be
the
thing
that
represents
that
precise
repo
that
that
we
are
working
with
for
this
hello,
cncf
app
right.
So
this
is
our
that's
our
that's
our
repo
for
this,
for
this
particular
app.
C
Go
to
that
repo
realize
that
there's
a
commit
ready
for
us,
grab
it
and
deploy
it.
So
we
can
see
and
that's
what
it
did
so
that
deliverable
led
cartographer
to
create
the
git
repository.
The
git
repository
very
quickly
realized,
there's
something
to
apply,
and
then
it
created
the
deployer
template
was
applied
and
it
created
this
so
just
to
make
sure
that
it
is
actually
running.
C
B
C
B
A
B
Let
us
know
if,
if
that's
not
the
case,
and
we
hope
to
continue,
continue
the
conversation
after
the
session,
so
wrapping
up
the
current
challenges
we
see
with
the
pipeline
orchestration
pattern.
Is
that
is
tightly
coupled
very
high
level
of
interdependencies
between
steps
and
once
you
start
scaling,
it
becomes
harder
to
maintain
to
adapt
to
different
workloads
and
also
to
you.
A
B
Modify
tools
or
add
tools,
as
we
saw
it,
it
implies
a
lack
of
consistent
paths
to
production,
because
these
highly
customized
do-it-yourself
pipelines
along
your
whole
environment
and
also
there's
no
clear
separation
of
concerns-
benefits
we
see
in
the
using
supply
chain.
Choreography
will
be
that
well
first,
because
of
the
choreography
pattern.
There
is
this
loosely
coupled
loose
coupling
between
steps
between
resources.
B
It
also
provides
a
model
with
clear
separation
of
concerns
both
for
operations
and
depth
teams
and,
finally,
giving
us
the
flexibility
to
produce
or
design
different
configurations
to
get
source
code
to
production
and
in
general,
is
much
more
reliable.
It
doesn't
have
a
dependency
on
a
central
entity
to
manage
all
the
steps,
much
more
trustable,
all
right.
We
hope
this
was
educational
for
you.
We
would
really
like
to
keep
the
conversation
going,
bring
your
questions,
your
easy,
your
tough
questions
too,
or
several
communication
channels.
B
I
will
let
me
I
will
put
here
link
to
our
slack
channel
in
the
coordinates
workspace.
You
are
welcome
to
join,
continue,
conversation
and
even
join
us
in
the
meetings.
If
you
want,
is
there
any
question
outstanding
question
right
there
that
we
could
address
in
the
few
minutes
that
we
have
remaining.
B
C
I'm
not
sure
how
much
is
on
the
road
map
and
how
much
is
now.
I
guess
david
you're,
probably
you're,
probably
more
up
to
date
on
on
and
cartographer,
but
if
you're
talking
about
k-pac,
then
k-pac
does
definitely
have
optimizations
built
into
it
and
it
does
a
lot
of
like
caching.
It
doesn't.
It
doesn't
apply
the
build
packs
in
parallel,
but
there's
there.
C
C
B
C
The
example
at
the
bottom
I
mean
definitely
there's
a
lot
of
use
cases
if
you
don't
have,
if
you're
in
cluster
and
if
there's
not
a
tool
that
does
exactly
what
you
want
like
like
plugs
or
paper
like
kpak,
for
example,
the
git
push
use
case
right
we
had
to
use
tekton,
for
that
tecton
is,
is
a
tool
that
allows
you
that
will
execute
for
you
in
a
container
a
script
of
your
of
your
authoring
right.
So
cartographer.
B
C
Run
a
container
photographer
can
orchestrate
things,
but
you
need
some
kind
of
like
arbitrary
activity
to
happen.
You
could
reach
out
to
something
like
a
techton
and
tekton
will
run
any
script
for
you.
So
I
think
that
probably
covers
a
few
of
these
sort
of
cases
where
the
task
that
you're
trying
to
accomplish
doesn't
exist
as
as
a
tool
itself
in
in
in
kubernetes.
C
C
Set
of
google
machines
using
cartographer
so
because
it's
just
this
orchestration
layer
that
can
orchestrate
any
any
any
sequence
of
tools
and
those
those
tools
can
essentially
accomplish
anything,
because
if
there
isn't
a
tool
that
does
exactly
what
you
want,
you
can
say
you
can
use
a
tool
that
can
run
any
script
that
you
want.
That
can
make
call
outs.
You
know
that
can
check
things
out
that
are
outside
the
cluster.
Trigger
things
check
check
responses.
C
B
C
Yeah,
so
he's
using
right
he's
goes
from
a
git
source
and
he
provisions
virtual
machines,
so
he's
stamping
out
so
so
that
terraform
kind
of
question
right.
That
repo
would
be
a
great
example
of
how
to
stamp
out
a
bunch
of
virtual
machines
and
so
that
that's
the
approach
that
scott
took,
but
you
can
use
it
as
a
model
if
you
want
to
take
a
slightly
different
approach
so
yeah.