►
From YouTube: CNCF Research End User Group: Air Gapped Solutions
Description
No description was provided for this meeting.
If this is YOUR meeting, an easy way to fix this is to add a description to your video, wherever mtngs.io found it (probably YouTube).
B
B
A
Yeah
good
morning,
everyone
or
good
evening,
depending
on
where
you're
at
I'm
jeff
salens,
I
work
in
the
cnf
working
group
as
one
of
the
co-chairs
right
now
underneath
the
cncf
umbrella.
So
I
work
with
my
friend,
taylor
and
ian
wells
on
around
like
we're
really
focused
on
kind
of
the
network
device
inside
of
containers
kind
of
paradigm,
but
we
typically
work
with
service
providers
and
what
you'll
find
is
that
most
service
providers
run
air-gapped
environments
and
there's
lots
of
lots
of
reasons
for
why
they
have
to
do
this.
A
You
know.
Typically,
you
know
you
want
some
type
of
network
segmentation
when
you're
hosting
the
internet.
You
want
to
keep
your
private
stuff
private,
and
so
typically,
you
know
there's
maybe
at
best
a
proxy,
sometimes
not
even
that,
and
it's
for
you
know
your
typical
security
compliance
reasons
right.
A
So
it's
not
just
the
whole
walled
perimeter,
but
you
know
the
era
of
potentially
pulling
up
a
malicious
image
through
you
know
a
public
repo
you
run
a
helm
chart
and
suddenly
something
spins
up
that
you
don't
want
to
spin
up
and
it
tries
to
phone
home.
If
there's
a
default
proxy
setup,
you
can
get
yourself
into
trouble
really
really
fast.
A
A
So
the
other
big
thing
right
is,
you
know
you
got
to
start
with
an
internal
repository.
It
could
be
any
of
the
favorite
ones.
You
know
it
could
be
artifactory,
it
could
be
harbor
be
homegrown,
but
one
of
the
biggest
things
that
you
have
to
instantly
you
know
get
all
the
people
who
want
to
move
fast
to
not
do
is
to
basically
just
turn
that
into
a
proxy.
A
A
So
if
you
put
don't
put
the
right
restrictions
in
place,
I
know
typically,
the
word
restriction
isn't
really
liked
in
the
the
cloud
native
world,
because
everybody
wants
to
be
agile
and
move
fast
and
get
things
on
demand,
but
we
found
that
it
actually
saved
us
a
lot
of
pain
by
controlling
what
releases
were
made.
You
know
available
to
this
far
right
cloud
infrastructure.
A
They
do
things
and
you
will
find
lots
and
lots
of
rando
things
that
slip
through
the
cracks
so
depending
on
what
you're,
using
to
deploy
kubernetes
and
to
you
know
what
images
you're
hosting
you
will
find
that
like
in
you
know
your
ranchers,
your
tan
zoos,
your
open
shifts,
even
a
lot
of
homegrown,
cube,
adm
or
cube
spray
deployments
and
stuff.
There
are
hidden
curl
commands
everywhere.
There's
assumptions
that
packages
are
available.
C
A
Like
I
mean
originally,
we
were
pulling
in
like
the
whole
helm,
repo
right,
like
just
the
stream
helm
repo
and
suddenly
you
start
going
through
everything
and
there's,
like
you,
know,
here's
a
chart
for
deploying
bitcoin
miners
and
we're
like.
Oh,
we
probably
don't
want
this
available
in
our
data
centers
right,
so
we
started
to
build
the
filters.
It
took
a
lot.
I
mean
it's
like
most
automation
tasks.
A
There
was
a
lot
of
pain
and
effort
up
front
and
then
once
we
kind
of
got
to
the
top
of
that,
you
know
hockey
stick
curve.
We
fell
over
the
other
side,
and
so
it
started
with
you
know:
developers
just
kind
of
doing
whatever
they
wanted,
which
you
know
it's
just
because
they're
trying
to
get
stuff
done
and
then
they
would
try
to
go
and
deploy
in
the
air
gap,
environment
and
everything
would
break
we'd
go
collect
all
the
lessons
learned
like.
A
Why
isn't
this
working
you
know
like
which
urls
did
we
not
catch
in
this
chart?
Or
this
manifest?
You
know.
Sometimes
the
containers
themselves
think
that
they
can
reach
out
to
the
internet.
So
you
know
you
spin
up
the
image
and
then
within
the
automation
within
the
container
itself,
especially
if
you're
building
runners
and
stuff
you'll
find
like
all
kinds
of
stuff
baked
into
a
runner
that
suddenly
just
pukes
on
itself.
A
When
you
try
to
do
this
in
an
air
gap
world,
so
that
was
iteration
one
is
you
know,
they're
building
locally,
they
put
it
into
dev
everything
breaks.
We
do
some
analysis,
then
we
got
it
to
where
we
were.
You
know
creating
the
taboo
of
where
we
made
it
to
where
you
would
make
a
request,
the
private
registry,
and
then
it
would
just
automatically
pull
something
down.
Do
the
thing.
But
then
there
was
no
filters
in
place.
A
You
know
the
appropriate
repos
mapped
out,
and
the
other
thing
too
is
you
know,
I'm
assuming
since
the
cncf,
I'm
being
very,
like
you
know,
kubernetes
and
container
focus,
but
we
had
to
do
this
for
everything
right.
So,
like
the
base
os
image,
you
have
to
create
your
image
and
then
all
of
the
tools
that
are
building
that
image.
We
only
let
them
pull
from
the
private
repositories.
A
So
all
of
the
packages.
You
know
whether
it's
yum
or
whether
it's
you
know
debian
based
we're
sitting
there
vetting
all
these
packages,
putting
them
into
the
repository,
then
building
the
images
and
honestly,
once
we
went
all
the
way
to
the
left
in
the
build
process
and
thought
about
what
do
we
actually
need
to
build?
A
We
then
started
to
write
all
the
web.
Hooks
to
you
know,
pull
everything
from
upstream
immediately.
Do
the
scan
and
then
tag
it
make
it
available
for
dev
and
then
eventually
what
we
did
was
the
devs
would
just
build
within
the
dev
environment
or
locally,
but
they
would
point
you
know
their
local
devices
to
the
internal
repositories.
Instead,
when
they
were
doing
specific
repositories
and
then,
if
the
package
wasn't
there
we'd
make
a
note
of
it,
we'd
go
we'd,
get
it
for
them.
A
We
and
they
could
now
do
this,
do
self-service,
but
the
framework
was
already
there
in
place
so
that
they
know
that
they're
not
going
to
pull
anything
malicious
that
it's
going
to
be.
You
know
tagged
appropriately
like
so.
Like
I
said
once
you
get
that
automation
in
place,
then
the
devs
are
allowed
to
kind
of
do
what
they
want,
while
also
still
meeting
like
what
you
know.
Production
and
operations
are
demanding
from
a
security
and
a
compliance
standpoint.
C
A
C
So
and
that's
that's
the
thing
that
I
think
I
find
crazy
at
g
research
where
developers
don't
like
that
developer
box
is
also
air
gapped
and
they
don't
actually
have
access
to
the
internet
and
to
get
to
even
understand
like
what
they
need.
I
don't
I
don't
know
how
they
know
that.
Sometimes,
like
you
want
a
hugging,
you
got
to
go
out
to
the
internet
and
figure
out
which
one
you
want
and
then
to
get
that
inside.
There
isn't
a
proxy.
Yet
anyway,
that
yeah.
A
A
You
know
areas
or
sorry
environments
or
one
of
our
data.
Centers,
there's
basically
like
this
inlet.
That
starts
with
are
you?
Building
on
one
of
the
golden
images?
Are
the
packages
that
you
need
available,
and
so
you
know
we
provide
that
base
template
and
we
we
would
start
giving
out
tips
right
for,
like
the
developers
who
are
building
locally.
Be
like
look.
You
spin
up
this.
You
know
in
virtual
box
on
your
machine
start
with
this
image.
A
A
If
the
answer
is
no
run,
yum
update,
you
know,
add
the
repos
that
you
need
and
then
we'll
check
it
make
sure
that
it's
safe
and
then
once
you
get
into
the
you
know
the
true
pipeline
towards
production
and
you
move
through
dev
you'll
find
out
quickly
whether
or
not
you
built
your
stuff
correctly,
because
it'll
break
in
the
dev
environment,
with
little
risk
to
you
right
like
dev,
is
we
treat
it
truly
as
dev?
If
stuff
breaks?
A
That's
okay,
but
it's
not
going
to
let
you
build
anything
that
you
did
not
see
it
in
that
private
repo.
So,
like
you
know,
it's
on
the
developer
to
kind
of
keep
track
of
what
may
not
be
available
for
them,
and
then
you
know
they
need
to
run
the
diffs
to
find
out.
You
know:
where
are
they
going
to
fall
on
their
face,
and
sometimes
they
don't
know
and
that's
why
we
have
the
dev
environment?
As
you
know,
they
build
it
locally
in
the
box.
A
Okay,
go
deploy
this
and
dev
see
what
breaks
and
then
you
know
typically
it'll
break
two
or
three
times
before
they
catch
everything.
You
know
just
because
they've
pulled
something,
and
you
know
the
amount
of
code
they're,
writing
themselves
versus
stuff
that
they've
just
pulled
from
other
places.
You
know
is
sometimes
very
drastically
way
more
towards
the.
D
A
At
the
old
one
I
mean
you
know,
it
depends
like
a
bunch
of
your.
You
know:
standard
security
scanning
tools,
so
like
image,
scanning
tools,
code
scanning
tools-
you
know
vera
code
x-ray.
If
it
was
in
artifactory
or
prismacloud,
I
mean
a
lot
of
the
big
players
and
we
run
different
kind
of
scans
and
different
types
of
compliance
checks.
Then
we'd
also
have
like
a
battery
of
functional
tests
right.
So,
for
instance,
I
mean
we
treated
the
infrastructure
the
same
as
we
did
the
application
so
like.
A
We
would
have
this
whole
battery
of
tests
to
make
sure
that
all
of
the
packages
we
needed
to
build
kubernetes
existed
for
instance,
and
that
the
packages
that
we
were
putting
together
would
survive
like
sona
bowie
that
would
survive.
You
know
we
would
use
disaster
recovery
methodologies
where
we'd
you
know
back
up
cd,
we'd
completely
nuke
the
cluster
rebuild
from
the
cluster,
and
like
so
I
mean
we,
we
treated
everything
from
top
to
bottom.
Like
you
know
this
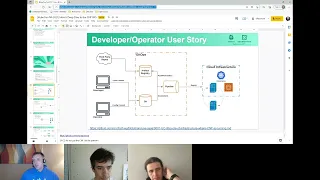
whole,
like
top
left
hand
corner
here,
the
whole
get
ops
thing.
A
You
know
I'm
not
going
to
say
we
were
even
80
there,
but
that
was
what
we
were
ultimately
striving
for,
and
so
whether
it
was
you
know,
all
I'm
doing
is
updating.
You
know
like
cube
adm,
for
instance
right
or
I'm
updating,
cube
proxy.
I'm
updating,
like
I
said,
a
fluentd
thing.
The
application
itself,
I'm
making
an
update
to
the
base
operating
system.
Every
single
one
of
those
was
declared
in
ansible
and
ansible
was
sitting
there
creating
a
mapping,
and
you
can
do
this
with
any.
A
You
know
pick
your
favorite
scripting
modeling
language
of
choice,
but
basically
what
we
would
do
is
we
would
make
you
know
these
infrastructures
code
templates
to
the
best
of
our
ability,
then
put
the
kubernetes
manifest
on
top
of
that
with
the
helm,
charts
and
so
we'd
build
like
this
layered
stack
and
everything
line
by
line
you
know,
would
map
only
to
an
internal
repository
and
then,
like,
I
said
where
we
would
constantly
think
we
were
good.
Is
you
know,
we've
used,
rancher,
we'd
use
tanzania
we've
used
openshift
in
the
past
and
stuff.
A
Is
you
know
our
manifest
would
be
clean
like
the
yaml
driving
ansible
or
the
ammo
that
we
were
pushing
into
kubernetes?
Everything
pointed
to
an
internal
repository,
but
then
there's
some
internal
mechanism
within
tanzi,
for
instance,
that
thinks
it
can
go
back
to
vmware
or
you
know.
Openshift
is
assuming
that
the
satellite
instance
has
access
to
the
internet,
and
that
is
always
when
we
found
all
of
the
gotchas,
as
we
were
trying
to
do
this
or
at
the
application.
C
Yeah
and
in
a
couple
cases
I
mean,
I
run
an
open
source
program
office.
So
in
a
couple
cases
we've
had
to
go
back
to
whatever
project
it
is
and
try
and
fix
their
stuff
so
that
it
doesn't
phone
home
or
there
is
an
option
for
looking
at
an
internal
repository,
or
you
know
some
file
somewhere
kind
of
thing.
Occasionally,
we've
actually
run
into
places
where
people
didn't
want
to
to
fix
the
stuff.
A
You
know
we
walk
a
fine
line
with
open
source
and
also
wanting
you
know
if
we
can
get
it
some
type
of
vendor
supported
backing,
for
you
know
even
open
source
projects.
I
mean
that's
how,
like
you
know,
the
red
hats
of
the
world
make
their
money.
For
instance,
writers,
provide.
You
know,
service
agreements
on
open
source
software,
so
yeah
it
gets
weird
and
it
was
a
lot
of
times
I'll
be
honest.
A
Sometimes
you
just
got
to
take
your
lumps
and
deal
with,
like
you
know,
bruises
that
come
along
the
way,
but
what
we
would
find
sometimes
is
like
certain.
You
know,
open
source
communities
or
vendors
would
be
like.
Will
you
change
this?
So
we're
not
going
to
support
you
and
we're
like?
Well,
then
I
can't
use
your
software
like
it.
That
is
definitely
like
a
struggle
right,
and
so
I
mean
the
with
like
the
more
sane
ones
we
were.
A
You
know
we
even
got
them
to
start
making
it
so
that
some
of
these
things
were
modular
so
like
it
would
actually
like
guide
you
into
like
adding
the
repositories
that
you
would
potentially
pull
through.
You
know
others
gave
us
the
full
heisman
trophy
stiff,
arm
and
told
us,
you
know
if
you
do
this
you're
out
of
compliance
and
then
most
were
somewhere
in
the
middle
right,
where,
like
they
grudgingly
slowly
but
surely,
but
like
I
said
that
was
with
me
wielding.
A
You
know
my
company's
name
behind
me
and
being
like
I'll
go
to
this
other.
You
know
competitor
or
I
mean
even
in
the
open
source
world
right
like
I
mean
how
many
different
log
porters
are.
They
are
you
know,
everybody's
convinced,
there's
the
best,
I'm
like
hey
I'll
I'll
switch
from
fluent
d
to
log
stash.
If
you
guys
are
gonna
beat
jerks,
you
know
like
and
like
they're,
they
still,
you
know
they.
They
want
their
babies
to
succeed.
So
even
in
the
open
source.
A
There's
some
level
of
you
know,
protection
and
willingness
to
try
to,
like
you
know,
make
your
software
project
stand
above
the
rest,
so
I
mean
we
definitely
kind
of
leveraged
that
a
little
bit.
It's
definitely
harder.
You
know
if
you're
like
an
eight-man
startup
and
your
lead
devs
like
hey.
I
have
to
do
this
because
of
this
and
they're
like
yeah.
We
don't
care
about
you
that
that's
definitely
going
to
be
a
much
bigger
challenge.
C
Yeah,
it's
you
know.
We
we've
been
mostly
successful,
except
where
the
people
we're
trying
to
convince
are
so
big.
They
just
decided
to
ignore
us.
There's
google
and
amazon
come
to
mind
the
aws
one
that
comes
to
mind
currently
is
something
in
the
client
that
they
don't
actually
follow
the
http
standards
for
redirection,
and
we
point
this
out
to
them
and
they're
just
like
yeah
we're
not
going
to
fix
that
like,
but
it
doesn't
yeah.
A
A
Too,
you
have
to
decide
where
you're
like
so
the
amazon
example
right,
if
you're
using
eks
as
cni,
it's
it's
a
routable
ip
address
throughout
your
vpc
right.
So,
like
you
really
have
to
like
understand
too,
and
I
come
from
like
a
networking
background,
so
the
legacy
model
of
security
of
you
know,
I
think
of
things
and
like
perimeters
and
like
you
know,
you
know,
here's
this
walled
garden,
here's
this
well!
A
Like
I
think
someone
I
think,
ricardo,
you
said
at
the
beginning
that
a
lot
of
people
in
this
group
you
know
work
in,
like
you
know
the
the
education
space
like
at
universities
or
like
research
and
stuff.
So
I
mean,
like
you
know,
I'm
assuming,
like
cern,
you
know
like
they
probably
like.
Don't
even
have
a
fiber
line
running
to
anything
that,
like
so
there's
no
risk
of
it
right
I
mean
if
you're
gonna
do
that,
then
you
need
to
make
sure
that
your
dev
environment
is
gonna.
B
B
Controlling
the
machines
or
or
the
accelerator
is
is,
is
very
much
controlled,
but
then
you
want
to
give
developers
a
good
experience
and
they
have
a
general
network
where
they
can
actually
get
internet
connectivity
and
do
their
builds.
And
things
like
this
so
imagine
like
one
situation
would
be
you
do
all
your
work.
All
your
builds
all
your
images
in
some
sort
of
general
network
and
then
through
this
process,
that
you
also
described
of
kind
of
approving
images.
B
To
the
air
gap
is
that
you
actually
have
some
path
for
the
images
to
be
promoted
to
to
be
exposed
in
an
air-gapped
environment.
How
this
works
could
be
done
in
different
ways,
but
let's
say,
for
example,
you
will
have
two
hardware
instances,
one
in
a
general
network,
another
one
in
a
network
and
you
will
control
the
what
gets
replicated
automatically.
B
But
then
the
question
here
is:
if
you
would
have
deployments,
both
in
multiple
air
gap,
environments
and
you're
running
instances
of
a
registry
in
each
of
these
aircraft
environments.
How
much
do
you
hide
this
from
the
applications
and
from
the
developers?
Because
there
are
some
things
you
can
do
like,
for
example,
have
mutating
web
hooks
that
will
just
rewrite
the
registry
to
use
a
local
registry
things
like
this.
How
far
do
you
go
into
making
this
invisible
to
the
to
the
service
managers,
developers
etc?.
A
So
the
answer
is,
it
depends,
which
I
know
is
a
cop-out
but
I'll
explain,
because
for
one
there's,
there's
lots
of
ways
to
solve
this
air
gap
right.
So
I
definitely
don't
want
to
propose
solutions
just
because,
depending
on
your
environment,
I
mean
one
proposed
solution.
Is
I
take
a
thumb
drive
and
I
walk
to
all
the
different
environments
and
I
plug
it
in
and
I
upload
it
to
the
registry.
But
you
know
what
you
were
saying
about
having
multiple.
A
That
was
the
single
source
of
truth
for
everybody,
and
we
then
had
a
bunch
of
satellites
in
different
environments
where
they
would
have
a
private
connection
to
the
source
registry,
but
then
other
than
that
they
were
only
accessible
to
that
local
environment.
And
then
we
had
a
mirroring
strategy,
and
so
what
this
afforded
us
was,
since
we
had
a
single
source
of
truth,
where
we
basically
had
a
single
instance
to
write.
A
But
you
couldn't
read
from
it
because
we
didn't
want
to
over
tax
the
thing
that
was
like
you
know
our
master
source
of
truth
and
then
everyone
else
was
a
read
in
its
local
environment
and
was
only
accessible
there.
But
then
your
your
point
about
you
know
mutating
web
books
is
basically
then
I
could
take
an
image
and
deploy
it
anywhere,
and
there
was
just
this
assumption
that
there
was
a
local
registry
within
that
local
network,
and
you
were
always
since
it
was
a
single
source
of
truth
with
a
common
tag.
A
It
doesn't
matter
where
your
software
is
deploying
because
you
get
to-
and
this
is
something
this
I
mean-
and
this
took
us
like
18
months
to
get
to
so
I
don't
want
to
make
it
sound
like
it's
trivial,
but
basically
it
got
to
the
point
where,
like
a
developer,
would
write
one
image.
You
know
that
they
would
then
push
upstream
into
that
source
of
truth
and
that
one
image
got
to
make
the
assumption
that
it
was
going
to
call
you
know
a
local
url
and
since
they're
private
networks.
A
You
know
we
leveraged
things
like
anycast
addresses
on
the
networking
side
and
then
we,
you
know,
got
a
little
bit.
You
know
loose
with
them,
some
of
our
url
naming
because
you
know
these
were
all
in
isolated
environments.
You
know,
depending
on
which
data
center
you're
in
and
stuff,
and
then
we
would
control
in
our
route
tables
what
networks
were
and
weren't
exposed.
A
And
so
then
you
know
your
software
deploys
in
any
of
our
different
data
centers
or
any
of
our
different
vpcs
or
other
public
cloud
instances,
and
it
was
always
assuming
that
the
registry
was
local
to
that
network
and
it
was
common.
So
then
you
have,
you
know
federated
images
and
federated.
You
know
secure
packages
in
these
air-gapped
environments,
but
then,
like
I
said,
I
mean
the
other
way
to
do.
It
is
like
you
could
do.
A
A
Right
like
you
can
do
whatever
you
want
right,
it's
your
device,
you
break
it,
you
fix
it,
you
rebuild
you
go,
but
the
shared
dev
environment
right
definitely
still
allowed
to
break
things
there,
but
we're
hoping
that
you
did
your
due
diligence.
So
then
you
pull
those
images
into
the
source
of
truth.
But
the
first
thing,
as
far
as
like
our
promotion
status,
is
the
tag
first
makes
it
available
only
to
the
dev
environment.
A
So
now
you
have
the
satellites
in
those
air
gap,
dev
environments-
and
this
tag
says
that
you
know
only
these
users.
Basically,
what
we
try
to
get
to
is
you
know.
Policy
is
code,
it's
kind
of
a
buzzword,
but
you
know
using
like
different
policy
engines
and
whatnot.
We
just
made
it
so
the
devs
could
pull
images
in
as
they
wanted.
A
The
policy
would
say
you
know
you
can't
promote
this
image
to
these.
You
know
dev
repos,
until
the
scans
have
been
done
until
the
tests
have
been
run.
If
those
are
successful,
you're
good,
but
once
we
got
the
policy
in
place
and
overcame
that
automation
hurdle,
we
basically
just
kind
of
took
the
reins
off
and
let
the
developers
go
because
the
you
know
left
and
right
limits
were
in
place
to
where
they
could
move
as
fast.
B
A
Yeah,
the
developers
had
a
lot
more
insight
early
on
because
things
were
breaking
and
making
the
mad
and
they're
like
hey.
What's
going
on,
like
I'm
just
gonna
like
fix
this,
but
once
we
kind
of
hit
like
that
18-month
to
almost
two-year
mark,
we
just
kind
of
like
I
said,
fell
over
the
other
side
of
the
hill.
The
policy
was
in
place.
A
Like
you
pull
in
third-party
software,
then
there's
always
going
to
be
some
kind
of
deconfliction
so
but
yeah
we
were
able
to
make
it
so
where
it
was
largely
abstracted
from
them
and
like
once,
we
stopped
making
things
painful
for
them.
They
stopped
asking
us
questions
and
they
just
did
their
thing
awesome.
B
B
C
I
was
just
trying
to
think
of
what
else
we,
how
else
I
think
about
it
from
the
standpoint
of
this.
You
know
we're
an
air
gap
company
and
I
run
an
open
source
team
and
there's
inherent
tension
there,
and
I
don't
know
whether
it's
worth
just
trying
to
think
about
that
tension
and
there's
any
discussion
to
be
had
around
it.
E
For
that
matter,
so
yeah
we,
we
leverage
git
lab
quite
a
bit
for
for
a
lot
of
those
kinds
of
things.
Just
from
an
organization
model
perspective.
We
use
the
you
know
the
runners
and
the
way
that
they're
designed.
We
can
be
a
little
bit
flexible
about
that,
but
we
it
depends
on
what
environment
we're
talking
about,
because
sometimes
it's
kind
of
hard
to
avoid
the
transfer
of
certain
kinds
of
files
without
walking
them
over
and
physically
applying
them
to
said
cluster
space.
E
B
B
Our
environment
as
well
like
we
also
have
a
gitlab,
and
we
explore
a
lot,
the
runners,
but
what
we've
been
trying
as
much
as
possible
now
is
to
have
this
model
that
also
jefferson
is
describing,
which
is
to
have
one
single
source
of
truth
for
all
the
packages,
images
and
have
that
really
tight
and
then
define
policies
on
how
things
should
be
mirrored
or
replicated
to
different
environments
and
yeah
yeah.
Those
those
will
be.
B
B
We
actually
do
the
same
for
external
packages.
I
don't
know,
like
jeffrey
mentioned
briefly,
this
idea
of
having
kind
of
pull
through
caches
in
in
the
repositories.
We
do
that
as
well.
We
we
try
to
enforce
even
on
our
general
networks,
that
nothing
is
pulled
directly
from
whatever
it's
all
coming
through
our
single
source
of
truth,
even
if
that
means
pulling
through
and
and
then
just
making
them
available
after
the
checks.
E
Yeah,
we
do
the
same
thing
where
we
use
policies
to
drive
okay,
where,
where
is
that
single
source
of
truth
that
we're
allowed
to
pull
from
in
order
to
really
tightly
control?
You
know
even
people
within
that
space.
Trying
to
you
know,
do
custom
things
or
try
things
out
directly.
You
know
where
are
they
allowed
to
pull
those
resources
from
so
we
we
control
that
via
policy.
So.
B
I
think
alex
asked
before
about
the
actual
tools
being
used,
maybe
like
for,
for
us.
We
use
specifically
for
container
images.
We
are
relying
on
harbor
and
we
run
the
cve
vulnerability
scanners,
plus
some
additional
checks
that
we
have
in
addition
to,
like
whatever
goes
in
the
in
the
code
themselves
in
the
library
books.
C
Yeah,
I
feel
like
we
were
using
aquasec
at
one
point.
I
don't
know
if
we're
still,
we
are,
I
know
black
duck
because
something
on
the
inside
as
well.
I
I
sometimes
don't
see
all
of
everything,
because
I'm
on
the
outside
those
are
two
that
I
know
that
we're
employing
I
assume
x-ray,
because
we
use
artifactory
as
well.
C
G
Oh,
what
the
timing
I
was
just
about
to
drop
off,
so
I
I
I
have
to
to
admit
that
I'm
in
ibm
research,
so
I'm
a
little
bit
removed
from
production
environment,
although
I
have
been
you
know,
involved
in
you,
know
the
development
and,
and
then
you
know,
okay
and
continuous
integration
and
deployment
from
for
some
ibm
services
before,
but
not
currently
at
at
the
moment.
But
it's
so
you
know
just
a
few
comments
on
some
of
the
little
some
of
the
things
that
were
mentioned.
B
G
G
Are
using
different
pipelines
actually,
so
there
are
some
efforts,
of
course,
to
unify
those
things,
but
you
can,
as
you
can
imagine
you
know,
ibm
is
very
big.
Many
many
units
right
doing
different
things.
So
I
I
don't
see
you
know
one
unified
devsicops
pipeline
with
with
with
fixed
set
of
tools
that
are
forced
on
everyone,
certainly
in
in
in
research.
We
have
flexibility
in
that.
G
G
And
that's
that's
the
other.
That's
the
the
the
other
thing,
of
course,
that
for
some
of
for
some
of
our
projects,
we
have
only
inner
source.
So
we
replicate
like
the
the
github.com
model
in
in
github.ibm.com,
and
basically
we
have
projects
that
people
can
contribute
to.
We
call
it
inner
source
right
following
the
same
open
source
model.
G
B
C
B
B
Interesting
one
as
well,
so
that
will
be
in
two
weeks
march
16th.
I
I'm
just
thinking
if
we
should
cover
both
in
the
same
section,
a
session
or
or
if
it's
even
worth
to
split
because
they
are
not
really
the
same,
like
crossplane
is
more
a
generic
way
to
integrate
external
resources,
while
cluster
api
is
really
focusing
on
one
one
use
case,
so
maybe
we
choose
one
which
one
would
people
prefer.
B
H
H
C
C
C
Klaus
ma
has
a
project
volcano
and
and
there's
a
whole
bunch
of
work
around
batch
scheduling
and
in
one
of
the
tag
sessions
we
thought
that
it
might
be
useful
to
have
a
focused
working
group
on
just
that
as
part
of
the
cncf.
There
is
one
already
happening
as
part
of
kubernetes,
which
met
last
week.
That
was
the
discussion
last
week
we
have
one
going
to
the
cncf
in
general.
B
C
B
And
and
then
I
just
posted
the
link
for
the
this
collocated
event
at
cookon
in
valencia
in
may,
so
the
cfp
is
still
open
until
I
think
monday
next
week,
midnight
pst
so
crazy
for
tuesday.
For
all
of
us,
I'm
supposed
to
link
directly
so
feel
free
to
submit
a
proposal,
including
things
like
the
batch
system
initiative.
It's
probably
worth
talking
about
it
in.
In
this
event,
there
will
be
talks
about
the
kubernetes
patch
working
group
and
the
proposal
for
queue
that
that
that
we
we
saw
in
the
last
meeting.