►
From YouTube: YAML-Defined Dataset Lineage
Description
Edward Vaisman (Wavelo) gives a demo of how you can define Dataset-to-Dataset lineage via YAML during the February 2022 Community Town Hall.
Learn more about DataHub: https://datahubproject.io
Join us on Slack: http://slack.datahubproject.io
Follow us on Twitter: https://twitter.com/datahubproject
A
Okay,
so
hi,
my
name
is
edward
vaseman
and
I'm
a
senior
captain
administrator
at
wavelo
here
to
talk
about
managing
your
lineage
and
data
hub
through
the
use
of
gamma
files.
Just
a
quick
note
about
wave
low,
we
are
a
new
software
business,
that's
on
a
mission
to
make
telecom
a
breeze,
and
all
that
means
is
that
we
want
to
provide
flexible
and
modern
software
to
communication
service
providers
and
in
even
shorter
terms,
software
as
a
service
telecom.
A
Okay,
also
for
those
of
you
who
have
been
on
the
internet
for
a
while
wave
low
is
a
part
of
the
toucas
family.
So
if
that
interests,
you
at
all
two
cows
is
hiring
right.
All
you
have
to
do
is
go
to
two
cows.com
careers
or
you
can
message
me
directly
on
slack
on
the
data
community,
and
you
know
we
can
iron
out
some
of
the
details.
A
So
to
help
bridge
that
gap,
we
recently
contributed
a
file-based
linear
source
to
datahub,
which
will
allow
you
to
start
linking
your
datasets
together.
I
would
say
it's
best
used
as
a
sort
of
duct
tape,
while
teams
are
still
going
through
the
process
of
adopting
a
data,
ops
approach,
but
it's
it's
good
to
at
least
like
get
you
off
the
ground.
I
would
say
so.
A
A
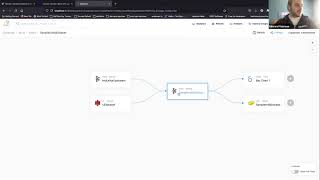
It
already
has
some
lineage
associated
information,
but
when
I
browse
it,
I
notice
that
you
know
what
the
sample
kafka
data
set
doesn't
have
all
the
information
it's
actually
a
little
bit
misleading
in
the
sense
that
it
actually
sourced
its
data
from
other
kafka
topics,
right
which
isn't
present
just
by
looking
at
the
ui
here.
So
let's
go
ahead
and
add
some
new,
a
new
lineage
to
it.
So
the
first
thing
I'm
going
to
look
at
here
is
I'm
going
to
look
at
the
the
recipe
file.
A
The
only
thing
you
have
to
pay
attention
to
in
the
recipe
file
is
that
there's
two
parameters:
there's
a
file
which
just
a
path
to
our
our
lineage
file.
That's
in
yaml
format
and
there's
a
field
called
preserve
upstream,
which
I'll
talk
to
at
a
later
point.
The
type
up
here
you
would
set
to
be
data
hub,
lineage
file
in
the
latest
release
of
pip
right
now,
I'm
just
using
the
custom
plugin
that
I
have
okay.
So,
let's
take
a
quick
peek
at
example
lineage.
A
A
Sample
data
set
I'm
okay
with
this-
I'm
okay
with
this,
I'm
okay
with
this,
and
I
want
to
add
a
new
upstream
for
it.
So
I
know
that
there's
you
know
my
kafka
upstream
somewhere
there
and
you
know
what
maybe
it's
actually
also
grabbing
data
from
another
data
source.
So
I'm
going
to
keep
this
s3
data
set
over
here.
I'm
going
to
quickly
just
run
this
through
the
data
hub
ingest.
A
Okay,
so
it's
already
produced
one
work
unit
for
this
urn.
Let's
go
back
to
datawi,
I'm
gonna
do
a
quick
refresh
and
boom.
Now
we
have
lineage
between
our
sample
capital
data
set
and
our
you
know.
Other
data
sets
currently
only
data
set
to
data
set
connections
would
work,
but
you
know,
depending
on
how
that
data
process
pr
goes.
A
We
might
also
want
to
include
like
an
application
in
between
very
important
for,
like
an
event
streaming
world
where
we
have
microservices
in
between
that
we
may
want
to
link
in
between
topics
or
something
and
as
I
promised,
let's
talk
about
preserve
upstream
so
by
default.
This
is
true
and
all
this
field
does
is
it
determines
whether
or
not
you
want
to
keep
the
existing
lineage
that
already
exists
within
data
hub.
A
A
Do
a
quick
refresh
and
now
our
data
set
only
has
one
upstream
associated
with
it,
and
that's
really
all
it
takes
to
get
lineage
hooked
up
through
a
yaml
file.
Just
a
quick
caveat.
It
only
goes
one
layer
deep,
so
you
can't
just
start
adding
you
know
another
another
upstream
here.
It
won't
look
through
it.
So
if
you
wanted
to
add
another
lineage
for
maybe
this
new
upstream,
you
would
start
with
entity
and
name
whoops
type.