►
From YouTube: Zendesk: Managing Metadata as Code with Protobuf
Description
David Leifker (Zendesk) gives a demo of the new Protobuf Ingestion Source during the March Town Hall.
Learn more about DataHub: https://datahubproject.io
Join us on Slack: http://slack.datahubproject.io
Follow us on Twitter: https://twitter.com/datahubproject
A
So
I'm
an
engineer
at
zendesk,
and
so
one
of
the
things
that
we
have
a
lot
of
kind
of
floating
around
our
system
are
protobuf
schema
files,
and
so
these
protobuf
schemas
get
turned
into
messages
in
kafka
at
the
end
of
the
day.
But
we
have
a
lot
of
legacy
in
you
know
metadata
and
source
code
comments
and
all
kinds
of
stuff
that's
improved
above
so
let's
get
into
kind
of
kind
of
pulling
that
into
data
hub.
A
For
for
wider
usage,
I'm
just
going
to
hit
a
couple
different
points,
just
kind
of
give
you
the
top
level
high
high-level
context
of,
what's
going
on
here,
some
examples
of
just
some.
Some
basic
schema
and
documentation
ingestion
into
data
hub
and
then
we'll
get
into
a
little
bit
more
advanced
features
about
actually
adding
extensions
to
the
protobuf
schema
to
annotate.
A
Your
your
messages
to
pull
in
even
more
data
than
you
know
is
it
was
even
you
know
that
I
thought
possible
when
I
started
this,
so
let's
go
ahead
and
get
right
into
it.
So
you
know,
I
think,
like
most
folks
are
using
protobuf.
We
have
a
cicd
process
that
takes
the
text-based
schema
files
and
generates
our
protobuf
client
libraries.
You
know
our
different
client
bindings,
so
this
was
kind
of
an
opportunity.
A
I
think
for
us
to
kind
of
inject
ourselves
into
that
existing
process
and
pull
in
all
kinds
of
information
into
data,
documentation,
links,
properties,
tags
terms,
ownership
and
domain
on
our
future
roadmap
is
kind
of
looking
at
also
contain
containers
and
deprecation
status.
We
find
that
you
know
for
a
lot
of
the
stuff.
A
So
how
does?
How
does
this
general
process
work?
So
you
might
think
that
we
end
up
parsing
all
these
schema
text
files
and
that's
actually
not
the
case.
We
would
use
the
schema
files
for
the
raw
view
within
data
hub,
but
in
general
we're
ingesting
the
protobuf
descriptor
binary.
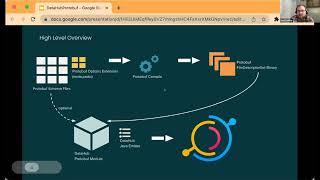
This
is
kind
of
a
temporary
file.
Essentially,
that's
used
when
the
client
libraries
are
being
generated,
so
what
I've
done
is
I've
created
a
datahub
protobuf
module?
A
A
All
right,
so,
let's
just
kind
of
look
at
some
examples,
because
I
think
that's
probably
the
best
way
to
do
it.
So,
at
the
end
of
the
day,
you
know
we're
getting
things
like
documentation,
ownership
tags
and
things.
I've
mentioned
before.
One
of
the
challenges
with
protobuf,
which
are
highly
nested,
is
a
given.
A
Protobuf
file
might
have
multiple
messages
in
it
and
some
of
those
might
be
entirely
nested
and
some
of
those
might
be
top
level
entities,
and
so
there
was
some
work
done
to
take
a
look
at
the
file
structure
and
take
a
look
at
the
graph
of
the
nested
nested
entities
and
try
to
figure
out
what
are
my.
What
are
my
root
entities
and
we
do
that.
You
know
on
a
per
file
basis,
so
like
within
a
given
file.
A
What's
the
root
entity
and
then
also
as
as,
like
the
combination
of
all
your
schemas,
what
are
the
root
entities
and
we'll
pull
those
out?
You
can,
of
course,
override
it
and
say
well,
I'm
interested
in
this
specific
message
to
be
emitted
as
it
as
a
data
set
into
data
hub,
but
we
do
a
lot
of
automatic
detection.
Hopefully
covers
most
use
cases.
A
And
so
you
know,
one
of
our
goals
was,
of
course,
to
have
that
both
the
tabular
view
and
the
raw
view
and
with
the
raw
view
is
optional.
You
know
one
of
the
things
with
protobuf
is
that
your
actual
full
schema
is
off
often
spread
out
through
multiple
files,
and
so
the
raw
view
is
not
a
concatenation
of
all
of
those
different
files.
It's
just
the
the
primary
file.
A
Also,
another
thing
that
you'll
come
across
is
you'll,
you'll
see
a
lot
of
like
well-known
types,
and
we
do
our
our
best
to
map
those
into
you
know
the
data
hub
types,
so
these
are
basically
wrappers
that
google
creates
so
like,
for
example,
I
think
you
know
how
how
we
represent
a
string
or
how
we
represent
the
timestamp
with
primitives.
It
could
be,
could
be
done
in
different
ways.
Essentially,
that's
what
these
wrapper
types
are
doing,
but
we
just
kind
of
support
them
and
show
the
native
data
type.
A
There's
there's
a
bug
in
the
screenshot.
Clearly
it
should
be
a
time
stamp
and
not
a
struct,
but
the
intent.
Is
there
the
other
kind
of
complexities
with
protobuf
schema?
Is
you
know
we
have
you
know?
One
of
so.
We
have
union
types,
we
have
array
types,
we
have
map
types,
we
have
all
of
this
kind
of
complex
structure,
and
all
of
that
is,
you
know,
appropriately
nested
or
appropriately
displayed
within
data
hub
with
with
the
great
support
for
nested
objects
that
already
exist
in
github.
So
that
was
a
good
good
match.
A
The
other
thing
that
our
pro
buff
files
have
is
they
have
a
lot
of
you,
know
c
style,
inline,
documentation
and,
and
we
you
know,
references
and
links
and
things
to
different
sources.
So
we
definitely
wanted
to
source
that
information
from
these
text
files
and
so
we'll
pull
in
things
like
descriptions
on
messages,
descriptions
on
columns,
we'll
pull
out
some
standard
things
like
slack
channel
links
and
get
owners
and
you'll
see
them
populated
as
institutional
memory
and
descriptions
and
the
same
thing
at
the
field
level
too.
A
A
So
this
is
a
base64
encoded
binary
of
the
file
descriptor
set,
which
could
be
reused
down
the
line.
You
know.
Maybe
we
want
to
reingest
that
binary
without
going
through
a
cicd
process
again,
because
we're
just
possibly
updating
the
way
that
we're
parsing,
that
particular
binary
into
data
hub
objects.
A
A
A
Okay,
so
we
are
we're
talking
about
protobuf
here,
so
google
has
protobuf
version
two,
where
they
kind
of
supported
these.
This
ability
to
extend
their
internal
types,
so
these
are
like
options
that
are
kind
of
around
the
the
compilation
of
the
protobuf
files
and
not
actually
part
of
the
message
formats
themselves.
A
So
it's
just
kind
of
ignored,
which
is
great,
so
we
can
use
it
for
our
purpose
and
not
affect
anything
else
downstream
and
there's
two
types:
there's
a
message:
option
and
a
field
option
and
we're
basically
just
talking
about
message:
options
or
data
set
level
options.
Field
options
are,
you
know,
column
levels,
so
this
would
be
like
a
definition
here
where
we
defec
define.
So
our
primary
key,
for
example,
is
a
field
option
and
then
here
we're
actually
setting
that
on
an
actual
field.
A
In
this
case,
a
user
id
and
then
at
message
level
or
data
set
level.
This
is
how
you
would
interact
with
this
particular
metadata
definition
here
and
in
this
case,
we're
passing
tags
on
a
data
set
all
right.
The
other
thing
that
kind
of
we're
supporting
is.
You
can
actually
emit
a
particular
annotation
as
multiple
in
multiple
ways,
so
you
could
have
something
that
is
stored
as
a
property,
a
tag
an
owner
all
at
the
same
time.
There's
not
you
with
that.
One
annotation
can
actually
generate
multiple
aspects
within
data
hub.
A
A
A
So
the
first
thing
I
want
to
talk
about
is
domain
ownership,
so
this
is
the
ability
to
kind
of
you
know,
teams
or
user
ownership.
So
I'm
going
to
create
an
annotation
that
can
be
repeated,
so
we
can
obviously
have
a
data
set,
that's
owned
by
multiple
teams,
and
then
we
also
have
this
ownership
type
too,
so
like,
for
example,
a
data
steward
this.
A
This
name
of
the
annotation
is
actually
you
know,
follows
along
with
the
the
enum
type
that's
defined
within
data
hub,
so
data
steward
and
those
new
types
that
were
just
added
as
well
as
the
legacy
ones
too.
So
the
domain
again
is
is
basically
similar
to
we're
just
going
to
create
an
annotation
for
the
domain
and
then
that'll
be
again
sent
to
the
data
set.
So
this
is
how
we
would
define
that
and
there's
lots
of
examples
on
how
to
define
that
and
then
this
is
how
we
would
use
it.
A
So
we
have
a
message
here:
it's
in
the
marketing
domain,
so
the
marketing
would
generate
your
your
marketing
domain
there.
The
team
ownership
here
would
be
added
to
the
data
set
as
owners,
as
you
would
expect
by
default.
It
is
assumes
a
corp
group.
However,
you
can't
always
override
it
by
specifying
the
corp
user
instead
and
you'll.
A
In
this
case,
we
exposed
it
as
both
the
main
objects
owners
and
then
as
well
as
properties,
so
I'm
just
pointing
out
that
you're
seeing
it
in
both
places,
wherever
we
were
using
a
repeated
or
an
array
of
values
in
the
properties
file,
we'll
naturally
turn
those
into
arrays
json
arrays,
all
right,
so
there's
a
lot
of
different
types
of
properties.
So
this
is
like
us
just
defining
the
different
kinds,
but
at
the
end
of
the
day,
this
is
kind
of
the
output
right.
So
you
can
define
you
know
prop
one.
A
We
can
also
export
tags,
so
you
know
tags
on
both
the
message
or
the
field
levels,
so
we
define
them
like
this
and
again
this
is
more
of
the
same,
but
at
the
end
of
the
day
you
might
have
a
message
that
has
annotations
like
this
and
they're
generated
on
the
data
sets.
These
are
this
particular
field
details
again
the
exact
same
thing,
automatic
generation
tags,
and
then
we
can
do
the
same
thing
with
the
terms.
The
only
difference
with
the
terms
is
that
the
terms
must
exist
within
github.
A
Before
you
try
to
ingest
this
we're
not
actually
creating
new
tag
terms.
We
are
creating
new
tags
that
they
don't
exist,
but
in
this
case
this
must
exist.
I'm
creating
a
protobuf
definition
here.
These
integers
don't
matter,
but
it
just
allows
me
to
use
them
either
as
an
enum
or
as
a
fully
qualified
term,
and
those
again
will
work
on
either
data
sets
or
or
columns,
and
so
just
in
summary,
you
know
where
we're
taking
information
and
annotations
from
photobook
files
and
we're
sending
all
the
information
over
to
github.
B
Want
to
say
that
this
is
yeah
just
want
to
say
that
this
is
actually
really
cool
and
it
really
fits
in
with
our
what
we
are
trying
to
drive
in
kind
of
data
cultures
around
the
world.
Shifting
left
is
what
we're
calling
it
moving
giving
data
producers
tools
to
produce
metadata
right
next
to
where
their
data
definitions
live,
and
this
is
one
part
of
that
story,
huge
thanks
to
david
and
the
entire
team
for
contributing
this.