►
From YouTube: Helping Customers Use GitLab for Deployment
Description
Agenda:
* With Clients, Be a Trusted Advisor, Not a Pundit
* Mutable vs Immutable Stacks
* Integrated Deployment as a Service - What, Why, How
* End Point Management for Mutable Compute
* Mapping Customer Infrastructure and App Deployment Needs to GitLab
Presentation:
https://docs.google.com/presentation/d/1Rp2qORf0jtI9sS0JVKpWvwAiwB5N0dzp4__fAUjAXYM/edit?usp=sharing
A
B
B
Gonna
get
these
two
aligned
here,
all
right,
so
just
quickly
a
few
things
kind
of
a
heads
up
agenda
we'll
try
to
go
through
with
clients
being
a
trusted
advisor,
not
a
pundit,
and
I
think
this
is
important
in
this
area
to
understand
where
gitlab's
strengths
are
and
where
it
kind
of
trails
off.
Also
we'll
talk
a
little
bit
about
mutable
versus
immutable
stacks,
what
they
are
and
kind
of
how
they
came
to
be
we'll
talk
about
integrated
deployment
as
a
service.
B
So
this
is
something
that
I
think,
typically
missed
in
a
lot
of
conversations
with
customers
is
that
there
are
integrated
deployment
as
a
service
capabilities
in
certain
places.
Kubernetes
is
one
of
them
which
has
brought
this
to
the
fore,
but
there
are
others,
and
so
we
kind
of
have
to
have
a
bit
of
an
understanding
of
that.
We'll
talk
about
endpoint
management
for
mutable
compute
commute
compute,
so
compute
that
cannot
be
simply
replaced.
What
are
some
of
the
end?
B
B
B
I've
taken
the
liberty
of
stretching
the
original
ask
of
at
immature
customers
because
I
feel
like
we
have
a
lot
of
potential
to
misstep
here
for
all
of
customers,
so
I
just
wanted
to
make
sure
that
we
kind
of
get
a
handle
on
all
of
it
and
at
the
end
we
have
kind
of
a
decision
tree
that
handles
the
mature
versus
immature
customers,
and
then
I
usually
try
to
make
my
presentations
more
visual,
but
didn't
have
the
time
on
this
one.
Just
a
bit
of
background
about
myself.
B
B
There
are
many
valid
and
sometimes
invalid
reasons
for
customers
to
pursue
patterns
that
aren't
what
we
consider
best
on
point.
So
it's
important
to
not
just
opine
the
primarily
primarily
or
only
the
greatest
and
latest
or
the
best
practice,
so
you
don't
want
to
be
so
strongly
dispositioned
on
that.
You
don't
fundamentally
see
what
the
customer
has
that's
different,
there's
also
natural
limits
on
the
applicability
of
new
practices
to
systems
built
with
previous
methodologies
and,
as
we
all
know,
tech,
that's
a
real
thing.
B
Customers
can't,
you
know,
pull
themselves
out
of
the
mud
overnight,
even
if
they
have
an
application
that
could
benefit
from
that
there's
also
real
and
substantial
cost
to
modernizing,
especially
for
its
own
sake,
and
then
also
keeping
in
mind
that
when
you
work
in
this
industry,
you
have
green
fields
all
the
time.
You
stand
up
a
brand
new
cluster
and
do
some
stuff
on
it.
The
cluster
is
bad.
You
just
delete
it
and
do
another
one
customers
usually
their
world's
opposite,
especially
in
production.
B
They
can't
green
fields
that
production
is
not
completely
immutable,
that
they
can
blow
it
away
and
recreate
it
in
minutes,
and
then
the
characteristics
of
some
systems
mean
that
the
in
context
best
practice
might
be
an
older
practice.
Even
if
it's
a
brand
new
system,
so
it's
actually
the
system
attributes
that
dictate
whether
it's
best
practice
to
be
immutable,
mutable
or
some
sort
of
hybrid,
and
so
it's
important
to
understand
that
the
best
practices
apply
to
the
pattern
of
the
application,
not
the
current
calendar
date.
B
So
it's
really
important
to
understand.
Why
is
your
customer
doing
what
they're
doing
then?
Sometimes
they
can
articulate
that
well
and
sometimes
they
can't
you
want
to
be
careful,
but
about
assuming
that
if
they
can't
articulate
it,
then
it's
irrelevant
or
it's
unchosen
or
it's
not
a
characteristic.
That
needs
to
be
maintained.
So
sometimes
customers
can't
tell
you
why
they
need
to
patch
production
instances.
B
But
when
you
dig
into
the
details
under
the
covers
you
find
out
why
they
have
to
even
though
they
can't
necessarily
tell
you
so
pundicity
is
for
marketing,
and
some
of
us
do
both
right.
You
do
some
marketing,
you
talk
about
best
practices,
best
patterns,
but
trusted
advisorship
is
for
clients.
So
when
you
get
in
front
of
a
client,
you
don't
want
to
be
giving
them
all
the
latest
stuff.
They
already
heard
on
the
best
practices
that
they
can't
get
to
for
some
reason
or
another.
B
So
just
just
a
note
about
handling
these
situations
appropriately
when
we're
in
front
of
customers
versus
marketing,
so
immutability
there's
a
video
out
there
by
hashicorp.
That's
really
good
on
mutable
versus
immutable.
Basically
mutable
means
changeable,
so
the
ability
to
change
things
or
the
necessity
to
be
able
to
change
things
and
immutable
means
unchangeable.
B
So
in
the
case
of
infrastructure,
we
think
of
updating
existing
compute
with
new
application,
binaries
versus
completely
replacing
those
compute
units
with
a
pre-configured
new
set
of
binaries
and
configuration
with
mutable.
Some
of
the
attributes
that
are
typical
are
the
multi-purpose
stacks,
so
monolithic
stacks,
they're,
sharing
resources,
centric,
so
the
whole
reason
we
had
shared
compute,
whether
it's
on
the
mainframe
or
your
desktop
at
home,
is
because
of
the
need
to
share
resources.
You
don't
want
to
have
five
computers
at
home
for
five
different
purposes.
B
B
Mutability
usually
requires
patching
cycles,
so
we
have
to
maintain
the
software
and
the
operating
system
that
underlies
the
application.
So
we
have
that
attribute.
Updates
can
be
smaller
and
more
bandwidth
efficient.
So
when
you
send
five
patches
to
machine,
it's
a
lot
less
bandwidth
than
sending
a
whole
new
machine
or
on
the
machine
image.
B
There
is
a
hybrid,
that's
very
common
on
the
web.
We
externalize
our
state
and
data
and
then
our
compute
is
mutable.
So
if
you
think
of
a
web
server
farm,
that's
on
classic
instances
with
operating
systems
under
it
generalized
compute,
but
there's
no
data
on
them
and
there's
no
state
on
them
so
that
if
one
terminates
a
new
one
spawned
and
we're
good
to
go.
B
Then
we
get
into
immutable.
So
single
purpose
stacks
are
the
the
way
here
they
tend
to
be
application
centric,
so
the
whole
stack
exists
for
this
one
application
or
application
component.
It
creates
a
predictable
tested
configuration.
It
does
require
entire
machine
replacement
cycles
to
do
updates
whether
you're
patching
an
os.
So
you
have
container
os
vulnerabilities
or
any
other
kind
of
update.
B
It
also
requires
an
additional
envelope
release
cycle
and
I'm
not
a
fan
of
these
when
they're
not
necessary,
but
you
get
your
software
ready.
You
test
it,
and
you
say
the
software
is
ready
for
release.
Now
you
have
to
package
it
inside
of
another
binary
asset,
which
you
also
need
to
test
and
release,
potentially
the
separate
version
number
because
it
encloses
your
actual
software
assets.
So
this
can
be
a
downside,
depending
on
the
situation.
B
Is
this
just
a
deployment
concern?
Absolutely
not
so
whenever
developers
develop,
they
develop
against
an
assumed
baseline,
and
this
has
been
the
ongoing
contention
between
dev
and
ops.
Forever
is
what's
the
assumed
baseline,
including
runtimes
versus?
What
did
I
build
it
on
versus?
What
am
I
deploying
it
on,
and
so
this
is
very
much
a
development
concern.
If
you
build
immutably,
then
you're
expecting
your
baseline
to
be
perfectly
exactly
what
you
spec
and
nothing
else.
B
B
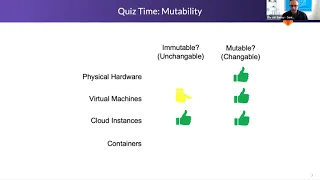
Mutable
mutable,
yes,
mutable,
so
physical
hardware,
you
got
an
os
on
there.
There
was
some
systems
way
back
in
the
day
that
could
make
them
somewhat
immutable,
where
you
could
restore
a
snapshot
of
a
physical
machine
from
another
hard
drive
partition.
Some
of
you
may
have
reset
a
machine
to
its
factory
deployed
state
with
something
similar.
What
about
virtual
machines.
B
Virtual
machines,
I
give
them
a
on
immutable
and
think
of
them
as
more
as
mutable.
You
can
do
implementations
with
virtual
machines
that
make
them
more
like
immutable
compute,
similar
to
what
we
talked
about
with
the
hybrid.
What
about
cloud
instances
so
we're
talking,
about
instance,
based
compute,
a
full
operating
system
standing
on
an
instance
beautiful?
B
C
A
B
B
When
we
have
external
deployment
for
mutable
environments,
it's
a
very
heavy
lift.
So
if
you
think
about
products
that
put
an
agent
on
every
endpoint
and
then
have
a
management
station
and
then
you
send
patches-
and
you
send
software-
and
you
monitor
what's
on
them-
that's
a
very
heavy
lift,
doing
external
deployment
for
mutable
environments,
where
state
and
data
are
changing.
B
Travis
dpl
abstracts
various
deployment
technologies,
but
it
does
not
provide
iac
for
them.
So
this
is
an
example,
and
we
actually
have
a
page
on
our
website
that
says:
use
travis
dpl
as
a
possible
deployment
capability.
However,
it's
just
an
abstraction
layer,
so
the
customer
whoever's
using
it
still
needs
to
know
the
underlying
stuff
and
have
built
their
system
based
on
cloud
formation
or
google's
engine
or
azure
resource
manager.
So
it
just
abstracts
the
deployment
piece.
Only
now
aws
has
what
I'll
call
a
super
catalyst
strategy.
B
They've
been
building
and
giving
away
deployment
as
a
service
integrated
for
long
before
kubernetes
was
around
for
regular
for
all
their
computing.
What
I'll
call
fabrics
they're,
not
technically
a
fabric
as
in
a
host
list,
but
all
application
infrastructures
are
fabrics
where
you
can
deploy
your
applications
to
they're
highly
mature,
so
there's
advanced
deployment
patterns
such
as
canary
and
gradual.
B
If
you
think
about
the
runners
for
this
on
on
amazon,
there
is
no
runners,
it
just
runs
in
the
cloud
when
you
do
this
for
us,
when
we
run
a
deploy,
we
have
to
have
a
runner
somewhere
or
a
scalable
runner
farm
they're,
permissionable,
they're
iac,
driven
by
default.
So
it's
all
driven
by
cloud
formation
or
if
there's
a
sub
sub
involved
like
code
deploy,
they
have
their
own
domain
specific
language.
B
So
some
examples
code
deploy
amplify
has
built-in
deployment
amplifies
a
quick
way
to
build
mobile
based,
apps
sam
quick
way
to
build
server,
serverless
apps
abstracts
certain
things
away
for
you
big
contrast.
Vmware
is
just
virtual
machine
infrastructure.
There's
not
application
fabrics,
at
least
not
to
my
knowledge,
built
right
into
vsphere.
B
There's
no
load,
balancing
no
update
appliance.
Wear
like
there
is
in
amazon.
So
when
you
get
into
vmware,
there's
usually
another
product
involved
to
manage
that
so
integrated
deployment
as
a
service
for
physical
hardware,
do
we
have
integrated
deployment
as
a
service
when
we
have
physical
hardware
or.
B
B
Cloud
instances
can
be
either
way
depending
on
how
you
implement
so
they're
kind
of
a
hybrid
here
as
well.
So
if
you
have
aws
asgs
with
code
deploy,
you
can
either
update
applications
or
replace
the
entire
farm
with
images.
So
you
can
create
a
basically
an
integrated
plan.
Docker
containers,
oops
animations
off
here,
docker
containers
external.
B
B
It's
also
a
heavy
lift
to
keep
that
agent
installed
and
healthy
everywhere.
So
I've
been
in
organizations,
we
have
a
hundred
thousand
endpoints
and
you
have
ten
percent
that
are
unhealthy
at
any
given
time,
just
because
of
sheer
massive
scale.
There
are
many
mature
systems
out
there.
It's
a
massive
product.
Category
updates
can
break
due
to
unexpected
state
and
data,
because
remember
that
state
and
data
is
on
the
compute
nodes
and
so
updates
can
end
up
breaking
you.
B
B
Infrastructure
environments,
something
to
keep
in
mind
everyone's,
like
infrastructure's
code,
infrastructure's
code,
great,
but
there's
not
always
100
immutability
possible.
So
if
you
have
a
paypal,
endpoint
that
comes
into
your
system,
you
have
to
be
able
to
make
sure
that
that
same
paypal
endpoint
is
attached
to
the
right
environments.
B
You
might
have
other
things
in
environments
like
rds,
you
stand
up
a
massive
rds
cluster
to
be
shared
you're,
not
wanting
to
re-stand
that
up
every
time
someone
runs
a
pipeline
because
it
takes
too
long
and
it
consumes
too
much
compute.
So
they
don't
can't
always
be
completely
immutable.
Also,
this
is
a
big
one.
Infrastructure's
code,
that's
engineered
for
bootstrapping
is
not
ready
for
continuous
updates,
so
sometimes
people
think
infrastructure's
code's
magic.
If
I
deploy
with
infrastructure's
code,
if
I
want
to
add
five
nodes
to
a
cluster,
I
just
put
five
and
shove
it.
B
That
might
be
true
for
some
simple
updates,
but
unless
you've
tested
and
engineered
your
infrastructure's
code
to
allow
changes,
then
it
may
break
the
next
time
you
try
to
update
something
with
it.
So
this
is
important
because
it's
a
step
of
maturity
for
customers
and
for
us
in
order
to
have
infrastructures
code.
That's
truly
update,
ready
where
you
can
update
any
part
of
the
infrastructure
and
have
it
pushed
through
and
do
a
in
place.
Update.
B
So
get
lab,
deploy,
auto
devops
deployment
derives
a
lot
of
its
value
from
kubernetes.
So
if
you
understand
the
development
of
git
lab,
the
initial
part
of
all
of
our
deploy
functionality
was
100
kubernetes
you
could,
as
far
as
what's
kind
of
out
of
the
box
and
constantly
download.
Now
customers
can
build
their
own
deploy,
no
problem,
but
a
lot
of
the
way
we
think
about
deploy
comes
from
kubernetes
roots,
so
it's
inherently
abstracted
from
the
underlying
cloud
or
virtual
infrastructure.
B
So
by
being
on
kubernetes,
we
automatically
it
doesn't
matter
what
cloud
you're
on
whether
you're
on
hardware,
whether
you're
on
vmware,
if
we're
just
having
to
interface
with
the
kubernetes
control
plane,
we
don't
care
what's
under
that
line,
which
is
not
true
of
other
kinds
of
compute,
it's
inherently
immutable,
so
it's
containers
so
the
way
to
update
kubernetes
clusters
replace
all
the
containers.
If
you
like
oops,
I
gotta
roll
back,
you
replace
them
with
the
old
copy,
the
containers
it's
inherently
immutable.
B
B
If
you
go
into
google
cloud-
and
you
do
managed
instance
groups-
it's
up
to
you-
whether
you
create
them
in
environments
that
are
separated
from
each
other
by
security
and
networking
or
if
you
put
them
all
in
one
big
blob,
so
there's
not
as
strong
of
support
and
strong
of
an
opinion
on
that
within
other
kinds
of
what
I'm
calling
application
fabrics
inherently
has
integrated
deployment
as
a
service.
So
that's
a
big
part
of
the
value
of
kubernetes
orchestration
is
to
have
that
concept
of
deployment
as
a
service.
B
So
these
are
not
direct
git
lab
attributes,
and
this
is
where
sometimes
I
think
folks
get
confused
is
that
these
are
attributes
of
gitlab
deploy
versus
these
are
attributes
of
gitlab
integrated
with
kubernetes
deploy.
So
that's,
I
think
an
important
understanding
is
that
this
kind
of
update
capability
is
really
when
we
hook
up
gitlab
to
kubernetes,
so
non-kubernetes
in
gitlab
gitlab
is
embracing
some
cloud-specific
integrated
deployment
as
a
service
technologies,
mainly
in
aws,
and
we'll
talk
about
them
in
a
minute.
B
Gitlab
does
not
do
management,
end
agents
for
end
endpoints
for
mutable
compute.
My
opinion
is,
nor
should
we
ever
it's
a
huge
and
massive
rabbit
hole
if
you
step
into
it
thinking
it's
going
to
be
easy,
because
your
experiences
with
mutable
immutable
compute,
the
other
general
rule,
is
when
deployment
as
a
service
exists
for
a
fabric.
You
should
use
it.
B
B
So
whatever
they
do
today
or
implement
a
third
party,
if
what
they
do
today
is
a
bunch
of
shell
scripts
that
might
be
possible
to
integrate
that
in
gitlab,
you'll
find
a
place
on
the
gitlab
website
that
says,
create
a
shell
script
that
remotely
reaches
out
to
all
the
systems
and
does
a
pull
onto
that
system.
That
is,
there's
no
status
updates
on.
What's
going
on,
there's
all
kinds
of
challenges
with
doing
something
that
simplistic
that
are
the
same
as
the
person
running
around
and
updating
each
machine
by
hand.
B
One
thing
that's
interesting
is
if
they
are
doing
stuff
by
hand
right
now,
they've
probably
got
all
the
security
boundaries
and
login
permissions
worked
out,
which
can
be
a
challenge
in
a
net
new
environment.
So
if
you
do
a
net
new,
clean
cloud
environment
and
all
of
a
sudden
you're
saying,
oh,
we
need
to
ssh
to
every
machine
or
rdp
to
every
machine.
There's
a
whole
bunch
of
assurances.
You
have
to
do
around
network
routability,
firewall
openings
as
well
as
services
running
on
the
target
clients.
B
B
So
then
we
are
building
out
or
have
started
our
first
mvc
on
using
git
lab,
auto
devops.
Now,
interestingly,
here
with
our
auto
devops
other
than
kubernetes,
we
don't
necessarily
have
status
coming
back,
so
you
can't
go
to
the
deployment
panel
and
find
out
how
many
instances
have
been
updated
out
of
how
many
total
are
in
the
cluster
aws
ec2
instances
coming
soon.
So
this
is
also
using
code
deploy
so
notice
we're
tapping
into
integrated
deployment
as
a
service.
B
When
we
do
this-
and
this
is
in
my
opinion,
the
right
thing
to
do-
because
we
don't
want
to
have
to
build
a
scaling
runner
farm
just
to
accomplish
deployment
to
5000
instances
now,
if
they're
in
vmware,
maybe
they
do
want
to
do
that,
but
otherwise
we
leverage
what
is
out
there.
One
thing
too,
about
runners
is
runners.
B
We
don't
have
any
meta
controls
in
our
pipelines,
so
in
code
deploy,
it's
services
talk
to
each
other
using
messages
services,
so
there
is
no
container
running
somewhere
during
a
deploy
where
with
us,
we
have
a
container
running
and
it
has
to
be
stay
open
for
the
entire
deploy
and
in
some
big
instances
this
could
be
like
two
days
to
get
the
status
back
or
continually
repeat
the
status.
So
when
you
can
use
a
scaled
cloud
service
a
lot
of
times
that
concern
of
meta
automation
is
handled,
aws
lambda.
B
If
the
customer
wants
to
use
lambda,
they
could
use
code
deploy.
We
don't
have
this
wired
up
to
gitlab,
auto
devops
aws
serverless
is
server
application
model,
which
is
another
abstraction
over
cloud
formation
and
code.
Deploy
that's
a
easy
way,
and
this
is
how
git
this
is,
how
amazon
promotes
to
developers
how
to
do
serverless,
because
they're
trying
to
basically
make
ops
and
deployment
be
a
non-issue
for
development
teams
like
they
don't
need
an
ops
team.
So
if
you
use
serverless
application
model,
the
beauty
of
it
is
on
a
command
line.
B
You
say,
add,
remo,
add
rds
database
services
and
it
goes
chunk
chunk
added
to
your
project
and
when
you
deploy
it,
it
deploys
rds
for
you
by
magic.
So
all
of
these
are
meant
to
kind
of
encapsulate
ops.
Now,
as
companies
grow
bigger,
their
application
is
huge.
They
usually
do
need
ops,
specific
skilling
and
attention.
B
Aws
amplify
is
another
one.
This
is
for
building
mobile
apps
very
rapidly,
it's
another
one
or
at
the
command
line
you
say:
hey,
I
need
cognito
mobile
authentication
services
enter
one
command
line.
It
adds
a
bunch
of
junk
to
your
source
files.
You
deploy
it
again
and
boom.
It
goes
up,
interestingly,
in
this
one.
I
should
indicate
this
here
amplify.
You
can
now
use
git
lab
as
a
deployment
source.
It's
the
only
place
in
amazon
that
I
know
of
where
you
see,
github,
bitbucket
and
gitlab
right
side
by
side
is
on
amplifydeploy.
B
D
B
B
So
you
just
as
the
last
stage-
and
I
think
I'm
going
to
cover
this
in
a
minute
as
the
last
stage,
you
would
simply
fire
up
a
container
with
amplify
cli
on
it
and
say
my
repo
is
here:
it's
got
all
the
source
files
deploy
that
into
amazon
and
what
we
don't
have
and
we'll
be
seeing
in
the
following.
Slides
is
status
feedback
from
that,
so
you
can
still
deploy
it,
but
you'd
either
have
to
have
a
container
sit
there
and
pull
that
service.
B
You
could
sit
there
also
and
deploy
pull
that
service
with
the
client
and
say
how
is
my
aws,
serverless
or
amplify
or
lambda
code
deploy
deployment
going
and
get
status
feedback
and
emit
that
to
a
log?
So
you
you
just
need
one
container
to
deploy
it
one
container
to
monitor
the
status
on
any
of
these
and
any
other
cloud.
B
It
would
basically
be
like
you'd,
say:
aws
lambda
deployment
or
code
deploy
deployment
command
line,
and
you
would
see
that
okay,
you
would
create
your
code
deploy
archive
and
then
on
the
next
command
line.
You
would
push
it
up
until
your
amazon
code
deploy
application.
They
call
it
to
run
an
update
with
that
new
revision.
So
it's
bespoke
marked
to
each
of
these
fabrics.
So
I
would
call
these
fabrics
down
the
left-hand
side.
B
B
D
B
So
one
of
the
reasons
I
wanted
to
go
through
some
of
this
immutable
infrastructure,
the
challenges
of
mutable
endpoints
and
managing
them
is
that
this
is
like.
If
you're,
not
careful
and
you're,
advising
a
customer
on
deployment,
you
can
easily
step
off
a
cliff
or
walk
them
off
a
cliff
because
of
these
various
attributes
and
the
complexities
of
what
kind
of
compute
they
might
be
deploying
to.
It
can
also
inform
you
steering
conversations
or
get
lab
implementation
or
get
lab
povs
a
certain
direction.
B
So,
for
instance,
they're,
like
hey,
we've
got
a
new
team
deploying
to
kubernetes,
and
then
we've
got
all
this
old
crusty
compute.
You
know
on
virtual
machines
or
something
else.
Then
you
can
advise
them
to
pov
on
kubernetes
and
let
them
know
that
whatever
work
has
been
done
to
deploy
to
those
other
environments
will
need
to
be
integrated
into
gitlab.
B
If
the
customer's
green
fields
are
just
getting
started
with
kubernetes,
then
it's
reasonable
to
steer
them
to
get
lab,
auto
devops
and
a
within
the
do
it
within
a
proof
of
value.
I
will
caution
you
that
true
multi-container
microservices
is
something
that
we
don't
have
patterns
for,
so
autodevops
does
assume
one
container
in
one
repo
and
that
when
it
builds
there's
no
there's
not
built-in
capability
to
wire
it
to
other
containers
that
build
out
of
other
repos.
B
If
they
already
know
and
are
using
kubernetes
deployment
directly
so
they're,
like
you
say,
oh
what
are
you
doing
for
deployment?
They
say
we
use
helm
and
coop
control.
You
want
to
be
careful
about
implying
that's
a
real,
simple,
easy
fit
into
git
lab
auto
devops.
Anyway.
Definitely
it's
more
compatible,
but
they
might
be
doing
some
very
opinionated
things
in
there
that
they've
developed
over
time.
So
it
depends
how
long
they've
been
doing
that
and
how
mature
they
are.
With
that,
whether
you
want
to
apply
or
position
that
for
auto
devops.
B
Now
on
these
slides,
I
have
post
pov
paid
pov.
You
could
also
be
pre
pov.
My
assertion
here
is
that
if
you,
if
a
customer,
starts
putting
this
kind
of
criteria
into
a
pov,
I
call
it
a
productionizing
pov,
because
this
is
work
that
normally
might
take
their
people
three
months
to
figure
out
and
you
just
stuffed
it
into
a
one-month
pov,
hopefully
hoping-
and
so
I
always
try
to
be
aware
of
when
a
pov
criteria
is
productionizing.
B
B
Then
using
a
third-party
deployment
solution
in
front
of
kubernetes,
then
I
would
just
say
they
can
then
decide
whether
to
integrate
that
with
gitlab.
So
there's
like
argo
cd
can
deploy
to
kubernetes,
so
you're
kind
of
putting
a
deployment
system
in
front
of
the
built-in
deployment
of
kubernetes
just
like
we
do
with
gitlab.
B
So
you
want
to
be
sure
that
if
they
have
a
really
opinionated
use
of
that
product
that
you're
careful
about
implying
that
it
should
be
a
direct
swap,
they
should
take
consideration
if
they
say
they
just
barely
implemented
argo
cd
like
three
months
ago.
Well,
that's
a
different
case,
so
get
lab,
supported,
non-kubernetes
or
get
lab
auto
devops.
So
this
is
basically
right.
Now,
that's
aws,
ecs
and
ec2
is
coming
if
it's
green
fields
use
it.
B
B
Ecs
support
built
into
autodevops
would
be
a
great
fit
for
them,
because
once
again,
they
might
have
very
opinionated
ideas
about
how
that
should
happen,
and
these
two
are
early
days
for
us,
if
they're
already
using
a
third
party
solution
which
can
have
a
whole
raft
of
issues
wrapped
into
it.
So
some
third-party
solutions
would
be.
B
If
you've
heard
argo
cd,
you've
heard
another
one
on
the
windows
side
is
octopus,
deploy
these
have
environment
management
capabilities
built
into
them
because
remember
they're,
not
in
the
deployment
fabric
in
the
application
fabric.
So
they
a
lot
of
times.
They'll
have
very
complex
config
data
management
built
into
them,
and
we
can
do
some
config
data
management,
but
it's
not
a
direct
user
experience.
B
So
just
be
careful
if
they're
using
a
third-party
solution,
you
might
want
to
suggest
that
they
think
about
integrating
with
it,
especially
on
the
short
term,
and
then,
if
they
want
to
consolidate
over
time
as
they
get
familiar
with
gitlab,
then
they
can
start
to
take
the
metaphors
and
the
work
processes
they've
built
into
this
third
party
tool
and
fit
it
into
gitlab
as
they
become
more
familiar.
But
once
again
you
don't
want
to
try
to
do
that
fitting
during
a
pov.
B
Non-Kubernetes
application
fabric
has
an
integrated
deployment
as
a
service,
so
this
would
be
you
know,
azure
resource
manager,
and
it
has
deployment
as
a
service
built
in.
For
you
know
doing
the
equivalent
of
asgs
and
azure
then
integrated
with
git
lab
mark
to
your
question
many
times
this
will
be.
You
can
do
this
in
a
pov,
because
it'll
be
one
or
two
ci
jobs
that
basically
and
the
customer
probably
already
knows
how
to
do
it.
B
So
rather
than
suggest
doing
scripts
or
even
travis
dpl,
I
would
suggest
hey,
learn
code,
deploy,
get
it
moving
and
then
integrate
it
with
gitlab
using
a
third
party
solution
suggests
that
they
could
potentially
consolidate
into
the
vendor's
deployment
as
a
service
to
have
complexity
and
cost
savings.
But
don't
try
to
do
that
as
part
of
the
pov.
So,
let's
say:
they're
using
octopus,
deploy
and
they're,
deploying
to
amazon
and
they're
wanting
to
save
the
octopus
deploy
cost.
B
You
could
say:
well,
you
might
be
able
to
move
to
code
deploy
at
some
point
in
the
future,
but
you
don't
want
to
try
to
put
that
in
scope
in
a
pov,
no
integrated
deployment
as
a
service
available
green
fields
implement
a
third-party
product
and
integrate
with
git
lab.
So
let's
say
they
got
a
whole
bunch
of
windows,
machines
on
vmware
and
they're.
Managing
it
by
hand.
B
I
would
tell
them
you
might
want
to
think
about
using
octopus,
deploy
and
integrating
that
with
git
lab,
because
that's
going
to
give
them
the
environments
that
we
have
in
kubernetes.
That's
going
to
give
them
a
lot
of
the
complex
data.
Config
configuration
data
management
if
they're
already
using
a
third-party
product,
just
tell
them
to
integrate
it
with
gitlab
lab.
B
If
they
want
to
consolidate,
you
should
tell
them
it's
probably
best
to
integrate
first
and
then
consolidate
later,
as
you
become
more
familiar
with
what
gitlab
can
do,
one
anti-pattern
using
traditional
endpoint
management
to
manage
cloud
public
apps.
So
if
you
get
a
really
unusual
organization,
they
might
be
trying
to
use
so
maybe
a
very
strong,
traditional
it,
and
now
they
have
a
customer
facing
application
on
the
web
and
they're
trying
to
use
something
like
microsoft,
sccm
to
manage.
B
D
B
B
Kind
of
what
I
have
prepared
to
handle
this
topic,
the
green
fields,
is
kind
of
the
original
ask.
So
wherever
you
see
green
fields
on
these
last
two
slides,
that's
the
original
ask
of
what.
If
a
customer
is
brand
new
at
something,
then
take
a
look
at
the
green
fields
items
here
and
that
will
give
you
an
idea
of
what
you
might
advise
them.
B
So
I'm
sorry,
it
can't
be
a
simpler
story,
but
it
all
depends
what
kind
of
application
the
customer
is
moving
where
they
are
in
maturity
with
already
managing
that,
whether
it's
with
products
or
their
own
engineering
capabilities
against
something
like
amazon
and
where
get
lab
is
with
what
it
can,
what
it
can
do
out
of
the
box
and
what
it
what
it
does
not
do.
Out
of
the
box,
thoughts,
questions,
follow-ups.
B
B
B
B
Well,
even
even
if
you
don't
do
the
work
and
they
do
the
work,
it's
going
to
extend
the
pov
because
their
engineers
are
going
to
have
to
understand
how
do
we
do
this
and
all
of
that-
and
so
I
I
call
this
productionizing
povs,
where
they're
trying
to
take
production,
concerns
and
work
them
into
pov.
To
me,
it's
kind
of
like
getting
professional
services
for
free
when
they
wedge
that.
B
B
B
You
know
that's
probably
a
question
for
kurt
or
okay.
They
are.
I
know
that,
like,
for
instance,
I
did,
I
found
a
comparison
of
their
spot
compute
to
aws
spot
compute
and
their
spot.
Pt
is
not
as
suitable
for
runners
because
it
has
a
required
termination
in
24
hours,
30,
second
location
from
the
time
you're
notified
until
they
terminate
the
instance
forcibly
on
you,
and
they
also
had
it's
fixed
price.
B
So
that's
why
they're
forcing
you
to
terminate
every
24
hours
is
because
they
can't
change
the
price
without
you
terminating
and
restarting,
and
where
aws
has
made
it
more
fluid
than
that.
So
it's
a
true
compute
market,
and
so
there's
there
continues
to
be
detailed
attributes
about
certain
parts
of
cloud
infrastructures
that
make
it
suitable
or
not
suitable.
B
So
I'm
not
sure
where
some
of
the
other
clouds
are
with
deployment
as
a
service
built
in
as
I'm
in
alliances
now
I'll,
probably
get
more
brush
up
against
that
and
it'll
automatically
have
some
curiosity
about
understanding
that
portion
of
other
clouds,
but
right
now,
I'm
not
I'm
not
the
guy.
On
that
sorry.
C
C
B
B
B
So
I
think
yeah
be
careful
not
to
confuse
gitlab's
overall,
deploy
capabilities
with
how
well
it
works
with
kubernetes,
because
that
was
first
and
foremost
for
us
and
then
be
careful
about
customers
who
do
have
experience
with
deployment
about
your
implications
that
they
should
use.
Git
lab
instead
and
then
always
be
hopeful
that
whatever
they're
doing
now,
they
can
integrate
it
with
one
or
two
jobs,
a
container
that
has
you
know
even
terraform
most
our
terraform
integration
is
a
container
with
terraform
on
it.
You
run
various
stuff.
B
Well,
almost
anything
else:
that's
truly
infrastructure
is
code
that
you
can
run
at
a
cly.
You
could
do
that
in
gitlab
too.
So
on
that
side,
if
they've
got
capable
engineers
just
tell
them,
yeah
do
a
container
to
deploy
it
another
one
to
monitor
status.
If
you
want
to
see
a
static
status,
I'm
encouraging
the
group
who
builds
deploy
that
we
should
build
a
mirror
the
status
of
all
of
these
other
deployment
as
a
services
back
into
gitlab,
so
be
really
cool.
B
If,
when
we
deployed
to
code
deploy,
we
get
back
the
list
of
instances,
so
we
know
how
many
there
is,
and
we
get
back
at
some
frequency
every
five
minutes,
how
many
are
done
and
how
many
are
in
progress
and
how
many
are
dead.
And
how
many
are
you
know,
so
we
could
pull
that
back
and
represent
it
in
deployment.
So
hopefully,
one
day,
we'll
start
to
get
more
of
that,
but
it's
going
to
be
a
build.
If
you
see
what
we
talked
about,
because
we
don't
have
the
kubernetes
control
plane.