►
Description
A discussion of how to integrate the Peach API fuzzing engine into the GitLab architecture within the six months.
A
What
I
wanted
to
do
is
figure
out,
and
what
we're
trying
to
figure
out
on
Peach
is
how
to
integrate
the
whole
thing.
So
probably
the
best
way
to
do
this
would
be.
Michael
can
probably
just
start
at
baseline,
explaining
what
the
peach
tool
does,
how
it's
architected
and
all
the
constituent
pieces,
and
then
there's
a
couple
diagrams
and
some
discussion
that
we've
had
about
how
to
get
that
in
to
get
lab.
A
So
we
can
start
talking
about
that
after
kind
of
the
baseline
and
then
Lucas
would
just
love
to
open
up
the
conversation
to
get
your
thoughts
on
pitfalls.
We
might
have
other
ways
that
we
could
do
it
and
then
also
just
how
to
navigate
to
get
lab
and
who
we
need
to
talk
to,
because
I
think
as
you'll
see.
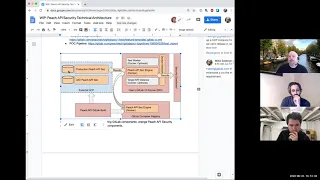
B
So
I'm
gonna
go
ahead
and
start
by
sharing
out
what
things
will
look
like
with
our
kind
of
our
proof-of-concept
integration
and
it's
kind
of
a
good
reference
point
to
talk
about
the
different
components
that
the
tool
currently
has.
So
where
we're
coming
from
is
kind
of
a
system
that
would
run
the
customer
site.
And
so
the
customer
would
have
a
central
server
hosted.
A
The
Mike,
before
you
jump
into
that,
maybe
just
start
even
more
basic.
Well
because
I'm
not
sure
if
you
know
what
peach
does,
but
basically
at
it
at
a
high
level
right.
You
have
a
website
and
peach
access
as
a
proxy
server
and
you
can
run
tests
or
whatever
it
goes
through
the
proxy
server
and
then
peach
will
take
those
requests
and
fuzz
those
requests.
So
it'll
change.
Those
requests
send
those
to
your
server.
Okay,
yeah
I
was
getting
there
yep.
B
Go
ahead
so
yeah
it's
an
arm
print.
It
was
an
on-premises
solution.
They
consisted
of
you,
know
essential
kind
of
UI
point
and
data
store
in
Postgres
SQL,
and
then
the
premise
here
was
that
you
know
you
would
integrate
a
testing
engine
in
your
work
in
your
pipeline
for
your
CI
CD
or
launch
one
as
a
red
team
member.
B
That
would
perform
the
testing
of
a
Web
API
technology
and
the
scanner
would
be
both
kind
of
fuzzing
and
awesome
kind
of
dynamic
analysis,
testing
of
an
API
and
the
system
was
originally
designed
to
be
part
of
a
CI
CD
flow.
So
you
know
we
spent
a
lot
of
time
thinking
about
how
the
components
would
fit
in
and
merged
in
with
the
CI
CD
flow.
B
B
So
I
think
the
thing
that's
that's
you
know
different
from
our
architecture.
Is
you
know
we
have
our
own
kind
of
back-end
system
that
you
know
has
both
a
REST
API
as
well
as
give
a
WebSocket
interface,
where
we
transmit
a
fairly
large
amount
of
data,
large
being
maybe
not
that
large
in
the
scope
of
things.
But
you
know
we
do
have
a
lot
of
data
flow
going
between
this
kind
of
API
scan
engine
bogger
instance.
That
would
run
in
the
CI
runner
and
it
communicates
pretty
heavily
back
to
this
API
security
services.
B
Piece
then
stores
data
in
a
in
a
database
for
the
purposes
of
showing
some
integration.
We're
gonna
start
popping
out
a
a
report
that
gets
picked
up
by
it.
So
the
security
dashboard
get
lab,
as
we
think
of
of
how
we
might
move
this
I
guess
this
would
be
a
good
point
to
stop
and
say:
does
this
making
sense?
Do
you
have
any
questions.
C
B
It's
a
good
question
so
in
terms
of
doing
the
testing
what
we'll
end
up
having
is
on
the
customer
side,
there
provide
a
target
system
that
we're
going
to
test
it
exposes
like
a
REST,
API
or
graph
QL
interface
or
something
of
that
nature,
and
that
might
be
like
this
target.
Api
instance
box.
That's
in
gray,
and
so
what
will
happen?
Is
you
know
our
engine
will
be
provided
you
know
here's
the
API
so
test
or
some
integration
that
lets
us
understand
what
we
need
to
do
to
perform
some
testing
a
list
of
urals.
B
Well,
your
recording
of
some
web
traffic
and
we're
going
to
go
ahead
and
make
connections
to
the
target
API
and
do
some
security
testing.
So
the
tool
has
a
list
of
what
we
call
checks
and
those
checks
can
be
things
like.
Is
your
TLS
stack
configured
correctly?
Do
you
have
insecure
protocol
encryption
algorithms
listed
or
specific
to
the
API
could
be
things
like?
B
C
B
C
B
B
This
you
know
the
the
back-end
service,
which
can
then
committed
to
Postgres
database
logic
for
doing
the
scans
does
largely
does
exist
in
this
engine,
and
so
it's
it's
kind
of
an
odd
combination
of
calling
stuff
on
the
backend
to
say,
like
hey,
we've
identified
and
found
this
rest
endpoint,
here's
some
data,
we're
storing
here's
a
default,
that's
occurred,
it's
fairly,
continuous
back
and
forth.
There.
A
B
So
we
can
be
given
a
llamó
configuration
file
that
we
then
send
up
into
the
production,
the
production
back-end
service,
to
create
a
testing
job
which
then
sends
back
down.
You
know
project
that
we
can
op
that
we
can
load
and
operate
on.
This
is
a
fair
amount
of
serialization
of
data
going
on
back
and
forth
there.
B
B
You
know
the
the
the
operations
that's
hitting
on
the
target
API,
and
then
we
will
start
driving
the
test
worker
runtime
and
have
it
repeat,
doing
the
test
over
and
over
and
over
and
over
again
as
we
modify
contents
of
the
traffic,
and
the
reason
that's
interesting
to
us
is
a
lot
of
times
with
API
is
there's
a
sequence.
You
must
call
like.
We
need
to
create
a
resource,
maybe
we
update
a
resource
and
then
we
delete
a
resource
and
so
to
test
each
of
those
things.
B
You
know
the
easiest
way
to
have
that
logic
given
to
us
is
to
replay
a
test
case,
and
so
in
that
case
will
happen,
is
there's
a
lot
of
data
moving
from
the
test
worker
through
a
proxy
on
the
engine
to
the
target
API
you
and
so
that's
kind
of
why
I'm,
showing
the
stalker
Network
here
is
whether
things
that
we
found
is.
We
were
able
to
use
the
services
feature
of
the
runner,
because
we
needed
to
have
kind
of
this.
B
C
So
the
so
so
I
think
that,
without
without
going
too
deep
into
a
tangent-
and
this
is
similar
to
the
problem
that
we
originally
had
integrating
on
gymnasium,
where
we
essentially
needed
a
Orchestrator
that
would
coordinate
between
a
couple
different
doctor
images.
And
so
the
initial
way
that
we
did
rollout
was
using
a
privileged
docker
and
docker
Orchestrator.
That
would
actually
handle
that
communication
within
the
scope
of
a
single
job.
So.
C
B
Yeah
so
I
think,
as
we
one
of
the
things
that
yeah
so
right
now,
you
know
I
have
an
example
of
providing
a
template
that
kind
of
solves
us
for
the
easier
they
just
provide.
So
we
could
some
container
image
names
and
move
forward.
I
think
what
we're
gonna
do
for
probably
for
our
first
release
is
this
test
worker
will
be
an
optional
component,
but
I'm
gonna
put
a
number
of
the
toolings
that
could
be
there
into
our
kind
of
engine
docker.
B
It
allowed
them
to
provide
some
files,
and
there
at
you
know
as
part
of
their
their
application
assets
that
we
can
pick
up
and
then
use
to
drive.
So
this
schedule
on
mounting
like
slash
app
to
get
access
to
things
and
they
can
pass
it
through
environmental
variables
like
here's,
a
recording
and
web
traffic.
Here's
an
open,
API
specification
and
we'll
start
doing
testing
from
that,
and
then
migration
and
then
a
maturity
path
for
them
is
recognizing.
B
They
could
try
and
perform
an
integration,
and
then
you
know
then
they're
kind
of
stuck
happy
to
have
this
test
worker
docker.
Well,
my
assumption
is
for
a
lot
of
the
users.
They
probably
already
have
an
image
that
runs
their
test
suite
in,
but
they're,
probably
not
just
running
that
from
the
straight
CI
worker,
but
I
I.
Don't
have
you
know,
I,
don't
know
that
for
sure.
B
So,
as
we
think
taking
this
into
a
fuller
integration,
you
know
obviously
so
there's
a
couple
things
that
started
happening
as
we
think
about
how
to
integrate
this
in
the
gait
lab.
One
is
that
you
know
we
were
not
designed.
We
didn't
design
our
database
to
be.
You
know,
small
on
tables.
We
have
an
ORM
layer
that
basic
produces
multiple
tables
per
class
to
possibly
so
right
now
we
have
about
49
tables
in
our
database
and
because
this
is
also
intended
to
be
on
customer
premises.
B
B
So
there's
so
all
the
data
we're
storing
is
either
for
driving
the
UI
experience
or
to
allow
us
to
do
intelligent
things
from
the
testing
standpoint
such
as
one
thing
a
customer
might
might
want
to
do
is
run
a
scan
that
only
that
only
verifies
that
existing
issues
have
been
resolved
right.
So
in
that
case
we
need
to
have
what
could
be
considered
assets
to
our
findings,
meaning
like
full
binary,
request/response
pairs
and
other
information.
B
That
would
not
necessarily
be
always
that
always
needed
in
the
UI,
but
you
know
a
good
UI
for
this
tool
would
show
trend
analysis,
so
a
view
you
would
want
to
have
the
data
is
I
want
to
see
the
number
of
vulnerabilities
of
occurring
over
time.
I
want
to
understand
if
a
vulnerability
is
new
or
old
or
has
come
back
so
allow
that
data
we
could,
you
know
realistically
go
for
the
UI
I
mean
we
could
realistically
give
that
date.
You
know
by
consuming
a
report
that
we
generate
by
app
from
every
test.
B
You
know
the
unicorn
layer,
the
Ruby
on
Rails
layer
could
consume
that
stored
itself
and
emulate
that
UI.
The
thing
that
would
be
the
thing
that
would
be
useful
to
have
for
our
engine,
though,
is
access,
quick
access
to
the
historical
data,
so
that
we
can
use
it
to
improve
new
testing
and
potentially
some
post
analysis
of
the
results
or
the
data
historical
data.
We
have
I
think
what
I
think
about
trying
to
be
couple:
the
UI
aspects
from
the
scan
engine,
the
main
thing
the
scan
engine
is
going
to
want
to
have
access
to.
B
Otherwise,
I
think
that
you
know
we
could
take
the
components
in
this
back-end
that
help
drive
the
scanning
and
push
a
lot
of
them
into
the
scan
engine.
You
know
the
scan
engine
could
have
it
in
memory
database,
the
whole
thing's
temporarily
locally,
and
then
those
can
be
pushed
out
at
the
end
or
there
could
be
some
decoupling
of
the
UI
aspects
versus
the
scan
engine
needs
yeah.
A
B
That's
a
really
good
question:
I
think
it's
going
to
depend,
we
could
probably
come
up
with
a
figure
per
API
I.
Imagine
it's
going
to
be
more
on
the
mega
bites
than
gigabytes
per
scan.
At
least
you
know,
I
think
per
scan
per
API
set.
My
hope
would
be.
It
would
be
under
100
megabytes.
You
know
on
in
a
good
case.
Right,
maybe
would
be
under
20,
20,
Meg.
B
I
think
what
would
be
capturing
there
is
would
want
to
know
it
wouldn't
be.
Every
request
that
we
ever
set
would
want
to
be
intelligent
about.
What
we
kept
I'd
want
to
keep
successful
data
like
one
thing
I
would
want
to
see
is,
would
want
to
build
up
all
the
different
successful
data
for
an
API
that
was
different
so
that
we
had
could
mix
and
match
or
understand.
If
we
have
data
from
a
different,
you
know
run
that
would
allow
us
to
fill
an
optional
portions
of
the
API.
B
B
A
So
there's
two
two
approaches
to
that:
one
is
just
grab
those
tables
move
them
into
the
rails
monolith.
The
other
is
and
I
linked
this
in
one
of
the
issues
potentially
creating
another
database
within
the
chips
with
your
lab.
We
now
have
I,
don't
think
anyone's
done
it.
Maybe
the
container
team
has
done
that
container
registry,
but
we
now
have
the
potential
of
introducing
a
new
database
and
I,
don't
think,
that's
a
huge
deal
from
a
technical
perspective
in
terms
of
adding
it
to
our
packaging
and
all
that
kind
of
stuff.
A
I
think
it
certainly
is
a
cultural
thing
if,
if
we
come
to
the
propose
a
new
database,
so
if
we
move
all
49
tables,
that's
certainly
a
very
boring
solution.
I,
don't
necessarily
know
how
quick
that
would
be
because
I'm
sure
we'll
get
a
lot
of
scrutiny
on
this.
Forty
nine
tables
probably
need
to
optimize
them
quite
a
bit.
A
I'm
also
not
convinced
that
that's
what
gitlab
wants
to
do
long
term,
because
it
seems
like
you
know,
I,
don't
know
how
many
tables
we
have
there
but
like,
if
you
know
close
to
fifty
of
the
tables
that
get
lab
at
shipping
are
just
for
fuzzing,
which
is
frankly,
a
real
small
part
of
gitlab
as
a
whole,
like
our
database
is
gonna,
be
in
the
thousands
of
tables.
If
we
keep
doing
that,
you
know
a
year
two
out
from
now
yeah.
C
A
C
C
It
is
also
is
going
to
make
a
lot
harder
for
us
to
get
some
data
out
of
here.
If
we
actually
like
segmented
off
and
I,
don't
know
how
much
we
want
to
be
tracking
this,
for
the
on-prem
instances
is,
is
NBC
here
on
Prem
support,
or
is
it
Gil
Abdul
commonly
support,
because
just
spinning
up
a
database
and
sticking
up
in
our
GCD
cluster
is
pretty
quick.
So
everything.
A
It's
quick,
except
that
we
don't
have
multi
tenant
built
into
that.
So
what
you're
seeing
here
in
the
blue
box
is
not
multi
tenant
it.
So
we
have
a
proof
of
concept
where
this
is
working,
but
that
little
arrow
in
the
center
that
says
results
that
right
now
has
a
hard-coded,
API
key,
so
Mike's
proof
of
concept.
If
I
were
to
try
to
do
that,
I'd
have
to
use
the
same
API
key.
Obviously
I
could
go
and
look
at
Mike's
results
or
vice-versa.
So
that's
not
something
we
can
ship
to
customers.
A
So
there's
a
potential
that
we
change
that
so
that
you
know
Mike
gets
a
separate
API
key
I
get
a
separate
API
key.
We
figure
out
how
to
make
that
multi
tenant
it
multi
tended,
and
then
that
could
be
potentially
just
in
in
get
lab
comm
and
the
cloud
install
I,
don't
know
that
that
would
be
acceptable
because
I
don't
know
that
we
really
ever
do
something
cloud
first
and
then
the
install.
C
The
other
idea
that
I
think
that
would
be
interesting
to
explore
is
if
we
use
our
cluster
integration
as
kind
of
like
a
baseline
for
this,
which
is
customers
essentially
install
their
own
peach
DB
into
their
group
level
cluster,
and
then
they
can
manage
their
own
data,
that's
all
controlled
by
them.
We
just
provide
basically
a
helmet
art
to
push
it
up
right.
B
Yeah
so
I
think
we
you
know,
Seth
had
brought
that
up
yesterday
and
I
thought
it
was
a
it
sound
yeah.
We
think
about
it.
A
lot
and
I
think
that
there's
you
know
I
think
that
there's
a
couple
things
that
that
solves
for
us
one.
You
know
if
we
think
about
doing
some
post
analysis.
That
does
not
happen
in
the
CI
pipeline.
You
know
stuff
pointed
out.
That
would
be
a
great
way
for
the
customer
to
get
billed
for
that
compute
time.
B
Second,
is
if
we
start
holding
the
fair
bit
of
data
over
time.
That
would
off,
though
the
storage
cost,
the
customer
and
I
think
it
would
be
reasonable
for
us
to
decouple
the
engine
and
the
backend
such
that
we
could,
you
know,
initially
be
used
without
that
data
store,
like
your
results,
won't
be
as
good.
Maybe
we
have
features
turned
off,
but
that's
possible.
B
One
of
the
things
that
happens
is,
if
we
add
a
new
check
to
our
system
like
a
new
thing
that
we
can
look
for.
That
will
cause
at
least
three
or
four
tables
to
have
to
get
generated
and
added
so
at
least
under
the
current
design.
You
know
without
redoing
the
entire
data
layer
I
would
expect
that
we're
gonna
have
more
and
more
tables
being
part
of
our
database,
which
might
be
another
reason
not
to
be
like,
or
at
least
be
aware
of
it.
But
it's
great
that
you're
who
you're
asking
about
that
yeah.
A
A
B
I
guess
the
plate
I
thought
there
was.
If,
if
this
results
line
to
the
dashboard
is
how
we
provide
information
to
drive
the
UI,
we
might
not
need
any
I.
Don't
I,
don't
know
what
that
looks
like,
but
I
would
assume
that
the
UI
UX
people
would
store
it
probably
the
same
way
we're
just
for
a
code
coverage
the
same
way
we're
just
stored
DAST,
it's
not
clear
I
guess
I'd
have
to
look
at
that
and
see.
B
C
B
For
you,
I
driving
would
probably
have
a
view
into
the
results
into
the
testing
that
would
basically
for
a
project
which
would
be
a
target.
Your
testing,
you
know
we
would
want
to.
Basically
one
view
would
be
maybe
like
findings
over
time.
One
view
could
be.
Here's
just
me
find
it
a
lot
of
it
center
around.
The
idea
of
the
vulnerabilities
you
found
are
the
findings.
We
have
found
how
they've
been
reviewed
and
turned
into
tickets.
B
What's
the
trends
around
that
and
so
on
for
our
stuff,
the
views
that
I
have
is
I
have
a
kind
of
that
vulnerability.
Centric
dashboard
view
from
a
UI
standpoint.
We're
then
you
can
drill
into
individual
findings,
and
then
they
have
maybe
links
out
to
JIRA
4,
and
then
we
also
have
a
view
for
testing
jobs.
You've
done
so
anytime,
because
since
we're
in
communication
with
our
scan
engine
anytime,
it
runs
in
a
pipeline.
B
So
I
would
guess
that
the
configuration
aspects
of
the
system
would
be
things
that
we
would.
You
know
I
guess,
because
we
see
relies
in
and
out
all
of
those
things.
You
know
those
tables
would
go
away
from
the
piece
that
did
not
have
the
UI
and
maybe
would
hold
the
whole
thing
around.
Configuration
might
just
go
away
because
we're
gonna
store
it
into
a
yamo
file,
any
UI.
We
have
around
it
in
the
future.
It's
probably
going
to
be
driven
from
the
animal
and
we've
done
in
memory.
C
I
appreciate
the
context:
I
I,
guess
I'm
I'm
looking
over
here,
because
there's
a
discussion
that
I'm
remembering
a
couple
months
ago
around
a
a
table
edition
called
something
like
CI
report
results
that
we
were
adding
to
our
primary
database.
That
essentially
allows
us
to
aggregate
well
do
any
kind
of
time
series
data
by
aggregating
results
from
pipelines.
C
If
we
actually
do
have
a
bit
of
paradigm
to
find
there,
but
if
it's
any
driving
to
use
like
that,
that
may
be
something
that
we
can
leverage
there.
So
that's
just
me:
vocalizing
I
thought
there,
but
I
guess
the
other
question
I
had
around.
That
is.
If
we
limit
all
of
those
tables,
then
I'm
curious,
what
your
thoughts
are
around
the
remaining
tables
is:
is
there
any
plan
to
I
I,
don't
know
if
you're
really
happy
with
the
current
data
structure
or
if
there's
anything
you
want
change.
B
I
guess
that
discussion
it's
a
little
complicated
based
on
the
fact
that
I
have
milestones
as
part
of
the
acquisition
that
I
must
hit
on
certain
dates.
So
you
know
on
one
level,
I
would
say
that's
not
an
option,
and
it's
not
in
you
know
my
contractual
obligations
to
do
you.
Let's
have
a
horrible
thing
to
say
on
the
other
level,
I
think
that
we're
I
am
absolutely
open
I.
We
should
be
open
to
that
just
being
sensitive
to
to
the
time
and
the
fact
that
I
have
to
hit
these
milestones.
Yeah.
A
A
The
question
is:
how
do
we
do
that
right?
Is
that
refactoring,
some
tables?
Is
it
ripping
out
some
configuration
and
making
it
ya
know
based?
Is
it
having
the
results,
go
to
the
security
dashboard
and
not
having
some
of
the
historical
analysis
in
the
in
the
in
the
UI?
That
is
part
of
peach
today,
so
I
think
there's
a
there's
a
hundred
questions,
I
think
at
the
end
of
the
day,
what
we're
just
trying
to
do
is
figure
out.
A
A
A
B
One,
the
one
limitation
on
the
tables
we
have
right
now
is
we
have
a
at
ORM
layer
that
auto
generates
our
tables
based
on
our
class
structure.
So
you
know
if
we
start
talking
about
making
large
changes
to
the
data
structure
there
has
to
be.
You
know,
mapable
into
my
art,
into
my
other
classes
or
I.
Have
we
have
to
rewrite
an
entire
day
layer
for
the
system,
so.
C
Okay,
okay,
so
that
that
makes
sense
it
sounds
like
where
we
can.
We
don't
want
to
move
things
around
and
I
guess
the
Colet.
The
only
question,
then,
is
if
we
need
to
move
anything
around
to
make
it
work,
but
as
far
as
like
solving
the
multi-tenant
issue,
without
major
changes
around
customer
control
of
their
data
around
having
what
we
have
today
and
getting
it
deployed,
I
think
that
the
the
idea
of
cluster
integration
is
really
promising
direction.
A
Yeah
yeah
the
alternative
to
the
cluster
integration,
that
what
we
have
I
think
is
basically
this
blue
box,
which
would
be
get
lab
infrastructure,
stands
up
that
blue
box.
We
make
that
multi-tenant
it,
so
the
change
on
the
code
side
would
be.
We
have
to
make
it
multi-channel
it
and
have
some
kind
of
authentication,
and
then
my
concern
is
that
that
is
one
work
for
infrastructure
team,
which
is
a
different
kind
of
paradigm
that
they're
operating
in
and
then
to.
A
If
you
want
to
run
that
on-premise,
that
becomes
a
distribution
challenge
right,
because
that
requires
a
lot
of
changes
to
how
this
whole
thing
gets
installed,
what
customers
need
and
so
on
and
so
forth,
whereas
if
we
leverage
the
the
kubernetes
work,
you
know,
like
you
said,
we
provide
a
helmet
art
and
you
know:
there's
not
a
lot
that
needs
to
get
changed
in
these
other
parts
of
your
lab.
Yeah.
C
I
think
that
the
biggest
issue
that
both
defend
and
the
configure
team
had
with
that
approach
is
that
the
the
marketable
like
the
addressable
funnel
gets
really
small
really
quickly,
once
you
say
who's
these
in
kubernetes,
okay,
who
wants
to
let
us
manage
your
cluster
in
kubernetes,
okay
and
it
there
is
really
really
quickly.
That
said,
the
I
think
the
important
question
is
whether
or
not
this
needs
to
run
in
the
customers,
infrastructure
or
not
and
I.
C
Don't
think
it
if
all
they
need
to
do
is
spin
up
a
cluster
and
we
support
multiple
clusters
at
a
group
level
or
a
project
level.
Then
this
can
be
an
entirely
isolated
cluster
I
I,
don't
see
a
requirement
for
deploying
something
like
there
they're
like
deploying
their
data
store
into
an
existing
like
open,
openshift
environment,
necessarily
like
that
that
could
happen.
But
I
guess
that's
the
big
big
question
so.
B
You
know
addressed
in
the
multi-tenant,
you
know,
I
think
the
multi-tenant
is
very
straightforward
to
add
in
meaning
that
I
think
all
that
needs
to
happen
is
we
need
to
authenticate
the
user
to
the
project
and
so
I
think
my
plan
was
when
we
go
to
create
the
testing
job.
You
provide
the
get
lab
identifier
for
the
project
and
say
the
personal
token
for
the
user
and
then,
if
there's,
if
there's
any
strip,
API
can
hit
either.
B
If
you
read
us
or
whatever
it
might
be
to
say,
here's
a
token,
here's
a
project,
ID,
let's
say
yes
or
no,
then
adding
that
into
our
data
layer
would
be.
You
know
quite
easy
and
all
of
a
sudden.
Now
we
have
the
API
key
goes
away
and
all
we're
talking
about
is
kind
of
doing
a
reasonable
authentication
system
authorization.
C
I
think
there
is
there's
ways
to
do
that
so
I
guess.
The
question
is
where
time
Yuna's
added
I
guess
what
would
be
in
terms
of
Ghaleb
primitives,
a
group
level
right
or
I
guess,
maybe
even
an
instance
level,
because
they're
definitely
like
a
number
of
access
controls
around
there
and
from
like
a
individuals
standpoint
you
something
like
an
access
token,
and
then
it
just
goes
up
from
there.
But
I.
A
C
C
So
if
you
get
lab
comm,
we
have
a
get
lab
dashboard
namespace,
that
is
a
group
and
then
there's
subgroups
below
it.
So
at
a
if
we
have
the
main,
like
the
rails,
monolith
right
there,
it
it
runs
off
kubernetes,
but
let's
just
assume
that
it's
using
our
cluster
integration,
so
you
can
find
a
cluster
at
an
at
a
instance
level,
a
group
level
or
a
project
level,
and
whether
or
not
we
go
with
the
cluster
integration
is.
Let's
just
consider
that
a
side
note
to
this.
C
This
is
just
a
good
way
of
discussing
like
the
way
that
we
break
down
permissions
and
grouping,
so
you
can
actually
create
a
shared
you.
You
create
a
shared
resource
like
a
cluster
at
a
group
level.
All
projects
under
that
group
have
access
to
that
same
cluster.
They
also
inherit
from
the
instance
level
as
well.
C
So
you
can
define
like
even
define
a
production
environment
and
a
staging
environment
and
use
that
project
environment
to
choose
which
resource
it's
accessing.
So
if
there
is
a
group
cluster,
that's
production
and
an
instance
cluster,
that's
staging
because
we
want
to
scope
a
production
instance
to
more
specific
settings
than
staging
one.
Then
that
means
that
all
projects
on
a
instance
could
use
a
staging
cluster
as
a
resource.
But
then,
when
they
do,
a
production
employee
goes
to
the
group
one.
So.
B
Let
me
see
if
I
understand
this
correctly
Julie,
when
I
think
of
the
spoon
like
a
cluster
I
would
think
of
those,
as
you
know,
kind
of
somewhat
several
permissions
and
the
user
permissions
inside
of
the
actual
application
and
when
you
say
having
something
a
resource
at
a
group,
or
instance,
level
I.
Think
of
like
our
database
was
the
database
when
I
get
an
instance
level.
B
I
would
think
the
database
is
the
resource
and
is
it
running
in
the
instance
or
group
or
project
layer
am
I
in
my
mapping
that
right
or
is
it
actually
tied
into
the
actual
idea
of
a
user
and
project
and
stuff
at
gitlab
and
is
the
resource
smaller
than
the
full
database?
Or
is
it
the
actual
database
itself
so.
C
C
Do
we
have
a
term
for
this?
The
I
guess
the
the
infrastructure
approach
using
something
like
a
the
blue
box
here,
the
tricky
part
there
is
that
we
we
are
essentially
moving
the
segmentation
to
an
application
layer
and
then
the
actual
service
segmentation
is
pretty
much
limited
to
instance,
if
we're
deploying
to
really
deploying
to
Dell
as
a
customer,
then
we
ship
them
a
single
Postgres
database,
just
part
of
the
rails
norm
list
and
a
single
Prometheus
instance
for
running
metrics
on
that
instance.
C
C
Do
we
want
to
make
that
for
an
individual
project?
So
in
the
case
of
deploying
a
prometheus
instance,
we
do
Prometheus
instance
of
planets
through
cluster
integrations
for
groups,
and
if
you
are
again,
if
you
are
Dell,
you
have
your
e-commerce
team
under
an
e-commerce
group,
and
you
have
your
internal
tools
team
under
an
internal
tools
group,
then
they
can
both
manage
their
cluster
resources
separately.
But
at
some
point
it
reaches
the
instance.
B
C
So
if
we
manage
the,
if
all
authentication
happens
through
the
through
pipelines,
at
least
for
data,
not
the
data
ingestion,
because
if
we
want
to
display
something
in
like
a
equivalent
of
a
scary
dashboard,
then
there
is
an
authentication
that
occurs
through
the
actual
application
and
that's
the
idea
of
meaning
store
like
cluster
credentials,
somewhere
in
our
rails
database,
the
actual
exchange
to
the
cluster
itself.
When
you're
deploying
a
get
live
runner.
If
we
use
a
shared
Runner
and
calm,
then
it
needs
to
be
provided
with
credentials
to
access
an
external
cluster.
C
B
So
the
idea
would
be
that
if
the
API
was
in
the
same
context
as
the
runner,
then
the
clusters-
you
know
authorization-
would
allow
the
runner
to
authenticate
to
the
API
and
access
the
data.
So
then,
if
we
could
extract
Vegas,
then
that
might
the
next
question
is
you
know
if
the
API
ends
up
not
in
the
same
group
as
the
CI
runner,
but
is
there
somebody
that
I
can
get
that
one
that
connects
to
me?
We
can
do
an
intelligent
authorization
of
it
and
say
and
and
how
like,
how
fine-grained
is
that
operation
get?
B
C
B
A
A
Was
yeah
so
I
think
the
one
thing
is
those
environment
variables
get
injected
to
the
runner,
which
includes
something
like
a
CI
token,
which
is
unique
and
I
think
Mike,
maybe
there's
where
you're
going
is
that's
the
eye
token
could
be
passed
to
the
peach
tool
and
then
I
don't
know
that
this
exists,
but
it's
something
we
could
build,
which
is
to
take
that
token.
Go
back
to
get
lab
and
say:
hey
I!
Just
got
this
token.
A
B
Yeah
exactly
so,
basically,
what
I
want
to
be
able
to
do
is
take
some
token
from
the
CI
that
you
know
it's
provided
to
the
CI
runner
that
is
given
to
me
with
the
project
ID
and
name
and
then
I.
Take
that
and
go
to
like
some
sort
of
auth
service
and
say
yes
or
no.
Give
me
yes
or
no
on
that,
but
you
know
I
want,
but
I
don't
want
to
do
is
trust
any
of
the
environmental
variables
that
someone
could
set.
B
So
here's
here's
one
of
the
ideas
I
changed
the
the
image
I'm
showing
here
where
you
know
we
we
might
show
some
some
ApS
DUI,
which
might
go
away,
but
maybe
this
idea
of
this
off
component
that
I
talked
to
you
to
do
the
authorization.
If
I
can
do
that,
then
I
think
multi-tenant
support
is
very
straightforward
and
then
the
only
risk,
and
then
at
that
point
you
know
as
long
as
we
harden
our
be
some
good
QA
on
our
API
pass
and
make
sure
that
we
always
validate
it.
A
C
C
The
only
the
only
reason-
and
maybe
this
is
just
the
quick
way
to
do
it-
for
getting
a
v1.
The
only
reason
I
kind
of
push
back
against
this
is
because
the
idea
of
like
storing
I
know
that
we
have
customers
that
don't
ever
want
their
data
stored
together
and
the
sooner
that
we
can
get
support
for
that
in
place.
Maybe
that's
not
my
target
market,
maybe
I'm
face
there
and.
B
You
bring
up
a
really
good
point,
so
you
know
when
I
think
about
how
to
provide
multi
time
support
one
of
the
things
that
occurred,
I
mean
I,
guess,
I,
guess
the
I
guess
I
should
ask
a
question
first,
which
is
you
know
when
we
say
don't
store
the
data
together?
Is
that
the
same
table
or
the
same
database
I
believe.
A
B
B
Being
you
know,
exacting,
ly
correct,
we're
a
sequel
injection
things,
but
you
know
that
same
premise
is
also
something
that
would
you
know,
allow
us
to
easily
use
different
databases.
You
know,
because
of
the
way
we've
designed
our
M
layer.
You
know
the
idea
of
the
namespaces
in
the
database
is
transparent
to
most
of
the
whole.
You
know,
storage
aspects,
so
that
changes
would
be.
You
know,
kind
of
contained
with
a
few
lines
of
code.
A
C
So
I
guess
the
interesting
thing
is:
if
we're,
if
we
come,
if
it
essentially
comes
down
to,
there
are
no
clever
tricks.
What
you
have
to
do
is
store
our
data
in
a
literally
separate
database.
I,
don't
know
if
that
is
an
actual
requirement,
but
if
it
is
we're
going
to
solve
that
problem
for
Gilad
comm,
as
well
as
the
on
Prem
Prem,
once
the
on
Prem
ones
is
easy,
assuming
that
we
just
scoped
it
to
instance,
level,
Ghaleb,
calm,
I,
don't
know
if
we,
maybe
we
just
don't
support
that.
B
C
But
again,
like
I,
think
that'd
be
custom,
manages
there
in
cluster,
it's
it's
on
them.
That's
that's
the
way
that
we
can
ensure
that
we're
complying
with
every
customer
we've
got
by
having
them
handle
their
own
data.
There's
gonna
be
drawback
to
that,
and,
and
probably
one
of
the
biggest
ones
is
getting
data
collection
back
out
of
those.
Maybe
that's:
okay,.
B
B
A
Think
one
step
like
we
can
take
is
we
should
go
through
the
database
table
by
table
and
figure
out
what
each
table
is
doing,
because
one
of
the
things
that
you
were
talking
about,
which
I
think
we
should
make
sure
we
don't
want
to
do
but
I'm,
pretty
comfortable,
saying
like
things
like
having
opening
up
a
ticket
a
JIRA
ticket
or
something
like
that.
That
is
all
work
that
we
are
gonna
defer
to
our
vulnerability
dashboard.
A
So
our
job
from
a
fuzzing
engine
perspective
is
to
run
the
run
the
tool
and
kick
out
results,
and
then
those
results
are
going
to
be
handled
at
the
dashboard
level.
I
think
for
the
near
term.
You
know.
Maybe
in
a
year
we
can
have
our
own
dashboard,
but
in
the
near
term
we
need
to
kick
out
those
results
and
they're
gonna.
A
Insecure
is
kind
of
clunky
which
is
like
we
take
the
vulnerabilities
and
we
take
on
one
branch
from
another
branch
and
we
do
a
dip
on
the
JSON
files
and
we
say
well,
three
of
those
vulnerabilities
don't
exist.
They
got
resolved
like
we're,
not
doing
it
in
a
real,
clean,
elegant
way,
which
I
think
is
my
kind
of
what
you're
talking
about,
which
is
like.
Let's
see
how
this
happens
over
time
and
and
so
on,
and
so
forth,
yeah.
C
So
from
like
a
individual
standpoint,
one
of
the
bigger
we
opted.
You
know
it's
kind
of
like
an
welcome
from
the
create
side
infrastructure
as
code
everything
stored
in
flat
files,
and
we
can
track
over
time
trends
by
dipping
things
as
things
develop.
So
maybe
like
a
really
radical
change
to
this
architecture,
it
would
be.
Can
we
move
everything,
that's
in
the
database
into
a
flat
file
and
ship
it
as
part
of
the
doctor
container.
C
B
You
know
that,
certainly
if
we
don't
want
to
be
any
historical
data
usage,
you
know
we
could
just
provide
the
configuration
file
have
a
memory
database
and
you
could
be
standalone
I.
Think
when
you
talk
about
saying,
can
we
just
take
the
data
and
then
hand
it
to
Hana
historical
data?
I
know
there
are
some
downsides
to
how
long
it's
gonna
take
to
load
the
data
into
an
internal
database,
the
memory
requirements
of
that
and
then
also
over
time.
It's
just
gonna
get
bigger
and
bigger.
So
there'll
be
some
data
transit
issues.
C
B
B
C
A
A
Don't
know
you
know,
like
all
the
other
stuff
that
generates
a
lot
of
information
in
gitlab
is
flat
file,
and
we
have
this
idea
where
artifacts
expire
and
so
on
and
so
forth
and
I
think
what
we're
trying
to
do
is
get
rid
of
that
idea
and
like,
let's
throw
all
the
stuff
in
a
database,
let's
be
able
to
query
it.
Let's
look
at
it
over
time,
but
yeah
we've
got
this
this
issue
of,
like
it
can
generate
a
huge
amount
of
data
which
can
cause
scaling
issues
for
gitlab
com.
I
I.
A
C
A
And
we
actually
have
this
problem
on
and
and
fuzzing
here,
which
is
like
when
we
run
a
vulnerability
test
right
and
we
hit
a
website
we're
hitting
it
with
the
request,
all
your
headers
and
then
we
get
the
response
right
and
the
webpage
can
respond
with
hundreds
of
kilobytes,
maybe
a
megabyte
of
HTML
or
more
and
let's
say
we
hit
a
thousand
web
pages
right,
we're
generating
a
lot
of
data
and
then,
if
you
want
to
run
that
again,
potentially
comparing
the
results.
That's
a
lot
of
stuff
to
start
throwing
into
a
database.
A
C
Yeah
I
think
that
for
us,
if
we
did
something
like
scope
did
by
group
by
instance,
whatever
providing
an
instance
level,
if
we
provide
a
gitlab
com
instance
level
datastore,
which
is
the
default
datastore,
we
provide
for
all
of
our
sass
customers.
That
would
start
getting
us
some
day
to
start
playing
with
exactly
what
we
want
to
do
there.
But
it
does
provide
the
flexibility
of
having
a
scope
to
individual
instances
or
groups
or
whatever
and.
A
C
C
This
is
one
of
our
demo
projects
for
demo
groups
for
defend
here,
and
we
have
things
like
this.
Is
our
whap
enable
in
demo,
which
is
just
a
project
for
demoing
our
web?
So
this
here
we
have
our
I
know
where
this
is
I
promise
there.
It
is
Hoover
neighs.
So
this
right
here
uses
a
cluster,
that's
defined
in
the
demos.
So
it's
actually
a
group
level
cluster
on
that
one,
and
so
the
environment
scope
is
star
which
just
means
deploy
any
environment
into
this
cluster.
C
C
Well,
yeah,
for
that,
for
this
cluster
is
shared
among
everything
within
demos.
We
don't
really
do
this.
We
don't
really
use
our
own
cluster
feature
for
Gila
org
as
a
group,
but
that's
that's
essentially
how
it
works.
It
also
has
supports
multi
clusters,
so
you
can
just
deploy
that
way
as
well
and
or
add
an
existing
cluster.
Once
you
figure
out
your
are
Bob
commercial
permissions
and
everything
yeah
and
then,
as
you
add
this
here,
it
becomes
available.
B
Think
my
feeling
is
that
to
ask
the
customer
to
do
that.
As
requirement
is
a
pretty
big
asking.
That's
a
lot.
I
understand
it
was
something
that
we
would
need
to
do,
but
I
would
certainly
you
know
since
we're
seeing
this
as
other
issues
for
their
tools.
It
seems
like
we
should
have
and
where
reasonable
solution
that
offloads
the
burden
of
creating
an
AWS
account
and
handling
the
billing
and
stuff
similar
to
what
we
do
with
CI,
where
we,
you
know,
have
a
not
concept
of
CI
minutes
that
gets
billed
to
the
customer.
I.
A
B
A
B
Realistically,
if
we
say
that
we're
not
storing
a
configuration
or
we
stored
it
as
a
yam
yam
o,
all
these
kind
of
underscore
configs
I
believe,
would
fall
away
from
what
is
required
in
the
back
end
and
could
only
might
only
exist
in
the
front
end
when
you
DC
rely.
If
you
were
to
deserialize
it.
This
is
how
we
would
store
it
or
view
it,
and
so
that
has
a
pretty
big
change
because
then
we're
just
talking
about
you
know
these
tables
here,
basically
10
tables
that
I
counted
and
they're
nothing's
really
indistinguishable
from
UI.
B
This
is
just
holding
the
base
of
what
the
project
looks
like
and
then
findings.
So
you
know
here
with
the
faults
and
this
findings
table.
This
would
be
results
from
a
test.
A
job
would
be
a
test
that
ran.
We
can
skip
licensing
since
we're
getting
rid
of
it.
You
know
profile
is
kind
of
connected
into
again
into
the
configurations,
and
then
we
have
this
concept
of
a
project.
B
A
B
Yeah
I
think
the
thing
that's
nice
about,
so
basically,
what
we're
using
is
reusing
a
layer
called
signal
R,
which
is
bi-directional.
You
know
we
have
exposing
objects
directly
over
WebSockets
channel
where
they
can
choose
from
either
binary
representation
or
JSON,
and
so
the
benefits
there
is.
We
don't
ever
do
teardown
of
that
connection,
once
it's
established,
and
so
it's
a
long
living
for
the
for
the
length
of
the
of
the
engine
running
now,
that's
that's!
It's
current,
very
noisy,
chattering
way
of
communicating.
You
know
past
an
initial
integration.
B
You
know
going
and
saying:
okay,
well,
we're
gonna
live
with
that.
Now
to
just
the
data
you
need
to
operations.
I
think
we
get
a
lot
closer
to.
You
know
maybe
be
able
to
get
rid
of
a
lot
of
the
back
and
forth.
That's
going
on
so
nimmy
and
api
would
work
at
that
point.
I.
The
big
question
we
have
to
look
at
is
just
is
is
looking
say:
when
do
we
have
to
pull
data?
And
you
know,
can
we
front-load
a
lot
of
that?
B
Or
is
there
gonna
be
just
a
lot
of
continuous
chatter
right
now,
you
know
fast
path.
For
integration,
though,
is
maybe
to
leave
that
in
place
for
the
time
again
lots
of
lots
of
choices
for
where
we
can
go.
If
we're
willing
to
change
a
lot
of
how
it
works,
how
long
that
will
depend
to
some
extent
on
what
the
users
configured?
Let's
say
they
can
be
anything
from
like
15
15
minutes
to
an
hour
or
more.
If
you
really
want
to
fund
something
a
lot.
C
A
Up
it
just
run
this
job,
and
it
runs
for
days
and
days,
and
this
is
actually
something
that
we've
talked
about
on
the
dash
side
is,
we
would
love
to
be
able
to
stream
results
to
our
dashboard,
so
that
you,
if
you
have
these,
runs
long-running
jobs?
It
gets
results
as
opposed
to
like
right
now.
The
runner
basically
is
like
hey,
you
have
to
get
an
artifact,
and
then
we
can
parse
it
which
doesn't
allow
you
to
do
to
do
real
long
scanning
jobs.
So.
B
You
know
in
the
case
of
a
long
reading
that
it
makes
a
lot
more
sense
than
to
start
thinking
about.
Maybe
our
original
design,
where
originally
we
had
talked
about
you
know
we're
gonna
have
this
back-end
service
and
the
UI
UX
would
actually
communicate
primarily
through
an
API
to
it,
and
you
know
we
have
constant
communication
with
our
engine,
which
is
updating
it
on
new
findings
status
of
its
testing,
and
then
it
can
be
queried
by
the
UI
component
to
display
an
up-to-date
dashboard
things
of
that
nature.
I
think
the
retraining,
the
report
only
works.
B
If
you
know
we're
willing
to
have
you
know
things
that
are
contained
in
a
typical
CI
job
kind
of
length
of
time.
If
we
go,
if
that's
something
we
really
want
to
do
is
go
beyond
that,
then
I
think
at
that
point
we
really
do
you
have
to
have
communication
from
the
engine
to
a
back-end
service
of
some
form,
yeah.
A
And
and
my
my
initial
thought
is
just
going
to
the
results
file
the
Yam
will
file.
Oh
sorry,
the
JSON
file
probably
is
what
will
be
realistic
for
a
milestone,
see
trying
to
do
this
additional
API.
Oh
sorry,
kind
of
this
orange
Fox
to
the
standalone,
where
we're
doing
a
lot
more
I'm
thinking.
That
might
be
too
much
to
try
to
do
in
architecture
for
the
stay
here.
A
B
A
B
B
So
I
mean
well,
I
would
really
need
to
do
there
is
him
is
like
my
back
in
component.
We
need
a
public
key.
The
rails
component
would
mean
to
know
how
to
get
access
to
a
secret,
and
then
you
know
we
would
just
build
an
aweful
off
blob
and
we
could
pass
it
back
and
forth.
We
can
lean
on
GWT,
since
we
understand
it's
it's
it's
bad
points
that
could
be
a
simple
way
than
to
offload
the
authorization
and.
C
A
C
C
B
I,
do
we
do
that
I
mean
we
know
it's
used
to
indicate
to
docker
the
docker
registry
and
the
talk
of
the
registry.
I.
Imagine
it's
been
implemented
is
as
Ruby
on
Rails
as
a
back-end,
so
I
imagine
we
could
probably
just
steal
some
lines
of
code
from
that
expose
an
API
that
can
be
hid
and
then
we
have
authorization.
B
A
B
B
A
I
mean
one
of
the
one
of
my
goal,
or
one
of
my
initiatives
is
the
more
that
we
can
get
this
to
rely
on
the
existing
yet
lab
infrastructure,
the
less
support
we
have
kind
of,
as
as
our
team,
because,
for
example,
if
we
have
our
own
service
or
server
that's
running
and
that's
a
peach
server
that
customers
install.
All
of
that
support
can
come
back
to
us
right
as
opposed
to,
if
that's
built,
on
top
of
the
monolith
or
anything
of
that
sort.
A
A
B
You
know
we
do
like
one
of
the
one
of
the
ways
we
support
using
this
tool
is
as
a
standalone,
meaning
that
this
back-end
component
can
also
run
tests.
So
you
know
here's
here's,
the
minimal
integration
thing
would
be.
We
forget
about
having
a
database,
you
forget
about
having
a
back-end
I,
push
sequel
light
into
the
engine
and
I.
You
know
flip
it
from
Postgres
to
sequel,
light
on
their
ORM.
It's
all
in
memory,
nothing's
nothing's
held
and
then
there's
a
report
generated.
Now
we
don't
have
a
database,
we
don't
have
a
back-end.
B
That
would
actually
be
realistic
to
view
and
then
we
can
consider
and
then,
if
we
need
and
then
we
can
go
from
there
now,
that
would,
of
course
we
wouldn't
have
a
sustained
historical
data
or
anything
like
that.
The
UI
would
be
complete
driven
from
the
report,
and
so
when
support
the
idea
of
the
long
run,
but
that
would
get
rid
of
these.
These
questions
on
the
infrastructure
side,
if.
C
A
And
that's
actually
what
we've
been
kind
of
looking
at
with
some
of
the
coverage
fuzzing
is
just
like.
James
was
playing
around
with
this
like
to
take
an
artifact
from
one
job,
move
it
to
the
next
and
then
to
the
next
to
the
next,
and
there
is
some,
it
was
actually
just
released,
pulling
the
last
successful
artifacts
from
a
pipeline.
So
you
can
do
something
like
that.
I
actually
kind
of
like
this
idea
in
terms
of
getting
this
out
to
customers,
because
it
does,
it
does
hit
some
of
our
goals.
A
I'm,
not
as
concerned
about
the
historical
records.
I.
Think
there's
a
question
for
Sam
I
would
love
the
historical
records,
but
I
can
imagine,
say
I'm
saying
you
know
what.
If
we
get
this
integrated,
we
get
this
out
to
our
customers.
First,
then,
we
can
worry
about
the
historical
data,
because
I
haven't
seen
a
huge
push
on
the
security
dashboard,
necessarily
for
some
of
that
historical
work
like
it's.
B
Well,
the
nice
thing
is,
we
don't
really
have
to
change
much
to
do
that,
so
we're
not
sacrificing
the
ability
that
we
could
do
it.
The
idea
of
a
worker
still
is
there.
The
back
end
is
still.
Is
there
all
it
does?
This
is
simplify
our
initial
MPC,
which
is
probably
towards
the
get
you
lab
ethos.
Anyways
yeah.
A
B
I
feel
at
that
point
the
amount
of
work
to
get
to
Mauston,
see
if
we
do,
that
is
quite
small.
I
mean
I.
Think
that
we've
achieved
that
very
quickly.
Mm-Hmm,
probably
in
the
same
timeline
is
we
would
be
talking
about
milestone,
B
right
because
milestone
B
isn't
very
large
anymore
yeah,
I,
guess
the
only
thing
that
you
know
this
is
a
discussion
that
we
would
need
to
account.
Think
about
is
I
just
need,
buy
off
from
all
parties
and
some
sort
of
written
thing
about.
We
just
had
to
handle
the
agreement.
Yeah
yeah
Ryan.
A
I,
the
the
goal
of
milestone
C
right,
is
to
figure
out
how
to
get
this
into
hands
of
customers,
and
you
know
that
that
may
be
cutting
some
of
the
extraneous
features
or
cutting
the
scope
of
getting
this.
But
I
think
everyone
would
be
really
excited
if,
if
we
got
this
and
take
customers
and
start
playing
around
with
it-
and
it
may
not
have
all
the
historical
or
all
that,
but
customers
will
see
how
how
it's
coming
along.
Okay,
okay.
A
And
and
by
the
way
we
did,
we
did
a
very
similar
thing:
gymnasium
and
Lukas.
Maybe
you
can
talk
to
this.
You
might
have
more
background,
but
gymnasium
had
things
like
Auto
monitoring,
your
projects
and
some
other
functionality,
and
basically
we
cut
a
lot
of
that
functionality
and
brought
it
back
to
much
more
of
a
core
product
when
it
came
into
yet
lab.
A
B
Well,
I
think
that
what,
by
doing
this,
the
only
thing
that
we
need
to
figure
out
is
the
report
format
other
than
that
everything
is
all
ready
for
me
to
go
ahead
and
start
implementation.
Okay,
I,
don't
think
there's
any
real
architecture.
I
feel
like
milestone,
be
the
other
thing
we
add
is
cutting
out
the
backend
and
replacing
the
worker.
I
could
probably
do
that.
Spread,
milestone,
be
and
mohit
and
then
I.
The
only
thing
is,
an
extension
might
be.
Mausam
see,
might
just
turn
out
to
be
vulnerability.