►
From YouTube: Continuous Change Management in a Secure Way
Description
Learn from our director of engineering how to shift left your change management process and why that is important. You will become familiar with the why and how of a safe and secure change management process.
A
All
right
welcome
everyone
to
our
webinar
today.
We're
excited
to
talk
to
you
about
continuous
change
management
in
a
secure
way
for
today's
topic,
we'll
give
folks
just
another
minute
to
join
in
before
getting
started.
While
we
wait,
I
wanted
to
share
some
housekeeping
items
with
you,
we
are
recording
today's
webinar
and
I
will
share
both
the
recording
and
the
deck
with
all
of
you
within
the
next
few
days.
After
our
presentation
today,
I'm
also
joined
by
some
of
my
customer
success.
A
Colleagues
we'll
be
able
to
answer
some
of
your
questions
along
the
way
through
the
zoom
q,
a
feature
you
may
submit
them
via
the
zoom
q.
A
so
we'll
be
able
to
kind
of
take
a
look
at
those
and
help
answer
those
along
the
way
and
just
a
brief
introduction
myself.
My
name
is
Chris
guitarte
I'm,
a
senior
customer
success
engineer
here
at
gitlab
and
I'd
like
to
introduce
you
to
some
of
the
folks
here.
A
That'll
be
talking
to
you
today
on
today's
topic,
a
person
who's
got
Wayne
Haber
he's
a
director
of
engineering
here
at
gitlab,
focusing
on
growth,
security,
governance,
machine
learning
and
anti-abuse.
We've
also
got
Sandra
breenen
who's,
a
customer
success
manager
here
at
gitlab
and
I'll.
You
know
without
further
Ado
I'll
go
ahead
and
pass
it
over
to
sander
to
kick
things
off.
B
So
thanks
Chris,
so
every
company
must
be
great
at
developing
security,
and
developing
software
will
also
cutting
costs.
This
is
really
important
to
every
company
and
every
organization
change
enablement
is
about
according
to
ITIL,
you
know
maximizing
number
of
successful
service
and
product
changes
by
ensuring
that
risks
have
been
assessed,
authorizing
changes
to
proceed
and
managing
the
change
schedule.
Anything
to
add
to
this
sander.
C
Yeah,
so
this
is
also
related
again
to
to
change
management
in
in
general,
where
change
management
has
been
around
for
a
long
time
and
people
organizations
are
constantly
trying
to
to
evolve
in
that,
and
ITIL
is
the
organization
that
sort
of
formalized
that
and
helped
organizations
to
to
professionalize
it
and
in
their
latest
edition,
the
fourth
edition
they
even
added
a
way
to
to
provide
organization.
With
this
continuous
change
management
function.
They
mentioned
that
organizations
might
adds
automation
to
the
change
management
process
in
order
to
provide
this
continuous
change
management.
B
So
characteristics
of
the
challenge,
you
know
manual
approval
processes,
you
know
every
time,
something's
a
manual
approval
process,
you're
waiting
on
people,
and
it
can
be
very
subjective
on
approving
or
not
and
often
people
to
know,
because
they
may
not
fully
understand
thing
or
it's
easy
for
them
to
say
no,
because
they
don't
have
the
full
context
of
the
needs
for
a
change.
External
security
approval
also
separate
security
approval,
not
only
manual
but
sometimes
external
security,
where
they're
not
integrated
into
the
process
fixed
deploy
slots,
we're
only
doing
deploys
at
certain
times
a
day.
B
C
Now
I
think
many
of
these
things
have
been
might
have
been
introduced,
while
adopting
ITIL
to
mitigate
risks,
of
making
changes
to
mitigate
any
problems
and
make
sure
that
the
change
will
happen
correctly
and
without
without
stability
problems,
so
to
say
so
that
yeah,
that's
where
this
is
coming
from
in
the
past
next
slide.
Yeah.
Yes,.
B
C
Yeah-
and
this
is
all
again
following
markets-
changes
with
the
coming
of
e-commerce,
with
a
lot
of
Internet
people
being
on
the
internet,
making
sure
that
your
customers
are
able
to
go
to
your
store
to
buy
something.
So
the
whole
Market
is
evolving.
It's
changing
very
rapidly,
and
organizations
have
to
adapt
to
that.
So
this
whole
shift
in
software
delivery
is
to
keep
up
with
that
yeah
next.
B
So
continuous
delivery
is
about
the
overall
software
delivery,
value
stream
planning
and
creating
so
planning
the
changes
issues
in
epics,
for
example,
integrating
and
verifying
so
doing
automated
tests
having
automated
verification
to
those
tests
doing
both
unit
tests
and
integration
tests
deploying
those
changes
to
automated
deployments.
So
that's
the
continuous
deployment
part
integrate
is
more
The
Continuous
integration
part
so
deploying
those
changes
once
the
tests,
succeed
and
they're
moved
out
to
multiple
environments
and
then
operating
them
to
making
sure
that
they're
they're
working
properly
and
then
also
monitoring
and
improving
them.
B
Looking
at
error
rates
operating
them
in
terms
of
feature,
Flag,
Management
on
new
changes
and
overall
doing
continuous
Improvement,
so
you
can
continue
to
improve
the
overall
service
and
product
that
you're
responsible
for
overall
it
streams,
leads
collaboration
and
eliminates
context,
switching
collaboration
and
content.
Switching
are
both
really
key.
You
know,
collaboration
is
to
make
sure
everybody's
working
together
and
that
the
Systems
Support,
the
people,
not
the
people
being
subjected
to
the
systems
and
being
able
to
work
together
successfully
and
context.
Switching
is
really
important.
B
Is
people
can
focus
on
their
part,
get
their
part
done
and
then
turn
it
over
to
the
system
to
do
the
next
Parts,
which
may
involve
other
people
acting
or
may
not?
That
flow
is
really
important
to
everyone's
morale,
but
also
Effectiveness,
in
terms
of
being
able
to
get
things
done
and
having
continuous
delivery
and
continuous
Improvement
to
supporting
continuous
change
management
allows
for
both
of
those
things
or
how
it
helps
to
support
significantly
both
of
those
things.
C
B
If
developers
are
have
fear
of
making
changes,
creating
quality
issues,
they
slow
down
the
rate
of
change
on
features
and
Bug
fixes,
so
improving
the
quality
and
automating
as
much
of
that
as
possible
and
making
it
so
that
they
can
like
turn
things
off
for
the
feature
flag.
If
there
is
a
quality
issue,
allows
you
to
improve
your
time
to
Market,
because
people
have
more
confidence
that
their
changes
won't
create
an
issue
or,
if
they
do
that,
they
will
be
able
to
respond
to
it
quickly
and
with
low
risk
to
the
users
reduce
costs.
B
Overall,
this
reduced
costs
to
overall
on
the
what
it
takes
to
deliver
these
changes
and
also,
as
we
mentioned
before,
better
collaboration
it
gives
it
enables
each
person
working
their
part
of
the
process.
The
ability
to
do
their
part
and
really
be
a
manager
of
one,
perhaps
so
they
can
do
their
part
and
be
really
successful
and
collaborate
with
others
as
enhanced
by
and
assisted
by
the
systems
not
hindered
by
the
systems
and
processes
of
advice.
C
True
yeah,
that's
how
time
to
Market
is
again
following
these
shifts
that
we've
seen
earlier
and
yeah
the
market
is
rapidly
changing
and
organizations
have
to
adapt.
So
with
agile.
We
saw
that
people
or
organizations
were
much
better
at
changing
requirements
so
that
it's
not
like
in
waterfall
a
lot
of
things
happen
and
then
you
implement
a
lot
of
things
are
written
down
and
you
implement
them
and
half
a
year
later
or
a
year
later
you
have
a
product
so
with
agile
that
changed.
A
C
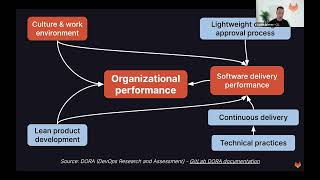
Yeah
organization
performance
is
based
on
did
that
go
into
the
next
slide,
is
good
I'll.
Take
that
one
as
well.
So
it's
a
resource
from
the
devops
research
and
assessment
organization
who
investigated
based
on
the
state
of
death
of
report,
what
organizational
performance
is
impacted
by
and
they
found
that
the
organizational
performance
is,
among
other
things,
impacted
by
software
delivery
performance
which
is
in
the
in
effect,
impacted
or
predicted
by
continuous
delivery
or
continuous
change
management.
C
One
last
note
on
this
approval
process,
so
they
also
found
that
having
a
external
widget
change,
the
proof
of
process
has
no
correlation
to
the
risk
of
failure,
so
the
risk
of
failure,
which
is
why
these
heavy
approval
process
was
introduced
in
first
place,
is
not
changing
due
to
having
a
heavyweight
approval
process
and
it
negatively
correlates
with
lead
time
and
deployment
frequency.
So
your
ability
to
make
changes
will
go
down
if
you
have
heavy
weighted
proof
of
process.
B
And
if
you
think
about
this
in
terms
of
you
know,
as
an
engineering
director
as
I've,
been
as
I
am
at
gitlab
and
have
been
at
a
number
of
companies,
it's
what
are
the
pressures
on
me?
Get
more
done,
you
know,
get
more
features
released
that
benefit
the
users,
get
more
bugs
fixed,
that
users
are
impacted
by
improve
quality.
You
know
Whenever,
there
are
issues,
get
them
thick.
Prioritize
them
fixed
quickly
that
especially
based
on
the
amount
of
impact
there,
but
also
don't
overwork.
B
The
team
make
sure
the
team
has
primer
out
make
sure
the
team
is.
Has
the
ability
to
learn
new
things?
Has
the
time
and
space
to
learn
and
make
sure
the
team
is
enabled
the
team
members
the
employees
are
enabled
to
do
their
job
and
not
where
the
systems,
both
the
the
systems
and
the
processes
that
we
use
support
them
rather
than
hinder
them.
So
those
are
not
necessarily
goals
that
those
goals
can't
exist
in
a
vacuum.
They
all
interplay
with
each
other.
B
So
using
a
process
like
this
and
a
continual
change,
management
really
helps
with
that.
Making
changes
should
be
easy,
simple,
safe
and
secure.
So
they
should
follow
processes
largely
automated.
They
should
be
simple,
prefer
a
boring
solution
over
a
complex
one.
This
sounds
kind
of
like
a
negative
statement.
It
really
isn't
a
boring
solution,
doesn't
mean
it's
boring
is
not
bad.
Boring
is
good.
It
means
it's
easy
to
understand.
It
means
it's
easy
to
implement.
It
means
it's
easy
to
put
an
MVC,
a
minimal,
viable
change
out
there
and
then
iterate
on
it.
B
Complex
ones
are
sometimes
needed,
not
not
very
often
but
sometimes
needed,
but
the
more
you
can
do
it
a
simple
boring
solution
and
iterate
on
it.
The
more
you
can
iterate,
you
can
put
it
out.
There
get
feedback
on
it
from
both
the
users
from
the
engineers
from
the
error,
budgets
from
performance
measurement
and
then
iterate
on
it
and
then
iterate
it
on
again.
B
This
complex
Solutions
take
a
lot
longer
and
they're
using
a
crystal
ball
on
what
may
be
coming
and
that
crystal
ball
may
be
perfect,
but
often
Isn't
So
doing
a
more
boring
solution
to
iterating
on
it
to
improve
it,
as
you
learn,
is
really
key,
in
my
opinion,
being
safe,
so
knowledge
that
if
you
make
a
mistake,
it'll
be
detected
early.
So
you
can
shift
security
to
the
left.
As
far
as
possible
example
is
tell
the
developer
when
they
introduce
a
security
issue
that
they
have
display
it
to
them.
B
As
soon
as
you
see
it
so
that
that
developer
can
fix,
it
can
can
validate
and
fix
it
not
wait
until
the
end
when
it's
much
harder
to
fix
and
harder
to
detect-
and
you
know
also
continuously
check
for
vulnerabilities,
not
only
due
to
changes
that
the
developers
introduce,
with
their
number
of
course,
trying
to
introduce
security
issues
it
just
sometimes
they
do
that
inadvertently.
But
sometimes
security
issues
are
outside.
B
The
control
of
the
developers
might
be
that
there's
a
dependent
library
that
the
code
is
using,
that
the
there's
a
new
security
vulnerability
released
for
it,
that
your
components
are
using
the
developers
didn't
introduce
that
it's
that
there's
an
outside
change
that
you
need
to
take
advantage
of
so
continuously
checking
for
those
vulnerabilities
is
really
key,
whether
you're
updating
the
system
or
not.
There's
security
work
to
keep
an
eye
on
and
act.
C
Yeah
that
one
thing
I
would
like
to
add
to
this
is
that,
with
with
continuous
change
management,
it's
my
vision,
maybe
to
to
pre-friend
vulnerabilities
rather
than
manage
them.
So
if
you
can
put
security
scans
as
early
as
possible
in
your
process,
you
will
find
vulnerabilities
as
early
as
possible
in
your
process.
You
will
find
them
before
the
emergency
request,
even
merged
into
main.
So
with
that,
you
can
immediately
solve
these
vulnerability
findings
before
they
have
even
breached
it
into
the
main
source
line.
C
C
On
the
other
hand,
there's
a
lot
of
projects
and
teams
that
have
a
existing
repository
and
they
are
now
going
to
shift
that
from
security.
So
what
do
you
do
then?
So
in
my
opinion,
all
these
vulnerabilities
that
you
will
find
in
the
first
Scan
they
were
there
already
and,
of
course
you
have
to
manage
them.
You
have
to
look
at
them,
but
that
doesn't
have
to
happen
in
the
first
week
of
doing
that
scan.
C
So
my
advice
would
be
to
still
Implement
these
scans
as
early
as
possible
and
then
configure
configure
them
in
a
way
that
you
only
show
new
findings
in
your
merge
request
and
make
sure
that
you
prevent
any
new
findings.
On
top
of
what
you
already
have
on
your
in
your
merch
request
and
in
the
meantime
you
can
then
work
separately
as
part
of
your
your
release
schedule
or
your
Sprints
Cadence
on
fixing
any
vulnerabilities
that
have
high
priority
on
the
list.
Vulnerabilities.
B
If
you
have
many
branches
of
your
code
and
you
try
to
merge
later,
it
can
be
a
nightmare.
I've
lived
through
that
at
previous
companies
many
times,
I
always
regret
it.
When
it's
long-lived
branches
to
nobody,
loves,
merge
conflicts,
and
this
is
a
way
to
avoid
it
using
minimal
a
minimal,
viable
change,
MVC
model
to
make
continuous
changes
possible
so
doing
those
smaller
changes
and
then
rolling
them
out
and
seeing
how
they
work.
B
You
know
at
gitlab
and
we
recommend
you
know
others
consider
it
if
not
doing
as
well
as
using
feature.
Flags
is
really
important.
So,
for
example,
we
may
roll
out
on
my
teams
and
other
my
peers
as
teams
a
back-end
change
before
the
front-end
change
that
uses
it.
So
it
might
be.
You
know
the
graphql
API
has
a
new
field
or
a
new
function.
New
data
available.
B
B
Here
are
the
issues
that
are
out
there
that
we're
looking
into
here's
the
here's,
the
here's,
the
status
of
them
Etc
and
that
really
helps
to
keep
an
eye
on
these
things
and
not
let
them
get
away
from
you
feature
Flags
to
quickly
enable
or
disable
features
is
key
and
not
just
enable
or
disable,
but
also
do
a
phased
rollout
so
that
you
can
try
it
for
a
percentage
of
users
or
customers.
First
before
all
and
roll
back
as
needed
a
b
testing.
B
The
test,
different
approaches
is
really
key,
so
you
know
you
don't
nobody
has
a
perfect
crystal
ball.
You
don't
necessarily
know,
but
it's
going
to
work
best,
so
you'll
do
different
options
on
things
to
see
how
things
work
and
overall,
improving
so
and
an
example
of
that
right
now
on
one
of
my
teams,
so
we're
working
on
the
AI
code,
suggestions
feature
at
gitlab,
which
is
currently
beta
and
we've
tried
different
models
for
making
code
suggestions.
B
And
then
we
look
at
the
user
acceptance
rate
of
those
suggestions
to
see
which
models
are
working
better
under
what
circumstances.
So
we
can
give
users
the
best
experience
and
also,
as
I
mentioned,
using
incremental
rollout
to
reduce
risk
rolling
out
not
only
to
a
percentage
of
customers
or
users
in
production,
but
also
rolling
out
to
different
environments.
B
So
we
have
our
development
environments,
we
have
our
staging
environment,
we
also
do
canarying,
so
we
send
a
percentage
of
production
traffic
to
servers
to
see
how
they're
going
before
we
fully
roll
the
production,
and
we
do
many
releases
of
gitlab
to
our.com
customers
or
our
hosting
customers
every
day
and
we'll
do
we
never
have
issues?
No,
we
we
sometimes
do
have
issues.
B
That's
why
we
have
feature
Flags,
that's
why
we
have
the
ability
to
roll
back
and
that's
where
we
monitor
these
things
closely
and
we've
gotten
really
good
at
it,
and
the
development
team
has
high
confidence.
They
can
make
changes
with
low
risk
of
being
big
negative
impact,
T
customers.
So
we
can
we
can
they
can
we
that
way
we
get
a
high
rate
of
change
on
new
features
being
released,
while
also
keeping
quality
and
security
and
performance
in
mind
as
well,
so
that
we
can
balance
those
things.
C
Awesome
yeah,
you
see
a
lot
of
the
the
DOA
technical
practices
in
play
here,
so
training
base
development
is
one
there's
also
monitoring
is
one
automation
is
one
I
presume.
You
also
have
test
Automation
in
place
to
make
sure
that
tests
run
automated
and
that
new
test
data
and
test
cases
are
checked
in
the
merge
request,
yeah
so
yeah.
These
are
all
these
technical
practices
that
I
mentioned
earlier.
That
predicts
software
delivery
performance
thanks.
B
You
have
checkups
best
practices
so
work
on
change
management
rather
than
a
change
management
team
work
on
a
change
management
process,
then
a
change
management
team
at
previous
companies.
You
know
in
the
distant
past,
I've
managed
I
led
a
change
management
team
and
it
is
a
thankless
job.
It
is
very,
it
is
very
hard
to
succeed
and
even
though
they
did
succeed,
it
was
with
much
heroics.
B
So
if
you
have
a
process,
both
technology
and
people
process
for
the
people
to
follow
that
supports
the
teams
rather
than
controls
the
teams
or
manages
the
teams
it
it
supports
them
and
facilitates
them.
You
end
up
with
a
much
better,
much
better
Morale
on
the
on
for
all
the
team
members
and
also,
but
just
a
more
effective
way
to
roll
out
changes
quickly
and
effectively.
If
you
want
a
lightweight
automated
change
approval
process,
so
we
don't
have
zero
manual
change
approvals,
bad
kid
lab.
B
B
C
C
This
is
also
what
what
the
devil's
handbook
will
tell
you
so
simply
making
sure
that
your
whole
product
or
software
delivery
process
is
automated
and
optimized
to
provide
flow
of
work.
Autom
not
only
automated
but
continuously,
and
that
you
can.
You
are
able
to
make
changes
to
improve,
to
experiment
with
the
safety
harness
in
place
so
that
you
can
try
things
out
without
breaking
the
entire
product
without
breaking
stability.
So
to
say,
which
is
for
the
upside
of
things,
their
most
important
thing.
B
It
reminds
me
a
bit
of
the
meme
I've
seen
many
times.
You
know
when
I
test
my
code,
I
test
in
production
with
I,
forget
I,
forget
the
actor
the
agenda
put
on
that,
but
the.
If,
if
you
have
the
right
safety
harness,
you
can
test
prior
to
production
and
in
production
with
low
risk.
But
so
you
can
move
quickly
exactly
so
accelerating
into
devops
and
how
to
implement
this
I've
implemented
devops
at
previous
company,
as
I
was
at
years
ago.
B
It
does
take
a
lot
of
change
and
change
management
in
terms
of
people
leadership
and
bring
the
people
along
for
the
process
in
terms
of
the
acronym
columns,
culture,
automate,
lean
measure
and
share.
So
it
is
about
make
sure
you
have
the
support
for
for
accelerating
devops
automating
as
much
as
possible,
bringing
people
in
the
early
adopters
in
early,
knowing
that
not
everybody's,
going
to
be
an
early
adopter,
getting
wins
with
those
early
adoption
teams
and
then
bringing
the
the
middle
of
the
bell
curve.
B
C
C
She
researched
this
and
she
even
found
and
and
described
an
accelerate
book
that
all
these
things
in
the
com
framework
actually
do
predicts
your
performance.
So
a
general
generative
organizational
culture,
a
technical
practices,
lean
product
management,
they
all
add
and
predict
this
devops
performance.
So
therefore,
I
think
this
is.
This
is
very
valuable.
B
They
had
a
transition,
it
covered
this
a
little
bit
earlier.
I
got
a
little
ahead
of
myself.
How
to
reduce
it
from
a
change
management
team
to
a
change
management
process
is
establish.
The
vision
make
a
change
management
plan,
identify
the
stakeholders,
that's
really
key,
so
you
know
not
only
is
it
the
development
teams
and
the
product
management
teams,
it's
security,
it's
infrastructure,
it
may
be
legal,
it
may
be.
You
know,
other
teams
is
marketing.
B
Maybe
other
teams
as
well
so
communicate
effectively
find
your
Champions
and
advocates
in
early
adopters,
as
I
mentioned,
that's
really
key
to
get
some
early
wins
and
then
build
upon
those
not
do
a
a
full
switch
for
everybody
all
at
once.
So
start
small
and
key
in
engineering
Engineers.
They
often
forget
to
celebrate
successes.
B
It's
really
important
to
celebrate
successes,
whether
it's
in
change
management,
overhauling
your
change
management
process
to
be
more
to
be
more
automated
and
enable
people
or
other
things
so
really
key
to
make
sure
to
celebrate
successes
and
also
Monitor
and
evaluate
so
monitor
how
things
are
going
evaluate
how
they
went.
Look
at
the
quality
of
the
releases
as
they're.
More
automated
in
terms
of
bug
rates
in
terms
of
performance,
in
terms
of
error
rates
and
also
in
terms
of
how
often
you
know
the
time
to
merge
a
change.
B
The
time
to
deploy
a
change.
You'll
see
some
Market
changes
as
you
do
more
Automation
in
these
areas,
and
it
can
really
help
to
show
the
value
and
convince
others.
It's
the
right
thing
to
do,
especially
the
middle
of
the
road
folks
in
the
in
the
bell
curve,
and
even
the
win
over
some
of
the
some
of
the
later
doctors
as
well.
C
B
B
I
think
it
was
400
developers.
Work
would
go
into
this
roughly
and
it
would
we'd
schedule
to
do
it
from
9
00
pm
to
3
P.M
three
days
in
a
row.
Two
subsequent
weeks
and
we'd
update
it
quarterly
at
is
hard
on
the
people.
It's
not
updating.
We
would
still
dot
releases
occasionally
when
you
know
when
they
were
criticals,
but
we
wouldn't
put
out
new
features,
except
for
every
every
quarter,
big
new
features-
and
that
was-
and
we
knew
we
needed.
B
We
knew
there
was
a
better
way
and
we
didn't
try
to
do
everything
all
at
once.
We
set
error
budgets.
For
example,
we
chose
teams,
okay,
which
teams
want
to
do
this,
and
do
we
need
to
have
do
this
earlier
in
order
to
get
a
higher
rate
of
change
and
we
decided,
for
example,
the
the
web
portal.
Well,
it's
one
one
of
the
key
components
was
a
lot
of
back-end
work
too
for
the
set
of
systems.
B
The
system
is
going
to
blow
up
when
we
update
it.
If
we're
doing
it
so
often
really
often
and
our
customers
are
going
to
be
upset.
We
said:
okay,
it's
okay
for
some
failures
to
occur.
The
error
budget
is
not
zero
percent.
It's
something
higher
than
zero.
We're
willing
to
take
some
risk
of
some
transactions
and
some
requests
failing
in
order
to
be
able
to
move
faster
and
kind
of
started
there
and
built
on
it.
B
Also,
knowing
that
and
then
other
teams
came
along
over
time
and
we're,
but
some
teams
they
some
people
on
some
teams-
it
wasn't
some
teams
generally,
we
were
just
dead
set
against
it
and
it
was
somewhat
due
to
fear
of
change
and
also,
you
know,
don't
break,
don't
fix.
What's
not
broken,
it
was
kind
of
their
perspective
in
some
cases
when
they
weren't
getting
that
it
was
broken.
You
know
releasing
every
three
months
was
a
non-starter
and
we
really
needed
to
fix
it.
B
B
We
looked
at
the
error
rates
at
the
end,
like
they're,
not
actually
worse
than
they
were
before,
they're,
actually
better,
because
we
can
respond
quicker
to
bugs
so
it's
it
but
start
small
and
build
on
it,
communicate
well
and
know
that
not
everybody's
going
to
buy
in
at
the
beginning,
but
you
win
them
a
lot.
You
win
them
over
to
it
along
the
way.
A
C
B
I,
wouldn't
I
wouldn't
do
an
MVC
approach
and
get
just
enough
of
those
things
to
start
and
then
build
on
them,
and
you
know
I
wouldn't
do
the
reason
in
that
transition
I
mentioned
we
did
the
web
application.
Is
it
was
possible
that
changes
to
the
web
app
could
break
the
back
end
data
like
we
could
record
incorrect
data,
which
that's
a
two:
it's
a
one-way
door
versus
a
two-way
door,
that's
hard
to
back
out,
but
it
was
generally
at
the
end
of
the
process
displaying
the
data.
B
I
might
start
with
the
mobile
app
that
the
bank
has,
because
it's
it's
important,
it's
very
important
it
it's
and
but
you
can
iterate
on
it
quickly
and
you
know
I
wouldn't
start
with
the
back
end
systems
that
are
processing
the
actual
banking
transactions.
If
you
break
that,
if
you
people,
if,
if
the
money,
if
the
number,
if
the
account
data
is
wrong
and
who
has
how
much
money
in
which
accounts
that's
a
bad
thing
and
also
so
I
would
start
with
the
lower
risk
things
before
moving
to
the
higher
risk.
B
Things
get
wins
on
the
lower
risk
things.
First,
not
to
say
that
you
know
the
user
interfaces
that
customers
use
at
Banks
were
low,
are
low
importance,
they're
very
high
importance,
but
you
know
it's
it's
looking
at
the
various
risk
levels
on
those
things
and
choosing
with
that
in
perspective,
as
well
in
mind
as
well.
Awesome.
C
B
You
can't
do
fully
automated
change
management
with
everything
you
can
do
it
on
most
things,
but
you
know
the
you
know
if
there
are
human
lives
at
stake,
if
it's
health
care
or
if
it's
you
know
Transportation,
you
know
where
things
are
moving
at
high
speeds
and
you
may
not
be
able
to
do
this.
If
it's
a
highly
regulated
industry
and
you,
you
may
not
be
able
to
automate
as
much
as
you'd
like,
although
automation
can
really
help.
B
So
you
have
to
keep
those
things
in
mind,
the
faster
you
can
move
on
those
things
on
the
and
have
the
good
guard
rails
in
place,
the
better.
Sometimes
you
can't
move
as
quickly
as
you'd
like
in
some
of
those
situations,
but
you
can
still
automate
a
lot
of
it
as
well.
So
this
is
some
things
to
consider.
C
That's
an
on
top
of
that
I
think
you
can
still
do
benefit
a
lot
from
continuous
change
management
in
terms
of
you
might
need
to
readdress
what
production
is
for
you,
I
mean
production
in
a
highly
regulated.
Environment
is
probably
not
the
end
product
where
the
user
is
using
it,
but
maybe
a
staging
environment
or
a
a
laboratory
environment
that
you
deploy
to
where
you
have
continuous
checks
and
tests
that
run
so
that
you
can
still
continuously
elaborate
and
change
and
experiment
with
new
things.
C
But
you
you,
then,
have
to
follow
a
certain
separate
process,
maybe
to
to
finalize
and
to
regulate
and
to
get
the
audits
right
and
so
on
before
you
can
push
it
really
to
production.
On
the
other
hand,
if
you
look
at
Tesla,
Tesla
is
a
highly
regulated
industry.
They
build
cars
and
they
are
still
able
to
do
updates
every
now
and
then
over
the
air
to
your
car,
and
they
are
still
able
to
sort
of
create
a
better
user
experience
in
the
car
while
being
highly
regulated
and
while
having
to
to
adhere
to
these
regulations.
B
You
definitely
need
a
balance.
I
agree
with
you.
There
Sandra,
so
key
takeaways,
you're,
keeping
calm
and
carrying
on
you
know
in
terms
of
automated
change
management
is
predicting
software
delivery
performance.
It
can
be
predictable,
so
you
can
improve
on
it,
shifting
security
to
the
left,
to
prevent,
detect
and
prevent
vulnerabilities,
making
things
easy,
simple,
safe
and
secure
and
having
a
vision,
a
plan,
communicating
it
and
also,
especially
in
engineering.
It's
important
remember
to
celebrate
the
wins
as
well
anything
to
add
to
the
key
takeaways
to
Andrew.
C
B
A
A
So
please
respond
to
the
school,
and
let
us
know
how
you
think,
what
you
thought
about
it
and
without
further
Ado,
let's
jump
into
some
questions,
so
I'm,
looking
into
some
of
our
submitted
questions
and
one
of
the
questions
was
related
to
the
door
slide
that
you
presented
some
of
the
research
there
and
what
are
some
of
the
technical
practices
that
you
talked
about.
That
help
predict
better
software,
develop
delivery
performance
that
was
mentioned
in
that
door
slide.
B
I'll
give
my
thoughts
and
then
love
to
hear
your
thoughts
as
well
as
symmetry.
One
is
meantime
to
merge.
How
long
does
it
take
from
when
a
developer
is
ready?
Has
something
changed
and
is
ready
to
have
it
reviewed
then
merged
when
it's
actually
merged
and
also
meantime
to
deploy?
How
long
does
it
take
to
deploy?
B
B
I
think
those
are
two
key
metrics
and
the
other
is
the
merge
request
rate
per
team,
not
per
person,
but
they
per
team,
which
we
watch
closely,
because
that
merge
request
per
person
per
team,
not
that
all
teams
are
equal
and
you
don't
want
to
look
at
on
a
per
person
basis
you
want
to
see
is:
is
that
e?
Is
that
stable?
Is
it
going
up,
or
is
it
going
down
and
researching
why,
if
it
is
sometimes
it's
due
to
unexpected
reasons,
you
want
to
look
at.
B
Sometimes
it's
due
to
expected
reasons
like
it
might
be.
A
team
is
working
on
a
bunch
of
small
bug,
fixes
that
give
you
a
large
number
of
merge
requests.
It
might
be
that
a
team
is
doing
a
bunch
of
Spike
work
and
doesn't
have
that
many
merge
requests
because
they're
doing
some
investigation.
Sometimes
it's
due
to
things
where
somebody's
stuck
on
a
team
or
a
whole
team
is
stuck
on
something
and
looking
at
those
metrics
help
you
look
at.
B
Oh,
the
team
wasn't
complaining
but
they're
having
they're
they're
stuck
on
something
and
they
could
use
some
help.
So
it's
a
combination
of
those
are
three
of
the
metric
side.
Okay,
so
mean
time
to
merge,
mean
time
to
deploy
and
also
the
merge
request
rate
per
person
per
team,
but
again
not
looking
at
a
per
person
level
poking
it
at
a
per
group
level,
not
comparing
group
to
group
but
looking
at
the
change
any
particular
group
over
time.
C
Cool
yeah
yeah,
these
metrics
would
help
you
in,
in
the
lean
perspective,
to
discover
any
non-value,
adding
work,
or
maybe
it's
even
also
in
the
devil's
handbook.
So
you
want
to
discover
any
non-value,
adding
work
happening,
for
example,
interrupts
for
incidents
or
so
on,
and
you
want
to
try
to
avoid
that
as
much
as
possible.
C
Now
continuous
testing
and
automated
testing
helps
you
in
testing
a
lot
more
cases
than
if
you
would
do
it
manually
and
that
that's
really
incredible
how
that
changes.
All
the
tests
you've
done
before
in
the
past
and
you
created
in
the
past
can
be
tested
along
with
any
new
tests
adding
and
you
can
test
many
different
scenarios.
That
also
requires
requires
proper
test
data
management.
A
Yeah
the
second
question:
I'm,
actually
glad
that
you
mentioned
error
rate
sander
I,
think
relates
to
the
second
question
here.
So
I
think
one
of
the
questions
was:
how
do
the
teams
monitor
the
number
of
errors
and
Wayne?
Maybe
you
can
kind
of
share
what
what
gitlab
does
and
standard
what
you've
advised
customers
to
do
on.
B
We
look
at
two
well,
maybe
called
three
primary.
That's
in
terms
of
error
rates.
We
look
at
two
primary
things.
We
look
at
for
each
end.
Point
which
might
be
a
portion
of
the
web
app
might
be
the
back
end,
graphql
and
rest
API
endpoints
as
well
in
the
gitlab
product.
It
also
be
other
things
like
for
giddly.
B
We,
you
know,
we
look
at
error
rates
and
jobs
running
Etc,
so
we
look
at
how
often
the
per
thing
is
it
succeeding
versus
failing
and
then
we
also
look
at
the
response
time
and
we
consider
over
a
certain
number
of
seconds
failed
and
it
can
be
different
based
on
endpoint.
Like
you
know,
a
web
user
interface
might
have.
You
have
shorter
time
frames
that
you're
that
you,
you
want
to
make
sure
users
have
good
experience
here.
If
it's
a
back-end
service
that
users
are
not
directly
waiting
on.
B
It
could
be
that
there's
a
something
that's
being
listed
as
an
error.
It
really
isn't
an
error
because
it
isn't
an
error
or
because
there's
an
automated
retry
and
the
retry
tends
to
work
and
there's
not
a
user
waiting
on
it.
So
it's
okay
or
sometimes
that's
not
the
case,
and
it
isn't
okay
and
we'll
we'll
look
at
it.
We'll
also
do
something
called
exceptions
where
a
group
for
particular
endpoint
will
get
an
exception
for
the
error
budget,
and
we
we
look
at
those
pretty
intensely
to
make
sure
it's
appropriate.
B
That's
it
that's
80
percent
of
that's
an
80
success
rate,
but
that's
really
low
usage,
and
if
the
team
knows
that
they're
working
on
that,
like
a
re-architecture
of
that
component
or
it's
not
super
high
priority,
we'll
give
them
time
to
fix
that
or
put
in
a
you
know,
Mark
that
as
not
something
for
the
team
to
look
at
in
an
error
budget
Miss
versus
it.
So
it's
a
combination
of
those
things
related.
B
Is
we
also
look
at
bug
reports
from
users,
whether
it's
free
users,
you
know
open
source
users
of
gitlab,
whether
it's
paying
customers.
We
look
at
that
in
terms
of
the
issues
filed
and
also
how
often
those
issues
are
related
to
support
requests
from
our
paying
customers
and
also
how
often
we
get
incoming
requests
or
pings
about
it
from
the
the
sales
teams.
B
The
customer
support
teams
from
a
paying
customer
perspective,
not
from
a
support
ticket,
but
from
other
discussions
and
track
those
to
prioritize
the
overall,
the
overall
priorities,
as
we
move
it
into
the
the
backlog
for
a
team,
but
also
look
at
that
in
terms
of
the
quality
of
the
component
It's.
A
combination
of
those
things
that
we
look
at
in
terms
of
error
budgets
on
and
on
book,
writs.
A
Yeah
and
I'm,
looking
here
at
the
Q,
a
from
our
attendees
here,
I
think
this
kind
of
details.
What
that
last
response?
You
know
you
know,
what's
the
response
time
and
percentage
of
fails
and
success
is
actually
considered
a
success.
So
I
think
this
can
highly
depend
based
on
you
know
what
we
had
provided
in
the
in
the
Q
a
here,
but
maybe
you
can
verbalize.
You
know
what
we
do
here
at
GitHub,
how
we
Define
that
or
how
we
advise
our
customers
to
find
out
themselves.
Andrew
yeah.
B
B
If
a
web
application
I,
don't
actually
remember
what
the
actual
cutoffs
are,
but
it's
something
along
the
lines
up
if
it's
a
web
application-
and
it
takes
greater
than
two
seconds
to
respond,
users
get
very
frustrated
so
and
we
don't
look
at
average
because
average
can
average
things
out
too
much.
We
look
at
you
know:
percentiles,
like
90,
often
95th,
percentile,
response
time,
99th
percentile
response
time,
so
unit,
95th
being
well
I,
don't
need
to
explain.
Percentiles
are,
of
course
the
other
is
back-end
system.
B
Where
there's
not
a
user
waiting
on
it.
We
may
not
have
a
two
second
cut
off
on
percentile,
but
it
may
be
higher
because
or
it
could
be
lower,
but
it's
often
higher.
If
there's
not.
If
it's
a
something
going
on
in
the
background,
where
there's
not
a
user
waiting
on
it,
you
know
generating
something
that
takes
30
seconds
like
a
big
export
of
data,
that
the
user
is
not
directly
waiting
on.
B
Is
you
know
you
don't
want
to
put
a
you
know
web
app
criteria
on
something
that's
back
and
that
a
user
is
not
waiting
on?
We
also
have
real-time
systems
that
are
not
web
apps,
but
things
like
as
I
mentioned.
One
of
my
teams
working
on
is
code
suggestions,
because
that's
where,
as
users
type
AI
behind
the
scenes
make
suggestions
on
the
code,
two
seconds
is
way
too
long.
For
that
that's
a
real-time
response
time,
so
something
much
less
than
two
seconds
is
really
important
for
that.
B
C
It
there's
even
sort
of
an
a
standard
on
on
this
topic
on
on
response
time.
So
to
say,
it's
just
called
the
app
text,
the
application
performance
index,
which
gives
you
sort
of
a
percentage
between
zero
and
one,
but
you
can,
of
course,
translate
the
two
percentage
on
your
performance
or
on
your
response
times
for
the
sale,
but
you
can
also
Define
as
you
as
you
say,
when,
with
in
terms
of
quality
questions.
C
A
two
second
response
time
is
way
too
long,
so
you
would
adjust
it,
but
the
the
score
that
you
get
from
that
AB
deck
score
is
still
the
same,
so
you
could
use
that
standard
to
standardize
on
okay.
What
is
success?
What
is
a
failure,
while
in
the
in
the
back
end
change,
What
DOT
success
means
let's
say.
B
A
A
B
Do
we
send
a
percentage
of
the
production
load
to
Canary
a
canary
environment
which
is
separate
from
production
to
look
for
an
increase
in
error
rates
and
if
the
error
rates
go
up
significantly
in
Canary,
when
we
push
a
new
release,
we
give
it
pause
before
we
push
that
release
to
production,
because
we
want
to
protect
our
our
production
users
from
it.
Does
it
catch
everything?
No,
surely
not,
but
it
catches
a
lot.
It
catches
things
that
are
pervasive
across
the
application
based
on
its
usage.
It
doesn't
catch
the
exception
cases.
B
So,
for
example,
my
team
pushed
a
change
that
was
not
caught
in
Canary
or
any
of
the
integration
test.
It
only
impacted
0.5
percent
of
customers.
They
were
using
a
feature
that
only
0.5
customer
0.5
percent
of
customers
are
using.
However,
that's
a
lot
of
customers
and
it
really
broke
the
functionality
for
that
for
those
customers,
so
we
didn't
catch
it
in
Canary.
We
didn't
catch
it
in
integration
testing.
B
We
didn't
test
catch
it
in
unit
testing
and
when
that
happened
once
so,
we
caught
it
via
customer
reports
and
what
we
did
is
is
we
immediately
turned
that
new
feature
off
with
a
feature
flag
so
that
we
could
get
that
functionality
restored
for
those
customers
and
then
did
a
RCA
or
a
blameless
RCA
blameless
root
cause
analysis.
Not
only
did
we
fix
the
problem
and
rolled
out
new
code
to
fix
the
problem
we
looked
at.
How
did
we
not
catch
this
earlier
without
pointing
fingers
at
people
we
looked
at?
B
How
did
the
process
in
our
systems
fail
the
people
in
being
able
to
detect
us,
and
it
turns
out,
we
needed
some
additional
automated
test
cases
that
when
customer
has
this
feature
enabled
and
this
data
exists,
it
was
kind
of
a
combination
of
those.
We
didn't
have
an
automated
test
case
for
that
and
we
accidentally
developers
actually
accidentally
didn't
handle
that
correctly
because
they
weren't
aware
of
it
and
instead
of
them
and
then
so
we
added
those
automated
test
cases
and
then
so
we
could
avoid
it
in
the
future.
B
If
we
do
create
a
production
incident
and
it
we
have
a
criteria,
it's
documented
in
a
republic
handbook.
If
a
team
creates
a
production
incident
and
it's
a
of
a
certain
severity,
a
high
severity
will
also
choose
if
we
want
to
put
that
team
on
a
production
change,
lock
a
PCL
production
change
left,
which
means
that
that
team
is
not
going
to
push
out
any
new
code
to
production
until
they
get
the
time
to
really
complete.
B
That
root,
cause
analysis
and
take
a
step
back
to
invest
in
the
time
on
other
things
that
could
prevent
future
production
incidents,
which
is
it's
not
punitive.
It's
to
give
the
team
to
time
to
focus
on
those
things
we
don't
put
in
production
change
locks
very
often
it's
pretty
rare
on
a
per
team
basis,
and
it
does
feel
punitive
to
that
team.
The
first
time
until
they
see
what
it's
really
about
is
giving
them
the
time
to
improve
availability
and
performance
the
second
time
they
don't.
B
It
doesn't
feel
punitive
to
them,
because
we
do
that
blameless,
root,
cause
analysis
and
take
a
step
back
to
go,
resolve
the
issues
and
potential
future
ones.
To
give
them
the
time
to
go
after
that,
Tech
debt
or
other
things
they
really
want
to
work
on
which
helps
them
succeed
and
reduce
the
risk
in
the
future
key
thing
on
all
that
is
the
blameless
or
CA.
B
C
Yeah
I
totally
agree,
and
this
this
links
to
the
culture
of
psychological,
psychological
safety,
you've
got
Dora
mentions
again
as
a
predictable
factor
for
software
delivery,
performance
or
organizational
performance,
as
well
as
to
lean
where
lean
says.
Okay,
if
something
goes
wrong,
you
stop
the
process
and
see
if
you
can
fix
it.
So
this
is
this
links
to
both
of
those,
and
these
are
good
practices
and
neat
things.
A
No
I
think
I
think
we're
almost
that
time
now,
so
we'll
wrap
it
up
there,
but
really
appreciate
you,
Wayne
and
Sandra
for
taking
the
time
to
walk
us
through
those
best
practices.
Sharing
your
experiences
again
and
thank
you,
everyone
for
joining
us
today,
we'll
look
forward
to
sharing
the
the
recording
of
today's
webinar
as
well
as
the
the
deck,
and
you
know
thank
you
again
for
joining
us
have
a
great
day
thanks.
Everyone
thank.