►
From YouTube: GitOps Infrastructure Automation
Description
Modern application development runs at a blistering pace, but the process for creating and maintaining infrastructure you need to deliver applications doesn’t always keep up. GitOps is an operational framework that takes DevOps best practices used for application development such as version control, collaboration, compliance, and CI/CD, and applies them to infrastructure automation.
In this session you’ll learn why GitOps is so powerful along with insights into how to start implementing GitOps such as the tools and processes to uplevel your infrastructure management.
A
B
A
A
Let's
see
all
right,
so
checking
I
am
moving
on
the
presentation
that
we're
doing
today
is
get-ups
the
future
of
infrastructure.
Automation
thanks
for
hanging
in
here
with
us
today,
super
excited
about
being
able
to
present
this
I'm
going
to
take
a
little
bit
step
back
in
history
of
sort
of
how
the
landscape
of
software
development
has
changed
over
time.
I
think
it's
a
great
level
set
of
where
and
how
we
got
to
get
ops
and
the
definition
of
that
get
ups
and
let's
get
going
so
basically
the
way
that
we
worked.
A
If
you
look
at
the
bottom,
left-hand
side
is
waterfall
right,
so
software
development
started
there.
These
were
very
large
projects.
If
you
will,
they
were
very
long
and
duration.
They
also
were
we're
still
using
this
methodology
today.
Quite
honestly,
it's
very
sequential
has
very
long
cycles.
We
don't
do
a
lot
of
learning.
A
We
do
a
lot
of
doing
in
a
sequential
way
when
we're
doing
waterfall,
which
obviously
proposed
a
problem
in
the
software
development
lifecycle
and
the
software
development
lifecycle
in
and
of
itself
is
we
wanted
to
be
able
to
learn
our
lessons
a
lot
faster
and
be
able
to
deliver
things
faster
into
production,
so
we
moved
into
agile.
So
as
we're
moving
across
to
this
modernization,
we
moved
into
agile,
so
that
was
great
right,
so
agile
brought
us
that
smaller
amount
of
changes
in
faster
iteration
within
our
projects.
A
So
we
were
able
to
accomplish
a
lot
of
work.
We
were
able
to
incorporate
a
lot
of
those
best
practices
and
lessons
learned
much
earlier
in
the
cycle
with
agile.
But
what
happened
at
this
point
as
we
started
to
modernize,
everything
is
development
was
actually
working.
Much
faster
than
Ops
could
handle
right.
So,
at
the
end
of
the
day,
as
development
goes
through,
they
actually
start
to
iterate.
They
actually
start
to
deliver
faster
ops,
says
wait
a
minute
I
can't
handle
all
of
this
demand
to
get
this
into
production.
A
I
need
all
of
my
checks
to
make
sure
it's
secure,
make
sure
it's
on
your
compliance,
make
sure
all
of
these
things
are
in
place
before
it
goes
out
into
our
my
production
environment.
That
is
where
we
evolved
into
the
devops
world.
So,
as
you
all
know,
with
DevOps
DevOps
is
really
at
the
very
core
root
of
its
methodology.
A
It
basically
is
about
breaking
down
the
walls
between
dev
and
ops,
and
it
just
even
involves
into
breaking
down
the
walls
of
security,
so
we
can
incorporate
that
into
what
we're
doing
as
well
here,
but
at
the
end
of
the
day,
this
is
where
the
automation
piece
came
in.
The
handoffs
became
more
automated
within
these
dev
ops.
Best
practices,
as
well
as
the
collaboration
started
to
happen
so
devastated
to
understand
what
they
needed
to
tell
the
OP
side
of
the
house,
and
all
of
those
walls
began
to
break
down.
A
So
in
theory,
this
should
been
a
great
state.
Well
guess
what,
as
we
move
into
more
of
a
cloud
native
world
from
a
software
development
lifecycle
standpoint,
now
we're
looking
at
containerization
we're
looking
at
micro
services,
we're
looking
at
concepts
around
containers
like
kubernetes,
so
cloud
native
really
has
brought
an
additional
layer
of
complexity
where
you
know
these
environments
are
very
dynamic
in
nature.
So
how
do
we
handle
all
of
that?
A
So
my
roadmap
here,
oops
I'm,
sorry
I,
actually
I'm
gonna,
take
a
step
back
I'm
having
a
little
difficulty
on
the
the
presentation
piece
so
bear
with
me.
I'll
get
used
to
this.
So
let's
talk
about
what
I'm
going
to
talk
about
today,
I
always
like
to
kind
of
level
set.
So
you
all
know
exactly
what
I'm
gonna
be
talking
about,
so
we're
gonna
we're
gonna
dive
into
what
is
get
ups,
our
definition
of
that
what
it
means.
Also
we're
gonna,
look
at
why?
Why
is
it
important?
What
are
some
of
the
benefits?
A
Why
are
so
many
organizations
moving
toward
get-ups
and
then
how
do
you
do
get
ups
things
like?
How
do
you
arrange
a
team?
How
do
you
build
your
team?
What
does
that?
Look
like
also
we're
gonna
look
at
some
of
the
barriers
to
adoption,
some
of
those
challenges
to
adopting
get
outs.
So,
let's
start
in
the
easy
one.
A
So
essentially
it's
an
operational
framework
that
incorporates
the
DevOps
best
practices
used
for
application,
development
things
like
version
control,
collaboration,
compliance,
see,
ICD
automation
and
basically
taking
those
concepts
that
we
know
are
tried
and
true
from
a
DevOps
standpoint
and
applying
them
to
infrastructure
automation
so
really
bringing
together
the
dev
aside
with
the
operations
side.
So
for
all
intensive
purposes.
You
could
really
just
call
this
DevOps
for
infrastructure
I'm,
actually
going
to
take
you
now
into
an
equation
or
my
version
of
the
equation.
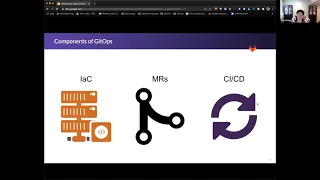
A
Here
of
what
get
UPS
is
kind
of
breaking
down
three
main
components
and
we'll
talk
through
each
of
these
components
here
as
well,
so
get
ups.
Equals
infrastructure.
Is
code
I'm
actually
going
to
challenge
you
on
that,
because
I
believe
that
that
is
more
than
just
infrastructure.
It
can
be
anything
that
operations
works
on,
so
it
can
be
things
like
policy
as
code.
It
can
be
things
like
configuration
is
code,
infrastructure
is
code,
so
I
will
actually
challenge
myself
and
you
to
think
about
how
this
will
look
from
a
get-ups
perspective.
A
Then
we
look
at
em
RS,
which
is
a
merge
request.
Merge
requests
plus
the
CI
CD
automation,
so
there
are
our
beautiful
components
of
get-ups.
Storing
infrastructure
is
code
in
your
get
repository
using
merge,
requests
or
m
RS
to
actually
be
that
change
agent
will
go
through
each
one
of
these
components
specifically
and
we'll
talk
about
exactly
what
they
do.
So
you
get
a
really
clear
understanding
of
what
that
means.
Last
but
not
least,
super
important
from
our
standpoint
is
our
the
automation
piece
for
the
reconciliation
loop.
A
This
ensures
that
our
infrastructure
is
always
up-to-date
at
any.
Given
time,
let's
go
into
infrastructure
as
code,
and
essentially
this
is
your
declarative
code
that
describes
the
desired
state
again.
Here's
where
I'm
gonna
challenge
you
to
think
outside
of
just
infrastructure,
you're
going
to
think
about
configuration,
you're,
gonna,
think
about
policy
as
code,
you
are
going
to
think
about
anything
essentially
that
the
operations
team
does.
Can
you
put
it
as
code?
Why
we'll
talk
about
that
in
a
little
bit
of
what
those
benefits
of
putting
it
in
as
code?
A
Basically,
infrastructures
code
is
stored
in
this
get
repository
and
it
has
version
control
version
control
is
extremely
powerful
when
you
incorporate
it
into
sort
of
this
infrastructure
as
code
concept
right,
so
it
helps
us
with
things
like
rollback,
etc.
So,
if
mistakes
happen,
something
happens
in
the
infrastructure.
Maybe
somebody
goes
out
there
and
manually
makes
a
change
in
the
infrastructure.
We
can
have
that
audit
trail
to
be
able
to
rollback
very
quickly.
So
our
mean
time
to
recovery
is
much
much
faster.
A
They
get
tooling,
as
a
user
interface
is
actually
super
exciting
and
should
be
very
exciting
for
the
operations
teams
right.
So
this
is
a
user
interface.
That
is
extremely
easy
to
use,
it's
tried
and
tested,
and
it's
something
that
they
can
actually
take
on
without
feeling
burdensome
by
you
know,
learning
got
another
solution
or
tool
em
ours,
so
merge
requests
as
the
agent
of
change
right.
So
essentially,
this
is
the
merging
of
one
branch
into
others.
So
you
have
your
get-ups
main
branch
becomes
your
main
production
branch.
A
If
you
will
and
then
whatever
is
in
that
environment
is
your
single
source
of
truth
and
then
you
have
various
branches.
That
then,
would
merge
into
that
main
branch.
Excuse
me
so
merge
requests
is
what
we
call
it
here
at
gate,
lab
other
solutions
will
call
it
as
a
pull
requests
PRS.
Basically,
those
are
your
gate
right.
So
this
has
to
happen.
The
M
are
the
PR
has
to
happen
before
any
change
gets
invoked
on
the
back
end.
A
M.
Ours
are
super
important
from
my
standpoint,
one
of
my
actual
favorite
things
within
the
gate,
lab
repository
and
the
gate
lab
solution
is
really
our
merge
request,
because
this
allows
coming
from
an
auditing
background.
This
allows
us
to
really
truly
understand
and
define
the
audit
trail
and
be
able
to
deliver
that
to
the
compliance
folks,
as
well
as
the
auditors,
in
a
very
easy
to
use.
So
what
happened?
When
did
it
happen?
Who
was
involved?
Who
approved
it
and
when
did
it
go?
Did
it
automatically
get
pushed?
How
did
all
of
these
things
happen?
A
It's
your
sort
of
single
source
of
truth
from
an
appliance
and
governance
standpoint,
so
many
people
can
contribute
to
the
merge
requests,
but
you
can
define
who's
actually
approving
that
merge
request
based
on
security
elements,
compliance
elements,
governance,
etc.
So
super
configuration
is
super
easy
to
do
within
merge
requests.
A
A
You
can
use
an
agent
that
lives
in,
for
instance,
a
kubernetes
cluster
right,
so
the
kubernetes
operator
it
goes
out,
it
pulls
the
information
back
and
it
allows
you
to
understand
kind
of
where
that
infrastructure
is
at
or
you
can
use
an
a
general
agent
list
push
base
where
your
CI
CD
is
always
running
or
even
running
on
a
regular
schedule
and
it's
checking
in
on
the
environment.
Basically
that
looks
for
the
defined
state
that
we
defined
up
front
and
it
syncs
things
as
we
need
them.
It's
a
super
super
powerful
from
an
automation.
A
A
So,
let's
talk
about
the
get-ups
flow.
What
does
this
look
like
from
a
flow
perspective?
So
let's
take
an
overarching
look
at
what
this
is
right,
so,
at
the
end
of
the
day,
this
looks
very
similar
and
should
look
very
similar
to
you
on
application
development.
It's
supposed
to
be
that
way.
Remember
what
we're
doing
here
is
we're
bringing
in
ops
and
we're
doing
infrastructure
as
code.
A
So
it's
going
to
look
like
a
software
development
lifecycle,
perhaps
so
the
creating
of
the
issue,
the
main
branch,
the
new
change
to
the
infrastructure
happens
at
that
point,
you
create
the
new
issue.
This
is
the
change.
This
is
why
the
change
is
going
to
happen
once
we
have
all
the
gates
and
all
the
approvals
to
move
forward.
We
then
create
the
merge
request.
Remember
the
merge
requests
actually
is
our
agent
of
change.
This
is
what
makes
that
change
happen
in
the
git
repository.
So
from
that
you
create
that
merge
request.
This
includes
the
collaboration.
A
It
includes
your
compliance
bits.
It
also
includes
the
audit
trail,
the
change
and
then
eventually
you
will
what
we
call
commit
your
changes
committing
your
changes
happens.
It
automatically
runs
your
CI
pipeline,
which
runs
all
those
checkpoints
that
you've
defined
and
make
sure
that
everything
is
copasetic.
So
then
we
have
essentially
a
review
app.
What
the
review
app
will
do
and
can
do,
for
you
is
take
a
look
at
what
that
future
state
will
look
like.
A
We
haven't
yet
pushed
this
into,
let's
say
our
production
environment,
yet
the
change
hasn't
gone,
but
we
can
take
a
look
at
that
review
app
and
see
the
change.
That's
going
to
happen.
It
gives
us
a
really
good
insight
into
what
that
will
look
like
and
then
at
that
point,
since
we
can
then
start
to
pull
in
the
rest
of
the
teams
and
the
cross-functional
teams
into
the
peer
review
and
discussions
around
this
particular
change.
Everybody
can
contribute,
a
small
portion
of
people
can
approve
based
on
how
you
define
that.
A
So
as
we
move
through
this,
we
then
merge
our
merge
requests.
The
issue
is
now
closed.
The
CCD
pipeline
runs
and
automatically
deploys,
and
then
you
begin
to
monitor
your
app
just
like
you
would
normally
so
that
is
our
get-ups
flow
again.
It
shouldn't
shouldn't
shock
you,
but
I
did
want
to
kind
of
take
you
through
this
step
by
step
flow
here.
So
a
lot
of
the
questions
that
we
get
when
we
present
topics
around
get-ups
is
what
is
the
difference
between
get-ups
in
infrastructure
is
code,
so
the
difference
is
infrastructure.
A
Is
code
may
or
may
not
be
version?
Controlled
infrastructure
is
code,
code
changes
may
or
may
not
go
through
the
right
of
the
defines
review
and
approval,
and
then
changes
in
infrastructure,
as
code
only
can
be
applied
in
many
ways
and
in
some
ways
it
may
apply
manually.
You
may
not
be
automated
all
very
fine
and
great
practices,
if
that
is
the
level
of
maturity
that
your
organization
is
in.
A
What
canasa
Lau's
you
to
do
is
again
get
that
code
into
the
get
repository,
have
the
ability
to
use
the
version,
control
and
leverage
the
version
control
and
then
enact
any
changes
document
those
changes
automatically
within
the
merge
request
and
heavier
infrastructure,
updated
eight
updates
be
pushed
automatically
into
the
infrastructure.
So
that's
the
main
differences
that
we
see
between
get-ups
and
infrastructure
as
code.
So
essentially
we
say
it's
infrastructures
coat
done
right.
A
That's
what
get
ops
is
so,
let's
talk
about
I'm,
going
to
kind
of
go
a
little
bit
faster
here
as
I'm
doing
a
tie
check
about
why
it's
important
with
get
up.
Why
get
ops
is
important.
Excuse
me.
So,
at
the
end
of
the
day,
I
talked
a
little
bit
about
some
benefits,
but
I'm
going
to
explicitly
talk
about
the
benefits
now
so
access
code,
again
I
told
you
I
was
going
to
challenge
you
on
this
that
it's
not
just
infrastructure.
It's,
it
can
be
a
lot
more
than
just
infrastructure
is
code.
A
So
what
happens
when
you
put
things
in
as
code,
whether
it's
policy
configuration
infrastructure,
you
automatically
almost
by
default,
get
a
self
documenting
concept
going
on,
because
it's
all
right
there
and
when
you
start
to
self
document
your
environments,
obviously
you'll
have
your
full-blown
documentation
outside
of
the
system.
But
when
you
start
to
document
the
process
in
the
how-to,
it
actually
can
then
be
shared
among
your
teams
very
very
easily.
They
can
look
back.
They
can
see
what
you
had
done
before
and
be
invited
in
to
participate
in
that
collaborative
motion.
A
Another
real,
clear
benefit
of
putting
everything
as
code
is
again
duplicating
in
environments,
becomes
a
very,
very
easy
task
at
that
point.
Next
version
control
benefits
with
rollback
enroll
for
capabilities.
So
if
you
have
an
issue,
you
can
sync
up
your
your
app
with
the
version
with
the
infrastructure,
change
and
rollback.
If
that's
what
you
need
to
do
basically
net-net.
What
happens
here
is
that
at
every
point
in
time
or
every
version
you
have
that
capability
to
roll
back
or
even
roll
forward.
What
does
this
do?
A
A
Next
automation,
benefits,
I,
think
I
kind
of
already
talked
a
lot
about
this,
so
I
won't
spend
a
ton
of
time
on
this.
Automation
is
huge.
If
your
organization's
ready
to
do
automation,
it
becomes
a
huge
benefit.
It
eliminates
the
human
risk
of
manually
pushing
something
that
perhaps
somebody
wasn't
supposed
to
do
didn't
understand
that
something
else
was
going
on
on
this
side
in
the
infrastructure
or
on
this
side
of
the
infrastructure.
So
you
can
actually
deploy
faster
and
more
often,
and
then
you
also
have
we.
A
We
basically
help
to
manage
that
configuration
drift
for
you.
That's
basically,
when
your
infrastructure
doesn't
match
your
set
of
configuration,
maybe
there's
a
failure,
a
Mis
configuration-
and
maybe
someone
did
a
manual
change.
So
this
actually
the
automation
runs.
It
will
update
it
to
that
known
state
all
throughout
this
not
to
be
excluded,
because
again,
I
believe
that
one
of
the
main
reasons
that
organizations
move
to
more
of
the
get-ups
is
really
around
security
and
compliance.
I
would
add
an
audit
trail
in
there.
Auditing
is
huge,
you
know
who
made
the
change.
A
Why
do
they
make
the
change
when,
when
they
come
in
to
audit
certain
things
within
the
system
within
the
infrastructure,
you
will
have
that
right
at
your
fingertips,
with
how
you're
doing
how
you're
doing
it,
who
did
it
and
when
they
did
it
also
from
a
granting
permission
standpoint.
Basically,
all
you
have
to
do
when
you
work
in
a
pure,
automated
fashion,
with
CIC,
as
you
grant
the
permissions
to
get
repository.
A
Many
contribute
to
this
process
from
a
security
and
a
client
standpoint,
but
only
a
certain
number
of
people
are
approving,
so
that
is
a
huge
piece
of
what
we're
doing
here
with
get-ups.
So
let's
move
on
to
how
to
do
get-ups,
so
I'm
gonna
go
through
this
really
very
quickly.
We
have
a
couple
more
slides
here
and
then
I
want
to
get
to
some
of
your
questions.
So
from
our
standpoint,
one
of
the
the
biggest
values
that
I
can
provide
to
you
is
to
show
you
kind
of
what
we're
seeing
from
a
gun.
A
So
it's
really
the
at
the
top,
where
you
have
the
slices
of
yellow.
That's
your
development
micro-services
scenes
that
are
comprised
of
dozen
SR
E's
and
everything
is
really
going
toward
that
micro
service,
where
they
are
being
attached
to
own
that
micro
service
from
beginning
to
end.
Now,
when
I
say
beginning
to
end,
that
does
not
necessarily
mean
that
they
need
to
own
the
platform
or
the
infrastructure
right.
So
what
we're
seeing
is
we're
seeing
the
rise
of
the
operations
platform
team
that
you
see
here
doesn't
necessarily
kubernetes
is
not
a
requirement
you
can.
A
You
can
store
infrastructure
as
code
and
do
merge
requests
as
the
change
agent.
The
platform
team
can
basically
provide
you
the
platform
as
a
service
with
or
without
kubernetes.
So,
really
that's
where
the
value
of
the
operations
platform
scheme
is
and
then
obviously
you
have
the
infrastructure
team
that
you
know
is
working
in
a
dynamic
environment,
spinning
up
and
down
cloud
environments
and/or
using
bare
metal.
A
So
let's
talk
a
little
bit
about
technologies,
because
this
is
another
piece:
is
how
do
you
do
it?
What
tools
do
you
use
so
I
would
say
I'm.
On
my
left
hand,
side
here
is
sort
of
my
laundry
list
of
the
technologies
that
I
believe
are
super
important
to
contributing
to
the
get-ups
solution.
Number
one.
A
It's
got
the
name
right
in
it
is
the
git
repository
I,
can't
not
to
say
that
and
then
the
next
layer
down
is
the
get
management
tools,
so
obviously
good,
lad,
github
and
bitbucket
kind
of
fit
into
that
management
solution.
It's
where
you
get
that
version
control
from
then
we
also
have
CI
or
continuous
integration
tools
out
there
that
are
necessary
to
implement
get
ops
as
well
as
continuous
delivery,
and
you
can
see
things
like
get
lab,
Jenkins,
spinnaker
circle
CI
and
we
worked
flux
in
those
tools.
A
We
also
are
looking
at
a
container
registry,
so
you
have
that
single
state
get
lab
and
docker
here
and
then
really
we're
sort
of
in
this
configuration
manager
and
infrastructure
provisioning.
We
allotted
configuration
manager
aside.
We
see
a
lot
of
ansible,
we
see
chef
and
puffit,
but
I
would
say
you
know,
sort
of
the
stand
out.
There
is
ansible
as
of
to
date,
infrastructure
provisioning.
We're
seeing
a
lot
of
terraform
more
and
more
we're
seeing
plumie
and
then
obviously
in
AWS
world,
we
see
the
cloud
formation
and
then
on
the
container
orchestration
side.
A
We've
actually
seen
both
sides
where
dev
has
taught
operations
to
be
more
deaths
in
trick
and
as
soon
as
that
light
bulb
goes
off
from
an
operation
standpoint
they're
like
wow.
This
is
really
amazing.
We
see
a
tremendous
amount
of
value,
but
conversely,
I've
also
seen
a
very
mature
operations
organization,
who
is
all
about
automation
that
have
actually
pulled
a
sort
of
manual.
Suffer
development,
lifecycle,
development
teams
into
the
world
of
automation.
A
So
it's
been
a
very
fun
ride
for
me
to
see
that,
but
I
would
say
net-net
you
need
to
evaluate
as
you
go
through
this
sort
of.
Where
is
your
operations
engineers
head?
Are
you
ready
to
take
on
to
my
second
bullet
a
sophisticated
level
of
deployment?
Automation
if
you're
not
start
with
automation
somewhere
else?
Maybe
it's
automated
testing?
Maybe
it's
implementing
C
ICD,
try,
automation
somewhere
else,
so
that
you
can
get
those
baby
steps.
A
So
folks
can
understand
whether
or
not
this
automation
is
something
they
can
take
on
and
then
also
that
one
of
the
biggest
sort
of,
although
I
said
I'm
going
to
challenge
you
around
everything,
it's
code
from
an
operational
standpoint.
Not
everything
belongs
this
code,
not
everything
belongs
and
they
get
rapid
repository
things
that
we've
seen
that
don't
really
belong
there,
don't
really
fit,
are
going
to
be
observability
tools,
feature
flags
and
incident
management,
so
nutnut.
What
we
talked
about
is
what
it
is.
Why
get
ups
and
how
to
do
get
ups?
A
We
talked
about
some
of
those
values.
We
talked
about
the
components
the
infrastructure
is
code,
the
merge
request
as
your
change
agent
and
the
CI
CD
as
your
reconciliation
loop.
We
talked
a
little
bit
about
how
to
set
up
your
teams,
what
tools
to
use
and
some
of
the
challenges
around
get-ups,
and
that
now
concludes
my
presentation.
I'm
going
to
bring
my
colleague,
William
Chia
on
online
right
now
to
help
me
out
with
some
of
the
questions
that
you
may
have.
A
C
B
All
right,
thanks,
first
of
all,
Tina
for
the
presentation
yeah,
like
you
said,
we
now
have
two
or
three
minutes
left
for
the
Q&A.
So
I
would
read
out
the
questions
that
I
got
so
far.
It's
it's
free
at
all,
so
let's
start
I
would
say,
and
then
you
two
can
decide
who
will
go
on
to
those.
The
first
question
would
be:
why
can
I
do
get
ups
with
terraform?
Isn't
that
enough.
A
C
Yeah,
that's
an
interesting
question:
I'm,
not
sure.
If
I
understand
all
the
perspective,
I
would
say
if
you,
if
you're
doing
get
ups
almost
assuredly,
you
are
using
terraform.
So
there
are
some
other
tools.
I
think
like
Tina
mentioned
gloomy
cloud
formation.
Other
types
of
templating
engines
I
have
a.
We
have
a
colleague
that
has
written
their
own
custom.
C
C
You
can
use
terraform,
and
so
then
the
question
would
be
if
I
mean,
if
I'm
using
terraform
is
that
de-facto
mean
I
am
doing
get
ops
and
and
I
would
say,
no
I
would
say
that
get-ups
has
it
has
a
few
kind
of
structures
around
it
that
that
are
part
of
it
that
a
part
of
the
practice
and
if
you
want
to
get
all
the
value,
it's
really
important
that
you
use
all
the
components
to
it.
So,
for
example,
as
I
know,
I've
chatted
with
Tina
a
lot
like
I
said
other
colleagues.
C
At
gitlab,
and
especially
with
with
gitlab
customers
and
users,
the
biggest
value
that
I
hear
most
often
like
I,
think
Tina
shared
a
really
long
list
of
here
like
fifteen
or
sixteen
different
values
you
can
get
out
of
get
ops,
but
the
one
that
I
hear
the
most
often
is
the
compliance
value.
The
idea
that
you
can
get
easy
auditing
out
of
who
made
which
change
at
what
time
and
you
have
an
easy
way
to
audit
your
changes
and
you
have
an
easy
way
to
adhere
to
any
compliance
policies.
C
You
have,
whether
they're
regulatory
or
whether
they're
internally
internal
compliance
or
whether
you
you
know
you
have
certain
certifications,
you're
going
for
when
you've
heard
your
compliance
policy,
and
you
need
to
adhere
to
that.
Usually
that
involves
only
having
certain
people
with
the
ability
to
access
certain
environments,
and
so
having
least
privileged
access
is
a
big
part
of
a
lot
of
compliance
policies.
So,
if
you're
using
terraform,
it's
an
amazing
tool,
but
that
doesn't
necessarily
mean
you're
getting
all
the
compliance
benefits.
So
when
you
are
doing
get
ops,
I
think
Gina.
C
What
you
talked
about
was
the
mr-s
that
change
agent.
This
is
the
idea
that
any
any
code
that
gets
eventually
gets
applied
to
production
or
any
application
code
that
gets
deployed
to
production
or
really
to
any
environment,
staging
or
dev
or
any
environments
that
you
have
the
way
that
that
code
get
there
is
by
being
merged
into
that
branch
and
then
an
autumn,
a
deployment
taking
place,
and
so
how
doing
that?
Mr,
as
that
change
agent,
this
is
where
you're
doing
code
review
we're
doing
peer
review.
C
This
is
where
approvals
can
happen,
so
not
just
the
actual
person
merging
it
and
enacting
that
change,
but
a
certain
bit
of
code
might
need
like
a
security
review
or
it
might
need
a
regional
review
in
order
to
adhere
to
your
compliance
policy.
So
there's
a
lot
there's
a
lot
to
it.
That's
more
than
just
doing
infrastructures
code
certainly
doing
the
pressure
code
is
a
component
of
it,
but
the
automation
is.
C
B
C
Have
everything
is
completely
mature?
Cd
everything
is
100%.
Automated,
there's
nothing
manual,
I've
containerized
everything.
Everything
is
in
a
very
sophisticated
kubernetes
cluster
and
I'm
doing
micro
services
and
I
have
service
mesh,
and
you
know
you
don't
need
to
have
everything
sophisticated
tomorrow.
You
can
start
out
with
start
defining
some
of
your
environments
and
infrastructure
as
code.
You
know
using
something
like
ansible
or
terraform,
these
kind
of
infrastructure.
C
As
code
tools
and
using
that
kind
of
merge
request,
you
can
start
doing
some
code
reviews
and
really
with
that
kind
of
simple
introduction,
you
can
do
that
even
on
just
one
or
two
environments,
you
don't
even
necessarily
do
it
on
production.
You
can
try
it
on
one
project
in
one.
In
may,
let's
say
your
staging
environment
of
your
dev
environment.
You
can
start
very,
very
small
and
then
incrementally
change.
C
That's
kind
of
what
I've
seen
folks,
whatever
whatever
an
organization
or
a
team,
is
adopting
any
type
of
new
technology,
whether
it's
agile
or
get-ups
or
or
any
kind
of
new
cultural
change,
because
there's
practice
that
comes
along
with
the
technology,
that's
kind
of
what
I've
seen
successful
I,
don't
know
Tina.
If
you've
got
some
thoughts
on
driving
change
in
your
organization,
yeah.
A
I
think
that,
from
a
cultural
standpoint
is
really
on,
think
about
and
evaluate
the
organization
from
a
the
standpoint
of,
is
your
ops
team
ready
to
think
more
like
a
developer
and
have
more
developer.
Centric
I'd
also
state
that
on
which
I
stated
during
the
presentation,
but
I
did
want
to
highlight,
don't
think
you
have
to
do
kubernetes
within
your
environment
in
order
to
get
the
get
ops
value.
I
will
leave
that
there
because
I
know
we're
a
little
over
time
and
I
apologize,
but
I
think
that
is
it
are
we
going
to
close.