►
From YouTube: IETF108-MLS-20200728-1300
Description
MLS meeting session at IETF108
2020/07/28 1300
https://datatracker.ietf.org/meeting/108/proceedings/
A
All
right
folks,
it's
nine
o'clock.
At
least
my
computer
tells
me
it
is
it's
top
of
the
hour.
So
let's
get
this
party
started.
This
is
the
mls
working
group.
Sorry,
I'm
just
switching
rooms
here,
real,
quick,
all
right.
So
it's
my
first
time
running
medeco
here
so
hopefully
you'll
bear
with
me.
Hopefully
I
won't
screw
anything
up
too
badly.
A
It
seems
like
some
people
have
done
some
sessions,
though,
and
there's
some
help
online.
So
in
case
I
do
anything
wrong.
You
can
correct
me
all
right,
so
this
session
is
actually
being
recorded.
I
don't
know
that
we
so
much
need
to
share
video,
I'm
going
to
run
most
of
the
slides.
If
you
need
audio,
you
can
request
and
I'll.
Let
you
in
there's
particulars.
A
A
A
Is
that
you
joe
agreeing
to
say
yeah,
that's
me
excellent!
Thank
you,
okay,
that
worked
out
better.
I
don't
we
don't
often
use
the
jabber,
but
hopefully
somebody's
watching
the
chat.
So
if
anybody
says
anything
in
the
chat
then
feel
free
to
kind
of
jump
in,
maybe
we
can
group
do
this
I'll
do
a
bit
of
a
status.
A
The
primary
motivation
of
this
this
session
is
going
to
be
maybe
a
little
different
than
some
of
the
other
sessions,
and
then
we
only
have
50
minutes
and
the
idea
was
to
go
through
the
any
outstanding
issues
and
pull
requests
on
the
protocol
draft
we'll
give
a
real,
quick
update
on
the
other
drafts.
So
we
have
three.
We
have
three
drafts
one's
expired.
The
federation
draft
has
expired.
A
That's
again
after
the
protocol
draft
has
kind
of
like
calmed
down
and
and
is,
is
more
in
a
more
final
state
and
that's
really
it
so
again.
Our
agenda's
kind
of
light
are
basically
our
plan
is
to
go
through
some
slides
that
richard
put
together
to
provide
some
history
about
what's
changed
and
stuff
and
then
jump
right
into
the
protocol.
A
B
B
So
I
wanted
to
provide
a
little
bit
of
background
for
what's
been
going
on
since
the
last
time
we
had
an
and
kind
of
ietf
crowd
oriented
meeting,
and
then
I've
got
a
kind
of
summary
of
the
the
way
forward
to
get
this
to
to
last
call
and
ultimately
to
rfc.
So
you
want
to
skip
forward
to
the
two
slides
on
the
avatars
there.
B
So
just
like
high
level
summaries.
Since
we
last
talked
about
this,
I
think
the
last
ietf
oriented
discussion-
I
don't
think
we
met
at
107,
but
I
kind
of
chose
draft
behind
this
kind
of
the
last
milestone
pulled
the
stats
out
of
github
we've
merged
32
pull
requests
and
had
eight
different
virtual
interims
to
to
discuss
them.
So
I
think
we've
had
a
pretty
good
cadence
of
you
know.
Getting
things
discussed
and
getting
emerged.
It
kind
of
is
a
good
compliment
to
the
mailing
list.
B
Discussion
always
pleased
to
see
new
contributors
showing
up
here
on
substantive
contributions
from
all
these
folks,
so
hopefully
we'll
get
some
more
new
contributions
from
from
folks.
So
please
view
this
as
a
an
encouragement.
You'll
get
some
recognition.
If
you
send
us
a
pr
next
slide,
please
these
are
the
32
pr's
that
have
been
merged.
There's
a
lot
of
stuff.
That's
in
here
that's
in
more
editorial,
more
minor
technical
fixes
to
things
like
struct
definitions
to
make
them
actually
parse.
B
I
think
one
of
the
things
I'll
emphasize
in
a
bit
is
that
the
overall
shape
of
the
protocol
has
not
really
changed
in
terms
of
you
know,
proposals
and
commits,
and
in
the
order
in
which
they
need
to
get
sent,
so
that
that's
kind
of
a
good
sign
of
stabilization
getting
toward
the
end
here
next
slide.
Please.
B
So
one
of
the
major
things
we've
changed
here
is
that
we've
we've
started
relying
more
on
this
hpke
construct.
So
when
we
started
up
the
hpk
draft
in
cfrg,
it
was
fairly
straightforward.
It
was
just
a
way
to
encrypt
to
a
public
key,
but
it
became
increasingly
clear
as
we
developed
that
draft
that
it
was
going
to
need
to
define
as
kind
of
a
next
layer
down
of
primitives.
B
So
there
are
interface
level
at
least
definitions
in
the
hpke
draft
of
what
a
kdf
looks
like
or
what
an
aead
primitive
looks
like
and
even
more
lately,
we've
imported
derived
key
pair
down
there,
because
that's
the
layer
at
which
you
know
the
chems
are
talking
about
or
that's
the
layer
kind
of
that
knows
about
the
details
of
accountants.
So
you
know
the
details
of
how
you
use
x
509
for
for
hpke.
B
The
only
thing
that's
not
provided
by
hpk
in
that
way
is
the
signature
algorithms,
which
we
are
leaning
on
tls
for
the
identifiers
and
and
definitions
there.
So
we
end
up
with
this
table
like
we
show
on
the
slide,
that's
the
table
in
the
in
the
iana
considerations
that
got
added
since
draft
of
nine,
which
just
lays
out
you
know
for
each
cipher
suite
the
left-hand
column
is
a
cipher
suite
it
identifies
which
of
the
chems
kdf's
aeads,
we're
using
with
hpke
and
the
signature
scheme
using
the
tls
identifiers.
B
I'm
happy
to
take
clarifying
questions
by
the
way
as
we
go
along
here
or
not
clarifying
questions,
because
I
think
we're
pretty
pretty
relaxed
on
time
here.
So
we
can
have
a
spontaneous
session
all
right.
So
the
other
two
changes
I'll
highlight
are
efficiency,
oriented
quoted
myself
here
back
when
we
were
discussing
doing
proposals
and
commits,
if
you
think,
back
to
mid
last
year
about
a
year
ago,
we
were
still
in
this
framework.
We
had
separate
ad
update,
remove
messages
and
in
late
2019
we
landed
this
vr.
B
Let's
switch
this
over
to
this
proposal,
commit
framework
which
is
simpler
in
a
lot
of
ways,
but
one
of
the
impacts
was
that
we
had
a
constant
time
ad
operation,
which
the
proposal
commit
framework
turned
into
one
that
was
login.
You
know
the
big
o
notation
is
caught.
Not
quite
accurate.
Here
was
log
n
in
the
good
case,
but
it
could
degrade
down
to
linear
so
as
as
I
think,
raphael,
and
I
in
particular
we're
looking
at
some
applications
here
and
looking
at
how
this
scales
up
to
some
large
groups.
B
This
seems
like
it
was
actually
an
issue.
This
is
scaling
out
to
log.
In
now,
when
we
were
considering
this,
the
the
proposal
commit
pr
and
noting
that
ads
got
less
performant
there.
The
discussion
there
noted
that
you
could,
in
principles
go
back
in
special
case,
commits
that
only
had
ads
and
get
their
performance
back
to
constant
time,
basically
by
not
ratcheting
the
group,
but
not
not
doing
an
asymmetric
ratchet
for
only
hash
ratcheting
forward,
not
which
is
how
we
got
the
the
performance
benefit.
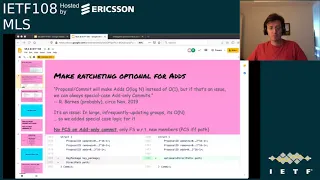
B
So
this
pr
just
took
that
that
principle
and
implemented
it.
So
we
said
that
in
the
so
syntactically
in
the
commit
the
path
which
kem's
new
entropy
to
the
group,
the
path
is
now
optional,
and
what
that
means
is
that
it's
optional,
when
you
have
ads
only
and
what
that
means
is
that
when
you
have
ads,
we
only
have
ads
in
a
commit.
B
You
ratchet
the
group
forward
just
by
hashing
the
epoch
secret
and
not
incorporating
any
new
entropy
and
then
for
anything
else.
If
you
have
updates
or
removes,
or
if
you
don't
have
any
any
proposals
at
all,
you
need
to
provide
a
path
and
can
some
new
entropy
to
the
group
and
that
entropy
gets
folded
into
the
key
schedule.
B
You
still
get
forward
security
with
regard
to
the
new
members
in
the
sense
that
they
can't
access
the
group's
communications
before
they
joined,
which
is
an
important
property,
but
you
don't
get
this
additional
property
that
you
got
as
an
effect
of
the
commit.
So
I
think
that's
something
we'll
need
to
be
clear
about
in
the
security
considerations
in
articulating
what
what
guarantees
the
protocol
provides,
but
I
think
the
impression
was
that
was
not
a
critical
property
to
lose
next
slide.
B
The
idea
here
is
that
when
you
add
someone
to
the
group
they
need
to
find
out
the
tree
so
that
they
can
generate
mls
messages
and
also
so
that
they
can
consume
messages.
So
in
this
in
the
commit
structure
we
have
right
now
in
order
to
process
that
commit
and
interpret
the
direct
path.
That's
there.
You
need
to
know
the
whole
structure
of
the
tree,
and
so
you
need
to
know
the
tree
before
you
can
process
a
commit
when
we
made
the
the
commit
welcome
changes.
B
B
So
if
you've
got
a
group
that
has
you
know
a
thousand
participants
you're
talking
about
hundreds
of
thousands,
hundreds
of
kilobytes
per
of
tree
data,
which
which
gets
tough
to
carry
around
because
in
the
in
the
you
know,
because
the
welcome
message
is
sent
by
a
member
of
the
group.
This
means
you
have
to
both
upload.
B
B
So
the
observation
here
is
that
the
tree
is,
you
know
big,
it's
heavy
to
upload
it
and,
if
you're
not
encrypting
your
proposals
and
commits
it's
possible
for
the
delivery
service
to
observe
those
and
keep
track
of
the
tree
itself,
or
you
know,
at
the
very
least
you
can
cache
copies
of
the
tree
that
they're
sent
to
it.
Some
other
way
right,
so
you
can
have
the
delivery
service
cache
that
so
you
don't
need
to
upload
it.
B
So
the
welcome
message
that
is
sent
by
a
member
of
the
group
can
just
have
a
commitment
to
the
tree.
The
tree
hash
on
the
right
side
of
this
diff
and
the
instead
of
uploading,
the
tree
from
the
member
in
the
group.
The
delivery
service
can
just
provide
that
alongside
the
welcome
the
the
main
trade-off
here.
Is
that
there's
a
bit
it
introduces
a
bit
of
ordering
dependency
in
terms
of
how
you
do
the
processing.
B
The
welcome
message
can't
be
authenticated
unless
you
have
the
tree,
because
you
draw
the
authentication
credentials
that
are
used
to
verify
the
the
key
and
the
credential
that
is
used
to
verify
the
welcome
message
from
the
tree
itself.
So
you
need
to
have
the
tree
in
hand
before
you
process
the
welcome
message,
but
the
feeling
so
far
is
that
that
was
a
tolerable
constraint
that
you
were,
even
if
you
were
getting
the
tree
from
not
the
same
source
as
the
welcome
if
it
was
getting
sent.
B
B
All
right,
so
I
wanted
to
talk
a
little
bit
about
the
the
timeline
for
getting
this
thing
finished,
since
it
seems
like
we're
kind
of
in
view
of
the
finish
line.
As
I
mentioned
above.
If
you
look
at
the
pr's,
we've
landed
in
the
last
few
months.
We've
kind
of
slowed
down
in
terms
of
major
changes
to
the
protocol.
B
If
you
think
back
a
year
or
more
like,
we
were
making
some
pretty
big
changes
with
proposals
and
commits
how
you
do
ads
and
removes,
and
all
that
has
been
stable,
for
I
don't
know
at
least
nine
months
or
so
six
or
nine
months
so
and
we've
been
making
efficiency
improvements.
We've
been,
you
know
tying.
You
know
making
some
updates
the
key
schedule,
but
the
that
major
thing
about
how
we,
you
know
the
overall
framework
for
how
we
do
changes,
updates
the
group
and
how
we
tie
things
together
is
pretty
stable.
B
B
So
I've
got
a
in
in
the
remainder
of
this
deck.
I've
got
a
list
of
kind
of
the
remaining
open
issues
we've
got,
which
broadly
bucket
into
some
protocol
changes
and
some
non-protocol
stuff,
which
is
how
we
explain
what
we're
doing
here
and
make
it
clear
and
make
it
obvious
what
the
properties
are.
So
we've
got
a
last
couple
of
buckets
of
issues
to
get
done,
but
it's
kind
of
almost
literally
a
handful.
I
think
we've
got
kind
of
five
ish
top
level
technical
protocol
changes
and
then
I
come.
B
B
Hopefully
we'll
nail
down
all
the
prose
issues,
and
that
will
be
a
good
point
to
kind
of
declare.
You
well
back.
I
think
draft.
Seven,
a
little
while
ago,
we
declared
a
an
analysis,
ready
draft
and
got
a
lot
of
good
findings
from
some
formal
verification.
Work
done
on
that,
and
I
think,
before
we
start
sending
this
off
for
ietf
last
call
and
all
that
last
process
churning.
B
It
would
be
good
to
do
another
one
of
those
analysis
redrafts
and
get
some
formal
verification
and
also
some
interop
testing
done.
I
think
the
main
question
here
is
how
long
we
want
to
leave
that
open
between
working
group
last
call
and
submitting
this
for
ietf
last
call
and
an
iesg
evaluation
sean.
Can
you
provides
you
remind
us
what
the
process
was
that
one
tls13
went
through
here,
because
I
think
they
did
some
analogy.
A
We
paused
we
paused,
basically
for
six
months
or
a
little
bit
longer,
depending
upon
what
kind
of
review
we
actually
got.
So
as
we
started
to
get
review,
we
kind
of
paused,
so
it
kind
of
depends.
I
mean
the
formal
verification
doesn't
just
happen
because
people
you
know
like
us,
they
they
do
it
because
they're
writing
papers
and
you
know
getting
stuff
out
of
it.
So
we
have
to
make
sure
we
line
up
somehow
with
something
to
be
able
to
get
them
to
get
stuff.
That's
published
and
looked
at
I'm
thinking.
B
A
A
B
I
want
to
run
through
what
I
believe
are
the
last
remaining
issues,
and
I've
cut
this
these
into
two
slides
and
tried
to
kind
of
bend
things
together
to
it's
a
consolidated
discussion
so
on
this
first
slide
here
are
the
the
protocol
issues
technical
issues,
things
that
are
going
to
require
protocol
changes.
The
second
slide
is
is
more
editorial
stuff,
although
that
may,
as
we
discussed
it,
may
turn
out
to
be,
have
some
critical
impacts,
something.
A
B
B
Protocol
prpr362,
which
is,
I
think,
the
more
the
smaller
change
in
aspects
of
336,
which
is
a
bigger
bucket
of
changes.
There
are
a
couple
of
gaps
between
where
the
how
the
key
schedule
works
and
how
it
should
work
302
is
in
in
360
the
pr
addresses
that
are
about
simplifying
the
encryption
of
sender.
Data
349
is
about.
B
Reducing
the
amount
of
metadata
that
is
leaked
by
the
the
encrypted
objects
we
send
around
and
then
there's
kind
of
a
bucket
of
changes
around
how
we
negotiate
how
we
do
psks
and
in
a
related
vein
session
resumption,
and
I
I
think,
the
last
bullet
there.
374
problems
should
probably
be
pulled
out
as
a
as
a
separate
top
level
item,
which
is
having
some
things
derived
off
the
key
schedule
that
people
can
use
to
authenticate
the
session.
B
You
know
independent
of
the
the
credentials
displayed
in
the
in
the
session
next
slide,
so
these
are
a
couple
of
new
slash.
They
think
slash
more
editorial
issues.
160
is
obviously
it's
a
low
number,
so
it's
been
kicking
around
for
a
while
benjamin
verduce
has
the
action
to
to
flush
that
out
a
little
bit.
B
B
B
So
this
is
this
covers
all
of
the
issues
that
are
currently
open
and
the
the
dot
dot
anything
else
at
the
bottom
is
my
explicit
invitation
for
folks
to
get
anything
else
filed.
If,
if
they
have
ideas,
they
have
issues
that
need
to
get
fixed
in
the
protocol,
because
we
are
closing
in
and
the
other
I'll
pause
briefly
here
in
case
folks
have
things
in
mind
that
they'd
like
to
bring
up
in
real
time
here.
B
C
B
So
I
think
if
you
go
to
yeah
slide
14
there
like
you,
got
okay
yeah,
so
in
in
the
current
key
schedule,
we
have
a
couple
of
disconnects
when
a
so
we
we
sort
of
added
this
psk
mechanism
without
thinking
about
it
quite
hard
enough.
We
shimmed
it
into
the
key
schedule
and
didn't
specify
how
you
negotiate
it
and
apparently
didn't
think
about
who
gets
it
when,
in
particular,
when
you
have
add
a
psk
in
an
epoch,
it's
added
a
point
in
the
key
schedule
before
the
secret.
B
B
Another
thing
that
the
raphael
had
observed
from
an
influence
and
implementation
point
of
view
as
challenging.
Is
that
the
the
group
context
object
is
shoved
in
in
a
bunch
of
specific
places,
it
would
be
slightly
nicer
for
an
implementation
point
of
view
to
just
you
know,
hash
that
in
kdf
that
into
one
point
in
the
key
schedule
and
then
have
that
kind
of
transitively
apply
for
the
things
that
are
derived
from
from
the
thing
that
includes
the
group
context.
So
the
the
I've
got
a
pr
here.
B
I
think
it's
362
that
that
does
kind
of
the
minimal
change
to
address
these
problems.
It
reorders
things
so
that
the
joiner
has
to
use
the
psk
to
get
the
fox
secret,
which
this
authenticates,
that
the
new
joiner
has
the
psk,
and
then
it
promotes
the
group
context
from
drive
secret
up
into
the
main
key
schedule,
so
in
in
pictorial
terms
on
the
next
slide.
B
B
On
the
right
hand,
side
you
send
the
joiner,
the
joiner
secret
so
that
they
have
to
add
the
psk
in
in
order
to
get
the
epoch
secret.
The
vertical
arrow
there
just
indicates
that
the
fox
secret,
now
kdf's
in
the
group
context,
would
be
happy
to
have
review.
I
feel
a
little
bit
weird
shoving.
The
group
context
there.
You
know
it
feels
right
because
on
the
one
hand
it
feels
right,
because
you
know
it
just
feels
like
it
should
go
into
the
epoch
secret,
because
it's
confirming
the
the
group
context.
B
B
B
C
B
B
B
B
That
nope,
I
think,
we're
moving
on
all
right.
So
I'm
going
to
consider
this
one
ready
to
go.
I
guess
john.
Does
that
make
sense
to
you
as
chair
can
sit,
go
ahead
and
merge
this
one
yeah
and
we
can
solicit
review
on
the
exact
scheme
and
fix
it
if
we
need
to
all
right
so
brandon.
I've
got
a
couple
slides
here
to
to
tee
this
up,
I'm
happy
to
introduce
the
topic
and
then
let
you
or
or
if
you'd
like
to.
B
B
The
nice
thing
about
that
is
that
it's
kind
of
zero
overhead.
You
kdf
some
you
sample
some
ciphertext
from
the
encrypted
content.
You
feed
it
into
a
kdf.
You
get
some
data
that
you
xor
with
the
thing
you're
masking,
so
you
it's
it's
nice
and
that
it's
it's
low
overhead,
it
doesn't
add
an
authentication
tag
or
an
explicit
nonce,
and
since
since
we
started
talking
about
this,
actually
there
was
some
academic
work
published.
That
did
some
good
security
analysis
and
proof.
This
has
the
properties
you'd
expect.
B
The
one
thing
it
doesn't
have
is
is
authentication,
so
the
authentication
properties
you
get
out
of
it
are
a
little
bit
more
subtle
than
using
an
aud
for
this,
and,
in
particular,
there's
a
bit
of
a
difference
between
what
quick
is
doing
with
this
mask
data
and
what
we
would
be
doing
so
the
data
we
would
be
masking
in
this
way
are
not
purely
about
nonce
formation.
It's
also
about
key
selection.
B
So
there
is
a
concern
that
you
know,
given
that
there's
the
authentication
you
get
here
is
or
that,
given
the
the
masking
constructs
available,
the
an
attacker
could
kind
of
change
some
bits
in
the
in
the
data
we
would
be
masking
and
thus
cause
folks
to
encrypt
with
a
an
incorrect
key,
which
seemed
seemed
like
a
downside.
So
I
think
we
there
is
pretty
good
consensus
to
to
not
do
the
quick
approach
directly
because
of
this
additional
key
selection
dimension
brendan
submitted
360,
which
is
an
interesting
second
attempt.
B
B
What
I'm
discussing
here
is
is
kind
of
my
spin
on
brendan's
pr,
so
I'm
taking,
I
admit,
I'm
taking
brendan's
idea
and
riffing
on
a
little
bit,
because
the
idea
of
the
pr
is
a
bit
different
from
this,
so
so
in
brendan's
proposal,
there's
a
second
aead
that
covers
the
mask
data
and
the
content
in
this
variants.
We
still
just
aad
the
the
sender,
data
and
use
the
ciphertext
for
the
notes
seems
simpler
to
me,
but
we'll
discuss
that
in
a
second
anyways
in
in
pictures
the
next
couple
slides.
B
This
is
how
mls
ciphertext
encryption
works.
Now
right
now,
you
first
encrypt
the
sender
data
using
explicit
nonce,
and
then
you
take
that
encrypted
center
data
and
it
becomes
aeid
into
the
content
encryption.
So
it's
kind
of
straightforward.
You
work
your
way
from
top
to
bottom
in
the
packet
next
slide.
B
So
for
this
scheme
this
you
know
sampling
the
non-set
of
the
content
to
work.
You
would
need
to
kind
of
reverse
things,
so
you
need
to.
You
would
need
to
encrypt
the
sender
the
content
first
before
you
encrypt
the
sender
data
and
I've
mislabeled,
the
the
second
row.
There
should
have
the
plain
text
center
and
generation,
so
you
need
to
encrypt
the
content
first
so
that
you
can
then
sample
a
nonce
out
of
it
that
you
use
to
encrypt
the
sender
data.
B
C
Here
so
I
just
wanted
to
say
that
basically,
the
issue
with
the
quick
approach
and
also
with
this
academic
paper
that
got
published
by
belair,
is
they
assumed
that
when
you
receive
a
cipher
text
from
the
network
that
you,
you
immediately
know
what
key
it's
encrypted
under.
So
if
you
get
a
ciphertext,
there's
no
question
about
what
key
it's
encrypted
under
and
you
try
to
decrypt
it
and
it
works
for
it
doesn't
with
mls.
Our
situation
is
slightly
different
because
we
encrypt
ciphertexts
with
different
keys
depending
on
who's
in
it.
C
C
The
thing
that's
not
shown
in
this
slide
is
the
the
encrypted
content
here
actually
has
the
authentication
tag
truncated
as
well,
so
it's
just
xored
with
like
a
stream
cipher
output,
but
that
is
fine,
because
the
ciphertext
gets
put
in
the
additional
authenticated
data
for
the
sender
data,
so
it
all
ends
up
being
authenticated
the
same
anyways.
It's
just
all
of
your
authenticated
data
is
sort
of
intuitively
against
this
little
encrypted
sender.
Data
piece.
B
C
And
that's
how
you
get
rid
of
both
the
explicit
nouns
and
the
unnecessary
auth
tags.
So
you
only
need
one
auth
tag
per
cipher
text
and
I
said
in
the
pr
that
I
think
that
might
be
like
an
efficiency
concern,
because
you
basically
have
to
do
two
passes
over
the
cipher
text
and
the
first
pass
is
to
authenticate
it
when
you're
decrypting,
the
singer
data
and
the
second
passes
to
actually
decrypt
it.
B
C
B
B
B
B
B
D
B
B
What
that
would
turn
into
is
really
a
a
requirement
that
this
or
a
limitation
that
this
protocol
could
only
be
used
with
misuse
resistance
aeads
like
siv.
I
don't
think
there's
any
correct
me
if
I'm
wrong
here,
but
I
don't
think
there's
any
nonce,
less
aeads,
there's
only
aeads
that
tolerate
nonseries.
B
E
My
interpretation
of
dan's
question
was
more
that
the
siv
mode
is
like
a
more
robust
construction
with
respect
to
various
sorts
of
flaws
or
errors
or
whatnot,
and
so
the
cost
of
that
robustness
is
that
you
have
to
do
a
second
pass.
But
if
we're
okay
doing
a
second
pass
in
general,
then
you
want
to
consider
having
the
more
robust
mechanism
just
in.
B
C
B
C
A
Looks
like
we
got
a
couple
of
options
that
we're
going
to
have
to
go
through
to
kind
of
get
a
sense
from
the
group,
whether
we
think
one
a
ssid.
The
other
does
not
make
sense
whether
we
we
can
do
brendan's
proposal
or
rich
proposal
that
there's
savings
or
benefits
from
doing
one
of
the
others.
Do
we
think
we
got
enough
information
to
be
able
to
take
that
to
the
list.
At
this
point,.
B
Yeah,
I
think
we've
got
enough
information
to
frame
a
good
question
to
the
list.
It
seems
to
me
that
one
of
these
two
options
should
be
viable,
whereby
I
mean
where
the
two
options
I
mean
with
the
extra
auth
tag
or
without-
and
I
think
the
main
question
is
just
whether
we
want
to
have
a
dependency
on
an
unauthenticated
encryption
algorithm,
as
well
as
an
ead
algorithm.
B
We
can
we
can
put
this
to
the
list,
but
yeah
brendan
thanks
for
putting
that
together.
That
was
a
a
useful,
interesting
take
on
this.
I
I
this
was
slight.
I
forgot
to
present,
but,
like
I
think
it's
either
this
or
nothing
something
like
this
or
or
we
should
just
give
up
on
simplifying
center
data.
Encryption
next
slide
just
a
flag,
another
couple
of
issues
buckets
of
issues
for
folks.
This
is
a
discussion.
That's
really
active
on
the
mailing
list.
Right
now,
I
think
we're
starting
to
converge.
B
I
hope
the
idea
here
is
we
we
expose
group
id
epoch
and
content
type
in
the
mls
ciphertext.
Now
that's
metadata
that
would
be
better
to
protect
content
type.
Is
the
easy
one
you
just
move
that
inside
of
the
encrypted
payload
and
then
the
discussion
we're
having
right
now
is
what
you
do
about
the
group
id
and
epoch,
whether
we
should
continue
to
expose
that
and
somehow
or
whether
it's
safe
to
to
do
something
like
either
encrypting
it
or
replacing
with
something
opaque.
B
So
please
tune
into
the
mailing
list
discussion
for
that.
In
the
last
bucket
of
things,
this
was
britta
hale
and
conrad.
Kovrak
posted
a
pr
336
that
I
was
a
bit
uncomfortable
with
it
just
because
it
addressed
a
bunch
of
different
use
cases
in
one
thing,
and
so
where
we
are
now
is
that
I've
been
trying
to
tease
these
apart
into
different
use
cases
and
kind
of
get
smaller,
more
digestible
chunks
that
we
could
land.
B
So
it
looks
like
what
we
need
to
to
get
to
where
they
they
wanted
to
go
is
to
you
know,
do
some
protocol
mechanics
to
add
extensions
to
the
commit
so
that
we
can
negotiate
psk's,
and
then
we
can
do
cool
things
like
have
resumption.
I've
put
quotes
here
by
analogy
to
tls
what
we
mean
is
authenticate
when
you're
joining
a
new
epoch
that
you
were
part
of
a
previous
epoch
of
the
group
to
have
some.
B
You
know
derived
psks
off
the
key
schedule
and
use
those
to
to
resume,
and
then
there's
some
stuff,
which
is
probably
separate
from
the
psk
stuff
about
brita,
has
done
some
work
on
how
to
authenticate
the
people
at
the
same
state
of
the
group,
which
is
kind
of
similar
to
some
of
the
short
authentication
string
stuff
that
was
done
with
zrtp
and
there's
a
zero
zero
draft
for
tls
for
how
you
use
it
for
pls
authentication.
But
the
idea
is,
you
derive
a
secret.
B
That
is
a
commitment
to
the
state
of
the
group,
and
then
you
you
can
compare
that
secret
to
verify
that
you've
got
the
state
of
the
group
same
state
somehow
out
of
banned.
So
this
is
still
in
the
kind
of
issue
refinements
and
we'll
move
to
the
pr
stage
pretty
soon.
But
this
is
kind
of
the
last
major
bucket
of
changes
I
see
so.
A
B
It
looked
like
you
were,
adding
three
secrets
to
the
key
schedule
all
at
once
and
now
it's
more
like
you
add
one,
and
then
you
add
two,
so
it's
it's
less
clear
that
we
need
a
multiple
combinator,
so
I'm
kind
of
inclined
to
put
the
nkdia
nprf
stuff
to
the
side.
For
the
moment
we
can
obviously
give
the
cfrg
some
time
to
to
give
feedback.
B
I
think
that
may
become
useful.
I
think
one
of
the
things
in
the
psk
domain
is
that
we're
going
to
wait
a
way
to
incorporate
multiple
psks
in
a
single
epoch,
so
yeah.
This
is
that's
where
I
was
going
jonathan,
that's
I
think
when
you
have
multiple
psks
or
maybe
some
additional
entropy
coming
in
in
an
epoch,
we're
going
to
want
a
way
to
combine
multiple
of
those.
So
that's
at
the
very
least,
a
future
pr
and
maybe
doable
as
an
extension.
A
Okay-
and
that
brings
us
to
the
end
of
our
session-
we
have
50
minutes
and
it's
9
50.
for
everyone
else.
The
plan,
I
think
what
we're
going
to
try
to
do
is
continue
with
the
interims,
we'll
probably
take
a
week
or
two
off,
but
then
we're
probably
going
to
go
right
back
to
one
every
other
week
to
try
to
see
if
we
can
bring
this
to
closure.