►
From YouTube: IETF110-PALS-20210312-1200
Description
PALS meeting session at IETF110
2021/03/12 1200
https://datatracker.ietf.org/meeting/110/proceedings/
A
A
This
session
is
actually
a
joint
session,
as
you
can
see
on
your
screen
with
pals
mpls
debt
net
and
spring,
and
the
four
co-chairs
for
this
session
of
record
are
myself
nick
layman
from
the
mpls
working
group,
lou
berger
from
debt,
networking
group
and
jim
goushard
from
the
spring
working
group.
Our
secretary
is
the
pals
secretary,
dave,
senecrow
who'll
be
taking
the
minutes
for
today
and
dave.
Thank
you
very
much
for
that
and
with
that
I'll
move
on
to
the
next
slide.
A
A
A
The
mpls
working
group
owns
the
basic
architecture
for
what
we're
going
to
be
talking
about.
However,
there
are
a
number
of
other
working
groups
that
make
the
the
take
advantage
of
the
technology
we'll
be
talking
about
today,
especially
pals
and
debt
net,
which
already
make
use
of
the
bottom
of
the
stack
and
we'll
be
hearing
the
proposals
for
general
delivery
functions
and
sr
mpls.
I
o
m.
A
A
So
the
agenda
for
today
is
I'm
starting
out.
I
have
the
first
five
minutes
this
introduction.
Next
we're
going
to
hear
stuart
bryant
talking
about
mpls
architectural
considerations.
He'll
have
20
minutes
to
do
so.
Next
comes
the
debt
net
data
plane
and
bellas
varga
will
be
presenting
that
then
we
have
generic
delivery
functions
from
jeffrey
mpls
in
c2,
oam
from
rakesh
and
multi-purpose
special
purpose
labels
for
forwarding
actions,
kore
and
that's
from
greedy.
A
A
Please
only
raise
your
hands
and
ask
questions
to
get
into
the
queue
if
you
have
a
a
question
to
for
just
to
on
on
a
particular
point
that
comes
up
in
the
on
the
slide,
but
we'd
like
to
keep
the
major
discussion
for
that
minute
period.
So
don't
actually
plan
to
start
a
major
discussion
on
any
of
the
points
until
we
come
to
the
discussion.
Time
is
just
basically
questions
for
clarification
and
in
terms
of
the
online
resources
for
this
meeting,
we
have
the
agenda.
A
We
have
etherpad,
please
feel
free
to
write
notes
in
etherpad,
just
as
you've
been
doing
for
the
other
working
groups.
All
week
we
have
the
jabber
room
and
I
would
like
to
take
advantage
of
my
co-chairs
to
watch
the
jabber
room,
as
I
present
the
slides,
and
make
sure
that
anything
that
comes
up
important,
that's
in
jabber,
gets
mentioned
on
the
record
and
send
an
email
to
tickets
at
meeting
ietf.org.
B
C
B
There's
also
some
propose
a
proposal
to
do
some
quite
interesting
things
actually
with
the
spl
bits
next
slide,
please
that
would
be
the
spare
sdl
bits.
So
pals
was
the.
Why
did
we?
Why
did
pals
sort
of
act
as
the
canary
in
the
coal
mine
pals,
was
the
first
working
group
to
deploy
metadata
below
the
bottom
of
stack,
that
is
to
say,
data
that
was
essential
to
process
in
order
to
process
the
payload
that
was
beyond
it?
That
was
the
pseudo
wire
control.
B
There
are
some
new
proposals,
though,
that
would
require
more
than
one
set
of
metadata
below
the
bottom
of
stack
and
pounds
as
pal
chairs.
We
thought
it
was
important
to
make
sure
that
the
addition
of
other
metadata
does
not
break
or
change
its
protocols
or
the
net
protocol,
or
if
it
does,
then
we
need
to
know
what
these
behavioral
changes
are.
What
the
cons,
consequences
and
mitigations
are,
in
other
words,
we're
not
saying
don't,
do
anything
but
go
into
this
new
world
with
open
eyes.
Next
slide.
Please.
B
So
none
of
the
proposed
changes
are
large
or
in
themselves
significant.
However,
in
combination,
they
result
in
complexity.
They
change
the
mpls
forwarding
model
and
indeed
the
mps
model.
40
model
has
changed
over
time
anyway,
but
they,
if
they're
not
done
right,
they
may
fundamentally
limit
future
mpls
development.
So
what
we've
done
is
record
all
the
interesting
parties
to
understand
the
needs
that
underpin
the
proposals,
to
understand
the
proposals
and
to
develop
a
way
forward.
B
B
So
it's
as
well
to
dwell
on
the
original
mpls
processing
model,
which
was
an
extremely
simple
and
elegant
approach
that
I've
always
admired
the
originators
for
designing.
So
you
take
an
mpls
label,
you
look
it
up,
you
take
the
top
label
and
you
look
it
up
in
the
the
fib
and
the
fib
points
you
to
some
forwarding
code
and
some
forwarding
parameters.
B
So
essentially
it's
a
table
driven
execution
function
and
new
forwarding
is
only
the
top
label,
that's
processed.
So
it's
very,
very
simple
and
lightweight
new
forwarding
code
can
be
added
simply
by
adding
the
code,
and
then
you
get
the
label
to
point
to
it.
So
it's
very
easy
to
introduce
a
new
function
into
the
design
and
the
mapping
between
the
label
and
the
forwarding
parameters
is
provided
by
the
control
plane.
B
B
The
original
special
purpose
labels
there
was
only
one,
and
I
think
it
could
only
be
at
the
bottom
of
stack
and
it
was
only
processed
at
disposition
I.e
when
all
the
other
previous
labels
had
been
popped,
and
there
were
only
a
tiny
number
of
them
used
in
practice.
Next
slide,
please
well.
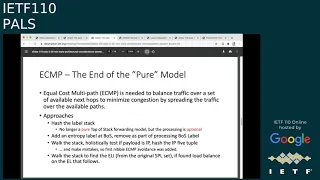
Ecmp
ecmp
was
really
the
end
of
the
pure
model.
B
Router
didn't
didn't
need
to
do
this,
so
you
could
hash
the
whole
stack
or
you
could
add
an
entry
label
at
the
bottom
of
stack,
which
was
moved
as
part
of
the
bottom
of
that
processing
label.
That's
what
sudo
wire
did
or
you
could
walk
the
stack
and
then
holistically
test.
If
the
payload
was
ip
and
hash
the
five
tuple,
that
was
done
quite
a
lot.
Unfortunately,
it
made
some
mistakes.
B
B
B
So
it's
the
right
thing
to
do.
It's
the
right
thing
to
do,
but
remember
it's
the
antithesis
of
the
original
model.
I
showed
you
in
one
of
the
early
slides
next
slide,
please
so
what's
the
impact
of
having
multiple
spls
in
the
stack
which
people
are
talking
about-
and
this
is
more
of
a
problem
for
the
the
two
label
version
the
espls
which
take
two
lses
to
do
it
for
a
start.
Stack
place
is
very
limited
in
some
edge.
B
Routers,
some
I
I
it's
been
quoted-
are
as
short
as
five
labels,
so
by
the
time
you've
done
some
fast
reroute,
the
delivery
label,
some
vpn
informational,
pseudo-wire
information
and
an
el
and
eli
there's
not
much
left
to
do.
This
is,
to
some
extent
been
changed
by
the
segment
routing
world,
but
nonetheless,
the
nut
the
size
of
the
label
stack
is
a
constant
worry.
B
Right
data
past
the
end
of
stack,
so
in
pseudowires
we
needed
some
additional
information
for
some
of
the
some
of
the
pseudo-wires.
We
were
processing,
and
so
what
we
did
was
we
put
a
control
word
at
the
end
of
the
stack,
and
this
was
disposed
when
the
bottom
stack
was
reached
because
the
pseudo-wire
label
said
exactly
what
the
pseudo-wide
type
was
and
hence
the
characteristics
about
the
control
word,
whether
it
was
there
and
how
long
it
was
how
to
interpret
it.
B
B
B
But
of
course,
if
you
had
a
pseudo
wire
with
a
control
word,
then
you've
got
to
do
that
at
the
same
time.
So
we're
now
in
the
start
of
the
combinatorial
issue.
Another
one
is
oam.
Well,
presumably,
actually,
if
you
wanted
to
do
iom,
you
might
want
to
do
fragmentation
on
a
pseudo
wire.
So
that's
three
items.
B
All
these
proposals
propose
to
add
additional
data
past
the
bottom
of
stack,
both
at
some
stages
proposed
to
indicate
this
by
the
presence
of
an
extended
special
purpose
label
both
proposed
to
run
on
packets,
carrying
user
data.
So
this
is
live
a
live
packet.
You
can't
just
pump
this
thing
off
to
the
rp
to
go
and
have
a
look
could
be
on
the
same
packet
and,
as
I
say,
other
proposals
are
now
in
the
works
next
slide.
Please
so
some
questions
should
we
support
the
use
of.
B
Special
purpose
labels
embedded
in
the
stack
to
trigger
per
hot
behavior
in
mpls,
or
should
we
require,
or
per
hot
behavior,
to
be
triggered
by
the
top
of
stack
label?
The
original
intent,
I
believe
in
mpls,
was
that
the
top
label
would
trigger
all
of
the
per-hop
behavior
and
what
and
what
you
would
do
is
to
create
a
new
effect,
but
we've
shown
a
great
reluctance
to
create
additional
effects,
particularly
running
across
the
the
p
routers.
B
So
there's
a
there's
a
few
things
that
that
I
did
around
sfl's
where
originally
I
was
thinking
that
we
would
use
a
special
purpose
label
to
trigger
this
behavior,
and
I
was
persuaded
by
george
swallow
and
and
a
few
others
that
actually
that's
not
the
mpls
way
to
do
it.
The
mpls
way
is
to
use
a
a
lay,
a
real
label
and
a
regular
label
and
signal
is
in
the
control
plane.
B
B
So
this
is
an
incomplete
list
of
the
various
proposals.
I
I
quickly
went
through
things
yesterday
to
lowe's
request
to
see
if
I
could
find
them
all.
I
don't
think
I
have
found
them
all,
but
this
is
a
place
to
start
and
I
am
sure
there
will
be
others.
I
certainly
am
minded
to
write
a
couple
myself,
so
you
know
the
the
the
we're
already
on
the
the
road
to
looking
at
these
things
and
we
need
to
decide
what
we
do
before
we
box
ourselves
into
a
corner.
D
B
The
majority
of
the
of
the
stack
others
may
take
a
different
view,
and
I'm
interested
in
that
one
of
the
things
that
people
should
remember
is
that
that
forwarding
buffer,
where
the
network
processor
operates
on,
is
incredibly
expensive
memory,
and
so
we
need
to
use
it
with
care.
That's
why
a
lot
of
these
routers
can't
or
forwarding
engines
can't
look
that
far
into
the
packet.
Does
that
address
your
question
bruno.
A
D
E
So
a
couple
of
points:
thank
you
for
this
presentation.
Andy
stewart.
This
is
laid
out
a
lot
of
the
questions
that
we
should
be
looking
at
some
of
them.
We
should
have
been
looking
at
for
a
while,
but
you
know
it
is
what
it
is
that
it's
doing
now,
then
not
to
do
it.
So
if
you
go
back
to
the
the
simple
forwarding
model
of
mpls
before.
E
E
E
E
Well,
so
the
point
is
that
when
you
get
beyond
the
labels
at
the
top
of
stack
which,
for
you
know
whatever
reason,
people
have
been
commenting,
you're
not
treating
this
truly
as
a
stack.
If
you're
looking
at
anything
beyond
the
proper
stack,
you
know,
and
of
course,
if
you,
if
you
pop
it,
then
you're
allowed
to
look
at
the
next
one,
but
while
keeping
it
there
you're
doing
stuff
with
it
beyond
the
tuple
stack.
E
E
So
so
the
way
we
process
the
top
of
stack
and
the
way
we
process
things
below
the
top
of
that
have
changed.
So
I
think
those
the
facts
and
that's
why
I
want
to
say
that
the
proper
stack
is
not
just
sent
to
your
saber.
Otherwise
you
could
say
everything
you
do
below
the
top
of
the
cycle,
same
as
what
you
did
on
the
top
of
the
stack.
B
No,
in
fact
it's
quite
interesting.
Isn't
it
because
you
also
in
some
implementations
they
automatically
do
ttl
decrements,
so
you
never.
You
could
never
be
quite
sure
what
the
ttl
actually
is
other
than
that
it's
not
hit
the
safety
right,
safety
rails,
so
yeah,
and-
and
so
yes,
you're
the
in
the
original
model.
You
weren't
supposed
to
look
below
the
top
of
stack
and
a
lot
of
the
you
know
the
as
we
started
the
ecmp.
F
B
G
Hello,
my
name
is
balaj
fargo
and
I
will
present
the
deterministic
networking
mpls
data
plane.
So
in
that
net
we
have
defined
two
data
planes
and
ip
and
the
amperage
data
plane.
Now
we
will
focus
on
the
mpls
data
plane
and
this
document
was
recently
published
as
an
rfc,
let's
start
with
some
basics,
so
so
that
net
discussion
focus
on
solution
for
networks
that
are
under
a
single
administrative
control
or
within
a
close
group
of
administrative
controls.
So
any
solution
for
large
group
of
domains
such
as
the
internet
are
out
of
scope.
G
What
we
intend
to
achieve
is
that
net
to
to
provide
deterministic
data
path,
and-
and
that
means
that
we
can
ensure
bounds
on
latency
loss
packet,
delay,
variation
and
high
reliability.
So
that
is
the
ultimate
goal,
and
in
order
to
achieve
these
targets,
we
have
defined
some
new
deathnet
mpls
data
plane
functionalities.
G
G
One
is
a
flow
id
to
being
able
to
identify
which
packets
belong
to
a
to
which
that
net
flow
and
the
sequence
number.
Then
we
have
to
make
some
some
special
functionality.
It
will
come
very
soon.
So
when
we
are
looking
to
service
sub-layer
specific
function,
they
need
both
of
this
information,
both
the
flow
id
and
the
sequence
number
for
the
forwarding
sub-layer
related
functions.
What
you
need
is
the
flow
id.
G
G
H
G
G
To
the
other
end
of
the
of
the
network
where
elimination,
node
is
is
placed
and
that
elimination
node
will
check
which
packet
is
received
and
of
course
it
will
take
only
one
example
from
the
packet
flows,
for
example,
with
the
segments
number
14
and
then
forwarded
to
the
egress
point,
so
practically
the
price
we
are
still
staying
that
that
slide.
Thank
you.
So
the
price
you
have
to
pay
for
the
extreme
reliability
is
bandwidth
because
you
are
using
this
joint
pass
and
there
is
no
primary
and
backup
paths.
G
So,
with
such
a
replication
and
elimination
function,
you
may
come
with
some
out
of
order
delivery.
So
this
is
why
the
third
function
the
ordering
function
was,
was
defined
in
the
bottom.
There
is
a
a
very
simple
network
figure
which
is
showing
how
these
functions
are
used
in
a
network
that
is
providing
that
net
service.
G
G
So
let's
look
to
the
to
the
encapsulation
on
the
on
the
next
slide,
how
it
is
look
like,
so
if
we
have
to
forward
a
packet
that
require
net-net
service,
we
take
that
in
a
payload
packet,
add
a.net
controller.
This
is
containing
the
sequencing
information
for
the
packet
and,
as
you
are
also
highlighting,
this
is
also
where
some
oem
indicator
can
be
placed.
G
Then
there
will
be
immediately
ahead
of
that
that
net
control
word
a
service
label,
that
is,
the
label
used
to
identify
the
net
flow
at
the
peer
that
net
node
and
then
ahead
of
the
service
label.
There
can
be
zero
or
more
mpls
forwarding
labors,
which
are
used
to
direct
the
packet
along
the
labor
switch
path
to
the
next
peer
node
and,
of
course,
we
will
have
the
necessary
data
link
and
physical
stuff.
G
It
is
important
to
highlight
the
death
net
control
word,
for
that
net
flows
is
a
must,
so
it
is
always
present
and
that
that
net
control
word
conforms
to
the
generic
shadow
via
mpls
control.
Word
definition:
we
have
28
bit
to
to
place
sequence
numbers,
so
different
sizes
of
sequence,
numbers
were
defined,
16,
bits
and
28
bits,
and
the
sequence
number
size
is
that
net
flow
specific,
so
at
each
hope
along
the
the
path.
Each
devnet
hope,
where
you
intend
to
use
the
net
control
version.
G
The
sequence
number
information
you
have
to
either
by
the
control,
airplane
or
locally
configured
that
size
and
one
important
stuff,
is
that
the
sequence
number
differs
somewhat
from
other
sequence.
Number
defined
for
pseudo
values
is
that
zero
is
an
ordinary
sequence
number,
so
it
does
not
have
any
special
meaning.
In
our
case,
that's
it
on
the
mpls
data
plane.
I
Very
quick
overview:
we
notice
that
some
ip
functions
can
actually
be
viewed
as
independent
of
ip,
for
example,
fragmentation
and
reassembly
aesp,
and
recently
we
noticed
that
this
topic
of
instituto
oem
and
in
some
other
functions
that
I
noticed
in
this
week's
ietf
sessions.
We
will
provide
more
background
in
our
draft
updates.
I
So
with
that
observation,
what
if
we
can
extract
those
functions
and
apply
it
to
any
layer,
for
example,
it
can
be
done
at
ip
layer,
npos
layer,
beer
layer
or
either
or
even
ethernet
layer
so,
and
it
can
be
a
down
for
many
functions,
so
this
has
two
axes.
One
is
that
at
any
layer,
the
second
one
is
that
any
really
generic
function.
That
is
not
depend
on
any
particular
layer.
I
I
I
When
it
is
used
for
mpos,
then
it
provides
a
way
to
prevent
from
being
mistaken
as
ip
packet
and
headerness
that's
standard,
and
then
they
we
have
both
this
header
and
next
header.
This
header
will
have
its
own
number
space.
That
gives
us
different
functions.
Generic
different
function,
generic
functions
and
the
next
header
comes
from
the
ip
protocol
number
space.
I
I
I
This
is
an
example
of
the
generic
fragmentation
header.
We
we
don't
need
to
focus
on
this
now,
but
I
want
to
point
out
that
one
thing
actually
stuart
and
noticed
that
a
by-product
of
this
generic
delivery
function.
Header
is
that
in
case
mpos
now
you
can
use
it
to
indicate
the
payload
type
that
comes
after
the
mpos
labor
stack.
That
is
not
the
original
intention
of
this
proposal,
but
it's
a
nice
by-product
of
it
next
time.
Please.
I
I
I
I
I
I
My
understanding
is
that
gach
was
designed
for
mqs
control,
channel
purpose,
gal
label
and
gach.
They
are
not
used
for
user
traffic.
The
gsh
structure
does
not
have
the
next
concept
either.
Now
gdf
is
for
generic
delivery
functions
over
different
layers.
Supporting
different
stackable
functions.
Af
is
applicable
to
both
user
and
control
traffic.
I
I
I
I
G
I
J
I
J
A
C
C
C
C
This
we
can
skip
this
slide
there.
We
can
go
to
the
next
one,
so
it
is
used
along
with
indicator
label
at
the
bottom
of
the
stack
indicator.
Label
tells
the
node
that
there
is
iom
data
fields.
After
the
end
of
stack.
We
we
have
defined
two
separate
labels,
one
for
edge
to
edge
case
and
one
for
hop
pi
up
case
as
iom
processing
can
be
heavy.
C
C
C
C
C
So
this
is
an
example
for
srm
pls
case.
There
was
a
review
comment
on.
How
does
it
work
with
path
segment,
so
it
shows
an
example
where
path
segment
would
go
just
before
the
iom
indicator
label.
You
will
see
at
basically
consistency
in
all
of
the
formats
where
iom
indicator
label
is
used
in
case
of
s28
at
the
bottom
of
the
stack
with
us1
and
next
slide
please.
C
So
this
is
a
second
option
of
by
hop
case,
hop
by
hop
case
again.
There
are
three
different
methods.
This
is
one
example
where
the
the
indicator
label
is
signaled
by
the
mid
node.
In
this
case
it
would
be
the
top
label
or
the
mid
node
where
packet
is
received,
and
that
indicates
not
only
the
forwarding
instruction,
but
also
that
there
is
iom
processing
required.
C
C
There
is
global
indicator
label
allocated
by
controller
as
well
and
again
carried
at
the
bottom
label
stack,
and
the
third
option
here
is
slightly
different
than
the
h2h
case,
where
it's
advertised
by
the
the
intermediate
nodes
or
decap
nodes,
wire,
signaling
or
flooding,
and
it's
carried
at
the
top
of
the
label
stack.
So
in
number
one.
You
have
two
labels
for
number.
Two
and
three
case:
you
only
have
one
extra
label
next
slide
piece.
C
Again,
the
procedure
on
end
cap
and
decap
nodes
are
the
same,
but
intermediate
node
now
finds
that
there
is
a
indicator
label,
so
it
will.
It
will
invoke
the
iom,
functionality,
processing,
module
and
say
there
is
iom,
something
has
to
be
done
for
iom
there.
Otherwise,
it's
just
optimized
and
packages
gets
forwarded
and
next
slide.
Please.
C
So
idea
is
that
iom
can
continue
to
be
at
the
bottom
of
the
stack.
We
know
a
node
always
knows
where
it
is.
Iom
processing
is
heavy.
You
have
timestamp,
you
have
node
id,
you
have
interface
id
many
things
to
be
done
in
iom,
so
it's
important
that
is,
you
can
easily
locate
where
it
is,
especially
on
the
intermediate
nodes
and
processed
it
quickly
and
forward
in
the
first
part.
So
this
is
again.
C
C
So
this
is
one
example
where
we
have
another
gsh,
let's
in
this
case
it's
an
edge
to
edge
case
packet
comes
in
with
sudoku
fire
label.
It's
not
end
of
the
stack,
looks
at
the
next
label
end
of
indicator
label.
It's
the
end
of
the
stack.
This
is
a
decap
node,
so
finds
the
iom
processes.
Iom
removes
the
iom,
indicator
label
and
metadata
and
continues
the
pseudo-wire
label
processing
along
with
his
control
work.
C
C
So
generic
delivery
function
again
the
way
I
understand
it's
for
ingress
and
egress
node.
There
is
no
hop
by
hop
processing,
so
our
packet
is
received
with
gda
gds
label
and
iom
indicator
label.
The
idea
is
the
same:
you
detect
iom
indicator
label
at
the
bottom
of
the
stack
process,
iom
remove
it
from
the
stack.
You
continue
with
your
gth
processing,
just
like
if
you
were
pursued
a
wire
label
or
any
other
use
cases
and
next
slide.
Please.
C
That
there
was
question
this
is
not
in
the
draft
again.
This
is
there
as
an
example
for
to
trigger
the
discussion.
You
have
multiple
labels
to
the
wireless
label.
Gta's
label
indicator
label.
They
go
in
in
a
certain
order.
You
will
find
indicator
label
at
the
bottom.
You
process
it
remove
it
go
to
the
gdh
you
process
gdh,
and
then
this
would
a
wire
label.
So
there
is
a
certain
order.
It
can
be
implemented
this
way
and,
as
you
can
see,
there
is
only
one
end
of
stack
or
label.
C
This
is
again
that
net,
so
the
idea
would
be
very
similar,
again
indicator
label
carried
at
the
bottom
of
the
stack
with
us1
you
process,
and
then
you
off
you
go
continue
with
your
normal
that
net
processing
again,
this
is
not
in
the
draft.
This
is
this
here
for
the
sake
of
discussing
in
today's
meeting
next
slide,
please
so
that
was
my
last
slide
and
welcome
your
discussions
and
their
comments.
K
J
As
balos
explained,
the
sequence
number
is
used
by
or
may
be
used
by,
that
net
intermediate
nodes
for
packet,
replication
and
duplicate
elimination
function,
so
putting
the
sequence
number
at
a
variable
length,
that's
a
definitely
very
expensive
for
that
net,
where
we're
trying
to
minimize
extra
processing
and
deliver
low
packet
to
us
and
guaranteed
latency
bound
latency,
so
that
I
think
it's
really
problematic,
because
iom
size
is
variable
of
their
heather
and
tov
prior
to
their
sequence.
Number.
Okay,
thank
you.
B
So
we're
going
to
have
to
be
scrupulously
careful
with
the
ordering
and
the
the
order
of
and
the
position
of
information
after
the
stack
and
also
we're
gonna
have
to
be
scrupulously
careful
with
the
ordering
of
labels.
So
I
I
would
expect
to
process
the
f
label
and
then
the
s
label.
Once
I've
got
the
s
label,
I
would
expect
to
be
able
to
easily
find
the
the
control
word
and
that's
not
obvious
how
that
works,
particularly
in
the
picture
we've
got
here.
I
B
Can
I
pick
up
on
that,
so
the
the
channel
defines
what
comes
after
the
channel.
So
if
you
wanted
to
create
a
new
channel
type
that
had
the
property
that
there
was
certain
data
after
it
that
you
could,
you
could
do
so:
there's
no
intrinsic
channel
type
information
but
or
next
header
information,
etc.
But
if
you
understand
the
gach
type,
then
you
can
understand
whatever
block
of
data
you
want
to
put
after
it.
B
If
you
wanted
to,
you
could
have
or
you
could,
we
could
allocate
a
new
gach
type
that
was
iom,
followed
by
pseudo-wire
pseudowire
information.
If
that
is
what
you
wanted
to
do,
or
was
iom
followed
by
gach,
we
could
have
we've
got
64
000
of
these
things.
We
do
have
to
worry
that
that
that's
going
to
be
a
table,
look
up
and
possibly
quite
expensive
to
do
if
we
have
too
many
of
them,
but
the
the
the
the
gach
type
defines
everything
that
follows.
A
Okay,
if
I
can
interrupt
this
is
this
is
really
going
beyond
clarification,
so
I
would
like
to
really
move
on
to
kuriti
and
if,
if
I
can
just
give
one
note
to
karidi
when
you
spoke
earlier,
your
microphone
was
low.
So
if
you
could
speak
closer
to
your
mic,
that'd
be
great.
Thank
you.
I
switched
mike's.
Is
this
better?
E
Okay,
thanks,
okay,
so,
let's
get
to,
I
think
the
slide
three
okay,
yeah
thanks!
So
I'm
going
to
you
know
I
want
to
thank
you
all
for
starting
this
discussion
and
and
and
organizing
this
session,
because
I
think
it's
important.
I
I
think
to
steward's
point.
You
know
I'm
going
to
try
to
follow
his
act
and
you
know
sort
of
you
know.
He
said
here's
where
the
history
is
and
here's
where
we
are
today.
E
I
want
to
focus
on
here's
where
we
are
today
and
it's
it's
almost
like
a
bookend
to
his
thing.
So
maybe,
if
you
think
of
it
this
way
he
was
good
cop
and
I'm
gonna
be
bad
cop.
I
might
be
terrible
cop.
I
might
be
not
so
terrible
cop
I'll
leave
you
guys
to
decide
that
when,
when
we
started
as
stuart
said,
you
looked
at
the
top
label
in
the
stack
and
you
looked
at
the
label
value.
E
So
I'm
going
to
interpret
what
comes
afterwards
as
an
ip
header
or
whatever.
So
anyway,
that
was
back
in
the
old
days
and
then,
as
he
said,
you
know,
things
have
changed
where
we
are
today
for
a
lot
of
process
packet,
founding
engines
you're.
Looking
at
top
of
that
pretty
much
the
way
that
stewart
mentioned
you're
going
to
look
at
that
and
say
what
following
decision
should
I
make
has
a
ttl
field.
E
You
know
give
me
calls
to
drop
the
packet
and
send
an
ecmp,
or
you
know
echo
one
of
those
things
saying
all
hell
broke,
those
look
at
the
tc
bits
and
say
what
what's
the
what's
my
faucet
traffic
classification,
but
we
go
beyond
that
and
we
actually
start
looking
down
the
the
stack
and
so
the
sacrosanct
bits.
Then
are
the
s
bits
because
you
really
need
to
know
when
you
should,
when
you
have
to
stop
and
how
far
you
go,
how
far
down
you
go.
E
It
depends
on
your
packet
processing
engine
and
the
capabilities,
your
buffers
and
all
those
things
and
what
you
do
also
changes.
For
example,
if
you
find
special
purpose
labels
in
the
stack,
you
don't
feed
them
into
your
into
the
mill.
That's
grinding
out
your
entropy,
so
you
know
you
get
a
label
at
the
regular
level.
You
stick
it
in.
You
grind
some
more!
You
stick
the
next
one
and
random
ones.
You
say.
Oh,
this
is
a
special
purpose
level.
I
gotta
do
something
different.
So
the
eli
kind
of
said:
hey,
stop
right!
Here!
E
E
E
This
is
where
we
are
today
and
and
but
the
problem
is
the
following:
if
you
step
back
and
again,
I'm
trying
to
put
you
know
a
stuart
like
view
to
this,
if
you
say
what
is
the
architecture
of
what
are
the
rules
of
processing
a
label
stack,
I
will
I
want
to
go
further
and
I
want
to
say
that
actually
it's
more
than
that.
What
are
the
rules?
E
What's
the
architecture
of
the
label
stack
and,
yes,
we
say
stack,
and
yet
we
are
not
using
it
as
stack
the
moment,
you
you
look
at
anything
below
the
top
of
stack,
not
having
popped,
the
top
of
stack
you're,
not
behaving
as
a
stack.
So
but
then
what
are
the
rules?
What's
the
architecture
for
everything
that
comes
after
the
end
of
stack
and.
E
Sort
of
you
know
you
can
build
those
up
and
say
just
the
architecture.
This
is
how
you
behave
with
the
stack.
You
know
you
can
push,
you
can
pop.
You
can
look
at
the
top
of
stack,
but
maybe
now
you
can
do
other
things
and
then
you,
you
similar.
You
say
for
stuff
that
comes
after
the
end
of
stack.
What
do
I
do
with
this?
E
But
you
have
to
sort
of
balance
that
against
the
there's
all
these
new
functions,
we
need
and
they're
all
these
new
things
that
we
want
to
do,
and
so
it's
that
push
and
pull
between
yeah
I've
got
this
beautiful,
pure
architecture
and
I
was
like.
But
how
would
you
do
this
and
that
I
think
oh
okay
wait
but
then
there's
another
piece
which
is
the
power
of
the
current
forwarding
engines
have
changed
dramatically
between
20
years
ago
and
today,
and
so
you
could
then
step
back
and
say
yeah.
E
E
It
was
complex,
the
a6
were
difficult
to
do
so.
Let's
build
a
simpler
asic
I'll.
Do
that
and
that
whole
rationale
for
how
you
build
how
you
design
your
forwarding
architecture
has
gone
away.
That
doesn't
mean
you
shouldn't
have
a
forwarding
architecture,
but
it
does
mean
that
you
aren't
limited
by
the
power
of
the
powering
engines
20
years
ago.
So
we
have
these
four
dimensions
that
we
got
to
look
at.
What's
the
architecture
of
the
label
stack,
what
should
be
the
architectural
label
stack?
E
What
should
be
the
architecture
of
what
comes
after
the
end
of
stack
bit?
What
should
what
are
the
new
functions
we
need,
and
how
do
we
accommodate
them
and
what's
the
power?
How
does
that
all
map
into
the
power
of
the
current
pfes
and
pfes
going
forward,
and
in
fact,
how
should
all
these
educate
pfe
designers
as
to
hey
this
addiction?
We
could
be
going
so
it
would
be
great
if
you're
there
with
us.
So
I
think
this
is
sort
of
the
the
knob
of
the
problem.
E
But
when
I
wrote
this
draft
and
when
I
wrote
you
know
some
of
the
suggestions,
it
was
more
along
the
lines
of
the
the
last
one:
here's
the
power
of
my
pfe.
So
I'm
just
going
to
go
ahead
and
do
this
so
so
I
am
more
than
happy
to
step
back
and
say:
okay,
let's
not
just
do
it,
but
let's
try
to
put
some
order
some
organization
to
this.
E
E
E
E
I
could
have
used
31
bits,
32
bits,
32
bits
would
be
bad
because
the
end
of
stack
bit
is
sacrosanct,
so
I
could
have
used
31
bits,
but
but
now
I'm
coming
back
and
saying
yes,
I
should
have
used
31
bits
back
then,
but
even
for
that,
following
actions
indicator
for
the
special
purpose
label,
I
could
have
had
all
these
other
bits.
And
yes,
this
is
a
proposal,
but
I
mean
the
the
higher
order
bit.
Is
that,
instead
of
just
saying
here's
an
entropy
label
indicator
or
here's
a
you
know
blah
blah
blah
indicator?
E
E
Is
it
no
further
fast
readout?
Is
there
a
flow
label,
a
flow
id?
Is
there
a
and
what's
it
called
guess,
a
slice
indicator?
Is
there
om
at
the
end
of
stack
and
and
so
so
we
can
then
turn
every
new
special
purpose
label
into
a
label.
That
says
I
have
a
lot
more
information
for
you
and
sort
of
like
the
eli
say
the
the
fields
that
follow
me
also
have
more
information,
and
the
bits
that
I
have
here
are
going
to
tell
you
whether
that
information
exists
or
not.
E
So
in
particular,
if
the
forwarding
actions
indicator
has
the
end
bit
turned
on.
If
there's,
if
it
remains
as
defined
here,
the
end
bit
basically
says:
don't
do
further
fast
without
well.
It
doesn't
need
any
more
data.
It
just
says
you
know
if
you
ever
come
into
a
situation
where
you
need
to
do
fast
layout,
I'm
just
telling
you
that
it's
not
a
good
idea
and
how
you
get
that
involved
is
orthogonal.
E
It
needs
no
extra
data.
But
if
you,
if
you
basically
say
I'm
an
entropy
label
indicator,
then
the
the
label
below
me
is
an
entropy
label.
Except
now
it's
all
31
bits
and
in
fact
I
use
the
eg
fields,
not
as
independent
flags,
but
as
a
two-bit
field.
That
say
you
know,
depending
on
the
value.
The
next
word
is
a
combination,
entropy
and
guess,
which
is
the
slice
indicator
or
in
you
know,
if
I
really
need
big
numbers
for
them,
then
I
could
have
an
entropy
followed
by
the
slice
indicator.
E
If
you
use
the
same
architecture,
then
you
can
do
multiple
of
multiple
things
as
well,
but
but
that
is
that
is
more
of
the.
I
can
do
this
and
I
need
to
do
this
and
not
so
much
of
the
architecture
of
how
you
do
this
so
so
it
is
good
to
then
say:
okay,
here's
a
nice
idea,
and
it
you
know,
like
I
said:
if
people
have
you
know,
you
know
forwarding
engines,
hopefully
not
things
that
are
five
six
years
old,
because
we
do
want
to
move
forward.
E
E
So
so
that
I
mean
in
a
nutshell,
the
proposal
is
that,
but
I
think
the
other
side
of
this
is
we
also
have
all
these
pressures.
I
mean
spring
has
put
a
lot
of
pressure
on
the
label
stack
because
it
makes
the
labels
act
so
big.
So
if
you
say
oh
just
go
to
the
end
of
stack
and-
and
you
know,
look
for
the
iom-
hop
by
hop
label
on
data
and
go
do
what
you
need
to
do.
E
That's
a
a
difficult
thing
to
do,
and
in
the
in
the
course
of
discussing
how
eli
and
el
should
work
together,
we
actually
started
thinking
about.
Should
we
put
the
eli
on
the
top
of
stack,
so
normally
at
the
top
of
stack?
Is
your
label
that
tells
you
what
to
do,
but
should
we
put
it
on
the
top
of
stack?
E
And
so
you
sort
of
say:
oh
there's
an
eli
here,
so
I'm
going
to
grab
the
next
label,
which
is
the
el,
then
I'm
going
to
grab
the
label
after
that
say:
okay,
that's
the
folding
label
and
then
maybe
you
know
if
it's
an
adjacency
said
I'm
going
to
pop
it.
I
know
what
to
do
now
with
the
label
with
the
with
the
packet.
E
Then
I'm
going
to
stick
these
back
on
and
then
I'm
going
to
do
that
every
half
and
we
seriously
thought
about
that
for
a
while
and
that's
a
huge
problem
with
this
is
no
longer
a
stack,
but
it's
also
a
huge
problem
with
you
know.
Can
my
forwarding
engine
do
this,
so
we
ended
up
by
saying
we
can
put
the
eli
multiple
times
inside
the
label
stack
and
so-
and
we
came
up
with
this
notion
of
a
readable
stack
depth
and
all
so.
E
We
sort
of
built
things
kind
of
ad
hoc
and
I
think
where
we
are
now
is
we
can
you
know
we
can't
not?
We
can
we
should
step
back
and
say
what
is
the
architecture
of
the
label
stack?
What
are
the
actions
you
can
take
on
a
label
stack?
How
do
you
do
this
in
the
context
of
big
deep
label
stacks,
especially
as
mandated
by
spring
and
when
we
do
get
to
a
label?
If
it's
not
at
the
top
of
stack,
is
it
different
from
a
label?
That's
at
the
top
of
stack?
E
So
I
think
those
are
the
bigger
questions,
the
rest
of
the
questions.
You
know
if
these
questions
are
answered
in
this
group,
then
the
rest
of
the
questions
are
the
questions
for
the
mkls
working
group.
Okay,
what
label
do
we
allocate
and
what?
What
do
these
bits
mean
I'll
stop
there?
I
I
want
to
say
one
other
thing
before
I
stop
the
idea
that
there's
a
label
stack
and
a
post
label
stack.
E
It
could
be
anywhere,
but-
and
I'm
telling
you
that
there's
something
in
the
packet
that
you
might
want
to
do
something
with
in
transit
and
it's
so
it's
not
a
matter
of
going
to
the
end.
You
know
at
that
point,
you
know
the
level's
faster
than
pretty
much
popped
and
now
you're
just
processing
the
packet
before
handing
it
off
to
the
next
thing,
which
is
could
be
you
know
to
ace
router.
E
A
Okay,
I'm
done
okay.
Thank
you
very
much
kuwaiti.
I
see
that
what
I'd
like
to
do
is
open
the
floor
for
general
discussion
of
everything
that
we've
heard
so
far,
plus
anything
else.
That's
on
your
mind,
that's
relevant,
of
course,
and
I
see
that
rakesh
is
the
first
person
in
the
queue
so
rakesh
go
ahead.
C
E
E
So
so
this
doesn't
have
to
be
at
the
bottom
of
the
label
stack
and
so
one
of
the
things
one
could
think
about,
and
one
of
the
things
that
I
started
thinking
about
didn't
put
in
the
draft
but
did
put
forward
the
idea
that
these
labels
can
repeat
so.
The
idea
is,
for
example,
I
could
have
a
forwarding
actions
indicator
that
says:
I'm
just
going
to
have
these
bits
that
say
what's
coming
up
next
and
I'm
not
going
to
carry
their
associated
data
or
I
might
carry
a
subset
of
the
associated
data.
E
The
idea,
the
idea
of
that
is
essentially
I
have
a
label
stack,
that's
25
labels
deep
and
a
lot
of
processing
engines
can
only
read
three
levels:
four
labels,
so
you
know
what
we
call
it
really
we'll
start
that,
then
what
you
could
say
is
I'm
going
to
put
one
of
these.
You
know
within
the
first
four
labels
so
that
you
can
see
it
and
then,
when
you
get
to
it
and
pop
it
off,
then
then
there'll
be
another
one
within
four
levels
and
and
so
on
and
so
on.
E
E
Let
me
go
to
the
end
of
stack
and
and
find
that
and
do
what
I
need
to
do
and
then
come
back
and
then
keep
going
right
and
and
if
it
can't
do
it,
it
doesn't
have
to
do
it
if
it
doesn't
have
any
hop
by
half
om
data.
Oh
good,
I
didn't
have
to
pass
the
level
stack
just
to
find
that
there's
nothing
to
do
so.
The
idea
is
that
this
could
be
repeated
and
it
could
say,
look
if
you
want
to.
E
There
is
not
necessarily
hubba
half
iron
data,
but
there
is
hop
by
hop
end
of
stack
data
that
you
would
have
to
pass
the
whole
stack
for
depending
on
your
budget
and
so
on.
You
can
do
it
or
not
so
and-
and
you
can
put
this
pretty
high
up
so
if
you
say
normally,
I'm
just
going
to
pick
up
four
labels
from
the
stack
and
I'm
going
to
process
them
and
and
keep
going.
E
Well,
I
mean,
if
you
introduce
a
new
special
purpose
label,
that's
going
to
happen.
So
what
you're
going
to
get
is
you're
going
to
get
a
new
special
purpose
label
here.
So
the
forwarding
action
indicator
is
a
new
special
purpose
table
and
it
basically
says
I'm
just
funking
your
special
purpose
label
where
these
bits
that
come,
you
know
the
tc
bits
and
the
ttl
bits
are
supposed
to
tell
you
what
to
do,
and
if
you
don't
understand
it,
you
have
two
choices.
E
Well,
this
is,
should
never
be
on
top
of
stack
because
the
you
know
there's
no
guarantees
that
the
ttl
will
be
anything
meaningful
or
the
tc
bits
would
be
anything
meaningful
so
so
take
that
you
know.
That
is
a
very
big
caveat
here.
So
you're
looking
at
this
forwarding
actions
indicator
and
say
I
don't
know
what
this
is
and
you
have
a
choice
of
dropping
the
packet
or
ignoring
it.
E
Oh
so
so
so,
first
of
all
for
any
new
special
purpose
label
for
water,
whether
you
use
the
tc
baits
or
not,
you
have
this
problem,
it's
it's
a
new
special
purpose
label
and
if
the
foreign
engine
doesn't
know
what
to
do
with
it,
it
could
I
mean
there's
some
prescribed
behavior,
but
it
is
different.
So
the
least
thing
is
to
just
say
I'll,
ignore
it.
The
worst
thing
is
to
say
I'll
drop
the
packet
and
it
doesn't
matter
whether
you're
using
the
tc
bits
or
not.
E
You
can
do
it
that
way,
but
I
want
to
be
able
to
optimize
because
we
have
multiple
types
of
pfes,
some
which
will
never
be
able
to
process
this,
but
some
which
can
process
this
at
a
cost.
And
if
I
push
this
up
to
the
top,
I
can
tell
you
up
front.
There
is
something
if
you
want
to
go,
get
it
go,
get
it
not.
Oh
all
the
time
go
to
the
bottom
of
stack
and
see
if
there's
something
interesting.
E
Always
have
s
equals
zero
for
the
the
oh,
so
the
data,
the
data
depends,
I
mean
so,
for
example,
if
the
eg
okay
again,
for
the
specific
example
that
I
put
in
the
mpls
working
group,
the
eg
value
can
have
zero
zero
meaning
there
is
nothing
so
actually
the
following
actions
indicator
itself
might
have
s
equals
one.
That's
why
I
said
s:
not
s
equals
0
or
s
equals
1..
The
forwarding
actions
indicator.
I
mean
eg
value
of
1
1,
for
example,
says
the
next
word
is
entropy.
E
The
word
after
is
the
slice
indicator,
because
you
want
them
both
to
be
big
and
so
you've
got
31
bits
of
each,
and
so
you
get
the
entropy
level.
Have
a
sub
0
and
the
slice
indicator
having
an
s
of
possibly
1.
If
there's
nothing
else
going
on
or
there
could
be
a
vpn
label
below
that.
So
you
know
it's,
it's
open.
It's
not!
This
is
not.
This
entire
thing
is
not
necessarily
at
the
top
of
the
bottom
of
the
track.
C
B
Could
I
suggest
that
maybe
we're
a
bit
in
the
weeds
here?
Yes,
because
this
is
only
one
proposal.
I
I
personally
think
it's
quite
an
interesting
one,
but
it's
only
one
and
we
need
to
go
up
up
a
few
levels
and
understand
you
know
things
like
whether
we
have
a
problem
and
what
we're
going
to
do,
etc
and
when
we
actually
do
the.
If
we
do
the
real
work,
when
we
do
the
real
work,
then
we
will
be
really
down
into
the
detail
of
the
design
of
kiriti's
packet.
A
L
Go
right
ahead:
okay,
okay,
yeah!
Thank
you,
stuart,
very
much.
That's
the
beginning
give
a
very
excellent
review
of
the
about
history
of
mps
evolution
about
two
and
a
half
years
ago.
Actually
we
started
to
realize
that
there
will
be
multiple
functions
with
the
complete
location
of
the
bottom
stack,
for
example
by
then
you
see
the
requirement
to
run
a
bunch
of
in-network
functions
such
as
asf
function,
service
chain
and
iom
in
steel
oem
and
some
other.
L
So
we
cannot
borrow
the
similar
idea
from
the
ipv6
by
introducing
the
concept
of
extension
header
to
the
mpos,
and
meanwhile
we
also
try
to
avoid
some
pitfalls
of
the
exchange
headers,
the
mpv6,
to
make
it
more
flexible.
For,
for
example,
we
should
allow
the
user
to
quickly
jump
all
the
extension
headers
to
access
our
original
payload.
L
Improvements
there.
Meanwhile,
actually
we
publish
a
bunch
of
related
drafts.
One
of
them
is
actually
talking
about
how
we
will
indicate
the
presence
of
the
extension
header
in
that
draft.
We
actually
list
quite
a
few
all
the
other
possible
ways.
We
can
consider
at
that
time,
for
example,
using
a
claim.
L
Another
special
purpose,
extension
header,
a
label,
a
special
purpose
label
or
use
the
extended
special
purpose
label,
or
use
the
gale
plus
ach
with
channel
type
extension
or
scale
plus
another
level
value,
and
even
another
approach
to
use
fec
label
to
to
to
be
the
exchange
has
indicator
in
that
draft.
We've
actually
list
all
the
pros
and
cons
of
each
each
method.
So
you
can
take
a
look
at
that
that
we
can
continue
the
discussion
from
there.
Also
we,
you
know
another
two
drops.
L
So
so
I
I
think
by
then
actually
two
years
ago,
in
one
of
the
mps
meeting,
we
already
gave
a
introduction
of
this
extension
header
idea,
but
by
then
it
seems,
there's
a
little
interest
in
networking
group
to
consider
this
issue,
but
I
think
now,
maybe
it's
a
it's
a
good
time
to
restart
it.
So
that's
why
we
also
revive
all
these
drafts
and
we
request
a
working
group
to
look
at
those
drafts
and
consider
the
comments
or
proposal.
A
B
E
B
A
I
I
N
Hi,
I
wanted
to
comment
on
what
stewart
called
the
weeds
from
curity
and
I
think
that's
an
important
layer
of
the
problem.
Obviously
we
may
only
want
to
get
to
it
when
we've,
you
know
gotten
down
to
it
with
respect
to
you
know
agreeing
on
the
importance
of
all
the
use
cases
represented
and
so
on,
but
some
some
note
on
on
the
weeds
here
and
I
think
what
stewart
and
and
kiriti
nicely
presented
is
that
we've
done
a
little
bit
of
a
very
much
ad
hoc
hacky
evolution
of
the
mpls
forwarding
plane.
N
But
yet
it
is
the
you
know,
most
flexible
encoding
of
packet
processing
that
we
have,
and
if
I
look
over
the
you
know
over
the
curtain
into
let's
say
what
spring
is
doing
with
the
different
variations
of
you
know
an
ssr
header
header
in
in
v6
and
where
also
the
question
is
always
coming
up.
Well,
what
can
be
done
and
what
cannot
be
done
in
various
different
forwarding
planes?
I
think
that
unless
we
want
to
continue
down
the
rabbit
hole
of
just
doing,
you
know
hacky
increments,
that
are
the
the
smallest.
N
You
know
encoding
language
for
variable
headers.
If
you
look
at
it,
it's
all
very
much
based
on
very
static
tlv
headers.
So
maybe
you
know
this
weeds
is
something
that
maybe
the
ietf
shouldn't
just
do
alone
here
for
this
particular
case,
but
maybe
reach
out
to
that
adjacency
of
p4,
because
they're
also,
I
think,
should
be
and
may
already
be.
Looking
into.
You
know
more
flexible
headers.
C
C
F
C
F
F
I
think
so
now
that's
the
most
popular
is
already
defended.
That's
the
for
the
ipv6!
I
think
that
for
the
ethernet,
I
think
it
is
a
little
difficult
to
use
this.
The
this
general
delivery
functions,
on
the
other
hand,
for
the
pr
layer.
I
also
doubt
that
why,
because
the
beer
already
can
be
encapsulated
in
the
forwarding
plane
or
the
ipv6
ipv6
the
data
plane,
so
if
the
peer
layers
have
this,
the
general
function,
delivery
for
the
mcrs
there's
also
the
generally
delivery
functions.
So
I
think
this
causes
the
replication
of
the
confliction.
F
I
I
Those
are
the
functions
that
currently
only
define
for
ip,
but
it
can
certainly
be
done
for
for
mqs
and
for
beer
or
a
beer
layer
without
using
ip
if
we
go
with
the
generator
function,
but
that's
a
bigger
topic.
We
don't
have
to
talk
about
today,
but
more
importantly,
is
my
point:
is
that
anything
while
it's
it's?
Yes,
it's
a
bigger
topic,
but
it's
going
to
be.
I
It
has
to
have
landing
points
in
mpos
or
in
beer
or
in
yes,
sr
research
wherever,
basically,
my
my
request
is
that
whenever
you
design
a
a
function
for
mpos
layer,
just
please
keep
in
mind
that
ask
yourself:
can
this
be
extracted
out
to
to
other
layers
and
also
to
add
to
rakesh's
comments?
See
I
forgot
what
he
was
talking
about.
Rakesh.
Could
you
could
you
say
remind
me
what
your
comments
were.
C
I
O
A
F
Jeffrey
this
is
the
comments
I
a
little
confused
for
the
for
this
because
he
mentioned
the
fragmentation
and
the-
and
this
is
how
this
is
the
ipsec.
This
is
the
circularity.
This
is
the
extension
header.
I
wonder:
that's
used
for
the
ethernet
layer
or
the
pr
layer
or
this
the
mkhr's
layer
there's
the
are.
There
are
such
user
cases.
C
J
B
A
I
Yes,
a
quick
response
to
rachel's
comments
about
using
the
iom
label
indicator
label,
so
we
notice
that
there
is
gel
label,
there's
our
indicator
label
and
then
there
is
also
gdf
indicate
the
neighbor
label.
So
if
you
consider
all
those
together,
if
we
could
somehow
conclude
that
using
gta
is
a
reasonable
thing
to
do,
then
we
can
use
one
label
to
indicate
that
gdp
edge
header
follows
and
from
there
you
can
de-multiplex
into
a
lot
of
a
lot
of
options
to
to
to
implement
things.
M
Hi,
I
think
the
question
about
gender
calorie
function.
I
have
a
question
so
the
examples
given
is,
like
you
know,
common
functionalities
like
ipsec
and
fragmentation
and
the
specific
new
functionalities
like
iom
right.
So
these
are
the
two
examples,
but
I
think
you
need
to
be
careful
about
even
the
ipsec
ksr
fragmentation
which
completely
depend
on
the
data
plane
right.
So
if
you
have
ipv4
and
ipv6
fragmentation,
how
fragmentation
is
done
completely
different
and
the
restrictions
are
different
right.
M
Similarly,
and
the
ethernet
ethernet
is
a
completely
different
beast
and
we
may
not
do
it
here,
so
it's
need
to
be
done
in
a
different
sdo,
so
I'm
I'm
really
confused
about.
Then,
if,
let's,
if
you
come
out,
come
come
to
the
specific
new
functionalities
like
iom
again,
iom
defines
what
needs
to
be
done
and
again
need
to
be
adapted
to
the
forwarding
layer
where
we're
talking
it's
done
in
ipv4
or
ipv6,
so
I'm
just
literally
confused
whether
it
is
so
much
tied
to
the
particular
data
plane.
A
C
Yeah,
so
one
comment
is
that
I
think
optimizing
one
indicator
label
on
the
stack
is
I
mean
it's
good,
but
what
happens
with
iom?
Is
that
you're
not
only
adding
indicator,
but
there
is
a
quite
a
bit
of
metadata.
That's
being
also
need
to
be
added
by
the
end
cap
node.
So
it's
not
just
the
header
length,
but
also
a
big
chunk
of
metadata.
C
A
B
B
B
B
B
B
B
It's
important
that
any
change
be
practical
on
the
forwarding
technology
likely
to
be
deployable
in
the
reasonably
near
future.
So
I've
not
said
it
has
to
work
on
any
old
piece
of
legacy
junk,
but
we've
got
to
have
a
vision
that
we
could
probably
and
it
doesn't
have
to
be
any
equipment-
that's
shipping
today
necessarily,
but
it
does
need
to
be
in
the
very
very
reasonably
near
future.
B
It's
important
that
we
minimize
the
number
of
changes
needed
to
support
the
new
needs
by
making
changes
that
provide
an
elegant
approach
that
satisfies
us.
Many
of
the
new
and
future
needs
as
possible.
Now
I
have
some
so
some
comments
about
ways
forward.
Do
you
want
me
to
pause
at
that
point
andy
and
ask
for
other
questions
or
or
does
any
of
the
other
chairs
want
to
chip
in.
B
If
we
agree
on
that,
then
I
would
suggest
that
the
chairs
work
with
the
ads
to
determine
the
best
way
to
progress.
So
we
could
have
an
interim.
We
could
have
a
specialist
workshop,
we
could
set
up
a
design
team
or
we
could
do
something
else.
Alternatively,
we
could
just
say
well.
Thank
you
very
much.
That
was
an
interesting
two
hours,
andy
and
stuart,
we'll
discuss
on
the
list
as
usual
and
progress
at
the
next
ietf.
B
B
B
E
B
B
P
Q
Actually,
sort
of
waiting
to
hear
members
of
the
working
group
speak
up
and
provide
their
opinion,
but
I
mean
based
on
what
I've
heard
at
the
mic
and
seen
at
the
you
know
in
the
chat
and
it,
and
certainly
I
I
think
six
is
a
correct
statement
so
yeah.
I
do
think
that
you
know
just
sort
of
sticking
this
in
the
back
burner
until
111
would
not
be
the
correct
thing
to
do.
R
Yeah,
I
guess
I
agree
with
what
john
said
I'd
like
to
add
that
I'm
not
so
much
in
favor
of
a
team.
I'd
prefer
the
discussion
to
start
on
the
mpls
list
or
on
mpls
and
parzan
or
whatever,
but
having
a
a
discussion
that
can
allow
as
much
people
as
possible
to
participate
and
then
see
where
it
leads
us,
but
indeed
working
at
a
faster
rate
than
three
times
a
year
is
a
good
thing
to
do
so.
B
Martin,
the
the
debt
net
world
had
over
essentially
open
design
teams
which
seemed
to
work
quite
well,
that
is
to
say,
there
was
a
core
group
that
used
to
turn
up
to
each
of
the
each
of
the
meetings
and
they
met
once
a
week
in
some
cases
once
every
two
weeks
with
a
focused
task.
But
anyone
could
join
and
the
and
take
part
in
it,
and
there
are
good
export
regulation
reasons
why
you
shouldn't
have
a
closed
design
team.
These
days.
P
A
A
A
Yes,
so
what
I
would
like
to
suggest,
seeing
as
we're
over
time
already,
is
that
we
we
continue
the
discussion
of
exactly
what
we
should
do
next
on
the
mpls
list,
and
I
would
also
like
us
to
focus
all
of
the
discussion
of
this
topic
on
one
list,
that
being
the
mpls
list,
and
that
way
people
aren't
scattered
to
three
or
four
different
email
lists
and
there
aren't
multiple
copies
of
each
email.
So
let's
continue
this
on
the
mpls
list.