►
From YouTube: IETF102-ANRW-20180716-1100
Description
ANRW meeting session at IETF102
2018/07/16 1100
https://datatracker.ietf.org/meeting/102/proceedings/
A
We
have
two
talks
in
this
session.
Our
first
talk
is
an
invited
talk
from
Alberto
Donati,
who
is
a
research
scientist
at
kata,
the
Center
for
Applied
Internet
data
analysis,
Alberto's
been
doing
a
lot
of
work
with
with
his
team
on
routing
security
or
shall
I
say
routing
in
security
over
the
past
many
years.
It's
still
a
topic,
it's
still
a
thing
and
he's
been
making
hay
on
that
today.
He's
gonna
talk
to
us
about
detecting
and
neutralizing
BGP
hijacking.
This
was
a
paper
I
think
it
appeared
in
CCR.
B
You
thank
you
thank
you
for
inviting
me
good
morning,
so
this
project
is
called
Artemis
and
it's
a
joint
work
between
kada
and
inspire
research
group,
but
for
the
University
of
Crete,
as
I
was
saying,
the
pivot
is
an
archive.
You
can
access
it
through
the
problem
of
the
workshop.
The
pillar
is
extremely
dense,
with
lots
of
results
and
experiments
and
contributions,
I
would
say
so.
B
I
will
go
very
quickly
and
just
try
to
give
you
some
insights
and
I
hope
that
you
will
be
interested
in
reading
the
paper
I'm,
assuming
that
the
topic
is
well
known
to
this
audience.
Bgp
hijackings,
when
an
attacker
is
stealing
or
manipulating
your
BGP
routes
and
the
traffic
diverts
from
the
original
route
route
and
it
reaches
an
attacking
of
the
new
system.
B
In
the
simplest
case,
then,
the
attacking
Odone
system
could
even
be
able,
in
some
cases,
to
send
traffic
to
the
legitimate
owner
of
these
prefix
and
therefore
position
itself
to
carry
out
a
man-in-the-middle
attack
at
a
large
scale.
So
we
call
these
many
hijacks,
and
this
is
the
mandatory
slide
that
you
can
picture
in
your
mind
with
all
the
latest
news
headlines:
big
names,
panic
and
I've
been
a
bit
lazy,
but
there
have
been
so
many
events.
B
So
last
week,
there's
been
lots
of
hype
about
the
big
channel
hijack
factory
shut
down
a
few
months
ago.
You
heard
about
the
Amazon
hijacks.
There
have
been
many
events
reported
over
these
years.
I
think
that's
scary,
but
what
is
also
scary
is
that
certain
attacks
can
be
carried
out
in
much
more
stealthy
way
in
a
more
sophisticated
way.
We
should
care
about
those
in
general.
We
should
care
about
the
fact
that
any
other
mo
system
on
the
Internet
is
still
vulnerable
to
this
problem.
Bgp
has
a
trust
problem
in
the
sensory
trust.
B
B
We
published
the
results
this
year
of
a
survey
that
we
did
last
year
with
more
than
70
of
readers,
participating,
asking
them
about
bgp
security
role
in
seniority,
the
solutions
that
they
have
been
taking,
and
why
and
why
not-
and
for
example,
about
that
PGI.
Unsurprisingly,
we
found
out
that
our
PGI
is
not
widely
deployed
because
it's
not
widely
deployed,
but
I.
Don't
think
this
surprises.
They
hear
the
crowd
here.
B
Well,
other
reasons
were
high
complexity,
a
high
cost,
and
anyway
we
have
to
deal
with
this
reality,
so
I
think
I
stay
in
some
time
to
take
off.
In
the
meantime,
we
are
left
with
some
reactive
solutions
there,
basically
based
on
third-party
services,
so
we
inquired
operators
also
about
these
services
that
some
of
them
use
how
satisfied
they
are.
B
What
are
the
problems
and,
in
terms
of
I,
mean
practical
problems
and
we
studied
these
approaches
and
unfortunately,
they
suffer
from
several
issues
starting
from
comprehensiveness,
because
most
of
them
are
our
focus
focus
on
only
very
simple
attacks.
For
example,
when
an
attacker
is
originating
the
prefix
of
someone
else
and
not
on
attacks
in
which
the
attacker
is
manipulating.
In
a
more
clever
way,
the
forged
announcements,
so
another
big
problem
of
these,
these
approaches
is
accuracy
which
is
a
problem.
B
Unfortunately,
by
design
they
are
prone
to
false
positives
and
false
negatives
because
of
practical
issues,
because
the
operator
that
uses
this
kind
of
services
needs
to
constantly
update
information
about
its
network,
which
phenomenal
system
is
supposed
to
announce
certain
prefix
prefixes,
at
which
level
of
aggregation,
which
alone
systems
are
their
neighbors
and
so
on,
and
this
doesn't
happen
consistently.
Let's
say
it
doesn't
happen
continuously
and
therefore,
then
there
is
the
problem.
B
B
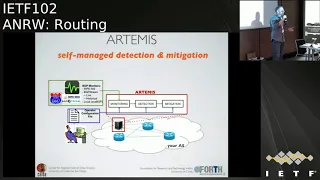
So
with
Artemis.
We
try
to
address
these
issues
by
proposing
a
radically
different
approach,
which
is
not
a
third
party
based
approach,
but
it's
self
managed.
So
the
idea
is
that
an
operator
protects
itself
by
running
Artemis
on
their
own
networking
server
in
their
own
network,
or
this
server
can
be
hosted
in
the
cloud
and
connected
through
a
separate
channel
to
your
network
and
what
it
does.
It
runs
the
Artemis
approach.
B
Basically,
it
uses
as
input
data
feeds
from
stream
of
BGP
data,
for
example,
for
project
from
projects
like
route
views
and
write,
briefs
and
information,
of
course,
from
the
local
routers,
the
routers
of
the
network
that
is
protecting,
and
you
can
imagine
that
it
might
take
information
from
a
route
reflector,
for
example,
and
then
the
other
input
that
it
uses
it's
a
configuration
that
can
be
tweaked
by
the
operator.
But
ideally
we
would
like
this
configuration
to
be
manually.
Sorry
automatically.
The
opposite.
12
be
automatically
updated
using
the
information
from
the
logger
routers.
B
So
this
is
quite
a
paradigm
shift
and
magically
kind
of
I
mean
we
spend
lots
of
people
worked
on
this
project
and
I
would
still
call
it
work
in
progress,
but
we
found
it
this
way.
We
were
able
to
address
all
the
four
issues
that
I'd
mentioned
earlier,
so
with
Artemis.
Actually,
we
are
able
to
cover
basically
all
types
of
attacks.
B
And,
of
course,
as
I
was
saying
earlier,
with
with
the
accuracy
then
comes
speed.
If
you
can
trust
the
alerts
are
coming
from
your
system,
then
you
can
think
about
automating
some
reactions
and
automating
mitigation,
and
in
the
paper
we
show
with
experiments
on
the
real
internet
that
with
Artemis
we
can
mitigate
hijacking
attacks
within
a
minute.
Actually,
it
happens
also
in
a
few
seconds
and
finally,
the
problem
of
privacy,
which
is
intuitive.
In
this
case,
all
the
information
stays
within
the
network
is
not
shared
with
a
third
party.
B
Okay,
so
basically
Artemis
is
based
on
BGP
data
and
it's
based
on
the
on
the
intuition
that
today,
the
public,
so-called
public
monitoring,
BGP
infrastructure,
the
structure
operated
by
projects
like
route
views
right,
please,
Colorado,
State,
University,
BGP
mon.
There
are
sharing
BGP
feeds.
It
became
so
pervasive
today
so
pervasive,
sorry
that
it
allows
to
have
great
visibility
into
what
happens
in
the
internet.
We
are
talking
about
hundreds
of
motors.
B
Another
important
aspect
that
inspired
us
is
that
these
projects
are
transitioning
into
a
live
stream
mode
of
sharing
feeds
and
therefore
we
can
start
conceiving
approaches
in
which
the
operator
leverages
this
data
for
near
real-time
detection.
So
in
the
paper
through
simulations,
we
show
we
actually
perform
some
extensive
simulations
using
data
from
the
real
internet
topology
at
least
what
we
call
in
fear
of
the
real
internet,
apology
and
AAS
relationships.
B
Infer
these
relationships
and
data
about
the
location
of
the
peers
of
the
collectors
of
route
views
and
write
briefs
which,
in
the
rest
of
the
talk
I,
will
call
simply
monitors
doing
these
simulations.
We
actually
showed
that
by
using
all
the
models
of
route,
fusion
right,
please
it's
possible
to
observe
all
attacks
of
those
that
we
simulated
with
a
significant
impact
and
by
impact,
and
so
you
want
to
look
here
basically
by
impact.
B
We
measure
impact
in
terms
of
percentage
of
autonomous
systems
that,
in
our
simulation
in
the
internet,
got
polluted
by
the
routes
forced
by
the
hijacker
and
I.
Think
I
should
hurry
up.
Cuz
time
is
short,
as
I
said,
this
is
kind
of
an
advertisement
for
the
paper.
You
find
more
information
about
impact
and
speed
in
our
simulations.
So
we
try
to
see
how
far
inspired
by
this
aspect
right
and
we
try
to
work
on
this
approach,
then
we
try
to
see
how
far
we
could
push
it.
B
So
in
the
paper
we
propose
a
BGP
hijacking
attack
taxonomy,
which
is
based
on
three
dimensions:
the
first
one
we've
got
it
type
0
1
2
is
based
on
where
the
attacker
is
placed
in
the
path.
So
if
the
attacker
is
actually
originating
the
prefix,
we
call
it
a
type
zero.
If
the
attacker
places
itself
one
hop
from
the
origin,
the
origin
is
the
legitimate
owner
of
the
prefix.
Then
we
talk
about
type
1
and
so
on.
B
Then
another
aspect
is
which
prefix
is
announced
by
the
attacker:
does
it
announce
the
exact
prefix
that
the
legitimate
owner
is
announcing,
so
it's
an
exact
prefix,
a
jack
or
a
sub
prefix,
or
is
it
announcing
space
that
is
owned
by
another
Ottoman
system,
but
it's
not
even
an
ounce,
and
then
we
talk
about
squatting
in
the
case
and
finally,
we
looked
at.
How
does
the
attacker
behave
and
what?
What
is
the
impact
on
the
data
plane?
Let's
say,
but
this
also
affects
the
gone
through
plane.
B
Actually
so
is
the
traffic
dropped,
and
so
it's
black
hauling
is
the
attacker
in
trying
to
impersonate
the
victim
or
is
instead
placing
itself
as
a
man
in
the
middle,
as
I
showed
in
one
of
the
first
slide,
and
this
has
an
impact
on
how
different
detection
approaches
work.
So
I
cannot
go
in
details
again
in
the
paper.
You
will
find
more
information.
B
There
is
an
analysis
of
related
work
with
respect
to
the
taxonomy
that
we
have
come
up
with,
but
actually
what
you
can
see
here
summarized
in
the
table
is
that
artists
basically
covers
all
the
types
all
the
attack
configurations
that
are
I
do
all
the
talkin
figurations.
One
thing
that
I
wanted
to
hide
here
is
a
mansion
for
I
Spy
people
that
was
published,
I
think
it's
cecum
ten
years
ago.
B
That
was
also
self-managed,
hijacking,
BGP,
hijacking
detection,
but
it
was
based
on
data
plane
and
some
doubling
techniques
do
not
operate
well,
cannot
operate
in
certain
scenarios
and
cannot
operate
with
certain
types
of
attack
configurations.
So
Artemis
think
it's
the
first
self-manage
approach
for
BGP
hijacking
that
is
based
on
control
plane
exclusively
on
control,
plane
data.
So,
as
you
can
imagine,
if
you
own
all
the
information
in
the
area
of
time
about
the
net,
most
of
the
detection
becomes
trivial,
and
this
is
what
we're
showing
here
for
a
large
tackle
and
class
of
attacks.
B
B
B
But
in
the
reverse
direction.
And
so
here
you
can
see,
the
link
is
X
is
y.
Where
si
is
access.
Y
is
actually
a
neighbor
of
the
origin.
Yes,
and
then
we
look
in
the
history
and
we
look
for
the
link
in
the
opposite
direction,
and
here
the
assumption
is
that
these
must
have
been
announced
by
a
sy.
So
it's
true
that
it
it
exists
in
the
topology,
a
link
between
ax,
x
and
y
sy
things
I
have
been
more
complicated.
B
Actually,
things
are
even
more
complicated
because
in
some
cases
the
attacker
might
be
able
to
do.
This
still
pollute
the
history
without
appearing
twice
or
using
a
second
twice
in
the
same
announcement
or
using
another.
Yes,
but
these
are
special
cases.
There
are
only
certain
cases
in
which
this
is
possible.
Basically,
the
attacker
is
pretending
that
there
exists
the
link
between
an
Aes
that
it's
adjacent
to
again,
so
a
link
between
ASX
and
asy,
and
I
yes,
there
is
adjacent
to
the
attack
so
because
of
these
also
special
case,
we
have
an
additional
restriction.
B
We
check
all
the
autonomous
system
numbers
that
appear
on
the
left
of
all
the
paths
in
the
history
that
showed
a
link
in
the
opposite
direction.
If
there
is
a
commonly
yes,
we
still
mark
it
as
suspicious
I
know
that
this
is
very
fast,
but
you
can
find
all
the
formalization
in
the
paper
we
have
lots
of
Greek
co-authors.
So
there
are
lots
of
Greek
letters
in
the
paper.
It's
fantastic,
so
I
invite
you
to
read
the
paper,
but
another
aspect
that
is
interesting
about
these
approaches.
Ok,
how
does
it
work
in
practice?
B
So
we
need
also
extensive
emulations.
We
actually
ran
out
in
stage
one
for
each
single
autonomous
system
that
in
March
2017
on
the
internet
was
announcing
prefixes,
so
pretending
to
run
our
same
Artemis
in
40,000
$50,000,
remember,
number
autonomous
systems
and
firewall
shredding
one.
We
were
shootin,
ok
and
we
perform.
We
use
history
from
the
last
ten
months
and
we
ran
this
for
30
days
again
for
each
single
AAS
originating
prefixes
and
using
data
from
all
the
routes
using
right,
piece
motors,
so
we're
talking
about
more
than
400
monitors.
B
B
This
is
one
every
ten
days
and
the
red
line
is
telling
you
which
ones
which
of
these,
how
many
of
these
links
would
have
generated
an
alert,
and
so,
for
example,
if
you
check
that
the
point
that
we
have
highlighted
in
this
case,
seventy-three
percent
of
the
autonomous
systems
running
Artemis,
so
less
than
one
suspicious
event
every
three
days,
which
still
you
might
think
it's
a
large
number.
These
are
still
alerts
right.
So
that's
why
we
came
up
with
stage
two
in
stage
two.
What
we
do
is
we
trade
latency.
B
We
wait
a
little
bit
after
we
detect
this
new
link
by
default
five
minutes
and
we
trade
this
for
additional
information,
and
there
are
three
aspects.
The
other
important
one
is
that
actually
there
is
the
intuition
that
if
this
was
actually
a
real
new
link
that
appears
in
the
topology
giving
some
time
to
BGP
to
converge,
we
would
start
seeing
in
some
cases
the
same
link
in
the
opposite
direction,
and
actually
these
happens
so
at
least
in
simulations,
because
this
is
something
that
we
couldn't
I
mean.
B
We
found
that
it
happens
in
reality,
but
it's
just
1%
for
the
route
fusion
right,
please
monitors
and
simulations.
We
found
what
we
actually
expected,
that
the
data
from
the
local
routers
is
really
precious
to
to
see
these
links
in
the
opposite
direction.
The
other
aspect
is
that,
by
waiting
a
little
bit,
we
can
start
estimating.
We
can
estimate
the
impact
that
the
attack
has
had
so
because
we
can
see
which
of
the
several
hundreds
of
miles
of
route
using
Rhys
have
seen
that
polluted.
B
Well,
not
polluted
that
suspicious
advertisement
and
so
announcement,
and
therefore
we
then
three.
We
can
use
this
information
to
change
the
policy
for
the
alerts.
For
example,
we
can
decide
to
treat
differently
alerts
that
have
had
a
very
small
impact
and
that's
what
the
operator
can
configure,
for
example,
only
for
certain
prefixes
in
Artemis
to
have
a
different
reaction
for
alerts
that
are
apparently
had
a
smaller
impact.
So,
basically,
what
we
can
do
is
to
trade,
removing
a
lot
of
false
positives
for
introducing
some
false
negatives,
with
potentially
less
impact
again
same
type
of
emulation.
B
B
So
the
message
here
is
that
the
majority
of
the
unverified
new
links
from
stage
one
the
past
stage,
one
I
actually
seen
by
only
one
more
and
then
for
example,
if
you
look
at
the
blue
line,
what
you
see
is
that
which
is
alerts
that
have
been
seen
by
three
or
less
motors,
then
you
would
see
that
for
81%
of
the
other
most
systems
in
our
emulation,
we
would
a
hand
they
would
have
not
seen
a
single
alert
in
a
month.
Finally,
I
hope
I
have
another
30
seconds
mitigation.
I
haven't
talked
much
about
it.
B
It's
of
course
important.
As
I
said,
there
are
two
approaches
that
we
propose
in
the
paper,
then
inspired
by
approaches
that
have
been
discussed
been
proposed
before
the
first
one
is
actually
do-it-yourself
is
just
the
aggregate,
your
routes.
Unfortunately,
you
can
do
that
only
down
2/24
level,
a
slash
twenty
five
wouldn't
be
wouldn't
propagate
on
the
internet.
The
other
one
is
okay,
relying
on
other
autonomous
systems
to
announce
your
route
and
tunnel
them
back
to
you
and
I
think
an
interesting
result
of
these
analysis.
B
Unfortunately,
this
one
could
have
been
done
only
in
simulations
we're
still
trying
to
convince
Akamai
cloud
design
they
are
here.
Please
come
talk
to
me
to
do
some
experiments
in
the
real
internet,
but
what
we've
seen
is
that
these
operators
are
actually
very
well-positioned
to
fight
me
to
be
hijacking
attacks.
These
are
operators,
sorry
I,
didn't
say
it's
written
here,
but
these
are
the
guys
who
performed
those
mitigation
by
BGP,
hijacking,
benign,
BGP,
hijacking.
B
They
announce
your
routes,
they
take
that
your
traffic,
they
scrub
it
and
they
tunnel
it
back
to
you
imagine
doing
the
same
thing
for
BGP
hijacking.
You
just
have
to
remove
the
scrubbing
phase,
but
it's
exactly
the
same
thing,
and
actually
the
simulation
suggests
that
they
would
well-
and
here
one
operators.
B
Okay,
one
last
word
about
Artemis:
there
is
an
open-source
tool
that
we
are
working
on
partially.
This
is
sponsored
by
the
ripe
NCC
community
projects
in
2017,
so
stay
tuned.
The
tool,
hopefully,
will
come
by
the
end
of
this
year
and
with
this
I
conclude
my
talk
and
if
you
have
any
questions,
be
happy
to
try
to
answer.
A
C
Course,
hi
I'm,
Jared,
Montz
from
Akamai
hi,
so
I
think
one
of
the
things
I
assume
is
an
underlying
premise
here
is
that
you
actually
know
what
you're
announcing
yes
and
you
can
actually
document
that
somewhere.
Somehow,
yes,
and
in
in
my
experience
in
working
with
networks,
they
actually
the
operators
often
do
not
know
a
complete
inventory
of
all
of
their
assets
of
IP
space,
believe
it
or
not,
and
they
don't
necessarily
know
what
the
a
the
origin,
a
s
or
the
a
s
path.
C
B
Forgive
us
we're
scientists,
no,
no,
no
I've
heard
that
and
that's
interesting
and
I
think
that's
a
problem
of
its
own.
First
of
all,
the
operators
should
try
to
solve
or
address.
Indeed,
this
is
marked
as
one
of
the
challenges
the
automated
confer.
We
call
the
automated
configuration
where
we
started
discussing
this
with
with
some
operators.
B
One
thing
we
can
imagine
is
we're
trying
to
work
on
scripts
that
would
take
data
from
route
reflectors
and
start
populating.
The
configuration
I
know
that
things
are
much
more
complicated
in
large
operators
networks.
So
another
option
is
also
to
monitor
the
data
and
there
it
then
collecting
it
automatically
and
they
have
a
human
in
the
past.
That
kind
of
verifies
this
thing
that
would
be
opportunities.
Nobody
there
to
start
putting
order
in
their
network
as
well.
Yeah.
C
D
B
D
B
D
B
Yes,
some
kind
of
interception,
I
would
say
so,
and
the
idea
is
that
same
mechanism
could
be
used
to
just
fight
somebody
hijacking
your
routes
and
without
the
need
to
do
scrubbing.
Of
course,
you
need
to
have
a
channel
enough
bandwidth
to
communicate
with
the
victim,
so
an
idea
would
be
to
to
at
least
peer
in
at
some.
My
ex
PE
colocation
facility
isn't.
A
A
A
F
Yes,
so
this
is
a
joint
work
with
Randy.
If
you
eat
alone,
tomas
and
matthias,
and
for
those
of
you
don't
know
what
about
origin
validation
is.
Let
me
just
give
you
the
brief
background,
so
it
pertains
to
bgp
the
same
problem
that
are
better
just
about.
So
you
probably
all
aware
so
a
BGP
and
there's
no
mechanism
that
allows
people
to
check
whether
an
AAS
has
permission
to
originate
a
certain
prefix
and
so,
for
example,
in
our
test
situation.
Here
we
have
a
is
a
and
C
they're,
both
originating
prefix
P.
F
F
Yeah
I'll
just
use
the
keyboard,
alright,
that
ASC
is
an
attacker
ASAS
division,
origin
and
since
PGP
follows
sir,
a
as
solar
stay
as
per
first.
In
the
absence
of
no
rule
overruling
policy,
the
traffic
will
go
to
the
attacker,
that's
the
problem.
We
already
have
a
solution
for
this.
It's
called
D
rpki,
the
resource
public
key
infrastructure.
This
is
a
specialized
public.
F
Okay,
so
just
some
definitions,
I
mentioned
these
are
physician
objects.
They
are
actually
called
route
original,
Feroze,
asians,
ross,
solid,
eric,
ripto,
graphic
objects.
They
authorize
exactly
one
a
s
to
originate
a
set
of
prefixes,
and
then
we
have
rel
author
notation,
which
is
a
bgp
router
validating
incoming
routes.
But
this,
doesn't
it
not
include
acting
on
this,
so
this
has
to
the
result
of
that
needs
to
be
using
the
policy
to
actually
do
anything.
F
Okay,
so
our
research
problem,
our
goal
is,
we
would
like
to
find
out
whether
there
are
any
a
s
that
are
actually
using
rough
based,
filtering
policies
and
there's
a
lot.
The
motivation
for
that
is
free
fold.
I
mean
first
of
all,
we'd
like
to
assess
the
current
state
of
Defense
on
the
Internet,
because
common
wisdom
suggests
that
no
one's
doing
this
and
we
like
to
know
if
that's
true
or
not.
Once
we
have
a
methodology
to
measure
this,
we
can
also
track
deployment
over
time.
F
We
can
attribute
spikes
and
deployment
to
certain
events
and
possibly
improve
deployment,
and
maybe,
if
we
give
people
a
list
of
a
s
that
are
actually
filtering,
this
will
create
an
incentive
for
other
people
to
at
least
look
into
this
and
perhaps
deploy
themselves,
and
the
challenge
here
is
of
course,
need
to
interfer
private
router
configurations
with
measurements
all
right,
so
there's
oh,
this
is
a
quick
definition
slide
just
from
the
same
page.
So
whenever
I
you
talk
about
BGP
data
or
I,
show
you
like
a
topology
or
something
we
always
take.
F
Data
from
our
collectors
around
connector
is
a
b2b
speaking
device
that
collects
updates
from
BGP
routers
and
dumps
them
periodically.
A
vantage
point
is
a
GP
router
that
peers
with
a
rod
collector
and
sends
updates.
So
our
Delta
cultures
monitors
I'll,
call
them
vantage
points,
so
we
should
have
synchronize,
but
oh
well
and
I'm
not
gonna
draw
the
route
collector
in
the
pictures,
so
this
is
always
implied
when
there's
a
technology.
It's
from
point
of
view
of
one
vantage
point:
okay,
now
on
to
actually
measuring
about
origin
valuation.
F
There
are
two
principal
approaches:
existing
work
has
used
uncontrolled
experiments.
What
I
mean
with
that?
Is
they
take
existing
BGP
data
from
drug
collectors.
They
take
existing
laws
and
they
use
heuristics
to
infer
which
AES
is
filtering
and
which
is
not,
and
this
can
be
done
fairly
quickly
because
it
already
only
needs
existing
data.
The
problem
with
this
is
that
it
doesn't
work
and
it
can't
work.
I'm,
not
gonna,
go
to
detail
why
it
can't
work.
If
you
like
to
know
more
about
this,
the
paper
that
this
talk
is
based
on
was
published.
F
Ccr
this
year.
There
we
go
into
detail
or
we
can
talk
offline.
So
what
we
are
doing
is
controlled
experiments,
so
this
involves
actively
announcing
our
own
prefixes
on
the
Internet
actively
creating
our
own
laws.
So,
of
course,
this
is
a
bit
slow
and
cumbersome.
We
need
to
actually
conduct
experiments.
We
need
an
AAS.
First
of
all,
I
need
our
own
IP
prefixes.
The
es
needs
to
be
reasonable,
reasonably
well
connected.
So
there's
a
pre
high
barrier.
F
In
our
case-
and
we
are
using
the
peering
testbed,
which
is
a
bgp
test-
verbs
where
researchers
can
experiment
on
the
internet
so
yeah,
we
are
conducting
multiple
experiments
to
measure
this
with
different
goals.
So
I'm
going
to
only
talk
about
the
basic
one,
which
has
the
goal
to
find
an
a
s
or
is
that
filter
invalid
routes
and
when
I
say
find
an
a
esta
fill
in
my
brows
I
mean
is
that
at
some
somewhere
in
its
network
has
deployed
route,
origin
validation,
they
don't
have
to
be
filtering
all
invalid
routes
they
receive.
F
It
only
has
to
be
some
filtering
going
on.
That's
that's
kind
of
our
goal,
and
this
is
this
experiment.
Is
the
core
is
very
simple:
we
announce
two
routes,
one
of
them
will
be
valid,
one
will
be
invalid
and
then
we
see
how
people
react,
adapt
in
infer
who's
filtering
or
not.
So,
on
the
BGP
side
of
things
we
announce
two
prefixes,
we
announce
PA
our
anchor
prefix
and
we
announce
PE
our
experiment.
Prefix
you
can
probably
tell
by
the
name
stats
PA
is
going
to
be
the
control
variable
when
I
can
change.
F
This
P
is
going
to
be
experimental
that
we're
gonna
play
with,
and
these
two
prefixes
are
at
least
on
our
site
treated
identically.
They
have
the
same
route
object
in
the
rear
database
because
some
folks
filter
on
that,
but
if
the
same
length
obviously
announced
an
onsen
at
the
same
time
to
the
same
origin
and
from
the
same
origin
to
the
same
Pierce,
so
we
hope
that
other
is
will
treat
them
identically
as
well.
Okay,
on
the
Arctic
ice,
several
things,
we
actually
conduct
the
experiments.
F
So
initially
we
issue
Rolo's
for
both
prefixes,
so
that
the
announcements
will
be
valid.
We
wait
until
this
propagates
throughout
the
internet
and
vantage
points
have
chosen
routes
for
both
prefixes
and
throughout
the
experiments.
The
anchor
prefix
will
always
stay
balanced
well
in
its
announcement
will
always
stay
valid
and
for
experiment
prefix.
We
now
start
periodically
changing
the
aurora,
so
the
announcement
flips
from
valid
to
envira
back
to
valid
and
we're
doing
this
on
the
24-hour
cycle.
F
So
each
experiment
is
contained
in
in
one
day
and
then
we
can
run
them
each
day
and
have
this
longitudinal
experiment
going
and
then
there's
essentially
two
types
of
situations
that
we
run
into
when
we
analyze
the
data.
One
is
that
we
are
directly
peering
with
a
mas.
That
has
a
vantage
point
so
in
this
case
we're
on
the
right.
This
is
steering
AAS
and
we
are
announcing
both
prefixes
directly
and
the
vantage
point
adopts
to
direct
route.
You
can
tell
by
the
color
that
both
announcements
are
valid.
This
is
the
initial
situation.
F
Now
we
flip
the
roller
for
the
experiment,
prefix
and
one
observation
that
we've
made
is
that
there's
no
route
anymore
for
the
experiment,
prefix,
which
pretty
inclusively,
tells
us
that
the
vantage
point
must
be
filtering
just
for
completeness
sake
in
this
image,
we're
appearing
directly
at
the
vantage
point,
but
it's
also
this
also
works.
This
reasoning
also
works
if
we
appeal
with
any
other
router
and
a
si,
because
we're
trying
not
trying
to
figure
out
whether
a
specific
router
is
doing
Ralph
we're
trying
to
figure
out
if
in
a
SS
doing
this
somewhere.
F
So
the
reasoning
still
works
here.
The
other
type
of
observation
we
made
is
that
there
still
a
path,
but
it's
an
alternate
path
over
a
third,
a
s
in
this
case.
This
also
tells
us
that
it
must
be
filtering
going
on
the
vantage
point
or
in
the
a
s,
but
clearly
they're,
not
dropping
all
invalid
routes,
they're
doing
it
selectively.
So
this
is
something
we've
actually
observed.
One
explanation
for
this
might
be
naps.
F
A
SX
is
a
provider
of
a
si
and
the
policy
is
to
always
accept
anything
from
a
provider
but
filtering
ballots
from
a
peer
all
right,
so
the
other
type
of
situation,
the
more
common
type,
is
that
we
are
not
directly
appearing
with
the
vantage
point,
a
s,
so
we
have
at
least
one
a
s
in
between
us
and
again,
the
initial
situation
is
similar.
The
invented
point
adopts
the
same
route
or
ASX
for
both
prefixes
to
both
ballot.
Now
we
flip
the
raw
again
and
similar
as
before.
The
path
is
gone.
F
That's
one
observation
we
made
and
the
other
observation
similar
as
before
is
there's
an
alternate
path.
The
problem
that
we
have
now
is
that
this
introduces
ambiguity.
We
know
that
someone
must
be
filtering
based
on
ruff,
but
we
can't
tell
who
it
is.
It
must
be
a
turret,
a
si
or
a
is
X
or
it's
both
of
them.
So
this
is
the
problem.
The
question
is
now:
how
do
we
solve
this?
Because
this
is
quite
a
limiting
constraint
on
our
experiment?
Reach
writing
community
McNown.
F
Surveys
were
not
directly
appealing
with
so,
unfortunately,
the
solution
is
try
to
establish
direct
peering
with
demanded,
pontius
and
then
we're
back
to
the
first
type
of
situation
where
we
can
reliably
determine
whether
they're
filtering
or
not,
or
we
can
check
if
the
intermediate
is,
has
a
vantage
point
and
then
do
the
same
type
one
situation
again.
So
obviously
these
are
not
very
scalable
solutions,
but
this
is
a
problem
with
our
approach
for
TAS
that
we
can
measure
it's
reliable
results
for
those
that
are
too
far
away
from
us
yeah.
This
is
a
problem.
F
Okay,
so
now
on
to
results,
we've
been
doing
this
for
about
a
year
or
less
before
October
20th.
We
had
found
three
AAS
that
drop
in
Bella
droughts,
none
of
the
big
ones.
It
was
a
small
Italian
ISP.
There
was
a
small
ice
bias,
be
in
the
UK
and
it
was
a
touch
networking
initiative
and
then
October
20.
If
something
happened
at
em
sakes,
the
Antiques
Road
server
offers
a
feature
where
it
essentially
filters
out
in
Dublin
routes
for
its
peers.
F
If
you
so
choose-
and
this
is
been
opt-in
feature-
and
now
it's
not
out
feature,
they
changed
this
October
tray,
F
and
our
algorithm
picked
this
up
and
all
of
a
sudden
had
over
50
a
s
dead,
now
drop
in
Bella
routes
and
as
a
side
note,
I
mean
this
is
not
technically.
Das
have
not
deployed
rad
origin
validation.
This
is
a
route
server
doing
this
for
them,
but
a
route
service
is
transparent
on
the
bgp
level.
So
we're
technically
counting
this.
F
F
Unfortunately,
the
peering
test
bed
is
not
peering
at
these
exchange
points,
so
we
don't
have
to
reach
to
pick
that
up.
Fortunately,
it
is
peering
at
the
m6.
So
that's
why
we
saw
it.
We
also
know
of
at
least
one
major
European
hike
speed.
It
is
gearing
up
to
do
this
and
I'm
sure
those
order,
X
piece
as
well
so
yeah.
It
looks
like
it's
getting
traction.
F
Each
row
in
the
table
is
for
an
a
s
and
Renee
s
that
we
think
is
filtering,
involve
outs
in
some
capacity
we
updated
daily
and
for
each
is
you
can
click
on
details
on
the
left
and
then
you'll
see
which
vantage
points
were
actually
measuring
when
we
last
measured
them
when
we
would
ask
to
think
that
we're
filtering,
yeah
and
so
on,
so
I
just
will
appreciate
any
feedback
on
this.
So
if
you
have
an
a
yes,
that's
filtering,
that's
not
on
the
list.
F
F
This
is
a
work
in
progress.
We've
done,
one
national
campaign
on
the
data
plane
would
around
200
AAS.
We
have
found
none
additionally,
a
stat
filter.
This
also
might
be
oh,
that's.
We
have
the
problem
of
those
negatives
since
an
Aes
might
filter,
but
the
traceroute
still
goes
through
because
of
a
default
route.
So
there's
not
much.
We
can
do
about
that
at
least
not
at
scale.
So
this
is
just
something
we
have
to
live
with
alright.
So
now
to
conclude,
cruise
control
experiments
are
crucial
to
measuring
an
adoption
of
rough
based
filtering
policies.
F
F
A
C
A
Whether
or
not
people
performing
these
checks
or
not
I
was
wondering
in
cases
where
you
saw
the
checks
being
being
enforced.
Do
you
think
you
could
use
that
to
perhaps
detect
the
use
of
this
for
adverse
purposes?
Censorship
or
other
things,
I'm
reminded
of
Sharon's
work
on
the
use
of
potential
misuse
of
these
for
causing
routers
to
filter
or
drop
prefixes
if
they
might
otherwise
accept
you
think,
there's
a
your
tour
would
currently
support
that
kind
of
measurement,
or
I.
F
If
I
understand
correctly,
I
think
this
would
be
more
appropriate
to
do
on
a
on
the
RPK
level
to
actually
check
out
who's
being
revoked
and
who's
being
issued.
Certificates
and
I
mean
if
we
do
have
a
scenario
where
everyone
knows
rpki
everyone
drops
in
ballots
and
to
find
out
censorship.
I
think
it
would
be
easier
to
look
at
the
certificates
and
the
rawest
are
being
issued.
F
Fix
their
stuff,
that's
I
mean
we
already
in
a
metal
slide.
We
saw
the
reasons
why
people
don't
use
RP
care
and
I.
Think
one
easy
thing
would
be
if
people
just
started
to
not
mess
up
their
Ross,
because
right
now
is
a
negative
incentive
to
deployment,
because
if
you
filter
imbalance,
you
might
lose
connectivity
to
actually
look
for
them,
it's
a
SS
or
in
Japan
prefixes,
which
is
bad.
So
people
just
get
on
that.
There's
a
lot
of
lot
of
other
routes
that
really
shouldn't
be
in
well
did.
A
F
G
So
you
know
traditionally,
when
people
ask
about
rpki
I,
hear
people
saying
that
they're
not
going
to
validate
because
they're
nervous
about
invalids
that
are
incorrect,
and
if
you
look
at
like
the
NIST
rpki
Monitor,
you
see
some
fraction
of
the.
You
know
results
of
the
RPI,
causing
things
to
be
invalid.
That
shouldn't
really
be
invalid
and
I
always
thought
like
my
mental
model
was
like
people
are
not
going
to
drop
invalids
because
they're
afraid
that
they're
dropping
something
they
shouldn't,
because
it's
a
bug.
G
G
I
mean
we
know
that
the
RPI
sometimes
causes
things
to
become
invalid
when
they
shouldn't
do
to
misconfigurations,
and
this
was
preventing
people
from
turning
on
route
origin.
Verification
for
a
long
time
so
what's
happening
is
this
change?
Is
it's
no
longer
true?
People
no
longer
worried
about
this
I
think.
F
Just
to
worry
about
this
I
think
it's
getting
better,
I
mean
I,
think
over
time
or
the
kafir'
started.
There
was
a
larger
number
of
invalids
that
were
just
misconfigurations,
that's
been
going
down,
but
they're
still
there
so
I
think
it's
slowly
getting
better
and
more
more
people,
maybe
I'm
trying
to
they
can
make
the
leap.
One
additional
thing
that
prevents
people
I
think
is
also
the
implementations.
Some
of
them
aren't
that
good.
F
So
we've
tested
a
few
implementations
and
we
found
at
least
one
major
vendor
that
did
not
really
reevaluate
routes
when
they
changed
rpki
state.
So
if
we
went
from
our
to
invalid,
they
wouldn't
notice
that
and
you'd
have
to
withdraw
the
route
and
renounce,
and
then
they
were
get
it
and
later
on.
We
found
that
even
that
didn't
work.
We
had
a
case
where
we
would
announce
the
router
was
Ballads,
the
validation
would
say
valid.
Then
we
would
withdraw
de
route
change
the
Roar
to
make
the
route
invalid.
F
E
Who
compared
route
fuse
announcements
with
the
rpki
longitudinally
and
ran
the
actual
algorithms
and
found
many
of
the
quote
invalids,
get
overridden
by
more
specifics
or
whatever,
and
that
the
number
of
actual
invalids
that
would
be
dropped
is
very
small.
And
so
maybe
some
of
the
operators
accident
and
read
that
paper.
H
Job
Snider's
entity:
the
number
is
today
roughly
2200
prefixes.
It
is
indeed
small,
but
it's
not
small
enough
for
an
operator
like
NCT
to
enable
original
elevation.
So,
to
this
extent,
I
will
reach
out
to
the
RA
RS
and
ask
ripen
Aaron
to
you,
know
their
customers
and
members
saying
hey:
either:
delete
aurora
or
fixed
a
rollup
one
of
the
two.
So
I
hope
that
we
can
bring
down
this
number
to
a
more
acceptable
failure
rates.
Yeah.
A
I
What
lunches
in
the
adjacent
space,
if
you
have
not
registered
for
the
a
nrw
either
by
paying
or
paying
to
attend
a
ETF
and
register
via
blue
you,
then
the
lunch
is
not
for
you,
so
at
least
wait
20
minutes
and
then
go
and
see
if
there's
any
food
left.
Otherwise,
if
you
have
registered,
please
go
next
door
on
my
brunch.