►
From YouTube: Kubernetes Sig Node 20180213
Description
No description was provided for this meeting.
If this is YOUR meeting, an easy way to fix this is to add a description to your video, wherever mtngs.io found it (probably YouTube).
A
B
C
D
Didn't
have
a
chance
to
read
your
doc
last
night
and
it
it's
really
great
I
guess
I
was
just
when
I
understand
how
I
should
I
think
when
you
tweeted
about
this,
you
said
something
like
oh
I'm,
gonna
have
a
follow-on,
doc
and
I'm.
Just
curious
is
to
follow
on
how
you
want
to
support
privileged
sidecar
containers,
yeah.
A
Like
I've
had
a
lot
of
conversations
with
people
over
the
past
couple
months
ago,
you
know
every
you
know
a
lot
of
things
where
people
are
like.
We
want
this
and
here's
a
way
that
we
could
support
it.
Okay,
you
know,
there's
there's
existing
examples
of
this,
like
cryo
with
clear
containers,
and
you
know
frothy
and
the
work
that's
coming
down.
A
The
pipe
of
cotton
gears
and
I
started
to
see
ways
in
which
these
different
conversations
didn't
quite
line
up
and
that
there
were
kind
of
gaps,
and
so
I
was
saying:
let's
take
a
step
back
and
think
about
what
are
what
everything
that
we
need
to
consider
in,
or
you
know,
try
to
capture
everything
that
we
need
to
think
about.
Okay
and
then
the
next
step
is
to
say.
Okay,
now
we
can
say
what
is
a
solution
that
we
want
to
kind
of.
A
D
I
was
just
trying
to
think
through
when
reading
through
the
dockets,
sometimes
useful,
to
know
like
what
the
desired
end
state
is
and
I
was,
if
you,
if
you're
gonna,
summarize
it
now
like.
If
there
was
another
use
case
that
I
didn't
pick
up
on
that
was
beyond
privileged
sidecar
containers.
I
could
just
be
curious
if
you
could
hide
like
that.
A
I
guess
these
are
the
goals
of
this
document
and
I
think
the
piece
that
I
was
missing
was
sort
of
like
what
are
the
next
steps,
and
you
know
I
kind
of
threw
out
that
you
know,
and
this
isn't
the
solution,
that's
the
follow-up
but
kind
of
how
do
we
get
there,
but
for
everyone
who
hasn't
had
a
chance
to
read
through
this
yet
and
the
goals
that
I
laid
out
for
this
specific
document
were
to
try
and
define
the
actual
problems
that
we're
trying
to
address,
and
so
that's
these.
These
use
cases.
A
What
are
all
the
different
ways
in
which
we
might
want
something
that
is
harder:
isolation
boundary
than
what
we
have
today
kind
of
to
develop
a
common
understanding
and
so
that
we're
all
on
the
same
page
when
discussing
this
and
capture
you
know,
as
I
said,
I
had
a
lot
of
conversations
with
different
people
and
kind
of
different
groups.
Thinking
about
this
in
slightly
different
ways
and
to
try
and
get
all
of
that.
All
of
that,
together
in
one
place,
you
know
there's
the
like
identity
pieces
that
are
being
discussed
and
sig
off.
A
And
so
yeah
I
mean
how
the
in
the
next
section
is
trying
to
get
into
the
use
cases,
and
so
these
are
sort
of
the
the
categories
of
use
that
I
came
up
with
and
I
love
to
hear.
If
there
are,
if
there's
anything,
that
I
missed,
that
would
definitely
be
really
useful
to
know
and
then
trying
to
kind
of
think
out.
What
are
the
specific
requirements
for
each
of
these?
F
E
F
F
Right
all
right,
I
think
that
makes
sense.
Yeah
I'll
try
to
review
this
closer
yeah.
One
of
my
main
concerns
is
just
making
sure
that
we're
moving
to
a
model
where
we're
not
placing
dependencies
on
the
cubelet
that
are
implying
the
OS
of
either
that
the
host
or
the
actual
pod
that's
running.
Just
because
we're
seeing
cases
like
virtual
qubit,
you
know
like
Windows
hyper-v,
where
you
can
have
one
OS
managing
pods
for
another
sames
can
be
true
in
freebsd
as
well.
Yeah.
A
D
F
Guess
what
I'm
getting
at
is
I
could
see
there
being
a
node
that
can
run
pods
for
multiple
os's
one
implementation
of
that
could
be
the
virtual
cubelet,
which
you
know
itself
is
a
broker
that
can
that
can
go
talk
to
the
cloud
service
or
another
implementation
of
that
would
be
what
we've
done
on
Windows,
with
hyper-v,
where
I
can
manage
both
Windows
and
Linux
containers
on
the
same
machine.
Basically,
I've
got
like
a
multiple
kernel
scenario:
I
guess
similar.
D
To
like
the
multiple
container
runtime
snare
like
because
you
can't
showed
you
like
I,
guess,
I'm
wondering
if
we
don't
go
and
say
that
host
OS
differs
from
pot
OS
like.
Is
that
just
a
simplifying
assumption
that
pays
dividends
versus
taking
on
a
complicated,
a
more
complicated
units
case
that
may
not
express
the
same
rewards
globally?
I
guess.
G
Think
I
think
there's
a
consideration,
even
if
you
have
a
Linux,
Linux
workloads
running
as
strongly
isolated
virtual
machines,
for
example,
if
you,
if
we
look
at
stuff
like
DNS
and
IP
tables,
you
know
anytime,
you
configure
anything
in
that
space.
You've
got
to
go
and
configure
those
individually
in
each
one
of
those
in
each
one
of
those
pods,
because
anything
that
you
do
on
the
host
doesn't
impact
the
pods.
G
D
I,
just
worry
that
we're,
like
kind
of
loosely,
is
trying
to
reach
consensus
on
like
a
very
broad
concept
where
like,
if
we
said
more,
that
we
would
try
to
enable
a
solution
for
like
containers
as
they're
traditionally
understood
today
versus
I,
guess
the
VM
style
containers
that
are
being
evaluated
for
the
future.
I
guess
my
bias
is
that
we
get
containers
as
they're
understood
today,
commonly
across
linux,
hosts
like
working
well
first
and
not
try
to
complicate
the
use
case.
D
You
support
more
I,
don't
I,
don't
know
how
others
feel,
but
I
guess
I'm
too
concerned
that
this
will
be
so
much
like.
Does
a
qiblah
need
to
support
multiple
container
runtimes
discussion,
which
I
think
we've
you
could
have
done
and
we've
kind
of
steered
away
from
and
we've
also
discussed
in
the
past.
D
Like
can
you
run
multiple
cubelets
in
a
single
node
which
you
could
have
done,
but
we
also
chose
to
steer
away
from
for
simplifying
reasons
and
so
I,
just
I'm
I'm
sensitive
to
us
just
kind
of
tacitly
saying
yeah
we'll
take
on
this
use
case
without
at
least
asking.
Why
and
and
what
the?
What
the
benefit
is
I.
E
Think
we
had
a
meaty
baton
off
the
pocket
here.
I
I
think
that
what
are
the
team
proposed
here
it
is.
We
try
to
be
find
in
the
kubernetes
context,
what
it
is
the
sandbox
for
the
container
for
the
partner.
That's
the
language
existing
to
the
night
is
a
PID
can't
finish
this
one.
So
I
think
that
here's
the
what
tradition
it
is
one
of
those
we
already
know
the
container
is
the
faster
and
it
is
faster.
It
is
provide
much
more
utilization,
all
those
kind
of
things,
but
we
also
know
the
exist.
E
Linux
container
have
the
problem
for
the
set
create
here:
isolation
for
the
stronger
imagination
right
now,
people
just
looking
at
the
butcher,
animation
technology.
So
but
I
think
this
is
one
of
those
technology.
We
may
have
them
some
other
technology.
That's
the
implementation
detail
right
now.
We
just
try
to
define
what
it
is.
The
layer
lightest
and
the
box
layer
looks
nice.
What
is
that
mean
for
the
system?
Call?
What
is
that
mean
for
the
network
and
a
file
system
and
all
the
other
areas?
E
And-
and
so
there's
analogy,
I
think
we'll
mix
off
that
automatic
for
that
the
visualization
technology
in
Connecticut
also
is
emerging
right
now
is
because
when
it
is
for
the
ISO
nation
and
also
other
people
looking
at
it
is
the
front
different
angle.
So
some
people
it
is
looking
eye
to
the
water
ignition
technology
in
the
kubernetes,
is
because
application,
what
information,
but
it's
hard
to
some
open
occasion
to
happen
to
be
canonized.
Oh,
we
already,
and
also
some
people
nectar,
for
example,
that
the
Cuban
work
they
look
at
it
is.
E
We
already
have
an
existing
VM
feel
the
for
last
20
years,
or
maybe
even
more
than
that,
and
how
am
I
going
to
quickly
run
those
kind
of
things
that
just
know
how
we
run
those
VM
on
the
open
side
and
we
can
run
on
the
triple-deckers.
So
that's
kind
of
a
different
angle,
so
I
and
also
there's
the
people
say:
oh,
like
a
Microsoft
that
obviously
I'm
looking
like
Oh
our
have
the
Windows
Server
I'm
going
to
house
the
some
UNIX
application.
E
So
that's
a
different
angle:
I
think
we're
off
the
topic
up
a
little
bit
because
needs
focus
on
what
it
is,
the
security
isolation
issue.
We
try
to
resolve
them.
So
that's
the
truth,
the
more
that
is
a
common
container
and
also
FEMA
plan
which
I
to
address
there's
the
some
other
talks.
You
know
what
elate
also
came
to
the
signal
for
Thermo
before
and
then
they
are
more
step.
Okay,
I
have
them
already
happened
here,
I'm
going
to
run
those
beer
and
but
it
is
kind
of
mix
or
format.
It
is
I.
E
D
D
H
E
What
you
supinate
I'm
I
will
arguable
that
it
is
really
required
for
the
multiple
tendency.
There
are
the
many
many
design
or
many
different
approach
to
solve
that
problem,
and
even
that
matter
attendants
so
say
it
is
the
bigger
scope
and
it
should
be
it's
different
from
what
Pima
care
I
want.
You
recently
yeah.
A
I
disagree
that
this
is
off
topic.
I,
think
that
it
there's
an
interesting
question
of
you
know.
Should
we
include
this
use
case,
because
you
know
one
of
the
things
that
virtual
virtual
machines
can
do
is
run
different,
guest,
OSS
and
different
virtual
machines,
and
should
we
include
that
use
case
in
here
and
I
think
this
is
a
good
discussion
to
have
and
I
think
it
sounds
like
a
lot
of
people
and
I
would
agree.
I
think
that
this
should
be
at.
We
should
consider
this
out
of
scope.
A
I
I
agree:
it's
a
little
out
of
scope
that
realistically
just
just
to
add
some
context
and
this
realistically,
your
your
your
guest
OS
is
most
likely
not
gonna
run
the
same
as
the
host
I
mean
it's,
it's
just
the
realistic
use
case
that
that's
happening
today.
So
your
guest
OS
running
your
sandbox
is
running
a
different
West
and
Andy
host.
Oh
yeah,.
H
Okay,
I
can't
think
of
this
casing
some
multi-tenant
cloud
and
also
actually,
instead
of
different
hoping
a
system,
you
can
want
different
guest
kernels,
which
is
the
more
common
user
case.
We
have
example:
I
I
have
only
actually
you
were
covered,
which
requires
some
specific
kind
of
work.
So
I
can
write.
You
know
how
are
the
best
and
a
box
yeah
yeah.
That's
why
you're
the
case
I
can
see
it
here.
F
I
A
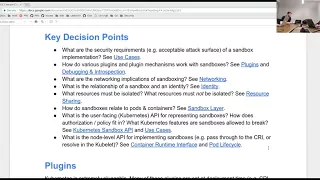
A
Yeah,
that's
a
great
question,
so
there
isn't
there's
sort
of
an
ordering
to
these
key
decision
points
and
I.
Actually,
Joe
I
put
them
in
the
order
that
the
doc
kind
of
addresses
these
but
I,
don't
necessarily
think
that's
the
order
that
they
need
to
be
answered
in
so
some
things
like
what
are
the
security
requirements
of
sandbox
implementation.
I
think
this
can
be
answered
much
later,
once
we've
sort
of
agreed
on
kind
of
what
are
the
higher
level
abstractions.
A
You
know,
let's
tackle
that
first
and
then
figure
out
the
rest
of
it
it's
kind
of
like
we
need
to
sort
of
answer
it
all
at
once,
which
is
kind
of
why
I
wrote
up
this
document,
because
I
was
finding
it
very
difficult
to
think
about
sort
of
these.
These
dependency
cycles
of,
like
you,
know,
well,
if
we
do
this
well,
then
we
need
to
do
this,
and
how
do
we
do
this?
So
do.
I
I
think
the
needle
s
pointed
they're,
not
level
API.
Basically,
the
question
being.
Do
we
have
do
we
support
multiples,
your
implementation
for
cubelets,
or
do
we
push
that
down
to
the
to
the
COI
implementation?
You
think
this
is
something
that
he
answered.
Kind
of
a
you
know.
What's
a
little
also
been
our
way
to
the
rest
of
the
of
the
question
here
or
is:
do
you
see
another
case
of
circular
dependency
here.
A
I,
actually,
don't
think
this
one
is
circular
I
think
that
I
feel
like
it
depends
on
this.
The
answer
to
the
sandbox
layer,
to
some
extent
I
mean.
Certainly
we
can't
define
an
a
you
know
what
this
year.I
extension
would
look
like
if
we
don't
know
what
the
sandbox
that
it's
describing
is
I
think
that
this
one
is
also
a
little
more
like
later
on
in
the
process,
around
implementation
of,
let's
figure
out
with
the
high
level
any
spectacle,
and
then
we
can
go
and.
D
I
guess
the
other
macro
question
I
had
Tim,
especially
in
the
sandbox
layer
front,
is
like
I
guess:
we'd
have
about
seven
layers
here
and
at
the
highest
level
you're
saying
we
only
trust
isolation
at
the
node
itself,
and
then
you
work
backwards.
I
guess
what
I'm
wondering
is
like.
Do
you
envision
certain
for
better
for
worse,
like
different
node
grouping
type?
That
would
be
pre-configured
to
support
particular
sandboxing
conventions?
D
I
guess
a
lot
of
the
settings
that
might
be
related
to
some
of
this
they're
like
container
runtime
wide,
like
even
we've,
talked
about
the
bug
container.
It's
like
you
have
to
go
and
enable
you
know
pit
namespacing
on
or
off
globally
and
I'm
wondering
if,
like
how
many
of
these
levels
of
sandboxing
one
might
want
to
achieve,
are
we
willing
to
say
they
achieve
by
having
to
support
different
node
types
and
look
through
those
know,
types
for
the
desired
isolation
you
want
so.
I
D
Some
of
these,
it
seems
like
we've,
already
had
to
go
and
like
in
the
pit
case
unless
I'm
mr.
Colin,
like
for
backward
compatibility,
stand
points.
We've
already
had
to
say
that,
like
it
might
not
be
the
same
everywhere,
but
I
feel
like
maybe
we're
already
boxed
in
having
to
support
more
than
one
dimension.
D
A
A
D
I
guess
that
wasn't
obvious
to
me
from
the
doc
that
you
were
going
to
invent
a
concept
of
a
sandbox
tearily
new
I
thought.
I
was
reading.
Moustakas,
basically
saying
you
know
what
level
of
isolation
is
provided
by
various
container
runtimes
today.
How
was
that
manifested
up
there
cube
and
then
just
kind
of
like
a
state
of
the
world,
but
I
was
not
envisioning
us
going
and
inventing
like
a
new
first
class
and
cons
to
the
sandbox
concept.
Mm-Hm,
maybe
I'm
not
aware
of
other
thoughts
you
might
have
had.
A
Yeah
I,
so
oh
I'll,
take
a
look
at
kind
of
how
I
can
clarify
that
here,
but
I
think
part
of
that
is
because
you
know
if
we
say
we're
gonna
sandbox
at
the
container.
It
could
just
be
a
flag
that
we
put
on
the
container
and
it's
it's
less
of
a
kind
of
like
totally
new
concept
versus
something
like
this.
D
B
E
Jesus,
do
you
guys
really
have
nectar
comes
in
about
a
set
of
her
container?
A
rain.
Tzedakah
container
has
the
privilege
and
industry
to
be
protective
for
the
rest
of
the
content
numbers
worth
wasting
of
health.
We
also
internal
internally
discussed
this
really
intense
and
we
don't
have
the
decision
yet,
and
we
also
don't
see
the
many
use
cases,
but
do
have
some
of
the
real
Rockets
people
prefer
have
that
one,
but
it's
not
that
the
common
thing
so.
A
Think
it's
kind
of
a
nice
to
have
as
opposed
to
a
hard
requirement.
So
sto
is
kind
of
the
one
case
that
I'm
most
familiar
with
in
the
case
of
you
know,
there's
an
init
container,
which
means
to
have
privileged
host
access
in
order
to
set
up
the
initial
firewall
rules.
But
then
the
sidecar
proxy
doesn't
need
those
same
privileges
and
also
the
credentials
that
are
in
the
sidecar
are
kind
of
the
credentials
that
are
owned
by
that
pods
identity.
There
aren't
any
secrets
that
the
other
containers
really
shouldn't
have
access
to.
A
So
it's
not
it's
I,
wouldn't
say
it's
a
hard
requirement
in
that
case,
but
it
is
sort
of
a
nice
to
have
because
you
know,
maybe
you
have
a
policy
that
all
of
your
you
know.
Workloads
are,
you
know,
built
internally
and
now
you
want
to
run
sto
and
you're
taking
in
this
kind
of
like
third-party
code,
and
you
want
to
separate
it
from
your
your
user
data
kind
of.
So
that's
where
some
of
those
kind
of
like
nice
to
have
you
system
in
I
mean.
D
To
answer
your
question:
Don
yeah
I,
don't
think
we
have
a
clear
answer,
but
our
default
option,
as
always
to
not
have
users
run
privileged
and
so
I
think
I
really
appreciate
what
Tim
is
identifying
here.
So
it
can.
We
can
have
those
discussions
with
the
various
service
mesh
activities
that
are
happening
to
see.
If
we
can
box
things
are
properly
but
like
right
now
it
would
be
a
blocker
for
us
to
assume
that
everyone
is
is
deploying
with
a
privileged
in
it
container.
Yes,.
E
A
D
D
We've
evaluated
that
so
we've
we've
explored
options
where
you
have
like
a
daemon
set
running
on
any
node
that
can
do,
builds
and
then
doing
some
cross
pod
coordination
where
that
daemon
SEC
knows
that
it
can
go
and
commit
the
image
on
your
behalf.
So
we
like
explored
that
route,
but
we
have
a
number
of
routes,
I'm
sure.
If
we
wanted
to
reach
out
to
Clayton,
he
could
give
us
product
pointers
to
Docs
I
can't
find
easily
on
on
the
routes
that
we
have
explored.
D
E
D
J
A
One
thing
I
want
to
mention
on
the
use
cases
I
was
trying.
I
was
listening
kind
of
like
every
use
case
that
we
might
want
to
solve.
It's
not
necessarily
the
case
that
we're
going
to
decide
that
actually
we're
going
to
come
up
with
a
solution
that
addresses
every
one
of
these,
so,
for
instance,
I
think
it's
still
to
some
degree
an
open
question
of
whether
we
want
to
support
the
isolated
sidecar
use
case.
I
I
It's
so
sorry,
I
mean,
as
a
user
I
can
I
can
understand
what
what
a
pod
is,
but
when,
when
I,
when
I
choose
to
put
it
in
in
a
sandbox,
what
I
mean?
What
is
what?
What
does
that?
What
is
that
going
to
mean
in
terms
of
isolation,
because
you
we're
saying
that
we
don't
want
to
tied
that
to
any
kind
of
specific
technology
but
I'm
when
I,
when
I
select
put
mine
when
I
choose
to
put
mine,
my
part
in
the
sandbox
as
the
user?
Why?
A
Yes,
so
that's
what
I
was
trying
to
get
out
with
this
first
decision
point
of,
like
you
know
like
what
you're
just
saying
like
the
user
says:
yes,
I
want
this
workload
to
be
sandbox.
What
does
that
actually
mean
like
what
are
the
guarantees
that
they
get
from
that?
And
what
is
you
know
has
you
know
they
have
to
go?
Read
the
documentation
of
Adak
containers
or
you
know,
whatever
the
backing
technology
is
yeah
I
see
that
as
an
open
question.
It's
you
know
when
I
started
on
this
project.
A
I
A
E
Another
request:
a
front
plan
of
service
folks,
so
in
general
they
want
everything
things
it
is
running.
It
is
the
center
box
there,
so
we
we,
we
also
need
to
say.
Oh,
that's
me
is
that
the
long
term
things
or
it's
just
any
week,
whoever
to
run
the
service
things
they
want
you
to
focus
out
so
I'll
pop
that
in
for
sediment.
A
Yeah
yeah,
so
I
could
see
that,
like
it's
a
little
more
until
they
like
kubernetes
as
a
service
or
containers
as
a
service
of
use.
Cases
of
you
know
suppose
we
now
want
to
say
that,
like
everywhere
cloud
or
every
user
workload
has,
as
in
a
sandbox
and
I,
see
that
as
kind
of
actually
outside
of
the
scope
of
this
and
more
in,
like
you
know
something
that
would
get
added
to
the
pot
security
policy
or
some
other
policy
or
admission
controller.
That
says
you
know
anything
from
you
know.
A
So
I
think
that
they
should
have
to
make
that
decision.
I
think
that
you
could
set
up
again
something
like
cloud
security
policy
where
you
say
you
know
the
the
cluster
admin
says
you
know
I
or
you
know
your
security
teams
like
makes
that
decision,
that
everything
should
be
sandbox
and
they
set
that
as
a
default
for
something
in
a
cloud
security
policy.
I
do
think
that
there
are
enough
wait.
What
I
was
saying
earlier,
like
a
sandbox
workload,
is
going
to
behave
differently
enough
from
a
regular
container.
A
That
I
think
this
needs
to
be
an
explicit
thing
in
the
config
file.
You
know
there
might
be
there
might
be
performance
considerations
there,
probably
we're
not
going
to
support
every
kind
of
resource
sharing
mechanism
that
is
supported
today,
and
so
there
will
be
some
kind
of
things
that
that
break
I.
Think
I
call
that
as
one
of
these.
A
E
I
So
that's
I
think
we
they're
there
to
use
cases
and
and
for
example,
when
we,
when
we
integrate
cata
containers
with
far
away
we
have
to.
We
basically
support
two
use
cases
where,
by
default,
you're
gonna
have
all
your
work
run
in
a
sandbox,
but
we
also
want
to
let
the
user
decide
and
specifically
annotate
the
part
two
to
enable
that
sandbox,
because
a
steam
was
saying
there
are
some
limitation
and
also
some
some
overhead
of
running
your
workload
in
the
sandbox.
So
I
mean
it's
to
me
there.
F
A
H
H
Yep,
okay,
so
yeah.
Now
this
this
documentation
is
basically
full
of
teams
work
so,
which
is
most
basically
for
hypervisor
best
sandbox
I
will
use
kata
example
here
so
because
obvious
that
it
is
the
most
complex
example
here
and
this
documentation
will
actually
collect
the
existing
or
proposed
ways
to
integrate
cut
harvest
current
content
of
runtime
interface.
H
So
I
would
like
to
give
it
a
summary
and
to
do
a
brief
introduction
and
to
do
an
evaluation
about
the
advantages
and
disadvantages
and
I
think
there
should
be
some
a
requirements
when
talking
about
and
talking
about
the
this
integration
integration
solutions,
for
example,
we
we
hoped
we
have
easy
installation.
We
hope
the
user
can
make
choices
as
they
wish
and
they
should
be
able
to
mix
the
round.
There
trusted
and
untrusted
workload
on
state
machines.
They
when
they're
large,
and
we
should
not.
H
We
should
never
want
to
break
any
existing
critical
features
and
the
network
storage
should
work.
So
these
are
always
options
we
want
to
have,
and
the
first
integration
options
I
can
see
in
the
unit
count
could
make
kubernetes
communities.
You
know
handle
the
kurdistan
box
in
a
crib
level.
Yeah,
that's
the
option.
It's
kind
of
like
the
crew
blade
will
acting,
will
act
as
water
of
the
CIA
GPA
and
we
both
call
and
make
a
decision
to
to
standard
a
request
to
Congress
on
the
implementation.
H
No
matters
cut
her
or
he
is
coming
on
time,
so
it
should
be
able
to
first
of
all
to
understand
the
acquirement
from
user.
For
example,
we
need
to
have
a
so
called
particular
runtime
claim.
It
can
be
some
kind
of
annotation
or
version
fitting
in
past
bake
and
besides,
that,
the
equivalent
should
be
able
to
allocate
this
GPR
request.
As
your
RPC
request,
based
on
some
the
imparted
privilege,
configuration
I,
think
Sam.
You
also
mentioned
it
before.
H
For
example,
a
party
required
a
host
network
which
cannot
be
handling
how
to
write
the
best
data
box.
They
should
be
automatically
redirect
to
the
neediest,
come
to
the
runtime
like
cryo
or
container
D.
So,
basically
there.
These
are
all
responsibilities,
are
creating
the
group
like
a
job
in
this
in
this
solution
and
the
current
status
of
this
solution
community
is
that
the
crew
blade
is
now
ready
for
it
because
could
not
understand
the
concept
of
secure
country,
runtime
or
hypervisor
best
one
time
and
that
any
other
Linux
container
run
communications
like
cryo
container.
H
The
darker
rocket
are
already
able
to
support
in
the
containers
for
a
long
time,
and
the
frankly
is
the
only
implementation
based
on
CI
to
support
wrongly
and
cut
out
stuff,
but
we
need
to
upgrading
it
to
using
kata
best
today,
you
still
in
the
wrong
way,
but
it's
not.
It
will
not
be
big
copy
problem.
So
this
is
the
current
status
option.
H
A
the
option:
option
B
I
can
see
here
quite
similar
to
auction
a,
but
there
are
a
lot
of
things
which
can
be
handled
actually
by
Osei
parks,
and
this
solution
has
been
proposed
by
marine
tastes.
People
I
think
it
means
they're
gonna
meeting
some
sometime
I,
remember
that.
So
this
is
basically
that
we
can
have
a
you
still
have
crew
plate
here,
but
we
don't
even
change
it.
We
will
set
up
a
CI
proxy
here
before
in
front
of
the
cotta
containers.
H
H
The
privileged
configuration
it's
quite
similar
to
cooperate
a
bit
just
to
move
all
in
all
this
work
to
the
CI
proxy
side
and
the
current
state
hosted
here
in
the
community
is
here
so
basically
the
crew
Brady
ready
you
don't
need
to
change
it
and
Frank
T
and
all
other
Linux
container
runtimes
are
ready
to
support
that
and
the
marina's
people
have
a
quite
a
similar
that
I
parks,
the
implementation,
but
I
mean
I.
Think
we
need
to
maybe
change
someone
it.
But
again
it's
doing
this
and
I.
H
Think
Laurentiis
is
also
using
this
CI
practicing
their
horse
solution.
I
mean
they
work,
work,
work
related
things
and
the
third
option
I
can
also
see
here,
which
has
also
been
proposed
in
the
community,
is
about
how
to
you
know
how
to
handle
these
kind
of
things
in
the
Linux
granham
layer,
and
in
this
case
the
runtime
implementations
like
Rio
or
container
D,
should
should
call
the
card
container
binary
just
like
what
they
did
for
run
C.
H
So,
basically,
those
all
of
the
latest
content
runtimes
we'll
have
to
run
times
at
least
and
and
again
for
Gong,
for
example,
cryo
content.
It
should
also
be
able
to
allocate
the
request
to
to
make
decision
where
it
should
call
the
run,
C
or
cut
containers
based
on
annotations
or
participate
or,
as
I
said,
based
on
the
parties.
Village
configuration
yeah,
it's
still
hard
to
miss,
don't
have
to
do
the
onion,
and
also
we
need
to
make
sure
that
this
is
configurable.
H
For
example,
it
was
there
to
use
kata
or
run
C
to
handle
the
the
users
were
called
by
default.
So
the
current
status
of
this
option
in
the
communities
is
that
equivalent
already
because
we
do
not
exchange
it
and
the
cradle
has
already
some
integration
work,
arrays,
clear
container,
but
again
we
need
to
change
it
to
use
kana
in
future
and
all
the
other
needs
container
runtimes,
including
content.
The
rocket
dog
here
are
not
ready
for
it,
so
we
need
to
do
some
work,
for
we
need
to
do
some
work.
H
I
can
see
that
they
are
already
proposal
in
continuity.
For
example,
I
also
did
a
briefing
evaluation
about
all
this
work,
for
example,
and
let's
go
to
the
option:
a
I
mean
the
crew
blade
level
first.
In
this
way,
I
can
see
some
advantages.
Like
the
you
know,
you
know
to
make
any
change
to
the
existing
Linux
container
one
times.
I
creo
container
get
our
hierarchy.
They
can
they
can
because
criminals
will
handle
the
it
has.
H
They
touched
the
it
hot
stuff
work
and
there
will
also
be
a
impedance,
the
ice
cream
for
cut
hug
because
it
may
actually
bring
us
me
some
benefits
like
it
will
have
a
dependable,
it's
really
really
cycle
and
it
has
its
own
tests
news.
Only
implementation,
CI
implementation,
so
will
be
more
flexibility
for
cut
among
containers,
and
there
is
no
extra
maintenance
effort
for
other
needs,
content
runtimes
near
and
equivalent.
In
this
case
it
aware
of
the
exist.
H
The
issue
of
using
persistent
volume
in
cotta,
because
today
I
had
why
the
best
container
adverse
to
know
IO
performance
with
persistent
valley
because
they
have
to
use
an
IP
FST's
to
do
fail,
sharing
because
hide
while
the
best
data
box
cannot
do
bad
month.
This
is
actually
a
very
important
problem
we
have
to
solve
and
if
we
have
a
state
freaky
I
extreme
for
caja,
we
actually
can
figures
fix
this
problem
more
easily,
because
basically,
we
can
use
a
customized
volume
plug-in
to
do
that.
H
So
we
have
already
implemented
a
flexible
in
plugin
for
extender
and
a
Google
Cloud
and
in
future
we
have
also
proposed
these
things
to
CSI.
So
hopefully
we
can
use
a
standardized
I
plug
into
to
support
that.
So
in
this
case
this
this
plug-in
very
simple.
We
just
escaped
the
face
of
the
persister
wall
in
plugging,
and
then
we
mount
a
block
device
directly
to
kaha,
so
everything
is
solved
and
but
but
again
we
also
can
see.
H
Some
disadvantages
of
solving
is
probably
in
crib,
really
well
the
most
important
being
an
intimation
fury
that
we
change
related
I.
It
should
know
multiple
can
turn
around.
They
surely
have
rate
you
to
stay
out
both
cattle
can't
around
how
I
want
to
use
for
sakura-con
the
runtime
right.
So
we
have
to
solve
this
problem
and
it
is
not
determined
yet
how
to
do
that,
and
also
it
has
image
image
map
to
the
Container
image
manager
complicit
here
here,
a
shoe
has
given
a
very
detailed
explanation
about.
H
What's
the
problem,
it's
basically
like
now
you
have
multiple
container
runtimes.
Then
then
every
one
candidate
runtime
has
its
own
image
management
solution.
So
how
can
you
integrate
them
together?
How
can
I
least,
for
example,
all
the
available
dark
container
images
which
actually
coming
from
two
different
CI
a--
shames?
We
should
solve
that
problem
and
is
it's
not
very
easy
because
there's
some
inconsistent
problem
here
I
can
see
and
also
we
need
to
maintain
multiple
CI
streams
in
a
community.
H
For
example,
you
have
you
have
to
maintain
frank,
T
and
cryo,
and
at
least
there
you
can
use
to.
I
only
can
use
secure,
can
I
run
high
wave
frankly,
and
usually
this
content
around
time-based
cryo.
So
you
have
to
do
that,
and
I
also
can
see
some
resourcing
finish.
The
problem
only
node,
because
basically
we
have
to
G
RPC
service
running
on
the
same
machine.
Sammy
also
mentioned
it.
The
other
thread,
I
I,
agree
with
him
that
there
should
be
some
problem
here.
H
I
mean
basically,
we
have
to
actually
service
to
handle
all
the
requests.
So
let's
go
to
the
solution.
Solution
B,
which
is
actually
saw
this
probably
incredible,
but
we
will
use
this
the
I
proxy
to
handle
it.
You
can
see
here
because
we
still
don't
need
to
touch
any
existing
units
contain
run
times
and
we've
also.
H
We
will
also
have
this
independence,
the
extreme
for
kata,
so
we
will
basically
have
one
the
the
first
three
prongs
of
option
a
here,
and
we
will
have
also
have
also
some
extra
benefits
like
again
we're
doing
it
with
this.
In
this
time
we
do
not
need
to
modify
crew
blades
at
all,
because
we
have
mean
now
we
have
a
CI
proxy
to
handle
this.
H
The
I
request
application,
and
also
in
this
solution,
the
CI
runtimes
like
Rio
and
contrary
now
can
be
installed
by
a
demon
state,
because
couplet
only
need
to
connect
to
the
foxie,
so
we
can't
employ
any
bank
and
the
ice
creams
in
gimmick
set,
which
is
very
easy.
I
also
can
see
some
disadvantages
here,
because
the
the
first
a
wall
we
need
to
do
is
that
we
need
to
maintain
as
the
I
proxy
stuck
no
matter
hitting
crew
blade
or
even
a
stapler,
the
repo
we
have
to.
H
We
have
to
do
that
and
again,
the
Seahawks
will
be
responsible
to
maintain
container
to
run
time
information,
no
matter
how
you
can
have
a
cache
information.
You
can
help
how
you
can
have
some
higher
key
information
either
cutting
the
you
know,
idea
of
the
container
like
that,
but
we
need
to
mentally
account.
Information
and
I
can
I
can
now
see.
There
are
at
least
the
two
solutions
in
the
community,
and
they
were
also
nutriment.
H
Em
in
this
case
was
the
only
to
maintain
multiple
CI
extremes
in
a
community,
for
example,
cata,
for
example,
as
the
ice
cream
for
cat
house.
Yes,
dear,
shame
for
Ron
see
at
least,
and
this
and
again
he
will
still
have
the
resource.
Infinity,
probably
know
the
automation
before,
and
we
still
have
the
image
management
companies
to
here,
but
it's
a
little
bit
easier
to
solve,
because
now
we
have
say
our
proxy,
so
we
can
do
everything
everyone
cleanest
their
products.
H
They
don't
need
to
high
cloud
in
the
crew
blades,
so
it's
a
little
bit
easier
than
the
option
80.
But
still
again
we
still
have
this
problem
and
the
lobster
see
the
option
see
here
that
we
can
integrate
cutter
in
totally
a
cia-run
ham,
shimla
well
I,
mean
example:
integrate
kata
equal
and
integrate
integrate
content
container
B.
H
That
should
be
option,
and
then
in
this
case
we
don't
need
to
change
kool-aid
at
all
and
we
would
have
better
resource
intensive
tree
in
a
node,
because
we
only
have
one
G,
OPC
server
can
order
request
and
it
should
be
easier
to
install,
because
basically,
we
have
only
one
CI
shame
here.
We
can
make
a
unified
package
and
unify
the
installation.
H
Documentation,
right
and
I
can
also
see
some
disadvantages
when
using
this
solution,
for
example,
the
most
most
most
important
thing
and
information
I
mean
the
it's
also
the
concern
for
me
and
at
the
runtime
and
Tanner
that
we
have
to
change
all
existence,
the
I
run
times
no
matter
container
do
cryo.
If
we
want
to
integrate
it
to
any
existing
ingots
can
here
on
time,
we
have
to
change
our
code,
it's
an
automation.
H
What
about
getting
the
new
container
you
see,
I
am
enti
dreams,
new
implementation,
I
know,
Alibaba,
is
have
is
doing
their
own
work
and
also
some
profits.
The
I
run
time
seeing
enterprises
they
they
have
their
own
solution.
How
can
we
integrate
cut
out
to
do
them
right
and
those
it's
not
kind
of
not
friend
friendly
to
run
times
other
than
cry
out,
and
the
continuity,
for
example,
rocket?
Who
will
do
this
kind
of
work?
How
can
work
in
people
with
the
color?
H
He
did
not
know
details
about
kata,
so
whenever
there's
issue
or
bug
or
problem
here
and
take
her
to
come
to
find
it
cut
her
people
to
sorry,
it
is
a
really
painful,
because
now
you
have
to
actually
handle
requests
coming
from
different
in
its
kind
of
run
time,
including
CI,
including
choir
and
and
container
decreased,
and
it
also
need
to
set
up
a
two
different
end-to-end
test.
Being
this
Linux
container
runtime,
for
example,
you
have
to
have
different
tests
for
Carter
even
contrary
that
that
also
need
extra
maintenance.
H
Here,
especially
when
we
have
this
er
testing
policy,
which
Yugi
has
proposed
to
be
posted
these
days.
We
would
have
this
checked
and
then
to
test
to
any
content
runtime.
So
we
have
to
do
this
work
in
one
CI
extreme
for
to
run
hands.
It's
actually
a
lot
of
work
and
even
cut
a
container
runtimes
maintained
errs
have
to
stop
her
from
this
extra
burden.
Here
and
again,
we
have
to
maintain
container
to
run
home
information
in
the
CI
a--,
shame
side,
no
matter
in
cryo
or
in
Kentucky.
We
have
to
maintain
that
color
information.
H
We
have
make
sure
the
end
of
the
be
partly
the
documentation
here
so
again.
In
this
case,
we
still
have
problem
to
in
to
solve
their
persistent
while
in
public
here,
because
we
have
to
ship
a
solution
to
every
country
around
animation
here
and
we
can
have
some
work
run,
but
it's
basically
depending
on
what
code
cuddle
old
kind
of
a
graph
driver
we
are
using
here
so
yeah,
I
least
all
all
of
the
information
in
this
in
this
table.
You
can
check
the
existing
state
hers
and
these
two
managers,
the
manager,
is
here
yeah.