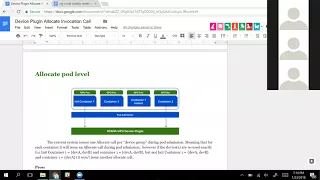
►
From YouTube: Kubernetes SIG Node 20180123
Description
Meeting Agenda:
https://docs.google.com/document/d/1j3vrG6BgE0hUDs2e-1ZUegKN4W4Adb1B6oJ6j-4kyPU
B
C
C
And
we
would
basically
and
because
of
the
new
init
container
behavior,
we
would
basically
say
we
have
this
group
of
devices
that's
assigned
to
in
a
container
one.
So
in
this
case
you
pupil,
we
issue
and
allocate
call
and
then
I'd
array
over
the
rest
of
the
the
next
containers.
If
we
see
that
container
one
uses
GPU
food,
then
because
we've
already
issued
an
an
opaque
call,
we
don't
issue
it
again
and
if
we
see
another
container
that
uses
a
device
a
GPU
device,
we
would
issue
an
alcohol
for
that
container
in
that
device.
C
And-
and
so
if
that
was
clear
to
you
and
if
that
wasn't
very
clear
to
you,
the
device,
the
document
describes
it
a
bit
more.
So
that
had
a
few
pros,
because
the
elkay
core
is
issued
during
put
admission.
So
that
means
that
if
the
device
per
unit
becomes
unavailable
for
some
reason
at
some
point
during
the
life
cycle,
for
example,
it
container
restarts.
C
We
don't
need
to
issue
another
llk
call
because
we're
basically
caching,
the
runtime
information,
that's
being
communicated
from
the
device
going
to
the
couplets
and
we
reinjected
to
the
container.
So
we're
check
by
doing
that
information
and
if
the
device
button
is
not
available,
then
we'll
we
don't
we
don't
care
because
we
already
had
an
information.
C
So
that
means
that
the
only
problem
that
might
happen
is
device
clogging
is
not
available
during
correct
mission,
and
in
that
case
we
can
just
reject
at
a
part,
and
the
problem
is
that
won't.
The
first
problem
is
that,
basically,
that's
not
a
really
good
model,
because
that
means
that
we
can't
really
issue
any
device
specific
instructions
for,
in
our
case,
for
the
nvidia
gpus,
we
can't
reset
the
state.
We
can't
catch
errors
that
so,
for
example,
let's
say
your
container
restarts
and
it
put
the
device
in
a
bad
state.
We
can't
the
nvidia
device.
C
Well,
you
cannot
try
to
fix
that
where
you
cannot
try
a
simple
example
would
be
that
say:
you
have
a
tensorflow
job
allocates
a
lot
of
memory
so
for
some
reason
the
software
crashes
and
puts
and
the
trigger
to
driver
the
Nvidia
driver
could
not
reclaim
the
memory.
And
if,
because
we
don't
have
can't
eggs,
we
can
reset
the
device
when
your
container
is
going
to
be
saw.
It
is
not
going
to
be
able
to
allocate
any
more
memory
and
you're
just
containers
just
going
to
crash
loop.
C
C
The
points
are
more
about
the
fact
that
the
model
has
some
limitations
and,
as
we
were
actually
talking
with
some
of
the
Red
Hat,
people
that
are
using
vfi
or
I
was
talking
with
them,
and
the
FIO
and
hypervisors
I.
Don't
know
if
they're
here
today,
and
they
mentioned
that
the
allocate
behavior
might
also
be
the
current
allocate
behavior
might
also
be
a
limitation
for
them.
But
they
mentioned
that
they
will
have
to
actually
comment
on
that
on
the
PR
to
confirm
that.
So.
A
Has
someone
unrest?
What's
the
limitation
or
can't
I
located
so
I
understand
English
DP
the
GPU
support
cases
and
so
kind
the
kind
allocation
it
is
only
down
on
the
setup
stage
you
for
the
powder.
So
all
the
container
is
that
there
is
no
no
allocation,
so
you
won't
have
the
have
the
way
to
solve
this
problem
because
due
to
the
limited
model
and
ended
the
potential
of
the
propertied
memory,
all
those
kind
of
things,
so
you
just
mention
that
in
the
in
the
openshift
already
had
the
using
the
eye.
E
C
D
C
A
A
C
C
To
answer
the
first
question
and
I
think
we
would
still
have
a
per
pod
allocate
call,
but
it
wouldn't
be.
The
model
that
we
currently
have,
and
mostly
because
we're
still
going
to
need,
is
some
kind
of
call
in
the
future
when
we
start
handling
new
man
technology.
But
the
idea
would
still
to
have
some
kind
of
your
PC
call
that
you
could
start
you
could
that
would
be
in
votes
out
of
container
so.
A
C
E
E
Him
and
I
think
it
has
been
used
by
the
VDS
packing
to
do
certain
container,
so
we
actually
want
to
learn
like
whether
there
is
any
plan
to
support
this
idea,
because
if
we
do
have
such
plan
basically
have
two
ways
to
to
do
certain
configuration
than
the
we
need
to
think
about
what
functionality
should
be
performed
of
it.
The
priest
at
who
can
perform
this
rule
the
best
parking
API
so.
C
To
give
you
more
context,
the
way
the
Nvidia
device
plug-in
works
is
we're
not
truly
requiring
your
now
to
install
the
Nvidia
drivers
and
to
install
Nvidia
dollar.
Could
we
NVIDIA
docker
is
a
docker
run
time?
What
it
does
is
really
it
just
repackage
when
C
and
adds
this
single
line
of
code.
That
says
add
pre-start
book
so
currently,
when
you're
using
the
device
Gorgon.
What
it
does
is
for
every
image.
If
for
every
image,
that
is
being
run.
C
C
F
A
G
Can
I
can
speak
to
that?
It's
official
here
we
do
need
changes
at
the
CRA
level.
The
idea
is
the
idea
that
I
proposed
earlier
was
that
we
can
have
an
exit,
call
between
create
and
start
of
a
container,
at
which
point
you
can
get
into
the
sandbox
and
do
whatever
changes
you
want,
but
in
this
context
I
mean
I
personally
feel
that
the
the
exact
model
or
the
the
pre-start
hook
model
is
better
suited
for
changes
being
made
in
the
container
sandbox.
Not
necessarily
outside.
G
The
topic
of
discussion
here
is
about
managing
devices
which
is
supposed
to
be
in
the
purview
of
device
plugins
themselves,
so
I
think
I
mean,
maybe
maybe
maybe
we
can
just
explore
that
option.
First
before
before,
like
diving,
deeper
into
pre-start
hooks,
it's
just
like
a
little
bit
more
difficult
because.
C
There's
two
things
here
then:
the
individual
specific
operations
that
we
need
to
execute
when
you're
in
a
data
center
and
you
actually
have
to
scrub
the
memory
for
security
reasons
or
just
research
fill
device,
because
it's
in
a
bad
States
and
there's
the
Lib
Nvidia
container
part
where
we're
actually
and
setting
up
the
container
so
that
it
can
run
GPU
images
or
it
can
access
the
different
GPU
future,
such
as
MPs
and
MPI
and
or
just
OpenGL
images,
or
even
just
normal
interest,
such
as
CUDA.
In
deep
burning
images.
Yeah.
G
I
have
the
same
question
as
Derek,
with
having
a
same
discussion
of
trying
to
yesterday.
In
that
it
feels
like
we
have
two
separate
stages.
One
is
allocate,
which
is
meant
to
like
just
reserved
a
bunch
of
devices
for
a
given
pod
and
in
the
second
phase
is
like
initialize
or
something
like
that,
which
is
like
trying
to
prepare
the
device
for
for
comes
maybe
at
the
container
boundary
on
a
two-part
boundary.
But
any
case
like
that
seems
to
be
two
separate
operations.
Alakay.
G
But
again
like
lets
us
not
combine
all
these
things
together,
they're
distinct
stages
and
if
you're
saying
that
there
is
no
necessity
for
having
a
special
allocate
call
because
of
the
fact
that
cubelet
actually
performs
allocation
and
there's
nothing
else
to
do
on
the
device
plug
inside
then
I
mean
that's
a
fact
and
let's
just
need
it
there,
and
then
that
is
the
nest
needs
or
initializing,
which
is
what
you
are
raising
now
its
colonization.
And
then
there
is
a
separate
need
for
running
priest
at
hooks.
B
G
So
that's
a
possibility
like
there
across
the
Seine.
The
the
thing
that
I'm,
not
sure
yet
is
like
crowd,
was
saying.
Is
there
a
need
for
an
allocate
call
like
if
the
device
plugin
is
not
going
to
do
anything
with
allocate
crawl
and
if
all
its
intelligence
is
only
in
analyze,
call
then
do
we
even
need
it,
and
at
least.
C
And
they
use
we're
actually
use
when
they
use
we're
making
of
the
is
to
tell
our
pre-start
hook
what
devices
to
expose
in
the
container
and
that's
something
that
we
do
need
at
least
and
at
the
elite
level.
And
there
is
as
as
you
as
you
mentioned,
the
initialize
part.
But
and
maybe
that's
it.
That's
something
that
could
be
solved
by
using
this
pre-start
pre-start
and
sending
the
devices.
C
C
E
C
Trying
to
find
API
boundaries
so
that
your
you
don't
use
the
container
pre-start
hook
to
do.
Everything
and
I
also
think
that
from
what
I
remember,
reading
the
sources
and
device
operations
might
take
sometimes
depending
on
depending
on
what
operations
we
want
to
execute
and
when
we
want
to
execute
them
and
if
I
remember
correctly,
the
CRI
time
time
out
for
an
operation
is
usually
two
minutes
and
you
can
actually
set
that
up.
But
I
don't
want
the
CRI
time
out
to
be
depending
on
the
device
you
have
any
node.
That's.
E
A
Feel
there
are
not,
it
is
just
try
to
see
what
it
is.
The
scope
and
II
need
she
owner
their
scope
and
also,
if
your
boundary,
so
so,
so
that
the
us
planning
actually
understand
what
is
high
positive
s.
It
is
handle.
So
it's
more
like,
for
example,
just
take
a
single
example.
Time
out.
Venue
is
more
understand
like
how
much
they
need
for
initializations
the
sea-ice
generica
api
and
two.
It
is
for
the
to
run
an
operation
in
the
container
context.
So
it
is
maybe
we
if
we
override
that
kind
of
things
it's
done.
A
G
I
mean
I
just
feel
like.
Let's
just
not
talk
about
preset
hooks
at
this
point
because,
like
even
if
we
add
a
pre
start
hook
between
create
and
start
in
the
CRI
hypothetically
speaking,
the
timeouts
further
could
be
larger
or
longer
I
mean
so
it's
I
feel
like
that's
a
separate
conversation
to
be
had.
Let's
just
like
I
mean
it
will
be
easier
for
us.
If
you
restrict
this
conversation
to
to
whether
we
need
we
need
an
additional
means
in
the
device
plug-in
API
that
will
enable
us
to
perform
per
container
operations.
C
It
could
take
from
30
seconds
to
10
minutes,
and
maybe
that's
a
discussion
that
we
want
to
have.
Is
that
maybe
we
want
to
have
that
test.
The
ten-minute
tests
sometime
to
happen,
drink
called
admission
or
at
the
puddle,
and
we
would
only
won't
have,
for
example,
memory
memory
scrubbing
at
GPU,
restart
memory,
checking,
etc
or
faster
operations
at
container
initialisation.
That
way,
yeah.
G
G
E
I
think
they
are
open
to
consider
to
make
this
a
configurable.
Behavior
is
the
rule
the
best
packing
API,
so
you
would
best
pack
in
some
give
us
packing
says:
I
need
to
have
this
continual
operation
car.
Then
they
can
set
this
up
during
the
initial
registration
and
we
will
trigger
this,
and
we
will
also
clarify
in
the
document
and
I,
come
what
kind
of
operations
of
a
inspect
that
he
was
plugin
to
perform
during
how
the
christian
was.
E
E
A
A
D
On
demine,
if
we
just
this
was
a
thirty
second
agreement,
we
had
discussed
adding
annotations
into
the
as
a
pass-through
down
to
the
device
plug-in
API,
which
has
a
PR
number
open,
I.
Think
I
was
in
favor
of
the
change.
It
seemed
like
most.
Everyone
else
disappear.
The
change
I
want
to
make
sure
that
there
were
no
other
disagreements
with
a
I.
Can.
A
F
G
E
G
I
mean
the
reason
I
brought,
that
up
is
because
I
mean
I've
been
working.
Another
assumption
all
along
that
one
of
the
other
key
abilities
with
bikes
plugins
that
we
get
is
that
it's
going
to
be
one
time
agnostic,
so
I
just
hope
that
we
don't
paint
ourselves
in
a
corner
where
we
have
a
matrix
of
of
runtimes
and
plugins
and
and
and
like.
Oh,
is
this
chosen
and
then
then
becomes
really
hard
for
users
to
consume
the
world.
So.
C
I
think
this
is
one
of
the
key
disagreements
we've
had
is
that
it's
Spidey
by
default,
it's
not
runtime
agnostic,
we're
trying
to
have
a
single
shared
library
that
would
allow
us
to
at
least
have
some
kind
of
library
underlying
that
would
be
coming
for
all
run
clients.
But
by
default
it's
it's
going
to
be
very
dependent
on
what
your
runtime
does.
G
D
A
Can
because
that
he
is
the
owner
and
also
in
this
quarter
next
quarter
he
is
going
to
in
charge
of
the
CI
production
and
work
and
also
rule
out
the
plans.
So
he
so
she
is
have
the
most
to
say
on
that
API.
So
I
think
we
should
so
so
we
make
that
least
general
cost,
and
it's
okay.
So
then
we
can
solve
that
off.
Nine
last.
E
C
E
C
D
I
guess
either's
fine,
so
this
was
a
topic
that
I
think
Peter
port
on
today
is
on
the
call
from
Red
Hat.
So
I
guess
Peter.
Do
you
want
to
summarize
the
challenges
we
were
facing
and
this
is
more
of
a
thought
exercise
to
see
if
others
from
the
community
having
the
same
problem
and
then,
if,
if
people
have
a
particular
preference
towards
a
solution
direction
so
Peter,
can
you
summarize
what
we
discussed
yesterday
sure.
H
We
would
like
to
be
able
to
collect
logs
and
be
sure
we
have
me
if
you
will
coordinate
or
the
location
the
logs
came
from
as
metadata
collected
with
those
logs
without
doing
any
additional
API
calls
to
kubernetes
to
get
that
data.
So
today,
if
I
want
to
know
where
a
log
comes
from
and
and
I
could
be
mistaken
by
the
way,
because
I'm
looking
at
we're
working
with
openshift,
3,
7
and
3/8,
which
is
not
the
latest
kubernetes.
H
H
You
don't
know
it's
it's
UUID,
and
so,
if
I
later
need
to
disambiguate
across
namespaces,
using
any
historical
records
in
the
logs
and
I
have
any
changes
to
namespaces
that
have
happened
over
time.
Where
a
namespace
case
reviews,
I,
potentially,
will
have
an
overlap
or
I
won't
be
able
to
disambiguate
the
by
namespace
and
UID.
H
That's
or
that
issue
is
posted,
which
is
host
name
container
UUID
and
same
at
the
time
pod.
You
UID,
and
it's
been
at
the
time
and
namespace
your
idea,
enhanced
and
at
the
time
and
I
believe
today
we're
missing
namespace
UID
in
that
metadata.
If
we
had
that,
then
we
can
collect
this
data.
The
logs
without
any
other
api's
calls
me
to
enrich
and
still
have
all
the
proper
location
information
for
logs.
Does
that
make
sense.
D
So
I
guess,
generally
speaking
like
we
want
to
make
sure
that
things
are
unique
across
space
and
time
and
obviously
Peter
did
a
good
job
describing
the
namespace
side.
The
challenge
I'm,
trying
to
reason
through
I'm,
just
curious
with
people's
perspectives
on
is
what
the
right
way
of
fixing
this
is
like
a
daily.
D
It
seems
like
Peter
wants
it
to
make
it
that
the
path
that
we
log
out
to
includes
that
identifying
information
and
and
that's
one
option,
and
if
we,
if
we
all
agree
that
that
is
approach
we
could
take
like
yeah,
there's
a
there's,
a
compatibility
problem
in
restaurant
too,
but
then
also
generally
speaking
like
do
we
want
the
cubelet
to
have
to
be
looking
this
up,
or
should
we
start
pursuing
a
path
with
sig
ap
machinery
so
that
on
object
meta,
you
always
have
the
namespace.
You
would
present
next
to
the
namespace
name.
D
I
Really
specific
issue:
listen!
This
has
been
there
since
the
beginning,
actually,
the
way
that
described
in
the
issue
right
now
that
looks
more
like
the
original
old
path.
Now
the
new
CI
path
in
the
new
CI
path.
We
have
the
pod
UID,
actually
a
directory
name,
and
but
we
don't
have
the
container
ID
anymore,
because
we
create
a
long
tag
before
even
creating
the
container.
So
chocolate
has
no
way
to
know
what
ID
runtime
is
going
to
assign
to
that
container.
So
yeah,
it's
a
mix
of.
H
Uniquely
identifies
that
pod,
but
that
if
the
thought
process
is
not
about
the
time
at
which
the
logs
happen,
it's
what
do
you
do
with
the
logs
after
you've
collected
them?
So,
for
instance,
if
I
am
looking
at,
you
know
the
mornings
logs
at
8:00
p.m.
at
night
and
during
the
day,
multiple
changes
have
happened
where
people
created
namespaces
using
the
same
they're
allowed
to
then
when
I
collect
those
logs
in
the
morning
and
I'm
just
looking
at
them
in
the
evening.
H
H
You
can
also
for
the
case
of
multi-tenancy,
where
someone
does
multi-tenancy
on
a
namespace,
then
the
namespace
UID
can't
help
you
differentiate
the
logs
across
the
tenancy,
and
then
you
have
the
potential
to
leak
logs
across
multi-tenancy
domains.
So
so,
in
this
spirit,
if
you,
if
you
get,
if
you
just
do
pod
UID,
which
is
okay
to
know
that
all
logs
came
from
a
given
pod,
it
doesn't
help
you
with
the
larger
forensics
or
the
larger
correlations
you
might
want
to
make
beyond
that
in
history.
H
So,
obviously,
at
the
time
you
can
make
the
argument
that
well
just
the
API
calls
and
find
out
what
the
UID
and,
at
that
point
in
time
you
you
know
what
to
go.
Do,
however,
even
there
it's
hard,
because
if
I
only
have
a
pod,
UUID
I
need
to
still
somehow
find
out
the
pod
names.
Do
any
queries
about
the
hard
metadata
right
and
I
can't
do
a
query
by
UUID
that
I'm
that
I'm,
aware
of
and
once
I
get
the
hard
metadata
I
only
have
the
namespace
name.
H
I
A
So
the
big
constant,
obviously
I'm,
talking
agree
with
what
Peter
and
I
I
Pro
this
approach.
The
big
concern
is
just
backward
compatibility,
so
we
need
to
first
to
solve
this
kind
of
things
to
say
what
it
is.
Is
there
any
risk
caused
by
being
in
fear
for
our
customers
right
because
kubernetes
in
production,
many
places.
D
A
We
need
to
stop
that
one
first
and
at
the
same
time,
I
think
this
is
actually
it
is,
may
need
to
change
some
API
or
maybe
well
yeah.
We
want
to
human,
it
do
some
dirty
work
and
Cori.
Those
kind
of
things
ended
before
the
read
to
the
disk.
All
those
kinds
of
things
is
in
a
decent
detailed
can
discuss
after
we
saw.
I
Ci
iPad
and
there's
your
links
for
the
old
paths
which
we
actually
use
today
so
enjoying
the
new
ones
safer,
but
doing
the
transition
from
the
old
to
the
new
CI
path
with
ya
will
happen.
Issues
you
mentioned,
but
anyway,
we'll
have
will
run
into
those
issues.
So
it's
better
that
we
just
come
up
with
repetitive
I
long
path.
Right
now
before
we
do
a
transition.
D
J
Well,
currently,
not
stats
are
being
used
for
for
policy
storage
policy
enforcement
of
the
notes,
because
cubelet
is
managing
this
shade
storage
on
the
nodes
and
also
for
affections
for
somebody,
stats,
API
is,
and
things
like
that
and
most
most
importantly,
its
use
of
the
container
level.
So
we
would
need
container
level
locks
launched
at
and
so
currently
for
top
see
a
twice
and
collects
water
container
stats.
J
So
it's
a
different
port
path,
but
for
CRI
star,
the
lock
stat
collection
is
of
the
pod
level
so
like
like
the
lock
path,
is
garlic
pods
and
then
the
pod
uid,
with
with
the
continuum
of
the
instance.
So
it
is
specific,
large
file
name.
So
with
this
there
is
there's
no
way
for
us
to
monitor
the
lot
static
because
we
are
aggregating.
We
are
pointing,
like
some
of
the
runtimes
appointing
the
pod
directory
for
monitoring
the
logs,
so.
J
In
our
summary,
MPI
is
monitoring
pipeline
and
again
eviction
strategies,
and
things
like
that.
So
we
wanted
to
make
a
small
proposal
on
what
the
options
begin.
What
are
the
options
we
can
pursue
and
option?
One
being
like,
we
can
point
this
year
twice
or
230
point
to
the
lock
at
the
container
log
file
itself.
This
will
be
like
more
easier
workaround,
but
this
might
be
temporary
because
we
have
the
log
rotation
coming
in
this
release.
J
So
the
second
option,
which
I
think
is,
which
is
also
a
preferred
option,
is
to
create
sub
directories
per
container
and
cubelet
can
point
this
Keyblade
sets
this,
creates
this
directory
subdirectory
under
the
pods
or
directory,
and
then
points
that
to
see
adviser
to
collect
the
stats
so
a
container.
So
if
there
is
lot
of
rotation,
the
locks
lock
files
are
created
within
the
sub
directory.
D
J
Also
depends
on
how
long
we
plan
to
support
C
advisor
integration
for
collecting
the
stats
so
with
option.
3
is
the
container
runtimes
themselves
support
locks
that
collection
container
atoms
may
not
be
able
to
may
not
be
aware
of
the
logger
rotation.
That
happens
because
logger
tation
will
be
done
by
cubelet,
but
we
need
to
have
some
capability
to
familiar
at
times
to
integrate.
What
see
advisor
are
be
able
to
give
out
the
stat
results
for
the
logs
per
container
and.
J
Redundant
work
because,
given
the
fact
that
all
the
see
other
end
times
pretty
much
have
a
standard
log
format,
so
it
it
might
just
be
read
and
work
to
implement
these
in
each
each
of
the
runtimes
abstraction
is
accumulated
itself
monitors
the
log
stats,
because
cubelet
is
a
lot
rotation
as
well.
So
it's
is
probably
the
logic
might
be
better
suited
in
the
cubed
itself.
The
monitor
the
container
log
stats
logs
to
generate
the
stats
for
it.
So
it's
up
to
the
people
like
if
there
is
any
opinions
or
options.
I
Nineteen
lock
rotation
is
still
in
discussion,
so
I
pasted
the
link
of
evaluation
and
proposal
in
the
meeting
notes.
So
basically
we
do
want
to
finalize
lock
rotation
for
this
quarter,
and
this
is
a
doctor
summarizing
different
options
and
I
did
pick
one
solution
at
the
end,
so
feel
free,
I,
don't
think
we're
going
to
details
about
the
stuck
today
so
feel
free
just
to
come
in
on
it.
F
A
I
F
A
B
K
I
H
A
K
B
A
D
A
C
I
K
J
K
I
L
Pretty
common
request
among
new
users,
like
it's
kind
of
the
two
trade-off
slits
you're,
either
generating
log
output
that
you
expect
to
be
meaningful
and
in
the
absence
of
info
we
expect
log
output
to
be
meaningful,
or
you
know
that
it's
not
meaningful
and
you're
willing
to
trade
it
in
order
to
get
availability.
It's
a
pretty
fundamental
choice:
I'm,
not
sure
that
we
are
always
able
to
make
that
decision,
that
excuse
level,
every
consumer
and
so
giving
the
choice.
You
know
at
a
pod
or
container
or
whatever
level
does
make
sense
in
the
long
run.
H
L
I
A
We
were
actually
run
of
time,
so
we
have
the
two
topical
way
within
our
three
topical
actually
doing
hoc
hour
and
so
so
I
believe.
There's
the
also
the
windows
container
resource
management.
Today
they
come
back.
In
the
last
week
we
gave
some
high-level
suggestion
and
I
believe
they
revised
that
one
and
we
should
do
this,
is
they
came
back
to
ask
a
full
review
and
from
the
signal
community
and
another
one
Terk?
We
are
going
to
reschedule
your
you're
discussing
about
the
new
remedy
system,
yeah.
D
That's
fine
I
guess
when
I
was
interested
on
that
one
as
if
I
wanted
to
assuming
we
had
agreement,
start
the
process
to
get
a
repository,
that
some
engineers
could
start
delivering
code
and
design
documents
to
and
so
I
guess
I
can
do
that
in
the
in
the
interim.
If
we,
if
we
have
no
disagreement
on
having
a
a
incubated
pair
to
the
node
problem,
detector,
essentially
yeah.