►
From YouTube: 20200924 SIG Architecture Community Meeting
Description
No description was provided for this meeting.
If this is YOUR meeting, an easy way to fix this is to add a description to your video, wherever mtngs.io found it (probably YouTube).
A
All
right,
hello,
everybody!
This
is
the
kubernetes
architecture
meeting
for
september
24th.
Thank
you
all
for
coming.
Please
remember
our
code
of
conduct
and
treat
each
other
with
respect
and
kindness,
and
today
we
have
just
a
couple
things
on
the
agenda:
we'll
start
with
a
presentation
from
open
cruise
and
then
we
have
a
discussion
over
female
containers
and
then
some
project
readout
for
performance.
A
B
B
B
B
So
for
that
we
are
doing
the
due
diligence
I
reached
out
to
sick
abs
in
the
stephen
committee,
and
the
student
committee
said
that
I
should
come
here
to
the
sick
architecture
first,
and
I
hope
that
after
this
meeting
would
hopefully
we
don't
have
to
go
to
a
steering
committee
again
and
we
can
just
reach
to
the
agreement
on
where
this
project
should
sit
on.
On
monday,
the
past
monday,
I
had
a
meeting
with
sick
abs
already
and
we've
had
the
agreement
on
where
it
should
be
in
their
opinion.
B
So
now
this
time,
I'm
here
to
gather
your
professional
opinion
as
to
where
this
project
should
sit
so
a
little
background
about
open
crews.
So
we
alibaba
cloud
we
have
kubernetes
offerings
both
for
the
external
customers
and
for
internal
customers,
meaning
that
our
large
e-commerce
website
actually
is
running
on
top
of
our
kubernetes
cluster.
B
B
So,
in
terms
of
the
cruise
workload
management
controllers,
there
are
currently
five
of
them
and
we
plan
to
add
a
new
one,
but
we'll
see
so
the
beginning
of
all.
These
came
from
people
who
are
complaining
about
staples
that
what
they're
doing
update
it
takes
very
long
time,
because
it's
doing
this
one
by
one
and
they
wanted
to
have
in
place
update,
meaning
that
they
want
to
bypass
the
api
service,
and
we
implemented
that
and
then
they're
saying.
B
B
Basically,
it's
used
to
manage
side
cars
like
you,
have
monitoring,
logging
side,
cars
and
it's
a
centralized
place
to
manage
those
side,
cars
and
it's
going
to
inject
the
side,
cars
and
it's
going
to
update
the
side
cars
using
using
the
in-place
update.
I
mean
that
you
don't
have
to
restart
the
row
out
of
of
your
workloads
once
you
have
a
new
version
of
the
sidecar
and
we
have
united
deployment.
B
This
is
a
use
case
when
you
have
your
cluster
is
crossing
different
data
centers
and
you
want
to
make
them
into
different
zones
like
in
aws.
They
have
a
name
availability
zone,
we
call
them
subsets
so,
but
this
is
like
segregating
your
whole
deployment
or
your
cluster
into
different
zones
and
manage
pausing
different
subsets.
B
B
So
that's
basically
the
the
the
current
status
or
the
design
of
what
we
have
so
a
couple
of
things
I
think
stood
out
in
the
cncf
presentation
with
why
they
were
because
it's
a
closed
door
discussion.
So
I
didn't
know
why.
But
I
was
wondering
why
they
are.
They
are
having
these
questions,
and
one
of
them,
I
think,
is
that
the
the
names
right
you
have
advanced
devil
said
and
they
with
on
unified
deployment,
and
they
think
it's
probably
a
fork
of
of
the
upstream
code.
B
So
we
don't
fork
upstream
code
because
we
basically
design
all
those
features
from
scratch.
So
we're
not
adding
a
wrapper
on
top
of
like
deployment
or
replica
set.
We
just
yeah,
so
we
use
the
atomic
part
and-
and
we
are
not
forking
the
the
logic
and
also
in
terms
of
use
cases
we
are
complementing
like
these
features,
are
more
useful
for
large-scale
production
uses
like
if
you
have
10
or
20
parts.
B
So
we,
these
features
are
mainly
designed
for
large-scale
production
users,
but
that
being
said,
even
though
it
is
being
used,
I
think
we
are
still
under
active
development,
especially
clone
set
and
other
new
new
controllers.
That's
being
discussed
right
now,
and
also
the
the
operator
part
of
it.
So
here
is
a
more
detailed,
more
detailed
example
on
the
film
set
like
it
has
different
types
of
update
strategies
available
and
things
like
maximum
available
max
search
and
stuff.
B
B
All
the
others
probably
don't
have
that
many
many
features
because
they
were
not
actively
developed
like
advanced
staple
set.
We
I
think
we
are
fixing
bugs,
but
we
are
not
adding
new
features
to
it,
but
the
concept
we
are
still
adding
new
features.
Another
another
example
would
be
sidecar
set.
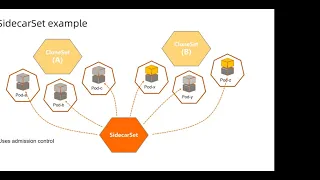
Sidecar
set
is
centralized
place
to
manage
all
the
sidecars
in
your
in
your
deployment,
so
it
uses
a
mission
control.
B
It
decouples
your
workload
from
the
from
the
side
cars,
so
you
don't
have
to
worry
about
them
and
also,
even
though,
in
this
diagram
we
say
clone
side,
it
also
works
on
deployment
or
other
standard
kubernetes
upstream
workload.
So
basically,
these
things
can
be
used
with
with
each
other
or
they
can
be
used
with
kubernetes
upstream
workload,
management
as
well
like
they
are
not
conflicting,
each
other
that
that's
for
sure.
Like
you,
you
install
these
controllers.
You
can
still
use
deployments
and
and
stifle
sets,
that's
not
a
problem.
B
So
it's
not
that
either
all
situation
as
well.
So,
like
I
said,
it's
complementing
the
features
and
I
think
that's
pretty
much
the
typical
things
that
I
would
like
to
introduce.
The
other
three
controllers
are
pretty
straightforward,
like
they
serve
single
purposes,
and
they
are
mostly
already
done
in
terms
of
development
and
feature
requests,
so
that's
not
much
to
talk
about,
but
they
are
useful
to
certain
use
cases,
so
we
hope
to
include
them
all
into
into
these
this
open
source
project
on
open
cruise.
So
that's
my
presentation.
B
A
A
But
you
know
certainly
from
a
sort
of
architectural
standpoint.
Different
workload
controllers
are
within
project.
They
don't
need
to
be
in
the
kubernetes
project.
You
can
either
certainly
create
your
own
instead
of
workflow
controllers
that
do
whatever
you
want
and
have
your
own
projects
do
whatever
it
is,
but
if
you're
interested
in
that,
then
you
know
that's
talking
to
speak
out.
Just
sounds
like
you
did,
it
would
be.
That
would
be
where
they
would
live
within
this
project.
A
You
know
not
talking
specifically
about
tactical
marriage
or
lack
of
I
don't
know
enough
about
it,
but
certainly
from
a
scope
perspective,
which
is
kind
of
what
I
would
think
would
be
interested
in.
It's
an
appropriate
set
of
projects
instead
of
controllers,
because
the
gaps
has
the
capacity
in
the.
A
C
C
I
think
there's
actually
a
couple
of
concerns
in
what
you
were
showing
like
the
idea
of
sidecar
as
a
resource
is
interesting,
independent
from
the
workloads
concepts,
there's
some
things
that
seem
like
they
would
be
generally
useful
features
and
like
why
doesn't
deployment
have
them?
I
don't
know
what
I
really
want
to
avoid
is
a
situation
where
users
have
to
sort
of
go
shopping,
for
which
workload
controller
is
right
for
them
like.
C
B
B
Controllers,
yes,
I
agree.
So
there
are
a
couple
of
things
one
like
I
said
there
are
like
certain
things:
that's
for
for
large
production
use
cases,
especially
talking
about
things
like
in
place,
update
where
you
kind
of
like
you,
you
bypass
the
api
server
right.
So
what
happens?
Is
it's
not
a
generic
use
case?
It's
really
in
the
it's
meant
for
a
control
environment,
where
you
know
what
you're
doing,
because
you're
not
getting
a
new
node
you're,
not
getting
allocated
new
resources
right.
B
The
purpose
of
going
through
on
the
the
apa
server
is
that
the
scheduler
would
assign
you
basically
destroy
and
create
a
new
part
for
you
and,
for
example,
you
you
have
totally
different
cpu
or
memory
usage
in
different
versions,
and
you
should
avoid
using
in
place
update,
but
in
production
environment
in
a
controlled
environment.
I
know
what
I'm
doing.
I
know
the
differences
in
these
images
and
I
can
make
a
nice
judgment
call
basically
saying
okay,
I
would
like
to
take
the
risk,
because
I
know
it's
not
gonna.
B
B
I
want
to
say
experiment
because
they
are
they're
already
in
use,
but
they
are
still
under
going
active,
active
development
there.
The
release
cycles
are
way
faster
than
more
frequent
than
than
the
upstream
really
cycles
in
terms
of
features,
I
would
feel
more
comfortable
of
merging
them,
like
the
merging
the
majority
of
them
after
it's
more
mature
like
right
now,
I
see
a
couple
features
that
can
be
donated
to
you
on
to
to
upstream
on,
like
the
ones
we
already
have
frozen
development
on
and
they
have
been
tested
for
a
while.
B
B
C
Oh
yeah,
sorry,
for
me,
the
audio
is
really
bad
on
the
receiving
end
too
so
andy.
I
heard
what
you're
saying
and
I
didn't
mean
to
start
a
side
conversation.
Maybe
at
this
point
we
should
take
it
back
to
mailing
list
and
and
discuss
the
like
the
path
forward
like
what
do
we
ultimately
want
and
what's
preventing
us
from
getting
there.
B
That
makes
sense,
yeah
and
also
yeah,
so
also,
I
would
like
to
confirm
that
I
think
this
will
be
the
like.
The
last
sake
that
I
need
to
go
to
before
on
going
back
to
cncf
and
and
hand
over
our
verdict,
because
I
think
steering
committee
would
have
only
like
meeting
once
a
month.
So
I'm
not
sure
that's
a
proper,
proper
form
for
such
discussions.
E
B
F
A
As
far
as
your
donation
to
cmcf
versus
kubernetes,
I
would
take
it
wholesale.
You
know
it's
really
going
to
be
up
to
the
apps.
I
would
say
I'm
curious
how
that
conversation
went,
but
it's
certainly
another
approach
is
to
be
an
independent
project
and
then
take
your
features
back
one
at
a
time
as
tim
is
suggesting,
but
it
really
comes
down
to
apps
can
accept
that
additional
commitment
to
support
and
develop
these
that's
my
opinion.
B
Thank
you.
I
think
sig
apps
were
saying
the
same
thing.
Basically,
so
they
suggested
that
we
stay
as
a
separate
project
for
them
keep
up
streaming
back
once
certain
features
are
available
or
one
that
when
the
upstream
is
actually
looking
for
those
features,
then
it's
a
good
time
to
contribute
back
and
eventually
be
absorbed
to
the
part
that
there's
going
to
be
huge
differences.
B
But
I
think
there
are
a
lot
of
common
use.
Cases
that
can
be
can
be
contributed
back
to
upstream,
and
we
certainly
do
want
to
have
to
have
our
workloads
or
our
code
be
part
of
the
official
release
of
kubernetes.
That
will
be
ideal.
It's
just
right
now.
We,
our
features,
are
still
under
development,
and
we
don't
have
much
we.
We
are
not
sure
about
how
these
things
will
go
eventually
or
will
look
like
eventually
after
runs
of
testings
by
by
the
community.
A
C
H
So
I
do
have
some
specific
questions,
but
I
thought
I
might
start
with
a
sort
of
a
brief
reminder
of
what
ephemeral
containers
are
and
how
they
work.
So
ephemeral
containers
are
it's
a
it's
an
alpha
feature
that
allows
adding
containers
to
a
pod.
That's
already
running.
It's
intended
for
troubleshooting
for
interactive
troubleshooting
of
things
like
distro-less
containers,
where
you
might
not
have
a
shell
ephemeral
containers
have
have
many
restrictions
above
normal
containers.
They
things
like,
they
don't
have
guaranteed
resources.
H
H
Nope,
okay
cool,
so
I
wanted
to
talk
about
a
couple
of
issues
that
were
a
bit
contentious
when
we
first
started
started
discussing
ephemeral
containers
years
ago
and
those
are
specifically
the
ability
to
remove
ephemeral
containers
right
now.
You
can
only
add
them.
You
cannot
change
or
remove
them
and
the
ability
of
configuring
a
security
context.
H
These
sort
of
these
weren't
fundamental
features
for
necessary
for
to
get
the
to
get
the
feature
started,
but
they
are
our
most
common.
Their
most
popular
feature
requests
now,
so
I've
written
up
an
update
to
the
cap,
which
I've
linked
in
the
meeting
notes
and
I'd
like
to
get
some
more
more
eyes
on
it.
H
So,
for
example,
I
I
just
learned
that
yesterday
that
I
should
not
be
building
on
top
of
pod
security
policy,
so
I
need
to
go
back
and
revise
the
kept
and
to
not
do
that,
but
but
I
would
like
to
be
able
to
make
these
two
things
configurable,
somehow
on
a
cluster
basis,
so
I'm
not
familiar
with
config
architecture.
I
I
don't
know:
do
we
it's
discussing
caps
and
update
the
caps,
something
that
we
do
here.
H
H
Okay,
so
the
main
architectural
input.
I
think
I
think
the
strongest
guidance
that
I've
gotten
so
far
was
for
us
from
the
api,
and
we
may
want
to
chat
about
the
api
with
some
experts
to
see
if
we
want
to
change
anything
before
graduating
to
beta.
But
these
two
specific
things
they're
sort
of
far-reaching.
H
H
C
Sorry,
like
there's,
there's
a
lot
of
audio
issues
going
on
okay.
I
I
paid
close
attention
to
this
at
the
very
beginning
and
then
it
seemed
like
it
was
under
control,
and
so
I
shifted
to
other
things,
and
I
haven't
really
come
back
to
it.
If
you
think
it's
useful,
I'm
happy
to
discuss
it
to
talk
about
what
the
bumps
are
that
you're
currently
experiencing
from
the
sort
of
api
point
of
view.
If
you
just
want
to
to
talk
with
somebody
from
from
this
group,.
H
H
H
Production
readiness
questions
great
yeah,
okay,
so
that
was
the
other
thing
that
I
wanted
to
discuss
with.
Is
I
get
some
feedback
through
through
github
issues,
but
but
not
a
lot,
so
I
don't
know.
I
would
like
to
be
able
to
get
more
feedback
and
more
opinions
from
the
community
about
whether
we're
you
know
we're
ready
to
to
move
to
beta,
whether
it's
something
that
we
we
want
to
pursue,
but
it
sounds
like
maybe
production
readiness
is
a
venue
to
do
that.
C
Production
readiness
is
definitely
something
that
we
should
pay
extra
attention
to.
I
think
I
believe
this
falls
into
the
case
of
everybody
who
wants
it,
but
it's
complicated
enough
that
few
people
are
able
to
make
the
time
to
think
about
it.
Deeply
enough.
I
don't
think
it's.
I
don't
think
you
should
interpret
silence
as
people
don't
want
this
or
aren't
excited
by
it,
mostly
as
everybody
looks
at
it
and
says,
oh,
my
god,
that's
complicated.
I
don't
have
time.
H
H
H
D
It's
actually
a
pool,
we
moved
neighborhoods
this
week
and
I
haven't
yet
figured
out
a
place
to
work
this
bright
and
early
in
the
morning.
So
here
we
are
I'm
going
to
share
my
screen,
but
I
am
not
able
to
yet.
Can
I
get
the
permissions
to
do
so
and
momento
some
exciting
stuff
on
the
way
we
will.
Finally,
as
cigarch
own,
a
release
blocking
job
as
soon
as
the
process
is
complete,
we're
definitely
kicking
it
off.
D
D
Anything
new
that
occurs
during
a
release
cycle
and
we
can
see
that
there's
a
entire
new
category
called
internal
api
server,
which
is
mainly
an
alpha,
but
whenever
we
enable
that
from
the
generated,
swagger
json
that
ends
up
in
the
kubernetes
repository,
which
is
our
source
of
truth.
Currently,
we
can
talk
about
whether
that's
the
right
source,
truth
or
not.
It
becomes
something
that
we
need
to
filter
out
as
either
writing
a
test
for
or
putting
in
our
list
of
endpoints.
D
D
D
We
can
see
that
this
has
a
list
of
all
those
new
internal
api
server
endpoints,
but
if
we
back
out
all
the
way
to
here
and
go
to
stable
and
this
stable
api
endpoint
is,
is
currently
not
tested
and
not
performance
tested,
I
think
we're
likely
just
going
to
create
a.
I
want
to
get
a
little
bit
of
feedback
on
the
process
for
what
happens
when
we
have
promotions
to
ga
that
are
pretty
normal.
Like
you're
gonna
anytime,
we
get
a
new
api
group.
D
We're
gonna
need
to
get
that
api
group
and
that's
part
of
the
stable,
but
that's
on
a
as
far
as
when
we
do
our
spinning
up
to
generate
the
swagger
json.
I
think
it's
part
of
the
release
process,
where
we
spin
up
an
api
server
with
all
alpha
and
beta
api
endpoints
enabled
and
do
a
quick
query
to
the
living
swagger
json,
endpoint
and
dump
it
into
the
kubernetes
repository.
D
D
It
listed
the
currently
untested
endpoints
and
returns
non-zero
so
that
the
job
fails,
and
this
is
where
we
will
get
an
email
notifying,
currently
our
team
and
then
I'd
love
to
get
some
feedback
on
where
that
should
go
longer
term.
Whether
we
create
a
conformance
mailing
list
that
interacts
with
sig
release
to
ensure
that
the
responsible
party
for
or
sig
for
creating
those
new
endpoints
covers
their
own
debt
before
the
release
is
made
or
they
have
to
revert
those
promotions.
E
D
D
D
As
I
continue
on,
we
saw
a
great
increase
in
our
conformance
in
in
1019,
and
we
have
a
little
conformance
progress
area
where
you
see
how
far
we've
we've
come.
The
the
red
stuff
is
not
always
our
team
completely,
but
but
pretty
much,
and
then
the
blue
light
blue
area
is
stuff,
that's
new
endpoints
that
were
promoted
with
tests
and
so
we're
looking
forward
to
those
being
completely
taken
over
and
be
the
only
way
to
get
new
endpoints
in
by
the
time
we
get
rid
of
that
gray
area.
D
We
have
cleared
all
debt
back
to
115.
yay,
so
there
used
to
be
gray
areas
here.
This
is
coverage
by
release
current
to
see.
What's
the
race
we've
erased,
it
all
the
way,
we're
working
on
this
114
area.
If
you
look
up
here,
you
can
see
we
had.
We
used
to
have
endpoints
up
here
this
one
here
now
we're
working
on
this
114
to
clear
it
all
back
to
the
beginning,
exciting
and
watch
on.
The
call
is
actually
one
of
the
few
people
who's
contributed.
That's
not
on
the
team!
D
D
So
if
you're
interested
in
what
our
specific
milestones
are
as
far
as
the
velocity
that
we
have
or
the
steps
that
we're
taking,
please
take
a
look
at
the
what
we
did
and
what
we're
up
to,
in
addition
to
the
work
that
ii
does
for
writing
tests
and
and
blocking
people
from
from
adding
new
apis
with
out
test.
We
also
have
had
a
lot
of
discussion
around
the
conformance
profiles
and
I
encourage
you
to
take
a
look
at
john's,
kept
and
give
feedback
on
that.
It's
been
a
lively
discussion
and
that's.