►
From YouTube: [SIG K8s-Infra] Bi-Weekly meeting for 20230927
Description
[SIG K8s-Infra] Bi-Weekly meeting for 20230927
A
A
We
we
might
get
some
increase
over
time.
We
don't
notice
that,
because
we
are
moving
a
few
proud
job
from
Google
to
JCP.
So
I
think
this
is
something
we'll
notice
over
time,
maybe
in
the
next
two
to
three
weeks,
which
might
be
the
only
change
I
yeah
I'm
aware
of
but
like
if
you
see
something
feel
free
to
yeah,
so
I
think
we
almost
end
of
the
month,
so
yeah
I
don't
see
anything
different
components.
Last
one.
E
A
A
F
F
A
A
A
A
A
Two
things
happening:
we
have
periodic
run
and
we
have
manual
runs
basically
three
job
trigger
manually
to
do
tests,
so
this
may
not
reflect
the
average
consumption
because
we
still
investigate
we
still,
we
I
think
we
spend
the
entire
month
when
I
say
we
mostly
folks
working
on
that
spend
the
entire
months
trying
to
debug
and
improve
chaos
in
order
to
make
that
happen.
So
I'm
not
sure
this
is
going
to
be
the
real
cause.
A
A
G
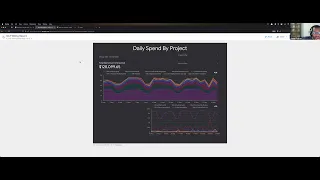
Just
on
the
cost
for
AWS,
there
is
the
moment:
83
000
of
credit
left
in
the
account
for
this
week.
I
didn't
check
the
consumption
up
to
now.
So
when
I
checked
over
the
weekend
on
on
your
Sunday,
we
had
a
few
thousand
left
and
the
previous
two
which
we've
earned
about
fifty
thousand
dollars.
So
we
should
just
be
cautious
that
we
don't,
in
the
last
few
days
of
the
month,
burn
through
83
000,
because
that
will
be
uncomfortable.
G
A
G
Yeah
I'm
just
saying
we
should
just
be
careful
not
to
burn
through
more
than
83
in
this
week,
but
I
I
think
we'll
be
good
if
we
just
follow
the
same
pattern
because
for
the
last
two
weeks
we
were
at
50.,
okay
and
then
on
on
that
topic.
What's
around
AWS
at
the
moment,
we
if
we
spend
the
way
we
spend
now
we're
gonna
reach
almost
2.7
million.
G
G
A
I
think
anything
I
think
next
year
is
a
is
the
next
year
conversation,
so
I
think
we
need
to
basically
finish
what
we're
doing
right
now
and
maybe
beginning
of
next
year.
We
come
back
to
this
conversation
again
and
see
what
we
can
do
in
terms
of
course,
I
would
say,
cost
them
optimization,
I'm,
not
really
worried
about
that.
A
Probably
about
were
about
the
trend.
We
are
because
I
think
we're
good
on
that.
I
think
we
are
really
good
on
that,
but,
like
so
when
we
finish
the
main
goal.
The
main
goal
here
was
like
basically
having
job
running
on
AWS
and
also
trying
to
move
things
outside
of
Google,
which
is
which
is
a
thing
in
progress,
and
that's
a
good
thing
and
later
we
can
talk
about
cost
optimization
when
we
are
like
end
of
the
year.
C
The
one
thing
I'll
say
like
well:
I
have
two
things
to
say:
one
and
Justin
kind
of
typed
out
exactly
what
I
was
gonna
say,
we're
at
the
point
where
we
can
kind
of
tune
things
and
like
I,
I,
looked
it
up
and
I
linked
it.
This
scale
job
is
running
every
12
hours.
We
could
have
our
costs
by
having
it
run
any
every
24
hours,
at
least
in
terms
of
the
scale
test
and
we're
still
probably
getting
like
data
resolution.
That's
useful
for
us
and
not
really,
you
know
impacting
too
much.
C
So
that's
good
to
that.
I
agree.
However,
what
I
will
say
is
I
know
in
Chicago
for
kubecon
there
are
going
to
be
discussions
about
what
to
what
the
donations
are
going
to
be
for
2024.
So
this
isn't
necessarily
A.
Let's
wait
until
the
end
of
the
year
type
of
thing.
This
is
something
that
we
need
to
think
about.
Sooner
than
December
sooner
than
November,
no
I
I
think.
A
Oh
I,
don't
want
to
say
no
I
like
we
don't
I,
don't
think
we
have
a
specific
control
of
the
donation
from
I
would
say
from
a
sick
prospective
or
excessive.
We
don't
have
control
on
that.
That's
why,
right
now
we
are,
we
monitor
course
we
acknowledge
was
to
Africa
is
going
to
be.
Basically,
we
have
some
kind
of
forecasts
until
end
of
the
year,
but
basically
between
now
and
November,
there's
a
lot
of
things
we
can
do
like.
Maybe,
like
you
say,
optimize,
sharp
right
job
brand.
A
Those
kind
of
thing
so
I'm
like
I,
don't
want
to
think
about
this
because
we
have
like
we
still
have
room
to
improve
things
like
there's,
there's
a
lot
of
story
behind
those
accounts,
so
we
didn't
cover
the
full
story
about
how
we
basically
use
the
club,
the
cloud
provider
right
now
so
I
think
like
right
now,
let's
have
full.
Let's
have
a
full
picture
of
the
infrastructure
and
think
about
how,
with
the
optimization
I
don't
want
to
do
optimization
when
I
don't
have
the
free
picture
of
everything.
G
And
also
something
else
to
add,
on
top
of
that,
looking
at
how
much
work
we
migrated
off
gcp
and
then
the
same
statement
that
I
made
about
Amazon
we're
almost
at
the
threshold
Google.
We
are
actually
now
headed
for
about
1.6
million
a
year
with
the
way
that
we
burn
it
now,
which
again
opens
the
conversation
of
all
the
things
that's
still
inside
Google.
G
A
Yeah
again,
those
type
of
conversations
next
to
your
conversation,
I,
want
to
focus
on
the
present
and
try
to
address
things.
I
can
address
quickly
like
I,
don't
want
big
playing
because
we're
almost
end
of
the
year
and
there's
like
still
a
lot
of
things
to
do
so.
I'm,
like
let's
focus
on
getting
through
the
full
infrastructure
owned
by
the
community.
Before
we
talk
about
cars,
because
if
you
try
to
do
optimization
right
now
and
later
say,
oh,
we
eat
technical
blocker
that
might
Conflict
at
some
point.
C
I
also
think
we're
we're
on
the
same
page,
I
think
we're
just
kind
of
saying
we're
saying
we
mean
the
same
thing,
but
we're
saying
different
things
like
in
my
mind.
We
still
have
a
whole
lot
of
work
to
do
to
move
things
right
and
we
need
to
focus
on
that.
First
and
foremost,
the
only
thing
that
I'm
saying
is
like
in
my
role
and
what
I'm
doing
I
need
to
make
sure
that
we
are
thinking
about
2024,
because
in
a
month
and
a
half
I'm
gonna
have
to
have
those
discussions
in
Chicago.
A
F
We
might
see
it
going
up
now.
The
number
is
lower.
We
had
lower
number
of
rollouts,
but
this
is
something
to
keep
an
eye
given
that
we
are
migrating
more
and
more
jobs.
So
it's
still
not
bad,
but
it's
something
to
keep
in
mind
that
it
might
go
a
bit
up.
Another
thing
that's
going
up
is
the
OBS
usage.
It's
still
not
bad,
but
it
got
from
a
few
dollars
to
a
few
hundred
dollars.
I
think
it
is
at
400
or
something
like
that.
It's
going
more
and
more
up.
F
So
this
is
definitely
picking
up.
It's
not
bad,
it's
nothing,
but
it's
nothing
to
keep
in
mind
in
case
you
see
even
more
increase,
so
I
honestly,
don't
know
how
many
users
are
adopting
it,
but
the
usage
is
going
up
and
actually
Cloud
front
is
quite
expensive.
It
seems
like
so.
This
is
something
to
pay
attention
to.
A
A
A
A
A
The
second
item
is
the
deprecation
of
the
kubernetes
really
is
broken.
Now
we
are
fastly
I
think
we
can
start
the
switch
to
a
community
on
bracket.
I
wish
I
talk
about
this
in
next
in
no
in
one
previous
six
release
so
talking
I'm
talking
under
micro
approval,
I
think
for
120
129.
We
want
to
announce
deprecation
into
the
description,
one
sorry
which
is
next
year
so
yeah
for
this
milestone.
A
A
F
D
D
We
shared
The
Proposal
with
the
meeting
participants
of
that
meeting,
and
we
received
some
feedback
during
the
meeting
as
well
as
between
meeting
and
now,
and
we
want
to
continue
the
conversation
around
the
proposal
and
ask
for
additional
feedback,
and
the
two
I
mean
topics
you
received
feedback
during
the
meeting
and
I.
Think
last
month
was
what
should
we
do?
You
know
eligibility
criteria,
as
you
know,
release
Shadow
program.
D
I'll
also
want
to
apply,
but
the
one
the
feedback
during
the
meeting
was
like.
We
should
perhaps
emit
the
applicants
to
kubernetes
organization
members
only
and
the
second
feedback
was
about
the
timeline
and
terms
so
I
made
those
updates
on
the
document
and
highlighted
those
parts
where
the
updates
were
made
and
just
again
want
to
bring
this
to
attention
of
the
group.
C
I
think
the
other
thing
that
I'll
add
is
much
as
Kate's
in
for
stuff
has
gotten
a
lot
done,
especially
in
the
last
eight
months.
We
don't
really
want
Kate's
infra
to
be
our
no
dims
and
Ben
and
Justin
in
a
trench
coat
as
as
we
keep
saying
so,
let's
at
least
try
and
get
some
things
going.
That
gets
more
people
involved.
A
A
C
A
I
think
my
take
would
be.
We
need
to
reduce
or
assumption
base,
basically
based
on
the
shadow
we
should
be
about
just
say
to
people
sure
just
show
up
if
you're
interested
do
the
job.
Do
it
not
specific
requirement,
you
don't
necessarily
need
to
you,
don't
necessarily
need
to
know
the
cloud
provider
in
detail
or
basically
the
one
thing
we're
looking
for.
Is
people
coming
and
doing
some
kind
of
commitment?
A
C
Yeah
I
feel
like
you
might
run
into
problems,
though,
because
there
are
certain
things
right
now
that
only
a
very
select
number
of
people
have
access
to,
and
so,
if
everyone
else
got
hit
by
a
bus,
there's
going
to
be
a
problem
right.
How
and
so
it's,
how
do
we
get
people
into
this
sig
and
Mentor
them
like
say,
Let's,
ignore
Let's,
ignore
the
technical
requirements
and
even
the
org
membership
of
this
proposal.
C
C
A
That's
why
you
have
technical
needs,
because
it's
now
up
up
to
technicalities
to
basically
build
that
that
trust.
What
you
basically
say,
what
we
talk
about
here
is
trust,
how
we
establish
trust
between
someone
outside
of
community
touching
the
core
of
physical
infrastructure.
This
is
a
trust
problem.
It's
not
a
technical
one,
how
you
solve
trust
at
scale
in
the
community,
like
that's,
like
that's
a
question
we
try
to
solve
for
so
many
years.
I,
don't
have
the
solution
for.
C
F
C
C
Comes
down
from
the
mountain
to
bestow
like
knowledge
and
wisdom
and
then
goes
away.
He
is
not
a
tech
lead
like
and
then
like
that
goes
to
Sig
organization,
but
what
I'm
saying
is
like
I
agree
with
what
you're
saying
I'm
just
trying
to
provide
and
produce
a
solution
that,
in
a
way
like
is
sustainable
for
the
community
I
like
we
can't
have
this
happen
again
and
I
know
you
have
been
trying
for
multiple
years
to
try
and
grow
this.
C
C
A
Okay,
so
I
think
we,
we
I,
think
there's
a
problem
of
like
basically
leadership
currently
in
the
scene,
and
the
only
way
to
address
is
to
like
have
rotate
current
yields
and
also
have
more
chills.
I.
Think
that's
like
the
one
thing.
The
first
thing
we
do,
but
also
I'm,
not
against
the
proposal.
Please,
if
you
want
to
go
if
you
want
to
basically
move
forward
with
this,
go
for
it
I'm
not
against
like,
but
my
just
concern
is
like
we
need
to
make
sure
we
don't
get
key
people
I.
A
A
What
I'm
saying
and
what
you're
proposing
is
most
like
a
compliments.
It's
like
basically
need
to
be
mixed
together,
yeah
because
yeah,
we
need
to
fix
our
leadership
problem
and
that's
true.
We've
been
waiting
for
too
long
for
this,
and
we
also
need
to
make
sure
we
don't
get
keep
people
when
they're
trying
to
be
to
be
part
of
the
city
and
I.
Think
that's
like
a
difficult
thing
to
do
so.
Yeah
yeah
we're
acting
the
way,
we're
aware
of
the
problem.
Just
let's
yeah.
D
Shadow
and
then
you
know
becoming
a
release
manager
for
the
next
release
and
that
actually
perhaps
gives
some
opportunity
to
know
for
their
force
to
be
recognized
and
may
hurt
them
when
they
go
and
talk
their
employers
to
spend
even
more
time
with
infra
like
sometimes
if
we
just
say
okay,
the
meetings
can
contribute.
It
doesn't
really,
at
least
in
my
experience.
D
It's
not
that
you
know
long-term
commitment,
because
sometimes
people
just
join
these
things
personal
time,
but
hang
some
official
kind
of
framework,
and
some
kind
of
you
know
Shadow
program
with
the
possibility
of
and
even
more
response
with.
This
would
actually
add
those
people
to
know
justify
their
engagement
as
well,
as
you
know,
get
some
kind
of
Return
of
investment
of
their
times.
A
Yeah
you,
you
you're
right,
that's
what
I'm
saying
I,
don't
basically
commitment
doesn't
mean
people
need
to
spend
40
hours
a
week
on
that,
it's
more
like.
If
we
basically
start.
Let's
say
we
start
a
shadow
program.
The
way
aspect
rotation,
because
the
rotation
cigarettes
might
not
be
the
same
in
other
cig
or
other
open
source
project.
So
do
we
expect
rotation
for
the
people
like
how
we
make
sure
people
are
happy
about
what
they
did
for
one
Milestone
and
walk
away
that,
like?
Maybe
people
want
to
stay
more
like
six
to
one
year?
A
Those
kind
of
situation
like
that's
what
I'm
saying
I'm,
not
against
the
idea
of
the
Shadow
program,
I'm
I'm,
just
concerned
about
the
requirement
to
enter
the
program
and
that's
like
the
one
thing
we
have
to
be
careful.
At
the
same
time,
yeah
Jeffy
said
yeah
we
need
have
because
having
program
having
a
shutter
program
means
you
need
to
have
mentors
and
that's
like
the
one
thing
we
are
missing.
Currently
we
don't
have
enough
Mentor.
If
we
have
20
people
coming
and
say:
oh
yeah,
we
want
to
be
shadows.
A
F
It's
just
been
up.
Okay,
sorry,
if
I
repeat
what
has
been
said,
I
have
been
a
little
off
but
yeah.
Quite
a
few
of
suggestions
for
my
side
about
this
sent
from
someone
who
has
experience
with
secret
list
way
of
working
I
think
it
is
very
important
to
make
a
distinction
here
that
this
is
not
like
your
listing,
so
the
very
releasing
work
is
that
you'll
get
a
bunch
of
tasks
to
work
on
like
go
to
this
GitHub
issue
and
then
post
this
comment
and
like
it
is
a
great
learning
opportunity.
F
This
is
something
that
is
for
sure
and
eventually
growing
up
to
a
mentoring
role,
but
the
issue
is
that
it
is
supposed
to
be
short
term,
and
this
is
not
about
here.
We
want
here
long
term
and
taking
release
team.
Is
some
cooperation
point
or
some,
let's
say
how
it
should
look
like
it
might
not
be
the
best
fit
here.
What
is
different
figures
that
might
be
helpful
is
how
release
engineering
team
works
or
release
management.
F
So
we
have
a
bunch
of
release
managers
to
the
release
manager,
Associates,
who
are
actually
long-term
team
rotated
or
added,
then
actually
Fox,
one
to
step
down
so
you'll
build
a
team
of
forks
and
you'll
check
up
upon
them,
regularly
make
sure
they're
up
with
us
that
they
still
want
to
stay
on
team
and
they
eventually,
if
needed,
add
new
folks.
So
this
theme
doesn't
really
have
to
constantly
having
your
forks
right.
F
This
has
been
mentioned
at
the
meeting,
so
we
can't
really
make
the
office
survey
and
then
have
a
bunch
of
fog
Supply,
and
then
there
are
tools
that
they
see
they
don't
like
it
disappear.
This
has
to
start
with
some
bootstrap
team
that
actually
has
experience
that
actually
have
a
good
track
record
of
being
engaged
in
the
community,
but
if
we
take
release
engineering
team
release
management
team
as
some
idea
that
might
work
better
than
release
team
actually
work,
because
this
is
definitely
not
a
good
way
of
working
for
this
team.
F
Exactly
and
I
will
personally
I
agree.
This
is
an
important
issue,
but
I
also
mentioned
this
in
chat.
I
think
we
should
try
to
decouple
the
technical
leadership
and
Leadership
of
this
thing
from
the.
How
are
we
going
to
work
with
this
because
I
strongly
believe
it
shouldn't
be
limited
that
you
have
access
to
the
infrastructure
only
to
the
technical
leads,
it
should
be.
A
team
like
you,
have
release
managers
who
have
elevated
access
to
everything.
That's
needed
that
are
not
strictly
leads,
actually
I
mean
speaking
of
signal.
It's
a
lot
of
release.
F
Managers
are
seriously,
but
there
are
some
exception
to
that.
There
are
a
few
of
us
that
are
not
please,
and
we
still
have
access
to
everything
that
we
need
to
do
the
job
so
I'm,
a
statistical
super
sensitive
like
some
super
important
secret
GitHub
talking
stuff,
like
that,
we
should
have
a
broader
people
covered
in
multiple
time
zones
that
can
actually
jump
they
do,
but
that
they're,
not
sick
leaders,
leaders,
but
only
people
who
have
this
access
and
that
we
have
communicated
it
and
that
we
have
like
it
somewhere
publicly.
F
A
Yeah,
there's
I
think
wait.
This
is
this
is
a
this
is
a
long
April
to
establish
Shadow
program.
We
might
need
more
than
one
more
conversation
about
this
I'm
happy
to
follow
up
with,
or
basically
you
give
your
fatty
and
teams.
Maybe
next
meeting
I
think
we
we
it's
good.
We
acknowledge
the
different
controller
problem
we
have
before.
We
basically
make
that
official.
A
B
Maybe
maybe
we
take
chance
there
and
say:
let's
try
to
solve
the
leadership
problem
directly
when
we
are
in
Chicago
at
least
come
up
there
with
a
solution.
I
mean
we
don't
need
to
implement
a
solution
in
Chicago,
but
maybe
we
can
have
a
talk
there
and
see
what
what
might
be
a
good
solution
for
a
leadership
topic,
and
then
we
can
move
forward
with
the
shadow
program
or
whatever
we
call
it
in
the
end.
C
A
F
C
C
A
C
Okay,
so
we
have
a,
we
have
a
an
agreement
with
Cube
cost
to
or
license
for
Cube
cost.
They
were
interested
in
us
installing
it
on
the
pro
eks
cluster,
so
we
can
use
it
to
actually
figure
out
how
much
each
job
and
each
I
don't
know
everything
costs,
and
we
can
kind
of
do
a
bit
better
of
a
price
and
budget
breakdown
like
we
can
get
pretty
granular
biggest
thing
is,
we,
you
know,
need
to
install
it,
so
we
just
need.
A
F
E
G
F
C
A
C
F
F
Me
so
this
issue
is
something
that
he
has
before
because
for
several
months
now
for
folks
who
are
not
aware
yet
of
it.
What
happens?
Is
that
notes
in
the
eks
costume
randomly
get
Frozen
completely
no
logs?
No
anything
basically
completely
Frozen,
and
we
don't
have
any
idea
what's
going
on,
because
we
don't
have
lots.
That's
the
first
thing.
There's
the
sacrifices.
We
don't
have
metrics,
we
don't
know
like
because
CPU
usage
or
the
process
that's
running
or
stuff
like
that,
there's
nothing.
F
We
have
been
working
with
abs
support
and
they
have
proposed
some
mitigation
over
the
time
and
I
apply
for
them
for
actually
taking
time
to
properly
figure
out
what's
going
on
and
they
even
have
their
senior
Linux
sanctioners
take
a
look
and
all
this
stuff
and
yeah.
So
none
of
the
mitigations
that
we
applied
actually
fixed
the
stability
issues,
there's
some
improvement.
In
my
opinion,
it's
maybe
not
as
bad
as
it
was,
but
it
didn't
help
so.
D
F
Have
idea
how
to
proceed
in
other
videos
and
what
they
want
from
us?
The
ABS
support
is
that
which
I,
Amazon,
Linux,
2
or
bottle
rocket.
The
problem
with
Amazon
is
that
it
doesn't
work
properly
with
kind.
So
that's
the
thing
and,
to
be
honest,
that's
working
for
us
because
it
doesn't
work
with
kind
properly.
It
can
spin
one
cluster,
but
if
it
tries
to
spin
another
cluster,
then
stuff
goes
wrong
and
yeah.
That's
not
good
good
enough
for
us
bottle
rocket
might
be
better
alternative
because
it
has
a
newer
kernel.
D
F
All
that
is
going
to
be
slightly
problematic,
because
we
also
have
to
make
sure
we
have
coordination
with
the
community,
because
if
we
decide
that
bottle
rocket
might
be
a
good
alternative,
we
would
have
to
put
it
in
production
and
that
might
make
tests,
and
we
would
need
to
make
sure
that
we
don't
affect
single
is
way
too
much
because
of
the
testing
signal.
Sdi.
D
F
And
also
other
community
members.
So
so
it's
not
going
to
be
easy
change,
but
they
want
the
ABS
support.
One
to
temporarily,
like
for
several
days
for
a
week,
run
some
of
the
operating
systems
that
they
maintain
because
they
might
be
able
to
more
easily
debug
it
because
they
have
more
idea
how
it
works
and
they
can
do
more
stuff
themselves
and
it's
much
harder
to
do
that
right
with
Ubuntu
right
now.
That
is
I'm
going
to
work
in
the
ETI
I'm.
Also
split
between
that
and
obs.
C
F
F
D
E
A
A
A
A
129.
Sorry
also
we
do
with
that.
Now
we
can
create
things
and
I
say:
break
quotes
because
we
don't
have.
We
don't
want
to
break
the
entire
Community
for
like
a
week,
but
I
have
a
breakup
two
to
three
days.
It's
fine,
there's,
no
SLA
on
the
on
the
CI,
so
I
would
say
yeah
make
sure
we
are
not
in
the
back
of
120
nine
release
and,
at
the
same
time
keep
going
with
AWS
support
team
because
yeah
they
will
try
to
escalate
the
thing
until
they
basically
say.
A
A
So
I
think
like
in
order
to
proceed.
If
you
want
to
basically
try
things,
let's
make
sure
we
are
not
if
we
are
not
affecting
the
release
of
129
by
moving
jobs,
the
master,
informing
and
master
blogging
to
GK.
So
we
sure
we
are
sure
like
we
are
not
in
the
path
of
129
now
for
allow
the
rest.
We
can
try
to
investigate
great
things
and
as
long
we
communicate
about
this
I
think
the
community
will
understand
that
we
are
trying
to
solve
an
existing
problem
and
it's
fine.
E
F
E
D
F
An
unpopular
opinion
because
if
we
are
moving
jobs
away,
we
are
decreasing
the
number
of
jobs,
that's
running
good.
We
are
making
it
harder
to
reproduce
the
issue
and
if
we
move
to
observate
change
the
amei
and
everything
works,
we
don't
know
if
it
is
because
we
move
jobs
here,
because
we
switched
the
Mei.
So
we
actually
need
to
keep
stuff
as
it
is,
and.
F
For
two
days
is
going
to
be
broke,
it's
important.
It
is
not
code
freeze
and
it's
not
postcode
freeze.
But
if
you
say
next
week,
it's
I
don't
know
week,
three
or
week,
four
yeah
it's
going
to
be
working
for
two
days
and
yeah,
don't
check
the
CI
signal.
It's
okay,
like
whatever
happens.
It
happens
and
we
are
going
to
see
what
happens,
because
if
you
now
start
moving
jobs
away
because,
okay,
let's
move
to
gcp,
we
reduce
the
number
of
jobs.
That's
running.
F
We
are
getting
official
because
yeah
we
are
moving
jobs
away
and
that's
going
to
fix
the
issue
themselves.
We
actually
have
seen
a
significant
Improvement
in
stability
once
we
moved
away
qbdm
jobs
because
there
is
much
less
jobs
running
in
that
faster
and
that
fixed
it
there's
like
no
point
in
doing
that
again,
because
more
jobs,
yeah
you're,
going
to
feed
the
stability
issues.
Disability
issues
only
happen.
If
you
have
like
more
stuff
running
on
the
cluster
like
more
jobs,
it
does
the
cap.
E
A
Why
not
have
Canary
version
of
this
master,
informing
masterbook
in
the
eks
classroom
and
have
like
a
separate
test
grade
dashboard
saying?
Oh,
those
I
cannot
raise
or
I
would
say
copy
of
the
mastering
from
a
master
blocking
from
GK
I'm
running
inside
AKs,
because
the
idea
is
to
make
sure
we
are
not
physically
CR
team
basically
have
good
visibility
on
the
CR
and
at
the
same
time,
if
you
want
to
investigate,
because
we
need
a
certain
number
of
projects,
we
just
make
the
canary
version
on
eks.
A
We're
not
we're
not
we're
not
breaking.
We
are
not
breaking
them
because
there's
an
existing.
Currently
we,
the
issue
is
happening
and
daughter
are
not
broken
right.
Now
we're
trying
to
establish
an
environment
where
we
can
do
we,
where
we
at
the
same
time,
we
make
sure
we
get
current
good
signal
for
the
release
and,
at
the
same
time,
we
investigate
the
issue,
because
we.
F
Could
basically
say
we
can't
we
can't
investigate
this
life.
We
can
only
see
if
it
is
going
to
change
anything.
If
it
is
not
going
to
change
anything,
then
we
have
to
take
some
other
approach
and
like
we
are
pretty
much
going
to
know
if
anything
changes
like
two
or
three
hours
after
switching
like
if
you
don't
see
because
pretty
much
it
happens,
every
several
hours
every
day.
So
if
you
don't
see
anything
happening
for
20
or
24
hours,
you
know
that
it
helped.
F
And
then
you
came
okay,
we
will
roll
out
back
and
then
we
will
figure
it
out.
If
something
bad
happens,
then
you
can
do
the
same
again.
You're
going
to
save
the
instance
to
do
the
rollout
back
to
Ubuntu
and
they're
going
to
investigate
that
field,
distance
so
like
as
soon
as
you
get
added
it.
We
don't
have
anything
broken
for
24
hours
so
that
we
get
the
first
instance
broken
after
a
few
hours.
You
can
pretty
much
roll
out
back
because
you
know
that
it's
broken
okay.
C
F
A
F
A
Let's
I
think
like
like
Marco,
said:
let's
like
wait
another
week,
get
feedback
from
it,
gets
reporting
and
see
what
we
can
decide
later.
I
think
yeah,
we
still
yeah
but
not
close
to
code
phrase,
so
I
think
it's
fine
we'll
leave
the
project
the
project
where
they
are
and
in
a
week
we
can
see
what's
happening.