►
From YouTube: Kubernetes SIG Multicluster 2021 Oct 19
Description
No description was provided for this meeting.
If this is YOUR meeting, an easy way to fix this is to add a description to your video, wherever mtngs.io found it (probably YouTube).
A
B
B
A
B
C
B
B
B
A
B
All
right,
I'm
taking
it,
I'm
taking
it
away
all
right,
so
I
mentioned
in
the
slack
yesterday
too,
but
I
wanted
to
talk
today
about
multi-cluster
topology,
aware
hints
and
I'm
gonna
do
kind
of
a
little
like
refresher,
slash
intro
for
anybody
who
doesn't
know
about.
What's
going
on
with
apology,
aware
hints
single
cluster
and
I
also
invited
rob
scott
from
sig
network
who's.
The
author
of
that
cap,
who
I
believe
is
on
the
line
now.
B
And
yeah,
so
I'm
going
to
talk
a
little
bit
about
that
and
then
I
kind
of
just
want
to
open
the
floor
for
here
I'll,
even
go
to
my
agenda
page.
How
about
that?
I
want
to
open
the
floor
for
discussing
what
this
existing
and
single
cluster
means
for
multi-cluster
services.
We've
talked
about
it
very
briefly
in
the
past,
and
there
is
some
language
in
the
kep
on
it
too,
that
you
know
we
will
support
basically
topology
aware
hints
at
some
point,
but
that
it
was
currently
in
flux.
B
B
If
we
need
to
advise
something
specific
if
we
need
to
say
anything
specific
about
implementations
or
about
how
this
integrates
with
single
cluster
and
how
it
it
changes
or
doesn't
change
for
multi-cluster,
and
I
have
some
like
seed
questions
at
the
end,
but
yeah
I'll
I'll,
stop
talking
about
the
agenda
and
just
talk
about
the
thing
now:
okay,
it
wouldn't
be
laura
loren's
slides.
If
it
didn't
have
a
bunch
of
google
slides
clipart
on
it,
so
here
we
are.
B
Basically
the
idea
for
single
cluster
topology
aware
is
to
try
and
address
this
question.
If
you're,
a
client
inside
this
cluster,
represented
by
the
circley
smiley
man
smiley
face,
is
what
this
is
called
you
and
you
have
a
cluster
ip
service.
You
might
want
to
ask
yourself
what
back
end
should
I
go
to
generally
for
cluster
ip
services.
The
idea
is
that
you
like
randomly
pick
or
it's
randomly
picked
for
you,
but
the
question
was
asked
in
sig
network.
Could
we
be
smarter
about
that?
B
One
is
that
it
provides
this
new
field
down
here
on
endpoint
slices,
so
this
is
endpoint
slice
type
that
can
be
a
string,
that's
some
type
of
zone,
and
the
idea
is
that
each
zone's
cube
proxy.
So,
like
a
cube
proxy
running
in
zone,
a
will,
look
on
endpoint
slice,
see
if
that
endpoint
slice
has
zone
a
annotated
on
it
and
we'll
be
like
okay
cool.
B
I
will
program
this
in
ip
tables,
because
I'm
zone
a
this
is
this
back
end
is
for
zone
a
we're
all
friends
right,
so
that's
kind
of
the
first
half
and
then
the
second
half
of
the
topology,
where
hands
kept,
is
that
it
also
provides
a
way
for
the
endpoint
controller
to
automatically
annotate
and
point
slices
with
these
hints.
So
you,
a
human
or
some
other
tooling,
wouldn't
need
to
attach
this
there's
an
auto
algorithm
that
was
decided
with
stig
network
that
for
all
the
endpoint
slices,
we'll
make
a
decision
of.
B
So
back
to
the
diagram,
our
happy
client
could
be
like.
Oh,
this
one
is
for
zone
orange
and
this
is
a
orange
I'm
in
the
orange
zone,
so
I
should
totally
go
there.
So
that's
the
the
idea
so
to
speak
a
little
bit
about
the
auto
part.
I
included
some
slides
to
explain
this
just
so
we
can
decide
if
this
is
relevant
for
for
us
in
multi-cluster
2.,
but
the
auto.
B
The
auto
behavior
to
automatically
add
annotations
to
all
endpoint
slices,
is
based
on
an
algorithm,
that's
emphasizing
the
capacity
of
each
zone.
So
the
idea
is
that
more
client
traffic
is
likely
to
originate
from
zones
with
bigger
with
more
nodes
in
it,
so
that
zone
should
have
more
back
ends,
allocated
annotated
with
that
zone.
So
there's
some
like
actual
words
down
here
from
the
caps
which
I've
also
turned
into
some
diagrams.
So
I'm
just
going
to
show
those
diagrams
here
really
quick,
so
we
can
all
be
on
the
same
page.
B
B
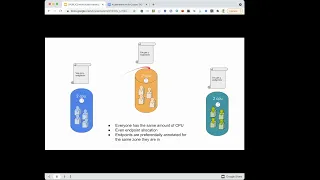
These
are
all
equally
likely
equally
likely
to
originate
client
traffic
that
might
want
to
go
to
one
of
these
back
ends,
so
each
back
end
gets
or
each
zone
the
teal
zone,
the
orange
zone
and
the
blue
zone
get
equivalent
numbers
of
back
ends,
annotated
with
their
zone
name
and
one
extra
sort
of
point.
That's
in
the
cap
is
that
endpoints
are
preferentially
annotated
for
the
same
zone
they're
in
so
in
this
situation.
If
we've
decided
everybody's,
even
so,
everybody
gets
four
endpoints
because
we
have
conveniently
four
endpoints
everywhere.
B
Then
they
all
get
annotated,
basically
with
their
same
zone,
because
they
will
try
and
choose
its
own
zone.
So
this
client
here
we
think
that
there's
going
to
be
sort
of
even
client
traffic
from
all
of
them,
because
they
have
the
same
capacity.
So
this
client
here
will
talk
to
its
blue
zone
back
ends.
This
client
here
will
only
ever
talk
to
its
orange
zone
back
ends,
and
this
one
will
talk
to
its
green
zone
back
ends,
so
where
this
is
different
is
if
one
zone
has
more
capacity
as
judged
by
cpus.
B
So
this
could
be
because
this
is
a
bigger
node
for
some
reason,
which
is
how
I
represented
this
in
clip
art
form,
or
it
could
just
be
that
there's
more
nodes
in
this
zone.
So
then,
the
algorithm
needs
to
just
to
basically
give
two
times
as
many
back-ends
to
the
blue
zone
annotation,
because
it
has
two
times
as
much
capacity
as
the
other
locations.
B
So
this
is
the
part
that
kind
of
sometimes
feels
confusing,
but
the
effect
here
since
we
need
six
endpoints
for
blue
three
endpoints
for
orange
and
three
endpoints
for
teal
is
that
we're
going
to
have
to
go
and
grab
some
end
points,
and
by
grab
I
mean
we
need
to
annotate
this
back
end
as
destined
for
traffic
from
blue
clients.
This
one,
even
though
it's
over
in
the
teal
zone
destined
for
traffic
from
blue
clients,
because
we
need
to
allocate
six
endpoints
to
this
blue
zone.
B
So
hopefully
the
pictures
helped
a
little
bit
explain
how
this
auto
behavior
works
and
again
this
auto
behavior
is
sort
of
half
of
of
the
whole
thing
right,
because
just
going
all
the
way
back,
there's
two
pieces
to
this.
The
fact
that
this
field
exists
at
all
that
anything
any
person
or
any
tool
could
fill
this
and
that
there's
a
single
cluster,
auto
behavior
that
operates
the
way
that
I
just
explained.
E
Hey
so
just
so,
I
understand
so
like
it
sounds
like
this
really.
Only
the
algorithm
only
drives
where,
like
which
endpoint
slices
get
the
annotation
like,
in
other
words
like
from
the
istio
perspective.
If
istio,
you
know,
obviously
needs
to
know
all
the
endpoints,
because
it
kind
of
implements
its
own
load.
Balancing
algorithm
will
all
endpoints
still
be
available.
C
F
B
So
this
is
kind
of
dense,
so
but
I'll
kind
of
go
through
them
one
by
one,
and
these
are
the
things
that
I'm
thinking
about
and
then
we
can
also
talk
about
anything
else.
Anybody
else
has
on
their
mind,
so
I
think
some
like
just
basic
questions
is:
if
this
is
a
property,
that's
set
on
a
service
which
it
is
there's
a
annotation
that
goes
on
a
service.
B
Is
that
something
that
we
need
to
carry
over
to
our
service
import,
or
you
know,
say
in
the
mcs
spec
that
we
need
to
carry
it
over?
Do
we
suggest
any
auto
behavior
at
all
from
that
is
like
or
any
auto
behavior
period?
If
so,
is
it
different
from
single
cluster,
auto
behavior
in
any
way
for
services
that
are
mcs?
B
So
one
interesting
thing
about
this:
auto
implementation
as
it
exists
today
is
it
needs
to
know
stuff
about,
like
all
the
nodes
right
and
right
now.
The
way
that
it's
going
to
be
designed
for
a
single
cluster
is
just
going
to
know
everything
about
the
nodes
in
one
cluster,
but
obviously,
if
we're
multi-clustered,
there's
nodes
in
other
clusters
to
consider
in
terms
of
capacity
planning,
if
we
were
going
to
be
mimicking
it
directly.
B
So
one
thing
is
that
the
hints
are
wrong
potentially
because
they
couldn't
take
into
account
if
they
were
designed
for
single
cluster
they're,
not
taking
into
account
the
potential
like
client
traffic
capacity
likelihoods.
I
guess
right.
The
proportion
of
client
traffic
that
we're
expecting
based
on
this
algorithm
from
the
other
cluster,
where
the
service
is
exported,
where
we
expect
client
traffic
to
try
and
contact
these
backends.
B
So
is
there
something
we
should
like
warn
people
or
like?
Should
we
do
something
about
this?
So
just
a
couple
more
slides
here
of
this
specific
case
is:
if
this
is
our
cluster
set
here
and
we
export
this
green
service
over
here
and
it
comes
with
its
location
and
annotation
or
sorry
if
it
comes
with
its
topology
hint
with
it.
That's
like.
Oh
I'm,
a
back
end
that
should
respond
to
blue
clients.
B
B
A
A
B
B
So
I
don't
know
if
that's
a
I
don't
know,
if
that's
a
relevant
point,
but
basically
if
a
multi-cluster
person
shows
up
and
like
now
added
some
zones,
basically
that
don't
like
don't
have
any
of
their
own
back
ends,
which
this
is
kind
of
questionable,
because
this
is
like
a
you
know,
shadow
back
end
here,
but
don't
have
any
of
their
own
back-ends.
Then
it
basically
turns
off.
G
F
F
F
F
E
B
F
F
F
F
F
F
F
F
F
F
E
F
B
F
F
A
F
F
A
A
B
F
F
D
D
F
B
D
B
I
think
if
I
am
getting
it
right,
it's
basically
just
going
to
do
like
round
robin
submarine
is
a
little
different,
but
just
basically
going
to
do
round
robin
across
all
of
the
exported
back
end
so
like
in
this
example.
I'm
pretending
that,
like
this
cluster,
doesn't
actually
have
any
of
its
own.
It
only
would
bump
over
here.
So
it
would
like
go
between
these.
It
doesn't
know
anything
about
these
hints,
yet
that's
the
part
under
discussion.
B
If,
instead,
this
was
like
actually
a
back
end
in
here,
it
would
bounce
between
this
and
all
of
these
guys,
if
they're
all
exported,
even
if
your
client
is
coming
from,
I
lost
my
smiley
face,
but
if
your
client
is
coming
from
over
here
for
submariner,
I
stephen
correct
me
if
I'm
wrong,
but
I
think
it
prefers
cluster.
First
cluster
local.
B
B
D
Under
the
the
41
has
say,
it
has
four
part
back
of
this
service
and
the
the
the
current
cluster
has
say
just
one
part
backing
up
with
the
balance.
Just
a
low
balance
between
I
mean
wrong
rubbing
between
two
clusters
so
which
leads
to
the
current.
The
the
one
part
get
hit
four
times
more
than
the
other
part,
or
it
would
be
really
low
balance.
H
Where
the
hints
fall
over
for
mcs
well
at
least
auto
hints,
as
they're
currently
defined,
because
inside
a
local
cluster,
the
you're
trying
to
optimize
for
a
request,
handling
capacity
and
so
number
of
cpus
or
node
size
for
and
some
metric
is
a
a
pretty
good
approximation
of
that.
But
then,
when
you're
crossing
from
one
cluster
to
another,
your
costs
are
going
to
be
quite
different
and
you
probably
want
to
optimize
for
something
other
than
cpu
capacity.
E
F
F
E
E
Yeah,
just
just
just
reiterating
like
it
just
seems
like
it's
very,
very
much
the
same
way
that
locality
information
is
kind
of
fundamental.
You
know
you're
you're
kind
of
driving
this
specific
hint
just
to
draw.
You
know
just
to
drive
that
you
know
particular
algorithm,
but
the
raw,
the
raw
data
is
is
just
generally
useful
and-
and
I
feel
like
any
sort
of
capacity,
information
might
be
more
in
that
category.
B
E
E
E
I
I
don't
know
in
in
terms
of
like
say
when
we
are
in
multicluster
right
and
we
have
two
other
clusters
say
we
have
no
service
endpoints
in
our
cluster,
so
we
want
to
go
to
the
other
ones.
Let's
say
you
know
like
they.
The
two
other
clusters
have
the
same
number
of
endpoints,
but
one
has
way
more
cpu
or
something
like
that.
You
know
so
we
may
we
may
choose
to
load
balance
slightly
differently.
In
that
case,.
F
E
F
F
F
F
E
Right
yeah,
so
I
mean
I
guess
what
I
see
is
whatever
raw
data
you're
using
to
determine
when
to
generate
those
hints.
I
mean
that's,
that's
fundamentally
saying
that
you
know
a
load.
Balancer
may
be
interested
in
this,
and
and
I'm
just
again
thinking
from
istio,
like
you
know,
if,
if
more
complex
load
balancers
you
know
want
to
do
something
clever,
it
might
be
useful
having
some
of
that
original
input.
E
If
such
a,
if,
if
the
simplistic
you
know
built-in
algorithm
that
kubernetes
comes
with
is,
is
going
to
use
that
then
perhaps
more
complicated
ones
will
as
well,
but
it's
just
a
thought,
but
but
yeah.
I
think
I
think
it's
going
to
be
one
of
those
things
like.
Let's,
let's
play
around
with
it
and
see
what
sort
of
stuff
is
useful.
B
A
Agenda
item
as
well,
but
I
think
in
it
would
be
great
to
cut
over
in
a
couple
minutes
to
jaromir
doing
a
demo
of
the
mcs
dns
plugin.
That's
that's
super
exciting
the.
If
we
could
real
quickly
just
discuss
that
first
question
that
we
didn't
get
to
yet,
I
think
rob.
Maybe
you
can
answer
this
for
us.
What
does
that
feature?
What
does
that
flag
do
for
a
service?
Does
that
is
that
intended
to
in
the
single
cluster
case?
B
B
A
A
B
Sorry,
I'm
kind
of
laggy
I
think,
but
I
feel
like
there's
a
weird
configuration
state
that
can
happen
where
we
pull
like.
We
bring
this.
It's
not
the
this,
but
we
bring
over
that
like
the
service
has
opted
in,
but
the
feature
gate
isn't
on
in
the
other
cluster,
and
I
don't
know
if
that's
weird
or
problematic.
B
Yeah,
maybe
there's
a
few
little
just
like
flow
charts
of
experiments
worth
like
thinking
about,
so
we
can
like
warn
people
for
mcs
like
if,
like
I
do,
think
we
need
to
carry
it
over
and
then
I
think
things
might
occur
differently
than
what
you
expect
if
the
future
gate
isn't
on
elsewhere,
and
so
that
can
be
part
of
the
category
of
things
where
like
similarly
to
if
you're,
mirroring
endpoint
slices,
there's
some
caveats.
I
guess
so.
A
Yeah,
actually,
that's
a
really
good
example.
Like
things
behave
differently
and
scale
is
different
in
clusters
that
support
endpoint
slice.
I
mean
they've
been
around
for
a
while
now,
but
clusters
that
support
it
voiceless
and
clusters
that
don't
but
yeah
laura.
I
think
great
idea
kind
of
writing
out
the
things
you
might
need
to
care
about,
but
I
don't
know
that
we
need
to
specifically
address
them.
Although
all
this
says
you
know,
rob
good
luck,
getting
it
to
beta
and
on
by
default.
123.
F
A
F
A
A
G
G
As
I
learned,
this
is
one
of
the
blockers
for
the
multicaster
api
graduation
to
beta,
so
I
actually
decided
to
kick
start
the
implementation
of
the
multi-cluster
dns
and,
as
we
discussed
with
laura
before
one
of
the
ways
how
to
do
that
is
actually
to
implement
a
separate
core,
dns
plugin.
It
can
be
just
enabled
and
it
would
support
multi-clustering
spec.
So
that's
that's
what
I
published
here
on
my
on
my
github.
G
So
from
the
from
the
implementation
perspective,
the
way
it
works.
It's
super
easy.
It's
almost
identical
to
the
existing
kubernetes
plugin,
so
I
actually
forgot
most
of
the
code
and
the
way
it
works
it
in
it.
It
runs
a
controller
in
the
background
and
it's
this
controller
monitors
all
service
imports
and
translates
all
queries
for
clusterset.local
zone
to
those
service
imports,
and
I
just
want
to
quickly
show
how
this
can
be
used
because
it
can
be
just
plugged
in
into
the
existing
code
dns.
G
G
So
it's
super
simple
as
that,
and
then
I
just
need
to
recompile
rebuild
the
code
dns
and
then
modify
the
cross
clusters
core
file
to
to
define
the
zone.
That's
going
to
be
managed
by
the
multi-cluster
plug-in
and
that's
it,
and
actually
I
can
show
you
just
quickly
how
this
works
live.
So
I
hope
you
can.
I
hope
the
font
is
not
too
small
and
you
can
read
it
so
I
have
my
own
service
import
here.
So
this
is.
G
G
So,
okay,
it
was
already
applied
before
so
anyway.
Now
now
I
can
actually
exercise
my
coordinates.
I'm
running
the
custom
build
locally
and
it
points
to
the
cluster,
and
so
I
can
do
I
can
do.
I
can
use
dick
to
send
dns
requests
and
I
can
now
just
follow
the
multi-cluster
in
a
spec.
So
for
a
records
we
know
it's,
it's
the
service
name
right.
It's
a
test
service
in
my
case,
namespace
is
my
namespace.
G
G
I'm
getting
the
ip
this
cluster
set
ip
defined
in
the
in
the
import.
I
can
do
the
same
for
for
srv,
obviously
following
the
spec,
so
in
case
of
srv,
I'm
getting
srv
with
the
board
as
well,
and
I
can
also
follow
the
more
precise
format
of
the
srv.
That's
a
the
board
and
the
vertical
I'm
following
this
as
srv
spec
tcp
right
and
I'm
gonna
get
the
same.
G
So
this
is
for
the
srv
support.
So
so
far
we
have
pretty
much
like
full
support
of
cluster
set
ips.
I
have
one
open
issue
here
and
it's
large
item
to
support
headless
services,
because
that's
something
I
don't
have
yet
so
it's
still
in
progress.
I
guess
my
question
is:
what
are
the
next
steps
here
because,
like
eventually,
I
assume
we
may
want
to
offer
this
to
core
dns
and
ideally
become
part
of
cardenas?
Is
that
is
that
true.
A
E
A
A
G
A
B
Together
there
was
someone
at
cuba
named
aaron
who
was
kind
of
interested,
so
I'll
connect
with
him
too
and
then
yeah.
It
sounds
like
there's
some
other
floating
around
implementations
we
might
want
to
pull
in
and
then
yeah
100
agree
to
get
this
and
as
like
incordian
s2.
So
we
can
figure
out
what
the
plan
is
for.